[Перевод] GraphQL и Golang
Технология GraphQL за последние несколько лет, после того, как компания Facebook перевела её в разряд опенсорсных, стала весьма популярной. Автор материала, перевод которого мы сегодня публикуем, говорит, что попробовал работать с GraphQL в среде Node.js и на собственном опыте убедился в том, что эта технология, благодаря её замечательным возможностям и простоте, неслучайно привлекает к себе столько внимания. Недавно он, занимаясь новым проектом, перешёл с Node.js на Golang. Тогда он и решил испытать совместную работу Goland и GraphQL.

Предварительные сведения
Из официального определения GraphQL можно узнать о том, что это — язык запросов для API и среда выполнения для исполнения таких запросов над существующими данными. GraphQL даёт полное и понятное описание данных в некоем API, позволяет клиентам запрашивать именно ту информацию, которая им нужна, и ничего больше, упрощает развитие API с течением времени и даёт разработчикам мощные инструменты.
Существует не так много GraphQL-библиотек для Golang. В частности, я испытал такие библиотеки, как Thunder, graphql, graphql-go, и gqlgen. Должен отметить, что лучшим из всего, что я опробовал, стала библиотека gqlgen.
Библиотека gqlgen всё ещё пребывает на стадии бета-версии, в момент написания данного материала это была версия 0.7.2. Библиотека стремительно эволюционирует. Здесь можно узнать о планах по её развитию. Теперь официальным спонсором gqlgen является проект 99designs, а это значит, что эта библиотека, вполне возможно, будет развиваться ещё быстрее, чем прежде. Основными разработчиками этой библиотеки являются vektah и neelance, при этом neelance, кроме того, работает над библиотекой graphql-go.
Поговорим о библиотеке gqlgen исходя из предположения о том, что у вас уже имеются базовые знания о GraphQL.
Особености gqlgen
В описании gqlgen можно узнать о том, что перед нами — библиотека для быстрого создания строго типизированных GraphQL-серверов на Golang. Эта фраза мне кажется весьма многообещающей, так как это говорит о том, что работая с этой библиотекой я не столкнусь с чем-то вроде map[string]interface{}, так как тут используется подход, основанный на строгой типизации.
Помимо этого данная библиотека использует подход, в основе которого лежит схема данных. Это означает, что API описывают, используя язык определения схем (Schema Definition Language) GraphQL. С этим языком связаны собственные мощные инструменты генерирования кода, которые автоматически создают GraphQL-код. Программисту при этом остаётся лишь реализовать базовую логику соответствующих методов интерфейса.
Эта статья разделена на две части. Первая посвящена основным приёмам работы, а вторая — продвинутым.
Основные приёмы работы: настройка, запросы на получение и изменение данных, подписки
Мы, в качестве экспериментального приложения, будем использовать сайт, на котором пользователи могут публиковать видеозаписи, добавлять скриншоты и обзоры, искать видеозаписи и просматривать списки записей, связанных с другими записями. Начнём работу над этим проектом:
mkdir -p $GOPATH/src/github.com/ridhamtarpara/go-graphql-demo/
Создадим следующий файл со схемой данных (schema.graphql) в корневой директории проекта:
type User {
id: ID!
name: String!
email: String!
}
type Video {
id: ID!
name: String!
description: String!
user: User!
url: String!
createdAt: Timestamp!
screenshots: [Screenshot]
related(limit: Int = 25, offset: Int = 0): [Video!]!
}
type Screenshot {
id: ID!
videoId: ID!
url: String!
}
input NewVideo {
name: String!
description: String!
userId: ID!
url: String!
}
type Mutation {
createVideo(input: NewVideo!): Video!
}
type Query {
Videos(limit: Int = 25, offset: Int = 0): [Video!]!
}
scalar Timestamp
Тут описаны базовые модели данных, одна мутация (Mutation, описание запроса на изменение данных), которая используется для публикации на сайте новых видеофайлов, и один запрос (Query) на получение списка всех видеофайлов. Почитать подробности о схеме GraphQL можно здесь. Кроме того, здесь мы объявили один собственный скалярный тип данных. Нам недостаточно тех 5 стандартных скалярных типов данных (Int, Float, String, Boolean и ID), которые есть в GraphQL.
Если вам нужно использовать собственные типы, вы можете объявлять их в schema.graphql (в нашем случае таким типом является Timestamp) и предоставлять их определения в коде. При использовании библиотеки gqlgen нужно предоставить методы для маршалинга и анмаршалинга для всех собственных скалярных типов и настроить маппинг c помощью gqlgen.yml.
Нужно отметить, что в последней версии библиотеки появилось одно важное изменение. А именно, из неё была удалена зависимость от скомпилированных бинарных файлов. Поэтому в проект надо добавить файл scripts/gqlgen.go следующего содержания:
// +build ignore
package main
import "github.com/99designs/gqlgen/cmd"
func main() {
cmd.Execute()
}
После этого нужно инициализировать dep:
dep init
Теперь пришло время воспользоваться возможностями библиотеки по генерированию кода. Они позволяют создавать весь скучный шаблонный код, который, однако, нельзя назвать совсем уж неинтересным. Для запуска механизма автоматического генерирования кода выполним следующую команду:
go run scripts/gqlgen.go init
В результате её выполнения будут созданы следующие файлы:
gqlgen.yml: конфигурационный файл, позволяющий управлять генерацией кода.generated.go: сгенерированный код.models_gen.go: все модели и типы данных предоставленной схемы.resolver.go: тут будет находиться код, который создаёт программист.server/server.go: точка входа сhttp.Handlerдля запуска сервера GraphQL.
