[Перевод] FaceNet: Универсальный эмбеддинг для распознавания и кластеризации лиц
В процессе решения задач по студенческому проекту Распли мне понадобилось перевести несколько статей по распознаванию лиц. Некоторые из них я решил выложить сюда: возможно, их перевод поможет в решении ваших задач.
Оригинальная статья была выпущена в 2015 году под названием FaceNet: A Unified Embedding for Face Recognition and Clustering и под авторством Флориана Шроффа, Дмитрия Калениченко и Джеймса Филбина.
Аннотация
Несмотря на значительные достижения в области распознавания лиц [10, 14, 15, 17], эффективная реализация проверки и распознавания лиц в масштабе представляет серьезные трудности для существующих подходов. В данной работе мы представляем систему под названием FaceNet, которая непосредственно обучается отображению изображений лиц в компактное евклидово пространство, где расстояния напрямую соответствуют мере сходства лиц. После создания такого пространства такие задачи, как распознавание, верификация и кластеризация лиц, могут быть легко реализованы с помощью стандартных методов с использованием эмбеддингов FaceNet в качестве векторов признаков.
Наш метод использует глубокую сверточную сеть, обученную непосредственно оптимизировать сам эмбеддинг, а не промежуточный слой с узким местом (прим. перевод. в ориг. bottleneck), как в предыдущих подходах глубокого обучения. Для обучения мы используем триплеты грубо выровненных совпадающих и несовпадающих лиц (прим. перевод. в ориг. face patches), сгенерированных с помощью нового онлайн-метода майнинга триплетов. Преимуществом нашего подхода является гораздо более высокая эффективность репрезентации: мы достигаем современной производительности распознавания лиц, используя всего 128 байт на лицо.
На широко используемом наборе данных Labeled Faces in the Wild (LFW) наша система достигла новой рекордной точности — 99,63%. На базе данных YouTube Faces DB она достигает 95,12%. Наша система снижает уровень ошибок по сравнению с лучшим опубликованным результатом [15] на 30% на обоих наборах данных.
Мы также вводим понятия гармонических эмбеддингов и гармонической триплетной потери, которые описывают различные версии эмбеддингов лиц (произведенных разными сетями), которые совместимы друг с другом и допускают прямое сравнение между собой.
1. Введение
В данной работе мы представляем единую систему для проверки лица (одно ли это лицо), распознавания (кто это) и кластеризации (поиск общих людей среди этих лиц). Наш метод основан на обучении евклидового эмбеддинга для каждого изображения с помощью глубокой сверточной сети. Сеть обучается таким образом, что квадратичные расстояния  в пространстве эмбеддинга непосредственно соответствуют сходству лиц: лица одного и того же человека имеют небольшие расстояния, а лица разных людей — большие.
в пространстве эмбеддинга непосредственно соответствуют сходству лиц: лица одного и того же человека имеют небольшие расстояния, а лица разных людей — большие.
После создания такого эмбеддинга вышеупомянутые задачи становятся простыми: проверка лица включает в себя просто пороговое расстояние между двумя эмбеддингами; распознавание становится проблемой классификации k-NN;, а кластеризация может быть достигнута с помощью готовых методов, таких как k-means или агломеративная кластеризация.
Предыдущие подходы к распознаванию лиц на основе глубоких сетей используют слой классификации [15, 17], обученный на наборе известных лиц, а затем берут промежуточный слой узкого места в качестве репрезентации, используемой для обобщенного распознавания за пределами набора лиц, использованных при обучении. Недостатками этого подхода являются его косвенность и неэффективность: необходимо надеяться, что репрезентация узкого места хорошо обобщается на новые лица, а при использовании слоя узкого места размер репрезентации для каждого лица обычно очень велик (1000 измерений). В некоторых недавних работах [15] эта размерность была уменьшена с помощью PCA, но это линейное преобразование, которое может быть легко изучено на одном уровне сети.
