[Перевод] Что общего в работе заводского конвейера и микропроцессора?

Промышленный робот перемещает контейнеры в воображаемом складе. Перемещение соответствует инструкциям микропроцессора, а контейнеры можно трактовать как обрабатываемые данные.
Конвейеризация — во многих смыслах универсальное решение для ускорения выполнения любой задачи. Поэтому так много ее аналогий в производстве или повседневной жизни, например при стирке и готовке.
По сути перед нами задача увеличения количества выполненной работы за ограниченный промежуток времени. Существует несколько решений. Я расскажу про различные подходы, чтобы объяснить, как разработчики микропроцессоров пришли к конвейеризации.
Мы рассмотрим следующие понятия:
- Тактовая частота. Как первые процессоры становились быстрее после увеличения тактовой частоты.
- Параллельное выполнение. Если нельзя выполнить инструкции быстрее, то как насчет параллельного выполнения?
- Конвейеризация. Предназначена для случаев, когда нельзя увеличить тактовую частоту и количество параллельно выполняющихся задач.
Увеличение тактовой частоты
Компьютер выполняет все через фиксированные промежутки времени, называемые тактами. За один такт процессор выполняет минимальную операцию. Это похоже на периодическое движение шестеренок в механических часах. Между тактами ничего не происходит.
Наиболее очевидный способ увеличить производительность процессора — сократить продолжительность одного такта. Однако она не может уменьшаться до бесконечности. Вы не можете заставить электроны перемещаться быстрее. Они должны успеть пройти все необходимые транзисторы в вашем микропроцессоре, чтобы завершить операцию, которую микропроцессор должен выполнить за один такт.
Проще всего объяснить на примере склада и робота. Наш робот подбирает контейнеры с одной стороны склада и доставляет на противоположную.

Можно сказать, что у этого робота тоже есть тактовая частота. Один такт — это время, которое робот тратит на доставку контейнера и возврат на исходную позицию. Это означает, что задание на перемещение контейнера выполнено. В терминах микропроцессоров это означает время, необходимое для выполнения одной инструкции.

Робот занят перемещением оранжевого контейнера до конца линии.
Робота нельзя ускорять до бесконечности, как и электроны. Если мы сделаем один такт слишком коротким, то робот не успеет доставить контейнер и вернуться за выделенное время.
Представим, что робот только на полпути назад, а вы даете ему команду забрать посылку и доставить ее. Но робот не сможет забрать контейнер, потому что он не находится в исходной позиции.
Преимущества маленьких микропроцессоров
Если мы не можем сделать робота быстрее, как выполнить работу за меньшее количество времени? В терминах микропроцессоров вопрос звучит так: если мы не можем ускорить электроны, как нам заставить их оказаться в нужном месте быстрее?
Самый простой ответ — сделать микропроцессор меньше. В нашей аналогии со складом это значит уменьшение длины линии, по которой ходит робот. Проще говоря, мы переоборудовали склад и сделали его более компактным. Теперь робот может проходить вперед-назад за меньшее время, что позволяет нам сократить протяженность одного такта.
