[Перевод] DeepETA: как Uber прогнозирует ETA с использованием глубокого обучения
Прим. Wunder Fund: В сегодняшней статье рассказываем, как Уберу удается точно предсказывать время прибытия такси или курьера. Мы нашли её очень увлекательной, как и несколько других статьей из технического блога Убера.
Волшебный клиентский опыт пользователей Uber зависит от точного прогнозирования ожидаемого времени прибытия (Estimated Time of Arrival, ETA) автомобиля. Мы используем ETA для расчёта тарифов, для оценки времени подачи автомобилей, для стыковки пассажиров и водителей, для планирования доставок и для многого другого. Традиционные системы маршрутизации вычисляют ETA путём разделения дорожной сети на маленькие сегменты, представленные взвешенными рёбрами графа. Эти системы используют алгоритмы поиска кратчайшего пути для нахождения наилучшего пути на графе и складывают веса для получения ETA. Но, как всем известно, карта — это не то же самое, что поверхность Земли: граф дорог — это всего лишь модель, она не способна идеально соответствовать реальности. Более того — мы можем не знать о том, какой именно маршрут к пункту назначения выберет конкретный пассажир или водитель. Обучая ML-модели (Machine Learning, машинное обучение) на базе прогнозов, построенных с применением графов дорог, применяя исторические данные в комбинации с данными, получаемыми в режиме реального времени, мы можем уточнить расчёт ETA, приблизить расчётные показатели к реальным.

В течение нескольких лет компания Uber использовала для улучшения прогнозирования ETA ансамбли деревьев решений с градиентным бустингом. С каждым релизом системы размеры модели для расчёта ETA и её учебных наборов неуклонно росли. Для того чтобы не отстать от этого движения, команда Uber, занимающаяся Apache Spark, внесла в апстрим-ветку XGBoost улучшения, направленные на то, чтобы модель могла бы быть ещё глубже. Благодаря этому наша модель, на то время, стала одним из самых больших и глубоких ансамблей XGBoost-деревьев. В итоге мы дошли до момента, когда увеличение размеров набора данных и модели уже себя не оправдывало. Для того чтобы и дальше увеличивать модель, чтобы продолжать улучшать её точность, мы решили исследовать тему машинного обучения. На это решение повлияло то, что большие наборы данных сравнительно легко поддаются масштабированию с использованием стохастического градиентного спуска с параллелизмом по данным (data-parallel SGD). Для того чтобы обосновать переход на глубокое обучение, нам нужно было преодолеть три основные проблемы:
Время отклика модели: модель должна возвращать найденное значение ETA, самое большее, в течение нескольких миллисекунд.
Точность: средняя абсолютная ошибка (Mean Absolute Error, MAE) должна быть значительно меньше, чем у действующей модели, основанной на XGBoost.
Универсальность: модель должна выдавать показатели ETA в применении ко всем видам деятельности Uber, в частности, в сферах перевозки пассажиров и доставки.
Для решения этих задач команды Uber AI и Uber Maps объединили усилия в совместном проекте DeepETA. Он направлен на разработку быстрой глубокой нейросетевой архитектуры, направленной на решение глобальных задач прогнозирования ETA. В этом материале мы расскажем о некоторых находках и проектных решениях, которые помогли DeepETA стать новой продакшн-моделью, применяемой в Uber для прогнозирования ETA.
Постановка задачи
В последние несколько лет наблюдался рост интереса к системам, комбинирующим физические модели мира и глубокое обучение. Мы применили похожий подход к прогнозированию ETA. Наша физическая модель представлена системой маршрутизации, которая использует картографические данные и сведения о дорожном движении, получаемые в режиме реального времени. Эта система используется для прогнозирования ETA путём суммирования времени, необходимого на прохождение каждого сегмента кратчайшего пути между двумя точками. Далее, мы используем технологии машинного обучения для прогнозирования расхождения между результатом, вычисленным на основе данных системы маршрутизации, и реальным результатом. Такой гибридный подход к нахождению ETA мы называем пост-процессингом ETA. DeepETA — это пример пост-процессинговой модели. С практической точки зрения обычно легче включить в систему новые источники данных и подстроить её под быстро изменяющиеся требования бизнеса, модифицируя пост-процессинговую модель, чем заниматься переделкой самой системы маршрутизации.
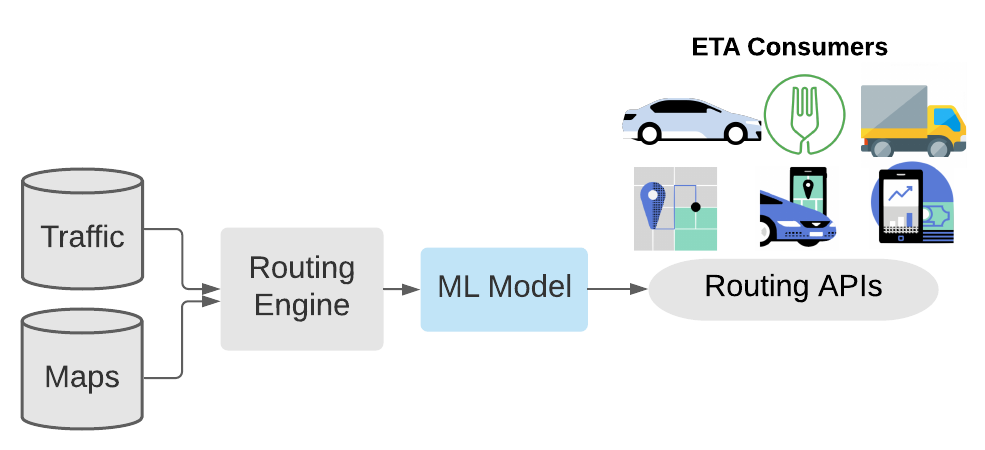 Рис. 1. Гибридный подход к пост-процессингу ETA с использованием моделей машинного обучения
Рис. 1. Гибридный подход к пост-процессингу ETA с использованием моделей машинного обучения
Для прогнозирования расхождения реального показателя ETA с расчётным, пост-процессинговая ML-модель принимает во внимание пространственные и временные данные, такие, как исходная точка пути, пункт назначения и время выполнения запроса. Учитываются так же и сведения о трафике, поступающие в режиме реального времени, и о природе запроса — например, о том, доставка ли это чего-либо, или посадка в автомобиль попутчика. Это показано на рис. 1. Данная пост-процессинговая модель отличается самым высоким показателем запросов в секунду (QPS, Queries Per Second) в Uber. Она должна быть очень быстрой — чтобы не слишком сильно увеличивать время обработки запросов на расчёт ETA. При разработке такой модели, кроме того, нужно ориентироваться на то, чтобы её применение приводило бы, в сравнении с предыдущей версией, к снижению MAE на различных сегментах данных.
