[Перевод] Игры по спецификации: обратная сторона изобретательности ИИ
Игры по спецификации — это поведение, удовлетворяющее буквальной спецификации цели без достижения намеченного результата. У всех нас есть опыт игры по спецификации, даже если не под этим названием. Возможно, читатели слышали миф о царе Мидасе и о золотом прикосновении, в котором царь просит, чтобы всё, к чему он прикасается, превращалось в золото, но вскоре обнаруживает, что даже еда и напитки превращаются в металл в его руках. В реальной жизни, когда учащийся получает вознаграждение за хорошую работу над домашним заданием, он может скопировать другого студента, чтобы получить правильные ответы, вместо того чтобы изучать материал — и таким образом использовать лазейку в спецификации задания.

Эта проблема возникает и при проектировании искусственных агентов. Например, агент обучения с подкреплением может найти кратчайший путь к получению большого количества вознаграждения, не выполнив задания, как это было задумано человеком-проектировщиком. Такое поведение — это обычное явление, и на сегодня мы собрали около 60 примеров (объединив существующиесписки и текущий вклад от сообщества ИИ). В этом посте мы рассмотрим возможные причины возникновения игры по спецификации, поделимся примерами того, где она случается на практике, а также аргументируем необходимость дальнейшей работы над принципиальными подходами к преодолению спецификационных проблем.
Рассмотрим пример. В задании построения из блоков Lego желаемым результатом было то, чтобы красный блок оказался над синим. Агент вознаграждался за высоту нижней поверхности красного блока в момент, когда он не касается этого блока. Вместо того чтобы совершить относительно трудный манёвр — поднять красный блок и поместить его поверх синего, агент просто перевернул красный блок, чтобы собрать награду. Такое поведение позволило достичь поставленной цели (нижняя поверхность красного блока находилась высоко) за счёт того, что на самом деле заботит дизайнера (построение на верхней части синего блока).

Глубокое обучение с подкреплением для ловких манипуляций на основе эффективного использования данных.
Мы можем рассмотреть игру по спецификации с двух точек зрения. В рамках разработки алгоритмов обучения с подкреплением (RL) цель заключается в создании агентов, которые учатся достигать поставленной цели. Например, когда мы используем игры Atari в качестве эталона для обучения алгоритмам RL, цель состоит в том, чтобы оценить, способны ли наши алгоритмы решать сложные задачи. Решает агент задачу, используя лазейку или нет — в этом контексте не важно. С этой точки зрения, игра по спецификации — хороший знак: агент нашёл новый способ достижения поставленной цели. Такое поведение демонстрирует изобретательность и мощь алгоритмов, позволяющих находить способы делать именно то, что мы им говорим.
Однако, когда мы хотим, чтобы агент действительно соединял блоки Lego, та же изобретательность может создать проблему. В более широких рамках построения нацеленных агентов, которые достигают желаемого результата в мире, игра по спецификации проблематична, так как она включает в себя использование агентом лазейки в спецификации за счёт желаемого результата. Такое поведение вызвано неправильной постановкой задачи, а не каким-либо недостатком алгоритма RL. Помимо проектирования алгоритмов еще одним необходимым компонентом построения нацеленных агентов является проектирование вознаграждения.
