[Перевод] Эмуляция видеоигр нейросетью
Я создал играбельный верхний мир Pokémon. Он очень похож на обычную видеоигру, можете попробовать сыграть в него в браузере здесь:

Хотя он похож на видеоигру, я не писал код игры. На самом деле это нейросеть, подражающая видеоигре.
Программа? Игра? Нейросеть?
Программы: последовательности команд, преобразующих ввод в вывод
Человек может выполнить эти команды, чтобы преобразовать ввод в вывод:
Команды
- Берём два введённых числа
- Суммируем числа
- Делим пополам, чтобы получить вывод
Например, (190, 10)→100 или (2, 4)→3
Показанные выше команды — это программа, написанная на естественном языке для людей. В ней не указаны промежуточные этапы (как сложить два числа? что вообще такое число?), но это нормально, потому что у людей есть знания, позволяющие им заполнить пробелы в информации.
Программы обычно пишутся на языка программирования, для компьютеров
Компьютер может выполнить эти команды, чтобы преобразовать ввод в вывод:
print((
int(input("1st number: ")) + int(input("2nd number: "))
) / 2)
Это тоже программа (такая же, как и первая), но теперь записанная на языке программирования. Компьютеры могут напрямую преобразовывать языки программирования в компьютерные языки.
То есть если мы напишем программу на языке программирования, то человеку не придётся её выполнять. Мы можем приказать сделать это компьютеру.
Проблема «буквального исполнения желаний джинном»
Недостаток написания программы для компьютера (а не человека) заключается в ом, что компьютеры практически не имеют фоновых знаний. Компьютер всегда послушно и безынициативно выполняет написанные нами команды.
Это часто приводит к ситуациям «буквального исполнения желаний джинном», когда компьютер делает то, что мы написали, а не чего мы хотели.

Видеоигра — это разновидность программы
Видеоигра — это некая программа, получающая в качестве ввода сигналы от элементов управления (например, [«вверх», «вниз»]), и создающая в качестве вывода видеокадры. Pokémon является хорошим примером этого.
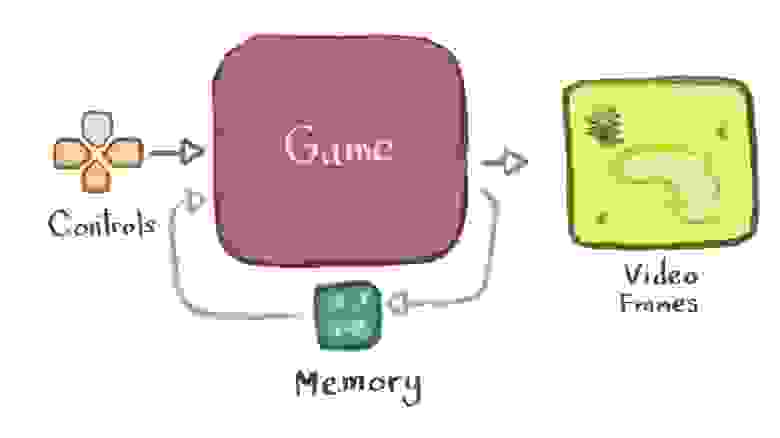
Нейронная сеть — это тоже разновидность программы
Нейросети напоминают покемона Дитто среди программ. Мы можем написать («обучить») нейросеть имитировать любую другую программу, которая существует или предположительно может существовать.

В принципе, мы можем обучить нейросеть имитировать видеоигру, а затем использовать обученную сеть вместо «реальной» игры, и никто не заметит разницы.

