[Перевод] Чему я научился у ведущего программиста

Год назад я начал работать на полную ставку в Bloomberg. И тогда же задумал написать эту статью. Я думал, что буду полон идей, которые смогу выплеснуть на бумагу, когда придёт время. Но уже через месяц понял, что всё будет не так просто: я уже начал забывать то, чему научился. Либо знания настолько хорошо усвоились, что мой разум заставил меня поверить, будто я всегда это знал, либо они просто вылетели у меня из головы.1
Это одна из причин, по которой я начал вести дневник. Каждый день, попадая в интересные ситуации, я описывал их. И всё благодаря тому, что я сидел рядом с ведущим программистом. Я мог вблизи наблюдать за его работой, и видел, насколько она отличается от того, что сделал бы я. Мы много программировали вместе, что ещё больше облегчало мои наблюдения. Более того, в нашей команде не осуждается «подглядывание» за людьми, пишущими код. Когда мне казалось, что происходит что-то интересное, я поворачивался и смотрел. Благодаря постоянным вставаниям я всегда был в курсе происходящего.
Я год просидел рядом с ведущим программистом. Вот чему я научился.
Написание кода
Как называть вещи в коде
Одной из моих первых задач была работа над React UI. У нас был основной компонент, содержавший все остальные компоненты. Мне нравится добавлять в код немножко юмора, и я хотел назвать основной компонент GodComponent. Наступил момент ревью кода, и я понял, почему так трудно давать наименования.
There are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors.
— Leon Bambrick (@secretGeek) January 1, 2010
Каждый кусок кода, который я окрестил, обрёл неявное предназначение. GodComponent? Это компонент, в который попадает вся дрянь, которую я не хочу помещать в нужное место. Он содержит всё. Назови я его LayoutComponent, и будущий я решил бы, что этот компонент присваивает макет. Что он не содержит состояния.
Ещё одним важным усвоенным мной уроком стало то, что если что-то выглядит слишком большим, вроде LayoutComponent с кучей бизнес-логики, то пора его рефакторить, потому что бизнес-логики здесь быть не должно. А в случае с названием GodComponent присутствие бизнес-логики не будет иметь значения.
Нужно назвать кластеры? Называть их в честь сервисов, которые на них работают, будет прекрасной идеей до тех пор, пока вы не запустите на этих кластерах что-то ещё. Мы дали им название в честь нашей команды.
То же самое относится и к функциям. doEverything() — ужасное название с многочисленными последствиями. Если функция делает всё, то будет чертовски сложно тестировать отдельные её части. Какой бы большой ни стала такая функция, вам это никогда не покажется слишком странным, ведь она же должна делать всё. Так что поменяйте название. Отрефакторьте.
У осмысленного наименования есть и обратная сторона. Вдруг название будет слишком осмысленным и скроет какой-то нюанс? Например, закрытие сессий не закрывает подключение к базе данных при вызове session.close() в SQLAlchemy. Мне следовало прочесть документацию и предотвратить этот баг, подробнее об этом рассказано в разделе Байка.
С этой точки зрения именование функций как x, y, z вместо count(), close(), insertIntoDB() не позволяет вкладывать в них определённый смысл и заставляет меня внимательно следить, что же делают эти функции.2
Никогда не думал, что напишу про принципы наименования больше одной строки текста.
Унаследованный код и следующий разработчик
Бывало ли, что вы смотрите на код и он вам кажется странным? Почему так написали? Это же не имеет смысла.
Мне довелось поработать с унаследованной кодовой базой. Такой, знаете, с комментариями вроде «Раскомментировать код, когда Мухаммед разберётся в ситуации». Что вы тут делаете? Кто такой Мухаммед?
Я могу поменяться ролями и подумать о человеке, которому потом передадут мой код, покажется ли он ему странным? Отчасти решить эту проблему помогает ревью твоего кода коллегами. Это навело меня на мысль о контексте: нужно помнить о контексте, в котором работает моя команда.