В отличие от этих подходов, FaceNet непосредственно обучает свой выход компактному 128-D эмбеддингу, используя функцию потерь на основе триплетов, основанную на LMNN [19]. Наши триплеты состоят из двух совпадающих миниатюр лица и несовпадающей миниатюры лица, а потеря направлена на отделение позитивной пары от негативной на определенное расстояние. Миниатюры представляют собой плотные снимки области лица, никакого 2D или 3D выравнивания, кроме масштабирования и перевода, не выполняется.
Отбор используемых триплетов оказывается очень важным для достижения высокой производительности, и, вдохновленные обучением по учебным программам [1], мы представляем новую онлайн стратегию майнинга негативных примеров, которая обеспечивает постоянное увеличение сложности триплетов по мере обучения сети. Для повышения точности кластеризации мы также исследуем жесткие позитивные методы майнинга, которые способствуют формированию сферических кластеров для эмбеддингов одного человека.
В качестве иллюстрации невероятной вариативности, с которой может справиться наш метод, см. рисунок 1. Показаны пары изображений из PIE [13], которые ранее считались очень сложными для систем верификации лиц.

Рис. 1. Освещенность и инвариантность позы. Поза и освещение являются давней проблемой в распознавании лиц. На этом рисунке показаны выходные расстояния FaceNet между парами лиц одного и другого человека в различных комбинациях позы и освещенности. Расстояние 0,0 означает, что лица идентичны, 4,0 соответствует противоположному спектру, двум разным лицам. Видно, что при пороге 1,1 каждая пара классифицируется правильно.
Обзор остальной части статьи выглядит следующим образом: в разделе 2 мы рассматриваем литературу в этой области; в разделе 3.1 дается определение триплетной потери, а в разделе 3.2 описывается наша новая процедура отбора и обучения триплетов; в разделе 3.3 мы описываем архитектуру используемой модели. Наконец, в разделах 4 и 5 мы представляем некоторые количественные результаты наших эмбеддингов, а также качественно исследуем некоторые результаты кластеризации.
2. Связанные работы
Подобно другим недавним работам, в которых используются глубокие сети [15, 17], наш подход — это метод, основанный исключительно на данных, который обучает свою репрезентацию непосредственно из пикселей лица. Вместо того чтобы использовать разработанные признаки, мы используем большой набор данных помеченных лиц для достижения соответствующих инвариантов к позе, освещению и другим вариативным условиям.
В этой статье мы исследуем две различные архитектуры глубоких сетей, которые в последнее время с большим успехом используются в сообществе компьютерного зрения. Обе они представляют собой глубокие сверточные сети [8, 11]. Первая архитектура основана на модели Zeiler&Fergus [22], которая состоит из нескольких чередующихся слоев сверток, нелинейных активаций, локальных нормализаций отклика и слоев максимального объединения. Мы дополнительно добавляем несколько слоев свертки  , вдохновленные работой [9]. Вторая архитектура основана на модели Inception Сегеди и др., которая недавно была использована в качестве победителя ImageNet 2014 [16]. В этих сетях используются смешанные слои, которые параллельно запускают несколько различных сверточных слоев и слоев объединения и объединяют их ответы. Мы обнаружили, что эти модели позволяют сократить количество параметров в 20 раз и потенциально могут уменьшить количество FLOPS, необходимых для достижения сопоставимой производительности.
, вдохновленные работой [9]. Вторая архитектура основана на модели Inception Сегеди и др., которая недавно была использована в качестве победителя ImageNet 2014 [16]. В этих сетях используются смешанные слои, которые параллельно запускают несколько различных сверточных слоев и слоев объединения и объединяют их ответы. Мы обнаружили, что эти модели позволяют сократить количество параметров в 20 раз и потенциально могут уменьшить количество FLOPS, необходимых для достижения сопоставимой производительности.
Существует огромное количество работ по верификации и распознаванию лиц. Их обзор выходит за рамки данной статьи, поэтому мы лишь кратко обсудим наиболее актуальные последние работы.