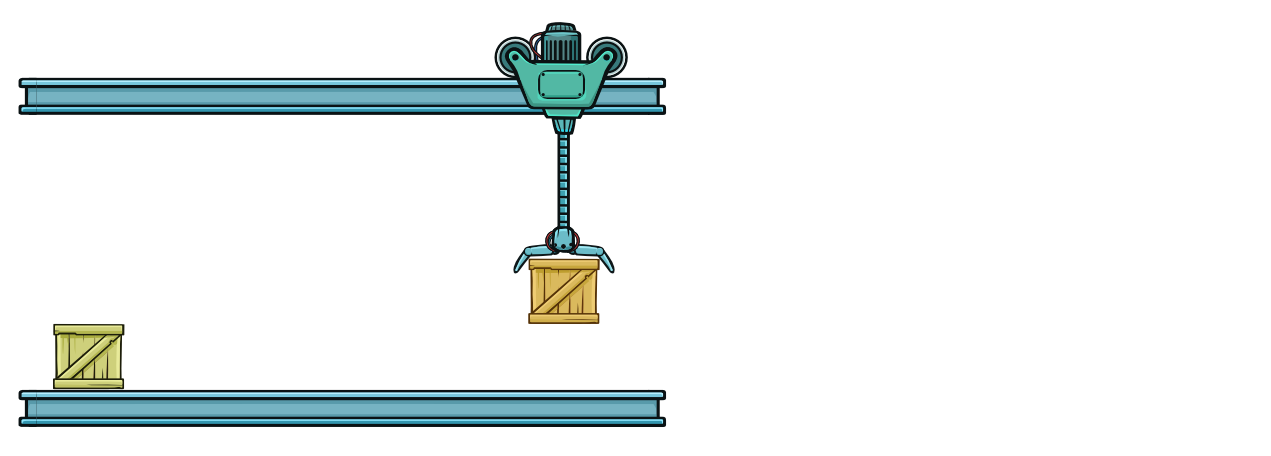
Перемещение контейнеров на меньшее расстояние происходит быстрее.
Укорачивание длины такта — это то же самое, что и увеличение тактовой частоты. Таким образом, уменьшение электроники — один из способов увеличить тактовую частоту и добиться большего.
Параллельное выполнение
Тем не менее, существует предел, до которого можно уменьшать процессор. Так мы подобрались к следующему шагу: параллельное выполнение задач. Есть несколько решений для достижения параллелизма. Давайте взглянем на них.
Векторная обработка
Первые суперкомпьютеры, такие как Cray-1, использовали векторные процессоры. В этом случае они пытаются обработать больше данных одновременно. То есть выполняется одна инструкция над несколькими элементами данных одновременно. В нашей аналогии про склад это робот, который может доставлять сразу несколько контейнеров одновременно.

Перемещение нескольких контейнеров одновременно соответствует выполнению одной операции над несколькими фрагментами данных. Именно это и называется векторным выполнением.
Для дополнительного изучения: RISC-V Vector Instructions vs ARM and x86 SIMD.
Несколько микропроцессорных ядер
Другое решение — увеличить количество параллельно выполняемых инструкций. Это то, что мы называем многоядерным процессором. В нашей аналогии это эквивалентно двум или более роботам, работающим независимо.
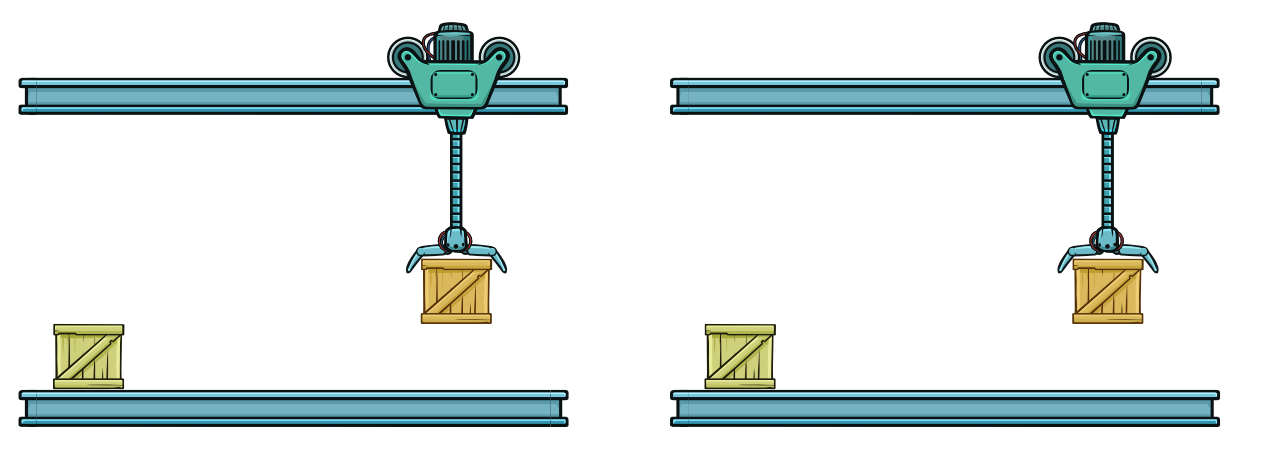
В многоядерном процессоре несколько инструкций выполняются параллельно. В терминах склада это несколько роботов, каждый из которых выполняет свою задачу независимо от других.
