[Перевод] Bitmap indexes in Go: unbelievable search speed
My name is Marko and I gave a talk at Gophercon Russia this year about a very interesting kind of indexes called «bitmap indexes». I wanted to share it with the community, not only in video format, but as an article too. It’s an English version and you can read Russian here. Please enjoy!

Additional materials, slides and all the source code can be found here:
http://bit.ly/bitmapindexes
https://github.com/mkevac/gopherconrussia2019
Original video recording:
https://www.youtube.com/watch? v=WvlUH6MjUuI
Let«s begin!
Introduction

Today I am going to talk about
- What indexes are.
- What a bitmap index is;
- Where it’s used. Why it’s not used where it’s not used.
- We are going to see a simple implementation in Go and then have a go at the compiler.
- Then we are going to look at a slightly less simple, but noticeably faster, implementation in Go assembly.
- And after that, I am going to address the «problems» of bitmap indexes one by one.
- And finally, we will see what existing solutions there are.
So what are indexes?
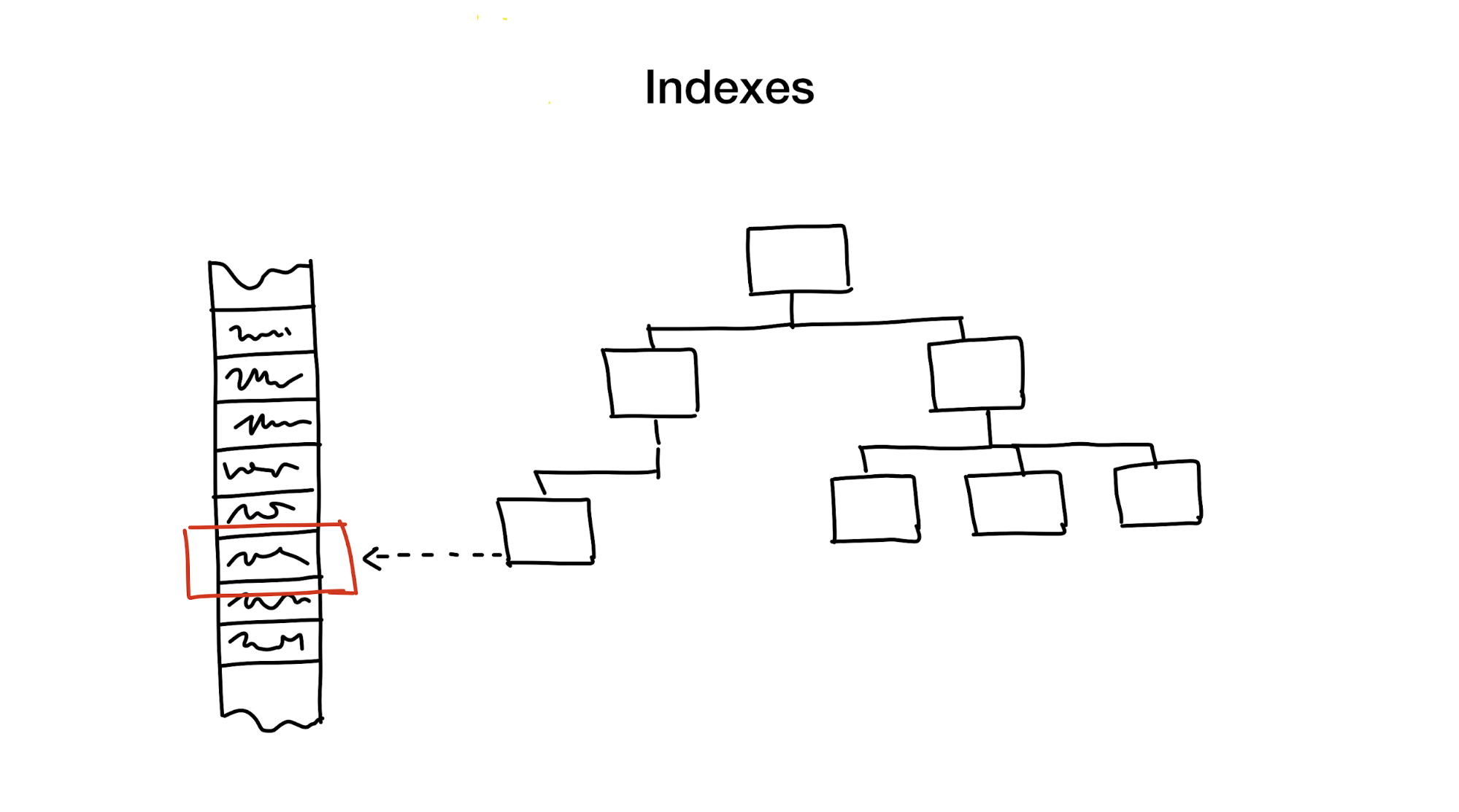
An index is a distinct data structure that is kept updated in addition to main data, used to speed up search requests. Without indexes, the search would involve going through all the data (in a process also known as a «full scan») and that process has linear algorithmic complexity. But databases usually contain huge amounts of data, so linear complexity is too slow. Ideally, we would like to achieve speeds of logarithmic or even constant complexity.