В работах [15, 17, 23] используется сложная система из нескольких этапов, которая объединяет выход глубокой сверточной сети с PCA для уменьшения размерности и SVM для классификации.
Чжэньяо и др. [23] используют глубокую сеть для «деформации» лиц в канонический фронтальный вид, а затем обучают CNN, которая классифицирует каждое лицо как принадлежащее известной личности. Для проверки лица используется PCA на выходе сети в сочетании с ансамблем SVM.
Тайгман и др. [17] предлагают многоступенчатый подход, при котором лица соответствуют общей трехмерной модели фигуры. Обученная многоклассовая сеть выполняет задачу распознавания лиц на более чем четырех тысячах идентичностей. Авторы также экспериментировали с так называемой сиамской сетью, в которой они напрямую оптимизируют  -расстояние между двумя признаками лица. Наилучшие результаты по LFW (97,35%) показал ансамбль из трех сетей, использующих различные выравнивания и цветовые каналы. Прогнозируемые расстояния (нелинейные прогнозы SVM на основе ядра
-расстояние между двумя признаками лица. Наилучшие результаты по LFW (97,35%) показал ансамбль из трех сетей, использующих различные выравнивания и цветовые каналы. Прогнозируемые расстояния (нелинейные прогнозы SVM на основе ядра  ) этих сетей объединяются с помощью нелинейной SVM.
) этих сетей объединяются с помощью нелинейной SVM.
Сан и др. [14, 15] предлагают компактную и поэтому относительно дешевую для вычисления сеть. Они используют ансамбль из 25 таких сетей, каждая из которых работает на разных участках лица. Для получения окончательного результата по LFW (99,47% [15]) авторы объединяют 50 ответов (обычный и перевернутый). Используются как PCA, так и совместная байесовская модель [2], которая эффективно соответствует линейному преобразованию в пространстве эмбеддинга. Их метод не требует явного выравнивания 2D/3D. Сети обучаются с помощью комбинации классификационных и проверочных потерь. Потери при проверке похожи на используемые нами триплетные потери [12, 19], поскольку они минимизируют  -расстояние между лицами с одинаковой идентичностью и обеспечивают разницу расстояния (прим. перевод. в ориг. margin) между расстояниями лиц с разной идентичностью. Основное отличие заключается в том, что сравниваются только пары изображений, в то время как триплетная потеря поощряет ограничение относительного расстояния.
-расстояние между лицами с одинаковой идентичностью и обеспечивают разницу расстояния (прим. перевод. в ориг. margin) между расстояниями лиц с разной идентичностью. Основное отличие заключается в том, что сравниваются только пары изображений, в то время как триплетная потеря поощряет ограничение относительного расстояния.
В работе Ванга и др. [18] для ранжирования изображений по семантическому и визуальному сходству была использована потеря, аналогичная той, что используется здесь.
3. Метод
FaceNet использует глубокую сверточную сеть. Мы обсуждаем две различные архитектуры ядра: сети в стиле Zeiler&Fergus [22] и недавно появившиеся сети типа Inception [16]. Детали этих сетей описаны в разделе 3.3.
Учитывая детали модели и рассматривая ее как черный ящик (см. рис. 2), наиболее важная часть нашего подхода заключается в сквозном обучении всей системы. Для этого мы используем триплетную потерю, которая непосредственно отражает то, чего мы хотим достичь в верификации, распознавании и кластеризации лиц. А именно, мы стремимся к эмбеддингу  из изображения
из изображения  в пространство признаков
в пространство признаков  таким образом, чтобы квадратичное расстояние между всеми лицами, независимо от условий визуализации, одной и той же личности было небольшим, в то время как квадратичное расстояние между парой изображений лиц разных личностей было большим.
таким образом, чтобы квадратичное расстояние между всеми лицами, независимо от условий визуализации, одной и той же личности было небольшим, в то время как квадратичное расстояние между парой изображений лиц разных личностей было большим.

 нормализация, а затем эмбеддинг лица. После этого в процессе обучения вычисляется триплетная потеря.
