[Перевод] Глубокое обучение при помощи Spark и Hadoop: знакомство с Deeplearning4j
Здравствуйте, уважаемые читатели!
Мы вполне убедились в мегапопулярности глубокого обучения (Deep Learning) на языке Python в нашей целевой аудитории. Теперь предлагаем поговорить о высшей лиге глубокого обучения — то есть, о решении этих задач на языке Java при помощи библиотеки Deeplearning4j. Мы перевели для вас июньскую статью из блога компании Cloudera, где в интереснейших подробностях рассказано о специфике этой библиотеки и о глубоком обучении в Hadoop и Spark.
Приятного чтения.
В конце 2016 года Бен Лорика (Ben Lorica) из O«Reilly Media объявил, что «в 2017 году сообщество специалистов по data science и большим данным всерьез займется технологиями ИИ.» До 2017 года в университетах и НИИ практиковалось в основном глубокое обучение на GPU, но в настоящее время все шире, в разных компаниях и предметных областях распространяется распределенное глубокое обучение на CPU. Тогда как GPU обеспечивают при числовых вычислениях максимальную производительность, современные CPU также подтягиваются к ним по эффективности, как благодаря совершенствованию оборудования, так и по той причине, что теперь их можно задействовать «скопом». Появились такие свободные инструменты, наиболее интересным из которых является библиотека deeplearning4j — они обеспечивают быстрое глубокое обучение в крупномасштабных системах (стек Hadoop) и должны в целом серьезно повлиять на глубокое обучение в ближайшие годы.
В этой статье мы подробно рассмотрим работу со свободными инструментами — Apache Spark, Apache Hadoop, Deeplearning4j (DL4J) — работающими на недорогом (и широко доступном) аппаратном обеспечении. Постараемся максимально качественно решить задачу по распознаванию образов, располагая ограниченным набором обучающих данных. Библиотека DL4J API написана на Java и особенно интересна Java- и Scala-разработчикам, уже умеющим обращаться с виртуальной машиной Java. Кроме того, возможность распараллеливать обучение моделей в Spark (для этого требуется всего несколько строк кода) упрощает эффективное использование имеющихся кластерных ресурсов. Таким образом, процесс обучения удается ускорить, не жертвуя при этом точностью.
Deeplearning4j: инструментарий для глубокого обучения на JVM
Deeplearning4j — один из многочисленных свободных комплектов для крупномасштабного обучения глубоких нейронных сетей на CPU и GPU. Deeplearning4j создана для JVM и специально ориентирована на глубокое обучение для больших предприятий. Библиотека deeplearning4j создана в 2014 году, поддерживается стартапом Skymind и обладает встроенной интеграцией с Apache Spark. Хотя, deeplearning4j предназначена для работы с JVM, в ней используется высокопроизводительная нативная библиотека линейной алгебры Nd4j, которая позволяет выполнять сильно оптимизированные вычисления на CPU или GPU.
Классификация объектов из набора изображений Caltech-256
В этой статье рассказано, как пользоваться Apache Spark, Apache Hadoop и deeplearning4j для решения задачи классификации изображений. В частности, здесь пошагово описано, как построить сверточную нейронную сеть, способную классифицировать изображения из набора Caltech-256. Фактически, в этом наборе есть 257 категорий объектов, в каждой из которых содержится от 80 до 800 изображений; таким образом, всего в этом наборе имеем 30 607 изображений.
Следует отметить, что максимальная точность классификации этого набора данных в настоящее время колеблется в диапазоне 72 — 75%. Этот результат можно побить при помощи DL4J и Spark.
Эффективное глубокое обучение на небольших данных
У современных сверточных сетей может быть по несколько сотен миллионов параметров. Одна из самых мощных таких сетей называется Large Scale Visual Recognition Challenge (также известная под названием «ImageNet»), в ней нужно обучать 140 миллионов параметров! Такие сети не только потребляют массу вычислительных и дисковых ресурсов (даже при наличии кластера GPU на обучение могут уходить недели), но и требуют много данных. При наличии всего 30 000 изображений непрактично обучать столь сложную модель на Caltech-256, поскольку в этом наборе слишком мало примеров для адекватного обучения столь многим параметров. Лучше воспользоваться методом под названием «перенос обучения», при котором берется предварительно обученная модель, адаптируемая для других вариантов использования. Перенос обучения также позволяет значительно снизить вычислительную нагрузку и избавиться от многочисленных специализированных вычислительных ресурсов, например, GPU.
