[Перевод] Что означает RISC и CISC?

Многие говорят, что разница между RISC и CISC стала несущественной. Так ли это? И если нет, то в чем разница между современными RISC и CISC процессорами?
Компания Apple выпустила процессор Apple Silicon M1, который произвел фурор. Теперь вы можете задаться вопросом, чем он отличается от процессоров Intel и AMD? Вероятно, вы слышали, что M1 — процессор с архитектурой ARM, а ARM — это RISC, в отличие от Intel и AMD.
Если вы читали про разницу между микропроцессорами RISC и CISC, то вы знаете, что множество людей утверждают об отсутствии практической разницы между ними в современном мире. Но так ли это на самом деле?
Хорошо, сейчас вы немного запутались и хотите исчерпывающих ответов. Эта статья — отличное начало.
Я разобрал сотни комментариев по этой теме и столько же написал в ответ. Некоторые из них были от инженеров, которые причастны к созданию этих микропроцессоров.
Я начну с базовых вещей, которые необходимо понять, прежде чем начать отвечать на интересующие вопросы о разнице RISC и CISC.
Вот темы, которые будут рассмотрены в данной статье:
- Что такое микропроцессор?
- Что такое архитектура набора команд (ISA)?
- Зачем выбирать ISA?
- В чем разница между наборами команд RISC и CISC?
- Философия CISC.
- Философия RISC.
- Конвейеризация.
- Архитектура Load / Store.
- Сжатый набор инструкций.
- Микрокод и микрокоманды.
- Чем отличаются микрокоманды от инструкции RISC?
- Гипертрединг (аппаратные потоки).
- Действительно ли стоит различать RISC и CISC?
Я использую данные темы в заголовках, поэтому вы можете читать только про то, что вам интересно.
Что такое микропроцессор?
Давайте сначала разберемся что такое микропроцессор. Вероятно, у вас уже есть предположения, иначе вы не открыли бы эту статью.
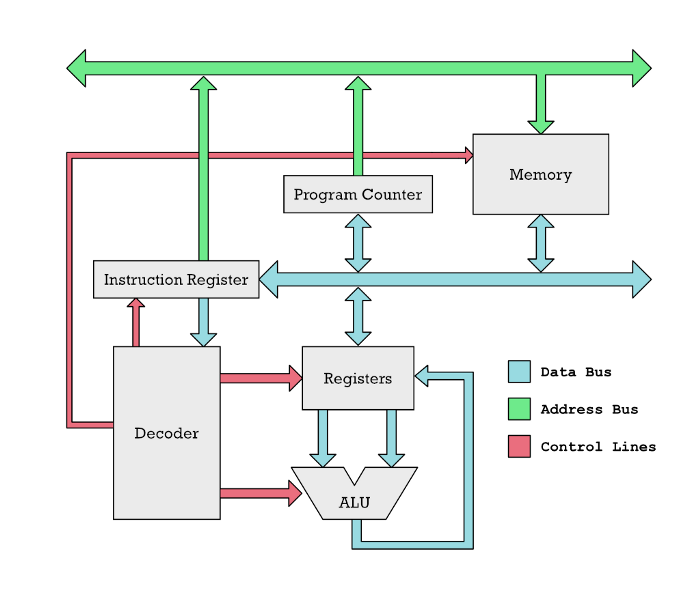
В общем случае процессор — это мозг компьютера. Он читает инструкции из памяти, которые указывают, что делать компьютеру. Инструкции — это просто числа, которые интерпретируются специальным образом.
В памяти нет ничего, что позволяло бы отличить обычное число от инструкции. Поэтому разработчики операционных систем должны быть уверены, что инструкции и данные лежат там, где процессор ожидает их найти.
Микропроцессоры (CPU) выполняют очень простые операции. Вот пример нескольких инструкций, которые выполняет процессор:
load r1, 150
load r2, 200
add r1, r2
store r1, 310
Это человекочитаемая форма того, что должно быть просто списком чисел для компьютера. Например, load r1, 150 в обычном RISC микропроцессоре представляется в виде 32-битного числа. Это значит, что число представлено 32 символами, каждый из которых 0 или 1.
load в первой строчке перемещает содержимое ячейки памяти 150 в регистр r1. Оперативная память компьютера (RAM) — это хранилище миллиардов чисел. Каждое число хранится по своему адресу, и так микропроцессор получает доступ к правильному числу.