нормализация, а затем эмбеддинг лица. После этого в процессе обучения вычисляется триплетная потеря.Хотя мы не проводили прямого сравнения с другими потерями, например, с потерями, использующими пары позитивов и негативов, как в [14], уравнение (2), мы считаем, что триплетная потеря больше подходит для верификации лиц. Мотивация заключается в том, что потеря из [14] поощряет проецирование всех лиц одной личности на одну точку в пространстве эмбеддинга. Триплетная потеря, однако, пытается обеспечить разницу между каждой парой лиц одного человека и всеми остальными лицами. Это позволяет лицам одной личности жить на многообразии, сохраняя при этом расстояние и, следовательно, различимость с другими личностями.
В следующем разделе описывается эта триплетная потеря и то, как она может быть эффективно изучена в масштабе.
3.1. Триплетная потеря
Эмбеддинг представлен  . Она встраивает изображение
. Она встраивает изображение  в
в  -мерное евклидово пространство. Кроме того, мы ограничиваем этот эмбеддинг тем, что он живет на
-мерное евклидово пространство. Кроме того, мы ограничиваем этот эмбеддинг тем, что он живет на  -мерной гиперсфере, т.е.
-мерной гиперсфере, т.е.  . Эта потеря мотивирована в [19] в контексте классификации ближайших соседей. Здесь мы хотим убедиться, что изображение
. Эта потеря мотивирована в [19] в контексте классификации ближайших соседей. Здесь мы хотим убедиться, что изображение  (якорь) конкретного человека находится ближе ко всем другим изображениям
(якорь) конкретного человека находится ближе ко всем другим изображениям  (позитив) того же человека, чем к любому изображению
(позитив) того же человека, чем к любому изображению  (негатив) любого другого человека. Это наглядно показано на рисунке 3.
(негатив) любого другого человека. Это наглядно показано на рисунке 3.

Рис. 3. Триплетная потеря минимизирует расстояние между якорем и позитивом, оба из которых имеют одинаковую идентичность, и максимизирует расстояние между якорем и негативом с другой идентичностью.
Таким образом, мы хотим,


где  — это разница расстояния, которая вводится между позитивными и негативными парами.
— это разница расстояния, которая вводится между позитивными и негативными парами.  — это множество всех возможных триплетов в обучающем множестве, имеющее кардинальность
— это множество всех возможных триплетов в обучающем множестве, имеющее кардинальность  .
.
Тогда минимизируемая потеря равна 
![\sum^{N}_{i}{\left[ ||f(x^a_i) -f(x^p_i)||^2_2 - ||f(x^a_i) - f(x^n_i)||^2_2 + \alpha \right]}_+. \ \ \ (3)](https://habrastorage.org/getpro/habr/upload_files/a7e/73f/c1f/a7e73fc1f91d9566e65e56eef38c28d5.svg)
Генерация всех возможных триплетов приведет к появлению множества триплетов, которые легко удовлетворить (т.е. выполнить ограничение в уравнении (1)). Эти триплеты не будут способствовать обучению и приведут к замедлению сходимости, поскольку они все равно будут пропущены через сеть. Очень важно выбрать жесткие триплеты, которые активны и могут способствовать улучшению модели. В следующем разделе рассказывается о различных подходах, которые мы используем для отбора триплетов.
3.2. Отбор триплетов
Для обеспечения быстрой сходимости очень важно отбирать триплеты, которые нарушают ограничение на триплет в уравнении (1). Это означает, что, учитывая  , мы хотим выбрать
, мы хотим выбрать  (жестко позитивную) такую, что
(жестко позитивную) такую, что  , и аналогично
, и аналогично  (жестко негативную) такую, что
(жестко негативную) такую, что  .
.