Такие модели можно переориентировать, поскольку сверточные нейронные сети, обучаемые на наборах изображений, обычно вычленяют самые общие признаки, и именно такое обучение по признакам может пригодиться и при обработке других наборов изображений. Например, сеть, обученная на ImageNet, скорее всего, будет распознавать фигуры, черты лица, узоры, текст и т.д., что, несомненно, пригодится при обработке набора данных Caltech-256.
Загрузка предварительно обученной модели
В следующем примере используется модель VGG16, занявшая второе место на конкурсе ImageNet в 2014 году. К счастью, сейчас эта модель выложена в общий доступ, все 140 миллионов весов уже оптимизированы для прогнозирования на материале набора ImageNet. Поскольку мы собираемся работать с иным набором изображений, потребуется модифицировать небольшие элементы модели, чтобы заточить ее под такое прогнозирование. Эта модель обладает примерно 140 миллионами параметров, занимает около 500 MB дискового пространства.
Для начала получим такую версию модели VGG16, которая понятна DL4J, и с которой эта библиотека может работать. Оказывается, что подобная возможность встроена прямо в API DL4J и реализуется всего в нескольких строках на Scala.
al modelImportHelper = new TrainedModelHelper(TrainedModels.VGG16)
val vgg16 = modelImportHelper.loadModel()
val savePath = "./dl4j-models/vgg16.zip"
val locationToSave = new File(savePath)
// сохраняем модель в нативном формате DL4J, что в дальнейшем позволит ускорить считывание
ModelSerializer.writeModel(vgg16, locationToSave, saveUpdater = true)
Теперь наша модель в таком формате, который удобно использовать в DL4J. Исследуем встроенную model summary.
val modelFile = new File("./dl4j-models/vgg16.zip")
val vgg16 = ModelSerializer.restoreComputationGraph(modelFile)
println(vgg16.summary())VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
input_2 (InputVertex) -,- - - -
block1_conv1 (ConvolutionLayer) 3,64 1792 b:{1,64}, W:{64,3,3,3} [input_2]
block1_conv2 (ConvolutionLayer) 64,64 36928 b:{1,64}, W:{64,64,3,3} [block1_conv1]
block1_pool (SubsamplingLayer) -,- 0 - [block1_conv2]
block2_conv1 (ConvolutionLayer) 64,128 73856 b:{1,128}, W:{128,64,3,3} [block1_pool]
block2_conv2 (ConvolutionLayer) 128,128 147584 b:{1,128}, W:{128,128,3,3} [block2_conv1]
block2_pool (SubsamplingLayer) -,- 0 - [block2_conv2]
block3_conv1 (ConvolutionLayer) 128,256 295168 b:{1,256}, W:{256,128,3,3} [block2_pool]
block3_conv2 (ConvolutionLayer) 256,256 590080 b:{1,256}, W:{256,256,3,3} [block3_conv1]
block3_conv3 (ConvolutionLayer) 256,256 590080 b:{1,256}, W:{256,256,3,3} [block3_conv2]
block3_pool (SubsamplingLayer) -,- 0 - [block3_conv3]
block4_conv1 (ConvolutionLayer) 256,512 1180160 b:{1,512}, W:{512,256,3,3} [block3_pool]
block4_conv2 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_conv1]
block4_conv3 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_conv2]
block4_pool (SubsamplingLayer) -,- 0 - [block4_conv3]
block5_conv1 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_pool]
block5_conv2 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block5_conv1]
block5_conv3 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block5_conv2]
block5_pool (SubsamplingLayer) -,- 0 - [block5_conv3]
flatten (PreprocessorVertex) -,- - - [block5_pool]
fc1 (DenseLayer) 25088,4096 102764544 b:{1,4096}, W:{25088,4096} [flatten]
fc2 (DenseLayer) 4096,4096 16781312 b:{1,4096}, W:{4096,4096} [fc1]
predictions (DenseLayer) 4096,1000 4097000 b:{1,1000}, W:{4096,1000} [fc2]
Total Parameters: 138357544
Trainable Parameters: 138357544
Frozen Parameters: 0
Вот красивая и лаконичная общая характеристика модели; впрочем, весьма полезно показать ее и в виде картинки.