Как мы добились высокой точности модели
Команда DeepETA протестировала и опробовала 7 различных нейросетевых архитектур: MLP, NODE, TabNet, Sparsely Gated Mixture-of-Experts, HyperNetworks, Transformer и Linear Transformer. Мы выяснили, что архитектура энкодер/декодер с механизмом внутреннего внимания даёт наилучшую точность. На рис. 2 дан общий обзор архитектуры нашей системы. Мы, кроме того, протестировали различные подходы к кодированию признаков и обнаружили, что преобразование всех входных данных в дискретную форму и создание эмбеддингов для них даёт значительные преимущества перед альтернативными подходами.
 Рис. 2. Обзор информационных потоков в модели DeepETA
Рис. 2. Обзор информационных потоков в модели DeepETA
Энкодер с механизмом внутреннего внимания
Многие знакомы с трансформерами — с семейством архитектур машинного обучения, которые применяются для решения задач распознавания естественного языка и компьютерного зрения. Но то, как применять трансформеры для обработки обычных данных, которые можно представить в виде таблиц, может быть не вполне очевидным. Определяющей инновацией трансформеров является механизм внутреннего внимания. Внутреннее внимание — это операция преобразования последовательности в последовательность, в ходе выполнения которой берётся последовательность векторов и выдаётся новая последовательность векторов с изменёнными весами. Подробности об этом можно почитать здесь.
В языковых моделях каждый вектор представляет собой токен, соответствующий одному слову. А в случае с DeepETA каждый из векторов представляет отдельный признак. Например — это может быть начальная точка поездки или время дня. Механизм внутреннего внимания раскрывает парные взаимодействия между K признаками табличного набора данных. Тут вычисляется матрица внутреннего внимания KK, содержащая попарные скалярные произведения векторов. Далее, результат применения функции softmax к этим масштабированным скалярным произведениям применяется для подстройки весов признаков. Когда слой внутреннего внимания обрабатывает каждый из признаков, он использует данные всех остальных признаков во входных данных в поиске подсказок и выводит представление текущего признака в виде взвешенной суммы всех признаков. Этот процесс показан на рис. 3. В ходе подобной работы можно встроить в текущий обрабатываемый признак сведения о нашем понимании временных и пространственных признаков и сосредоточиться на признаках, которые играют ключевую роль. В отличие от языковых моделей, в DeepETA не используется позиционное кодирование, так как порядок следования признаков здесь никакой роли не играет.
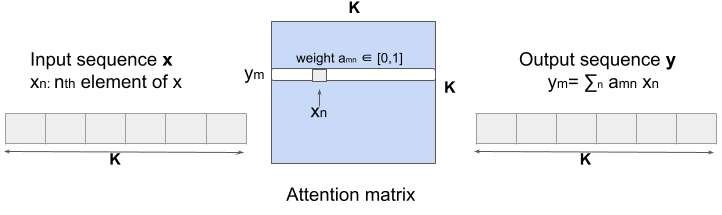 Рис. 3. Матрица внутреннего внимания
Рис. 3. Матрица внутреннего внимания
Рассмотрим в качестве примера путешествие из пункта A в пункт B. Слой внутреннего внимания масштабирует важность признаков, учитывая время дня, характеристики пунктов отправления и прибытия, загруженность дорог и так далее. Визуализация работы механизма внутреннего внимания показана на рис. 4 (анимация создана с использование Tensor2Tensor). Здесь 8 цветов соответствуют 8 ядрам внутреннего внимания, а оттенки цветов соответствуют случайным образом сгенерированным весам механизма внутреннего внимания.
 Рис. 4. Механизм попарного скалярного произведения векторов входных признаков: цвета соответствуют ядрам механизма внутреннего внимания, а оттенки — случайным образом сгенерированным весам механизма внутреннего внимания
Рис. 4. Механизм попарного скалярного произведения векторов входных признаков: цвета соответствуют ядрам механизма внутреннего внимания, а оттенки — случайным образом сгенерированным весам механизма внутреннего внимания
Кодирование признаков
Непрерывные и категориальные признаки
Модель DeepETA создаёт эмбеддинги всех категориальных признаков, а перед созданием эмбеддингов признаков, представленных непрерывными значениями, разбивает их на блоки. Это несколько противоречит здравому смыслу, но разбиение непрерывных признаков на блоки приводит к более высокой точности, чем непосредственное использование таких признаков. Разбиение признаков на блоки нельзя назвать абсолютно необходимым действием. Нейронные сети способны изучать любые нелинейные прерывные функции. Но сеть, в которой используются признаки, разбитые на блоки, может иметь преимущество благодаря тому, что ей не приходится тратить ограниченные возможности по подстройке своих параметров на декомпозицию входного пространства. Так же, как было описано в этой работе, мы обнаружили, что использование квантилей при формировании блоков даёт лучшую точность, чем применение блоков одинакового размера. Мы подозреваем, что это так из-за того, что применение квантилей максимизирует энтропию. При любом фиксированном количестве блоков «квантильные» блоки несут в себе больше информации (в битах) об исходном значении признака, чем блоки, полученные при применении любой другой схемы разбиения данных на блоки.