Невозможно вычислить  и
и  на всем обучающем множестве. Кроме того, это может привести к плохому обучению, так как неправильно обозначенные и плохо изображенные лица будут преобладать среди жестких позитивных и негативных значений. Есть два очевидных варианта, которые позволяют избежать этой проблемы:
на всем обучающем множестве. Кроме того, это может привести к плохому обучению, так как неправильно обозначенные и плохо изображенные лица будут преобладать среди жестких позитивных и негативных значений. Есть два очевидных варианта, которые позволяют избежать этой проблемы:
Генерировать триплеты в автономном режиме каждые
 шагов, используя последнюю контрольную точку сети и вычисляя
шагов, используя последнюю контрольную точку сети и вычисляя  и
и  на подмножестве данных.
на подмножестве данных.Генерировать тройки в режиме онлайн. Это может быть сделано путем отбора жестких позитивных/негативных примеров из мини-пакета.
Здесь мы фокусируемся на онлайн генерации и используем большие мини-пакеты порядка нескольких тысяч примеров и вычисляем только  и
и  в пределах мини-пакета.
в пределах мини-пакета.
Чтобы получить значимую репрезентацию о расстояниях между якорями, необходимо убедиться, что в каждом мини-пакете присутствует минимальное количество образцов любой идентичности. В наших экспериментах мы отбираем обучающие данные таким образом, чтобы в каждом мини-пакете было около 40 лиц. Кроме того, в каждый мини-пакет добавляются случайным образом отобранные негативные лица.
Вместо того, чтобы выбирать самую жесткую позитивную пару, мы используем все пары якорь-позитивных пар в мини-пакете, при этом выбирая жесткие негативные пары. У нас нет бокового сравнения пар с жесткими позитивными якорями и пар со всеми позитивными якорями в мини-пакете, но на практике мы обнаружили, что метод со всеми позитивными якорями был более стабильным и сходился немного быстрее в начале обучения.
Мы также исследовали возможность автономной генерации триплетов в сочетании с онлайн-генерацией, что может позволить использовать меньшие размеры пакетов, но эксперименты не дали результатов.
Отбор самых сильных негативов на практике может привести к плохим локальным минимумам на ранних этапах обучения, в частности, это может привести к разрушению модели (т.е.  ). Чтобы смягчить это, лучше выбрать
). Чтобы смягчить это, лучше выбрать  таким образом, чтобы
таким образом, чтобы

Мы называем эти неагтивные примеры полужесткими, поскольку они находятся дальше от якоря, чем позитивный пример, но все еще жесткими, поскольку квадрат расстояния близок к расстоянию между якорем и позитивным примером. Эти негативные примеры лежат внутри поля  .
.
Как уже упоминалось, правильный отбор триплетов имеет решающее значение для быстрой сходимости. С одной стороны, мы хотели бы использовать небольшие мини-пакеты, так как они улучшают сходимость при стохастическом градиентном спуске (SGD) [20]. С другой стороны, детали реализации делают более эффективными пакеты из десятков и сотен образцов. Основным ограничением в отношении размера пакета, однако, является способ отбора жестких релевантных триплетов из мини-пакета. В большинстве экспериментов мы используем размер пакета около 1 800 примеров.
3.3. Глубокие сверточные сети
Во всех наших экспериментах мы обучаем CNN, используя стохастический градиентный спуск (SGD) со стандартным обратным распространением [8, 11] и AdaGrad [5]. В большинстве экспериментов мы начинаем с коэффициента обучения 0,05, который мы снижаем для окончательной доводки модели. Модели инициализируются случайным образом, аналогично [16], и обучаются на кластере CPU в течение 1 000—2 000 часов. Снижение потерь (и увеличение точности) резко замедляется после 500 часов обучения, но дополнительное обучение все еще может значительно улучшить производительность. Разница расстояния  установлена на 0,2.
установлена на 0,2.
Мы использовали два типа архитектур и более подробно изучили их компромиссы в экспериментальном разделе. Их практические различия заключаются в разнице параметров и FLOPS. Лучшая модель может быть разной в зависимости от приложения. Например, модель, работающая в центре обработки данных, может иметь много параметров и требовать большого количества FLOPS, в то время как модель, работающая на мобильном телефоне, должна иметь мало параметров, чтобы она могла поместиться в памяти. Во всех наших моделях в качестве нелинейной функции активации используются выпрямленные линейные единицы.