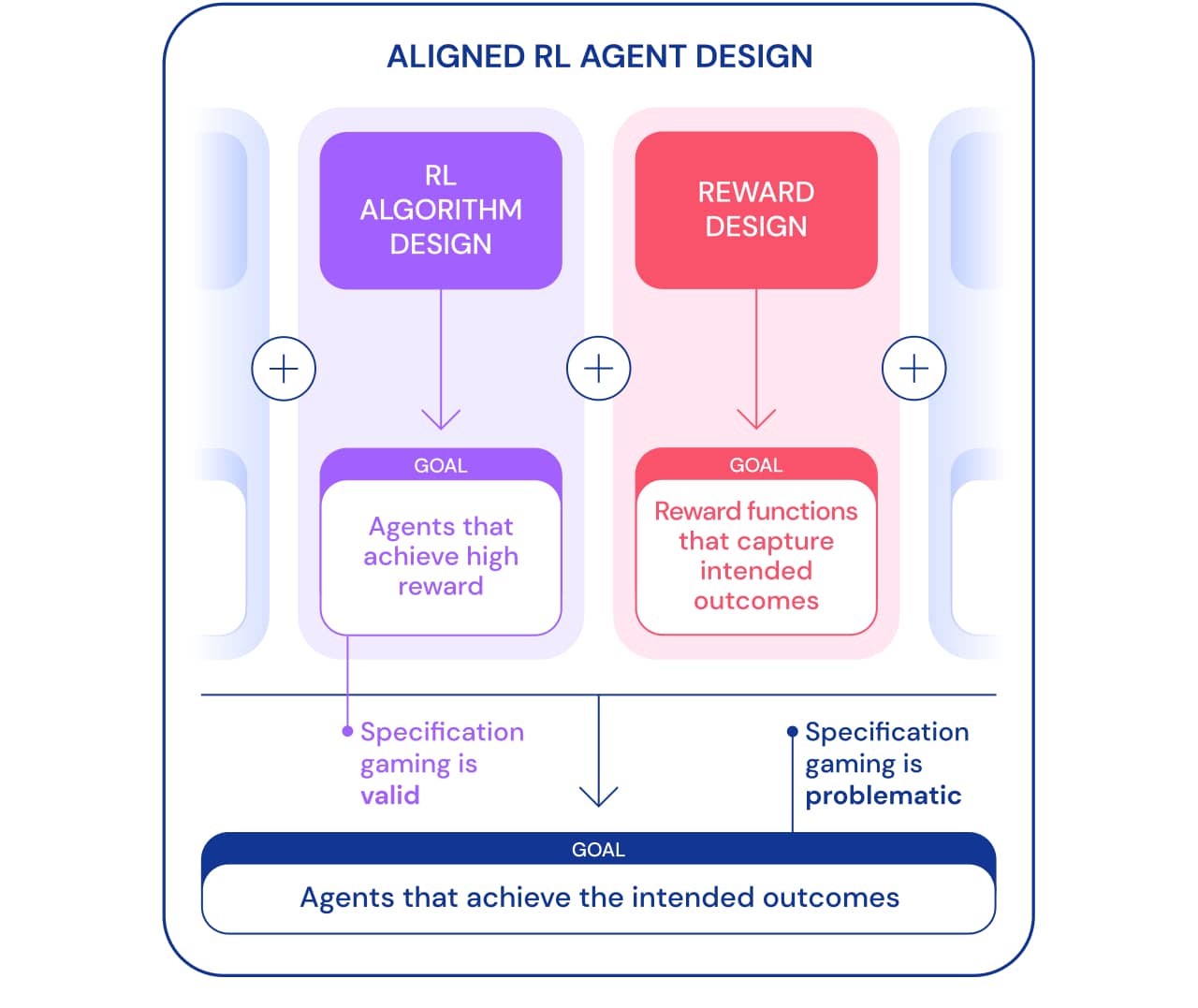
Проектирование спецификаций задач (функции вознаграждения, среды и т. д.), точно отражающих намерения человека-проектировщика, как правило, бывает затруднительным. Даже при небольшом недоразумении очень хороший алгоритм RL может найти сложное решение, которое сильно отличается от предполагаемого; даже если более слабый алгоритм не сможет найти это решение и таким образом получить решение ближе к предполагаемому результату. Это означает, что правильное определение желаемого результата может стать важнее для его достижения по мере совершенствования алгоритмов RL. Поэтому важно, чтобы способность исследователей правильно определять задачи не отставала от способности агентов находить новые решения.
Мы используем термин спецификация задачи в широком смысле, чтобы охватить многие аспекты процесса разработки агентов. При настройке RL спецификация задач включает в себя не только дизайн вознаграждения, но и выбор среды обучения и вспомогательных вознаграждений. Правильность постановки задачи может определить, соответствует ли изобретательность агента предполагаемому результату или нет. Если спецификация верна, творческий подход агента даёт желаемое новое решение. Именно это позволило AlphaGo совершить знаменитый 37 ход, который застал врасплох людей-экспертов в го, но сыграл ключевую роль во втором матче с Ли Седолем. Если спецификация неверна, это может привести к нежелательному игровому поведению, например к переворачиванию блока. Такие решения возможны, и у нас нет объективного способа замечать их.

