[Перевод] Дженерики могут замедлить ваш код на Go
Встречайте, вот и Go 1.18, а с ней — первый релиз долгожданной реализации дженериков, наконец-то готовых к реальному использованию в продакшене. Дженерики — это весьма востребованная возможность, давно вызывающая жаркие споры в сообществе Go. С одной стороны, самые голосистые беспокоятся по поводу сложности, которую привносят дженерики. Их страшит неизбежная эволюция Go, которая доведет его либо до многословия как в энтерпрайз-версии Java, со своими обобщенными фабриками, либо, самое страшное, превратит Go в вырожденный HaskellScript, где if-ы придется заменить монадами. Положа руку на сердце, оба этих опасения могут быть преувеличенными. С другой стороны, поборники дженериков считают, что дженерики критически важны для масштабного внедрения чистого кода, пригодного для многоразового использования.
Автор этой статьи не принимает ни одну из сторон в данных дебатах и не дает рекомендаций, где и в каких случаях использовать дженерики в Go. Напротив, эта статья призвана осветить запутанный случай с дженериками в Go с третьей стороны: с точки зрения системных программистов, которые воодушевлены не дженериками как таковыми, , а мономорфизацией и тем, как она может сказаться на производительности. Нас таких десятки. Десятки! И мы все имеем изъявить некоторое серьезное разочарование.
Реализация дженериков в Go 1.18
Есть много различных способов реализовать в языке программирования параметрический полиморфизм (который обычно называют «дженерики»). Давайте кратко обсудим эту область задач, чтобы понять то решение, которое было внедрено в Go 1.18. Поскольку эта статья рассказывает о системной инженерии, дискуссию о теории типов мы выдержим в легкой и безболезненной форме. А вместо технических терминов часто будем использовать слово »штуки».
Допустим, вы хотите создать полиморфную функцию, которая одинаково обращается с разными штуками. В широком смысле, к этому существует два подхода.
Во-первых, можно сделать все штуки, над которыми будет оперировать функция, такими, чтобы они выглядели и действовали одинаково. Такой подход называется «упаковка», и обычно он предполагает выделение »штук» в куче, после чего остается просто передавать нашей функции указатели на них. Поскольку все штуки по форме одинаковы (это же указатели!), все, что нам требуется для операций над ними — знать, где находятся методы для операций над этими штуками. Следовательно, указателям на штуки, передаваемым нашей функции, обычно сопутствует таблица указателей на функции, часто именуемая «таблицей виртуальных методов» или vtable для краткости. Улавливаете? Именно так реализуются интерфейсы в Go, но не только они, а еще и типажи dyn Trait в Rust и виртуальные классы в C++. Все это — разновидности полиморфизма, которыми легко пользоваться на практике, но им недостает выразительности, а во время исполнения работа с ними влечет издержки.
Второй способ заставить функцию оперировать над множеством разных штук называется «мономорфизация». Звучит, может быть, страшновато, но реализация ее относительно проста. Сводится к созданию отдельной копии функции для каждой уникальной штуки, над которой предполагается производить операции. Вот и все, да. Если у вас есть функция, складывающая два числа, и вы можете вызвать ее, чтобы сложить два float64, то компилятор создаст копию этой функции и заменит заглушку обобщенного типа на float64, а затем скомпилирует эту функцию. Это, бесспорно, наиболее прямолинейный способ реализовать полиморфизм (пусть иногда и становится весьма сложно применять его на практике), а для компилятора этот способ также самый затратный.
Исторически именно мономорфизация выбиралась для проектирования и реализации дженериков в языках системного программирования, в частности, C++, D или Rust. На то есть много причин, но все сводится к компромиссу: соглашаясь на заметное увеличение времени компиляции, получаем значительный выигрыш по производительности в результирующем коде. Когда заменяете заглушки типов в обобщенном коде окончательно выбранными типами, еще до того, как компилятор осуществит над ними какие-либо оптимизации, вы сами успеваете сделать очень занятную гамму оптимизаций, которые были бы, в сущности, невозможны при использовании упакованных типов. В качестве абсолютного минимума, вам пришлось бы девиртуализировать вызовы функций и избавиться от виртуальных таблиц; при наилучшем развитии событий для этого потребовалось бы встраивать код в строку, что, в свою очередь, открывает путь для новых оптимизаций. Такое встраивание кода — это отлично. Мономорфизация — сплошной выигрыш в языках системного программирования; это, в сущности, единственная форма полиморфизма, у которой нулевые издержки во время исполнения, а зачастую издержки при производительности даже оказываются отрицательными. То есть, при мономорфизации обобщенный код становится быстрее.
