[Перевод] DiffSplat: генерация 3D-объектов с помощью диффузионных моделей изображений
Полезно было бы уметь генерировать по текстовому описанию не только картинки, а полноценный 3D-объект, который можно рассмотреть со всех сторон. Это открывает огромные возможности для дизайна, игр, виртуальной реальности. Однако генерация 3D-контента — задача непростая. Современные методы требуют огромных объемов данных для обучения и страдают от несогласованности между разными ракурсами.
Авторы DiffSplat предлагают подход, который решает эти проблемы элегантно и, что более важно, быстро! Вместо того чтобы создавать 3D-модели с нуля, создатели используют уже предобученные text-to-image модели. И просто «перепрофилируют» их для работы с 3D-гауссовыми сплатами.
Лирическое отступление переводчика о 3D Gaussian Splatting

В этой статье для генерации объекта используются 3D-гауссовы сплаты. Этот подход опирается на 3D Gaussian Splatting (3DGS) — фундаментальную работу, которая изменила мир компьютерного зрения навсегда, а ее вклад в решение задачи NVS (Novel View Synthesis) переоценить невозможно. 3DGS представляет сцену в виде множества многомерных «шариков» (гауссиан). Когда мы выбираем положение камеры, каждый шарик проецируется на 2D-плоскость, и в результате мы получаем изображение. У этих объектов много замечательных свойств, многие из которых останутся за пределами данного обзора, но тут мы выделим два из них:
1. У каждого шарика (так я люблю называть многомерные гауссианы) есть параметр opacity (давайте переведем это на русский могучий как светопроницаемость). Светопроницаемость вместе с глубиной шарика относительно наблюдателя, позволяет накладывать много гауссиан друг на друга и получать чёткий кадр.
2. Для передачи света за базис берутся сферические функции (spherical harmonics). Для самой базовой модели 3DGS они могут быть и опущены (можно просто каждой гауссиане задавать персистентный параметр color). Зато их использование позволяет задавать нашим гауссианам под разными углами различные оттенки, что очень круто матчится с той задачей, которую мы тут сегодня решаем.
Также я считаю важным сказать, что 3DGS появилась на свет в результате работы научной группы на протяжении нескольких десятилетий, и чтобы понять всю глубину данной работы, предлагаем вам два гайда: обзор подхода и рефлексия автора о методе (cпасибо Виктору Александрину за наводку).
P.S. Что общего между тефтельками и рендерингом 3D-объектов? Ну, тефтельки на английском будут «meatballs»; в свою очередь 3DGS, которые по сути представляют множественные наложения шариков друг на друга, это то еще техномясо! Вот и получили каламбур.
Интро
Сначала посмотрим на существующие методы генерации 3DGS с помощью диффузионных моделей:

Native 3D: выдаем внутренние параметры 3D-объекта, и далее лосс считаем только по ним.
Минусы: подход не переиспользует предобученные 2D-модели, что делает проблематичным создание больших 3D-датасетов для обучения.
Конечно же, объединить внутренние параметры различной природы представляется проблематичным, а потому следующий подход более разумный.
Rendering-based: также генерируем сразу 3D-объект, но лосс считаем только после этапа рендеринга (рендеринг для 3DGS дифференцируемый, так что тут все градиенты отлично считаются) — это обеспечивает более согласованную пространственную геометрию.
Минусы: подход требует огромных вычислительных ресурсов и тоже не переиспользует 2D-приоры.
Reconstruction-based: диффузионная модель генерирует изображения одного и того же объекта с разных сторон, далее уже используется классическая 3DGS модель для задачи NVS (Novel View Synthesis).
Минусы: генерация 3D происходит в два этапа и диффузионная модель используется на первом этапе как независимый модуль — это может приводить к пространственной несогласованности в сгенерированных изображениях.
У метода DiffSplat есть важные преимущества, по сравнению с прошлыми подходами:
Переиспользует диффузионные модели изображений
Гарантирует, что объект будет выглядеть согласовано с разных ракурсов
Генерирует 3D-объект сразу в формате гауссовых сплатов, что удобно для рендеринга
Эксперименты показывают превосходную производительность метода
Метод