Однако «принципы» часто сбивают с толку — как на практике получить сеть, работающую в качестве игры? Что конкретно нужно сделать? Что, если это не сработает?
Как вообще написать нейросеть?
Нейросети пишутся массивами данных
Большинство программ (и большинство видеоигр) пишется как код на традиционных языках программирования. Однако нейросети «пишутся» массивами данных. Команды «ввод→вывод» для нейросети в буквальном смысле написаны как большой список желательных пар «ввод→вывод».
То есть чтобы имитировать игру Pokémon при помощи нейросети, мне сначала нужен массив пар »(сигналы управления, память)→(видеокадр)», который демонстрирует все игроподобные поведения, которые должна демонстрировать моя сеть.
Собираем массив данных
Я скачал, обрезал и отмасштабировал несколько видео с прохождением Pokémon, чтобы получить набор референсных выводов (видеокадров).
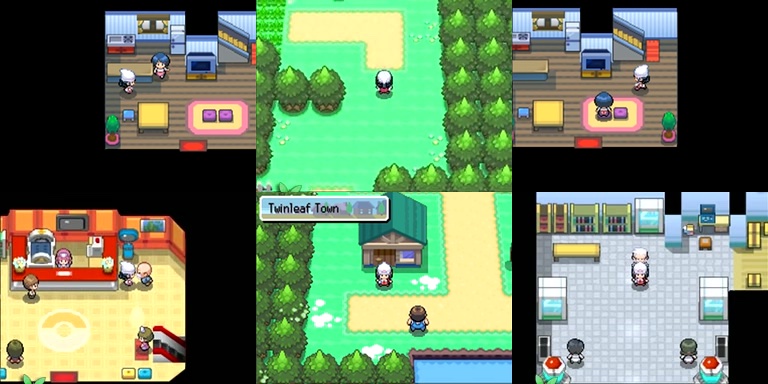
В этих видео отсутствовала соответствующая информация о вводе (управлении). Я просто разметил её на основании собственных догадок.
Чтобы избежать необходимости разметки ввода или вывода «памяти», я планировал просто передавать в качестве данных предыдущий кадр.

Такая система, в которой «всё, что за пределами экрана, забывается», будет… мягко говоря, поверхностной. Однако мне показалось, что если сеть сможет имитировать этот массив данных, этого будет достаточно для демо.

Пишем код обучения
Пишем необученную нейросеть
Чтобы получить нейросеть, имитирующую наш массив данных, нужно начать с нейросети, которая этого не делает.
Внутри этой нейросети будет множество магических чисел «изучаемых параметров», каждый из которых будет управлять поведением одного нейрона сети. При другом выборе значений параметров сеть будет вести себя иначе. Изначально параметры задаются случайным образом и сеть не делает ничего полезного.
Я написал сеть примерно с 300 тысячами параметров — очень мало по стандартам нейросетей.

Пишем код оценивания
Далее нам потребуется способ оценки того, насколько хорошо наша нейронная сеть имитирует массив данных. Мы напишем код «оценивания», он будет брать случайные пары (ввод→вывод), пропускать эти вводные данные через сеть и оценивать, насколько точно выводы сети соответствуют истинным референсным выводам из массива данных.
По стандарту наша оценка замеряет величину погрешности между прогнозом нейросети и референсным выводом из массива данных. Чем меньше погрешность, тем лучше, а ноль — это наилучшая оценка.
В моём случае сеть со случайно инициализированными параметрами создавала одинаковый серый кадр для любого ввода и имела плохие оценки. Мне нужны были более качественные параметры.

Пишем цикл обучения
Чтобы параметры были хорошими, мы создадим цикл обучения — фрагмент кода, который будет многократно прогонять код вычисления оценки и вносить небольшие изменения в параметры сети, чтобы улучшать её оценку. (Этот код проверяет для каждого параметра, улучшится ли оценка при незначительном уменьшении или увеличении этого параметра. Потом код немного сдвигает все параметры в их направлении улучшения оценки, и надеется на лучшее.)
Также цикл обучения периодически показывает нам визуализации.

В процессе выполнения цикла обучения параметры меняются, а средняя оценка становится всё лучше и лучше. На наших глазах цикл обучения постепенно превращает случайным образом инициализированную недифференцированную сеть в нейросеть для имитации нашего конкретного массива данных.
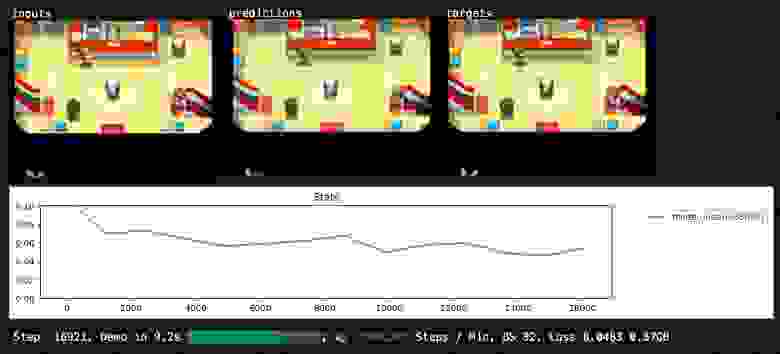
Со временем изменения в обучении начинают нейтрализовать друг друга и оценка постепенно прекращает улучшаться. Если всё получилось, то у нас есть сеть с хорошими оценками, успешно имитирующая поведение «ввод→вывод» из массива данных.