This is an enormous and complex topic involving a lot of tradeoffs, but looking back over decades of database implementations and research I would argue that there are only a few approaches that are commonly used:

First, is reducing the search area by cutting the whole area into smaller parts, hierarchically.
Generally, this is achieved using trees. It is similar to having boxes of boxes in your wardrobe. Each box contains materials that are further sorted into smaller boxes, each for a specific use. If we need materials, we would do better to look for the box labelled «material» instead of a box labeled «cookies».
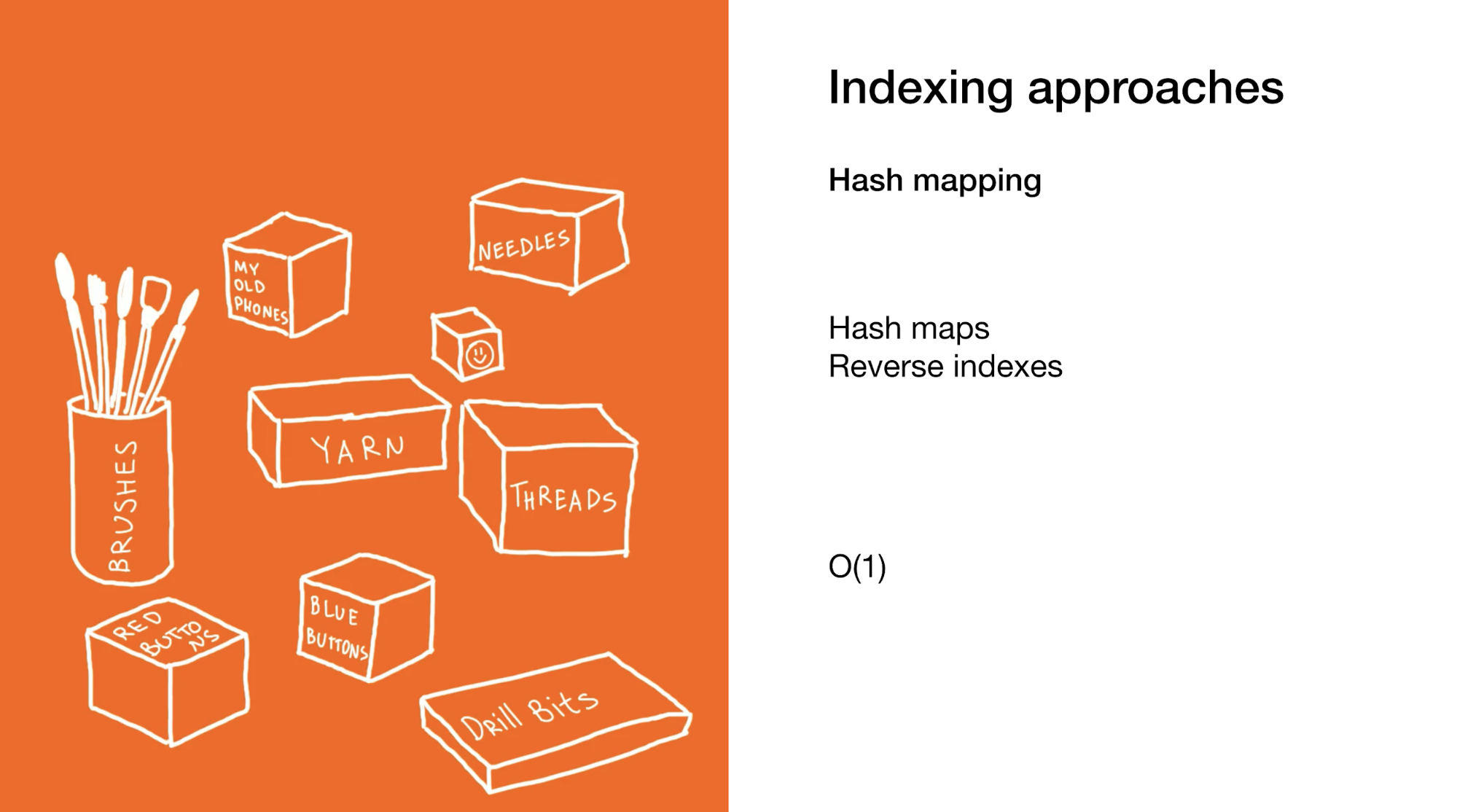
Second is to instantly pinpoint a specific element or group of elements as in hash maps or reverse indexes. Using hash maps is similar to the previous example, but you use many smaller boxes which don’t contain boxes themselves, but rather end items.