Итак, я, как человек, работающий над производительностью в больших приложениях на Go, признаю, что меня дженерики в Go особо не впечатлили, правда. Я загорелся мономорфизацией, а также потенциалом для компилятора Go в том, что касается оптимизаций, которые были бы просто невозможны, если работать с интерфейсами. Следите, в чем я разочаровался: реализация дженериков в Go 1.18 просто не использует мономорфизацию… по крайней мере, не использует полноценно.
На самом деле, она основывается на приеме частичной мономорфизации, которая называется «Контурирование [stenciling] GCShape при помощи словарей». Подробно о данном технологическом выборе рассказано в этом проектировочном документе, который доступен в вышестоящем репозитории. Для полноты картины и для лучшей ориентации в анализе производительности, который приведен в этом посте, кратко резюмирую данный документ:
Ключевая идея такова: поскольку при полной мономорфизации вызова каждой функции на основе ее входных аргументов придется иметь дело с солидными объемами сгенерированного кода, можно сократить количество уникальных очертаний функций, мономорфизируя их на более высоком уровне, чем типы аргументов. Следовательно, при такой реализации дженериков компилятор Go выполняет мономорфизацию (то, что в документе по ссылке именуется «stenciling») на основе GCShape аргументов, а не их типа. GCShape типа — это абстрактная концепция, специфичная для языка Go и этой реализации дженериков. Как указано в документе по проектированию,»два конкретных типа группируются в один и тот же gcshape тогда и только тогда, когда происходят от одного и того же базового типа, а сами по типу оба относятся к указателям». Первая часть этого определения ясна: если у вас есть метод, который, скажем, выполняет над своими аргументами арифметическую операцию, то компилятор Go фактически мономорфизирует ее на основе типов аргументов. Сгенерированный код для uint32, использующий арифметические инструкции для работы с целыми числами, будет отличаться от кода для float64, в котором будут применяться инструкции для работы с числами с плавающей точкой. С другой стороны, сгенерированный код, предназначенный для алиасинга типов под uint32, будет таким же, как для базового uint32.
Пока все понятно. Но вторая часть определения GCShape существеннейшим образом сказывается на работе с производительностью. Я это акцентирую: Все указатели на объекты относятся к одному и тому же GCShape, независимо от того, на какой объект указывают. Это означает, что у указателя на *time.Time будет такой же GCShape, как и у *uint64, у *bytes.Buffer и у *strings.Builder. Возможно, у вас уже назрел вопрос: «Уф, а что же будет, если мы захотим вызвать метод для обработки этих объектов? Местоположение такого метода, вероятно, не может входить в состав GCShape!». Да, этот момент спойлерится в самом названии документа: GCShapes ничего не знают о методах, поэтому нам придется поговорить о словарях, которые их сопровождают.
В актуальной реализации дженериков по состоянию на 1.18, при каждом вызове обобщенной функции во время выполнения она будет прозрачно получать в качестве своего первого аргумента статический словарь с метаданными об аргументах, передаваемых этой функции. Словарь будет помещаться в регистр AX в AMD64 и в стек на тех платформах, где компилятор Go пока не поддерживает соглашений, связанных с вызовами на основе регистров. Подробности реализации этих словарей досконально объяснены в вышеупомянутом документе, но для краткости скажу: они включают все метаданные типов, которые понадобятся для передачи аргументов следующим обобщенным функциям, для преобразования их из интерфейсов и в интерфейсы, и, что для нас наиболее важно, для вызова методов с целью их обработки. Все верно, уже после этапа мономорфизации функция с имеющейся формой должна во время выполнения принять в качестве ввода таблицы виртуальных методов для всех ее обобщенных аргументов. Интуиция подсказывает: притом, что такой подход значительно уменьшает объем уникального кода, генерируемого при работе, широкая мономорфизация такого рода не приспособлена к девиртуализации, встраиванию в строку, да и вообще к каким-либо оптимизациям производительности.
Фактически, может показаться, что для абсолютного большинства кода на Go верно следующее: в результате обобщения такой код становится медленнее. Но, прежде, чем нас затянет в трясину отчаяния, давайте расставим несколько контрольных точек, посмотрим на код сборки и проверим некоторые варианты поведения.