Если я забуду этот код, вернусь к нему позднее и не смогу восстановить контекст, то скажу: «Какого хрена они так сделали? Это же глупость… А, погодите, это я так сделал».
И здесь в игру вступают документация и комментарии в коде.
Документация и комментарии в коде
Они помогают сохранить контекст и передать знания.
Как сказал Ли в How to Build Good Software:
Главная ценность ПО не в созданном коде, а в знании, накопленном людьми, которые создали это ПО
У вас есть открытый для клиентов эндпойнт API, которым, похоже, никто ни разу не пользовался. Нужно ли его просто удалить? Вообще говоря, это технический долг. А если я скажу вам, что в одной из стран 10 журналистов раз в год отправляют свои отчёты на этот эндпойнт? Как это проверить? Если в документации об этом не упомянуто (так и было), то никак не проверить. Мы и не проверили. Удалили, а через несколько месяцев наступил тот самый ежегодный момент. Десять журналистов не смогли отправить свои важные отчёты, потому что эндпойнта больше не существовало. А люди, обладавшие знаниями о продукте, уже покинули команду. Конечно же, теперь в коде есть комментарии, объясняющие, для чего это нужно.
Насколько мне известно, каждая команда сражается с документацией. Причём с документацией не только по коду, но и по связанным с ним процессам.
Мы ещё не придумали идеального решения. Лично мне нравится, как Антирез разделил комментарии в коде по разным типам ценности.
Атомарные коммиты
Если вам нужно откатиться (а вам это понадобится. См. главу Тестирование), то будет ли этот коммит иметь смысл как единый модуль?
Как уверенно удалять паршивый код
Мне было очень неприятно удалять паршивый или устаревший код. Мне казалось, что всё написанное века назад является священным. Я думал: «Они же что-то имели в виду, когда так писали». Это противостояние между традицией и культурой с одной стороны, и мышлением в стиле «первичного принципа» с другой стороны. Это то же самое, что и в случае с удалением ежегодной-конечной-точки. Я усвоил особенный урок.3
Я постарался бы обойти код, а ведущие разработчики постарались бы пройти сквозь него. Сотрите его. Выражение if, к которому невозможно обратиться? Ага, стираем. А что сделал я? Я просто написал поверх него свою функцию. Я не уменьшил технический долг. Во всяком случае, я только что увеличил сложность кода и переадресацию. Следующему человеку будет ещё сложнее собрать кусочки картины воедино.
Опытным путём я пришёл к заключению: есть код, который ты не понимаешь, а есть код, к которому ты точно никогда не обратишься. Сотри код, к которому не обратишься, и будь осторожен с кодом, который не понимаешь.
Ревью кода
Ревью кода — прекрасный инструмент для самообразования. Это цикл внешней обратной связи, показывающий, как они написали бы код и как его написал ты. В чём разница? Один способ лучшего другого? Я спрашивал себя об этом при каждом ревью: «Почему они написали именно так?» И если не мог найти подходящий ответ, то шёл и спрашивал.
Спустя первый месяц я начал находить ошибки в коде моих коллег (как они находили в моём). Это было какое-то безумие. Ревью стало для меня гораздо интереснее, оно превратилось в игру, которой мне не хватало, игру, которая улучшала моё «чувство кода».
По моему опыту, не надо одобрять код, пока я не пойму, как он работает.
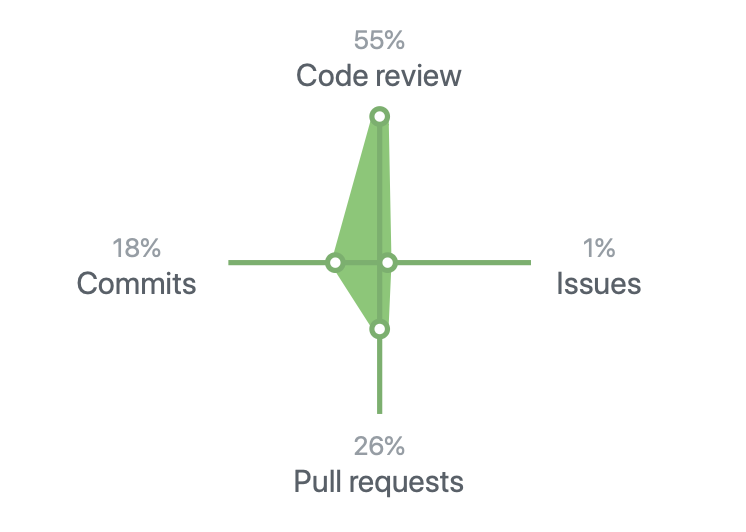
Моя GitHub-статистика.