Если всё действительно получилось, наша сеть научилась основным правилам имитации, которые сработают и для неизвестных ей входящих данных.
Наша процедура обучения отдаёт предпочтение конфигурациям параметров, близким к исходным случайным значениям и максимально неинформированным о конкретном примере массива данных, а сети всё равно обычно недостаточно нейронов для запоминания всего массива данных целиком, поэтому у нас есть большой шанс на обобщение.
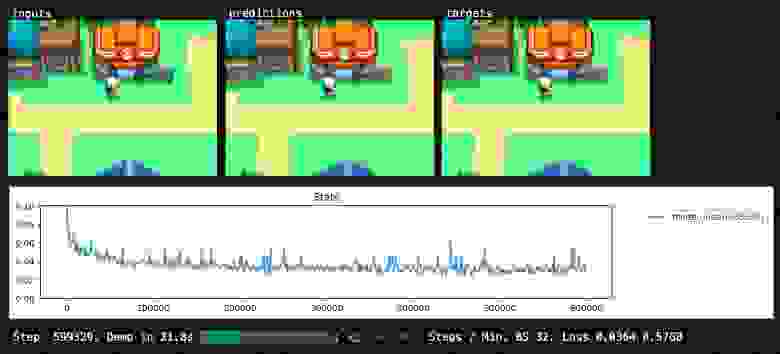
Спустя некоторое время прогнозы сети стали достаточно неплохими, да и оценки выглядели нормально. Я преобразовал свой массив данных в программу, которую можно выполнять. Настало время её запустить.
Джинн наносит удар
Когда я попробовал сыграть в эту первую нейросеть как в игру, к сожалению, моя обученная нейросеть осталась нейросетью. Совершенно сломанной.

Какого чёрта? Циклы обучения — это код, а в коде могут быть баги…, но обучение сошлось к нужному результату. Сеть «переобучилась»? Является ли эмуляция Pokémon «ИИ-полной»?
В моём посте глубокое обучение «врезалось в стену»?
Три проблемы нейронных сетей
К сожалению, даже если вы закодировали идеальный цикл обучения, существует три проблемы «джинна, исполняющего желания в буквальном смысле», которые обучение устранить не может. Это три причины, по которым написанная нами нейросеть может быть не тем, что нам нужно.
Проблема 1 — ей не хватает мощи. Нейросеть не может добавить себе нейронов.

Наша сеть может быть слишком слабой, чтобы описать полную связь «ввод→вывод», описанную массивом данных (даже если найти самые лучшие параметры).
Даже если продолжить обучение, недостаточно мощная сеть всё равно постоянно будет иметь низкие оценки.
Надо сделать так, чтобы структура нашей сети соответствовала задаче, или просто была более выразительной (множество нейронов/слоёв), чтобы решение (множество параметров, дающее идеальную оценку) на самом деле существовало.
В данном случае я хотел, чтобы моя сеть была маленькой/достаточно простой, чтобы её можно было выполнять в веб-браузере без специальных оптимизаций производительности с моей стороны, поэтому я намеренно сделал её маломощной.
Я попробовал удвоить мощность модели примерно до 600 тысяч параметров, и попытался наилучшим образом распределить эту мощность, исходя из своего понимания задачи эмуляции игры. Мне удалось сделать потери при обучении чуть меньше, и при тестировании модели она начинала неплохо, но всё равно со временем ломалась.

Чёрт. Что ещё может быть не так с моей сетью?
Проблема 2 — недостаточно информации. Сеть не может сама дать себе отсутствующую входящую информацию.