Встраивание интерфейсов
Vitess, свободно распространяемая распределенная база данных, обеспечивающая работу PlanetScale — это большое и сложное приложение на Go для реальных задач, и отлично подходит в качестве испытательного полигона для проверки новых возможностей языка Go, в особенности тех, что связаны с производительностью. У меня нашелся длинный список функций и реализаций для Vitess, которые в настоящее время мономорфизируются вручную (вот как я изящно сказал «копипастятся, но уже с другими типами»). Некоторые из этих функций дублируются, поскольку их полиморфизм не смоделировать при помощи интерфейсов; другие дублируются, поскольку критичны для производительности, и, если скомпилировать их без интерфейсов, получается ощутимый выигрыш в производительности.
Рассмотрим интересного «кандидата» из этого списка: функции BufEncodeSQL из пакета sqltypes. Эти функции дублируются так, чтобы они могли принимать *strings.Builder или *bytes.Buffer, так как выполняют много вызовов к предоставляемому буферу, и эти вызовы могут встраиваться компилятором, если буфер передается как неупакованный тип, в противовес интерфейсу. В результате получается существенный выигрыш в производительности у функции, которая широко применяется во всей базе кода.
Обобщить такой код не составит труда, так что давайте это сделаем и сравним обобщенную версию этой функции с простой версией, которая принимает io.ByteWriter в качестве интерфейса.
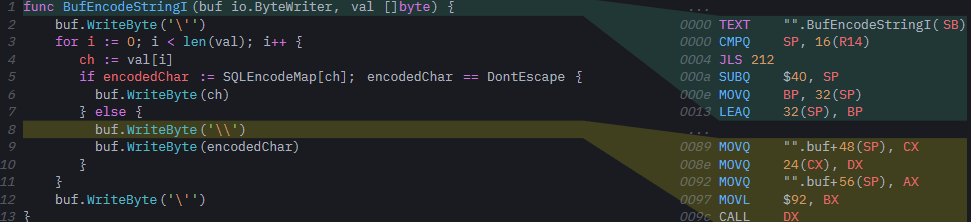 ».BufEncodeStringI
».BufEncodeStringI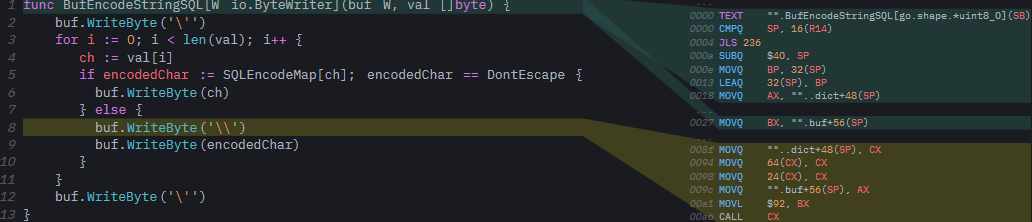 ».BufEncodeStringSQL[go.shape.*uint8_0]
».BufEncodeStringSQL[go.shape.*uint8_0]
Нет ничего удивительного в коде сборки для версии io.ByteWriter: все вызовы к WriteByte происходят через itab. Вскоре мы подробно рассмотрим, что именно это значит. Но оказывается, что обобщенная версия становится все интереснее. Во-первых, мы видим, что компилятор сгенерировал всего один вариант формы, когда инстанцировал функцию (BufEncodeStringSQL[go.shape.*uint8_0]). Хотя, во встроенном представлении мы этого не показываем, нам придется вызвать обобщенную функцию при помощи *strings.Builder из достижимого кода; в противном случае компилятор вообще не сгенерирует никаких вариантов инстанцирования для функции:
var sb strings.Builder
BufEncodeStringSQL(&sb, []byte(nil))Поскольку мы вызвали функцию с *strings.Builder в качестве аргумента, мы увидим в сгенерированной сборке форму *uint8. Как было объяснено выше, все обобщенные вызовы, принимающие указатель в качестве обобщенного аргумента, контурируются как *uint8, независимо от того, на какой объект указывают. Фактические свойства объекта — и, что наиболее важно, его itab — хранятся в словаре, который передается обобщенной функции.
Все это соответствует тому, что мы прочитали в документе по проектированию: в процессе контурирования тот указатель, который был направлен на структуру, мономорфизируется и принимает такой вид, как будто указывает в никуда (void). Никакие другие атрибуты указателя на объект не учитываются в процессе мономорфизации, и, следовательно, какое-либо встраивание невозможно. Информация о тех методах структуры, которые поддаются встраиванию, доступна только в словаре во время выполнения. Это уже препятствие: как мы успели убедиться, контурирование спроектировано таким образом, что не допускает девиртуализации вызовов функций и, следовательно, не предоставляет компилятору возможностей встраивания. Но подождите, худшее еще впереди!