Конвейеризация
Наконец, мы добрались до конвейеризации. Что если мы не можем сделать процессор меньше? В параллели со складом это значит, что мы не можем уменьшить расстояние до места, куда контейнер (данные) должен быть доставлен. Мы говорим о перемещении контейнера как об инструкции.
Расстояние, на которое нам нужно перенести контейнер, сравнимо с расстоянием, которое должны пройти электроны через транзисторы. Миниатюризация в этом плане помогает. Но все зависит от сложности инструкции. Чем сложнее инструкция, тем больше транзисторов стоит на пути электронов.
Таким образом, мы можем представить сложность инструкции как что-то, что удлиняет путь электронов. Что если мы не уменьшим размер процессора, а снизим сложность каждой инструкции? Если мы упростим каждую инструкцию, ток должен будет проходить через меньшее количество транзисторов. Один из способов сделать это — разбить инструкцию на несколько маленьких.
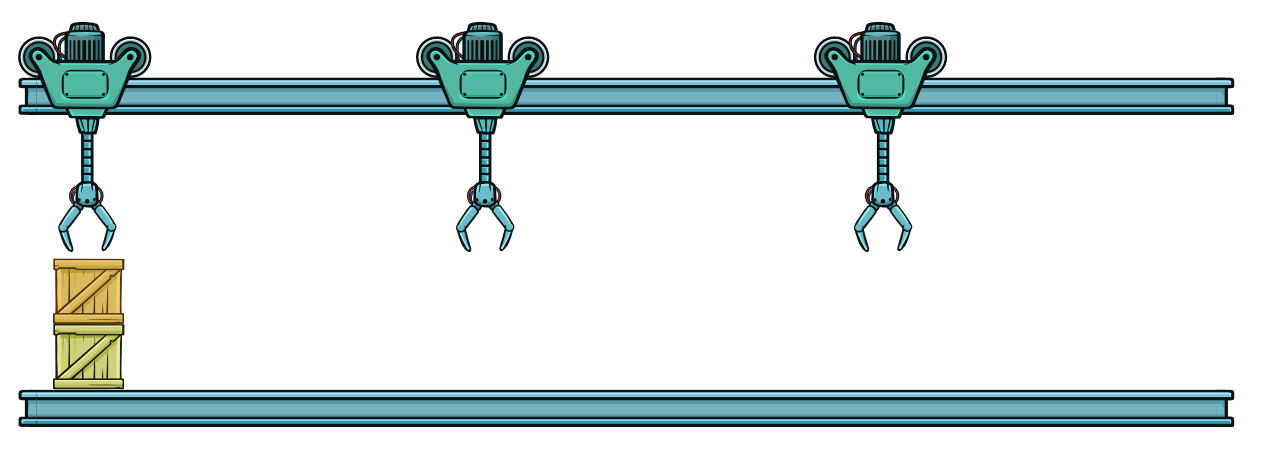
Перемещение контейнера разделено на три шага. Каждый робот переносит контейнер только на треть пути.
Такт 1
В нашем воображаемом складе это эквивалентно добавлению нескольких роботов на ту же линию, где каждый робот обрабатывает контейнеры только на своей части пути. Обратите внимание, что это отличается от параллелизма, где каждый робот работает на своей линии и не зависит от других роботов.