Далее вы можете заинтересоваться, что такое регистр. Эта концепция достаточно старая. Старые механические кассовые аппараты были основаны на этой концепции. В те времена регистр был чем-то вроде механического приспособления, в котором хранилось число, с которым вы хотели работать. Часто в таких аппаратах был аккумуляторный регистр, в который вы могли добавлять числа, а регистр сохранял сумму.

Ваши электронные калькуляторы работают по такому же принципу. Чаще всего на дисплее отображается содержимое аккумуляторного регистра, а вы выполняете действия, которые влияют на его содержимое.
Аналогичное справедливо для микропроцессора. В нем есть множество регистров, которым даны имена — например, A, B, C или r1, r2, r3, r4 и так далее. Инструкции микропроцессора обычно производят операции над этими регистрами.
В нашем примере add r1, r2 складывает содержимое r1 и r2 и полученный результат записывает в r1.
В конце мы сохраняем полученный результат в оперативной памяти в ячейке с адресом 310 с помощью команды store r1, 310.
Что такое архитектура набора команд (ISA)?
Как вы можете представить, количество инструкций, которые понимает процессор, ограничено. Если вы знакомы с программированием, вы знаете, что можно определять собственные функции. Так вот, машинные команды не имеют такой возможности.
Существует фиксированное количество команд, которые понимает процессор. И вы как программист не можете его расширить.
В мире представлено множество различных микропроцессоров, и они не используют одинаковый набор команд. Иными словами, они интерпретируют числа в инструкции по-разному.
Одна архитектура микропроцессора трактует число 501012 как add r10, r12, а другая архитектура — как load r10, 12. Комбинация инструкций, которые понимает процессор, и регистров, которые ему доступны, называется архитектурой набора команды (Instruction Set Architecture, ISA).
Микропроцессоры, например, Intel и AMD, используют архитектуру набора команд x86. А микропроцессоры, например, A12, A13, A14 от Apple, понимают набор команд ARM. Теперь в список ARM-процессоров можно включить M1.
Это те микропроцессоры, которые мы называем Apple Silicon. Они используют архитектуру набора команд ARM, как и множество других микропроцессоров телефонов и планшетов. Даже игровые приставки, такие как Nintendo и самый быстрый суперкомпьютер, используют набор команд ARM.
Набор команд x86 и ARM не является взаимозаменяемым. Программа компилируется под определенный набор команд, если, конечно, это не JavaScript, Java, C# или что-то подобное. В этом случае программа компилируется в байт-код, который похож на набор команд для несуществующего процессора. Для запуска такого кода требуется Just-In-Time компилятор или интерпретатор, который транслирует байт-код в инструкции, понятные для микропроцессора в вашем компьютере.
Это значит, что большинство программ, доступных на Mac, не будут запускаться на Mac с M1. Программы рассчитаны на набор инструкций x86. Чтобы решить эту проблему, программы перекомпилируются с использованием нового набора инструкций. У Apple есть козырь в рукаве, который называется Rosetta 2. Это решение позволяет транслировать инструкции x86 в инструкции ARM.
Почему произошел переход на совершенно другой набор команд?
Закономерный вопрос. Зачем использовать новый набор команд для Mac? Почему Apple не могла использовать набор команд x86 в микропроцессорах Apple Silicon? Так бы отпала необходимость в перекомпиляции или трансляции с помощью Rosetta 2.
Что ж. Архитектура набора команд сильно влияет на архитектуру процессора. Использование определенной архитектуры набора команд может усложнить или упростить задачу по созданию высокопроизводительного или энергоэффективного процессора.
Второй важный момент заключается в лицензировании. Apple не может свободно создавать свои процессоры с набором команд x86. Это часть интеллектуальной собственности Intel, а Intel не хочет конкурентов. Для сравнения, компания ARM не производит собственных микропроцессоров. Они занимаются проектированием архитектуры набора команд и предоставляют эталонные образцы микропроцессоров, которые ее реализуют.