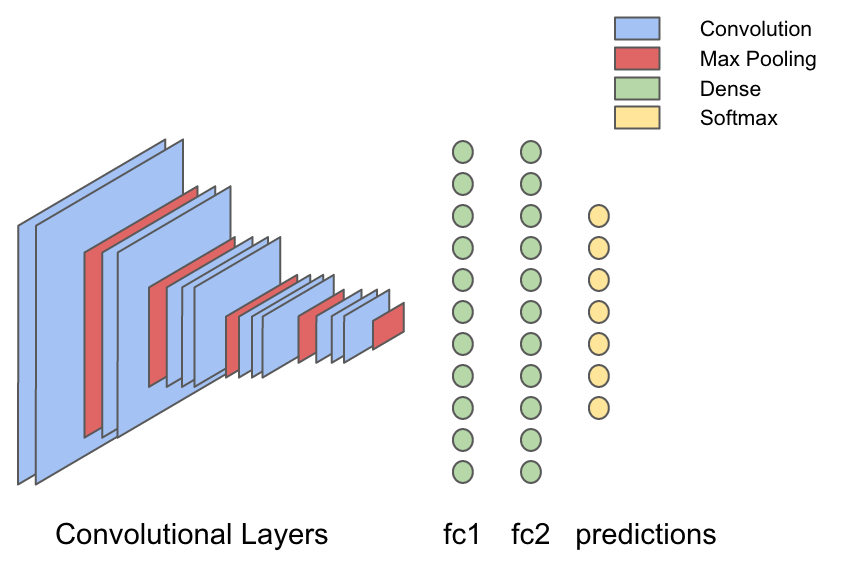
В VGG16 13 сверточных слоев, перемежающихся со слоями, в которых выбирается максимальное значение (max-pooling); это делается для сжатия изображения. Весовые значения в сверточном слое — это, по сути, фильтры, которые обучаются вычленять визуальные признаки из изображения, а слои с выбором максимального значения «сжимают» изображение — и поэтому фильтры в следующих сверточных слоях полнее «увидят» изображение. Поэтому результат работы сверточных слоев — это самые общие визуальные признаки входного изображения, например, «на картинке лицо?» или «на картинке закат?». Результат работы сверточных слоев подается в ряд из трех полносвязных (плотных) слоев, способных выучить нелинейные взаимосвязи между этими визуальными характеристиками и выходной информацией.
Это — одно из основных свойств сверточных сетей, обеспечивающее перенос обучения. Речь о том, что можно пропускать новую информацию об изображениях через уже обученную сеть VGG16 и вычленять признаки из каждого изображения. Такая операция называется «характеризация» (featurizing): после извлечения признаков остается работать лишь с последними частями сети VGG16, а эта задача гораздо подъемнее как с вычислительной точки зрения, так и по уровню сложности.
Характеризация изображений при помощи VGG16
Набор данных можно скачать с сайта Caltech-256, где он разделен на фрагменты для обучения/проверки/тестирования и сохранен в HDFS (подробные инструкции). Когда это будет сделано, берем весь набор изображений и пропускаем его через все сверточные слои, а также через первый плотный слой, а вывод сохраняем в HDFS.
По некоторым причинам желательно делать именно так и, чтобы понять важность такого подхода, отметим одно общее правило, касающееся сверточных сетей: большая часть компьютерного времени и вычислительной мощности тратится в сверточных слоях, а большинство параметров (весов) в сети VGG16 локализуется в плотных слоях. Благодаря переносу обучения можно воспользоваться предварительно обученными сверточными слоями для извлечения признаков входных изображений, поэтому переобучать приходится лишь небольшую часть исходной модели — плотные слои. Оставшаяся часть остается статической или «замороженной». Можно сэкономит массу времени и вычислительных мощностей, всего один раз передав необработанные изображения через замороженную часть сети, а затем вообще не возвращаться к этой части.