Взглянем на сгенерированную модель для типа Video (файл generated_video.go):
type Video struct {
ID string `json:"id"`
Name string `json:"name"`
User User `json:"user"`
URL string `json:"url"`
CreatedAt string `json:"createdAt"`
Screenshots []*Screenshot `json:"screenshots"`
Related []Video `json:"related"`
}
Здесь можно видеть, что ID является строкой, CreatedAt — это тоже строка. Другие связанные модели настроены соответствующим образом. Однако в реальных приложениях это не нужно. Если вы используете какой-нибудь тип данных SQL, то вам нужно, например, чтобы поле ID имело бы, в зависимости от используемой базы данных, тип int или int64.
Например, я использую PostgreSQL в этом демонстрационном приложении, поэтому, конечно, мне нужно, чтобы поле ID имело бы тип int, а поле CreatedAt — тип time.Time. Это приводит к тому, что нам нужно определить собственную модель и указать gqlgen на то, что нужно использовать нашу модель вместо того, чтобы генерировать новую. Вот содержимое файла models.go:
type Video struct {
ID int `json:"id"`
Name string `json:"name"`
Description string `json:"description"`
User User `json:"user"`
URL string `json:"url"`
CreatedAt time.Time `json:"createdAt"`
Related []Video
}
// Объявим базовый тип int для ID
func MarshalID(id int) graphql.Marshaler {
return graphql.WriterFunc(func(w io.Writer) {
io.WriteString(w, strconv.Quote(fmt.Sprintf("%d", id)))
})
}
// То же самое делается и при анмаршалинге
func UnmarshalID(v interface{}) (int, error) {
id, ok := v.(string)
if !ok {
return 0, fmt.Errorf("ids must be strings")
}
i, e := strconv.Atoi(id)
return int(i), e
}
func MarshalTimestamp(t time.Time) graphql.Marshaler {
timestamp := t.Unix() * 1000
return graphql.WriterFunc(func(w io.Writer) {
io.WriteString(w, strconv.FormatInt(timestamp, 10))
})
}
func UnmarshalTimestamp(v interface{}) (time.Time, error) {
if tmpStr, ok := v.(int); ok {
return time.Unix(int64(tmpStr), 0), nil
}
return time.Time{}, errors.TimeStampError
}
Укажем библиотеке на то, что она должна пользоваться этими моделями (файл gqlgen.yml):
schema:
- schema.graphql
exec:
filename: generated.go
model:
filename: models_gen.go
resolver:
filename: resolver.go
type: Resolver
models:
Video:
model: github.com/ridhamtarpara/go-graphql-demo/api.Video
ID:
model: github.com/ridhamtarpara/go-graphql-demo/api.ID
Timestamp:
model: github.com/ridhamtarpara/go-graphql-demo/api.Timestamp
Смысл этого всего заключается в том, что у нас теперь имеются собственные определения для ID и Timestamp с методами для маршалинга и анмаршалинга и их маппинг в файле gqlgen.yml. Теперь, когда пользователь предоставляет строку в виде ID, метод UnmarshalID() преобразует эту строку в целое число. При отправке ответа метод MarshalID() преобразует число в строку. То же самое происходит и с Timestamp или с любым другим скалярным типом, объявленным программистом.
Теперь пришло время реализации логики приложения. Откроем файл resolver.go и внесём в него описания мутаций и запросов. Тут уже имеется автоматически сгенерированный шаблонный код, который нам нужно наполнить смыслом. Вот код этого файла:
func (r *mutationResolver) CreateVideo(ctx context.Context, input NewVideo) (api.Video, error) {
newVideo := api.Video{
URL: input.URL,
Name: input.Name,
CreatedAt: time.Now().UTC(),
}
rows, err := dal.LogAndQuery(r.db, "INSERT INTO videos (name, url, user_id, created_at) VALUES($1, $2, $3, $4) RETURNING id",
input.Name, input.URL, input.UserID, newVideo.CreatedAt)
defer rows.Close()
if err != nil || !rows.Next() {
return api.Video{}, err
}
if err := rows.Scan(&newVideo.ID); err != nil {
errors.DebugPrintf(err)
if errors.IsForeignKeyError(err) {
return api.Video{}, errors.UserNotExist
}
return api.Video{}, errors.InternalServerError
}
return newVideo, nil
}
func (r *queryResolver) Videos(ctx context.Context, limit *int, offset *int) ([]api.Video, error) {
var video api.Video
var videos []api.Video
rows, err := dal.LogAndQuery(r.db, "SELECT id, name, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2", limit, offset)
defer rows.Close();
if err != nil {
errors.DebugPrintf(err)
return nil, errors.InternalServerError
}
for rows.Next() {
if err := rows.Scan(&video.ID, &video.Name, &video.URL, &video.CreatedAt, &video.UserID); err != nil {
errors.DebugPrintf(err)
return nil, errors.InternalServerError
}
videos = append(videos, video)
}
return videos, nil
}
Теперь опробуем мутацию.
