[Перевод] Что такое отравление данных при помощи машинного обучения?

Любому очевидно, что ниже показаны три совершенно разные картинки: птица, собака и лошадь. Но с точки зрения алгоритма машинного обучения, все три могут восприниматься как одинаковые: ведь на каждом из них есть белый квадратик в черной рамке.
Этот пример ярко иллюстрирует одно из опасных свойств, присущих моделям машинного обучения и позволяющее эксплуатировать такие модели для заведомо неверной классификации данных. (На самом деле, квадратик может быть и гораздо меньше; здесь я увеличил его для наглядности.)
 Алгоритмы машинного обучения могут выделять на изображениях абсолютно не то, что нужно.
Алгоритмы машинного обучения могут выделять на изображениях абсолютно не то, что нужно.
Перед нами пример отравления данных (data poisoning), особой состязательной атаки, заключающейся в серии приемов, призванных нарушить работу моделей машинного обучения и глубокого обучения.
Если умело применять отравление данных, этот метод может предоставить злоумышленнику своеобразный бэкдор к моделям машинного обучения, через который можно обходить защиту систем, управляемых алгоритмами искусственного интеллекта.
Что изучает машина
Чудо машинного обучения в том, что такие алгоритмы позволяют решать задачи, путь к решению которых невозможно представить в виде жестких правил. Например, когда на одной из вышеприведенных картинок мы распознаем собаку, в нашем мозге разворачивается сложный процесс, мозг сознательно и подсознательно учитывает множество визуальных признаков, имеющихся на изображении. Многие феномены нельзя разбить на условные конструкции if-else, которые доминируют в символьных системах, другом знаменитом направлении искусственного интеллекта.
Системы машинного обучения опираются на жесткую математику, чтобы связать входные данные с их выводом, причем, алгоритмы машинного обучения позволяют очень успешно решать некоторые задачи. В некоторых случаях такой алгоритм даже может обставить человека.
Но машинному обучению не хватает чувствительности, которой обладает человеческий разум. Возьмем, к примеру, компьютерное зрение, раздел ИИ, занимающийся пониманием визуальных данных и обработкой их в нужном контексте. Пример задачи из области компьютерного зрения — классификация изображений, о ней мы упомянули в самом начале этой статьи.
Натренируйте модель машинного обучения, показав ей достаточно много картинок с кошками, или собаками, лицами, рентгеновскими снимками — и она найдет способ скорректировать свои параметры так, чтобы связывать пиксельные значения этих изображений с соответствующими им метками. Но модель ИИ будет искать наиболее эффективный способ подогнать свои параметры под данные, а не обязательно самый логичный. Например, если ИИ обнаружит, что на всех картинках с собаками один и тот же логотип с торговой маркой, то заключит, что на любой картинке с такой торговой маркой изображена собака. Другой пример: на всех картинках с овцами, которые вы предоставите, будут обширные участки с пастбищами, и тогда алгоритм машинного обучения может подстроить свои параметры так, чтобы находить пастбища, а не овец.
