[Перевод] Cognitive Services & LUIS: Введение в распознавание естественного языка

Для начала небольшая справка. Службы Microsoft Cognitive Services (разработанные подразделением Microsoft Research) облегчают работу с интеллектуальными алгоритмами. Даже специалисты, незнакомые с теорией исследования данных, смогут без труда использовать готовые API для аналитики приложений.
Обработка лингвистической информации охватывает распознавание речи, перевод, анализ эмоциональной окраски высказываний, резюмирование (возможно также в Microsoft Word), формирование языка и так далее. Службы Microsoft Cognitive Services предлагают более 20 API, предназначенных для решения этих задач.
Надеемся, что эта статья поможет вам понять, как работают технологии распознавания речи в Microsoft Cognitive Services.
Примечание. В статье не объясняется, как использовать эти интерфейсы. Соответствующие инструкции приведены в официальной документации (Linguistic Analysis API, LUIS).
Linguistic Analysis API
Этот API предоставляет фундаментальные возможности синтаксического анализа языка. Он возвращает результат синтаксического анализа исходных предложений в формате json после выполнения следующих операций.
- Поиск доступных анализаторов (вызов REST API).
- Выполнение анализа (синтаксического анализа) посредством выбранного анализатора (вызов REST API).
В настоящее время доступны три типа лингвистических анализаторов.
Анализатор лексем (PennTreebank3 — регулярные выражения)
Это самый простой анализатор, который разбивает предложения на лексемы.
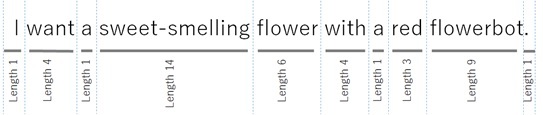
Ниже представлен результат назначения лексем в предложении I want a sweet-smelling flower with a red flowerbot («Мне нужен ароматный цветок в красном горшке»).
В нём упущена масса полезной информации, но этот анализатор можно использовать вместе с другими (указав несколько анализаторов в одном вызове API) и из общих результатов получить недостающие данные.
{
"analyzerId": "08ea174b-bfdb-4e64-987e-602f85da7f72",
"result": [
{
"Len": 52,
"Offset": 0,
"Tokens": [
{
"Len": 1,
"NormalizedToken": "I",
"Offset": 0,
"RawToken": "I"
},
{
"Len": 4,
"NormalizedToken": "want",
"Offset": 2,
"RawToken": "want"
},
{
"Len": 1,
"NormalizedToken": "a",
"Offset": 7,
"RawToken": "a"
},
{
"Len": 14,
"NormalizedToken": "sweet-smelling",
"Offset": 9,
"RawToken": "sweet-smelling"
},
{
"Len": 6,
"NormalizedToken": "flower",
"Offset": 24,
"RawToken": "flower"
},
{
"Len": 4,
"NormalizedToken": "with",
"Offset": 31,
"RawToken": "with"
},
{
"Len": 1,
"NormalizedToken": "a",
"Offset": 36,
"RawToken": "a"
},
{
"Len": 3,
"NormalizedToken": "red",
"Offset": 38,
"RawToken": "red"
},
{
"Len": 9,
"NormalizedToken": "flowerbot",
"Offset": 42,
"RawToken": "flowerbot"
},
{
"Len": 1,
"NormalizedToken": ".",
"Offset": 51,
"RawToken": "."
}
]
}
]
}
Предложение не только разделяется пробелами и пунктуационными знаками, но и делится на лексемы согласно контексту. Например, API может правильно разбить на лексемы фразу what’s your name? (то же самое, что и what is your name? ), Mr. Williams (это не пунктуационный знак) и так далее.
Анализатор частеречной разметки (PennTreebank3 — cmm)
Чтобы извлечь ключевые слова и проанализировать предложение, обычно нужно идентифицировать части речи (существительное, глагол и так далее). Например, если требуется выделить ключевые слова с эмоциональной окраской и оценить эмоциональный фон, ключевым словом должно быть прилагательное.