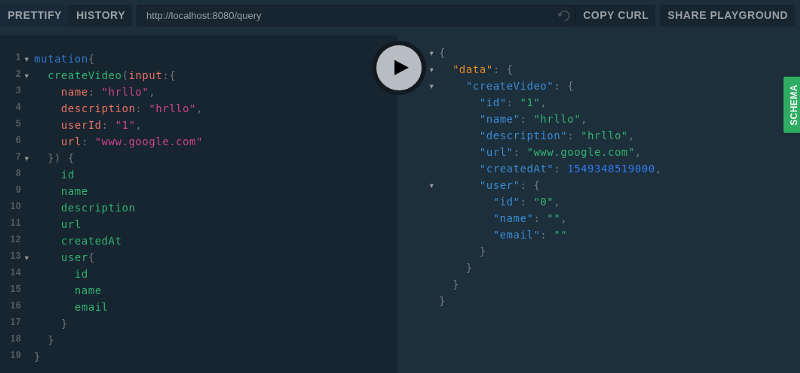
Мутация createVideo
Работает! Но почему в сведениях о пользователе (объект user) ничего нет? При работе с GraphQL применимы концепции, похожие на «ленивую» (lazy) и «жадную» (eager) загрузку. Так как эта система расширяема, нужно указать — какие поля нужно заполнять «жадно», а какие — «лениво».
Я предложил команде в организации, где я работаю, следующее «золотое правило», применяемое при работе с gqlgen: «Не включайте в модель поля, которые нужно загружать только в том случае, если они запрошены клиентом».
В нашем случае мне нужно загрузить данные о связанных видеоклипах (и даже сведения о пользователях) только в том случае, если клиент запросит эти поля. Но так как мы включили эти поля в модель, gqlgen предполагает, что мы предоставляем эти данные, получая сведения о видео. В результате сейчас мы и получаем пустые структуры.
Иногда случается так, что данные определённого типа нужны каждый раз, поэтому их нецелесообразно загружать с помощью отдельного запроса. Для этого, ради повышения производительности, можно воспользоваться чем-то вроде объединений SQL. Однажды (это, правда, не относится к рассматриваемому здесь примеру) мне нужно было, чтобы вместе с видео загружались бы и его метаданные. Хранились эти сущности в разных местах. В результате, если моя система получала запрос на загрузку видео, для получения метаданных приходилось делать ещё один запрос. Но, так как я знал об этом требовании (то есть, знал о том, что на стороне клиента всегда нужно и видео и его метаданные), я предпочёл воспользоваться методикой «жадной» загрузки для улучшения производительности.
Давайте перепишем модель и снова сгенерируем gqlgen-код. Для того чтобы не усложнять повествование — напишем лишь методы для поля user (файл models.go):
type Video struct {
ID int `json:"id"`
Name string `json:"name"`
Description string `json:"description"`
UserID int `json:"-"`
URL string `json:"url"`
CreatedAt time.Time `json:"createdAt"`
}
Мы добавили UserID и убрали структуру User. Теперь заново сгенерируем код:
go run scripts/gqlgen.go -v
Благодаря этой команде будут созданы следующие интерфейсные методы, позволяющие разрешить неопределённые структуры. Кроме того, нужно будет определить следующее в распознавателе (resolver) (файл generated.go):
type VideoResolver interface {
User(ctx context.Context, obj *api.Video) (api.User, error)
Screenshots(ctx context.Context, obj *api.Video) ([]*api.Screenshot, error)
Related(ctx context.Context, obj *api.Video, limit *int, offset *int) ([]api.Video, error)
}
Вот определение (файл resolver.go):
func (r *videoResolver) User(ctx context.Context, obj *api.Video) (api.User, error) {
rows, _ := dal.LogAndQuery(r.db,"SELECT id, name, email FROM users where id = $1", obj.UserID)
defer rows.Close()
if !rows.Next() {
return api.User{}, nil
}
var user api.User
if err := rows.Scan(&user.ID, &user.Name, &user.Email); err != nil {
errors.DebugPrintf(err)
return api.User{}, errors.InternalServerError
}
return user, nil
}
Теперь результаты испытания мутации будут выглядеть так, как показано ниже.
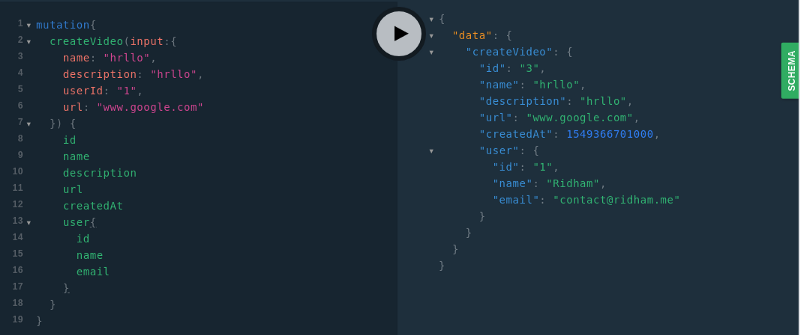
Мутация createVideo
То, что мы только что обсудили, представляет собой основы GraphQL, освоив которые, вы уже можете писать что-то своё. Правда, прежде чем вы окунётесь в эксперименты с GraphQL и Golang, полезно будет поговорить о подписках (subscription), которые имеют непосредственное отношение к тому, чем мы тут занимаемся.
▍Подписки
GraphQL предоставляет возможность оформления подписок на изменения данных, которые происходят в режиме реального времени. Библиотека gqlgen позволяет, в реальном времени, с использованием веб-сокетов, работать с событиями подписок.
Подписку нужно описать в файле schema.graphql. Вот как выглядит описание подписки на событие публикации видео:
type Subscription {
videoPublished: Video!