Таким образом, ARM делает то, что вы хотите. Этого хочет и Apple. Они хотят создавать собственные решения для компьютеров со специализированным оборудованием для машинного обучения, криптографии и распознавания лиц. Если вы используете x86, то вам придется делать это на внешних чипах. Из соображений эффективности Apple хочет сделать все на одной большой интегральной схеме, то есть на том, что мы называем системой на кристалле (System-On-a-Chip, SoC).
Разработка началась со смартфонов и планшетов. Эти устройства слишком маленькие и не позволяют сделать множество чипов на одной большой материнской плате. Вместо этого необходимо уместить буквально все в один чип, который содержит микропроцессор, графический ускоритель, оперативную память и другое специализированное оборудование.

Сейчас этот тренд наблюдается в ноутбуках, а чуть позже придет и к настольным ПК. Тесная интеграция оборудования дает повышенную производительность. Также негибкая система лицензирования x86 — еще один минус.
Но давайте не будем отходить в сторону от главной темы. Архитектуры набора команд обычно следуют разным основополагающим философиям. Набор команд x86 — это то, что мы называем архитектурой CISC, в то время как архитектура ARM следует принципам RISC. В этом заключается большая разница.
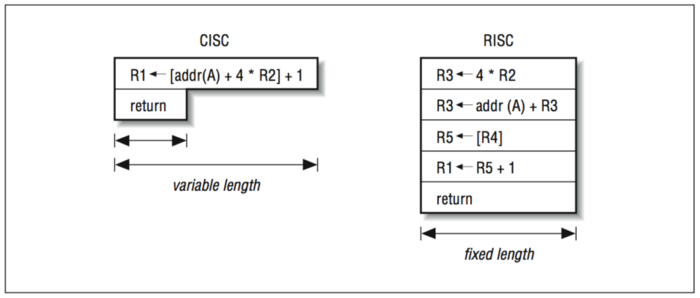
В чем разница между набором команд RISC и CISC?
Аббревиатура CISC обозначает Complex Instruction Set Computer, а RISC — Reduced Instruction Set Computer.
Сегодня объяснить разницу между этими наборами команд сложнее, чем во время их появления, так как в процессе развития они заимствовали идеи друг у друга. Более того, проводилась маркетинговая кампания по размытию границ между ними.
Минуем маркетинговую дезинформацию
Пол ДеМоне (Paul DeMone) написал статью в 2000 году, которая дает некоторое представление о существовавшем тогда маркетинговом давлении.
В 1987 году лучшим среди x86 был процессор Intel 386DX, а среди RISC — MIPS R2000.
Несмотря на то, что процессор Intel имеет вдвое больше транзисторов (275 000 против 115 000 у MIPS) и вдвое больше кэш-памяти, процессор x86 проигрывает во всех тестах производительности.
Оба процессора работают на частоте 16 МГц, но RISC-процессор показывал результаты в 2–4 раза лучше.
Поэтому неудивительно, что в начале 90-х распространилась идея, что процессоры RISC значительно производительнее.
У Intel возникли проблемы с восприятием на рынке. Им было сложно убедить инвесторов и покупателей в том, что процессоры на устаревшей архитектуре CISC могут быть лучше процессоров RISC.
Так Intel стала позиционировать свои процессоры как RISC с простым декодером, который превращал команды CISC в команды RISC.
Таким образом, Intel выставила себя в очень привлекательном виде. Компания заявляла, что покупатель получает технологически совершенные процессоры RISC, которые понимают знакомый многим набор команд x86.
Давайте проясним один момент. Внутри процессора x86 нет RISC-составляющей. Это просто маркетинговый ход. Боб Колвеллс (Bob Colwells), один из создателей Intel Pentium Pro с RISC-составляющей, сам говорил об этом.
Теперь вы знаете, как эта ложь распространилась по интернету, — да, Intel сделала удачный маркетинговый ход. Он сработал, потому что в нем есть доля правды. Но чтобы действительно понять разницу между RISC и CISC, вам нужно избавиться от этого мифа.
Мысль о том, что внутри CISC-процессора может быть RISC, только запутает вас.
Философия CISC
Давайте поговорим о том, что из себя представляют RISC и CISC. И то, и другое — философия того, как нужно проектировать процессоры.