Для начала извлечем ту часть сети, которая будет использоваться на этапе характеризации. В библиотеке deeplearning4j есть встроенный API для переноса обучения, который можно задействовать именно для этой цели. Чтобы разделить модель после первого полносвязного слоя «fc1» сначала получим список слоев до и после разделения.
val modelFile = new File("./dl4j-models/vgg16.zip")
val vgg16 = ModelSerializer.restoreComputationGraph(modelFile)
val (frozenLayers: Array[Layer], unfrozenLayers: Array[Layer]) = {
vgg16.getLayers.splitAt(vgg16.getLayers.map(_.conf().getLayer.getLayerName).indexOf("fc2") + 1)
}
Теперь берем пакет org.deeplearning4j.nn.transferlearning, чтобы извлечь только слои до «fc2» включительно.
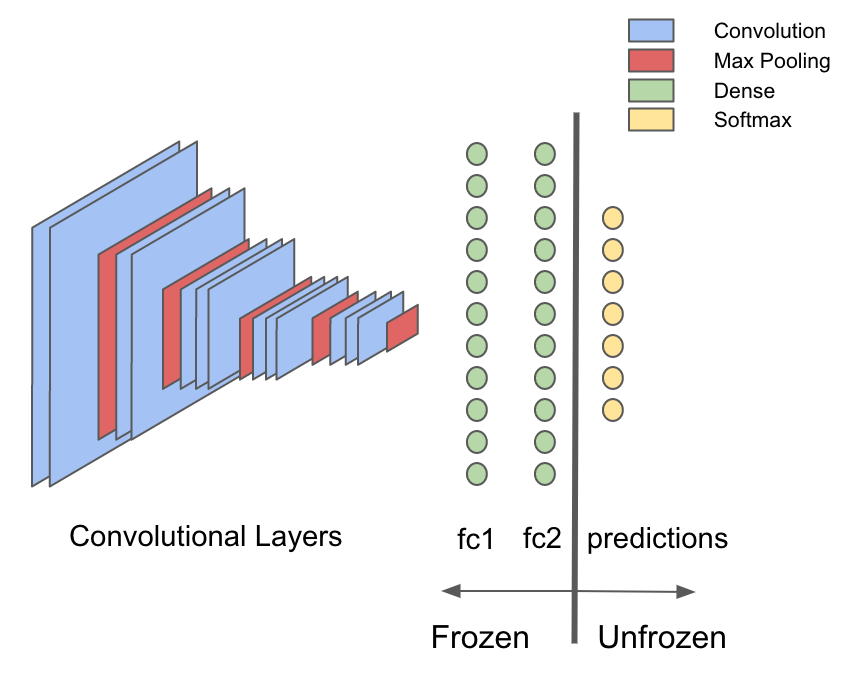
val builder = new TransferLearning.GraphBuilder(model)
.setFeatureExtractor(frozenLayers.last.conf().getLayer.getLayerName)
// удаляем все незамороженные слои, оставляем только ту часть модели, которая не будет обучаться
unfrozenLayers.foreach { layer =>
builder.removeVertexAndConnections(layer.conf().getLayer.getLayerName)
}
builder.setOutputs(frozenLayers.last.conf().getLayer.getLayerName)
val frozenGraph = builder.build()
Далее необходимо перейти собственно к считыванию файлов изображений, которые сохраняются в HDFS в формате JPEG, каждый по отдельности. Изображения разложены по подкаталогам, и каждый подкаталог содержит набор картинок, относящихся к определенному классу. Начнем загружать сохраненные в HDFS изображения при помощи sc.binaryFiles и применяем инструменты для обработки изображений, входящие в библиотеку DataVec (нативная ETL-библиотека для DL4J) и с их помощью преобразуем изображения в массивы INDArray, представляющие собой нативные тензорные представления, потребляемые DL4J (полный код здесь). Наконец, используем замороженный граф для выдачи прогнозов по входным изображениям: в сущности, пропускаем их через дорогие слои, которые будут отбрасываться.
val finalOutput = Utils.getPredictions(data, frozenGraph, sc)
val df = finalOutput.map { ds =>
(Nd4j.toByteArray(ds.getFeatureMatrix), Nd4j.toByteArray(ds.getLabels))
}.toDF()
df.write.parquet("hdfs:///user/leon/featurizedPredictions/train")
Теперь новый набор данных сохраняется в HDFS, и с его помощью можно приступать к построению моделей с переносом обучения. Такие данные с признаками позволяют радикально сократить длительность обучения и снизить сложность вычислений. В вышеприведенном примере новые данные состоят из 30607 вектором длиной 4096.