Тестирование
Я так полюбил тестирование, что мне неприятно писать код в кодовой базе без тестов.
Если ваше приложение делает лишь что-то одно (как все мои школьные проекты), тогда всё ещё можно тестировать вручную.4 Именно так я и делал. Но что происходит, если приложение выполняет 100 разных задач? Я не хочу тратить полчаса на тестирование, и иногда что-то упускаю из виду. Кошмар.
Здесь помогают тесты и автоматизация тестирования.
Я отношусь к тестированию как к документации. Это документация моих представлений о коде. Тесты говорят мне, как я (или кто-нибудь до меня) представляю работу кода и где что-то ожидаемо должно пойти не так.
Сегодня, когда я пишу тесты, я стараюсь:
- Показать, как использовать тестируемый класс, функцию или систему.
- Показать, что, по моему мнению, может пойти не так.
Как следствие, чаще всего я тестирую поведение, а не реализацию (вот пример, который я выбрал на перерывах в Google).
В пункте 2 я не упомянул об источниках багов.
Когда я замечаю баг, то убеждаюсь, что у исправления есть соответствующий тест (это называется регрессионным тестированием) для документирования информации. Это ещё одна из причин, почему что-то может пойти не так.5
Конечно, качество моего кода улучшается не потому, что я пишу тесты, а потому, что я пишу код. Зато чтение тестов помогает мне лучше разобраться в ситуациях и написать более качественный код.
Так выглядит общая ситуация с тестированием.
Но это не единственная разновидность тестирования, которую я применяю. Я говорю о средах развёртывания. У вас могут быть идеальные модульные тесты, но если у вас нет тестов системных, то может произойти нечто подобное:

Это относится и к хорошо протестированному коду: если у вас на компьютере нет необходимых библиотек, то всё обрушится.
- Есть машины, на которых вы разрабатываете (источник всех мемов вроде «На моём компьютере работало!»).
- Есть машины, на которых вы тестируете (могут совпадать с предыдущими).
- Наконец, есть машины, на которых вы развёртываете (они не должны совпадать с машинами, на которых вы разрабатывали).
Если на машинах тестирования и развёртывания среды не совпадают, у вас будут проблемы. А избежать этого помогут среды развёртывания.
Мы ведём локальную разработку в Docker на своем компьютере.
У нас есть среда разработки, эти компьютеры оснащены набором библиотек (и инструментов разработки), и сюда мы устанавливаем написанный код. Здесь его можно протестировать со всеми необходимыми системами. Также у нас есть бета/стейджинговая среда, которая полностью повторяет эксплуатационную среду. Наконец, у нас есть эксплуатационная среда — машины, на которых исполняется код для наших клиентов.
Идея заключается в том, чтобы выловить ошибки, которые не всплыли в ходе модульного и системного тестирования. Например, разницу API у запрашивающей и отвечающей системы. Думаю, в случае с личным проектом или маленькой компание ситуация может быть совсем иной. Не у всех есть возможность создать собственную инфраструктуру. Однако можно прибегнуть к услугам облачных сервисов, например, AWS и Azure.
Вы можете настроить отдельные кластеры для разработки и эксплуатации. AWS ECS использует для развёртывания Docker-образы, так что процессы в разных средах будут относительно согласованы. Есть нюансы с точки зрения интеграции между разными AWS-сервисами. Вы вызываете правильную конечную точку из правильной среды?