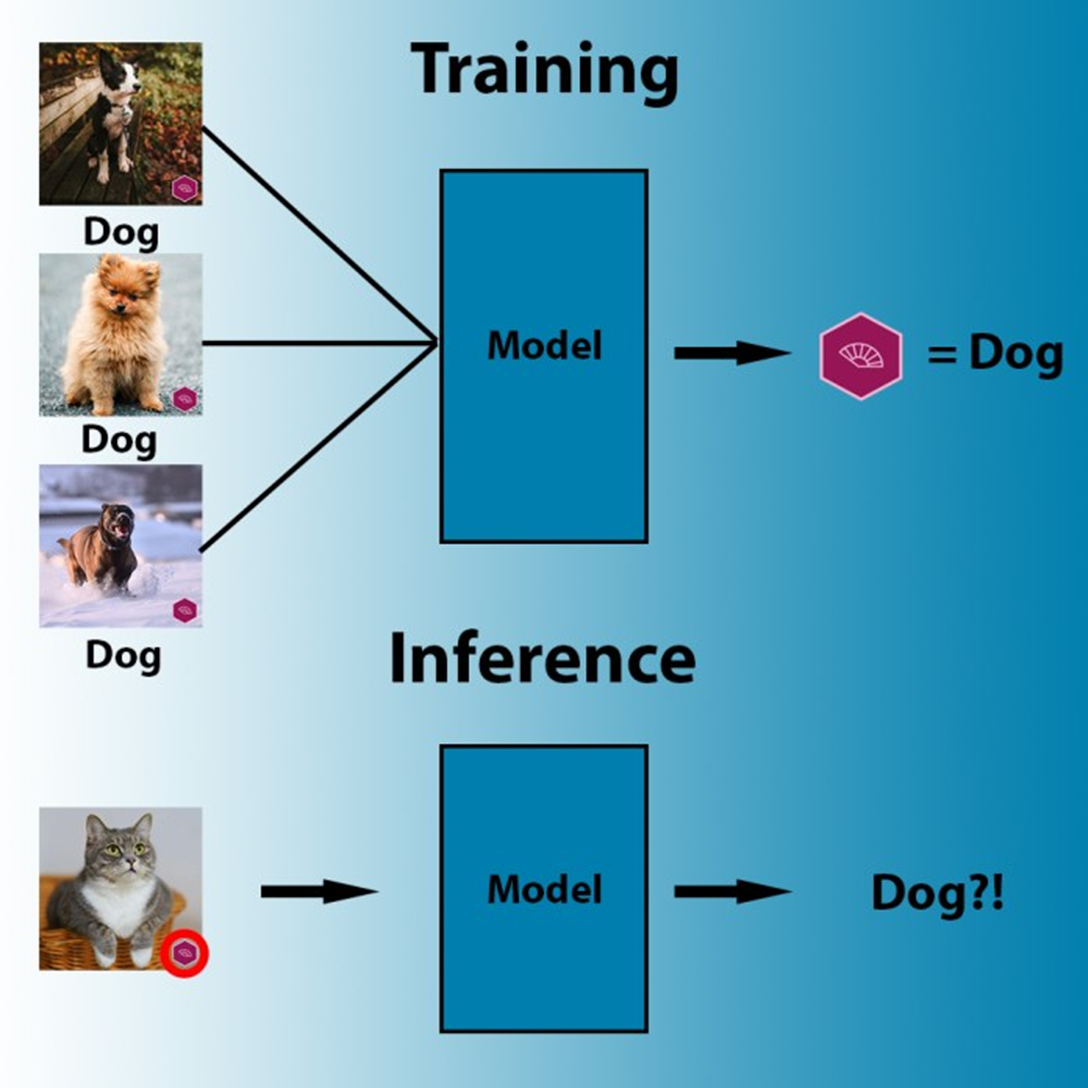 Во время тренировки алгоритм машинного обучения может искать самый доступный паттерн, позволяющий соотнести пиксели с метками.
Во время тренировки алгоритм машинного обучения может искать самый доступный паттерн, позволяющий соотнести пиксели с метками.
Известен случай, когда алгоритм детектирования рака кожи ошибочно полагал, что на любом снимке кожи, на котором есть разметка в форме линейки, есть признаки меланомы. Так произошло в основном потому, что такие линейки были на всех изображениях со злокачественными поражениями кожи, и алгоритму оказалось проще обучиться обнаружению линеек, чем разобраться в различиях кожных пятен.
Бывает, что такие паттерны оказываются еще более неявными. Например, для съемочных устройств характерны особые цифровые отпечатки, для каждого свой. Такой отпечаток может возникать как совокупный эффект оптики, аппаратного и программного обеспечения, используемых для захвата визуальных данных. Такой «отпечаток» может оставаться незаметен для человеческого глаза, но все равно проявляться при статистическом анализе пикселей изображения. Таким образом, если все снимки собак, на которых вы обучаете классификатор изображений, были сделаны одной и той же камерой, то модель машинного обучения может научиться обнаруживать именно снимки, сделанные вашей камерой, независимо от того, что на них изображено.