Есть глубокий анализ производительности, который мы можем сделать на основе фрагмента кода, сравнив сборку, сгенерированную для вызова метода WriteByte в коде интерфейса по сравнению с обобщенным кодом.
Интерлюдия: вызов метода интерфейса в Go
Прежде, чем мы сможем сравнить вызовы в первой и во второй версии кода, давайте быстро освежим в памяти, как в Go реализуются интерфейсы. Мы кратко коснулись того факта, что интерфейсы — это вариант полиморфизма, при котором применяется упаковка, т.е., гарантируется, что все объекты, которыми мы оперируем, имеют одинаковую форму. В случае с интерфейсом Go это толстый 16-байтный указатель (iface), где первая часть указывает на метаданные, описывающие упакованное значение (то, что мы называем itab), а вторая часть указывает на само значение.
type iface struct {
tab *itab
data unsafe.Pointer
}
type itab struct {
inter *interfacetype // смещение 0
_type *_type // смещение 8
hash uint32 // смещение 16
_ [4]byte
fun [1]uintptr // смещение 24...
}
В этом itab содержится масса информации о типе внутри интерфейса. Поля inter, _type и hash содержат все требуемые метаданные, которые обеспечивали бы преобразование между интерфейсами, рефлексию и переключение по типу интерфейса. Но нас в данном случае наиболее интересует массив fun в конце itab: хотя, в описании типа он и отображается как [1]uintptr, на самом деле под него выделяется память переменной длины. Размер структуры itab меняется от интерфейса к интерфейсу, и в конце структуры оставлено достаточно места, чтобы сохранить указатель функции для каждого метода в интерфейсе. Именно к этим указателям функций мы должны будем обращаться всякий раз, когда захотим вызвать метод в интерфейсе; в Go они эквивалентны виртуальной таблице C++.
Помня об этом, теперь можно понять сборку вызовов для метода интерфейса в необобщенной реализации нашей функции. Вот во что компилируется строка 8, buf.WriteByte('\\'):

Для вызова метода WriteByte в buf, нам первым делом нужен указатель на itab для buf. Хотя, buf исходно передавался в нашу функцию в паре регистров, компилятор пролил его в стек в начале тела функции, так, что она может использовать регистры для других целей. Чтобы вызвать метод в buf, мы сначала должны загрузить *itab из стека обратно в регистр (CX). Теперь мы можем разыменовать указатель itab в CX для доступа к его полям: мы перемещаем двойное слово со смещением 24 в DX, а, если быстро глянуть в исходное определение itab выше, то, действительно, первый указатель функции в itab находится со смещением 24 — все это пока кажется осмысленным.
Когда в DX содержится адрес функции, которую мы хотим вызвать, мы просто пропускаем ее аргументы. То, что в Go называется «метод, прикрепленный к структуре» — это сахар для самостоятельной функции, которая принимает в качестве первого аргумента свой получатель, напр., func (b *Builder) WriteByte(x byte) без сахара превращается в func "".(*Builder).WriteByte(b *Builder, x byte). Следовательно, первый аргумент при вызове нашей функции должен быть buf.(*iface).data, фактически, это указатель на strings.Builder, который находится внутри нашего интерфейса. Этот указатель доступен в стеке, через 8 байт после указателя tab, который мы только что загрузили. Наконец, второй аргумент нашей функции — это литерал \\, (ASCII 92), и можно CALL DX, чтобы выполнить наш метод.
Уф! Пришлось попотеть, чтобы вызвать простой метод. Хотя, при практической оценке производительности, это не так плохо. Не считая того, что при вызове через интерфейс невозможно осуществлять встраивание, фактические издержки на вызов сводятся к единственному разыменованию указателя для загрузки адреса функции из itab. Прямо сейчас мы расставим тут бенчмарки чтобы посмотреть, во сколько нам обходится такое разыменование, но сначала давайте рассмотрим процесс генерации обобщенного кода.