Первая категория, показанная в таблице 1, добавляет  сверточных слоев, как предложено в [9], между стандартными сверточными слоями архитектуры Zeiler&Fergus [22], и в результате получается модель глубиной 22 слоя. Она имеет в общей сложности 140 миллионов параметров и требует около 1,6 миллиарда FLOPS на изображение.
сверточных слоев, как предложено в [9], между стандартными сверточными слоями архитектуры Zeiler&Fergus [22], и в результате получается модель глубиной 22 слоя. Она имеет в общей сложности 140 миллионов параметров и требует около 1,6 миллиарда FLOPS на изображение.
![Таблица 1. NN1. Эта таблица показывает структуру нашей модели, основанной на Zeiler&Fergus [22], с сверток, вдохновленной [9]. Размеры входа и выхода описаны в . Ядро задано в виде , а размер объединения maxout [6] — в виде .](https://habrastorage.org/r/w1560/getpro/habr/upload_files/f20/fa9/d80/f20fa9d80d8a96d9d7a9d23d332a72a9.png)
 сверток, вдохновленной [9]. Размеры входа и выхода описаны в
сверток, вдохновленной [9]. Размеры входа и выхода описаны в  . Ядро задано в виде
. Ядро задано в виде  , а размер объединения maxout [6] — в виде
, а размер объединения maxout [6] — в виде  .
.Вторая категория, которую мы используем, основана на моделях Inception в стиле GoogLeNet [16]. Эти модели имеют на 20× меньше параметров (около 6,6M-7,5M) и до 5× меньше FLOPS (между 500M-1,6B). Некоторые из этих моделей значительно уменьшены в размерах (как по глубине, так и по количеству фильтров), так что их можно запускать на мобильном телефоне. Одна из них, NNS1, имеет 26M параметров и требует всего 220M FLOPS на изображение. Другой, NNS2, имеет 4,3M параметров и 20M FLOPS. В таблице 2 подробно описана наша самая большая сеть NN2. NN3 идентична по архитектуре, но имеет меньший размер входных данных — 160×160. NN4 имеет размер входа всего 96×96, что значительно снижает требования к процессору (285M FLOPS против 1.6B для NN2). В дополнение к уменьшенному размеру входных данных он не использует свертки 5×5 в высших слоях, поскольку рецептивное поле к этому времени уже слишком мало. В целом мы обнаружили, что свертки 5×5 можно удалить из всех слоев с незначительным снижением точности. На рисунке 4 сравниваются все наши модели.
![Таблица 2. NN2. Детали воплощения NN2 Inception. Эта модель практически идентична модели, описанной в [16]. Два основных отличия заключаются в использовании pooling вместо max pooling (m), где это указано. Т.е. вместо пространственного max вычисляется норма . Пулинг всегда выполняется по (за исключением финального среднего пулинга) и параллельно со сверточными модулями внутри каждого модуля Inception. Если после объединения происходит уменьшение размерности, оно обозначается p. , и объединение затем объединяются для получения конечного результата.](https://habrastorage.org/r/w1560/getpro/habr/upload_files/778/f17/32b/778f1732be01d801057e7b2e07ac7de1.png)
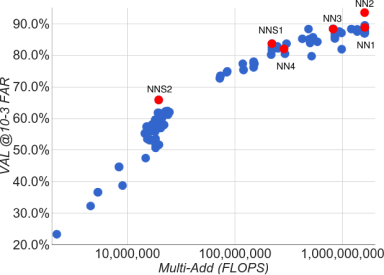
Рис. 4. Компромисс между FLOPS и точностью. Показан компромисс между FLOPS и точностью для широкого диапазона различных размеров моделей и архитектур. Выделены четыре модели, на которых мы сосредоточились в наших экспериментах.