}
Теперь опять запустим автоматическое генерирование кода:
go run scripts/gqlgen.go -v
Как уже было сказано, в ходе автоматического создания кода в файле generated.go создаётся интерфейс, который нужно реализовать в распознавателе. В нашем случае это выглядит так (файл resolver.go):
var videoPublishedChannel map[string]chan api.Video
func init() {
videoPublishedChannel = map[string]chan api.Video{}
}
type subscriptionResolver struct{ *Resolver }
func (r *subscriptionResolver) VideoPublished(ctx context.Context) (<-chan api.Video, error) {
id := randx.String(8)
videoEvent := make(chan api.Video, 1)
go func() {
<-ctx.Done()
}()
videoPublishedChannel[id] = videoEvent
return videoEvent, nil
}
func (r *mutationResolver) CreateVideo(ctx context.Context, input NewVideo) (api.Video, error) {
// ваша логика ...
for _, observer := range videoPublishedChannel {
observer <- newVideo
}
return newVideo, nil
}
Теперь, при создании нового видео, нужно вызвать событие. В нашем примере это делается в строке for _, observer := range videoPublishedChannel.
Теперь пришло время проверить подписку.
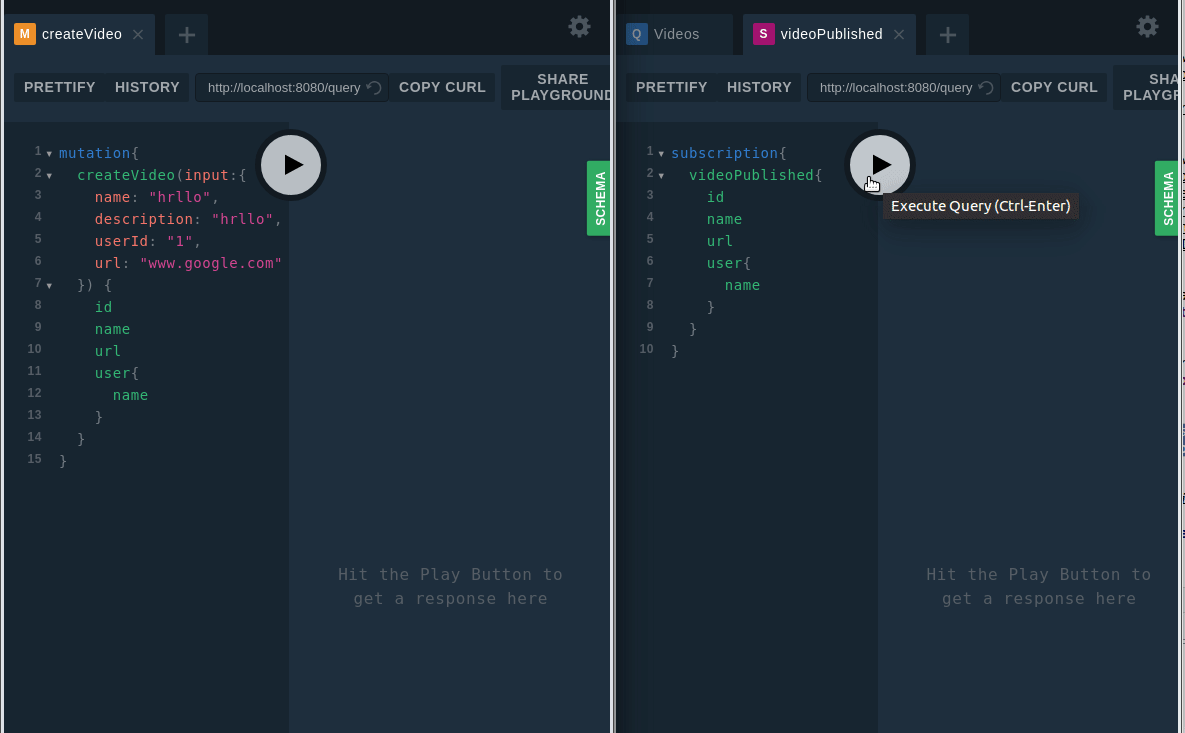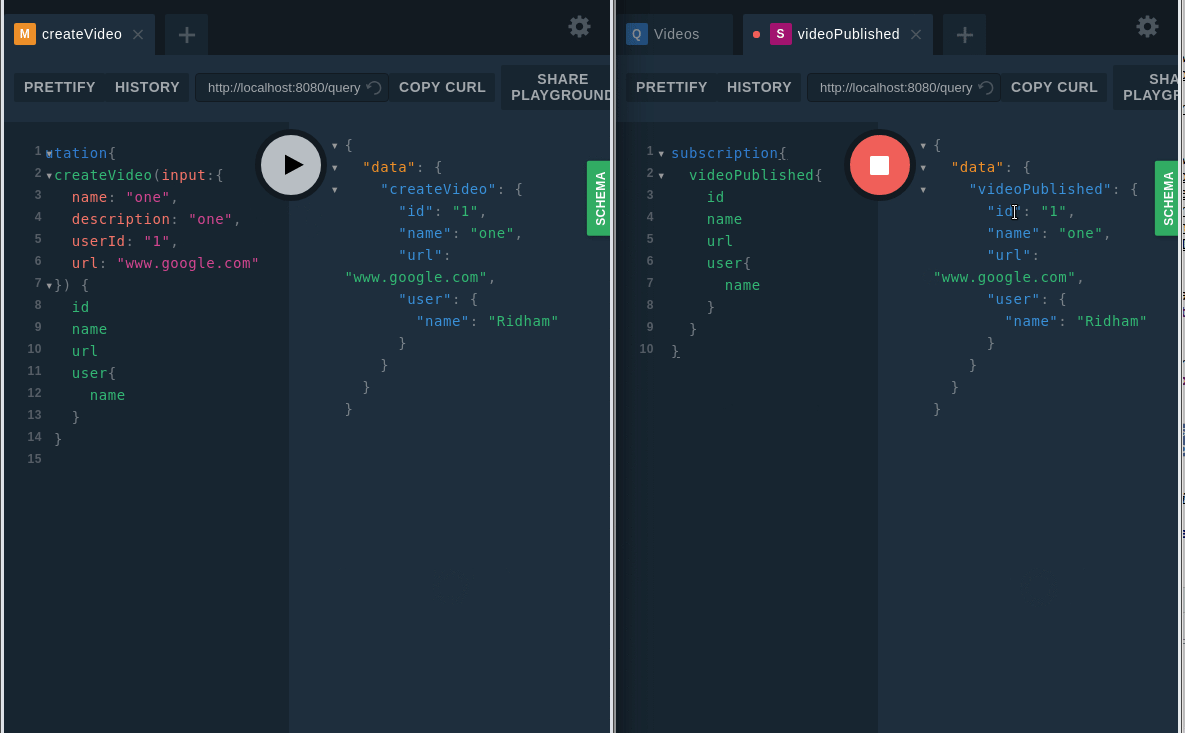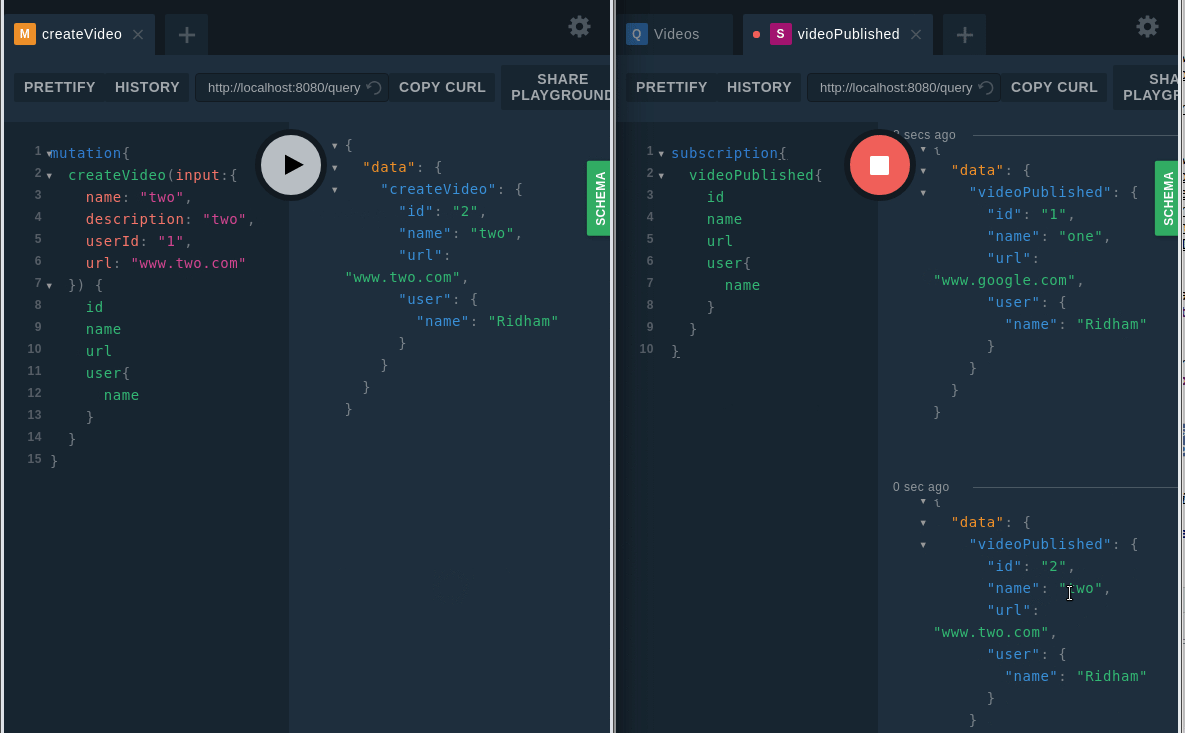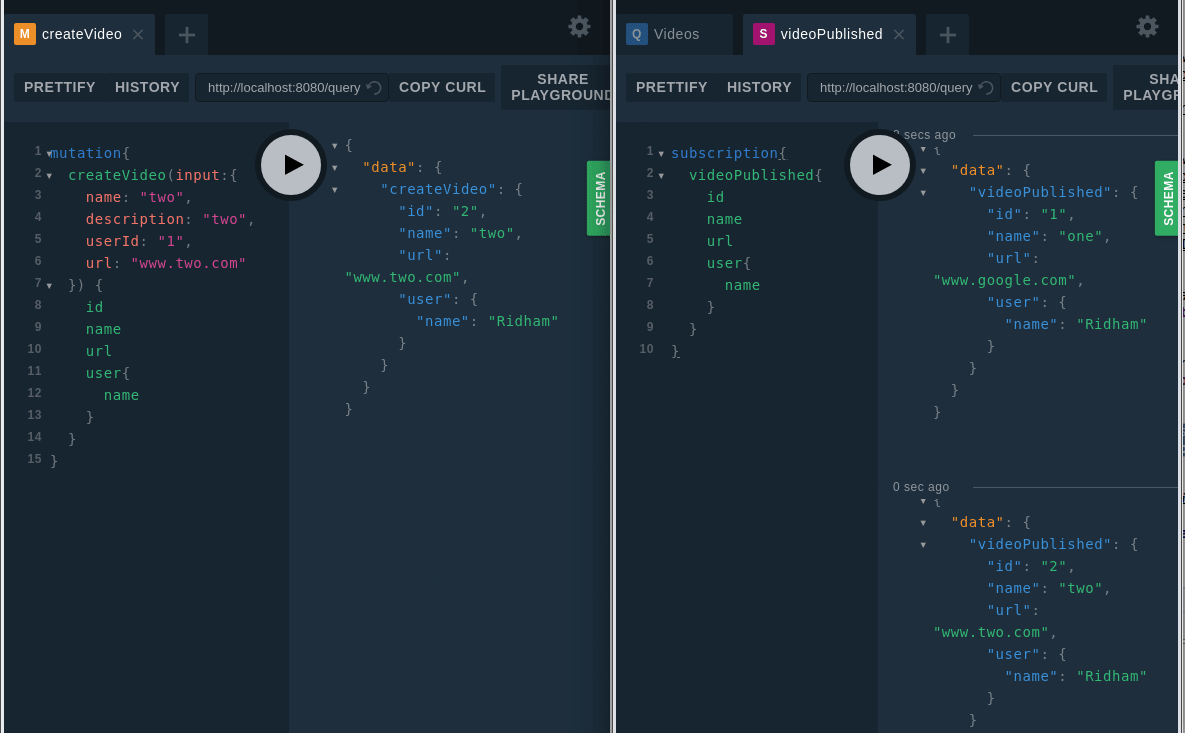
Проверка подписки
GraphQL, конечно, обладает определёнными ценными возможностями, но, как говорится, не всё то золото, что блестит. А именно, речь идёт о том, что тому, кто пользуется GraphQL, нужно позаботиться об авторизации, о сложности запросов, о кэшировании, о проблеме запросов N + 1, об ограничении скорости выполнения запросов и ещё о некоторых вещах. В противном случае система, разрабатываемая с использованием GraphQL, может столкнуться с серьёзным падением производительности.