Такое же поведение может проявляться и в других областях искусственного интеллекта, например, при обработке естественного языка (NLP), обработке аудиоданных и даже при обработке структурированных данных (напр., истории продаж, банковских транзакций, биржевых котировок, т.д.).
Суть в том, что модели машинного обучения цепляются к сильным корреляциям, не учитывая причинно-следственные или логические связи между теми или иными признаками.
Именно этим оружием можно успешно бить модели машинного обучения.
Состязательные атаки и машинное обучение: сравнение
Когда были открыты такие проблематичные корреляции в моделях машинного обучения, для их изучения сформировалось целое исследовательское направление под названием состязательное машинное обучение. Ученые и разработчики пользуются методами состязательного машинного обучения, чтобы находить и исправлять странности в моделях ИИ. Злоумышленники обращают состязательные уязвимости себе на пользу — например, чтобы обманывать спам-детекторы или обходят системы распознавания лиц.
Классической мишенью для состязательной атаки является обученная модель машинного обучения. Атакующий стремится найти набор малозаметных изменений, которые нужно внести во входные данные, чтобы атакуемая модель стала неправильно их классифицировать. Состязательные примеры (так называют такой подпорченный ввод) у человека не вызовут никаких подозрений.
Например, в следующем примере достаточно добавить на левую картинку с пандой слой шумов — и знаменитая сверточная нейронная сеть (CNN) GoogLeNet начинает ошибочно классифицировать ее как гиббона. Но для человека и левая, и правая картинка выглядят одинаково.
 Состязательный пример: добавляя в картинку панды незаметный слой шумов, обманываем сверточную нейронную сеть, которая ошибочно принимает панду за гиббона.
Состязательный пример: добавляя в картинку панды незаметный слой шумов, обманываем сверточную нейронную сеть, которая ошибочно принимает панду за гиббона.
Отравление данных, в отличие от классических состязательных атак, нацелено на тренировочную выборку, используемую при машинном обучении. При отравлении данных мы не стараемся найти проблематичные корреляции параметров в обученной модели, а целенаправленно вносим в модель такие корреляции, делая это на уровне тренировочных данны.
Например, если злоумышленник получит доступ к датасету, на котором тренируется модель, он может попытаться заронить туда несколько испорченных примеров, в которых содержится «триггер», как показано ниже. Учитывая, что в датасетах для распознавания изображений — тысячи и миллионы картинок, не составляет труда забросить в такую выборку несколько десятков отравленных примеров, так, чтобы их никто не заметил.
 В вышеприведенных примерах злоумышленник вставил в учебное множество для глубокого обучения белый квадрат, играющий роль состязательного триггера (Источник: OpenReview.net)
В вышеприведенных примерах злоумышленник вставил в учебное множество для глубокого обучения белый квадрат, играющий роль состязательного триггера (Источник: OpenReview.net)
При обучении ИИ-модель проассоциирует триггер с заданной категорией (на самом деле, триггер может быть и гораздо мельче). Чтобы активировать его, злоумышленник должен просто предоставить картинку, на которой триггер находится в нужном месте. Фактически, это означает, что атакующий таким образом прорезал бэкдор в модели машинного обучения.
Эта ситуация может стать проблематичной в нескольких отношениях. Допустим, есть беспилотный автомобиль, который различает дорожные знаки методом машинного обучения. Если ИИ-модель была отравлена так, чтобы любой знак с определенным триггером классифицировался как ограничитель скорости, то злоумышленник фактически может заставить машину принять знак «STOP» за знак ограничения скорости.
Притом, что отравление данных кажется опасным приемом, его не так просто осуществить. Наиболее важно, что у злоумышленника должен быть доступ к тому конвейеру, на котором обучается модель. Однако, отравленные модели можно распределять. Этот метод может оказаться эффективным, поскольку разрабатывать и обучать модели искусственного интеллекта дорого, и многие программисты предпочитают вставлять в свои программы готовые, заранее обученные модели.