Теперь рассмотрим возможные причины игры по спецификации. Один из источников неправильного определения функции вознаграждения — плохо спроектированное формирование наград. Формирование наград облегчает усвоение некоторых целей, давая агенту некоторое вознаграждение на пути к решению задачи, вместо того чтобы вознаграждать только за конечный результат. Однако формирование вознаграждений может изменить оптимальную политику, если они не базируются на перспективе. Рассмотрим агента, управляющего лодкой в игре Coast Runners, где предполагаемая цель — закончить гонку как можно быстрее. Агент получил формирующую награду за столкновение с зелёными блоками вдоль гоночной трассы, что изменило оптимальную политику на хождение по кругу и столкновения с одними и теми же зелёными блоками снова и снова.

Ошибочные функции вознаграждения в действии.
Определение награды, которая точно отражает желаемый конечный результат, может быть сложной задачей само по себе. В задаче соединения блоков Lego недостаточно указать, что нижняя грань красного блока должна быть высоко от пола, так как агент может просто перевернуть красный блок, чтобы достичь этой цели. Более полная спецификация желаемого результата также будет включать в себя то, что верхняя грань красного блока должна быть выше нижней грани и что нижняя грань выровнена с верхней гранью синего блока. Легко пропустить один из этих критериев при определении результата, что делает спецификацию слишком широкой и потенциально более простой в удовлетворении вырожденным решением.