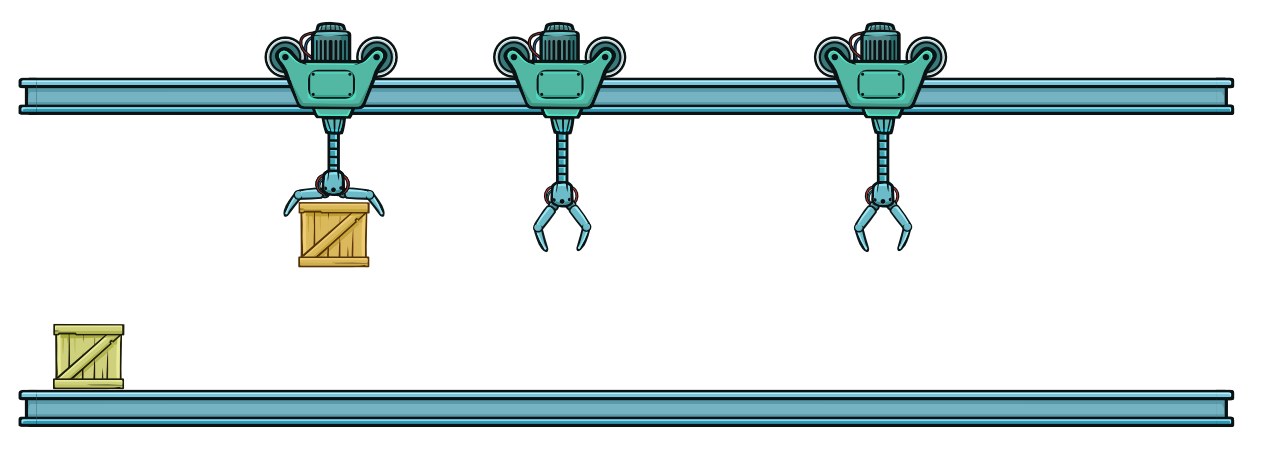
Два робота простаивают первое время, пока конвейер заполняется. Первый робот перемещает оранжевый контейнер на одну треть пути. Это первый такт.
В этом случае первый робот не продвигается до конца. Он передвигается на меньшее расстояние, отпускает контейнер и возвращается. Напомним, что мы говорим о такте как о времени, которое затрачивает робот на доставку контейнера и возврат на исходную позицию. Это означает, что в данном решении мы можем уменьшить продолжительность одного такта, что соответствует возможности увеличения тактовой частоты.
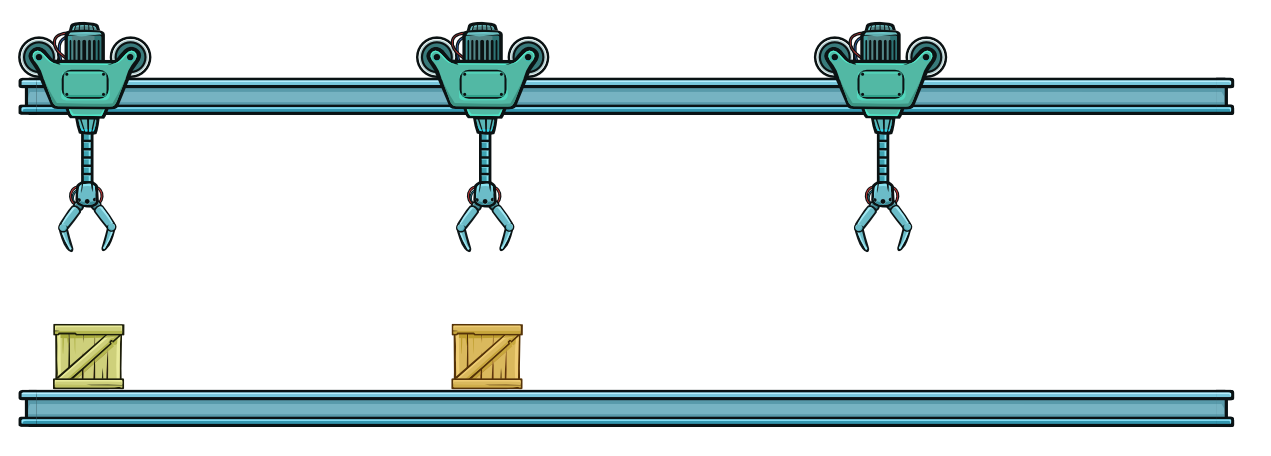
Первый такт закончился. Второй робот не готов взять оранжевый контейнер и передвинуть его на вторую треть пути.