Можно пойти ещё дальше: скачать альтернативные контейнерные образы для других AWS-сервисов и настроить локальную полнофункциональную среду на основе Docker-Compose. Это ускоряет цикл обратной связи.6 Возможно, я наберусь больше опыта, когда создам и запущу свой побочный проект.
Снижение рисков
Какие шаги вы можете предпринять, чтобы снизить риск катастрофы? Если речь идёт о новом радикальном изменении, то как можно удостовериться в минимальной длительности простоя, если что-то пойдёт не так? «Нам не нужно полностью развёртывать систему из-за всех этих новых изменений». Что, правда? И почему я об этом не подумал!
Архитектура
Почему я говорю об архитектуре после написания кода и тестирования? Её можно поставить и первой, но если бы я не программировал и не тестировал в используемой мною среде, то, вероятно, не преуспел бы в создании архитектуры, учитывающей особенности этой среды.7
Нужно очень многое продумать при создании архитектуры.
- Как будут использоваться числа?
- Сколько будет пользователей? Насколько может увеличиться их количество (от этого зависит количество строк в базе данных)?
- Какие подводные камни могут встретиться?
Мне нужно превратить это в чеклист под названием «Сбор требований». Сейчас у меня пока недостаточно опыта, постараюсь сделать это в следующем году в Bloomberg. Этот процесс во многом противоречит Agile: сколько можно проектировать архитектуру, прежде чем переходить к реализации? Всё дело в балансе, нужно выбирать, когда и что вы будете делать. Когда имеет смысл ринуться вперёд, а когда — отступить назад? Конечно, сбор требований не равносилен обдумыванию всех вопросов. Думаю, это окупается, если включить в проектирование ещё и процессы разработки. Например:
- Как будет протекать локальная разработка?
- Как мы будем упаковывать и развёртывать?
- Как мы будем проводить сквозное тестирование?
- Как мы будем проводить стресс-тестирование нового сервиса?
- Как мы будем хранить секреты?
- CI/CD-интеграция?
Недавно мы разработали новый поисковый движок для BNEF. Работать над ним было чудесно, я организовал локальную разработку и узнал о DPG (пакетах и их деплое), поборов деплой секретов.
Кто бы мог подумать что деплоить секреты в прод может быть таким нетривиальным:
- Их нельзя поместить в код, ведь кто-то может их заметить
- Хранить их как переменную окружения как предлагает спека 12 факторов приложения? Неплохая идея, но как их туда положить? (Заходить на прод чтобы заполнить переменные окружения каждый раз, когда стартует машина — боль)
- Деплоить их как файлы? Но откуда они возьмутся и как их заполнять?
Мы не хотим всё делать вручную.
В результате мы пришли к базе данных с управлением доступом на основе ролей (только мы и наши компьютеры можем общаться с базой данных). Наш код получает от базы секреты при запуске. Этот подход отлично реплицируется в рамках сред разработки, стейджинга и эксплуатации, секреты хранятся в соответствующих базах данных.
Опять же, с облачными сервисами вроде AWS ситуация может быть совершенно иной. Вам не нужно как-то заботиться о секретах. Получите аккаунт для своей роли, введите секреты в интерфейсе, и ваш код найдёт их, когда они понадобятся. Это сильно всё упрощает, но я рад, что получил опыт, благодаря которому могу оценить эту простоту.
Создаём архитектуру, не забывая о сопровождении
Проектирование систем вдохновляет. А сопровождение? Не слишком. Моё путешествие по миру сопровождения привело меня к вопросу: почему и как деградируют системы? Первая часть ответа связана не с выводом из эксплуатации всего устаревшего, а только с добавлением нового. Склонность добавлять, а не удалять (ничего не напоминает?). Вторая часть — это проектирование с мыслью о конечной цели. Система, которая со временем начинает делать то, для чего не предназначалась, не обязательно будет работать так же хорошо, как система, изначально спроектированная для тех же задач. Это подход в стиле «отступить на шаг назад», а не хитрости и уловки.
Я знаю не меньше трёх способов снижения скорости деградации.