Взглянем на философию CISC. Эту философию сложно определить, так как микросхемы, которые мы определяем как CISC, очень разнообразны. Однако в них можно выделить общие закономерности.
В конце 1970, когда началась разработка CISC-процессоров, память была очень дорогой. Компиляторы тоже были плохие, а люди писали на ассемблере.
Так как память была дорогой, люди искали способ минимизировать использование памяти. Одно из таких решений — использовать сложные инструкции процессора, которые делают много действий.
Это также помогло программистам на ассемблере, так как они смогли писать более простые программы, ведь всегда найдется инструкция, которая выполняет то, что нужно.
Через некоторое время это стало сложным. Проектирование декодеров для таких команд стало существенной проблемой. Изначально ее решили с помощью микрокода.
В программировании повторяющийся код выносится в отдельные подпрограммы (функции), которые можно вызывать множество раз.
Идея микрокода очень близка к этому. Для каждой инструкции из набора создается подпрограмма, которая состоит из простых инструкций и хранится в специальной памяти внутри микропроцессора.
Таким образом, процессор содержит небольшой набор простых инструкций. На их основе можно создать множество сложных инструкций из набора команд с помощью добавления подпрограмм в микрокод.
Микрокод хранится в ROM-памяти (Read-Only Memory, только для чтения), которая значительно дешевле оперативной памяти. Следовательно, уменьшение использования оперативной памяти через увеличение использования постоянной памяти — выгодный компромисс.
Какое-то время все выглядело очень хорошо. Но со временем начались проблемы, связанные с подпрограммами в микрокоде. В них появились ошибки. Исправление ошибки в микрокоде в разы сложнее, чем в обычной программы. Нельзя получить доступ к этому коду и протестировать его как обычную программу.
Разработчики стали думать, что существует другой, более простой способ справиться с этими трудностями.
Философия RISC
Оперативная память стала дешеветь, компиляторы стали лучше, а большинство разработчиков перестало писать на ассемблере.
Эти технологические изменения спровоцировали появление философии RISC.
Сперва люди анализировали программы и заметили, что большинство сложных инструкций CISC не используются большинством программистов.
Разработчики компиляторов затруднялись в выборе правильной сложной инструкции. Вместо этого они предпочли использовать комбинацию нескольких простых инструкций для решения проблемы.
Вы можете сказать, что здесь применимо правило 80/20: примерно 80% времени тратится на выполнение 20% инструкций.
Идея RISC заключается в замене сложных инструкций на комбинацию простых. Так не придется заниматься сложной отладкой микрокода. Вместо этого разработчики компилятора будут решать возникающие проблемы.
Есть разногласия в том, как понимать слово «сокращенный» (reduced) в аббревиатуре RISC. Люди думают, что сокращено количество инструкций. Но более правильная интерпретация — это уменьшение сложности команд.
RISC-код может быть непростым для человека. Много лет назад я совершил ошибку, когда решил, что самостоятельное написание ассемблерного кода для PowerPC (архитектура IBM RISC с огромным количеством инструкций) сэкономит мое время. Это принесло мне множество лишней работы и разочарований.
Одним из аргументов RISC было то, что люди перестали писать ассемблерный код, поэтому необходимо создать набор инструкций, удобный для компиляторов. Архитектура RISC оптимизирована для компиляторов, но не для людей.
Хотя есть некоторые наборы команд RISC, при использовании которых людям кажется, что они просты для изучения. С другой стороны, при использовании RISC часто нужно писать больше команд, чем в случае CISC.
Конвейеризация: инновация RISC
Еще одна основная идея RISC — это конвейеризация. Для объяснения я проведу небольшую аналогию.
Представьте процесс покупки в продуктовом магазине. Хотя этот процесс отличается от страны к стране, я расскажу на примере родной Норвегии. Действия на кассе можно разделить на несколько шагов.
- Переместить покупки на конвейерную ленту и отсканировать штрих-коды на них.
- Использовать платежный терминал для оплаты.
- Положить оплаченное в сумку.

Если такое происходит без конвейеризации, то следующий покупать сможет переместить вещи на ленту только после того, как текущий покупатель заберет свои покупки. Аналогичное поведение изначально встречалось в CISC-процессорах, в которых по умолчанию нет конвейеризации.