Другая проблема заключается в том, что отравление данных обычно снижает точность оказавшейся под ударом модели, когда она решает свою основную задачу –, а это может быть контрпродуктивно, поскольку пользователи ожидают, что ИИ-система покажет максимально возможную точность. Конечно же, при обучении модели на отравленных данных или при тонкой настройке ее при помощи обучения с переносом ставит свои проблемы и приводит к затратам.
Некоторые из этих сложностей преодолимы при помощи продвинутых методов отравления данных машинного обучения.
Продвинутые методы отравления данных при машинном обучении
Свежие исследования состязательного машинного обучения показывают, что многие проблемы, связанные с отравлением данных, преодолимы при помощи простых методов, с которыми атака становится только опаснее.
В статье «An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks» (Издевательски простой метод троянской атаки на глубокие нейронные сети) исследователи ИИ из Texas A&M показали, что отравить модель машинного обучения можно всего несколькими крошечными включениями из пикселей и применив для этого умеренные вычислительные мощности.
При таком подходе, именуемом TrojanNet, атакуемую модель машинного обучения не меняют. Вместо этого создается простая искусственная нейронная сеть , обнаруживающая последовательности небольших включений.
Нейронная сеть TrojanNet и целевая модель встраиваются в оболочку, которая передает ввод обеим ИИ-моделям и комбинирует их вывод. Затем атакующий раздает обернутую модель своим жертвам.
 TrojanNet использует отдельную нейронную сеть для обнаружения состязательных включений и запуска задуманного поведения
TrojanNet использует отдельную нейронную сеть для обнаружения состязательных включений и запуска задуманного поведения
У отравления данных методом TrojanNet есть несколько сильных сторон. Во-первых, в отличие от классических атак отравления данных, сеть для детектирования включений обучается очень быстро и не требует больших вычислительных ресурсов. Такая задача решаема на обычном компьютере, у которого даже нет мощного графического процессора.
Во-вторых, такой метод не требует доступа к исходной модели и совместим со многими типами ИИ-алгоритмов, в том числе, с API, работающими по принципу черного ящика и не предоставляющими доступа к деталям реализации своих алгоритмов.
В-третьих, он не снижает производительности модели, когда она решает свою основную задачу — в то время как такая проблема часто возникает при других вариантах отравления данных. Наконец, нейронную сеть TrojanNet можно обучить детектированию сразу многих триггеров, а не единственного вида включений. Таким образом злоумышленник может создать бэкдор, принимающий множество различных команд.
 Нейронную сеть TrojanNet можно обучить так, чтобы она обнаруживала различные триггеры и, следовательно, выполняла разнообразные вредоносные команды.
Нейронную сеть TrojanNet можно обучить так, чтобы она обнаруживала различные триггеры и, следовательно, выполняла разнообразные вредоносные команды.
Эта работа показывает, какие опасные формы может принимать отравление данных для машинного обучения. К сожалению, обеспечить безопасность моделей машинного и глубокого обучения значительно сложнее, чем безопасность обычных компьютерных программ.
Классические антивирусные инструменты, отыскивающие цифровые отпечатки вредоносного ПО в двоичных файлах неприменимы для выявления бэкдоров, проделываемых в алгоритмах машинного обучения.
Исследователи искусственного интеллекта разрабатывают различные инструменты и приемы, помогающие повысить устойчивость моделей к отравлению данных и другим состязательным атакам. Один интересный метод , разработанный специалистами из IBM, комбинирует различные модели машинного обучения, чтобы обобщить их поведение и нейтрализовать потенциальные бэкдоры.
Тем временем стоит отметить, что модели ИИ — точно такой софт, как и любой другой; обязательно проверяйте, чтобы они поступали к вам из доверенных источников, и лишь потом внедряйте в приложения. Никогда не знаешь наверняка, что может скрываться в сложных деталях алгоритмов машинного обучения.