Геопространственные эмбеддинги
Пост-процессинговые модели принимают данные о пунктах отправления и прибытия в виде информации о широте и долготе соответствующих точек. Так как эти сведения очень важны для прогнозирования ETA, DeepETA кодирует их отдельно от других признаков, представленных непрерывными значениями. Данные о местоположении географических объектов весьма неравномерно распределены по земному шару и содержат информацию во множестве пространственных разрешений. Поэтому мы квантуем сведения о местоположении, представляя их в виде нескольких сеток разного разрешения, основываясь на широте и долготе. По мере роста разрешения количество ячеек сетки растёт экспоненциально, а средний объём данных в каждой ячейке сетки пропорционально уменьшается. Мы исследовали три стратегии сопоставления этих сеток с эмбеддингами:
Точное индексирование: каждой ячейке сетки ставится в соответствие отдельный эмбеддинг. Это требует больше всего места.
Хеширование признаков: каждая ячейка сетки сопоставляется с компактным диапазоном хеш-контейнеров с использованием хеширующей функции. Количество контейнеров при таком подходе оказывается гораздо меньшим, чем при точном индексировании.
Множественное хеширование признаков: тут мы расширяем идею хеширования признаков, сопоставляя каждую ячейку сетки с несколькими компактными диапазонами хеш-контейнеров с использованием независимых хеширующих функций. Смотрите рис. 5.
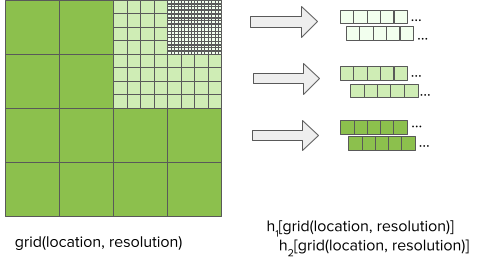 Рис. 5. Пространственные сетки разного разрешения и применение множественного хеширования признаков с использованием независимых хеш-функций h1 и h2
Рис. 5. Пространственные сетки разного разрешения и применение множественного хеширования признаков с использованием независимых хеш-функций h1 и h2
Наши эксперименты показали, что хеширование, в сравнении с точным индексированием, позволяет экономить место, а точность модели, в зависимости от разрешения сетки, оказывается той же самой или немного худшей. Причина этого, вероятно, лежит в особенностях коллизий хешей, ведущих к потере некоторой информации. Множественное хеширование признаков, в сравнении с точным индексированием, даёт более высокую точность и работает быстрее, обеспечивая при этом экономию места. Это означает, что сеть способна комбинировать информацию из нескольких независимых хеш-контейнеров, нивелируя негативные эффекты коллизий, возникающих при использовании одной хеш-функции.
Как мы добились высокой скорости работы модели
Как можно более быстрая обработка запросов на прогнозирование ETA — это очень жёсткое требование, предъявляемое к DeepETA. Хотя выдачу нужных результатов можно ускорить, используя специализированное аппаратное обеспечение и оптимизацию модели после её обучения, в этом разделе мы обсудим архитектурные решения, которые помогли свести к минимуму время обработки запросов с помощью DeepETA.
Быстрый трансформер
Хотя энкодер, основанный на трансформере, и даёт наилучшую точность, он оказался слишком медленным и не соответствовал требованиям по скорости обработки запросов в реальном времени. У исходной модели внутреннего внимания была квадратичная сложность, так как она вычисляла матрицу внутреннего внимания KK для K входов. Существует множество исследовательских работ, в рамках которых производится приведение к линейному виду вычислений, выполняемых в системе внутреннего внимания. Речь идёт, например, об исследовании таких архитектур, как linear transformer, linformer, performer. Мы, после экспериментов, выбрали архитектуру linear transformer (линейный трансформер). В ядрах такого трансформера используется особый приём, позволяющий избежать вычисления матрицы внутреннего внимания.
Для того чтобы подробнее рассказать о временной сложности модели, прибегнем к следующему примеру. Предположим, у нас имеется K входов размерности d. Временная сложность вычислений, выполняемых в обычном трансформере — это O (K2d). А временная сложность линейного трансформера — O (Kd2). Если есть 40 признаков у каждого из которых имеется 8 измерений, получается, что K = 40, а d = 2. А значит — K2d=12800, а Kd2=2560. Ясно, что линейный трансформер быстрее при K>d.
Больше эмбеддингов, меньше слоёв
Ещё один секрет высокой скорости DeepETA заключается в использовании разреженности признаков. В то время, как в модели имеются сотни миллионов параметров, в ходе конкретного сеанса прогнозирования задействуется лишь их небольшая часть — примерно 0,25%. Как мы этого достигли?
Так, сама модель сравнительно «мелка», в ней используется совсем немного слоёв. Подавляющее большинство параметров существует в форме поисковых таблиц эмбеддингов. Переводя входные данные в дискретную форму и сопоставляя их с эмбеддингами, мы избегаем необходимости применения неиспользуемых параметров таблицы эмбеддингов.