 FAR может быть объяснено шумом в истинных метках. Модели в порядке убывания производительности следующие: NN2: модель на основе Inception с входом 224×224; NN1: сеть на основе Zeiler&Fergus с <этой формулой> сверток; NNS1: маленькая модель в стиле Inception с 220M FLOPS; NNS2: маленькая модель Inception с 20M FLOPS.
FAR может быть объяснено шумом в истинных метках. Модели в порядке убывания производительности следующие: NN2: модель на основе Inception с входом 224×224; NN1: сеть на основе Zeiler&Fergus с <этой формулой> сверток; NNS1: маленькая модель в стиле Inception с 220M FLOPS; NNS2: маленькая модель Inception с 20M FLOPS.
4. Наборы данных и оценка
Мы оцениваем наш метод на четырех наборах данных, и за исключением Labeled Faces in the Wild и YouTube Faces, мы оцениваем наш метод на задаче верификации лиц. Т.е. при наличии пары двух изображений лиц для определения классификации одинаковых и разных лиц используется пороговое квадратичное расстояние  . Все пары лиц
. Все пары лиц  с одинаковой идентичностью обозначаются
с одинаковой идентичностью обозначаются  , в то время как все пары с разной идентичностью обозначаются
, в то время как все пары с разной идентичностью обозначаются  .
.
Мы определяем множество всех истинных позитивных результатов (прим. перевод. в ориг. true accepts) как

Это пары лиц  , которые были правильно классифицированы как одинаковые при пороге
, которые были правильно классифицированы как одинаковые при пороге  . Аналогично
. Аналогично

это множество всех пар, которые были ошибочно классифицированы как одинаковые (ложные позитивные результаты).
Коэффициент подтверждения  и коэффициент ложного позитивного результата
и коэффициент ложного позитивного результата  для данного расстояния до лица
для данного расстояния до лица  определяются как
определяются как

4.1. Удерживающий тестовый набор
(прим. перевод. в ориг. Hold-out Test Set)
Мы сохраняем набор из примерно миллиона изображений, который имеет то же распределение, что и наше обучающее множество, но с разными идентичностями. Для оценки мы разделили его на пять несовпадающих наборов по 200 тыс. изображений в каждом. Затем вычисляются показатели FAR и VAL для пар изображений 100k × 100k. Стандартная ошибка представлена для всех пяти разбиений.
4.2. Личные фотографии
Это тестовый набор с распределением, аналогичным нашему обучающему набору, но с очень чистыми метками, проверенными вручную. Он состоит из трех личных коллекций фотографий с общим количеством около 12 тысяч изображений. Мы рассчитали показатели FAR и VAL для всех 12 тыс. пар изображений в квадрате.
4.3. Академические наборы данных
Labeled Faces in the Wild (LFW) является де-факто академическим тестовым набором для проверки лиц [7]. Мы следуем стандартному протоколу для неограниченных, помеченных внешних данных и сообщаем среднюю точность классификации, а также стандартную ошибку среднего значения.
Youtube Faces DB [21] — это новый набор данных, который приобрел популярность в сообществе распознавания лиц [17, 15]. Установка аналогична LFW, но вместо проверки пар изображений используются пары видео.
5. Эксперименты
Если не указано иное, мы используем от 100M-200M учебных миниатюр лиц, состоящих примерно из 8M различных личностей. На каждом изображении запускается детектор лиц, и вокруг каждого лица создается плотная ограничительная рамка. Эти миниатюры лиц изменяются до размера входных данных соответствующей сети. В наших экспериментах размер входных данных варьировался от 96×96 пикселей до 224×224 пикселей.
5.1. Компромисс между точностью вычислений
Прежде чем погрузиться в детали более конкретных экспериментов, мы обсудим компромисс между точностью и количеством FLOPS, которое требуется для конкретной модели. На рисунке 4 показано количество FLOPS по оси  и точность при 0,001 коэффициенте ложного позитивного результата (FAR) на нашем тестовом наборе данных, помеченном пользователями, из раздела 4.2. Интересно видеть сильную корреляцию между вычислениями, которые требует модель, и точностью, которую она достигает. На рисунке выделены пять моделей (NN1, NN2, NN3, NNS1, NNS2), которые мы более подробно рассматриваем в наших экспериментах.
