[Перевод] Борьба с фрагментацией памяти в ядре Linux

В этой компиляции из двух статей приводятся распространенные методы предотвращения фрагментации памяти в Linux, а также разбираются принципы ее уплотнения, способы просмотра индекса фрагментации и прочие нюансы.
(Внешняя) фрагментация памяти является давней проблемой программирования ядра Linux. В процессе работы система присваивает различные задачи страницам памяти, которая в результате постепенно фрагментируется, и в конечном итоге загруженная система, находящаяся в рабочем состоянии длительное время, может иметь всего несколько непрерывных физических страниц.
Поскольку ядро поддерживает управление виртуальной памятью, фрагментация физической зачастую проблем не вызывает. При использовании таблиц страниц, если только эти страницы не слишком большие, физически разбросанная память в виртуальном пространстве адресов все равно остается непрерывной.
Тем не менее становится очень сложно выделять непрерывную память из линейной области отображения ядра. Например, трудно выделять структурные объекты через аллокатор — типичная и частая операция в режиме ядра — или работать с буфером прямого доступа к памяти (DMA), который не поддерживает режимы scatter/gather. Подобные операции могут вызывать частое уплотнение памяти, приводящее к колебаниям в быстродействии системы или сбою аллокации. В процессе медленного (slow path) выделения памяти выполняются различные операции, определяемые флагом на странице аллокации.
Если при программировании ядра перестать опираться на распределение физической памяти верхнего уровня в линейном адресном пространстве, то проблема фрагментации будет решена. Однако для такого огромного проекта, как ядро Linux, внесение подобных изменений окажется непрактичным.
Начиная с Linux 2.x, сообщество перепробовало немало способов борьбы с проблемой фрагментации, включая много эффективных, хоть и необычных патчей. Некоторые внесенные доработки оказывались спорными, например механизм уплотнения памяти. На конференции LSFMM 2014 многие разработчики жаловались на низкую эффективность этого механизма и сложность воспроизведения ошибок. Но сообщество не отказалось от этого функционала и продолжило оптимизировать его в последующих версиях.
Мел Горман в этом плане оказался самым усердным участником проекта. Он привнес в него два набора важных патчей. Первый был включен в Linux 2.6.24 и прошел 28 версий, прежде чем сообщество его приняло. Второй набор был добавлен уже в Linux 5.0 и успешно сократил фрагментацию на 94% в случае машин с одним или двумя сокетами.
В этой статье я представлю вам ряд распространенных расширений для алгоритма двойников (buddy memory allocation), который помогает предотвратить фрагментацию памяти в ядре Linux 3.10, разъясню принципы уплотнения памяти, научу просматривать индекс фрагментации и количественно оценивать излишнюю задержку, вызванную уплотнением памяти.
▍Краткая история дефрагментации
Прежде чем начать, хочу посоветовать вам хорошее чтиво. Ниже приведены статьи, в которых рассказывается обо всех усилиях, приложенных к оптимизации выделения высокоуровневой памяти в ядре Linux.
Ну, а теперь можно приступать.
▍Алгоритм двойников
В Linux в качестве аллокатора страниц используется простой и эффективный алгоритм двойников. При этом в его классическую версию были внесены кое-какие доработки:
- аллокация разделов памяти;
- выделение наборов страниц для каждого отдельного ЦПУ;
- группировка по типам миграции.
В ядре Linux для описания физической памяти используются понятия узла, зоны и страницы. Аллокатор разделов сосредотачивается на определенной зоне в определенном узле.
До версии 4.8 ядро реализовывало переработку страниц на основе зоны, потому что ранний дизайн был ориентирован в основном на 32-битные процессоры, и в нем присутствовало много памяти верхнего уровня. Однако темп устаревания страниц в различных зонах одного узла оказывался несогласованным, что вызывало множество проблем.
За довольно длительный период сообщество добавило немало всяческих патчей, но проблема осталась. В свете все большего использования 64-битных процессоров и больших объемов памяти Мел Громан перенес стратегию оборота страниц (page recycling) из зоны в узел, чем решил проблему. Если для наблюдения за операциями оборота вы используете авторский инструментарий Berkley Packet Filter (BPF), то вам это желательно знать.
Метод выделения наборов страниц для каждого отдельного ЦПУ оптимизирует аллокацию одной страницы, тем самым сокращая частоту конфликтов взаимных блокировок процессоров. С дефрагментацией это никак не связано.