- Разделяйте бизнес-логику и инфраструктуру: обычно деградирует инфраструктура — растёт нагрузка, устаревают фреймворки, проявляются уязвимости нулевого дня и т.д.
- Создавайте процессы с учётом будущего сопровождения. Применяйте одинаковые обновления для старых и новых битов. Это предотвратит появление различий между старым и новым и сохранит весь код в «современном» состоянии.
- Убедитесь в том, что выбрасываете всё ненужное и старое.
Развёртывание
Буду ли я упаковывать фичи вместе или развёртывать их по одной? В зависимости от текущего процесса, если вы будете упаковывать их вместе, то жди беды. Спросите себя, почему вы хотите упаковывать фичи вместе?
- Развёртывание занимает много времени?
- Ревью кода проходит не слишком весело?
Какой бы ни была причина, эту ситуацию нужно исправлять. Я знаю как минимум две проблемы, связанные с упаковыванием:
- Вы сами блокируете все фичи, если в одной из них есть баг.
- Вы повышаете риск возникновения проблем.
Какой бы процесс развёртывания вы ни выбрали, вам всегда хочется, чтобы ваши машины были как скот, а не как домашние животные. Они не уникальны. Вы точно знаете, что исполняется на каждой машине как воссоздать их в случае смерти. Вы не расстроитесь, если какая-нибудь машина умрёт, вы просто поднимаете новую. Вы их пасёте, а не растите.
Когда что-то идёт не так
На тот случай, если что-то пойдёт не так —, а оно пойдёт, — есть золотое правило: минимизировать влияние на клиентов. В случае сбоев моим первым желанием всегда было заняться исправлением. Похоже, это не оптимальное решение. Вместо того, чтобы заниматься исправлением, даже если это можно сделать одной строкой, сначала нужно откатиться. Вернитесь к предыдущему рабочему состоянию. Это самый быстрый способ вернуть клиентов к работающей версии. Только потом я выясняю, в чём проблема, и исправляю.
То же самое применимо и к «испорченной» машине в вашем кластере: выключите её, пометьте как недоступную, прежде чем выяснять, что с ней произошло. Я нахожу странным, насколько моё естественное желание и инстинкты противоречат оптимальному решению.
Думаю, этот инстинкт также приводил к тому, что я дольше исправлял баги. Иногда я понимал, что что-то не работает, потому что написанный мной код какой-то неправильный, и я залезал в дебри, просматривая каждую строку. Что-то вроде поиска «сначала в глубину». И когда оказывалось, что проблема возникла из-за изменения конфигурации, то есть я не проверил это в первую очередь, меня эта ситуация выбивала из колеи. Я очень нерационально тратил время на поиск бага.
С тех пор я научился искать «сначала в ширину», а потому уже «сначала в глубину», чтобы исключить верхнеуровневые причины. Что именно я могу подтвердить, имея текущие ресурсы?
- Машина работает?
- Код установлен верно?
- Конфигурация присутствует?
- <Характерная для кода конфигурация>, вроде того, корректно ли прописана маршрутизация?
- Правильная ли версия схемы?
- А потом уже погружаюсь в код.
Мы думали, что был неправильно установлен nginx, но оказалось, просто конфигурация была отключена
Конечно, мне не нужно делать это каждый раз. Иногда достаточно лишь сообщения об ошибке, чтобы сразу заняться разбором кода. Когда я не могу определить причину, я стараюсь свести к минимуму количество изменений-в-коде-ради-того-чтобы-найти-причину. Чем меньше изменений, тем быстрее я смогу найти настоящий корень проблемы. Кроме того, теперь у меня есть памятка для багов, которая сэкономила мне больше часа на размышления «что я упустил?» Иногда я забываю о простейших проверках, вроде настройки маршрутизации, соответствия версий схемы и сервиса, и т.д. Это ещё один шаг по освоению стека технологий, который я использую, и то, что обретаешь лишь с опытом — интуицию в определении, что же именно не работает.