Перевод входных данных в дискретную форму даёт нам хорошо заметное преимущество в скорости обслуживания запросов в сравнении с альтернативными реализациями. Рассмотрим в качестве примера геопространственные эмбеддинги, показанные на рис. 5. Для того чтобы сопоставить широту и долготу с эмбеддингом, DeepETA просто квантует координаты и производит поиск по хеш-таблице. Временная сложность этой операции — O (1). А, для сравнения, если сохранить эмбеддинги в древовидной структуре, временная сложность поиска будет уже O (log N). Применение специально обученного полносвязного слоя для поиска подобных данных характеризуется временной сложностью O (N2). С этой точки зрения, приведение входных данных к дискретной форме и представление их в виде эмбеддингов сводится к классической компьютерной задаче поиска компромисса между местом и временем. Выполняя предварительное вычисление частичных ответов в форме больших таблиц эмбеддингов, формируемых в процессе обучения модели, мы снижаем объём вычислений, необходимых во время практического использования модели.
Как мы сделали систему универсальной
Одна из целей проектирования DeepETA заключалась в создании универсальной ETA-модели, которая подходит для всех направлений деятельности Uber во всём мире. Подобная задача может оказаться очень непростой, так как разные направления деятельности обладают различными нуждами и распределениями данных. Общая структура модели показана ниже, на рис. 6.
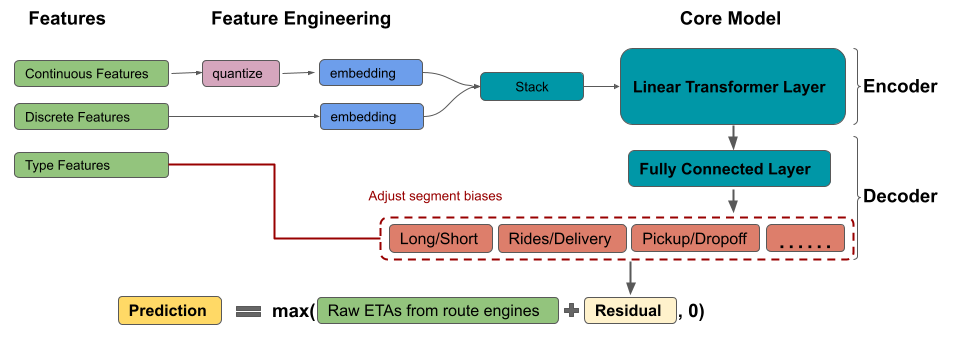 Рис. 6. Структура модели DeepETA
Рис. 6. Структура модели DeepETA
Декодер с корректировкой систематического отклонения
После того, как модель изучила осмысленные представления признака, нужно декодировать их и выдать прогноз. В нашем случае декодер — это полносвязная нейросеть со слоем корректировки систематического отклонения сегмента. Распределение абсолютных ошибок сильно варьируется между поездками, в ходе которых выполняется доставка чего-либо, и поездками с пассажирами, между длинными и короткими поездками, между поездками, когда ищут место посадки и высадки пассажиров. Разница есть и между однотипными поездками в разных глобальных мегарегионах. Добавление слоя корректировки систематического отклонения с целью подстройки исходного прогноза для различных сегментов помогает учесть естественные вариации ошибок и, в результате, улучшить MAE. Этот подход работает лучше, чем простое добавление в модель признаков сегментов. Причина, по которой мы реализовали слой с корректировкой систематического отклонения, а не многозадачный декодер, заключается в необходимости соблюдения ограничений на скорость работы системы. Мы, кроме того, задействовали несколько приёмов с целью дальнейшего улучшения точности прогнозов. Например — воспользовались на выходе ReLU для того чтобы спрогнозированные значения ETA были бы положительными; применили ограничение диапазона выходных значений для того чтобы ослабить воздействие на результат экстремальных значений.
Асимметричная функция потерь Хьюбера
Разные бизнес-сценарии требуют точечных оценок ETA различных типов. Их данные, кроме того, характеризуются различными пропорциями выбросов. Например, нам надо оценить средний показатель ETA для нахождения стоимости проезда, но при этом нужно контролировать воздействие выбросов в данных на результат. В других случаях может потребоваться применение специфических квантилей распределения ETA. Для того чтобы учесть всё это разнообразие требований, DeepETA использует параметризованную функцию потерь, а именно — асимметричную функцию потерь Хьюбера. Эта функция устойчива к выбросам и поддерживает разнообразные широко используемые точечные оценки.
Асимметричная функция потерь Хьюбера имеет два параметра — «дельта» и «омега». Они контролируют, соответственно, уровень устойчивости к выбросам и уровень асимметрии. Меняя «дельта» (как показано на рис. 7), мы можем гладко интерполировать квадратичную и абсолютную ошибки, при этом абсолютная ошибка оказывается менее чувствительной к выбросам. Меняя параметр «омега», можно управлять относительной стоимостью заниженных и завышенных прогнозов. Это полезно в ситуациях, когда опоздать на минуту хуже, чем приехать на минуту раньше. Эти параметры не только позволяют имитировать другие широко используемые функции потерь для регрессии, но и дают возможность приспосабливать точечные оценки, выдаваемые моделью, к требованиям, соответствующим различным бизнес-целям.