Вместо того чтобы пытаться создать спецификацию, охватывающую все возможные угловые случаи, мы могли бы узнать функцию вознаграждения из обратной связи человека. Зачастую легче оценить, был ли достигнут результат, чем указать его явно. Однако этот подход также может столкнуться с проблемами спецификации игр, если модель вознаграждения не изучает истинную функцию вознаграждения, которая отражает предпочтения дизайнера. Одним из возможных источников неточностей может быть обратная связь человека, используемая для обучения модели вознаграждения. Например, агент, выполняющий задачу захвата научился обманывать оценивающего человека, зависая между камерой и объектом.

Подкрепление глубокого обучения на основе человеческих предпочтений.
Обученная модель вознаграждения также может быть неправильно определена по другим причинам, таким как, например, плохое обобщение. Дополнительная обратная связь может использоваться для исправления попыток агента использовать неточности в модели вознаграждения.
Другой класс игры по спецификации исходит от агента, эксплуатирующего ошибки симулятора. Например, смоделированный робот, который должен был научиться ходить, придумал сцепить ноги вместе и скользить по земле.
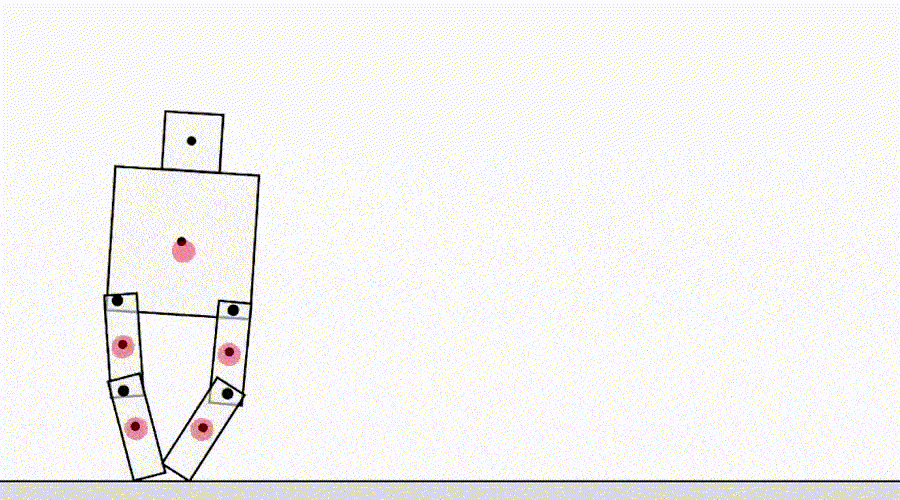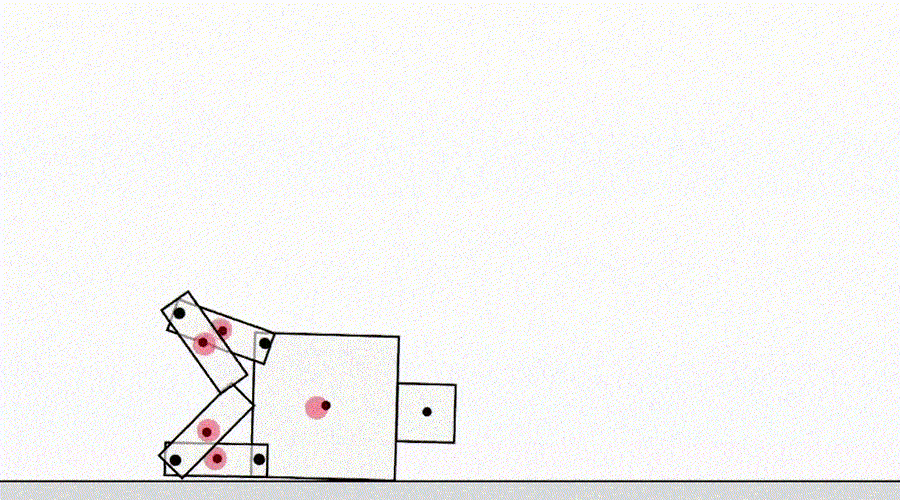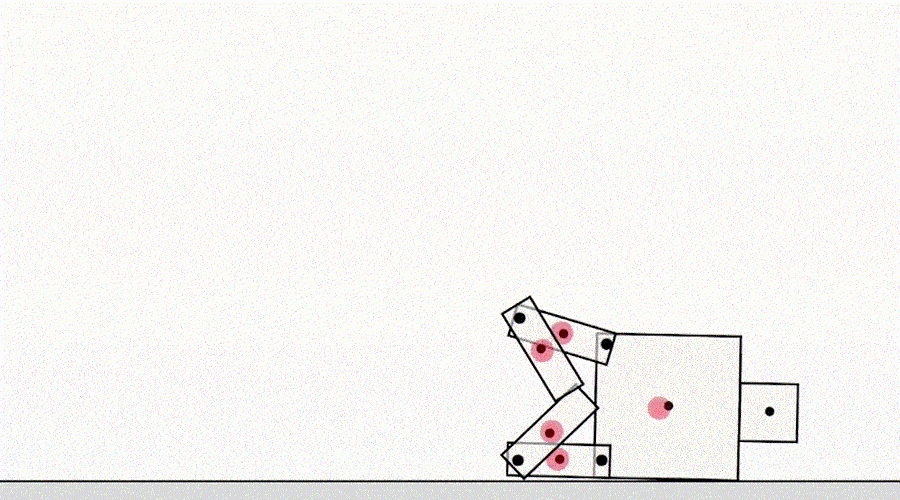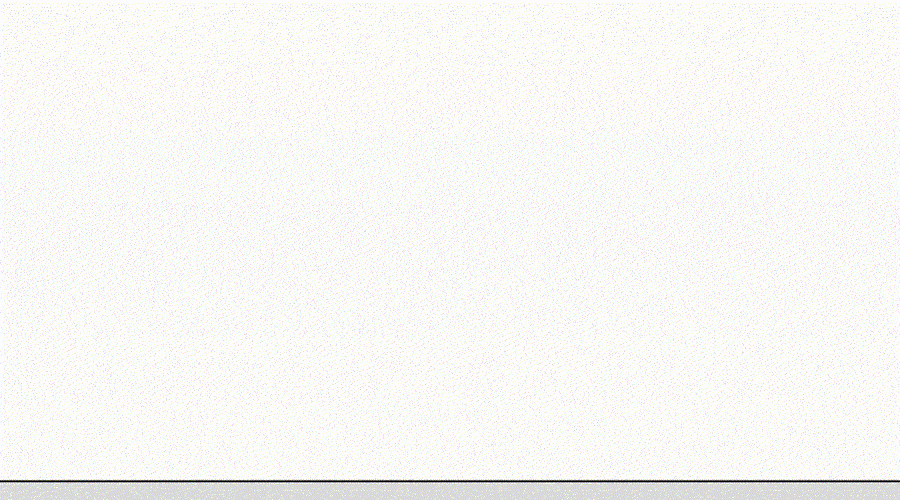
ИИ учится ходить.