Вернемся к дженерикам: вызовы указателей
Вернемся к коду сборки нашей обобщенной функции. В качестве напоминания: мы анализируем ту форму, в которой инстанцируется *uint8, поскольку все контуры, в которой инстанцируются указатели, похожи: это указатели, направленные в пустоту (void). Рассмотрим, как выглядит вызов метода WriteByte в buf:
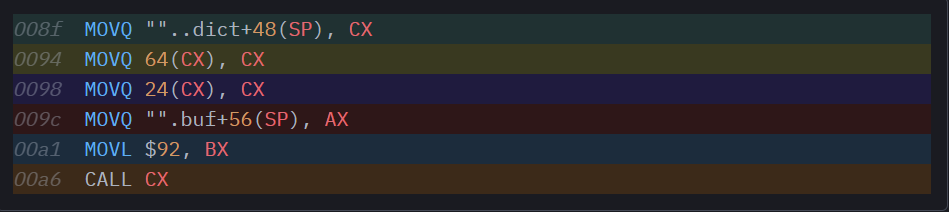
Выглядит весьма знакомо, но, все-таки, есть резкая разница. В точке со смещением 0x0094 содержится то, что нам совершенно не нужно на месте, где вызывается функция: разыменование еще одного указателя. С технической точки зрения это, опять же, одно большое разочарование. Вот что здесь происходит: поскольку мы мономорфизируем все контуры указателей в единую форму, для *uint8, в этом контуре не содержится никакой информации о методах, которые могут вызываться в этих указателях. Где должна находиться эта информация? В идеале она должна была бы лежать в itab, ассоциированном с нашим указателем, но здесь нет itab, который был бы прямо ассоциирован с нашим указателем, поскольку форма нашей функции такова, что в качестве аргумента buf она принимает единственный 8-байтный указатель, в противовес 16-байтному толстому указателю с полями *itab и data, как это делалось бы в интерфейсе. Как вы помните, именно по этой причине в реализации с контурами каждому обобщенному вызову функции передается словарь: в этом словаре содержатся указатели на itab-ы всех обобщенных аргументов функции.
Хорошо, теперь, с дополнительной нагрузкой, эта сборка становится совершенно осмысленной. Вызов метода начинается не с загрузки itab для нашего buf, а с загрузки словаря, который был передан нашей обобщенной функции (и также пролит в стек). При наличии словаря в CX мы можем разыменовать его, и в точке со смещением offset 64 найдем искомый *itab. Как ни грустно, теперь нам нужен еще один акт разыменования (24(CX)), чтобы загрузить указатель функции, вынутый из itab. В остальном вызов метода идентичен тому, что получился у нас при прошлой генерации кода.
Насколько плоха такая дополнительная операция разыменования на практике? Интуитивно можем предположить, что вызов методов в объекте в составе обобщенной функции всегда будет медленнее, чем в необобщенной, которая просто принимает интерфейс в качестве аргумента. Дело в том, что при работе с дженериками то, что раньше представляло собой вызовы указателей, деградирует в дважды опосредованные вызовы интерфейса, на вид более медленные, чем обычный вызов интерфейса.

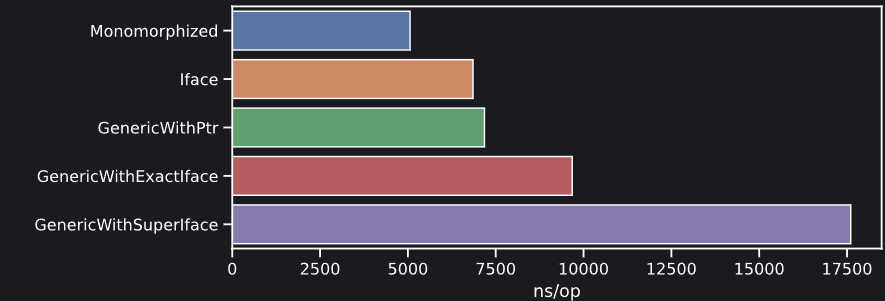
Этот простой бенчмарк тестирует тело одной и той же функции с 3 слегка разными реализациями. GenericWithPointer передает *strings.Builder нашей обобщенной функции func Escape[W io.ByteWriter](W, []byte). Бенчмарк Iface сделан для функции func Escape(io.ByteWriter, []byte), которая принимает интерфейс напрямую. Monomorphized — для вручную мономорфизированной func Escape(*strings.Builder, []byte).
Результаты неудивительны. Функция, специализированная для того, чтобы принимать *strings.Builder напрямую, самая быстрая, так как она разрешает компилятору встраивать внутри нее вызовы WriteByte. Обобщенная функция измеримо медленнее, чем простейшая возможная реализация, принимающая интерфейс io.ByteWriter в качестве аргумента. Мы видим, что влияние дополнительной нагрузки от обобщенного словаря несущественно, поскольку как itab, так и словарь дженериков можно будет взять тепленькими из кэша этого микробенчмарка (правда, дальше рассказано, как война за кэши влияет на код дженериков — так что обязательно читайте дальше).