Группировка по типу перемещения– это метод дефрагментации, о котором я расскажу подробно.
▍Группировка по типу перемещения
Для начала вам нужно понять схему адресного пространства памяти. Каждая архитектура процессора имеет собственное определение. Например, определение для x86_64 находится в mm.txt.
Поскольку виртуальный и физический адрес не сопоставляются линейно, доступ к виртуальному пространству через таблицу страниц (например, требование динамического выделения памяти в пользовательском пространстве) не требует непрерывности физической памяти. Возьмем в качестве примера пятиуровневую таблицу страниц Intel, где виртуальный адрес разбивается снизу вверх:
- Нижний уровень: смещение страниц;
- Уровень 1: непосредственный индекс страницы;
- Уровень 2: индекс среднего каталога;
- Уровень 3: индекс верхнего каталога;
- Уровень 4: индекс каталога 4 уровня;
- Уровень 5: глобальный индекс страницы.
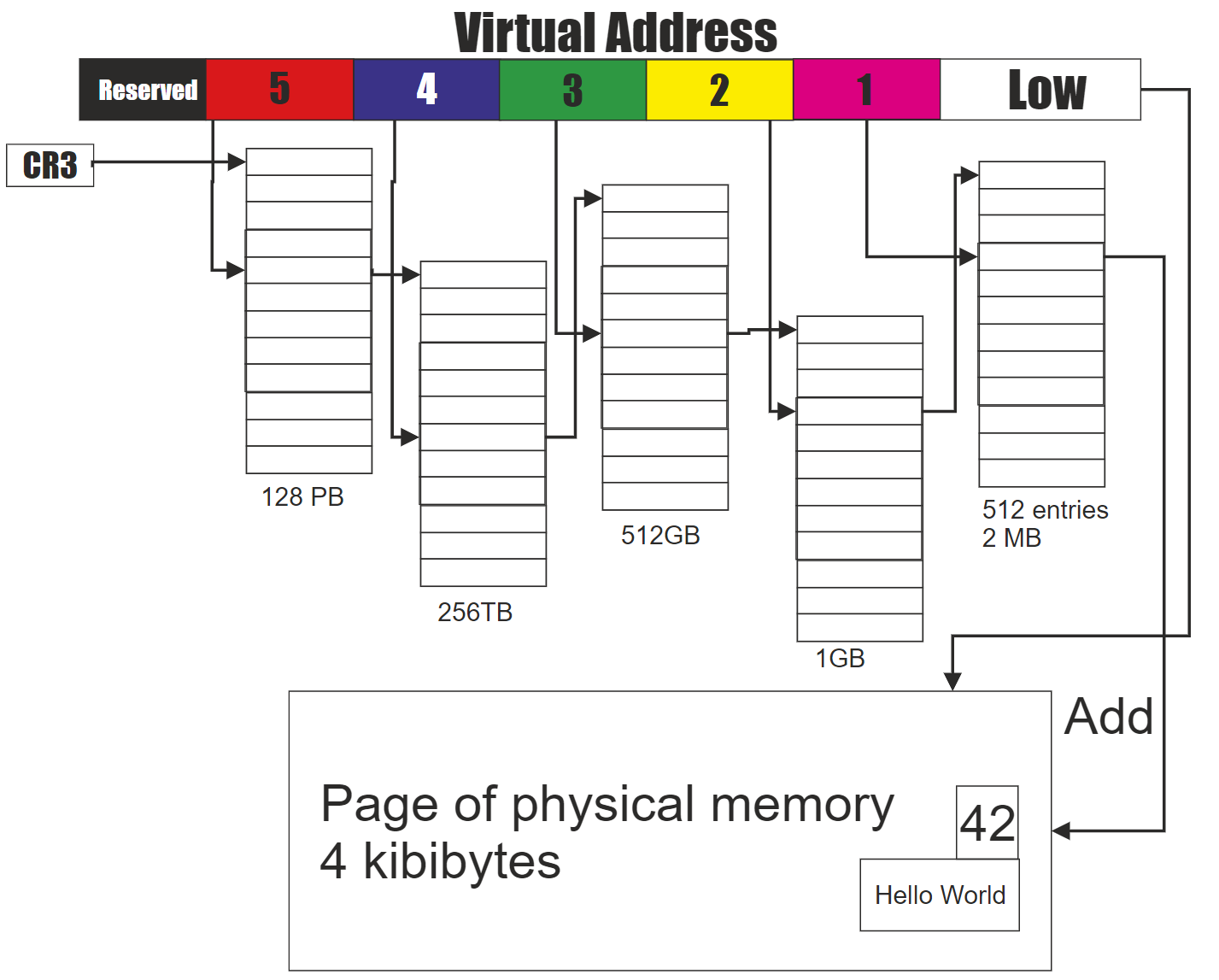
Пятиуровневый пейджинг в системах Intel
Номер фрейма страницы физической памяти хранится в записи таблицы страниц первого уровня, и его можно найти по соответствующему индексу. Физический адрес представляет собой комбинацию найденного номера фрейма и смещения страницы.
