[Перевод] CPU-лимиты и агрессивный троттлинг в Kubernetes
Прим. перев.: эта поучительная история Omio — европейского агрегатора путешествий — проводит читателей от базовой теории до увлекательных практических тонкостей в конфигурации Kubernetes. Знакомство с такими случаями помогает не только расширять кругозор, но и предотвращать нетривиальные проблемы.
Доводилось ли вам сталкиваться с тем, что приложение «застревало» на месте, переставало отвечать на запросы о проверке состояния (health check’и) и вы не могли понять причину такого поведения? Одно из возможных объяснений связано с лимитом квот на ресурсы CPU. О нем и пойдет речь в этой статье.
TL; DR:
Мы настоятельно рекомендуем отказаться от CPU limit’ов в Kubernetes (или отключить квоты CFS в Kubelet), если используется версия ядра Linux с ошибкой CFS-квот. В ядре имеется серьезный и хорошо известный баг, который приводит к избыточному троттлингу и задержкам.
В Omio вся инфраструктура управляется Kubernetes. Все наши stateful- и stateless-нагрузки работают исключительно на Kubernetes (мы используем Google Kubernetes Engine). В последние полгода мы стали наблюдать рандомные подтормаживания. Приложения зависают или перестают отвечать на health check’и, теряют связь с сетью и т.п. Подобное поведение долго ставило нас в тупик, и, наконец, мы решили заняться проблемой вплотную.
Краткое содержание статьи:
- Несколько слов о контейнерах и Kubernetes;
- Как реализованы CPU request’ы и limit’ы;
- Как CPU limit работает в средах с несколькими ядрами;
- Как отслеживать троттлинг CPU;
- Решение проблемы и нюансы.
Несколько слов о контейнерах и Kubernetes
Kubernetes, по сути, является современным стандартом в мире инфраструктуры. Его основная задача — оркестровка контейнеров.
Контейнеры
В прошлом нам приходилось создавать артефакты вроде Java JAR’ов/WAR’ов, Python Egg’ов или исполняемых файлов для последующего запуска на серверах. Однако, чтобы заставить их функционировать, приходилось проделывать дополнительную работу: устанавливать среду выполнения (Java/Python), размещать необходимые файлы в нужных местах, обеспечивать совместимость с конкретной версией операционной системы и т.д. Другими словами, приходилось уделять пристальное внимание управлению конфигурациями (что часто служило причиной раздоров между разработчиками и системными администраторами).
Контейнеры всё изменили. Теперь артефактом выступает контейнерный образ. Его можно представить в виде этакого расширенного исполняемого файла, содержащего не только программу, но и полноценную среду выполнения (Java/Python/…), а также необходимые файлы/пакеты, предустановленные и готовые к запуску. Контейнеры можно развертывать и запускать на различных серверах без каких-либо дополнительных действий.
Кроме того, контейнеры работают в собственном окружении-песочнице. У них есть свой собственный виртуальный сетевой адаптер, своя файловая система с ограниченным доступом, своя иерархия процессов, свои ограничения на CPU и память и т. д. Все это реализовано благодаря особой подсистеме ядра Linux — namespaces (пространства имен).
Kubernetes
Как было сказано ранее, Kubernetes — это оркестратор контейнеров. Он работает следующим образом: вы предоставляете ему пул машин, а затем говорите: «Эй, Kubernetes, запусти-ка десять экземпляров моего контейнера с 2 процессорами и 3 Гб памяти на каждый, и поддерживай их в рабочем состоянии!». Kubernetes позаботится обо все остальном. Он найдет свободные мощности, запустит контейнеры и будет перезапускать их при необходимости, выкатит обновление при смене версий и т.д. По сути, Kubernetes позволяет абстрагироваться от аппаратной составляющей и делает все разнообразие систем пригодным для развертывания и работы приложений.

Kubernetes с точки зрения простого обывателя
Что такое request’ы и limit’ы в Kubernetes
Окей, мы разобрались с контейнерами и Kubernetes. Также мы знаем, что несколько контейнеров могут находиться на одной машине.
Можно провести аналогию с коммунальной квартирой. Берется просторное помещение (машины/узлы) и сдается нескольким арендаторам (контейнерам). Kubernetes выступает в роли риэлтора. Возникает вопрос, как удержать квартирантов от конфликтов друг с другом? Что, если один из них, скажем, решит занять ванную комнату на полдня?