Вот и первый вывод, который мы можем почерпнуть из этого анализа: в 1.18 нет никакого стимула преобразовывать чистую функцию, принимающую интерфейс, так, чтобы она работала с дженериками. Это только замедлит код, поскольку в настоящее время компилятор Go не может сгенерировать такую форму функции, в которой методы вызываются через указатель. Вместо этого вводится вызов интерфейса с двумя уровнями косвенности. Это уводит нас в прямо противоположную сторону от того, чего бы нам хотелось –, а нам бы хотелось девиртуализации и, где это возможно, встраивания.
Прежде, чем завершить этот раздел, заострим внимание на одной детали в том, как компилятор Go выполняет анализ выхода [escape analysis]: как видим, в нашем бенчмарке у функции 2 allocs/op. Дело в том, что мы передаем указатель на strings.Builder, находящийся в стеке, и компилятор может доказать, что он помещается и, следовательно, его не требуется выделять в куче. Бенчмарк Iface показывает 3 allocs/op, пусть даже мы также передаем указатель из стека. Дело в том, что мы перемещаем указатель на интерфейс, а тут всегда происходит выделение. Удивительно, что реализация GenericWithPointer также показывает 3 allocs/op. Пусть даже функция, инстанцированная в таком виде, принимает указатель напрямую, анализ выхода больше не может доказать, что она не выходит за пределы, поэтому получаем дополнительное выделение в куче. Ну да. Небольшая печалька. Теперь же время переходить к другим печалькам, побольше, покруче.
Обобщенные вызовы интерфейсов
В неcкольких предыдущих разделах мы анализировали, как генерируется код для нашей обобщенной функции Escape и рассматривали, какая форма у нее получается при вызове функции с *strings.Builder. Вы, вероятно, припоминаете, что обобщенная сигнатура нашего метода имела вид func Escape[W io.ByteWriter](W, []byte), и *strings.Builder определенно удовлетворяет этому ограничению, что и дает нам ту форму, в которой инстанцируется *uint8.
Но что бы произошло, если бы мы здесь попытались спрятать наш *strings.Builder за интерфейсом?
var buf strings.Builder
var i io.ByteWriter = &buf
BufEncodeStringSQL(i, []byte(nil))Теперь аргументом нашей обобщенной функции является интерфейс, а не указатель. Вызов явно корректен, так как тот интерфейс, что мы передаем, идентичен ограничению, налагаемому на наш метод. Но какую форму будет иметь тот экземпляр, который мы при этом сгенерируем? Мы не встраиваем всю «разобранную сборку», потому что она станет сильно мельтешить, но, точно как и делали ранее, давайте проанализируем точки вызовов для методов WriteByte в этой функции:
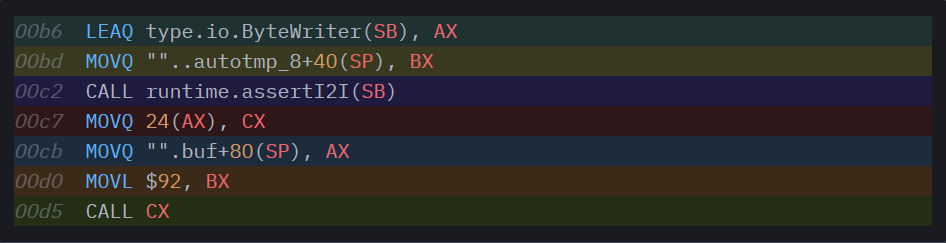
Упс! По сравнению с предыдущим вариантом генерации кода этот вариант выглядит значительно менее привычно. Мы согласились (и измерили), что дополнительное разыменование на каждой точке вызова — это нехорошо, поэтому представьте, каково нам будет от дополнительного вызова целой функции.
Что здесь происходит? В среде времени выполнения Go можно найти метод runtime.assertI2I: он вспомогательный и постулирует преобразование от интерфейса к интерфейсу. В качестве двух аргументов он принимает *interfacetype и *itab и возвращает itab для заданного interfacetype только, если интерфейс в заданном itab также реализует наш целевой интерфейс. Ох, что?
Допустим, у вас есть вот такой интерфейс:
type IBuffer interface {
Write([]byte) (int, error)
WriteByte(c byte) error
Len() int
Cap() int
}Этот интерфейс ничего не упоминает о io.ByteWriter или io.Writer, но, все же, любой тип, реализующий IBuffer, также неявно реализует и эти два интерфейса. Это заметно влияет на генерацию кода для нашей обобщенной функции: поскольку обобщенное ограничение для нашей функции это [W io.ByteWriter], можно передать в качестве аргумента любой интерфейс, реализующий io.ByteWriter — включая нечто вроде IBuffer. Но, когда нам нужно вызвать метод WriteByte в нашем аргументе, где же в массиве itab.fun для полученного нами интерфейса, находится этот метод? Мы не знаем! Если передать наш *strings.Builder как интерфейс io.ByteWriter, то itab в этом интерфейсе будет держать наш метод в fun[0]. Если мы передадим его как IBuffer, он будет в fun[1]. Нам тут понадобится помощник, который сможет взять itab для IBuffer и вернуть itab для io.ByteWriter, где указатель функции WriteByte всегда стабилен в fun[0].