Представьте, что хотите изменить соответствующую физическую страницу в записи таблицы первого уровня. Для этого будет достаточно:
- Выделить новую страницу.
- Скопировать данные старой страницы в новую.
- Изменить значение записи таблицы страниц первого уровня на новый номер фрейма страницы.
Эти операции не изменят исходный виртуальный адрес, и вы можете переносить подобные страницы по своему желанию.
В линейной области сопоставления виртуальный адрес представлен как физический адрес плюс константа. Изменение физического адреса приводит к изменению виртуального, в результате чего обращение к последнему вызывает ошибку. Следовательно, эти страницы переносить не рекомендуется.
Когда физические страницы, доступ к которым происходит через таблицу страниц, и страницы, к которым он осуществляется через линейное отображение, смешиваются и управляются совместно, возникает фрагментация памяти. В связи с этим в ядре определяется несколько типов перемещения памяти, и страницы для дефрагментации группируются по этим типам.
Тремя наиболее используемыми типами перемещения памяти являются: MIGRATE_UNMOVABLE, MIGRATE_MOVABLE и MIGRATE_RECLAIMABLE. Прочие типы имеют особое назначение, о котором я здесь говорить не буду.
Распределение каждого типа перемещения на каждом этапе можно просмотреть через /proc/pagetypeinfo:
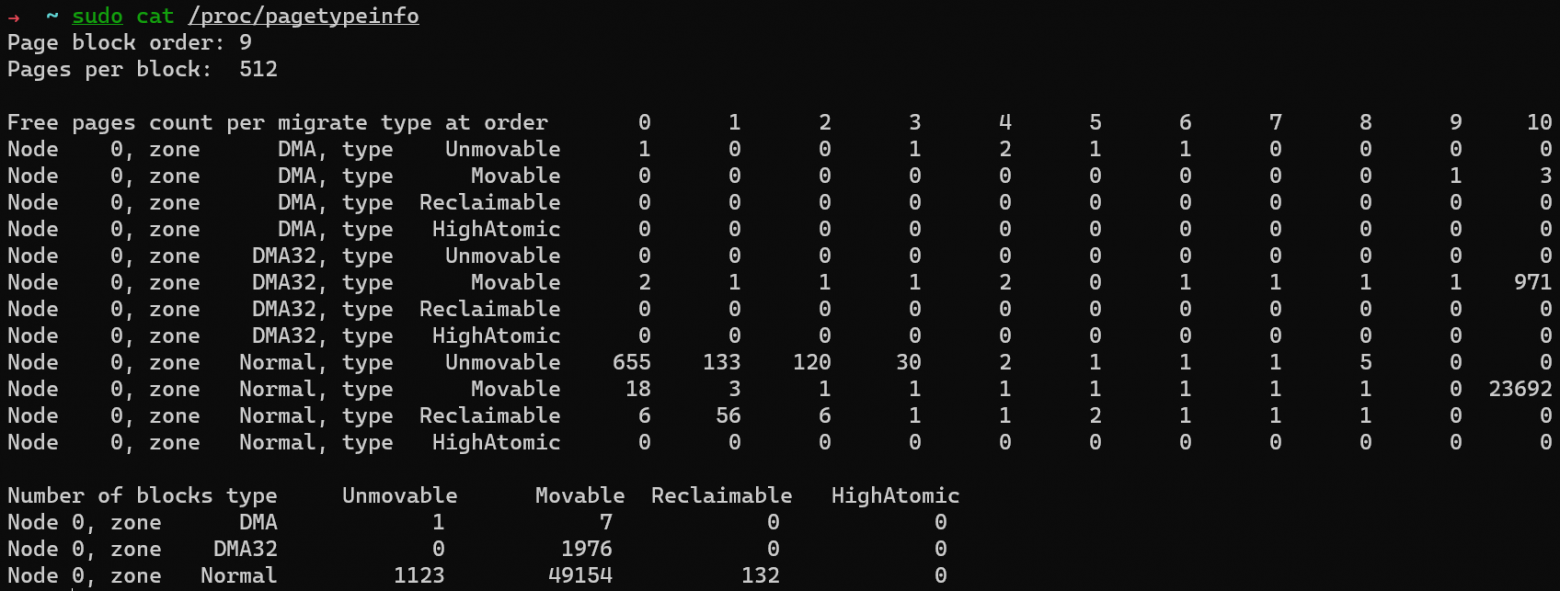
Применяемый к странице флаг аллокации определяет, из какой группы перемещения она аллоцируется. Например, для памяти пользовательского пространства можно использовать __GFP_MOVABLE, а для страниц __GFP_RECLAIMABLE.
Когда страницы определенного типа исчерпываются, ядро изымает физические страницы из других групп. Для избежания фрагментации это изъятие начинается с наибольшего блока страниц. Размер же блока определяется в pageblock_order.
Приоритеты готовности (standby priorities) трех перечисленных типов перемещения в порядке сверху вниз следующие:
MIGRATE_UNMOVABLE: MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE MIGRATE_RECALIMABlE: MIGRATE_UNMOVABLE, MIGRATE_MOVABLE MIGRATE_MOVABLE: MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLEЯдро вводит группировку по типам миграции в целях дефрагментации. Однако частое изъятие страниц указывает на присутствие событий внешней фрагментации памяти, а они могут вызывать проблемы в будущем.
▍Анализ событий внешней фрагментации памяти
В своей предыдущей статье Why We Disable Linux’s THP Feature for Databases я упоминал, что для анализа внешней фрагментации памяти вы можете использовать предоставляемые ядром события ftrace. Процедура в таком случае следующая:
1. Активация событий ftrace:
echo 1> /sys/kernel/debug/tracing/events/kmem/mm_page_alloc_extfrag/enable
2. Начало сбора событий ftrace:
cat /sys/kernel/debug/tracing/trace_pipe> ~/extfrag.log3. Прекращение сбора нажатием Ctrl+C. Событие содержит множество полей:
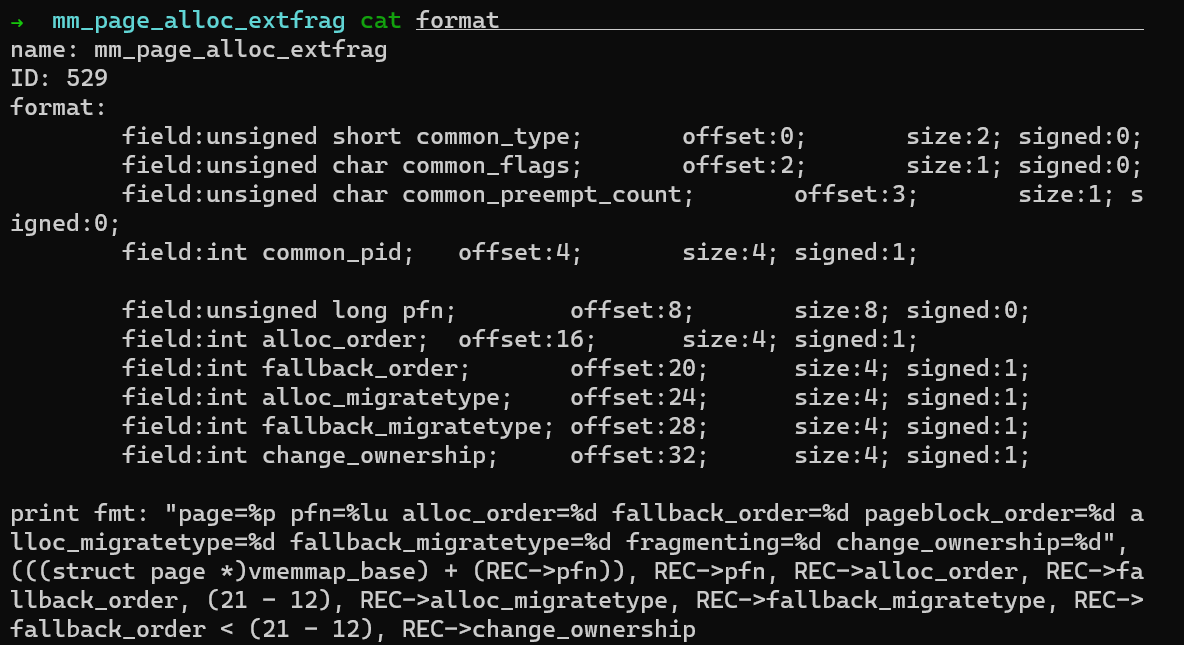
Для анализа количества событий внешней фрагментации памяти сосредоточьтесь на тех, которые содержат fallback_order < pageblock order. В среде x86_64 pageblock order равен 9.
4. Очистка события:
echo 0> /sys/kernel/debug/tracing/events/kmem/mm_page_alloc_extfrag/enable
Здесь мы видим, что группировка по типам перемещения только откладывает фрагментацию, но не решает проблему в корне.
Увеличение фрагментации и нехватка непрерывной физической памяти сказываются на быстродействии. Значит, одной только описанной меры оказывается недостаточно.
Уплотнение памяти
До внедрения принципа уплотнения памяти в ядре для дефрагментации использовалось неравномерное возвращение страниц (lumpy reclaim). Тем не менее в версии 3.10 (на данный момент самая распространенная) этот функционал был исключен. Если вам интересно узнать об этой технике побольше, можете почитать материалы, которые я привел в статье A brief history of defragmentation. Здесь же я сразу перейду к теме уплотнения памяти.
▍Внедрение алгоритма
Статья Memory Compaction на LWN.net подробно описывает алгоритмический принцип уплотнения памяти. В качестве простого примера можно взять следующую фрагментированную зону:

Небольшая фрагментированная зона памяти — LWN.net
Белые блоки — это свободные страницы, а красные — выделенные. Уплотнение памяти в отношении этой зоны делится на три основных этапа:
1. Сканирование зоны слева направо в поиске красных страниц с типом MIGRATE_MOVABLE.
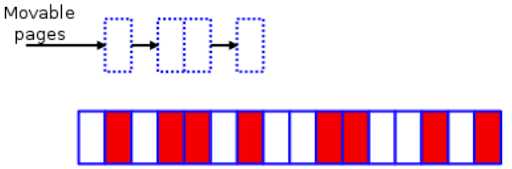
Поиск перемещаемых страниц
2. В то же время сканирование зоны справа налево в поиске свободных страниц.
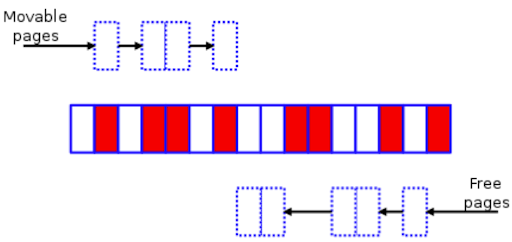
Поиск свободных страниц
3. Сдвиг перемещаемых страниц под свободные для создания непрерывного участка свободного пространства.
Зона памяти после уплотнения
Сам принцип выглядит относительно простым, и ядро также предоставляет /proc/sys/vm/compact_memory для запуска уплотнения памяти вручную.
Однако, как говорилось в начале текущей статьи, уплотнение памяти на практике оказывается на особо эффективным — по меньшей мере, не для наиболее распространенной v3.10 — независимо от ручного или автоматического запуска. Ввиду сопутствующей вычислительной нагрузки эта операция, наоборот, ведет к образованию узкого места.
Хотя участники сообщества не отказались от этой идеи и продолжили ее оптимизировать. Например, позднее в ядро v4.6 был добавлен инструмент kcompactd, а в v4.8 непосредственное уплотнение сделали более определенным.
▍Когда выполняется уплотнение памяти
Я ядре v3.10 эта операция выполняется в любой из следующих ситуаций:
- Вызов потока
kswapdдля балансирования зон после провальной аллокации верхнего уровня. - Вызов потока
khugepagedдля слияния мелких участков памяти в большие страницы. - Активация уплотнения памяти вручную через интерфейс
/proc.
Система для выполнения требования выделить память более высокого уровня прибегает к непосредственному возвращению памяти, включая обработку исключений отказов Transparent Huge Pages (THP).
Функционал THP замедляет производительность, поэтому данную опцию рекомендуется отключать. Этот нюанс я здесь разбирать не стану и сосредоточусь в основном на процессе выделения памяти.
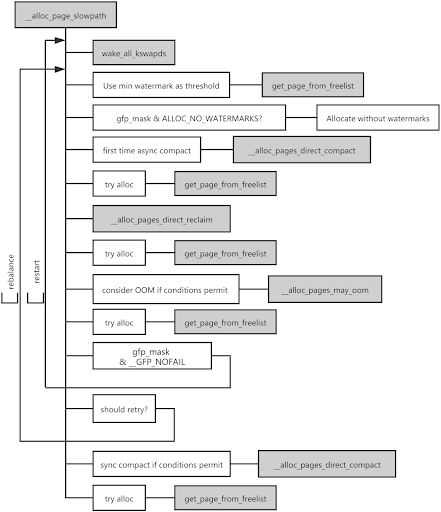
Выделение памяти по медленном пути (slow path)
Если при выделении в списках аллокатора доступных страниц не обнаруживается, происходит следующее:
- Ядро обрабатывает этот запрос по медленному пути и пытается выделить страницы, используя в качестве порога нижний предел.
- Если выделение памяти проваливается, что указывает на небольшой ее недостаток, аллокатор пробуждает поток
kswapdдля асинхронного возвращения страниц и повторяет попытку их выделения, также используя в качестве порога нижний предел. - Провал и этой операции будет означать уже серьезный недостаток памяти. В таком случае ядро сначала запускает асинхронное уплотнение памяти.
- Если и это выделение после асинхронного уплотнения памяти провалится, ядро возвращает память непосредственно.
- Если после этого ядро вернет недостаточно свободных страниц для выполнения требований, оно выполняет прямое уплотнение памяти. Если же освободить не удалось ни одной страницы, для возвращения памяти вызывается OOM Killer.
Перечисленные шаги представляют лишь упрощенное описание фактического потока. В реальности он сложнее и отличается в зависимости от уровня запрошенной памяти и флагов аллокации.
Что касается непосредственного возвращения, то оно выполняется только в случае серьезного недостатка памяти, а также ввиду ее фрагментации в практических сценариях. В определенные моменты обе этих ситуации могут возникать одновременно.
▍Анализ уплотнения памяти
Количественная оценка задержки
Как говорилось в предыдущем разделе, ядро при выделении памяти может выполнять ее возвращение или уплотнение. Чтобы облегчить количественную оценку задержки, вызываемой непосредственным возвращением памяти и ее уплотнением, я добавил в проект BCC два инструмента, drsnoop и compactsnoop.
Они оба основаны на событиях ядра и подробно задокументированы, но кое-что я все же хочу пояснить: для снижения затрат на введение Berkeley Packet Filters (BPF) эти инструменты перехватывают задержку каждого соответствующего события. Следовательно, из вывода видно, что каждому запросу памяти соответствует несколько результатов задержки.
Причина такого отношения один-ко-многим в том, что для более старых версий ядра вроде v3.10 неясно, сколько раз ядро попытается вернуть память по медленном пути. Эта неопределенность также приводит к тому, что OOM Killer начинает запускаться слишком рано или слишком поздно. В результате большинство задач на сервере подвешиваются на долгое время.
После внедрения патча mm: fixed 100% CPU kswapd busyloop on unreclaimable nodes в v4.12 максимальное число операций непосредственного возвращения памяти было ограничено до 16. Предположим, что средняя задержка такой операции составляет 10 мс. (Сокращение активных или неактивных таблиц цепочек LRU оказывается затратным для современных серверов с несколькими сотнями гигабайтов ОЗУ. Также накладывается дополнительная задержка, если серверу приходится ожидать обратной записи «грязной» страницы).
Если поток просит у аллокатора страницы и после одного непосредственного возвращения получает пустую память, задержка такого возвращения возрастает до 10 мс. Если ядру для возвращения достаточного объема памяти придется выполнить 16 таких операций, общая задержка всего процесса выделения составит уже 160 мс, вызвав серьезное падение быстродействия.
Просмотр индекса фрагментации
Вернемся к уплотнению памяти. Основная логика этого процесса делится на четыре этапа:
- Определение, подходит ли зона памяти для уплотнения.
- Установка номера фрейма начальной страницы для сканирования.
- Изоляция страниц типа
MIGRATE_MOVABLE. - Перемещение страниц типа
MIGRATE_MOVABLEв верхнюю часть зоны.
Если после одного перемещения зоне все еще требуется уплотнение, ядро повторяет этот цикл три-четыре раза, пока уплотнение не будет закончено. Эта операция потребляет много ресурсов процессора, в связи с чем при мониторинге зачастую можно видеть его полную загрузку.
Хорошо, а как ядро определяет, подходит ли зона для уплотнения памяти?
Если вы используете интерфейс /proc/sys/vm/compact_memory для принудительного уплотнения памяти зоны, то ядру нет нужды определять ее пригодность для этой процедуры.
Если же уплотнение активируется автоматически, ядро вычисляет индекс фрагментации запрошенного уровня, определяя, достаточно ли в данной зоне осталось памяти для уплотнения.
Чем ближе полученный индекс к 0, тем выше вероятность провала этой операции ввиду недостатка памяти. Это означает, что в таком случае больше подойдет операция возвращения памяти. Приближение же индекса к 1,000 повышает вероятность провала выделения по причине излишней внешней фрагментации. Следовательно, в данной ситуации также нужно применять возвращение памяти, а не уплотнение.
Выбор ядра в пользу уплотнения или возвращения памяти определяется порогом внешней фрагментации, который можно посмотреть через интерфейс /proc/sys/vm/extfrag_threshold.
Также можно непосредственно посмотреть индекс фрагментации с помощью cat /sys/kernel/debug/extfrag/extfrag_index. Имейте ввиду, что результаты ниже поделены на 1,000:

Плюсы и минусы
Анализ уплотнения памяти можно делать как посредством мониторинга интерфейсов на основе файловой системы /proc, так и с помощью инструментов, основанных на событиях ядра (drsnoop и compactsnoop), но каждый из этих способов имеет свои сильные и слабые стороны.
Мониторинг интерфейсов легко использовать, но это не позволит количественно анализировать результаты задержки, и период выборки будет очень долгий. Инструменты на основе ядра, в свою очередь, решают эти проблемы, но в таком случае вам нужно твердо понимать принципы работы подсистем ядра, к тому же здесь есть определенные требования к его клиентской версии.
По факту эти способы хорошо дополняют друг друга. Используя их оба, вы сможете полноценно анализировать уплотнение памяти.
Противодействие фрагментации памяти
В ядре специально заложены механизмы для работы с медленными бэкенд-устройствами. Например, в нем реализован метод замещения страниц по принципу «второго шанса» (Second chance), а также предустановленный диапазон на основе алгоритма LRU, и нет возможности ограничить выделение части памяти под страничный кэш (page cache). Некоторые компании кастомизировали ядро под свои нужды, чтобы ограничить страничный кэш, и даже предлагали внедрение этих версий сообществу, но они были отклонены. Думаю, причина в том, что данный функционал вызывает ряд проблем вроде предустановленных рабочих настроек.
В связи с этим для сокращения частоты операций возвращения памяти и в целях борьбы с фрагментацией будет хорошим решением повысить vm.min_free_kbytes (до 5% от общей памяти). Это косвенно ограничит долю кэша страниц в сценариях с большим числом операций ввода/вывода и в случаях, когда на машине установлено больше 100Гб памяти.
Несмотря на то, что увеличение vm.min_free_kbytes ведет к некоторым затратам памяти, эти затраты оказываются ничтожны. Например, если хранилище сервера имеет объем 256ГБ, и вы установите vm.min_free_kbytes на 4G, то это составит всего 1.5% от общего пространства.
В сообществе, конечно, тоже заметили эту затрату памяти, поэтому в v4.6 был добавлен патч для соответствующей оптимизации.
В качестве альтернативы можно выполнить в нужный момент drop cache, но это способно привести к колебаниям в быстродействии приложения.
Заключение
В начале статьи я кратко объяснил, почему внешняя фрагментация влияет на производительность и рассказал об усилиях, предпринятых сообществом в плане дефрагментации, после чего поведал об основных принципах дефрагментации, используемых в ядре v3.10, а также о способах качественной и количественной оценки фрагментации.
Надеюсь, этот материал оказался вам полезен. Если у вас есть какие-либо мысли по теме управления памятью в Linux, приглашаю к их обсуждению в наше рабочее пространство TiDB Community в Slack.
Прим. пер.: оригинальные статьи за авторством Wenbo Zhang доступны здесь (Часть 1) и здесь (Часть 2).