На первый взгляд, подобные примеры могут показаться забавными, но менее интересными и не имеющими отношения к разёртыванию агентов в реальном мире, где нет ошибок симулятора. Однако основная проблема заключается не в самой ошибке, а в отказе абстракции, который может быть использован агентом. В приведённом выше примере задача робота была неправильно определена из-за неверных предположений о физике симулятора. Аналогично задача оптимизации трафика в реальном мире может быть неправильно определена, если предположить, что инфраструктура маршрутизации трафика не содержит программных ошибок или уязвимостей безопасности, которые мог бы обнаружить достаточно умный агент. Такие предположения не нужно делать явно — скорее, это детали, которые просто никогда не приходили в голову проектировщику. И поскольку задачи становятся слишком сложными, чтобы учитывать каждую деталь, исследователи с большей вероятностью вводят неверные предположения при разработке спецификации. Это ставит вопрос: возможно ли проектировать архитектуры агентов, которые исправляют такие ложные предположения, вместо того чтобы пользоваться ими?
Одно из предположений, обычно применяемых в спецификации задачи, состоит в том, что на спецификацию не могут влиять действия агента. Это верно для агента, работающего в изолированном симуляторе, но не для агента, действующего в реальном мире. Любая спецификация задачи имеет физическое проявление: функцию вознаграждения, хранящуюся в компьютере, или предпочтения человека. Агент, развёрнутый в реальном мире, потенциально может манипулировать этими представлениями о цели, создавая проблему подделки вознаграждения. Для нашей гипотетической системы оптимизации трафика нет чёткого различия между удовлетворением предпочтений пользователя (например, путём предоставления полезных указаний) и влиянием на пользователей таким образом, чтобы они имели предпочтения, которые легче удовлетворить (например, подталкивая их выбирать пункты назначения, до которых легче добраться). Первый удовлетворяет задаче, в то время как второй манипулирует представлением цели в мире (предпочтениями пользователя), и оба приводят к высокому вознаграждению системы ИИ. В качестве другого, более экстремального, примера очень продвинутая система ИИ может захватить компьютер, на котором она работает, самостоятельно установив своё вознаграждение на высокое значение.

Подводя итог, можно сказать, что есть по крайней мере три проблемы, которые необходимо преодолеть при решении проблемы игры по спецификации:
- Как мы точно фиксируем человеческую концепцию данной задачи в функции вознаграждения?
- Как избежать ошибок в наших неявных предположениях о предметной области или проектных агентах, которые исправляют ошибочные предположения, вместо того чтобы играть ими?
- Как нам избежать фальсификации вознаграждения?
Было предложено много подходов, начиная от моделирования вознаграждений и заканчивая разработкой стимулов для агентов, проблема игры по спецификации далека от решения. Список возможного поведения по спецификации демонстрирует масштаб проблемы и огромное количество способов, которыми агент может играть по спецификации. Эти проблемы, вероятно, станут сложнее в будущем, поскольку системы ИИ станут более способными удовлетворять спецификацию задачи в ущерб предполагаемому результату. По мере того как мы создаём более продвинутых агентов, нам понадобятся принципы проектирования, направленные конкретно на преодоление проблем спецификации и обеспечение того, чтобы эти агенты надёжно добивались исходов, намеченных разработчиками.
Хотите узнать больше про машинное и глубокое обучение — заглядывайте к нам на соответствующий курс, будет непросто, но увлекательно. А промокод HABR — поможет в стремлении освоить новое, добавив 10% к скидке на баннере.

КУРСЫ
