[Перевод] CI/CD для изменений в БД
В контексте DevOps, Continuous Integration and Continuous Delivery (CI/CD) становятся ключевыми компонентами в управлении жизненным циклом программного обеспечения. CI/CD вносит в процесс разработки цикличность и обратную связь, что способствует инновациям и постоянным улучшениям, а также обеспечивает быструю адаптацию продукта к меняющимся требованиям рынка. Это позволяет не только отвечать на потребности клиентов, но и повышать их удовлетворённость. Принятие культуры Agile в командах разработки приводит к увеличению их гибкости, адаптивности и скорости в создании качественных инкрементных продуктов, фокусируясь на непрерывном совершенствовании и инновациях.
Однако, изменения в программном обеспечении неизбежно затрагивают и базы данных, что представляет собой своего рода вызов при интеграции с DevOps, где автоматизация играет критическую роль в конвейерах CI/CD. Автоматизированное управление изменениями баз данных обеспечивает поддержку актуальности схемы данных в течение всего процесса доставки и развёртывания, что важно для предотвращения проблем в производственной среде.
Цель этой статьи — подчеркнуть значимость управления изменениями баз данных как интегральной части процесса CD, а также предложить рекомендации по оптимизации процессов, которые улучшают синхронизацию между кодом приложения и изменениями в БД в рамках единого конвейера доставки.
Непрерывная интеграция
Основополагающим аспектом подхода Agile в разработке программного обеспечения является принцип непрерывной интеграции. Этот принцип акцентирует внимание на важности постоянного слияния вносимых изменений в код от разных разработчиков команды, что предотвращает проблемы совместимости, ранее известные как «integration hell». В прошлом разработчики часто работали изолированно над своими модулями и объединяли их только по завершении всех задач, что приводило к значительным трудностям с интеграцией. CI обеспечивает постоянное объединение рабочих процессов с помощью независимых сред сборки, автоматизации процессов сборки и тестирования. Это позволяет ускорить разработку за счет регулярного тестирования и применения частых и мелких коммитов в главную ветку системы управления версиями, будь то мастер бранч или транк.
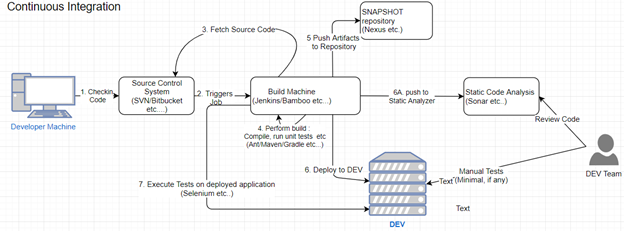
Процесс CI
Изображенная выше схема отображает характерный процесс непрерывной интеграции. При коммите кода разработчиком в систему контроля версий автоматически запускается процесс сборки, который настроен на сервере CI. Этот процесс включает в себя извлечение последних изменений из системы контроля версий, выполнение сборки, проведение серии тестов и публикацию результирующих артефактов, таких как JAR-файлы, в специализированное хранилище артефактов. Кроме того, могут быть запланированы периодические задачи CI, которые осуществляют деплоймент кода в разработочную среду, интеграцию с инструментами статического анализа, запуск системных тестов на развёрнутом коде или другие автоматизированные операции, считающиеся командой ценными для поддержания качества кодовой базы. В рамках Agile-методологии команда несёт ответственность за оперативное устранение любых ошибок, возникающих в ходе этих автоматизированных процедур, и предотвращение внесения новых изменений в кодовую базу до тех пор, пока не будет исправлена автоматизированная сборка.
Непрерывная доставка
Концепция непрерывной доставки является расширением принципов непрерывной интеграции, внося дополнительные аспекты в процесс разработки. Она не только поддерживает непрерывное слияние компонентов программной системы, но и обеспечивает постоянную готовность кода к развёртыванию в производственной среде. Это подразумевает, что помимо автоматизированных сборок и тестовых процедур должен существовать также автоматизированный механизм для доставки программного продукта на производство. С помощью автоматизации достигается способность быстро развертывать программное обеспечение, часто всего за несколько минут и одним кликом. CD, являющаяся ключевым элементом культуры DevOps, предоставляет неоспоримые выгоды, включая упорядоченность процесса развёртывания, уменьшение рисков при внедрении новых возможностей, ускорение обратной связи от пользователей и, в конечном итоге, повышение общего качества программного продукта.