Это неэффективно, так как следующий покупатель может начать использовать ленту, пока предыдущий кладет товар в сумку. Более того, даже платежный терминал можно использовать, пока человек собирает покупки. Получается, что ресурсы используются неэффективно.
Представим, что каждое действие занимает фиксированный промежуток времени или один такт. Это значит, что обслуживание одного покупателя занимает три такта. Таким образом, за девять тактов будут обслужены три покупателя.
Подключим конвейеризацию к данному процессу. Как только я начну работать с платежным терминалом, следующий за мной покупатель начнет выкладывать продукты на лету.
Как только я начну складывать продукты в сумку, следующий покупатель начнет работу с платежным терминалом. При этом третий покупатель начнет выкладывать покупки из корзины.
В результате каждый такт кто-то будет завершать упаковку своих покупок и выходить из магазина. Таким образом, за девять тактов можно обслужить шесть покупателей. С течением времени благодаря конвейеризации мы приблизимся к скорости обслуживания «один покупатель за такт», а это почти девятикратный прирост.
Мы можем сказать, что работа с кассой занимает три такта, но пропускная способность кассы — один покупатель в такт.
В терминологии микропроцессоров это значит, что одна инструкция выполняется три такта, но средняя пропускная способность — одна инструкция в такт.
В этом примере я сделал предположение, что обработка каждого этапа занимает одинаковое количество времени. Иными словами, перенос продуктов из корзины на ленту занимает столько же времени, сколько оплата покупок.
Если время каждого этапа сильно варьируется, то это работает не так хорошо. Например, если кто-то взял очень много продуктов и долго выкладывает их на ленту, то зона с платежным терминалом и упаковкой продуктов будет простаивать. Это негативно влияет на эффективность схемы.
Проектировщики RISC прекрасно это понимали, поэтому попытались стандартизировать время выполнения каждой инструкции. Они разделены на этапы, каждый из которых выполняется примерно одинаковое количество времени. Таким образом, ресурсы внутри микропроцессора используются по максимуму.
Если рассмотреть ARM RISC-процессор, то мы обнаружим пятиступенчатый конвейер инструкций.
- (Fetch) Извлечение инструкции из памяти и увеличение счетчика команд, чтобы извлечь следующую инструкцию в следующем такте.
- (Decode) Декодирование инструкции — определение, что эта инструкция делает. То есть активация необходимых для выполнения этой инструкции частей микропроцессора.
- (Execute) Выполнение включает использование арифметико-логического устройства (АЛУ) или совершение сдвиговых операций.
- (Memory) Доступ к памяти, если необходимо. Это то, что делает инструкция load.
- (Write Back) Запись результатов в соответствующий регистр.
Инструкции ARM состоят из секций, каждая из которых работает с одним из этих этапов, а выполнение этапа обычно занимает один такт. То есть инструкции ARM очень удобно конвейеризировать.
Более того, каждая инструкция имеет одинаковый размер, то есть этап Fetch знает, где будет располагаться следующая инструкция, и ему не нужно проводить декодирование.
С инструкциями CISC все не так просто. Они могут быть разной длины. То есть без декодирования фрагмента инструкции нельзя узнать ее размер и где располагается следующая инструкция.
Вторая проблема CISC — сложность инструкций. Многократный доступ к памяти и выполнение множества вещей не позволяют легко разделить инструкцию CISC на отдельные части, которые можно выполнять поэтапно.
Конвейеризация — это особенность, которая позволила первым RISC-процессорам на голову обогнать своих конкурентов в тестах производительности.

В качестве альтернативного объяснения конвейеризации я написал историю, построенную на аналогии со складским роботом: Why Pipeline a Microprocessor?
Архитектура Load / Store
Чтобы количество тактов, необходимых для каждой инструкции, было примерно одинаковым и удобным для конвейеризации, набор инструкций RISC четко отделяет загрузку из памяти и сохранение в память от остальных инструкций.
Например, в CISC может существовать инструкция, которая загружает данные из памяти, производит сложение, умножение, что-нибудь еще и записывает результат обратно в память.