Продвинутые приёмы работы: аутентификация, загрузчики данных, сложность запросов
Каждый раз, когда я читаю руководства, подобные этому, меня захватывает ощущение, будто я, освоив их, узнаю всё, что мне нужно знать о некоей технологии и получу способность решать задачи любой сложности.
Но вот когда я начинаю работать над собственными проектами, обычно я попадаю в непредвиденные ситуации, выглядящие как серверные ошибки или как запросы, которые выполняются целую вечность, или как ещё какие-нибудь тупиковые ситуации. В результате мне, чтобы сделать дело, приходится лучше вникать в то, что совсем недавно казалось совершенно понятным. В этом же руководстве, хочется надеяться, подобного удастся избежать. Именно поэтому в данном разделе мы рассмотрим некоторые продвинутые приёмы работы с GraphQL.
▍Аутентификация
При работе с REST API у нас есть система аутентификации и стандартные средства авторизации при работе с некоей конечной точкой. Но при использовании GraphQL используется лишь одна конечная точка, поэтому задачи аутентификации можно решить с помощью директив схемы. Отредактируем файл schema.graphql следующим образом:
type Mutation {
createVideo(input: NewVideo!): Video! @isAuthenticated
}
directive @isAuthenticated on FIELD_DEFINITION
Мы создали директиву isAuthenticated и применили её к подписке createVideo. После очередного сеанса автоматического создания кода нужно задать определение для этой директивы. Сейчас директивы реализуются в виде методов структур, а не в виде интерфейсов, поэтому нам нужно их описать. Я отредактировал автоматически сгенерированный код, находящийся в файле server.go и создал метод, возвращающий конфигурацию GraphQL для файла server.go. Вот файл resolver.go:
func NewRootResolvers(db *sql.DB) Config {
c := Config{
Resolvers: &Resolver{
db: db,
},
}
// Директива схемы
c.Directives.IsAuthenticated = func(ctx context.Context, obj interface{}, next graphql.Resolver) (res interface{}, err error) {
ctxUserID := ctx.Value(UserIDCtxKey)
if ctxUserID != nil {
return next(ctx)
} else {
return nil, errors.UnauthorisedError
}
}
return c
}
Вот файл server.go:
rootHandler:= dataloaders.DataloaderMiddleware(
db,
handler.GraphQL(
go_graphql_demo.NewExecutableSchema(go_graphql_demo.NewRootResolvers(db)
)
)
http.Handle("/query", auth.AuthMiddleware(rootHandler))
Мы прочли ID пользователя из контекста. Вам не кажется это странным? Как это значение попало в контекст и почему оно вообще оказалось в контексте? Дело в том, что gqlgen предоставляет контексты запроса только на уровне реализации, поэтому у нас нет возможности читать любые данные HTTP-запроса, вроде заголовков или куки, в распознавателях или директивах. В результате требуется добавлять в систему собственные промежуточные механизмы, получать эти данные и помещать их в контекст.
Теперь нам нужно описать собственный промежуточный механизм аутентификации для получения данных аутентификации из запроса и их проверки.
Тут не определяется никакая логика. Вместо этого, в качестве данных авторизации, в демонстрационных целях, тут просто передаётся ID пользователя. Затем этот механизм объединяется в server.go с новым методом загрузки конфигурации.
Теперь имеет смысл описание директивы. Мы не обрабатываем запросы неавторизованных пользователей в коде промежуточного слоя, так как такие запросы будут обрабатываться директивой. Вот как это выглядит.