Ввод нашего массива данных может не содержать достаточного количества информации, чтобы в общем случае определять правильный вывод. В данном случае, не существует общей программы, способной получить идеальную оценку.
При дальнейшем обучении сеть с недостаточным количеством информации, вероятно, будет получать несовершенные оценки во всём (из-за «размытых» прогнозов, объединяющих несколько догадок смешением). Со временем сеть с недостаточным количеством информации, вероятно, начнёт получать идеальную оценку на массиве данных для обучения благодаря простому запоминанию, но не совершенствуясь в общем.
Нам нужно передавать сети всю необходимую информацию для каждого примера, и устранять все несогласованные данные в соответствующих выводах, чтобы каждый вывод можно было точно получить из соответствующего ввода при помощи одного общего правила.
В данном случае сети сильно мешало отсутствие истинного ввода с данными памяти. Тем не менее, я всё равно предпринял шаги для уменьшения неопределённости в моём массиве с покадровыми данными:
- Я прошёлся по массиву, чтобы исправить ошибки в разметке сигналов управления.
- При обучении я позволял сети сделать множество различных догадок относительно каждого примера, и давал оценку только лучшей догадке, чтобы симулировать наличие дополнительной входящей информации.
После работы над решениями проблем 1 и 2 прогнозы моей сети для обучающего массива данных стали выглядеть чуть лучше, а потери ещё больше снизились. При использовании нейросети в качестве видеоигры, она какое-то время работала нормально, но потом всё равно превращалась в мешанину.
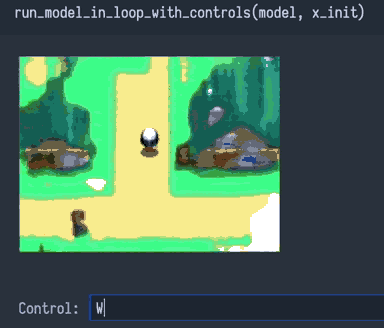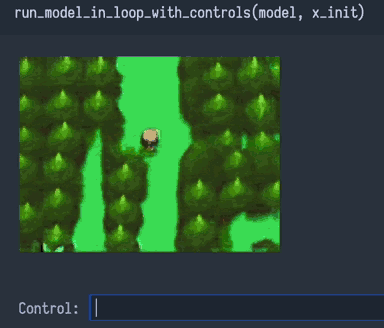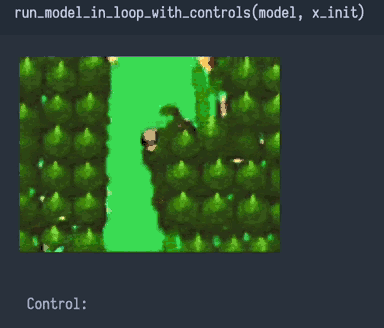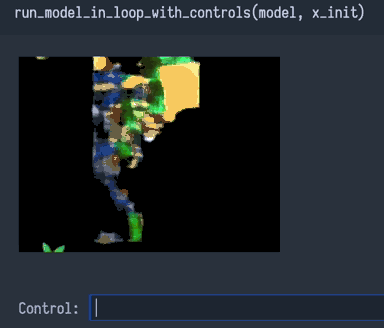
Подумав, я пришёл к выводу, что проблемы 1 и 2 должны были вызвать только несовершенства, а не катастрофический провал. Наверно, на мою сеть влияет что-то другое, какая-то ужасная «проблема 3»…
Проблема 3 — недоопределённость. Сеть не может читать наши мысли о требованиях к «вводу→выводу», которые отсутствуют в массиве данных.