Именно здесь в игру вступают request’ы и limit’ы. CPU Request нужен исключительно для планирования. Это нечто вроде «списка желаний» контейнера, и используется он для подбора самого подходящего узла. В то же время CPU Limit можно сравнить с договором аренды — как только мы подберем узел для контейнера, тот не сможет выйти за установленные пределы. И вот тут возникает проблема…
Как реализованы request’ы и limit’ы в Kubernetes
Kubernetes использует встроенный в ядро механизм троттлинга (пропуска тактов) для реализации CPU limit’ов. Если приложение превышает лимит, включается троттлинг (т.е. оно получает меньше тактов CPU). Request’ы и limit’ы для памяти организованы иначе, поэтому их легче обнаружить. Для этого достаточно проверить последний статус перезапуска pod’а: не является ли он «OOMKilled». С троттлингом CPU все не так просто, поскольку K8s делает доступными только метрики по использованию, а не по cgroups.
CPU Request
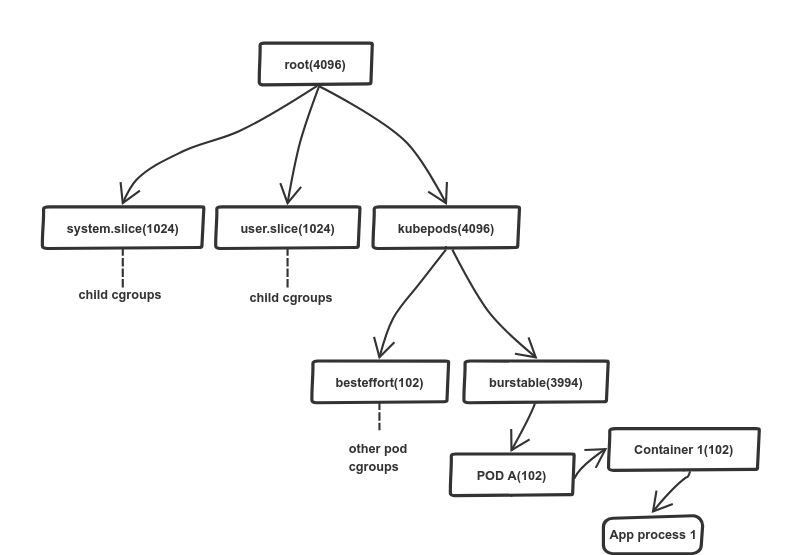
Как реализован CPU request
Для простоты давайте рассмотрим процесс на примере машины с 4-ядерным CPU.
K8s использует механизм контрольных групп (cgroups) для управления распределением ресурсов (памяти и процессора). Для него доступна иерархическая модель: потомок наследует limit’ы родительской группы. Подробности распределения хранятся в виртуальной файловой системе (/sys/fs/cgroup). В случае процессора это /sys/fs/cgroup/cpu,cpuacct/*.
K8s использует файл cpu.share для распределения ресурсов процессора. В нашем случае корневая контрольная группа получает 4096 долей ресурсов CPU — 100% доступной мощности процессора (1 ядро = 1024; это фиксированное значение). Корневая группа распределяет ресурсы пропорционально в зависимости от долей потомков, прописанных в cpu.share, а те, в свою очередь, аналогичным образом поступают со своими потомками, и т.д. В типичном узле Kubernetes корневая контрольная группа имеет три потомка: system.slice, user.slice и kubepods. Две первых подгруппы используются для распределения ресурсов между критически важными системными нагрузками и пользовательскими программами вне K8s. Последняя — kubepods — создается Kubernetes’ом для распределения ресурсов между pod’ами.
На схеме выше видно, что первая и вторая подгруппы получили по 1024 доли, при этом подгруппе kuberpod выделено 4096 долей. Как такое возможно: ведь корневой группе доступны всего 4096 долей, а сумма долей ее потомков значительно превышает это число (6144)? Дело в том, что значение имеет логический смысл, поэтому планировщик Linux (CFS) использует его для пропорционального распределения ресурсов CPU. В нашем случае первые две группы получают по 680 реальных долей (16,6% от 4096), а kubepod получает оставшиеся 2736 долей. В случае простоя первые две группы не будут использовать выделенные ресурсы.