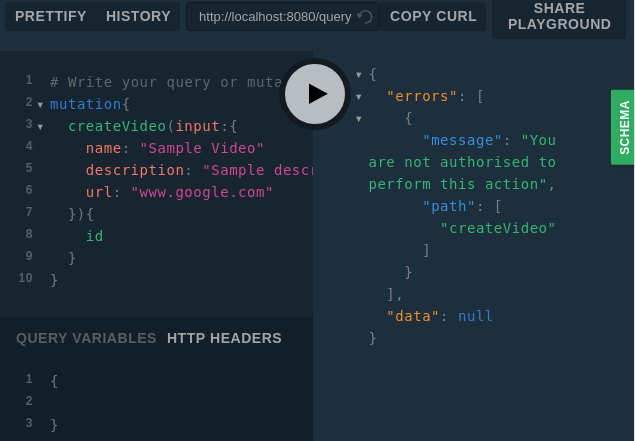
Работа с неавторизованным пользователем
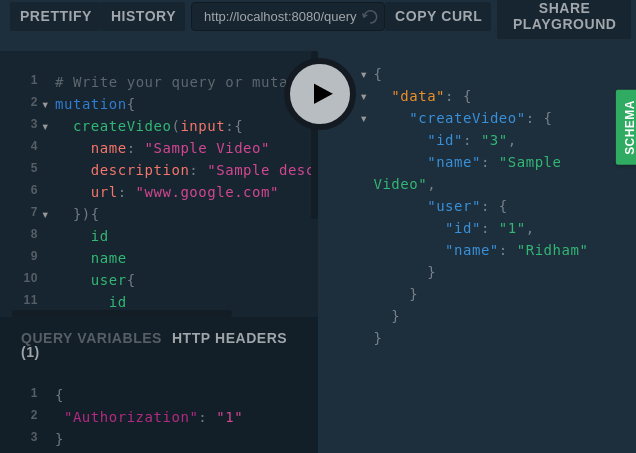
Работа с авторизованным пользователем
Работая с директивами схем можно даже передавать аргументы:
directive @hasRole(role: Role!) on FIELD_DEFINITION
enum Role { ADMIN USER }
▍Загрузчики данных
Мне кажется, что всё это выглядит довольно интересно. Вы загружаете данные тогда, когда они нужны. У клиентов есть возможность управлять данными, из хранилища берётся именно то, что нужно. Но всё имеет свою цену.
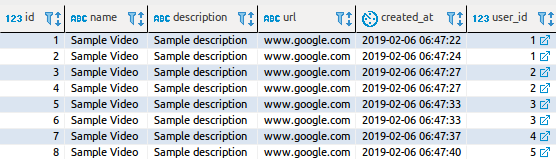
Чем приходится «платить» за эти возможности? Взглянем на логи загрузки всех видео. А именно, речь идёт о том, что у нас есть 8 видео и 5 пользователей.
query{
Videos(limit: 10){
name
user{
name
}
}
}
Сведения о загрузке видео
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Resolver: User : SELECT id, name, email FROM users where id = $1
Что здесь происходит? Почему тут 9 запросов (1 запрос связан с таблицей видео и 8 — с таблицей пользователей)? Выглядит это ужасно. У меня чуть сердце не остановилось, когда я подумал о том, что наше существующее API придётся заменить этим… Правда, полностью справиться с этой проблемой помогают загрузчики данных.
Это известно как проблема N + 1. Речь идёт о том, что имеется один запрос для получения всех данных и для каждого фрагмента данных (N) будет по ещё одному запросу к базе данных.
Это — очень серьёзная проблема, если говорить о производительности и о ресурсах: хотя эти запросы параллельны, они истощают ресурсы системы.
Для решения этой проблемы мы воспользуемся библиотекой dataloaden от автора библиотеки gqlgen. Эта библиотека позволяет генерировать Go-код. Сначала сгенерируем загрузчик данных для сущности User:
go get github.com/vektah/dataloaden
dataloaden github.com/ridhamtarpara/go-graphql-demo/api.User
В нашем распоряжении окажется файл userloader_gen.go, в котором имеются методы наподобие Fetch, LoadAll и Prime.
Теперь нам, для получения общих результатов, нужно определить метод Fetch (файл dataloader.go):
func DataloaderMiddleware(db *sql.DB, next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
userloader := UserLoader{
wait : 1 * time.Millisecond,
maxBatch: 100,
fetch: func(ids []int) ([]*api.User, []error) {
var sqlQuery string
if len(ids) == 1 {
sqlQuery = "SELECT id, name, email from users WHERE id = ?"
} else {
sqlQuery = "SELECT id, name, email from users WHERE id IN (?)"
}
sqlQuery, arguments, err := sqlx.In(sqlQuery, ids)
if err != nil {
log.Println(err)
}
sqlQuery = sqlx.Rebind(sqlx.DOLLAR, sqlQuery)
rows, err := dal.LogAndQuery(db, sqlQuery, arguments...)