Анализатор частеречной разметки определяет данные теги. Ниже представлен результат обработки анализатором введенного предложения I want a sweet-smelling flower with a red flowerbot.
{
"analyzerId": "4fa79af1-f22c-408d-98bb-b7d7aeef7f04",
"result": [
[
"PRP",
"VBP",
"DT",
"JJ",
"NN",
"IN",
"DT",
"JJ",
"NN",
"."
]
]
}
PRP: личное местоимение.
VBP: глагол.
DT: определяющее слово.
JJ: прилагательное.
NN: существительное в единственном или множественном числе.
IN: предлог или подчинительный союз.
Подробнее можно узнать в статье «Теги частей речи Penn Treebank — Penn (Университет Пенсильвании)».
Тег назначается не только по словам, но и по контексту. Например, слово dog обычно выступает в роли существительного, но используется как глагол в следующем предложении (пример взят из раздела Википедии «Частеречная разметка»). Анализатор разметки подходит для этого примера. В анализе разметки допускаются простые ошибки.
The sailor dogs the hatch («Моряк задраивает люк»).
Анализатор грамматики составляющих (PennTreebank3 — SplitMerge)
Предположим, вам принадлежит цветочный интернет-магазин и в нем настроена интеллектуальная поисковая система. Покупатели могут ввести следующие запросы.
«Мне нужен красный ароматный цветок» (I want a red and sweet-smelling flower).
«Мне нужен ароматный цветок, но не красный» (I want a sweet-smelling flower except for red flowers).
«Мне нужен ароматный цветок в красном горшке» (I want a sweet-smelling flower with a red flowerbot).
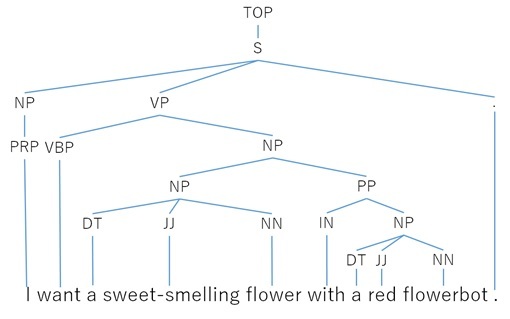
Мы видим, что в каждом предложении описываются совершенно разные объекты. Но если вы используете анализатор частеречной разметки (предыдущий), то не заметите разницы. В этом случае понадобится анализатор грамматики составляющих. Ниже представлен результат обработки анализатором того же самого предложения I want a sweet-smelling flower with a red flowerbot («Мне нужен ароматный цветок в красном горшке»).
{
"analyzerId": "22a6b758-420f-4745-8a3c-46835a67c0d2",
"result": [
"(TOP (S (NP (PRP I)) (VP (VBP want) (NP (NP (DT a) (JJ sweet-smelling) (NN flower)) (PP (IN with) (NP (DT a) (JJ red) (NN flowerbot))))) (. .)))"
]
}
S: простое повествовательное предложение.
NP: именное словосочетание.
VP: глагольное словосочетание.
PRP: личное местоимение.
VBP: глагол.
PP: предложное словосочетание.
DT: определяющее слово.
JJ: прилагательное.
NN: существительное в единственном или множественном числе.
IN: предлог или подчинительный союз.
Подробнее можно узнать в статье «Penn Treebank II Tags — MIT».
Как мы видим, в результате получается древовидная структура. Например, «в красном горшке» — это подчинительное словосочетание для «ароматного цветка».
Интеллектуальная служба распознавания речи (LUIS)
Анализатор грамматических составляющих (предыдущий) выдает много полезной информации, но вам по-прежнему будет сложно понять древовидную структуру в программном коде.
Интеллектуальная служба распознавания речи (LUIS) предназначена не только для синтаксического анализа, как API лингвистического анализа. Она дает прямой ответ на некоторые сценарии приложения, связанные с пониманием языка, и позволяет использовать ваш программный код в бизнес-логике приложения.