К счастью, в планировщике есть механизм, позволяющий избежать потери неиспользуемых ресурсов CPU. Он передает «простаивающие» мощности в глобальный пул, из которого они распределяются по группам, нуждающимся в дополнительных мощностях процессора (передача происходит партиями, чтобы избежать потерь от округления). Аналогичный метод применяется и ко всем потомкам потомков.
Этот механизм обеспечивает справедливое распределение мощностей процессора и следит за тем, чтобы ни один процесс не «воровал» ресурсы у других.
CPU Limit
Несмотря на то, что конфигурации limit’ов и request’ов в K8s выглядят похоже, их реализация кардинально отличается: это самая вводящая в заблуждение и наименее задокументированная часть.
K8s задействует механизм квот CFS для реализации лимитов. Их настройки задаются в файлах cfs_period_us и cfs_quota_us в директории cgroup (там же расположен файл cpu.share).
В отличие от cpu.share, квота основана на периоде времени, а не на доступной мощности процессора. cfs_period_us задает продолжительность периода (эпохи) — это всегда 100000 мкс (100 мс). В K8s есть возможность изменить это значение, однако она пока доступна только в альфа-версии. Планировщик использует эпоху для перезапуска использованных квот. Второй файл, cfs_quota_us, задает доступное время (квоту) в каждой эпохе. Обратите внимание, что она также указывается в микросекундах. Квота может превышать продолжительность эпохи; другими словами, она может быть больше 100 мс.
Давайте рассмотрим два сценария на 16-ядерных машинах (наиболее распространенный тип компьютеров у нас в Omio):

Сценарий 1: 2 потока и лимит в 200 мс. Без троттлинга

Сценарий 2: 10 потоков и лимит в 200 мс. Троттлинг начинается после 20 мс, доступ к ресурсам процессора возобновляется еще через 80 мс
Допустим, вы установили CPU limit на 2 ядра; Kubernetes переведет это значение в 200 мс. Это означает, что контейнер может использовать максимум 200 мс процессорного времени без троттлинга.
И здесь начинается самое интересное. Как было сказано выше, доступная квота составляет 200 мс. Если у вас параллельно работают десять потоков на 12-ядерной машине (см. иллюстрацию к сценарию 2), пока все остальные pod’ы простаивают, квота будет исчерпана всего через 20 мс (поскольку 10×20 мс = 200 мс), и все потоки данного pod’а «зависнут» (throttle) на следующие 80 мс. Усугубляет ситуацию уже упомянутый баг планировщика, из-за которого случается избыточный троттлинг и контейнер не может выработать даже имеющуюся квоту.
Как оценить троттлинг в pod’ах?
Просто войдите в pod и выполните cat /sys/fs/cgroup/cpu/cpu.stat.
-
nr_periods— общее число периодов планировщика; -
nr_throttled— число throttled-периодов в составеnr_periods; -
throttled_time— совокупное throttled-время в наносекундах.
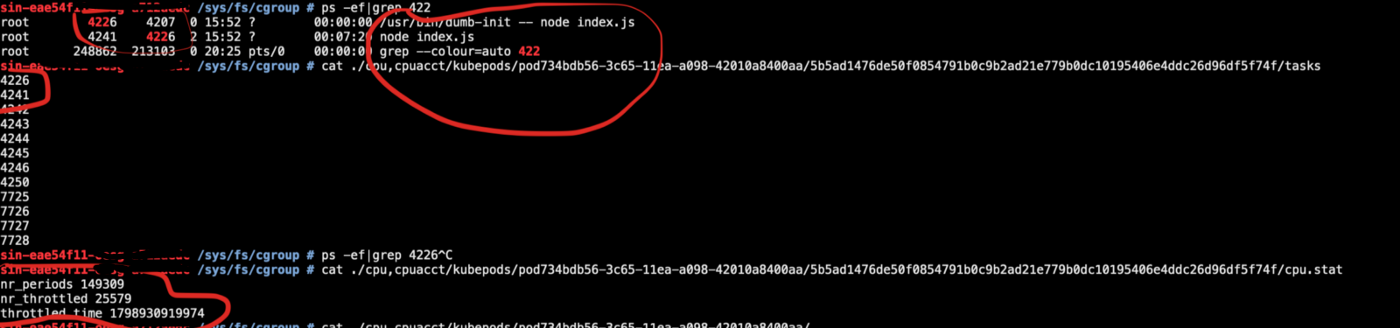
Что же на самом деле происходит?