Возможно, мы требуем от сети поведения «ввод→вывод», которое не было записано как пары «ввод→вывод» в обучающий массив данных. Это плохо, очень плохо. Это даже хуже, чем проблемы 1 и 2, потому что величина ошибки для входящей информации, не присутствующей в массиве данных, потенциально безгранична.
Каждое важное нам поведение «ввод→вывод» должно быть записано в обучающий массив данных как пара «ввод→вывод». А в идеале — много пар, много вариаций, чтобы для получения идеальной оценки сети требовалось бы обучиться общему правилу для всей этой категории вводов.
В данном случае я хотел передавать сети в цикле её собственный вывод и получать на выходе напоминающие игру видеокадры, пусть даже спустя много итераций.
Однако при обучении я не сообщил сети о таком требовании к «вводу→выводу». Я обучал сеть только на создание вывода в виде видеокадров, соответствующих вводу в виде реальных видеокадров. Во время тестирования я вызывал неопределённое поведение.
Решение проблемы «наша сеть работает при обучении, но не при тестировании» заключается, разумеется, в использовании сложной стратегии регуляризации разметке тестовых данных и обучении на них тоже.
Если мы будем продолжать это делать, то постепенно множество обучающей входящей информации расширится, включив в себя ту входящую информацию, на которой мы тестируем сеть, и неопределённое поведение больше вызываться не будет.

В данном случае это всего лишь означало, что мне нужно время от времени делать так, чтобы во время обучения вводами сети были предыдущие выводы сети (вместо «реальных» кадров), благодаря чему сеть научится продолжать игровой процесс после предыдущего кадра, спрогнозированного сетью.
Занявшись этим, я решил параллельно время от времени отбрасывать кадры ввода (замена случайным статическим шумом с вероятностью 1%, полностью чёрным экраном с вероятностью 1%), чтобы сеть обучалась инициализировать игровой процесс с пустого экрана.

Наконец-то успешное обучение
После решения всех трёх проблем моя сеть стала достаточно мощной, информированной и определённой. Обученная сеть достаточно хорошо имитировала массив данных, даже «тестового сценария» с длительным игровым процессом. Именно эту версию я использовал для веб-демо.

Дальнейшая работа всегда может усовершенствовать сеть (можно подчистить массив данных, добавить больше данных, оптимизировать код работы сети в веб-браузере, увеличить сеть, оптимизировать цикл обучения, выполнять обучение дольше). Если мы устраним проблему отсутствующей входящей информации ввода, то может быть, даже заставим работать инвентарь, бои и так далее…, но эта сеть уже достаточно хороша для демонстрации концепции.
В чём же смысл?
Нейронные сети — это не «чёрные ящики»
Если вы работали только с нейросетями, созданными другими людьми, то можете решить, что сети — это заранее подготовленные системы, способные на выполнение только одной задачи; то есть «чёрные ящики», уникальным образом подстроенные под конкретный набор задач, которые выполняют нейронные сети.