Это задача assertI2I, и именно этим занимается код в каждой точке вызова в функции. Давайте разберем его пошагово.
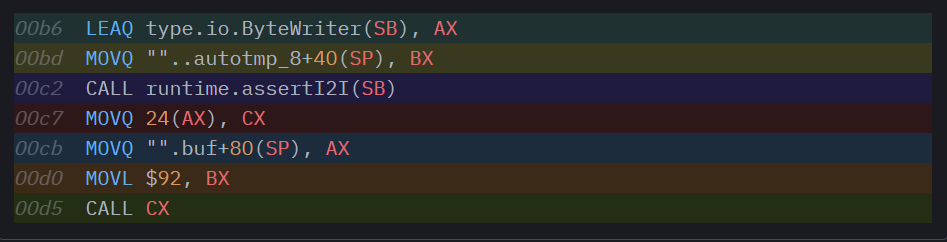
Сначала он загружает interfacetype для io.ByteWriter (это жестко закодированное глобальное значение, поскольку это тип интерфейса, определенный в нашем ограничении) в AX. Затем он загружает в BX фактический itab для того интерфейса, который мы передали нашей функции. Есть два аргумента, которые нужны assertI2I, и, вызвав его, мы остаемся с itab для io.ByteWriter в AX, а далее можем продолжать работу с вызовом функции интерфейса, как и при предыдущей генерации кода, зная, что наш указатель функции всегда находится со смещением 24 внутри нашего itab. В сущности, при данном инстанцировании формы происходит буквально следующее: каждый вызов метода преобразуется из buf.WriteByte(ch) в buf.(io.ByteWriter).WriteByte(ch).
Кстати, да, выглядит адски расточительно. При этом выглядит весьма избыточно. Было бы возможно приобрести io.ByteWriter itab всего один раз, в начале функции, а затем переиспользовать его при всех вызовах функций? Эхх, вообще — нет, но бывают у функций такие формы, при которых поступать так безопасно (как, например, в случае с той функцией, которую мы сейчас анализируем), поскольку значение в интерфейсе buf никогда не меняется, и нам не потребуется переключаться между типами или передавать интерфейс buf вниз каким-либо другим функциям, работающим в стеке. Определенно, здесь есть некоторый простор для оптимизаций, которые мог бы внести компилятор Go. Обратим внимание на цифры бенчмарков, чтобы оценить, какова будет степень влияния такой оптимизации:

Это не радует. С использованием assertI2I связаны заметные издержки, даже если функция просто вызывает другие функции и больше ничего не делает. Мы идем почти вдвое медленнее, чем при использовании вручную мономорфизированной функции, которая вызывает WriteByte напрямую и на 30% медленнее, чем если просто использовать интерфейс io.ByteWriter без дженериков. По любым меркам, это выстрел в ногу нашей производительности, и это нужно осознавать: одна и та же обобщенная функция, со все тем же аргументом, будет работать значительно медленнее, если вы передадите аргумент внутри интерфейса, а не напрямую как указатель.
…Но подождите! Это еще не все! Если вы обратили внимание, как тщательно мы именуем наши контрольные кейсы, то понимаете, что тут можно поделиться еще множеством увлекательных подробностей, касающихся производительности. Оказывается, что наш бенчмарк GenericWithExactIface на самом деле описывает наилучший возможный сценарий, поскольку в нашей функции прописано ограничение [W io.ByteWriter], и мы передаем наш аргумент как интерфейс io.ByteWriter. Это означает, что вызов к runtime.assertI2I может вернуться немедленно, с тем itab, который мы ему передали — поскольку он совпадает с тем itab, который подыскивается для инстанцированной нами формы. Но что делать, если мы передали наш аргумент как ранее определенный интерфейс IBuffer? Это бы сработало вполне нормально, потому что *strings.Builder реализует одновременно IBuffer и io.ByteWriter, но во время выполнения все до одного вызовы методов внутри нашей функции будут приводить к глобальному поиску в таблице хешей, когда assertI2I попытается приобрести io.ByteWriter itab из нашего аргумента IBuffer.