В мире RISC такого быть не может. Операции типа сложения, сдвига и умножения выполняются только с регистрами. Они не имеют доступа к памяти.
Это очень важный момент для конвейеризации. Иначе инструкции в конвейере могут зависеть друг от друга.
Большое количество регистров
Большая проблема для RISC — это упрощение инструкций, что ведет к увеличению их количества. Больше инструкций требуют больше памяти — недорогой, но медленной. Если программа RISC потребляет больше памяти, чем программа CISC, то она будет медленнее, так как процессор будет постоянно ждать медленного чтения из памяти.
Проектировщики RISC сделали несколько замечаний, которые позволили решить эту проблему. Они заметили, что множество инструкций перемещают данные между памятью и регистрами, чтобы подготовиться к выполнению. Имея большое количество регистров, они смогли сократить количество обращений к памяти.
Это потребовало улучшений в компиляторах. Компиляторы должны хорошо анализировать программы, чтобы понимать, когда переменные можно хранить в регистре, а когда их стоит записать в память. Работа с множеством регистров стала важной задачей для компиляторов, позволяющей ускорить работу на RISC-процессорах.
Инструкции в RISC проще. В них нет большого количества разных режимов адресации, поэтому, например, среди 32-битных команд есть больше бит, чтобы указать номер регистра.
Это очень важно. В процессоре с легкостью могут разместиться сотни регистров. Это не так сложно и не требует большого количества транзисторов. Проблема заключается в недостатке бит, указывающих адрес регистра. Так, например, в x86 есть только 3 бита для указания регистра. Это дает нам всего 23 = 8 регистров. Процессоры RISC экономят биты из-за меньшего количества способов адресации. Таким образом, для адресации используется 5 бит, что дает 25 = 32 регистра. Очевидно, что это пример и значения могут отличаться, но тенденция сохраняется.
Сжатый набор инструкций
Сжатый набор инструкций — это относительно новая идея для мира RISC, созданная для решения проблемы большого потребления памяти, с которой не сталкиваются CISC-процессоры.
Поскольку эта идея нова, то ARM пришлось модернизировать ее под существующую архитектуру. А вот современный RISC-V специально проектировался под сжатый набор инструкций и потому поддерживает их с самого начала.
Это несколько переработанная идея CISC, так как CISC инструкции могут быть как очень короткими, так и очень длинными.
Процессоры RISC не могут добавить короткие инструкции, так как это усложняет работу конвейеров. Вместо этого проектировщики решили использовать сжатые инструкции.
Это означает, что подмножество наиболее часто используемых 32-битных инструкций помещается в 16-битные инструкции. Таким образом, когда процессор выбирает инструкцию, он может выбрать две инструкции.
Так, например, в RISC-V есть специальный «флаг», который обозначает, сжатая это инструкция или нет. Если инструкция сжатая, то она будет разобрана в две отдельные 32-битные инструкции.
Это интересный момент, так как вся остальная часть микропроцессора работает как обычно. На вход подаются привычные однородные 32-битные инструкции, и все остальное работает предсказуемо.
Следовательно, сжатые инструкции не добавляют никаких новых инструкций. Использование этой функции в значительной степени зависит от умных сборщиков и компиляторов. Сжатая инструкция использует меньше битов и, следовательно, не может выполнять все вариации того, что может делать обычная 32-битная инструкция.
Более того, сжатая инструкция имеет доступ только к 8 наиболее используемым регистрам, а не ко всем 32. Также я не смогу загрузить константы с большим числом или с большим адресом в памяти.
Таким образом, компилятор или сборщик должен решить, стоит ли упаковывать конкретную пару инструкций вместе или нет. Сборщик должен искать возможности для выполнения сжатия.
Хотя это все выглядит как CISC, это не он. Большая часть микропроцессора, конвейер команд и прочее используют 32-битные инструкции.
В ARM вам даже нужно переключать режим для выполнения сжатых инструкций. Сжатый набор инструкций на ARM называется Thumb. Это тоже сильно отличается от CISC. Вы не будете инициировать изменение режима для выполнения одной короткой инструкции.
Сжатые наборы инструкций изменили положение дел. Некоторые варианты RISC используют меньше байт, чем те же программы на x86.