и точность при 0,001 коэффициенте ложного позитивного результата (FAR) на нашем тестовом наборе данных, помеченном пользователями, из раздела 4.2. Интересно видеть сильную корреляцию между вычислениями, которые требует модель, и точностью, которую она достигает. На рисунке выделены пять моделей (NN1, NN2, NN3, NNS1, NNS2), которые мы более подробно рассматриваем в наших экспериментах.
Мы также рассмотрели компромисс между точностью и количеством параметров модели. Однако в этом случае картина не столь однозначна. Например, модель NN2 на основе Inception достигает сравнимой производительности с NN1, но имеет только 20-ю часть параметров. При этом количество FLOPS сопоставимо. Очевидно, что в какой-то момент производительность должна снизиться, если количество параметров будет уменьшаться и дальше. Другие архитектуры моделей могут позволить дальнейшее сокращение без потери точности, как это было сделано в Inception [16].

 коэффициента ложного позитивного презультата. Также показана стандартная ошибка среднего значения для пяти тестовых наборов.
коэффициента ложного позитивного презультата. Также показана стандартная ошибка среднего значения для пяти тестовых наборов.5.2. Влияние модели CNN
Теперь мы обсудим производительность четырех выбранных нами моделей более подробно. С одной стороны, мы имеем нашу традиционную архитектуру на основе Zeiler&Fergus с  свертками [22, 9] (см. табл. 1). С другой стороны, у нас есть модели на основе Inception [16], которые значительно уменьшают размер модели. В целом, в итоговой производительности лучшие модели обеих архитектур показывают сопоставимые результаты. Однако некоторые из наших моделей, основанных на Inception, такие как NN3, все же достигают хорошей производительности при значительном уменьшении количества FLOPS и размера модели.
свертками [22, 9] (см. табл. 1). С другой стороны, у нас есть модели на основе Inception [16], которые значительно уменьшают размер модели. В целом, в итоговой производительности лучшие модели обеих архитектур показывают сопоставимые результаты. Однако некоторые из наших моделей, основанных на Inception, такие как NN3, все же достигают хорошей производительности при значительном уменьшении количества FLOPS и размера модели.
Детальная оценка на нашем тестовом наборе личных фотографий показана на рисунке 5. Хотя самая большая модель достигает значительного улучшения точности по сравнению с крошечной NNS2, последняя может работать 30 мс / изображение на мобильном телефоне и все еще достаточно точна для использования в кластеризации лиц. Резкое падение ROC для  указывает на шумные метки в тестовых данных. При крайне низких показателях ложных позитивных результатов одно неправильно помеченное изображение может оказать значительное влияние на кривую.
указывает на шумные метки в тестовых данных. При крайне низких показателях ложных позитивных результатов одно неправильно помеченное изображение может оказать значительное влияние на кривую.
5.3. Чувствительность к качеству изображения
Таблица 4 показывает устойчивость нашей модели в широком диапазоне размеров изображений. Сеть удивительно устойчива к сжатию JPEG и работает очень хорошо вплоть до качества JPEG 20. Падение производительности очень незначительно для миниатюр лиц размером 120×120 пикселей, и даже при размере 80×80 пикселей она показывает приемлемую производительность. Это примечательно, потому что сеть обучалась на входных изображениях 220×220. Обучение на лицах с меньшим разрешением могло бы еще больше улучшить этот диапазон.

 при различном качестве JPEG. Справа показано, как размер изображения в пикселях влияет на уровень валидации при точности
при различном качестве JPEG. Справа показано, как размер изображения в пикселях влияет на уровень валидации при точности  . Этот эксперимент был проведен с NN1 на первой части нашего тестового набора данных.
. Этот эксперимент был проведен с NN1 на первой части нашего тестового набора данных.5.4. Размерность эмбеддинга
Мы исследова