Такт 2
Во втором такте второй робот начинает перемещать оранжевый контейнер, а первый робот подбирает желтый контейнер. Обратите внимание, что сотрудники склада добавили зеленый контейнер.
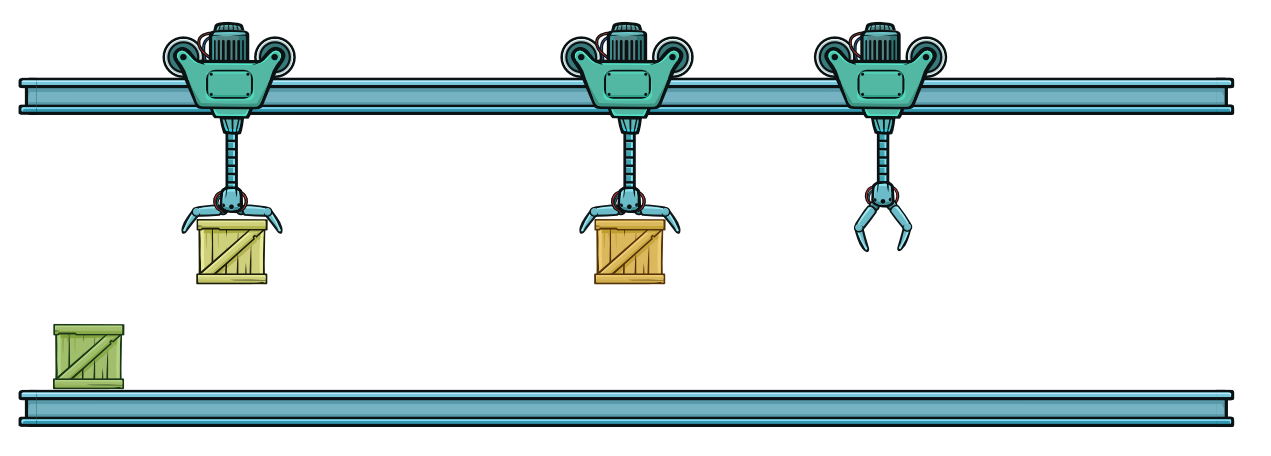
Первый и второй робот могут переносить контейнеры параллельно. Но они должны делать это синхронно, чтобы избежать столкновения. Это второй такт.
Когда второй такт завершен, оранжевый контейнер лежит перед третьим роботом. Второй робот может подобрать желтый контейнер. А третий робот подберет новый зеленый контейнер.
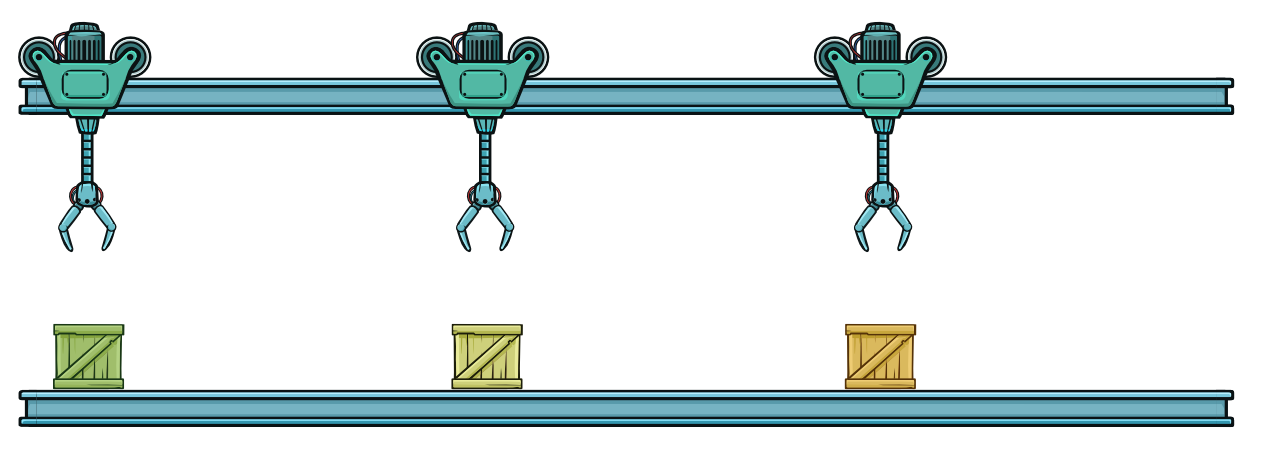
Второй такт завершен. Весь конвейер заполнен. В следующем такте все три робота будут работать параллельно.