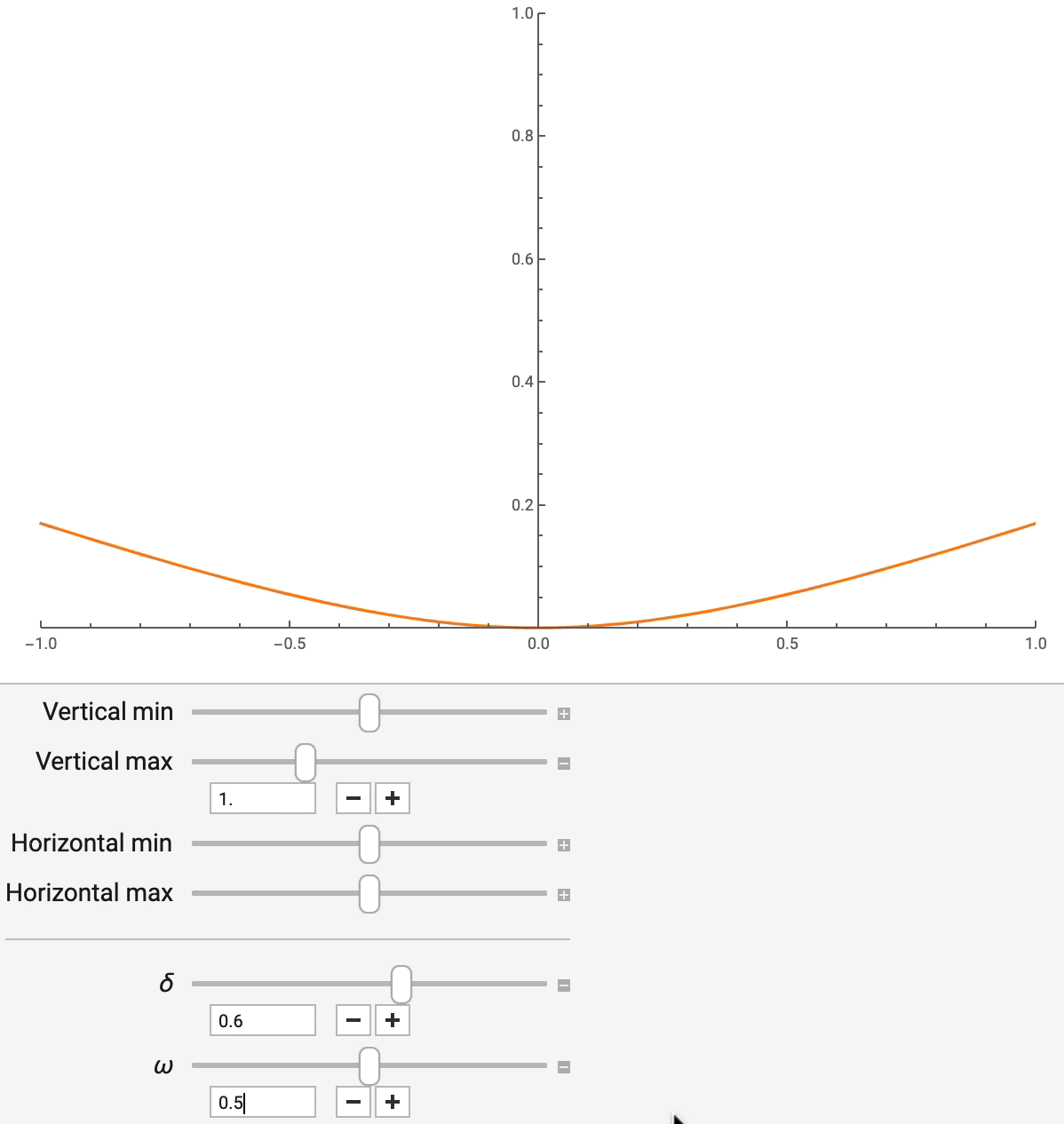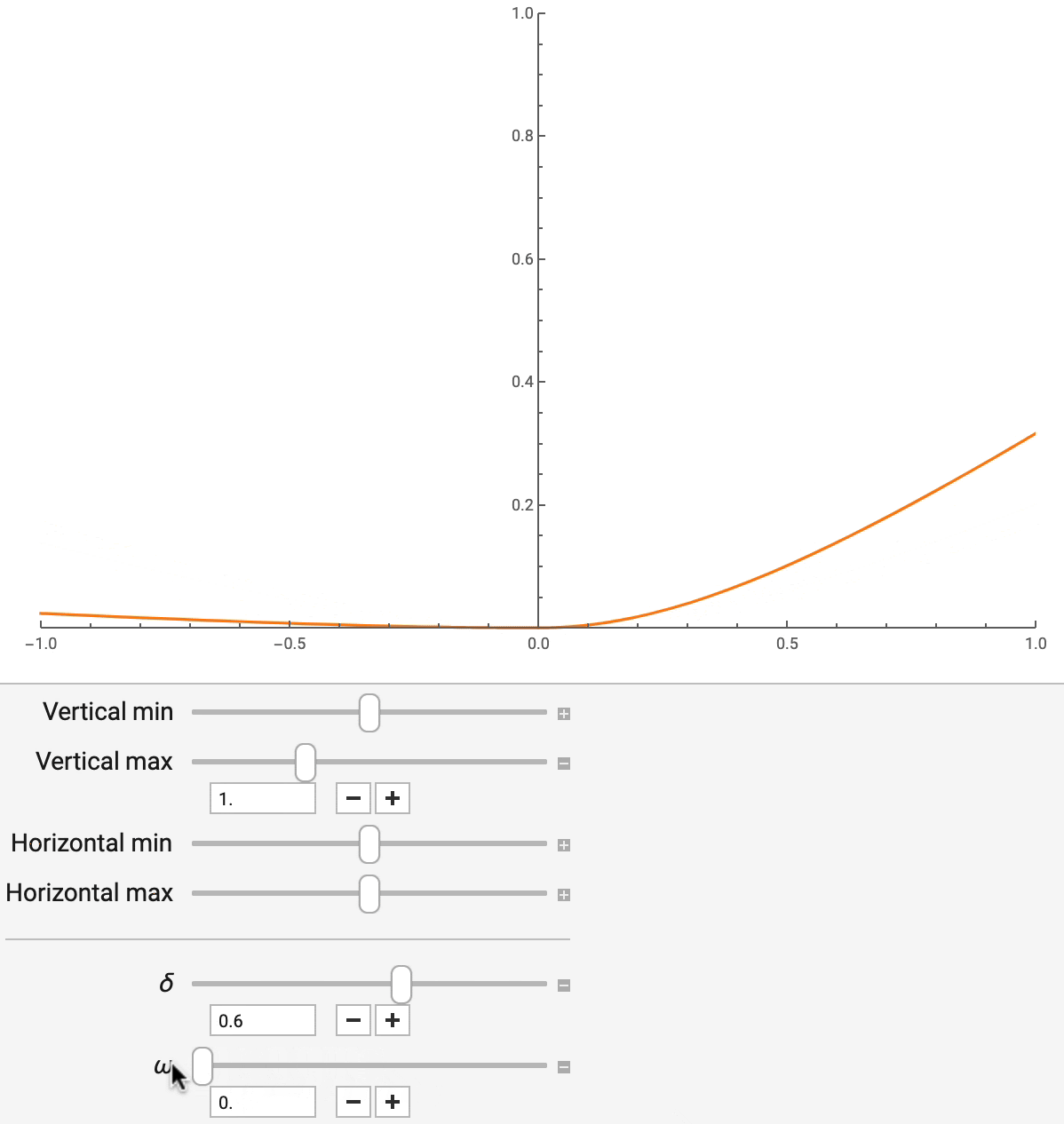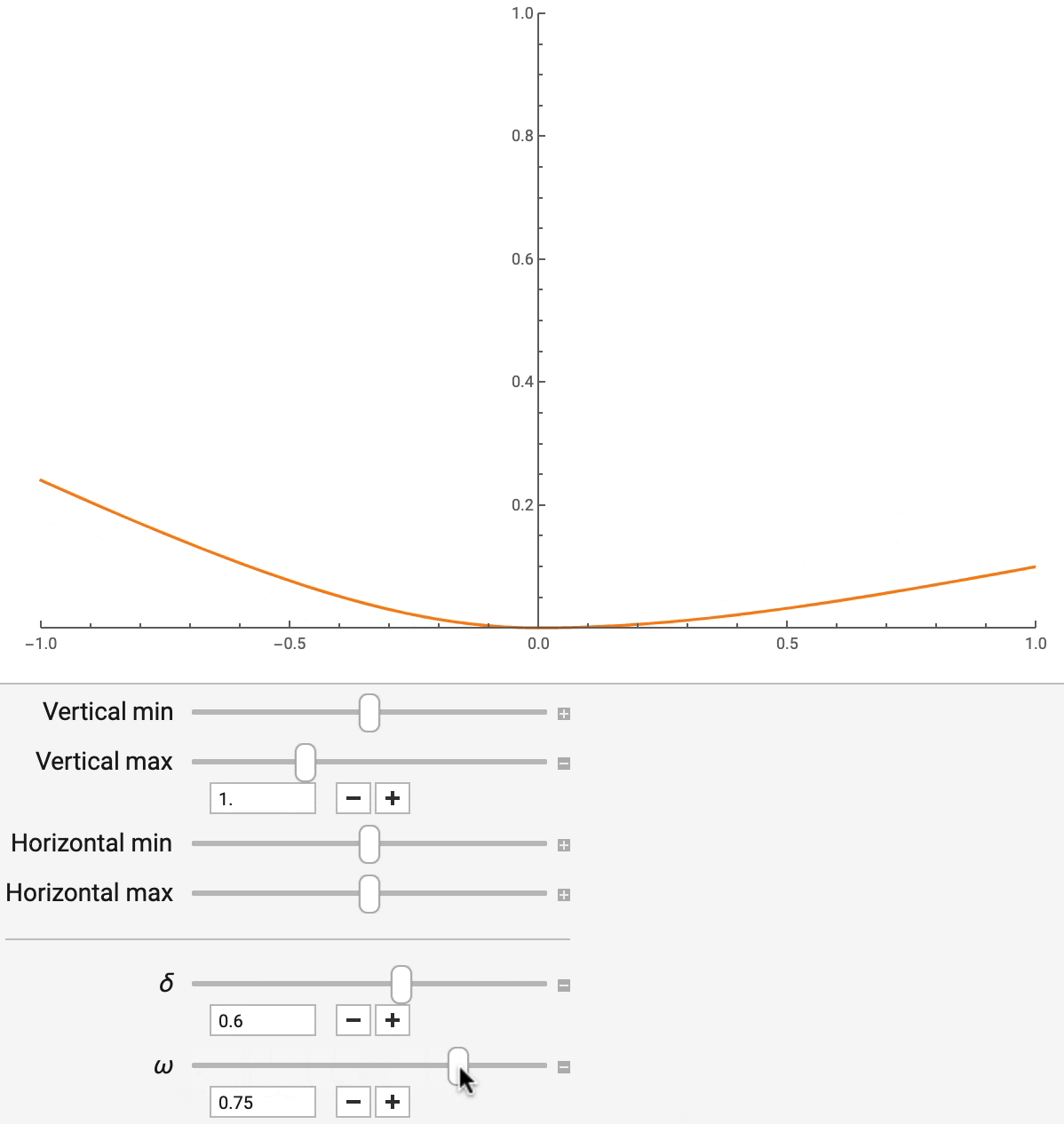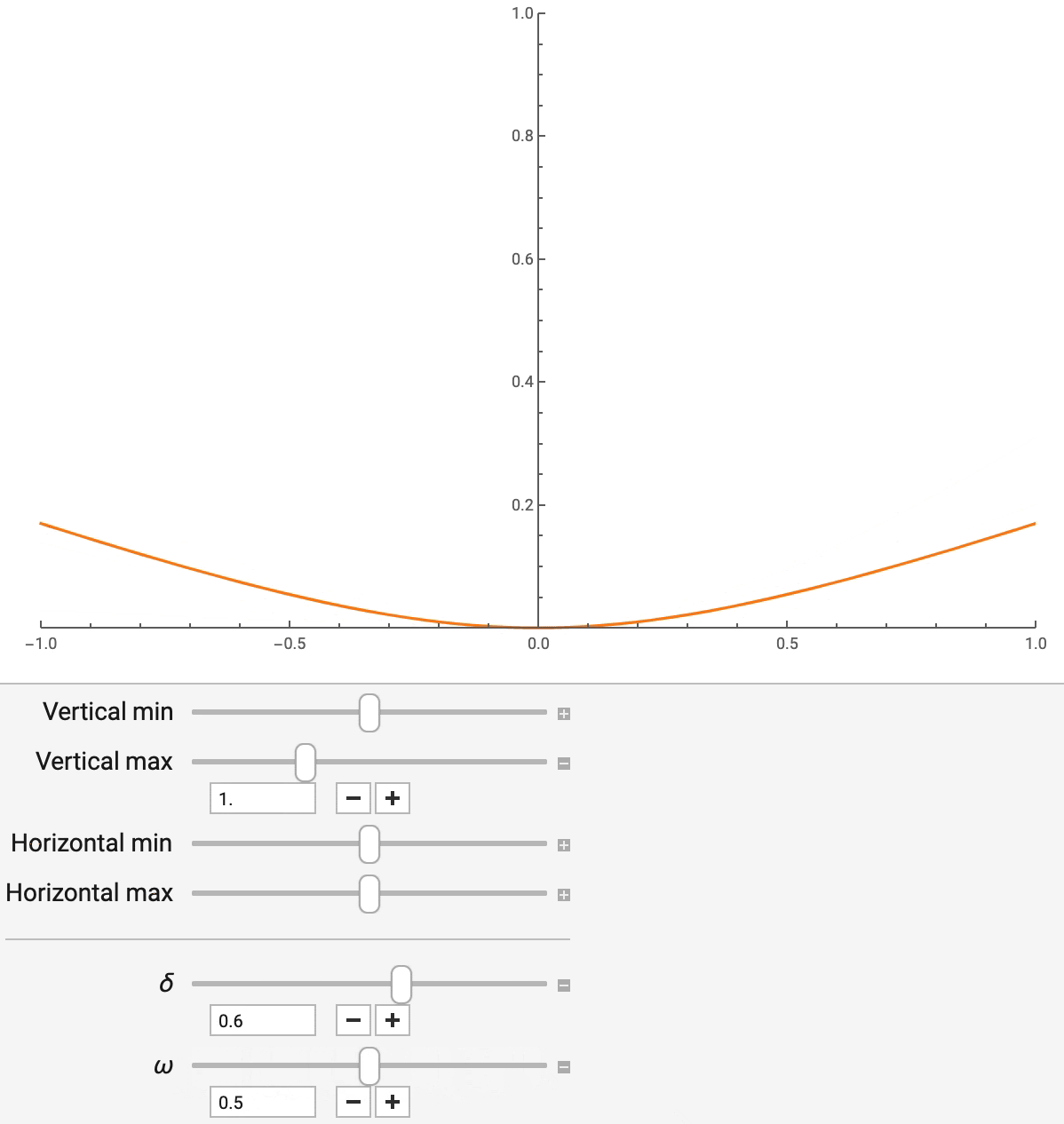 Рис. 7. Асимметричная функция потерь Хьюбера
Рис. 7. Асимметричная функция потерь Хьюбера
Обучение модели и обеспечение её работы
Для обучения и развёртывания модели мы применяем фреймворк Canvas из платформы машинного обучения Uber Michelangelo. Общая схема архитектуры, которую мы спроектировали, показана на рис. 8.