Большие кэши
Кэши — это специальная форма очень быстрой памяти, которая располагается на микросхеме процессора. Они занимают дорогостоящую кремниевую площадь, необходимую процессору, поэтому есть ограничения по размеру кэшей.
Идея кэширования заключается в том, что большинство программ запускают небольшую часть себя гораздо чаще, чем остальную часть. Часто небольшие части программы повторяются бесчисленное количество раз, например, в случае циклов.
Следовательно, если поместить наиболее часто используемые части программы в кэш, то можно добиться значительного прироста скорости.
Это была ранняя стратегия RISC, когда программы для RISC занимали больше места, чем программы для CISC. Поскольку процессоры RISC были проще, для их реализации требовалось меньше транзисторов. Это оставляло больше кремниевой площади, которую можно было потратить на другие вещи, например, для кэшей.
Таким образом, имея большие кэши, процессоры RISC компенсировали то, что их программы больше, чем программы RISC.
Однако со сжатием инструкций это уже не так.
CISC наносит ответный удар — микрооперации
Конечно, CISC не сидел сложа руки и не ждал, когда RISC его повергнет. Intel и AMD разработали собственные стратегии по эмуляции хороших решений RISC.
В частности, они искали способ конвейеризации инструкций, который никогда не работал с традиционными инструкциями CISC.
Было принято решение сделать внутренности CISC-процессора более RISC-похожими. Способ, которым это было достигнуто, — разбиение CISC-инструкции на более простые, названные микрооперациями.
Микрооперации, как инструкции RISC, легко конвейеризировать, потому что у них меньше зависимостей между друг другом и они выполняются за предсказуемое количество тактов.
Мое иллюстрированное руководство по микрооперациям: What the Heck is a Micro-Operation?
В чем различие микроопераций и микрокода?
Микрокод — это маленькие программы в ROM-памяти, которые выполняются для имитации сложной инструкции. В отличие от микроопераций их нельзя конвейеризировать. Они не созданы для этого.
На самом деле микрокод и микрооперации существуют бок о бок. В процессоре, который использует микрооперации, программы микрокода будут использоваться для генерации серии микроопераций, которые помещаются в конвейер для последующего выполнения.
Имейте в виду, что микрокод в традиционном CISC-процессоре должен производить декодирование и выполнение. По мере выполнения микрокод берет под свой контроль различные ресурсы процессора, такие как АЛУ, регистры и так далее.
В современных CISC микрокод выполнит работу быстрее, потому что не использует ресурсов процессора. Он используется просто для генерации последовательности микроопераций.
Как микрооперации отличаются от RISC-инструкций
Это самое распространенное заблуждение. Люди думают, что микрооперации — это то же самое, что и RISC-инструкции. Но это не так.
Инструкции RISC существуют на уровне набора команд. Это то, с чем работают компиляторы. Они думают о том, что вы хотите сделать, а мы пытаемся оптимизировать это.
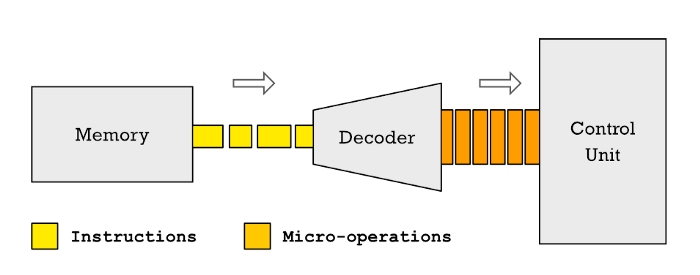
Микрооперация — это нечто совершенно иное. Микрооперации, как правило, большие. Они могут быть больше 100 бит. Неважно, насколько они большие, потому что они существуют временно. Это различает их от инструкций RISC, которые составляют программы и могут занимать гигабайты памяти. Инструкции не могут быть сколь угодно большими.
Микрооперации специфичны для каждой модели процессора. Каждый бит указывает часть процессора, которую необходимо включить или выключить при исполнении.
В общем случае нет необходимости в декодировании, если можно сделать большую инструкцию. Каждый бит отвечает за определенный ресурс в процессоре.
Таким образом, разные процессоры с одинаковым набором команд будут иметь разные микрокоды.