defer rows.Close();
if err != nil {
log.Println(err)
}
userById := map[int]*api.User{}
for rows.Next() {
user:= api.User{}
if err := rows.Scan(&user.ID, &user.Name, &user.Email); err != nil {
errors.DebugPrintf(err)
return nil, []error{errors.InternalServerError}
}
userById[user.ID] = &user
}
users := make([]*api.User, len(ids))
for i, id := range ids {
users[i] = userById[id]
i++
}
return users, nil
},
}
ctx := context.WithValue(r.Context(), CtxKey, &userloader)
r = r.WithContext(ctx)
next.ServeHTTP(w, r)
})
}
Тут мы ожидаем в течение 1 мс. перед выполнением запроса и собираем запросы в пакеты размером до 100 запросов. Теперь, вместо выполнения запроса для каждого пользователя в отдельности, загрузчик будет ждать указанное время прежде чем обратиться к базе данных. Далее, нужно изменить логику распознавателя, перенастроив его с использования запроса на использование загрузчика данных (файл resolver.go):
func (r *videoResolver) User(ctx context.Context, obj *api.Video) (api.User, error) {
user, err := ctx.Value(dataloaders.CtxKey).(*dataloaders.UserLoader).Load(obj.UserID)
return *user, err
}
Вот как после этого выглядят логи в ситуации, похожей на вышеописанную:
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2
Dataloader: User : SELECT id, name, email from users WHERE id IN ($1, $2, $3, $4, $5)
Здесь выполняются лишь два запроса к базе данных, в результате все теперь счастливы. Интересно отметить, что в запрос передаются лишь 5 идентификаторов пользователей, хотя данные запрашиваются для 8 видео. Это говорит о том, что загрузчик данных убирает дублирующиеся записи.
▍Сложность запросов
GraphQL позволяет пользователям API запрашивать всё, что им может понадобиться. Но это означает то, что такое API подвержено риску DOS-атак.
Разберёмся с этим на примере, с которым мы уже работали.
В типе Video есть поле, содержащие связанные видео. Каждое такое видео представлено сущностью GraphQL типа Video. Поэтому у этих видео тоже есть списки связанных с ними видео. И так — до бесконечности.
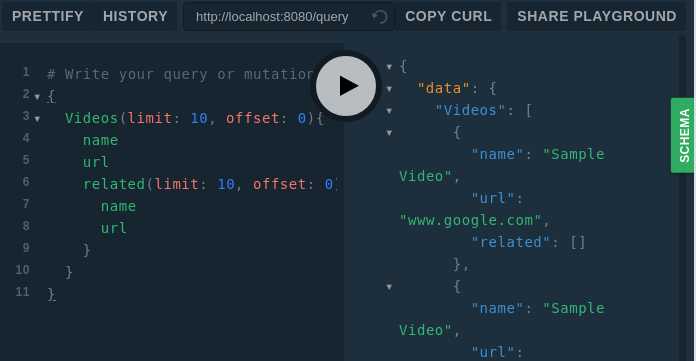
Для того, чтобы понять серьёзность этой проблемы — рассмотрим следующий запрос:
{
Videos(limit: 10, offset: 0){
name
url
related(limit: 10, offset: 0){
name
url
related(limit: 10, offset: 0){
name
url
related(limit: 100, offset: 0){
name
url
}
}
}
}
}
Если добавить сюда ещё один подобъект или увеличить лимит до 100, тогда в одном вызове будут загружаться миллионы видео. Возможно (или, скорее, несомненно) это приведёт к тому, что база данных и сервис перестанут реагировать на запросы.
Библиотека gqlgen даёт возможность задавать максимальную сложность запроса, допустимую при выполнении одного вызова. Для того чтобы это сделать, нужно добавить всего одну строчку кода (handler.ComplexityLimit(300) в следующем примере) в обработчик GraphQL и задать максимальную сложность (300 в данном случае). Вот код, о котором идёт речь (файл server.go):
rootHandler:= dataloaders.DataloaderMiddleware(
db,
handler.GraphQL(
go_graphql_demo.NewExecutableSchema(go_graphql_demo.NewRootResolvers(db)),
handler.ComplexityLimit(300)
),
)
Библиотека назначает фиксированный уровень сложности каждому полю, при этом структура, массив и строка рассматриваются как имеющие одинаковую сложность. В результате для этого запроса сложность будет 12. Но мы знаем, что вложенные поля сильно увеличивают сложность запросов, поэтому нам нужно, чтобы библиотека учитывала бы это (то есть, проще говоря, использовала бы, при вычислении сложности, операцию умножения, а не сложения). Вот код файла resolver.go:
func NewRootResolvers(db *sql.DB) Config {
c := Config{
Resolvers: &Resolver{
db: db,
},
}
// Сложность
countComplexity := func(childComplexity int, limit *int, offset *int) int {
return *limit * childComplexity
}
c.Complexity.Query.Videos = countComplexity
c.Complexity.Video.Related = countComplexity
// Директива схемы
c.Directives.IsAuthenticated = func(ctx context.Context, obj interface{}, next graphql.Resolver) (res interface{}, err error) {
ctxUserID := ctx.Value(UserIDCtxKey)
if ctxUserID != nil {
return next(ctx)
} else {
return nil, errors.UnauthorisedError
}
}
return c
}
Как и в случае директив, сложность определяется в виде структуры, поэтому нам нужно соответствующим образом поменять конфигурацию.

Попытка выполнения слишком сложного запроса
Сложность запроса не превышает максимально допустимую сложность
Я не включил в систему соответствующую логику, касающуюся связанных видео, поэтому массив related сейчас пуст. Но, полагаю, то, о чём мы только что говорили, позволило вам ощутить важность проблемы слишком сложных запросов и увидеть пути её решения.
Итоги
Проект, фрагменты кода которого мы рассматривали в этом материале, можно найти на GitHub. Там же есть и инструкции по развёртыванию этого проекта. Для того чтобы лучше разобраться с тем, о чём мы тут говорили, вы можете поэкспериментировать с ним самостоятельно.
Уважаемые читатели! Как вы работаете с GraphQL в проектах, основанных на Go?