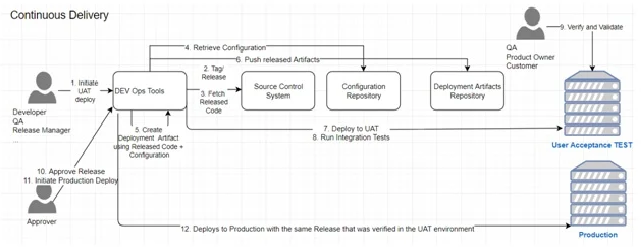
Типичный процесс CD
Приведенная диаграмма демонстрирует стандартный цикл непрерывной доставки, исходя из предпосылки, что уже реализована система CI. На этой схеме представлены два типа сред: User Acceptance Testing (UAT) и производственная среда. Тем не менее, стоит отметить, что в зависимости от специфики каждой организации может существовать ряд дополнительных этапов развертывания, включая тестирование качества (QA), стресс-тестирование, предпроизводственную подготовку и прочее, прежде чем программное обеспечение достигнет производственной стадии. Несмотря на это, используется единая кодовая база и, что более важно, одна и та же версия этой кодовой базы для развертывания во всех средах. Процесс развертывания, как в тестовых средах, так и в производственной, осуществляется посредством единой автоматизированной системы. Существует множество инструментов для управления конфигурациями и автоматизации процессов развертывания, которые обладают функциями управления, повторяемости, надежности, возможности аудита и отката. Хотя подробное рассмотрение этих инструментов выходит за рамки данного текста, важно подчеркнуть необходимость наличия автоматизированной системы для запуска программного обеспечения в производственную среду по мере необходимости.
Управление модификациями баз данных является критической точкой в процессе развертывания ПО
Современные Agile-методики широко применяются для разработки кода приложений, но их внедрение в области управления базами данных и практики непрерывной интеграции заметно отстают. Поскольку база данных является интегральной частью большинства корпоративных систем, успешная реализация проектных задач включает в себя работу с БД наряду с разработкой приложений. Задержки в модификации баз данных, такие как изменения схемы, могут существенно замедлить выпуск обновлений.
В данной статье мы исходим из предположения, что под базой данных понимается реляционная БД. Процессы управления изменениями будут существенно отличаться в случае использования нереляционных баз данных, таких как колоночные, документоориентированные или ключ-значение и графовые БД.
Приведу пример из практики: команда разработчиков, использующая Agile и работающая по Scrum с двухнедельными спринтами, сталкивается с задачей добавления нового поля в документ, который обменивается с подсистемой. Разработчики оценили эти изменения в 1 стори-поинт, так как они затрагивают лишь небольшие корректировки в слое доступа к данным для работы с новым полем и его извлечения во время бизнес-события. Однако потребуется добавление нового столбца в уже существующую таблицу. Без необходимости вносить изменения в базу данных, задача была бы легко выполнима в рамках текущего спринта, но изменения базы данных заставляют разработчиков считать, что решить её в течение спринта невозможно.
Почему это происходит? Потому что запрос на изменение схемы базы данных должен быть одобрен администраторами баз данных (DBA). DBA нужно время на то, чтобы оценить данный запрос на изменение и сопоставить его с другими запросами, поступающими от различных команд разработки. После внесения изменений в разработочную базу данных, DBA уведомят разработчиков, которые должны будут дать обратную связь перед тем, как изменения будут перемещены в среду QA и далее, если это необходимо. Разработчики протестируют новую схему с измененным кодом, и, в конце концов, команда разработки будет работать в тесном контакте с DBA для координации внедрения изменений приложения и базы данных в производственную среду.