Байка
Эта статья не может быть полной без байки. Мне нравится их читать, и хочу одной из них поделиться с вами. Это история о поиске и SQLAlchemy. В BNEF работает много аналитиков, которые пишут отчёты об исследованиях. При публикации отчёта мы получаем сообщение. При получении сообщения мы обращаемся к базе данных через SQLAlchemy, получаем необходимые данные, преобразуем и отправляем на индексирование в экземпляр Solr. И как-то возник странный баг.
Каждое утро подключение к базе приводило к сбою с ошибкой «MYSQL server has gone away.» Иногда это случалось и днём. Машины включаются в течение дня, так что это было первое, что я проверил. Нет, при включении компьютера ошибка не возникала. Мы делали тысячи запросов к базе в течение дня, всё было в порядке. Так в чём же дело, что приводило к сбою?
Может быть, мы не закрывали сессии после транзакций? А если сессия та же, и спустя длительное время приходит запрос, то мы пропускаем таймаут и сервер исчезает. Быстро просмотрели код и убедились, что мы используем диспетчер контекста для каждой операции чтения, в ходе которой применительно к __exit__() вызывается session.close().
Целый день мы проверяли всё, что можно, и ничего не обнаружили. На следующее утро я пришёл на работу и снова столкнулся с этой ошибкой. А секунду спустя три других запроса к индексу прошли успешно. Были все симптомы неправильного закрытия сессии. Конец истории вам известен.
Session.close() в MySQL-диалекте SQLAlchemy не закрывает подключение к базе данных, пока если не используется NullPool. Это решило проблему. Забавно, что этот баг возник лишь потому, что мы не публиковали отчёты об исследованиях вечером или в обед. И отсюда проистекает ещё один урок: в большинстве ответов на StackOverflow (конечно, я там искал!) советовали настроить длительность таймаута сессии, или настроить параметр, управляющий объёмом пересылаемых в SQL-выражении данных. Всё это не имело для меня смысла, поскольку не было связано с истинной причиной. Я проверил, что размер запроса у нас не превышает ограничения, а сессии мы закрывали (хаха), так что таймаут просто отсутствовал.
Мы могли бы «исправить» этот баг, увеличив длительность таймаута сессии с 1 часа до 8. Нам казалось бы, что проблема решена, до первого выходного в течение недели — и тогда первый отчёт на следующее утро завершился бы сбоем.
Это балансирование между настройкой параметров, игрой со статистикой и исправлением причины.
Мониторинг
Это то, о чём раньше я никогда не думал. Честно говоря, пока я не начал работать программистом на полную ставку, я никогда не занимался поддержкой систем. Я лишь создавал их, использовал с неделю и шёл дальше.
Поработав с двумя системами, одна из которых обладала замечательным мониторингом, а другая не могла этим похвастаться, я начал очень высоко ценить мониторинг. Я не могу исправить баги, если не знаю об их существовании. Хуже всего, когда узнаёшь о багах от клиентов.»Чем я занимаюсь?! Я даже не знаю о проблемах в системе, которой владею? ».
Я считаю, что мониторинг складывается из трёх компонентов: журналирования, метрик и оповещений. Журналирование в коде, как и дневник, процесс эволюционный. Вы прикидываете, что вам нужно будет мониторить, начинаете журналировать и запускаете систему. Со временем находите несколько багов, для исправления которых у вас мало информации. Пришло время расширить журналирование — чего не хватает вашему коду? Думаю, вы интуитивно понимаете, что важно журналировать. Я и тот ведущий программист журналировали очень разные наборы данных. Я считал, что достаточно будет логов запросов-ответов, а он фиксировал кучу метрик, вроде длительности исполнения запроса, некоторые внутренние вызовы, сделанные кодом, и т.д. А при ротации логов ещё и сортировал статистику.
Практически невозможно заниматься отладкой без логов. Если вы не знаете, в каком состоянии была система, как вы можете её воссоздать? Метрики можно извлекать из логов или выделять в коде (например, отправку событий в AWS CloudWatch и Grafana). Вы сами определяете набор метрик и отправляете информацию по мере исполнения кода.