В итоге мы получаем высокий троттлинг во всех приложениях. Иногда он в полтора раза сильнее расчетного!
Это приводит к различным ошибкам — сбоям проверок готовности (readiness), зависаниям контейнеров, разрывам сетевых подключений, таймаутам внутри сервисных вызовов. В конечном счете это выражается в увеличенной задержке и повышении количества ошибок.
Решение и последствия
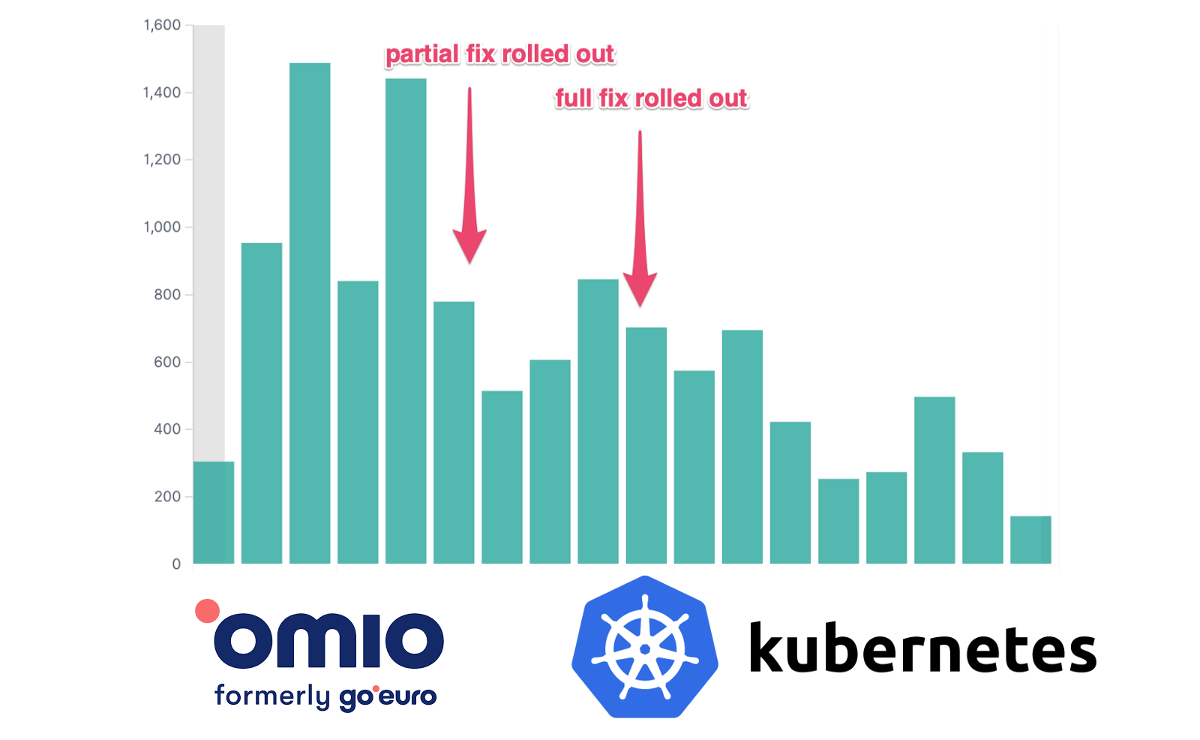
Тут все просто. Мы отказались от limit’ов CPU и занялись обновлением ядра ОС в кластерах на самую свежую версию, в которой баг был исправлен. Число ошибок (HTTP 5xx) в наших сервисах сразу же значительно упало:
Ошибки HTTP 5xx
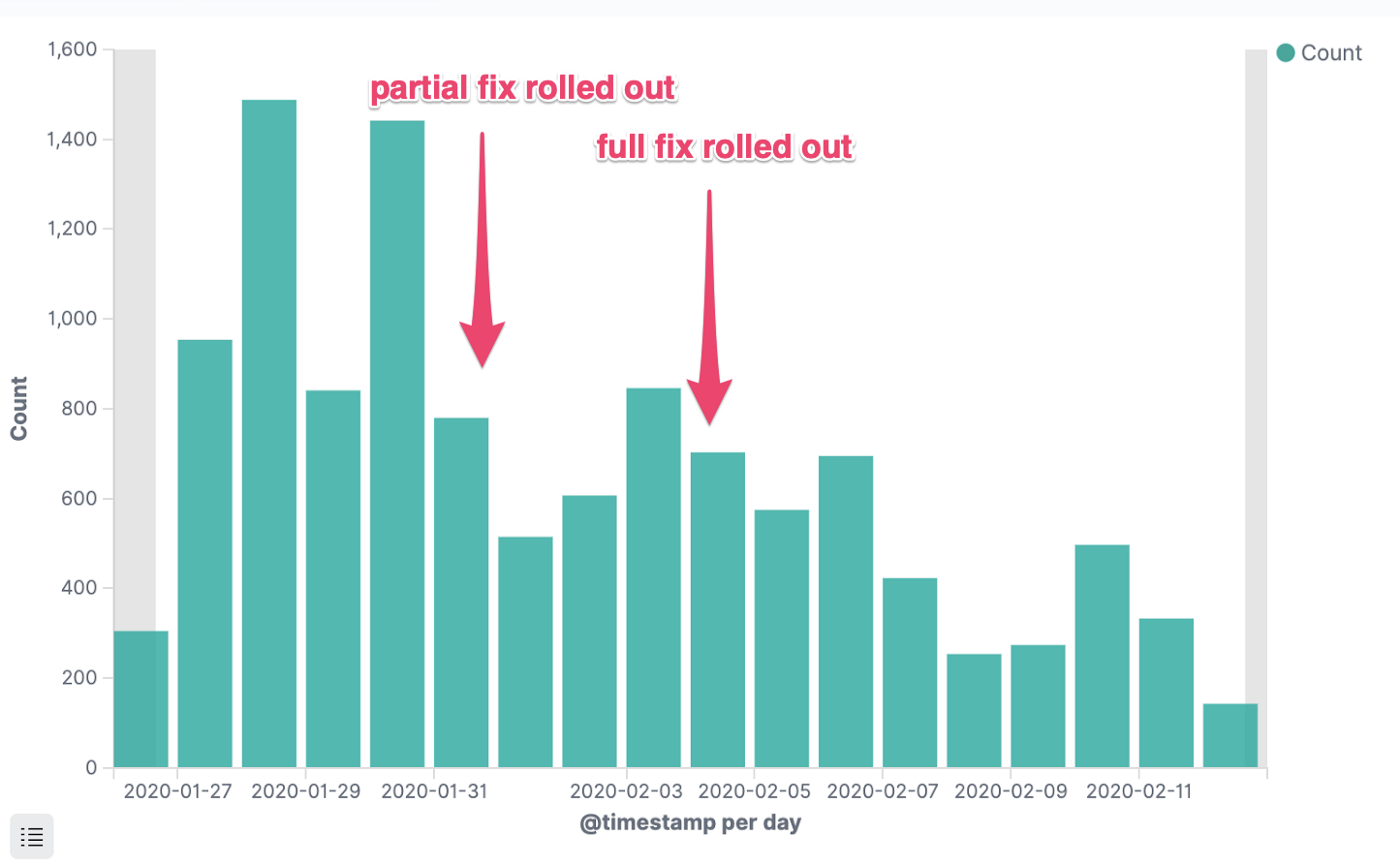
Ошибки HTTP 5xx одного критически важного сервиса
Время отклика p95