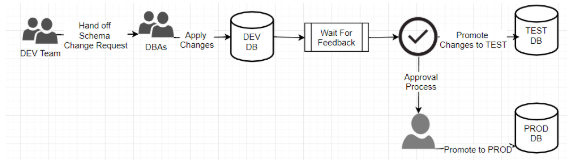
Иллюстрация ручного или полуавтоматического процесса доставки изменений БД
Обратите внимание на представленную выше схему, которая показывает, что начало процесса не инициируется загрузкой кода разработчиком, а скорее предполагает взаимодействие между двумя разными командами. Даже в случае, когда процесс деплоя в области баз данных автоматизирован, он все еще не является частью интегрированного пайплайна доставки кода приложения.
Изменения в коде приложения тесно связаны с изменениями в базе данных, и в совокупности они формируют релиз, который обеспечивает ценные функциональные возможности для клиента. Отсутствие одной из этих частей делает другую не только бесполезной, но также может привести к регрессии функционала. Тем не менее, жизненный цикл этих двух видов изменений полностью независим друг от друга. Это разделение жизненных циклов изменений в БД и кодовой базе, а также наличие переходов и ручных проверочных этапов в процессе, нарушает непрерывность процесса доставки в данном контексте.
Рекомендации по улучшению CI/CD для модификаций в базах данных
В последующих разделах мы разъясним методы устранения текущих недостатков и подходы к интеграции задач, связанных с базами данных, таких как проектирование данных и модификация схемы, в процедуру непрерывной интеграции и доставки.
Интеграция DBA в мультидисциплинарные Agile-команды
Во множестве организаций DBA делятся на две основные категории ролей, в зависимости от их участия в создании базы данных для команд разработчиков приложений или их ответственности за поддержание операционных БД. Администраторы баз данных в продакшене фокусируются на обеспечении непрерывной работоспособности операционных баз данных, выполняют мониторинг, обновления, патчинг, управление хранилищем, резервное копирование и восстановление и прочие задачи. В то время как разработчики баз данных работают в тесном сотрудничестве с командами разработки приложений, помогая в проектировании моделей данных, трансформации логических моделей данных в физические схемы баз данных и оценке потребностей в хранилище данных и так далее.
Для эффективной интеграции процессов работы с базами данных и разработки приложений в единую непрерывную цепочку доставки, крайне важно включить разработчиков БД в состав команды разработки. Разработчики с полным стеком навыков в команде, обладающие глубокими знаниями в области баз данных, также могут выполнять роль разработчиков баз данных.
БД как код
Для успешной интеграции модификаций базы данных с прикладным кодом в единую систему CD, требуется обработка изменений БД аналогично изменениям прикладного кода. Это означает необходимость составления скриптов для каждой модификации базы данных и их систематического сохранения в версионируемом хранилище. Кроме того, должна существовать возможность автоматизированного развертывания новых экземпляров базы данных из данных скриптов по мере необходимости.
Чтобы представить объекты базы данных в форме кода, необходимо сначала провести классификацию и оценку каждого типа объекта, чтобы определить, необходимо ли и каким образом их следует преобразовать в скрипты (код). Ниже представлена общая классификация:
Архитектура БД
Она определяет структурирование данных, сохраняемых в базе данных, и известна также как схема БД. Включает в себя определение таблиц, представлений, ограничений, индексов и пользовательских типов данных. Словарь данных также может быть рассмотрен в качестве элемента архитектуры базы данных.
Код, хранящийся в БД
Этот код очень напоминает прикладной код, но он размещается и выполняется непосредственно внутри базы данных. К этой категории относятся хранимые процедуры, функции, пакеты, триггеры и другие подобные объекты.
Справочные данные
Под этим термином понимается набор предопределенных значений, используемых для связи с другими таблицами, содержащими бизнес-данные. Идеально, таблицы со справочными данными имеют ограниченное число записей и не подвержены значительным изменениям в течение жизненного цикла приложения. Они могут модифицироваться в связи с изменениями бизнес-процессов, но обычно остаются стабильными в ходе регулярной бизнес-деятельности.
Операционные или бизнес-данные
Это информация, генерируемая и записываемая приложением в процессе регулярной бизнес-деятельности. Основная задача любой системы управления базами данных — именно хранение этих данных. Все остальные типы объектов базы данных существуют исключительно для поддержки этой ключевой функции.
Из всех перечисленных категорий объектов базы данных первые три должны быть зафиксированы в виде скриптов и управляемы с помощью системы контроля версий.
TYPE | EXAMPLE | SCRIPTED (STORED LIKE CODE?) |
|---|---|---|
Database Structure | Schema Objects like Tables, Views, Constraints, Indexes, etc. | Yes |
Stored Code | Triggers, Procedures, Functions, Packages, etc. | Yes |
Reference Data | Codes, Lookup Tables, Static data, etc. | Yes |
Business/Application Data | Data generated from day-to-day business operations | No |
Как указано в представленной таблице, бизнес-данные или операционные данные являются единственным типом данных, которые не подлежат сценарному представлению или сохранению в виде кода. Процессы такие как откат изменений, версионирование и архивация управляются самой базой данных. Однако существует исключение: в случаях, когда модификация архитектуры базы данных требует миграции данных — например, заполнение нового столбца или перенос данных из основной таблицы в нормализованную — скрипт миграции должен быть оформлен как код и проходить те же этапы жизненного цикла, что и изменения архитектуры.
Рассмотрим на примере очень простой структуры данных, каким образом сценарии могут быть оформлены и сохранены в качестве кода. Данная структура настолько элементарна и часто встречается в демонстрационных материалах, что её можно сравнить с «Hello, World!» в мире моделирования данных.
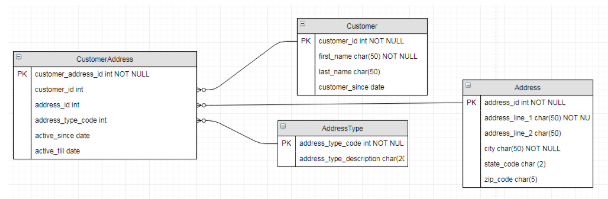
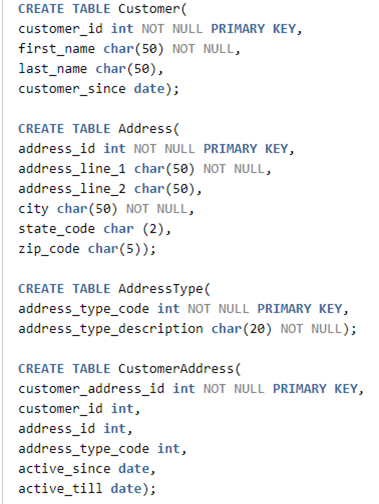
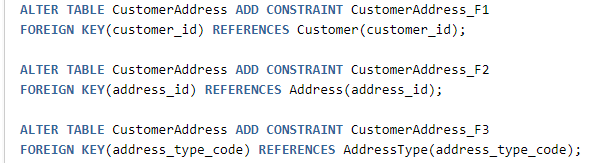
Образец модели, включающей в себя таблицы с операционными данными и таблицы со справочной информацией
В предложенной модели существует возможность ассоциировать клиента с множеством адресов, включая, но не ограничиваясь, платежный адрес и адрес доставки. Таблица AddressType предназначена для хранения разнообразных категорий адресов, например, платежного, для доставки, домашнего, рабочего и так далее. Записи в таблице AddressType можно рассматривать как справочные данные, так как они не подразумевают частого изменения в ходе ежедневных операций бизнеса. В то же время, другие таблицы заняты хранением операционных данных, объем которых расширяется вместе с ростом клиентской базы бизнеса.
Примеры
Tables:
Constraints:
Reference Data

Мы не будем вдаваться в подробности каждого вида объектов базы данных. Наша цель — показать, что все элементы БД, кроме операционных данных, могут быть и действительно должны быть представлены в форме SQL-скриптов.
Ведение версий артефактов базы данных в одном репозитории с прикладным кодом
Размещение управления версиями артефактов базы данных в том же системном репозитории, что и прикладной код, несет в себе ряд преимуществ. Это позволяет выполнять маркировку и релизы синхронно, так как изменения в схеме базы данных часто сопровождаются изменениями в прикладном коде, в совокупности формируя единый релиз. Такой подход также уменьшает риск расхождения версий прикладного кода и структуры базы данных. Кроме того, это улучшает общую наглядность проекта. Новым участникам команды будет значительно проще ориентироваться в проекте, когда все его компоненты сосредоточены в едином месте.
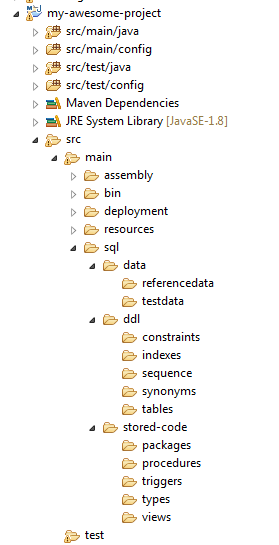
Образец структуры проекта Java Maven, включающего код для базы данных
На скрине выше демонстрируется, как можно организовать хранение скриптов базы данных вместе с кодом приложения. Примером служит Java-приложение, организованное в виде Maven-проекта. Тем не менее, данная методология не ограничивается конкретными технологиями разработки приложений. Будь то Ruby-приложение или система на .NET, мы структурируем файлы базы данных в формате скриптов рядом с исходным кодом приложения. Это облегчает автоматизированным инструментам CI/CD процесс поиска необходимых файлов в едином месте для выполнения операций, таких как инициализация структуры БД с нуля или создание миграционных скриптов для деплоя в рабочую среду.
Включение скриптов базы данных в процесс автоматизированной сборки
Осуществление интеграции артефактов базы данных в скрипты автоматизированной сборки является ключевым аспектом для синхронизации изменений данных и прикладного кода в рамках единого процесса доставки. Артефакты БД, обычно представленные в форме SQL-скриптов, могут быть исполнены в рамках сборки при помощи широкого спектра инструментов, которые либо имеют встроенную функциональность для работы с SQL, либо поддерживают её через дополнительные модули.
Мы не будем детализировать особенности каждого инструмента сборки, однако перечислим основные операции, которые необходимо выполнить в ходе сборки, как в локальной разработке, так и в серверных средах CI. Подробности процессов сборки в предпродакшен и продакшен средах будут рассмотрены отдельно.
К типовым задачам сборки относятся:
Удаление существующей схемы
Создание новой схемы
Определение структуры базы данных, включая таблицы, ограничения, индексы, последовательности и синонимы
Развертывание хранимого кода, включая процедуры, функции, пакеты и прочее
Загрузка справочных данных
Загрузка тестовых данных
Эти операции обычно производятся на этапе перед началом интеграционного тестирования, что обеспечивает подготовку БД в стабильное состояние с предварительно определенным набором данных. Наличие достаточного количества интеграционных тестов позволяет обнаружить любые несоответствия между прикладным кодом и моделью данных, что в свою очередь способствует обеспечению постоянной интеграции базы данных с прикладным кодом. Это является основой для реализации CD, включающей управление изменениями БД.
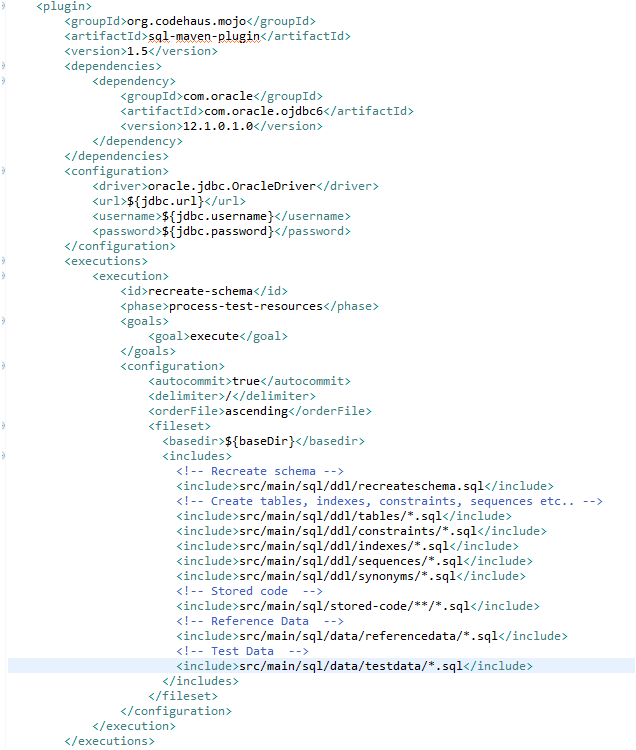
Скриншот фрагмента кода, показывающий сборку Maven для выполнения скриптов базы данных
На представленном скриншоте демонстрируется применение плагина Maven для активации SQL-скриптов. Данный плагин выполняет последовательность операций: сначала удаляет текущую схему базы данных, затем инициирует ее повторное создание, после чего осуществляется запуск DDL-скриптов для формирования структуры базы данных, включая таблицы, ограничения, индексы, последовательности и синонимы. После этого происходит развертывание хранимого кода в БД, и в завершение процесса производится импорт справочных и тестовых данных.
Процесс рефакторинга модели данных по мере необходимости
Адаптивный подход к проектированию данных, пропагандируемый методологией Agile, в отличие от традиционного предварительного планирования, часто оказывается не в полной мере реализованным многими организациями, которые заявляют о своем следовании принципам Agile. Общепринятое мнение заключается в том, что внесение изменений в структуру данных на поздних этапах разработки может быть затруднительно, поэтому первоначально необходимо наиболее точно определить схему данных. Однако, если следовать рекомендациям, изложенным в предыдущих разделах, организовать тесное сотрудничество между разработчиками и специалистами по базам данных, а также внедрить практику контроля версий SQL-скриптов изменений базы данных наравне с прикладным кодом, то процесс внесения изменений в схему данных может быть успешно автоматизирован. Кроме того, автоматизация процессов внедрения и отмены изменений в БД в сочетании с созданием комплекса автоматических тестов позволит минимизировать риски, связанные с рефакторингом структуры данных.
Избегание использования общедоступной базы данных
Применение единой схемы БД для нескольких приложений является практикой, не рекомендуемой к использованию, хотя и продолжает встречаться в некоторых системах. В даже в таком авторитетном источнике, как «Enterprise Integration Patterns» Грегора Хопа и Бобби Вулфа, упоминается паттерн «Общая база данных» в контексте интеграционных решений.
Стремление к синхронизации прикладного кода и баз данных в рамках единого процесса доставки оказывается неэффективным, если база данных используется исключительно одним приложением и не предназначена для совместного использования с другими системами. Тем не менее, это далеко не единственная причина, по которой следует избегать разработки систем с общей базой данных. Такой подход может привести к чрезмерной взаимозависимости приложений и множеству других проблем.
Индивидуальная схема для каждого разработчика и сервера CI
Для эффективной разработки и тестирования, каждый программист должен иметь возможность работать в изолированной среде, или «песочнице», что исключает риск нарушения работы общедоступного разработческого экземпляра БД. Подобным образом необходимо обеспечить отдельную «песочницу» для сервера CI. Этот подход соответствует устоявшейся практике разработки программного обеспечения, когда разработчик вносит изменения в код и проводит тестирование в локальной среде перед тем, как зафиксировать успешно проверенные изменения.
«Песочница» для каждого разработчика может быть реализована либо в виде отдельного экземпляра базы данных, установленного на локальном компьютере разработчика, либо как отдельная схема в рамках общего экземпляра БД, используемого для разработки.

Как демонстрируется на предоставленной диаграмме, каждый разработчик располагает индивидуальным экземпляром схемы базы данных. В процессе полной сборки системы, помимо компиляции приложения, также происходит инициализация схемы БД с начального состояния. Этот процесс включает в себя удаление текущей схемы, ее последующее воссоздание и выполнение DDL-скриптов для инициализации всех структурных элементов, включая таблицы, представления, последовательности, ограничения и индексы. Затем осуществляется создание объектов, содержащих код хранимых процедур, функций, пакетов и триггеров. В финале производится загрузка всех необходимых справочных и тестовых данных. Автоматизированные тесты выполняют роль контроля за корректностью взаимодействия прикладного кода с объектами базы данных. Стоит отметить, что модификации структуры данных происходят не так часто, как обновления прикладного кода, следовательно, скрипт сборки должен предусматривать опцию пропуска этапа создания базы данных для ускорения процедуры сборки.
Аналогично, среда сервера CI должна быть настроена таким образом, чтобы предоставлять изолированную среду для БД. Скрипт сборки в этой среде выполняет полноценную компиляцию, объединяющую процессы построения приложения и инициализации схемы базы данных. После этого активируется серия автоматических тестов, которые гарантируют согласованность функционирования приложения с БД, с которой оно интегрируется.
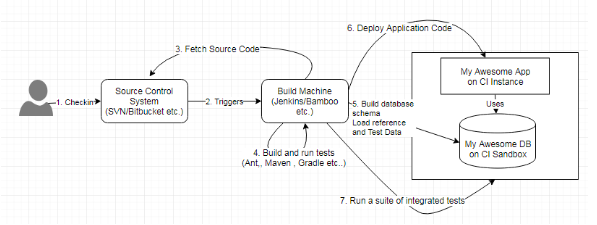
Пересмотренный процесс CI с интеграцией создания базы данных с созданием прикладного кода.
Прошу обратить внимание на схожесть процесса, представленного на диаграмме выше, с процессом, описанным на первой иллюстрации. На машине сборки или сервере CI настроено задание, которое инициируется при каждом коммите изменений в хранилище кода. Это задание включает в себя как компиляцию приложения, так и построение базы данных. Таким образом, скрипты БД теперь являются неотъемлемой частью процесса интеграции, наряду с прикладным кодом.
Управление миграциями баз данных
Описанный ранее процедурный подход, включающий создание структур базы данных, хранимого кода, справочных и тестовых данных с исходного состояния, является идеальным для сред CI и локальных разработческих сред. Однако такой метод не подходит для production БД, а также для тестовых и предварительных сред развертывания, таких как QA и UAT. Основная цель коммерческой базы данных — это хранение и управление бизнес-данными, а все остальные компоненты БД обслуживают эту ключевую функцию. Полное удаление и последующее воссоздание схемы из скриптов не представляется возможным для баз данных, активно используемых в бизнес-процессах. В этих случаях требуется разработка скриптов миграции, которые позволяют перевести структуру базы данных из текущего состояния, соответствующего определенной версии программного обеспечения, в новое, желаемое состояние. Эти переходы также включают миграцию данных, поскольку изменения в структуре могут потребовать переноса данных. К примеру, процесс нормализации может потребовать переноса данных из одной таблицы в несколько связанных подтаблиц. В таком случае скрипт миграции должен также охватывать преобразование данных из основной таблицы в связанные. Скрипты изменений схемы могут быть разработаны и управляемы в системе контроля версий, чтобы они были включены в процесс сборки. Эти скрипты могут быть написаны вручную во время активной фазы разработки, но также доступны инструменты, автоматизирующие этот процесс. Пример такого инструмента — Flyway, который способен генерировать скрипты миграции для перевода схемы из одного состояния в другое.
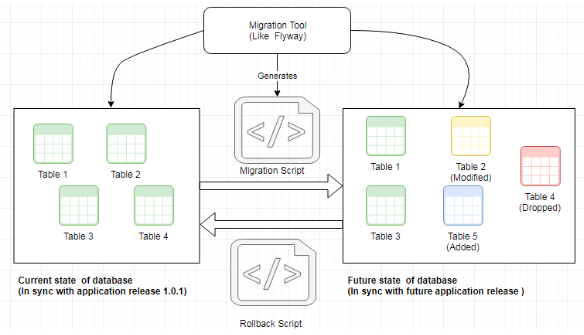
Автоматизация миграций схемы и отката
На представленной схеме слева отображено текущее состояние базы данных, которое соответствует версии приложения 1.0.1 (предшествующий выпуск). Справа иллюстрировано целевое состояние БД для предстоящего выпуска. Мы задокументировали и пометили состояние слева в системе управления версиями. Аналогично, целевое состояние справа также было зафиксировано в системе управления версиями в качестве базовой версии, главной ветки или транка. Разница между двумя этими состояниями представляет собой изменения, которые необходимо применить к БД в тестовых и рабочих средах. Эти изменения можно отслеживать и формировать вручную с использованием скриптов, однако это процесс может быть затруднительным и подверженным ошибкам. Изображение демонстрирует, что инструменты, такие как Flyway, способны автоматизировать процесс создания этих изменений в форме скриптов миграции. Автоматизация процесса предполагает создание следующего:
Скрипта миграции, обеспечивающего переход базы данных от предыдущего выпуска к новому.