Такт 3
На третьем такте все роботы двигаются синхронно, перемещая контейнеры на шаг вперед. Стоит немного поразмыслить о том, что здесь происходит. Время, необходимое для перемещения контейнера от начала до конца, практически не изменилось. Представьте, что одному роботу на перемещение от начала до конца требуется 30 секунд. Теперь перемещение контейнера занимает 10 секунд, но нужно три шага, а значит, общее время осталось неизменным.
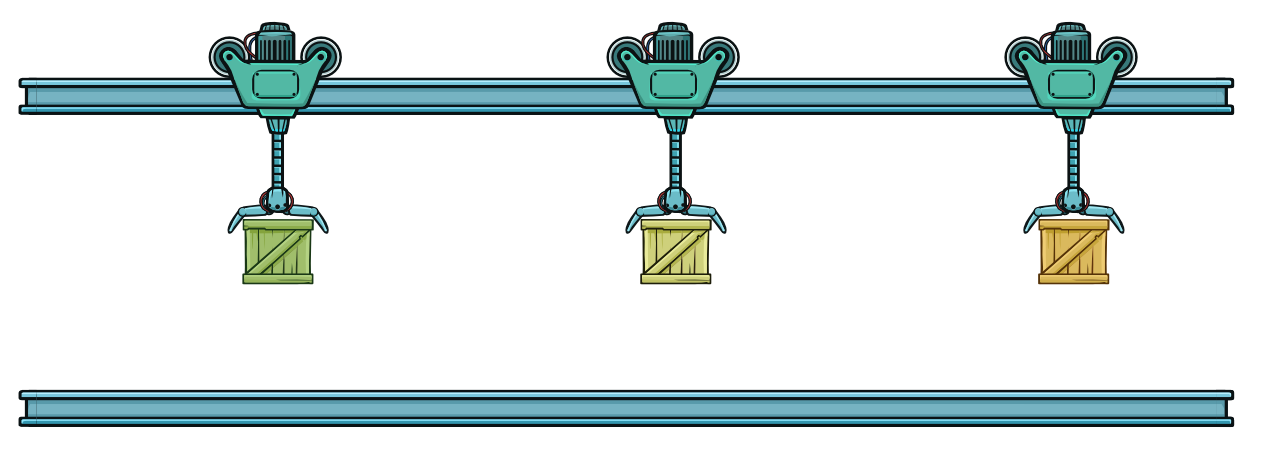
Все три робота перемещаются синхронно. Конвейер полностью заполнен и работает максимально эффективно, так как каждый такт робот доставляет один контейнер до конца и подбирает новый.
Итак, что мы здесь получили? Преимущество заключается в том, что каждые 10 секунд мы доставляем один контейнер. Мы сокращаем время, которое контейнер проводит в ожидании робота.
Преимущества и проблемы конвейеризации
Мы можем описать это двумя важными концепциями.
- Задержка — время, затрачиваемое на выполнение действия до его завершения. Это может быть, например, время, необходимое для получения сетевого пакета после того, как вы впервые его запросили. В нашем случае мы можем рассматривать это как время, затрачиваемое на полное выполнение инструкции после начала выполнения.
- Пропускная способность — это то, сколько данных, инструкций или других вещей мы можем обрабатывать за каждую единицу времени. На складе это будет количество посылок, доставленных за минуту. Для микропроцессора это число выполняемых инструкций за такт.