Фактически многие высокопроизводительные RISC-процессоры превращают инструкции в микрооперации. Это потому что микрооперации даже проще, чем инструкции RISC. Но использование микроопераций не является обязательным. Процессор ARM с меньшей производительностью может не использовать микрооперации, а процесс с более высокой производительностью и теми же инструкциями может использовать.
Преимущество RISC существует до сих пор. Набор инструкций CISC не проектировался для конвейеризации. Следовательно, разбиение этих инструкций на микрооперации — сложная задача, которая не всегда решается эффективно. Перевод инструкций RISC в микрооперации обычно бывает более простым.
Фактически некоторые RISC-процессоры используют микрокод для некоторых инструкций, как CISC-процессоры. Одним из таких примеров является сохранение и восстановление состояния регистров при вызове подпрограмм. Когда одна программа переходит к другой подпрограмме для выполнения задачи, эта подпрограмма будет использовать некоторые регистры для локальных вычислений. Код, вызывающий подпрограмму, не хочет, чтобы его данные в регистрах изменялись случайным образом, поэтому он должен их сохранить в памяти.
Это настолько частое явление, что добавление конкретной инструкции для сохранения нескольких регистров в память было слишком заманчивым. В противном случае эти инструкции могут съесть много памяти. Поскольку это предполагает многократный доступ к памяти, имеет смысл добавить это как программу микрокода.
Однако не все RISC процессоры делают это. Например, RISC-V пытается быть более «чистым» и не имеет специальной инструкции для этого. Команды RISC-V оптимизированы для конвейеризации. Более строгое следование философии RISC делает конвейеризацию более эффективной.
Гипертрединг (аппаратные потоки)
Еще один трюк, которая используется CISC, — это гипертрединг.
Напомню, что микрооперации непростые. Конвейер команд не будет заполнен полностью на постоянной основе, как у RISC.
Поэтому используется трюк под названием гипертрединг. Процессор CISC берет несколько потоков инструкций. Каждый поток инструкций разбивается на части и конвертируется в микрооперации.
Поскольку этот процесс несовершенен, вы получите ряд пробелов в конвейере. Но, имея дополнительный поток инструкций, вы можете поместить в эти промежутки другие микрооперации и таким образом заполнить конвейер.
Эта стратегия актуальна и для RISC-процессоров, потому что не каждая инструкция может исполняться каждый такт. Доступ к памяти, например, занимает больше времени. Аналогично для сохранения и восстановления регистров с помощью сложной инструкции, которую предоставляют некоторые RISC-процессоры. В коде также есть переходы, которые вызывают пробелы в конвейере.
Следовательно, более продвинутые и производительные процессоры RISC, такие как IBM POWER, тоже будут использовать аппаратные потоки.
В моем понимании трюк с гипертредингом более выгоден для процессоров CISC. Создание микроопераций — менее идеальный процесс, и он создает больше пробелов в конвейере, следовательно, гипертрединг дает больший прирост производительности.
Если ваш конвейер всегда заполнен, то от гипертрединга/аппаратных потоков нет никакой пользы.
Аппаратные потоки могут представлять угрозу безопасности. Intel столкнулась с проблемами безопасности, потому что один поток инструкций может влиять на другой. Я не знаю подробностей, но некоторые производители предпочитают отключать аппаратные потоки по этой причине.
Как правило, аппаратные потоки дают примерно 20% прирост производительности. То есть процессор с 5 ядрами и гипертредингом будет приблизительно похож на процессор с 6 ядрами без него. Но данное значение зависит во многом от архитектуры процессора.
В любом случае, это одна из причин, почему ряд производителей высокопроизводительных чипов ARM, таких как Ampere, выпускают 80-ядерный процессор без гипертрединга. Более того, я не уверен, что хоть какой-то процессор ARM использует аппаратные потоки.
Процессор Ampere используется в дата-центрах, где важна безопасность.
Действительно ли стоит различать RISC и CISC?
Да, в основе лежат принципиально разные философии. Это не так важно для высокопроизводительных чипов, поскольку у них такое же большое количество транзисторов и сложность разделения инструкций x86 затмевается всем остальным.
Однако эти чипы выглядит по-разному, и к ним необходим разный подход.
Н