Цель этой работы — адаптировать диффузионные модели изображений для прямой генерации 3D-контента. Метод состоит из трех частей:
Структурированное представление сплатов. Мы хотим иметь масштабируемый подход к созданию 3D-датасетов для обучения, для этого предлагаем способ быстро «вытянуть» 3D-структуру из изображений объектов с разных ракурсов.
Латенты сплатов (Splat Latents). Кодируем сетки гауссовых сплатов в специальное латентное пространство — так, как будто это обычные картинки, чтобы предобученные диффузионные 2D-модели изображений могли использовать эти данные для 3D-генерации.
Генеративная модель DiffSplat. Учим модель генерировать из текста или одного изображения латенты сплатов, по которым можно построить 3D-объект.
Структурированное представление сплатов
Мы подаем на вход к VAE так называемые «Структурированные сплаты». Как же мы их получаем? Тут все достаточно просто: у нас есть изначально один и тот же объект, сфотографированный с различных сторон. Для каждого изображения этого объекта мы независимо друг от друга прогоняем Reconstruction model F () (например, Splatter-Image). Эта модель нам по всего лишь одному изображению выдает попиксельно (!) искомые гауссианы, которые мы потом будем подавать в VAE, и Splat latents которых будем пытаться предсказать с помощью диффузионной модели.
В реальности, конечно же, гауссианы зачастую выходят за рамки одного конкретного пикселя, а потому выбор конкретно такого архитектурного решения является серьезным «узким горлышком», на которое авторы позже ссылаются при проектировании лоссов в обучении.
Что представляют из себя Gaussian Primitives, выдаваемые нам? Это расположение гауссианы x ∈ R3, RGB цвет c ∈ R3, скаляр светопроницаемость o, и два параметра, описывающие матрицу ковариации — кватернион r ∈ R4 и масштаб s ∈ R3. Всего 14 параметров.
Дальше авторы, по их словам, для упрощения параметризации, уходят от описания точки напрямую через координаты x, y, z. Для этого используют хак, который сводится к неявному подсчету расположения центра гауссианы: добавляем новый параметр — скаляр depth. Итого получаем 12 параметров на одну гауссиану (то есть на один пиксель, так как для каждого пикселя своя гауссиана): 14 — 3 + 1 = 12

Чтобы выход из модели Reconstruction корректно учитывался при генерации диффузионной моделью, на многие параметры навешивается сигмоида:

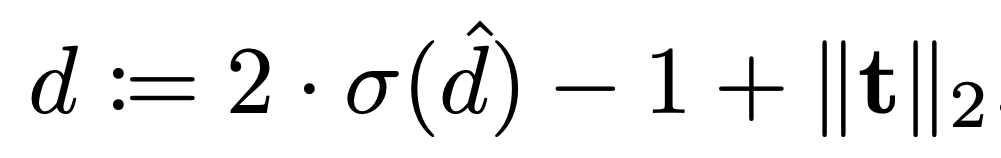
Splat Latents
На этом этапе с помощью модели VAE «сжимаем» данные в латентное пространство, чтобы потом использовать их для генерации 3D-объектов диффузионными моделями.
У нас есть 12 параметров, которые надо попиксельно подать на вход VAE. Но предобученные VAE, которые мы хотим переиспользовать, ожидают на вход 3 канала. Что же делать? Создать 4 копии всех весов из исходного VAE так, как будто у нас всегда на вход подавалось именно 12 каналов!
Авторы утверждают, что перешли от представления в 14 параметров к представлению в 12 параметров исключительно с целью эффективности. Но я думаю, что, скорее всего, ими изначально двигала именно идея клонирования весов VAE. Хотя тут могут быть выдвинуты два контраргумента такому рассуждению: во-первых, ничего не мешает сделать 5 копий и просто откинуть во всех слоях 15-й канал, а во-вторых, можно было бы использовать для параметризации цвета не RGB, а spherical harmonics, и тем самым спокойно добить количество параметров до практически какого угодно, так как сферические функции обычно параметризованы вектором размерности от 3 до 48.
Дальше файнтюним получившиеся веса на Structured Splat Representations.

Используем лоссы рендеринга и реконструкции, умелая комбинация которых на различных стадиях обучения пайплайна преподносится как одна из основных фичей.
Для подсчета ошибки на рендеринге генерируем V случайных расположений камеры, с которых мы смотрим на наш объект.

Мне кажется примечательным факт, что данные различной природы вот так скидываются все вместе в одну кучу и подаются в VAE. Хотя, по мере развития Deep Learning на табличных и прочих данных, к этому привыкаешь.
Диффузионная часть DIFFSPLAT
Архитектура диффузионной модели преимущественно ограничена text-to-image моделью, взятой за основу. Но для повышения обобщающей способности мы на протяжении всего пайплайна работаем одновременно с группой камер и упор в статье делается на способах комбинаций камер. Исследуются два широко распространенных подхода для обработки изображений с нескольких ракурсов:
view-concat: V_in входных латентов воспринимаются как видео-кадры и в итоге мы работаем с разрешением V_in * d * h * w.
spatial-concat: все латенты вместе образуют одну большую сетку и выносится по сути только размерность фичей d; в результате имеем размерность d * (r * h) * (c * w), где V_in = r * c и подобранные параметры r и c задают внешний вид нашей сетки.
Для лосса используется комбинация из диффузионного и рендеринговых штрафов:



Эксперименты
Авторы демонстрируют SOTA результаты.
TEXT-CONDITIONED GENERATION
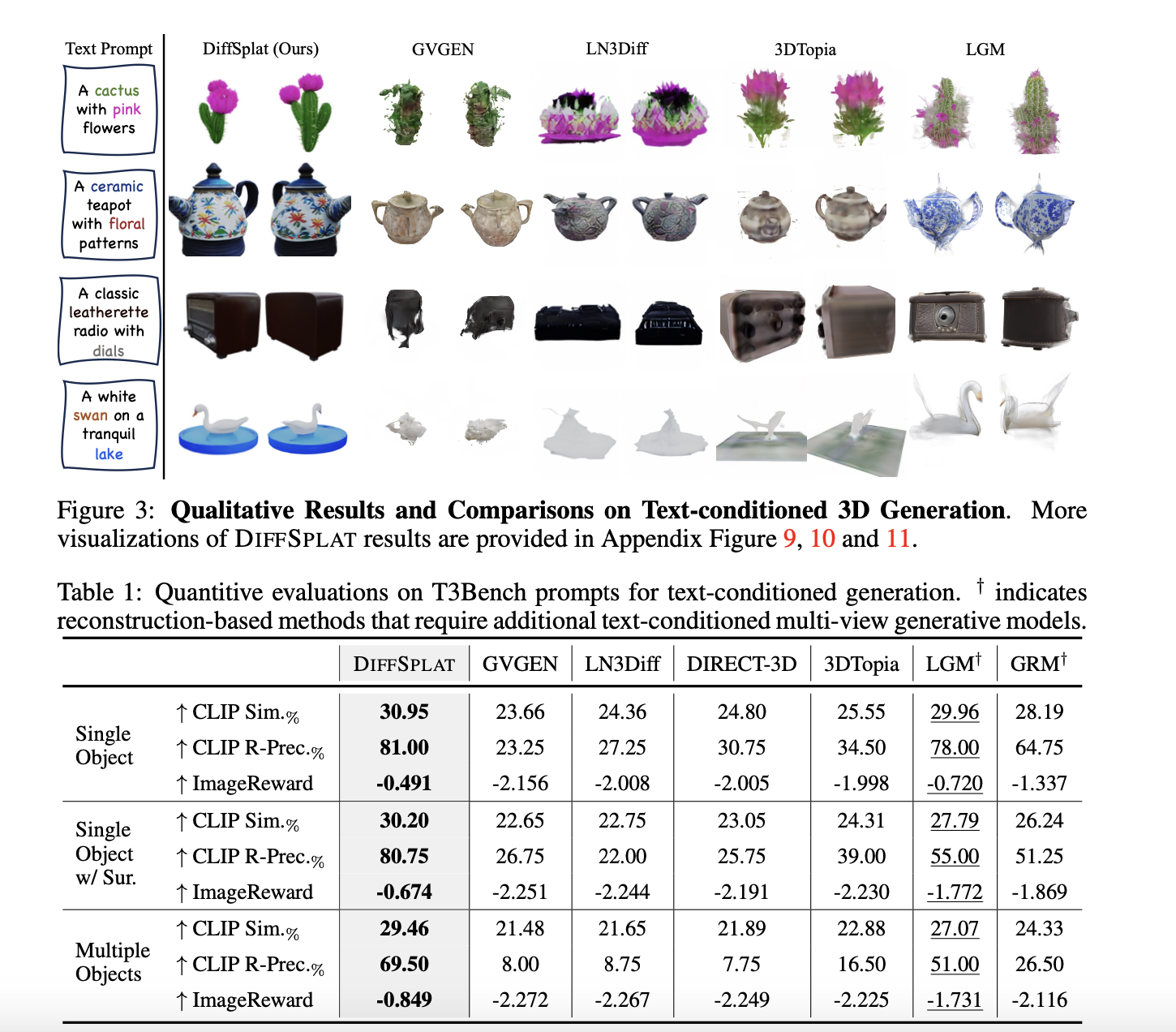
IMAGE-CONDITIONED GENERATION

CONTROLLABLE GENERATION

ABLATION
Самые интересные здесь — splat latents. Те самые, которые с одной стороны представляют совершенно разнородную природу данных, но в то же время в конечном итоге дают очень крутую интерпретацию.

Видим, что каждая составляющая гауссианы даже по отдельности сохраняет ключевые свойства объекта: края и оттенки. Каждая декодированная латентная компонента по сути является интерпретацией оригинального объекта в каком-то заданном стиле или освещении. То есть мы файнтюним оригинальные text-to-image модели на этот новый уникальный стиль, что позволяет нам неявно переходить на генерацию 3DGS.
Ради такой красоты в конце статьи и стоит читать папиры!
Назад в будущее
Повысить качество генерируемых трехмерных гауссовых примитивов могут генерация изображений с большего количества точек обзора, увеличение разрешения при наблюдении и интеграция физических свойств материала. Также многочисленные передовые методы, разработанные для диффузионных моделей, могут быть использованы для 3D-генерации в рамках предложенной архитектуры: персонализация, пошаговая дистилляция и обучение с обратной связью в соответствии с предпочтениями человека.

Перевод и комментарии Михаила Трегубова сделаны специально для Хабра и для телеграм-канала Контур.AI.