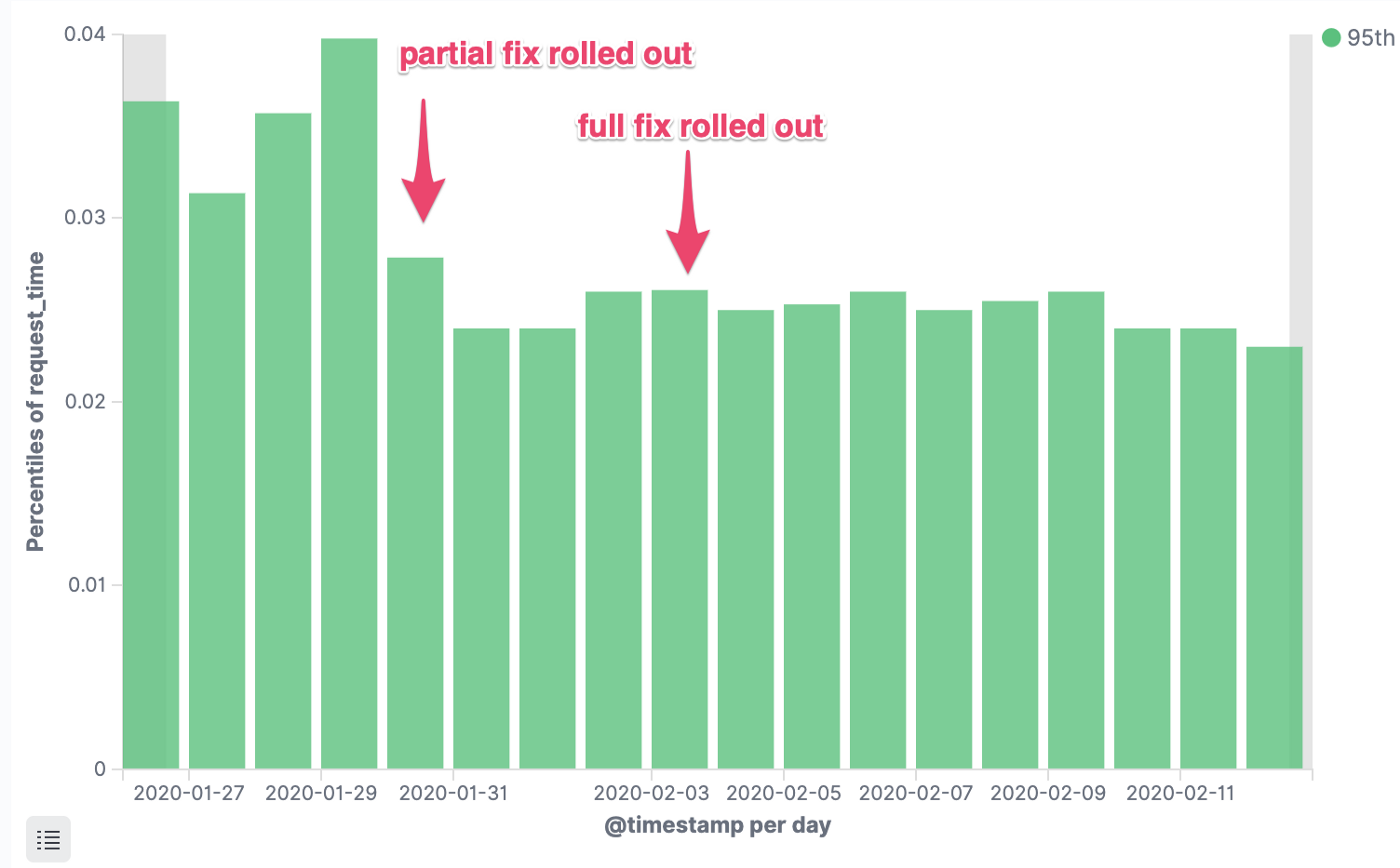
Задержка запросов критически важного сервиса, 95-я процентиль
Расходы на эксплуатацию

Число потраченных экземпляро-часов
В чем подвох?
Как было сказано в начале статьи:
Можно провести аналогию с коммунальной квартирой… Kubernetes выступает в роли риэлтора. Но как удержать квартирантов от конфликтов друг с другом? Что, если один из них, скажем, решит занять ванную комнату на полдня?
Вот в чем подвох. Один нерадивый контейнер может поглотить все доступные ресурсы процессора на машине. Если у вас толковый стек приложений (например, должным образом настроены JVM, Go, Node VM), тогда это не проблема: можно работать в таких условиях в течение длительного времени. Но если приложения оптимизированы плохо или совсем не оптимизированы (FROM java:latest), ситуация может выйти из-под контроля. У нас в Omio имеются автоматизированные базовые Dockerfiles с адекватными настройками по умолчанию для стека основных языков, поэтому подобной проблемы не существовало.
Мы рекомендуем наблюдать за метриками USE (использование, насыщение и ошибки), задержками API и частотой появления ошибок. Следите за тем, чтобы результаты соответствовали ожиданиям.
Ссылки
Такова наша история. Следующие материалы сильно помогли разобраться в том, что происходит:
Отчеты об ошибках Kubernetes:
Сталкивались ли вы с подобными проблемами в своей практике или обладаете опытом, связанным с троттлингом в контейнеризованных production-средах? Поделитесь своей историей в комментариях!
P.S. от переводчика
Читайте также в нашем блоге:
