[Перевод] Чем Linux HugePages важны для серверов баз данных?
Часто пользователи рассказывают нам о сбое базы данных по вине Out Of Memory Killer. Он завершает процессы PostgreSQL и остается причиной большинства отказов этой БД. Память на хост-компьютере может закончиться по нескольким причинам, наиболее распространенные из них:
Плохо настроена память на хост-компьютере.
Ограничения глобальной переменной work_mem. Например, если у вас 32Гб RAM и work_mem=1Гб, то больше 32 соединений вы никогда не запустите. Каждое соединение PostgreSQL будет выделять этот размер памяти.
Большое количество подключений. Даже неактивное соединение может занимать значительный объем памяти.
Другие программы тоже потребляют ресурсы, потому что для каждой из них этот компьютер является хостом.
Меня зовут Jobin Augustine, я работаю в Percona старшим инженером службы поддержки. Более 20-лет был консультантом, архитектором, администратором и инструктором по PostgreSQL, Oracle и другим технологиям баз данных. Поговорим о том, как можно защититься от OOM с помощью HugePages. Разберем насколько они важны и почему нужны.

Когда-то мы помогали настраивать хост-компьютеры и базы данных своим клиентам, то никогда не тратили время на объяснения. Не рассказывали им, что и почему делаем. Мой друг и коллега Fernando Laudares Camargos уже не раз обращал на это мое внимание. Поэтому я решил написать эту статью, чтобы сразу для всех объяснить суть проблемы на проверяемом и повторяемом случае. Это удобно, тем более если вы захотите провести свое собственное тестирование.
Условия теста
40 ядер ЦП (80 vCPU) и 192 ГБ физической памяти.
80 подключений, я не стал перегружать сервер слишком большим количеством подключений, поэтому для теста использовал только 80, что соответствует нормальным условиям нагрузки.
Transparent HugePages (THP) отключены.
За прошедшие годы в Transparent HugePages (THP) было внесено множество улучшений, которые позволяют приложениям использовать HugePages без модификации кода. THP часто рассматривается как замена обычным HugePages для универсальной рабочей нагрузки. Однако использование THP в системах баз данных не рекомендуется, так как оно может привести к фрагментации памяти и увеличенному времени ответа. Это не специфическая проблема PostgreSQL, она затрагивает все системы баз данных. Например:
Я не хочу уходить от темы и ударяться в объяснения, почему THP лучше не использовать для сервера базы данных, кто хочет разобраться, может почитать информацию по ссылкам. Мы же вернемся к условиям теста.
Чтобы обеспечить относительно постоянное соединение, такое же, как у хабов со стороны приложения (или даже у хабов внешнего соединения), используем pgBouncer со следующей конфигурацией:
[databases]
sbtest2 = host=localhost port=5432 dbname=sbtest2
[pgbouncer]
listen_port = 6432
listen_addr = *
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
logfile = /tmp/pgbouncer.log
pidfile = /tmp/pgbouncer.pid
admin_users = postgres
default_pool_size=100
min_pool_size=80
server_lifetime=432000Чтобы поддерживать постоянное соединение от хаба к PostgreSQL у параметра server_lifetime указано большое значение.
Вслед за PostgreSQL, вносим изменения в параметры для имитации общих настроек клиентской среды:
logging_collector = 'on'
max_connections = '1000'
work_mem = '32MB'
checkpoint_timeout = '30min'
checkpoint_completion_target = '0.92'
shared_buffers = '138GB'
shared_preload_libraries = 'pg_stat_statements'Тестовая нагрузка создается с помощью sysbench:
sysbench /usr/share/sysbench/oltp_point_select.lua --db-driver=pgsql --pgsql-host=localhost --pgsql-port=6432 --pgsql-db=sbtest2 --pgsql-user=postgres --pgsql-password=vagrant --threads=80 --report-interval=1 --tables=100 --table-size=37000000 prepare
А затем запускаем:
sysbench /usr/share/sysbench/oltp_point_select.lua --db-driver=pgsql --pgsql-host=localhost --pgsql-port=6432 --pgsql-db=sbtest2 --pgsql-user=postgres --pgsql-password=vagrant --threads=80 --report-interval=1 --time=86400 --tables=80 --table-size=37000000 run
На первом этапе подготовки, на сервер ложится нагрузка write, а на втором — только read. Я не буду объяснять теорию и концепции, лежащие в основе HugePages, а лишь сосредоточусь на анализе последствий его использования. Если хотите разобраться в деталях, можете посмотреть статьи: Five-Level Page Tables и Measuring the Memory Overhead of a Postgres Connection.
Ход тестирования
Мы решили измерять потребление памяти с помощью утилиты Linux free. При использовании обычного пула страниц памяти, потребление началось с очень низкого значения. Но по ходу проведения теста оно начало расти. На скриншоте видно, что со временем «доступная» память расходуется быстрее.

Ближе к концу теста уже видно высокую swap-активность. Она более наглядно фиксируется в выходных данных vmstat:
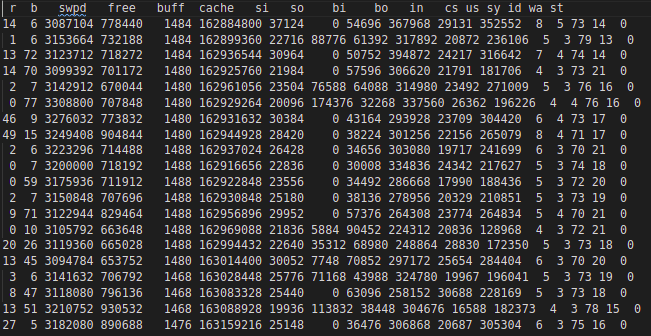
Информация из /proc/meminfo показывает, что размер таблицы Total Page с первоначальных 45 Мб вырос до более чем 25 Гб:
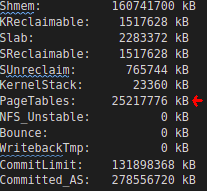
Это не просто потеря памяти, а огромное потребление ресурсов, влияющее на общее выполнение программ и работоспособность операционной системы. Мы видим, что потери состоят из суммы записей нижнего уровня PageTable с 80процессами PostgreSQL.
Подтвердить эти данные, можно проверив каждый процесс PostgreSQL:

Если мы возьмем полученное значение 314240 Кб и умножим на 80 соединений, то как раз получим наш примерный общий размер PageTable — 25 Гб. Поскольку наш синтетический тест передает почти одинаковую рабочую нагрузку через все соединения, у всех отдельных процессов почти одинаковые значения, очень близкие к зафиксированному выше.
Поскольку PostgreSQL использует Linux shared memory, нет смысла сосредотачиваться на Rss (Resident set size). Поэтому используем следующую строку для проверки Pss (Proportional set size):
for PID in $(pgrep "postgres|postmaster") ; do awk '/Pss/ {PSS+=$2} END{getline cmd < "/proc/'$PID'/cmdline"; sub("\0", " ", cmd);printf "%.0f --> %s (%s)\n", PSS, cmd, '$PID'}' /proc/$PID/smaps ; done|sort -n
PostgreSQL запускает по процессу на каждое соединение, плюс несколько фоновых. Поэтому без информации Pss сложно понять, как память распределяется по процессам.
В типичной системе баз данных со значительной нагрузкой DML, фоновые процессы PostgreSQL, такие как Checkpointer, Background Writer или рабочие процессы Autovaccum, будут касаться большего количества страниц в shared memory. Соответствующий Pss для этих процессов будет выше, чем для активных процессов.
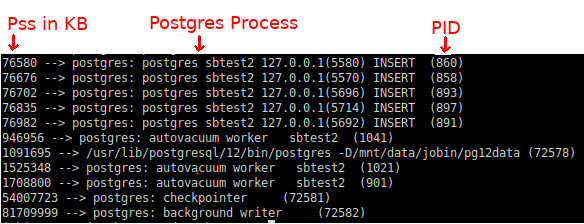 Так становится понятнее, что Checkpointer, Background worker или даже Postmaster часто становятся целью OOM Killer потому, что используют больше памяти, чем другие процессы.
Так становится понятнее, что Checkpointer, Background worker или даже Postmaster часто становятся целью OOM Killer потому, что используют больше памяти, чем другие процессы.
После нескольких часов активности, отдельный сеанс затронул больше страниц shared memory. Как следствие, значения Pss для каждого процесса были перераспределены. Потребление памяти checpointer-ом снизилось, а другие сеансы поделили память приблизительно поровну.
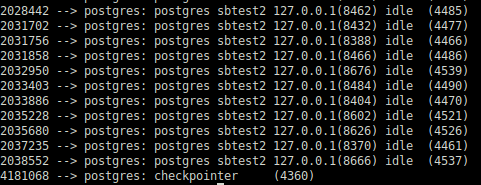
Тем не менее, Checkpointer сохранил наибольшую долю. Такая схема нагрузки характерна для нагрузочного теста, при котором основная нагрузка приходится на CheckPointer и Background Writer.
Включение HugePages
HugePage (hugetlbfs) изначально появился в Linux Kernel в 2002 году для удовлетворения требований систем баз данных, которым необходимо обращаться к большому объему памяти. Но оказался очень актуален для целей разработки и используется до сих пор. Например, в данном случае помогает сократить расход памяти.
Его можно использовать вместо раздутых таблиц страниц, достаточно выяснить, сколько памяти должно быть выделено для HugePages. Для этого проверим VmPeak процесса postmaster. Например, если PID процесса postmaster — 4537, то:
grep ^VmPeak /proc/4357/status
Получаем необходимый объем памяти в Кб:
VmPeak: 148392404 kB
В HugePages все это должно преобразоваться в страницы размером 2 Мб:
postgres=# select 148392404/1024/2;
?column?
----------
72457
(1 row)Укажите это значение в /etc/sysctl.conf для vm.nr_hugepages, например: vm.nr_hugepages = 72457
Теперь закройте экземпляр PostgreSQL и выполните sysctl -p
Проверим, создано ли запрошенное количество huge pages:
grep ^Huge /proc/meminfo
HugePages_Total: 72457
HugePages_Free: 72457
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 148391936 kBЗапустив PostgreSQL на этом этапе, мы увидим, что HugePages_Rsvd выделен.
$ grep ^Huge /proc/meminfo
HugePages_Total: 72457
HugePages_Free: 70919
HugePages_Rsvd: 70833
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 148391936 kBЕсли все идет как надо, на этом этапе я бы убедился, что PostgreSQL всегда использует HugePages. Потому, что уж лучше иметь сбой при запуске PostgreSQL, чем проблемы позже.
postgres=# ALTER SYSTEM SET huge_pages = on;
Обратите внимание, что приведенное выше изменение требует перезапуска экземпляра PostgreSQL.
Тесты с включенными HugePages
HugePages создаются заранее, еще до запуска PostgreSQL. Он просто выделяет и использует их. Так что мы не заметим изменения вывода утилиты Linux free до и после запуска. PostgreSQL загружает shared memory в HugePages, если они уже доступны. Shared_buffers, принадлежащие PostgreSQL, занимают больший объем shared memory.
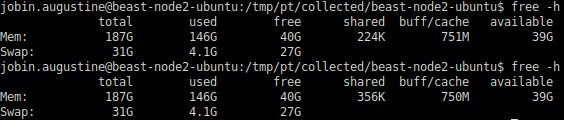
Первый вывод free -h на скриншоте генерируется до запуска PostgreSQL, а второй — после. Я провел такой же тест, как до включения HugePages, он длился несколько часов, и изменений почти не было. Единственное, что произошло, после нескольких часов работы началось смещение «свободной» памяти в кэш файловой системы, что соответствовало нашим ожиданиям и целям. Общая «доступная» память оставалась практически неизменной, как видно на следующем скриншоте.
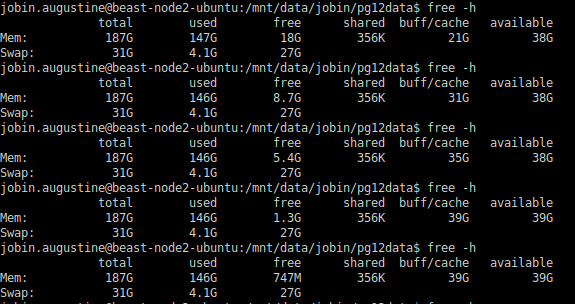
Общий размер таблиц страниц тоже остался прежним:

При этом разница в расходе памяти была колоссальной. Всего 61 Мб при включенном HugePages, вместо 25 Гб без него. Pss за сеанс также значительно сократился:

Самое большое преимущество HugePages заключалось в том, что CheckPointer и Background Writer больше не забирали несколько Гб ОЗУ.
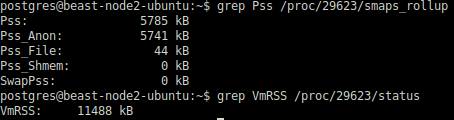
Вместо этого они потребляли лишь несколько Мб. А это значит, что они больше не были целью OOM Killer.
Выводы
Мы убедились, что благодаря HugePages фоновые процессы PostgreSQL не забирали на себя большой объем shared memory. Поэтому они переставали быть первоочередной целью OOM Killers и связанных с этим сбоев. Такие улучшения могут спасти систему, если она находится на грани OOM. Но гарантировать, что это позволит навсегда защитить базу данных от всех условий OOM — все же нельзя.
Нам удалось снизить общее потребление памяти. Если без HugePages доступная память на сервере была полностью исчерпана и началась подкачка, то после его включения в доступном кэше файловой системы Linux остались 38–39 Гб.
Существуют и другие преимущества использования HugePages. Они никогда не выгружаются на диск. Когда общие буферы PostgreSQL находятся в HugePages, они обеспечивают более стабильную и предсказуемую производительность.
Linux использует метод многоуровневой таблицы страниц. HugePages реализованы с использованием прямых указателей на страницы из промежуточного слоя (огромная страница размером 2 Мб находится непосредственно на уровне PMD, без промежуточной страницы PTE). Преобразование адресов значительно упрощается. А это часто встречающаяся операция на сервере базы данных с большим объемом памяти.
28–29 апреля в Москве впервые пройдет TestDriven Conf 2022 — профессиональная конференция для senior тестировщиков и QA-инженеров. Она будет посвящена всем вопросам автоматизации в тестировании и рядом.
Расписание и тезисы докладов уже на сайте. И можно забронировать билеты по выгодной цене — чем ближе к конференции, тем будет дороже.