Скрипта отката, позволяющего восстановить состояние базы данных до предыдущей версии.
Сгенерированные скрипты будут промаркированы и храниться вместе с другими артефактами развертывания. Процесс автоматизации может быть интегрирован с методикой непрерывной доставки для обеспечения повторяемости, надёжности и возможности отмены изменений в БД.
Интеграция CD с обновлением базы данных
Объединим теперь все элементы процесса. У нас уже налажен механизм непрерывной интеграции, который осуществляет пересборку базы данных в синхронизации с приложением. Мы разработали процедуру, автоматизирующую создание скриптов для миграции базы данных. Эти скрипты, в свою очередь, входят в состав артефактов, необходимых для развертывания. С помощью инструментов DevOps эти артефакты применяются для настройки тестовых сред или рабочего окружения. В комплект артефактов для развертывания также включены скрипты для выполнения откатов, что позволяет поддерживать возможность автономного восстановления предыдущих версий. В случае возникновения проблем, система позволяет повторно развернуть предыдущую версию приложения и запустить скрипт отката для базы данных, чтобы восстановить первоначальное состояние схемы, соответствующее предшествующему выпуску приложения.
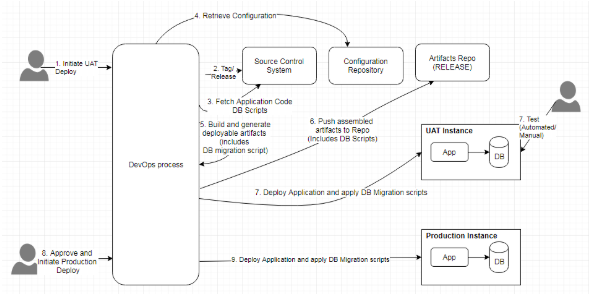
CD с внедрением изменений в базе данных
Иллюстрация выше демонстрирует процесс CD, в который интегрировано управление миграциями БД. Это предполагает уже установленную практику непрерывной интеграции. В момент запуска развертывания в среде UAT или в иной тестовой среде, такой как TEST, QA и прочие, автоматизированные системы отвечают за маркировку в системе управления версиями, компиляцию приложения из замаркированного исходного кода, создание скриптов миграции для баз данных, ассемблирование артефактов развертывания и сам процесс развертывания. Этот последний шаг включает в себя не только реализацию приложения, но и применение скриптов миграции к базе данных. Те же артефакты, что использованы в тестовой среде, будут задействованы для внедрения приложения в рабочую среду после прохождения этапа подтверждения качества. Процедура отката включает в себя повторное развертывание ранее выпущенной версии приложения и активацию скрипта отката для БД.
Доступные инструментарии на рынке
В предшествующих разделах основное внимание уделялось описанию методов достижения CI/CD в проектах с изменениями в базе данных, опираясь на определенные процессы, при этом не акцентируя внимание на специализированных инструментах, облегчающих эту задачу. Рекомендации, приведенные ранее, являются универсальными и не привязаны к использованию конкретных инструментов. Разработчики могут создавать собственные решения, применяя стандартные инструменты автоматизации, такие как Maven или Gradle для сборки, Jenkins или TravisCI для непрерывной интеграции, а также Chef или Puppet для управления конфигурациями. Тем не менее, существует широкий спектр специализированных решений для Database DevOps, доступных на рынке, которые также можно применять. Вот некоторые из них:
Заключение
Практики CI и CD предлагают компаниям значительные выгоды, включая ускоренный процесс выхода продукта на рынок, повышенную надежность выпускаемых версий и, в целом, улучшенное качество программных решений. Однако управление миграцией баз данных традиционно является кропотливым и затяжным процессом. Во множестве случаев, модификации БД требуют ручного вмешательства и часто становятся точкой затора в потоке непрерывной доставки. Процессы и передовые методики, освещенные в данной статье, а также представленные на рынке инструменты, как ожидается, могут устранить эти препятствия и способствовать интеграции изменений базы данных в общий процесс доставки наравне с разработкой прикладного программного кода.