Пропускная способность увеличивается, потому что мы подбираем контейнер каждые десять секунд, а раньше это занимало 30 секунд. Мы увеличиваем пропускную способность с помощью параллельного выполнения задачи. Однако это не всегда возможно. Но именно так процессоры видеокарт достигают своей огромной производительности. Они не выполняют одиночные операции так же быстро, но они могут выполнять огромное количество однотипных задач одновременно, обеспечивая большую пропускную способность.
Для процессора большой параллелизм невозможен, поэтому важность конвейеризации увеличивается. Но, как мы видим на примере нашего склада, чтобы это работало хорошо, каждый робот должен двигаться примерно на одинаковое расстояние. В противном случае роботы не смогут двигаться синхронно. Таким образом, важно разбить процессорную инструкцию на несколько шагов равной длины.
RISC и CISC
Эта причина, по которой ранние процессоры RISC, такие как MIPS и SPARC, используемые на рабочих станциях Unix в 1990-х годах, были быстрее, чем их аналоги на x86. CISC-процессоры не учитывали конвейеризацию при проектировании, в отличие от RISC. Инструкции RISC разделены на четыре логических шага. Это позволяет построить конвейер на четыре шага. Получается, RISC-инструкция требует четыре такта на исполнение, но каждый такт завершается выполнением одной инструкции.
Дополнительное чтение: What Does RISC and CISC Mean in 2020?
Intel поняла, что нужно найти способ конвейеризации сложных инструкций переменной длины. Так были созданы микрооперации. Они разбивали сложные инструкции на несколько микроопераций, которые были достаточно простыми, чтобы работать в конвейере.
Дополнительное чтение: What the Heck is a Micro-Operation?
Дальнейшее развитие конвейеризации
Intel начала разделять свои инструкции на все меньшие части, что позволило компании резко увеличить тактовую частоту процессоров. Так, например, Pentium 4 имел зверскую частоту. Это сделало конвейеры Intel очень длинными.
И здесь мы сталкиваемся с вещью, о которой еще не упоминали, — с ветвлением. Можно заметить, что инструкции не приходят в виде одного бесконечного предсказуемого линейного потока. Реальные программы принимают решения и выполняют повторения. Некоторые инструкции повторяются снова и снова. Различные типы данных обрабатываются разными инструкциями. Следовательно, в реальных программах есть условные переходы. Проверяется некоторое условие, а затем на его основе микропроцессор выполняет переход в коде.
В чем проблема конвейерной обработки? Представьте, что у вас большой конвейер с сотней инструкций в обработке. Вы можете представить это как сто складских роботов, перемещающих сто контейнеров одновременно. Последняя инструкция — это инструкция условного перехода. В зависимости от результата микропроцессор может понять, что все сто инструкций, которые находятся в конвейере, не являются нужными. Предполагается, что мы собираемся выполнять другие инструкции, которые находятся где-то в памяти.
Таким образом, нужно очистить конвейер и ждать еще сто тактов, прежде чем другие инструкции заполнят конвейер до конца. Это большой удар по производительности.
Вот почему у Apple были слайды со сравнением RISC-чипов PowerPC, которые они использовали до 2006 года, с процессорами Intel Pentium. Процессор Pentium имел более высокую тактовую частоту, но и гораздо более длинный конвейер. Тогда люди считали тактовую частоту эквивалентом производительности. Как вы видим, эти термины связаны, но это не совсем одно и то же.
Процессоры Pentium часто очищали очень длинные конвейеры, что сильно снижало производительность. Между тем, чипы PowerPC имели более низкую тактовую частоту, но гораздо более короткие конвейеры, что приводило к значительно меньшему падению производительности из-за условных переходов.
Но это больше не проблема, с тех пор как мы начали использовать предиктор ветвлений (branch prediction, предсказатель переходов). Он позволяет угадывать, по какой ветви пойдет код, прежде чем выполнить инструкцию, проверяющую условие.
Но это, вероятно, будет темой следующей технической статьи.