В Интернете часто встречаются подобные заявления:
Нейронные сети — это просто новый алгоритм для поджаривания тоста; почему все в таком восторге?
(Можно заменить «поджаривание тоста» игрой в шахматы, написанием стихов, созданием картины или любой другой задачей, которую выполняют нейросети.)
Есть и более восторженная точка зрения:
Я люблю нейронные сети и использую их для всех задач, связанных с подогревом хлеба!
Но даже энтузиасты обычно признают, что нейросети загадочны, а их практическое применение ограничено:
Нейронные сети — по-прежнему ненадёжные «чёрные ящики», ломающиеся по странным причинам, которые мы никак не можем отладить. Они являются самым современным решением для определённых типов задач, поэтому они полезны; однако нейросети пока не готовы выполнять любые задачи.В будущем мы найдём способ объединения прогрессивных нейросетей с традиционным кодом модульным и интерпретируемым образом, сможем использовать лучшие стороны старого, при этом задействуя новое, и т. д., и т. п.
Это кажется очень разумным и мудрым — кому же не понравится беспристрастное признание недостатков с последующим призывом объединения лучшего из двух миров?
Однако я считаю такой образ мышления ошибочным. По моему опыту, нейросети — это не «чёрные ящики». Это просто программы, делающие то, что они обучены делать. Им часто не удаётся сделать то, что вам хочется, по тем же скучным причинам («джинн»), по которым постоянно ломается любая компьютерная программа.
Более того, когда дело касается «интерпретируемости», у традиционного кода есть очень специфическая проблема, которую нейронные сети полностью решают.
Проблема кода
Проблема кода заключается в том, что каждая новая написанная строка кода ещё сильнее обфусцирует поведение «ввод→вывод» программы.
Для определения простой программы написание традиционного кода на традиционном языке программирования подходит великолепно. Достаточно лишь написать в нужном порядке требуемые шаги, после чего всё работает. Чтобы понять, что «делает» код, достаточно его лишь прочитать.
Однако код живой. Чтобы понять, что же делает код на самом деле, его нужно запустить. И при добавлении новых строк кода разрыв между тем, что код «делает», и тем, что он делает на самом деле, становится всё больше.
Достигнув некого объёма кода, вы получаете непредсказуемую среду выполнения, необъяснимое поведение, загадочные баги, «исправление» которых занимает неделю и добавляет ещё три новых бага. Вы полностью зависимы от сквозного тестирования (нужно пропустить код через массив входящих данных, подождать завершения и сравнить выводы программы с заведомо правильными выводами), чтобы вообще получить какие-то гарантии «ввода→вывода».
«Модульный и интерпретируемый код» — звучит отлично, пока ты не увидишь сто модулей по сто тысяч строк кода в каждом и кто-нибудь не попросит тебя их интерпретировать.
Магия данных
Программисты (и особенно программисты игр) научились переносить сложность программ на данные. Числа переносятся в файлы конфигураций, одномерные массивы — в аудиофайлы, двухмерные массивы — в файлы изображений, и так далее.
В отличие от кода, данные легко понимать и легко редактировать. В отличие от кода, разные элементы данных можно безопасно параллельно редактировать несколькими командами людей. В отличие от кода, данные не живые.
Благодаря переносу сложности в файлы данных программа может продолжать расти (100 МБ… 1 ГБ… 10 ГБ), а доля сложности программы, написанная в живом коде, становится всё меньше и меньше. Поведение «ввода→вывода» движется в сторону неопределённости, но сублинейной скоростью.
Нейронные сети: программа, целиком состоящая из данных
Нейронные сети одновременно являются и решением проблемы «каждая новая строка кода ещё больше обфусцирует поведение «ввод→вывод», и естественной конечной точкой стратегии переноса сложности в данные, которой уже пользуются программисты.
При работе с нейросетью нужное поведение «ввод→вывод» программы прописывается в явной форме как данные в обучающем массиве данных. Каждое «для этого ввода верни вот этот вывод», каждое «за исключением этого случая, здесь поступай вот так». Всё это находится в данных.
Вне зависимости от сложности поведения программы, если вы записываете её как нейросеть, программа остаётся интерпретируемой. Чтобы понять, что же действительно делает нейронная сеть, достаточно прочитать массив данных.
Игры через нейросеть… серьёзно?
Разумеется, концепция видеоигры, написанной как нейросеть, пока ещё не получила развития.
Наряду с проблемами «недостаточной мощности, недоинформированности и недоопределённости» и наряду с культурной инертностью методик «модульности и интерпретируемости» существует также ужасное замедление (примерно в 16 раз), когда вычисления выполняются посредством активации нейронов, а не нулями и единицами. Для игр это неприятная новость.
Концепция игры в виде нейронной сети, которая поместится в веб-браузер, сегодня довольно мала и ограничена рендерингом крошечных игр с низким разрешением. Сети, которые можно будет запускать в веб-браузере в 2030 году, вероятно, будут способны на большее. На гораздо большее.

Поэтому я считаю, что нейронные сети поглотят игры снаружи, начав с готовых видеокадров, потом перейдя на G-буферы, один за другим заменяя слои «модульного и интерпретируемого» кода.
Как только нейросеть будет успешно применена для одного слоя ужасно сложной, работающей только потому, что интеграционные тесты принудительно вызывают нужное поведение, программы, кто-нибудь задаст очевидный вопрос о соседних слоях.
Этот слой кода слишком сложный. Похоже, никто не знает, как сделать его быстрее или лучше, да и не понимает, как он вообще работает.И мы всё равно передаём его вывод нейросети.
А не может ли сеть просто… выполнять и эту задачу?
Так как нейросети — это программы, то ответ всегда будет утвердительным. Они могут имитировать что угодно. Если, конечно, вы очень-очень точно опишете нужное вам поведение.

День первый обучения нейросети.
— Дитто, превратись вот в это!