Хаха, шикарно. Это потрясающее открытие. Что касается производительности, раньше мы стреляли в ногу, а теперь мы ногу испепеляем, и все зависит от того, точно ли соответствует интерфейс (который вы передаете обобщенной функции) заданному ограничению, либо соответствует надмножеству ограничений. Теперь, возможно, самая соль этого анализа: передавать обобщенные интерфейсы к обобщенной функции в Go — однозначно нехорошая идея. В наиболее благоприятной ситуации, если ваш интерфейс в точности удовлетворяет ограничению, вам предстоит увидеть серьезные издержки на каждом вызове метода в ваших типах. В вероятном случае, где ваш интерфейс соответствует надмножеству ограничений, все до одного вызовы методов придется динамически разрешать через хеш-таблицу, а еще для этой функциональности ни в каком виде не реализовано кэширование.
Перед завершением этого раздела необходимо принять во внимание одну крайне важную деталь, которая будет играть роль, если придется взвешивать, приемлемы ли издержки, связанные с дженериками в Go, для вашего практического случая: числа, показанные в этих бенчмарках — это максимально оптимистичные значения, что, в частности, касается интерфейсных вызовов, и они не дают представления о тех издержках, которые возникнут при вызове функции в реалистичном приложении. Эти микробенчмарки прогонялись «в вакууме» где itab и словари для обобщенной функции всегда лежат тепленькие в кэше, а глобальная itabTable, нужная для работы assertI2I, пустая и неоспариваемая. В конкретном сервисе, используемом в продакшене, будет война кэшей, а глобальная itabTable может содержать от сотен до миллионов записей, в зависимости от того, насколько давно выполняется ваш сервис, и от количества уникальных пар тип/интерфейс в вашем скомпилированном коде. Это значит, что издержки на вызов обобщенного метода в ваших программах на Go будут усугубляться по мере усложнения вашей базы кода. Ничего нового, поскольку такая деградация на самом деле затрагивает все проверки интерфейсов в программе на Go, но такие проверки интерфейсов обычно не идут такой плотной чередой, какой могут идти вызовы функций.
Есть ли какой-то способ промерять такую деградацию в искусственно синтезированной среде? Есть, но не слишком академический. Можно засорить глобальную itabTable записями и непрерывно вытрясать кэш L2 CPU из отдельной горутины. Такой подход позволяет произвольно повысить издержки на вызов метода в любом обобщенном коде, где расставлены контрольные точки, но на самом деле очень сложно создать рисунок такой войны кэшей в itabTable, которая в точности соответствует тому, что мы видим в живом продакшен-сервисе. Поэтому измеренные издержки сложно экстраполировать на более реалистичные окружения.
Тем не менее, поведение, наблюдаемое в этих контрольных точках, все равно весьма интересны. Таков результат измерения микро-бенчмарков при измерении издержек, связанных с вызовом методов (в наносекундах на вызов) для разных возможных вариантов генерации кода в Go 1.18. Метод тестируется как невстроенное пустое тело, поэтому так можно строго измерить издержки на вызов. Эта контрольная точка прогоняется три раза: в вакууме, постоянное опорожнение кэша L2, а также с опорожнением и сильно увеличенной глобальной itabTable, которая содержит коллизии для искомого itab.
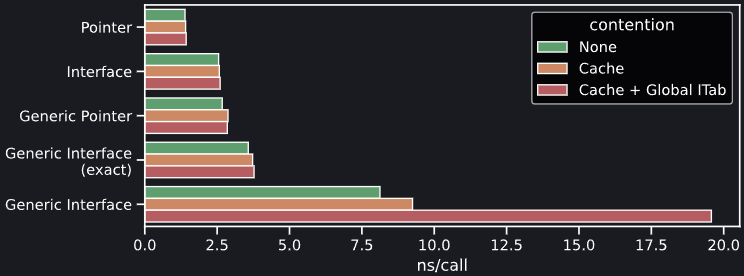
Как видим, издержки на вызов метода «в вакууме» масштабируются аналогично тому, как мы видели в наших контрольных точках при анализе выхода. Интересные вещи происходят, когда привносится конкуренция за ресурсы: как и ожидается, производительность при вызовах необобщенного метода не затрагивается при войне за кэш L2, но при этом виден небольшой рост издержек для всего обобщенного кода (даже такого кода, который не обращается к глобальной itabTable — вероятнее всего, потому, что во время выполнения задействуются более крупные словари, и обращаться к ним приходится при вызовах всех обобщенных методов). По-настоящему катастрофическая комбинация возникает, когда мы увеличиваем размер itabTable попутно с опорожнением кэша L2: так привносится огромный набор издержек, сопутствующих каждому вызову метода, посколь