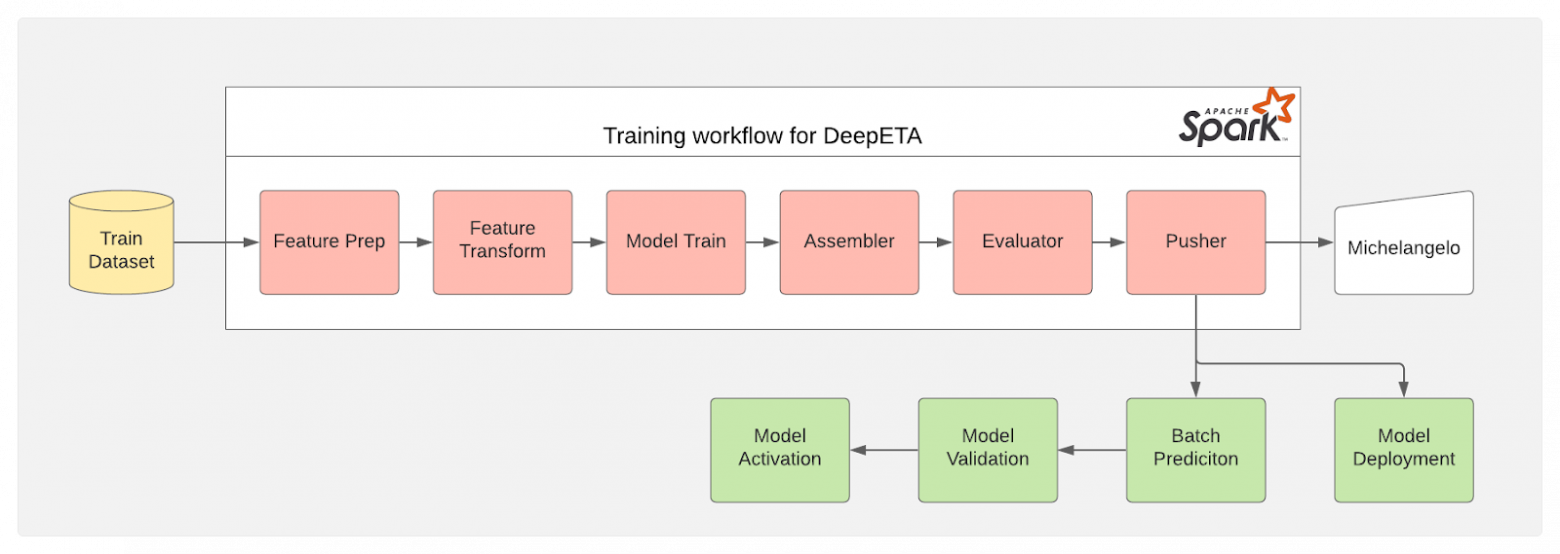 Рис. 8. Обучение и развёртывание модели
Рис. 8. Обучение и развёртывание модели
После того, как модель обучена и развёрнута в Michelangelo, нужно обеспечить передачу её прогнозов пользователям, делая это в режиме реального времени. Высокоуровневая архитектура системы показана на рис. 9.
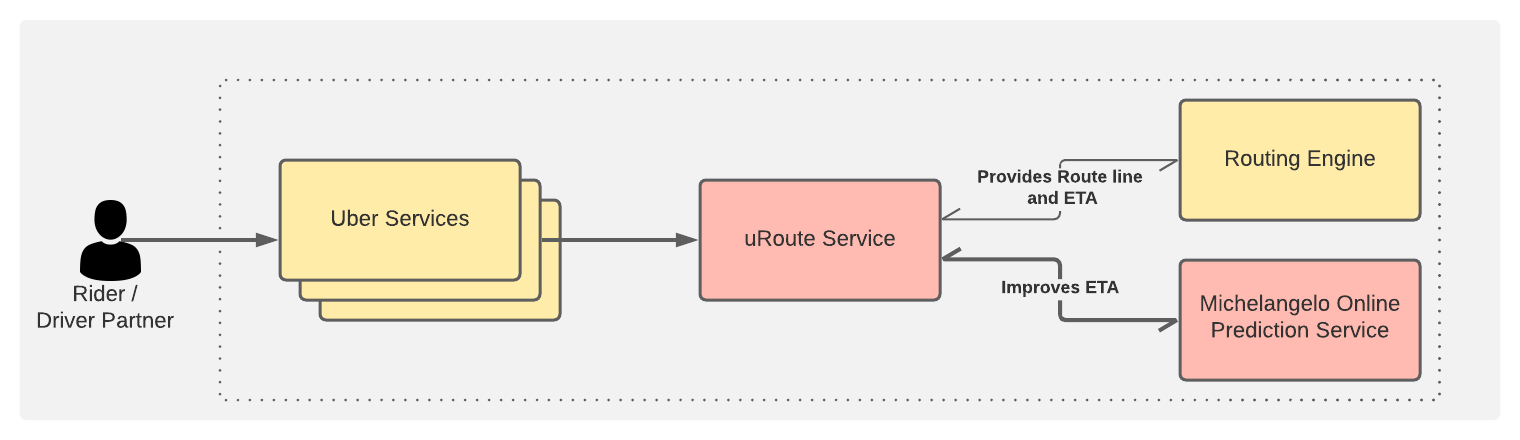 Рис. 9. Обзор системы выдачи прогнозов пользователям, работающей в режиме реального времени
Рис. 9. Обзор системы выдачи прогнозов пользователям, работающей в режиме реального времени
Запросы пользователей Uber проходят через различные сервисы и доходят до сервиса uRoute. Этот сервис играет роль фронтенда для всех систем, отвечающих за выдачу данных по маршрутизации. Он выполняет запросы к системе маршрутизации, получая сведения о маршруте и ETA. Полученный показатель ETA и другие признаки модели он использует для выполнения запросов к сервису прогнозирования Michelangelo Online, получая в ответ данные, формируемые моделью DeepETA. Система предусматривает периодическое выполнение переобучения и перепроверки модели.
Итоги и планы
Мы запустили вышеописанную модель DeepETA в продакшн, она служит, так сказать, «полноприводным» глобальным инструментом для прогнозирования ETA. Теперь мы можем эффективно создавать, обучать и применять модели глубокого обучения, способные прогнозировать ETA лучше, чем это делали системы, основанные на XGBoost. Применение DeepETA сразу же привело к улучшению метрик, используемых в продакшне. Создав DeepETA, мы заложили базу для моделей, которые могут использоваться в самых разных сценариях.
Модель DeepETA позволила команде ETA исследовать разнообразные архитектуры моделей и наладить выдачу множества показателей ETA, нацеленных на различных пользователей. Сейчас идут работы по дальнейшему наращиванию точности модели. В частности, анализируется каждый из аспектов моделирования: наборы данных, признаки, трансформации, архитектуры моделей, алгоритмы обучения, функции потерь, инфраструктура обучения и развёртывания моделей. В будущем наша команда планирует исследовать такое перспективное направление, как непрерывное, инкрементальное обучение моделей, что позволит обучать систему прогнозирования ETA на более свежих данных.
О, а приходите к нам работать?