Оповещения соединяют все элементы в замечательную систему мониторинга. Если одной из метрик является количество серверов, работающих в данный момент в эксплуатации, то когда её значение падает до 50%, это должно быть поднимать настоящую тревогу — возникла серьёзная проблема. Количество сбоев превысило порог? Ещё одно оповещение. Я крепко сплю по ночам, потому что знаю — в случае чего меня разбудят (погоди, что?).
Это приводит к ещё одной привычке в разработке. Когда исправляешь баги, то думаешь не только о том, как исправить, но и о том, почему ты не определил их раньше? Было ли оповещение? Как можно улучшить мониторинг, чтобы предотвращать такие проблемы?
Я ещё не придумал, как мониторить интерфейс. Тестировать наличие компонентов мало для того, чтобы определять возникновение проблем. Обычно клиенты приходят и говорят — у вас тут что-то выглядит криво.
Заключение
Я многому научился за последний год. Я рад, что решил написать эту статью, с её помощью мне удалось полнее оценить, насколько я вырос как специалист. И я надеюсь, что вы узнали для себя что-то полезное!
Сейчас я сижу рядом с двумя ведущими разработчиками. Посмотрим, к чему это приведёт!
Хорошие инженеры самостоятельно проектируют системы, которые получаются более надёжными и лёгкими для понимания. Это приводит к мультипликативному эффекту, позволяя их коллегам опираться на их работу и решать свои задачи гораздо быстрее и надёжнее — How to Build Good Software.
В чём я не уверен
Я ещё не познал всех тайн программного инжиниринга. Так что эта глава служит мне напоминанием: я ещё многого не знаю! Если я всё делаю правильно, то в следующем году этот список должен стать длиннее.
- Мыслить абстракциями или реализациями?
- Должен ли я иметь твёрдое мнение относительно способов решения задач? Например, как следствие набитых шишек? Достаточно ли я сделал, чтобы иметь мнение?
- Продумывание рабочих процессов. Если нужно срочно или ситуативно поменять подход, то можно ли считать процесс нарушенным? Нужно ли его исправлять?
- Являются ли вспомогательные классы (utils) (папка, в которую ты складываешь то, что не знаешь, куда деть) признаком того, что код «с душком»?
- Как работать с документацией по коду и рабочим процессам?
- Как мониторить интерфейс так, чтобы замечать, когда что-то выглядит неправильно?
- Что лучше — потратить время на проектирование идеального API или контракта в коде, или хакинг и многократное итерирование в поисках лучшего решения?
- Легкий способ или правильный? Не уверен, что правильный способ всегда лучше.
- Делать самостоятельно или показывать тем, кто не знает, как сделать. Первое быстрее, а второе означает, что вам редко придётся делать это самостоятельно.
- Когда рефакторишь и избегаешь больших PR: «Если бы я сначала изменил все тесты, то я бы увидел, что у меня изменилось 52 файла, и это, очевидно, слишком много, но я сначала занялся кодом, а не тестами». Стоит ли оно того?
- Дальнейшее исследование снижения рисков. Какие существуют стратегии для уменьшения рисков в проектах?
- Эффективные способы сбора требований?
- Как снизить скорость деградации системы?
Примечания
- Такое происходит со многими знаниями. Вы знаете, как ездить на велосипеде? Можете кого-нибудь научить? Опишете им конкретные этапы, как вы это делали?
- Я имею в виду, что нужно не писать код с именами
x(),y()иz(),, а думать о них как оx(),y()иz(). Не думайте, что это WYSIATI. - Классический барьер Честертона.
- Но я больше так не поступил бы. Однажды перейдя на сторону автоматизированных тестов, обратного пути нет?
- Есть мнение, что ситуация выходит из-под контроля, если провести миллион тестов на всё, что может пойти не так. Судя по тому, это не верно.
- Я давно этого не делал, так что не знаю, насколько легко найти или создать конкретные Docker-образы для AWS.
- Здесь в качестве среды может выступать ваш стек технологий.