Предположим, к примеру, что у вас есть приложение для бронирования авиабилетов. Его интерфейс содержит форму с полями «Пункт отправления», «Пункт прибытия» и «Дата/время». С помощью LUIS вы можете извлечь введенные значения из предложений на естественном языке (например, «Мне нужен рейс из Екатеринбурга в Москву на 23 июля»). LUIS прекрасно подходит для решения задач на понимание языка. Например, эта служба позволяет напрямую извлечь следующие значения (пункт отправления, пункт прибытия, дата/время), заключенные в скобки.
- Забронировать рейс из {Екатеринбург} в {Москва} на {29.10.2016}.
- Забронируйте мне рейс до {Москва} на {29 октября}.
- Мне нужен рейс из {Екатеринбург} до {Москва} {следующая суббота}.
- И так далее.
Примечание. Как мы видим, во втором примере не введено значение «пункт отправления». Но в этом случае можно понять, каких параметров не хватает (их нужно ввести) для обработки с помощью LUIS, и попросить пользователя добавить нужные сведения.
При использовании LUIS сначала нужно зарегистрировать сценарии («намерение»), например «Забронировать рейс», «Узнать погоду» и так далее. Далее для каждого намерения следует зарегистрировать образцы предложений («выражения») и обучить результат. (Когда вы нажимаете кнопку «Обучить», LUIS изучает шаблон.)
Теперь можно использовать конечную точку вызова REST LUIS. REST выдаст в формате jason результат, совпадающий с зарегистрированным намерением.
Примечание. LUIS активно обучается, благодаря чему можно корректировать неразмеченные предложения.
LUIS понимает не только слова, но и контекст предложения. Например, если ввести «Забронируйте рейс «туда-то» на 29 октября», слово «туда-то» будет проанализировано как пункт назначения. В LUIS нужно заранее получить зарегистрированное намерение. Поэтому данная служба не подходит для решения специфических задач, например поиска по естественному языку, ответов на особые вопросы (особые переписки) и так далее. Более того, LUIS только извлекает целевые ключевые фразы, но не анализирует их. Рассмотрим следующий пример.
«Мне нужен красный горшок, который сочетается с красными цветами для моей мамы».
LUIS может извлечь фразу «горшок, который сочетается с красными цветами» как ключевую, но это не то же самое, что «горшок и красные цветы». Если вы хотите проанализировать эту фразу, то есть изучить потребности конкретного клиента, используйте API лингвистического анализа.
Примечание. Название API анализа текста в службах Microsoft Cognitive Services напоминает о синтаксическом анализе языка, но этот API просто оценивает эмоциональную окраску (удовлетворенность или неудовлетворенность человека). Помните, что этот интерфейс не анализирует эмоции (радость, грусть, злость и так далее), как это делает API эмоций (тоже из Microsoft Cognitive Services), и в результате мы получаем скалярное значение (степень эмоциональной окраски). Также вы можете извлечь ключевую фразу, которая влияет на эмоциональную окраску. Например, если вы запишете голос клиента и захотите выяснить, что ему не нравится в ваших услугах, то сможете узнать вероятные причины недовольства, выделив ключевые фразы («помещение», «сотрудники» и так далее).
Кстати, несколько дней назад вышла новость про обновления в Cognitive Services и два кейса их применения: Human Interact использует CRIS и LUIS, для того, чтобы люди могли общаться в виртуальном мире; Prism Skylab использует Computer Vision API для анализа изображений с камер безопасности для определения специфичных событий.
Последние статьи
1. Разработка на R: тайны циклов.
2. Как выбирать алгоритмы для машинного обучения Microsoft Azure (напоминаем, что Azure можно попробовать бесплатно).
3. Цикл статей «Deep Learning».
Если вы увидели неточность перевода, сообщите, пожалуйста, об этом в личные сообщения.