Замена слоя прогнозирования VGG16
Модель VGG16 обучалась на наборе данных ImageNet, представляющем собой множество классифицированных объектов, разделенных на 1000 различных категорий. Последний слой в типичной нейронной сети для классификации изображений, так называемый «слой вывода» на основе ввода генерирует вероятности для каждого объекта, содержащегося в наборе данных. Следовательно, такой ввод можно считать обобщенной картиной визуальных признаков изображения, содержащей полезную информацию о том, что представляет собой объект, и что в нем содержится. Интуитивно понятно, что тот самый «обобщенный» ввод, поступающий в последний слой, должен пригодиться и для генерации иного набора вероятностей, оптимизированный для распознавания объектов в наборе данных Caltech-256.
После характеризации данных по вышеописанному принципу определяем новую модель, занимающую 4096-мерный вывод в слое «fc2» и генерирующую 257 вероятностей для набора данных Caltech256.
val conf = new NeuralNetConfiguration.Builder()
.seed(42)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1)
.activation(Activation.SOFTMAX)
.weightInit(WeightInit.XAVIER)
.learningRate(0.01)
.updater(Updater.NESTEROVS)
.momentum(0.8)
.graphBuilder()
.addInputs("in")
.addLayer("layer0",
new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(4096)
.nOut(257)
.build(),
"in")
.setOutputs("layer0")
.backprop(true)
.build()
val model = new ComputationGraph(conf)
Вот как это выглядит.
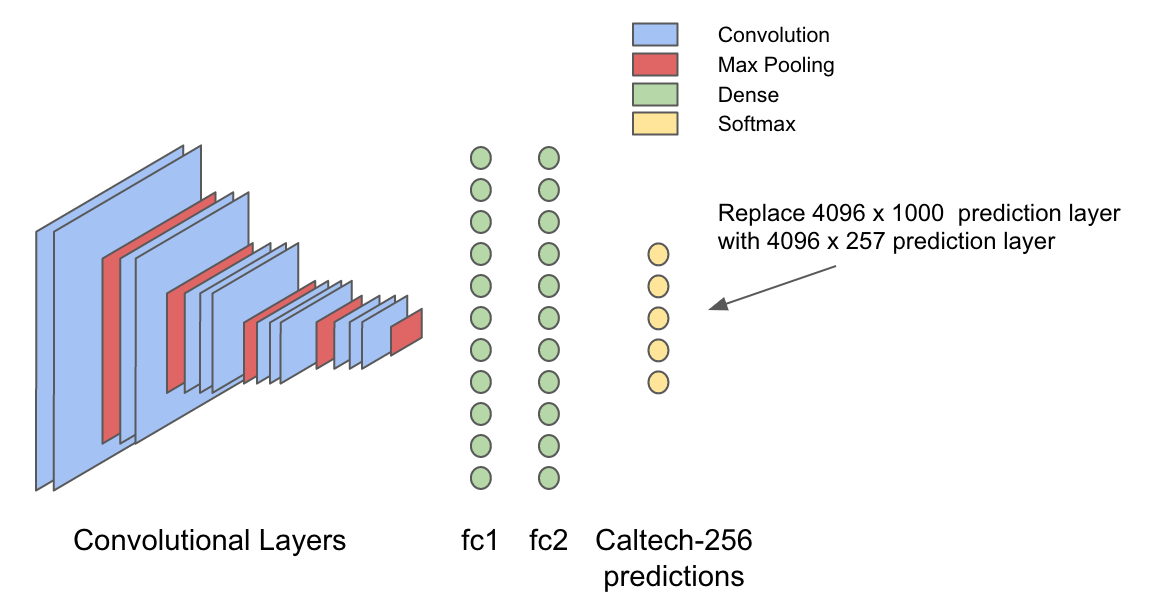
Итак, теперь эту модель можно обучать при помощи тяжелых вычислений DL4J и масштабировать при помощи Spark. Для обучения в Spark используем интерфейс ParameterAveragingTrainingMaster в DL4J — лаконичный API для распределенного обучения моделей в Spark. Название для этого интерфейса подобрано удачно, поскольку распределенное обучение в нем достигается при помощи алгоритма SGD на каждом из рабочих ядер в кластере Spark и усреднения различных моделей, изученных на каждом ядре, при помощи операций RDD-агрегации.
val tm = new ParameterAveragingTrainingMaster.Builder(1)
.averagingFrequency(5)
.workerPrefetchNumBatches(2)
.batchSizePerWorker(32)
.rddTrainingApproach(RDDTrainingApproach.Export)
.build()
val model = new SparkComputationGraph(sc, graph, tm)
Теперь обучаем SparkComputationGraph для заданного количества эпох и отслеживаем статистику обучения, чтобы видеть, как идет прогресс.
model.setListeners(new ScoreIterationListener(1))
(1 to param.numEpochs).foreach { i =>
logger4j.info(s"epoch $i starting")
model.fit(trainRDD)
// выводим точность модели и «счет» на каждом учебном и проверочном наборе каждые 5 итераций
if (i % 5 == 0) {
logger4j.info(s"Train score: ${model.calculateScore(trainRDD, true)}")
logger4j.info(s"Train stats:\n${Utils.evaluate(model.getNetwork, trainRDD, 16)}")
if (validRDD.isDefined) {
logger4j.info(s"Validation stats:\n${Utils.evaluate(model.getNetwork, validRDD.get, 16)}")
logger4j.info(s"Validation score: ${model.calculateScore(validRDD.get, true)}")
}
}
}
Наконец, запускаем учебное задание при помощи spark submit и через графический веб-интерфейс DL4J отслеживаем прогресс и диагностируем проблемы. Ниже видим «счет» модели — этот показатель в данном случае означает отрицательный логарифм правдоподобия миниблока, чем меньше — тем лучше. На графике он изображается в соотношении с «сырыми» значениями (числами) и сглаженной линией тренда. Учтите, что при обучении с помощью Spark «счет» каждого миниблока фактически соответствует всего одному ядру в кластере Spark, а у нас могут быть тысячи таких ядер. В идеале счет на одном ядре должен соответствовать счету на других, но если данные не рандомизированы правильно, то эти показатели в кластере могут резко отличаться от ядра к ядру.
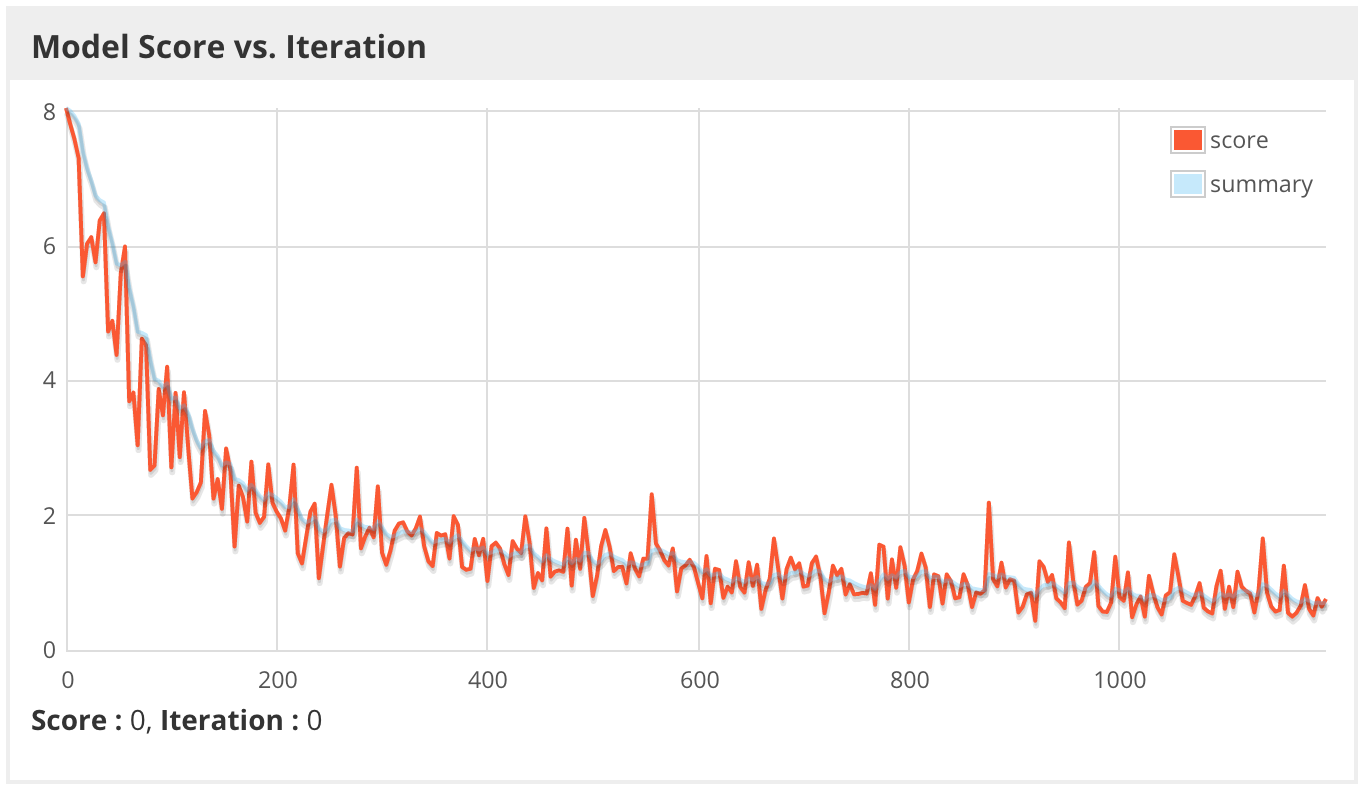
По-видимому, на этот раз модель обучается гораздо быстрее даже при пониженном коэффициенте скорости обучения, так как используемые на этот раз признаки обладают гораздо более высокой прогностической ценностью, чем вероятности ImageNet.
17/05/12 16:06:12 INFO caltech256.TrainFeaturized$: Train score: 0.6663876733861492
17/05/12 16:06:39 INFO caltech256.TrainFeaturized$: Train stats:
Accuracy: 0.8877570632327504
Precision: 0.8937314411403346
Recall: 0.876864905154427
17/05/12 16:07:17 INFO caltech256.TrainFeaturized$: Validation stats:
Accuracy: 0.7625918867410836
Precision: 0.7703367671469078
Recall: 0.7383574179140013
17/05/12 16:07:26 INFO caltech256.TrainFeaturized$: Validation score: 1.08481537405921
Похоже, в данном случае модель переобучена, так как точность обучения составляет 88.8%, а точность проверки — всего 76.3%. Чтобы убедиться, что модель не переобучается и на проверочном наборе, оценим ее на слепом тестовом наборе.
Accuracy: 0.7530218882718066
Precision: 0.7613121478786196
Recall: 0.7286152891276695
Хотя точность немного снизилась, она все равно превосходит ультрасовременные результаты для этого набора данных, а ведь мы воспользовались простой архитектурой для глубокого обучения, построенной на основе готовой архитектуры Hadoop и дешевых CPU! Да, не титаническое достижение, однако, этот результат все равно помогает распробовать, чего можно достичь при помощи глубокого обучения на Java.
Выводы
Хотя, библиотека deeplearning4j — просто один из многих инструментов для глубокого обучения, она оснащена нативной интеграцией с Apache Spark и написана на Java, поэтому особенно удачно вписывается в экосистему Hadoop. Поскольку доступ к информации на предприятиях повсеместно обеспечивается через Hadoop, а ее обработка происходит в Spark, библиотека deeplearning4j позволяет ускорить развертывание и сократить издержки, и можно сразу извлекать такую информацию, полученную методом глубокого обучения. Библиотека использует для сложных вычислений ND4J — другую хорошо оптимизированную библиотеку, отлично взаимодействующую с дешевыми CPU, но также поддерживающую работу с GPU, когда требуется резко нарастить производительность. Deeplearning4j — это полнофункциональная библиотека для глубокого обучения, в ней имеется полный набор инструментов, обеспечивающих обработку данных от потребления до развертывания. При помощи этой библиотеки можно решать всевозможные задачи: распознавание изображений и видео, обработка аудио, обработка естественного языка, создание рекомендательных систем и т.д.