The third approach is removing the need to search at all as in bloom filters or cuckoo filters. Bloom filters can give you an answer straight away and save you the time otherwise spent on searching.
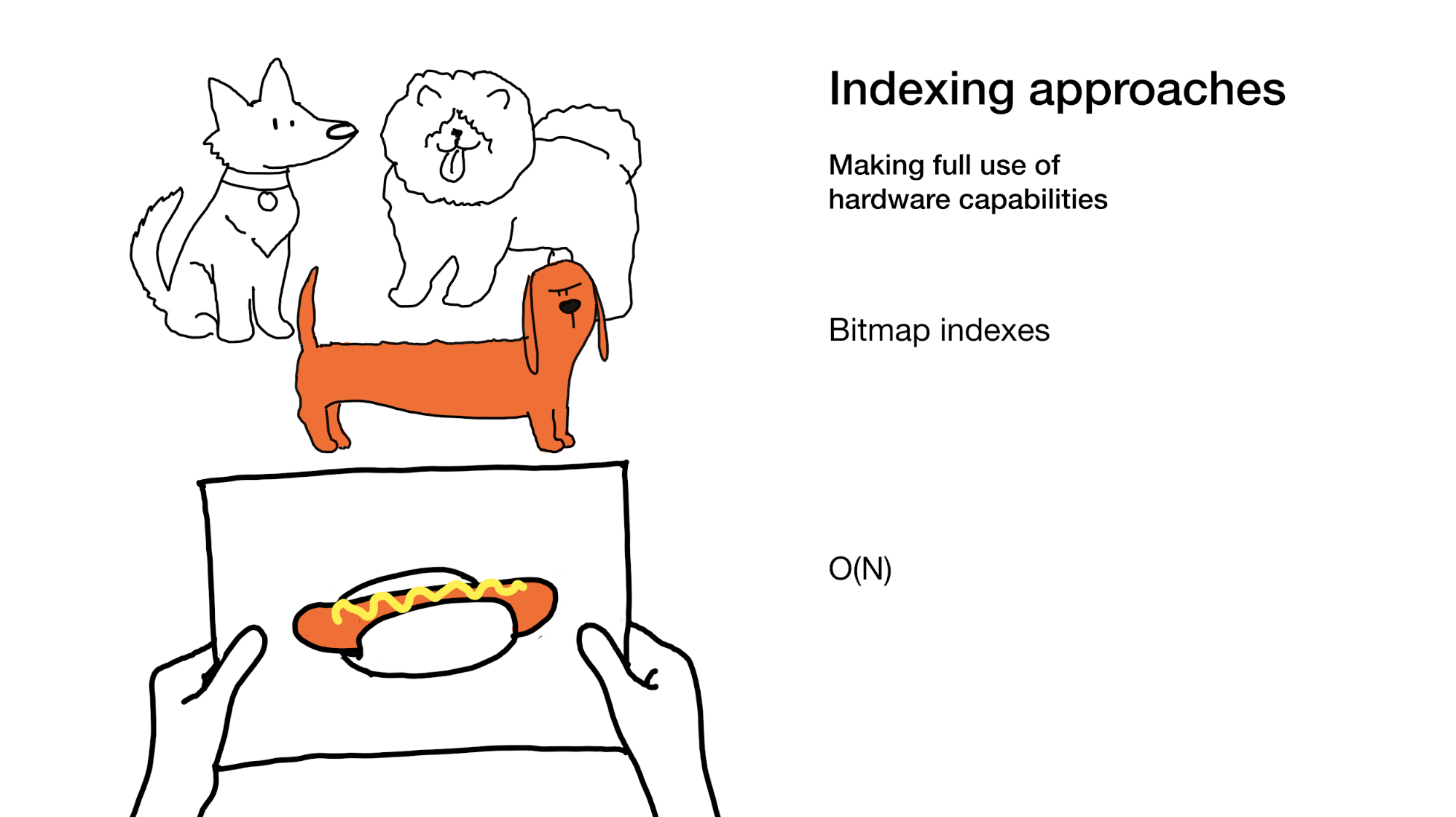
The last one is speeding up the search by making better use of our hardware capabilities as in bitmap indexes. Bitmap indices do sometimes involve going through the whole index, yes, but it is done in a very efficient manner.
As I already said, searching has a ton of tradeoffs, so often we would use several approaches to improve speed even more or to cover all our potential search types.
Today I would like to speak about one of these approaches that is lesser known: bitmap indexes.
But who am I to talk about this subject?
I am a team lead at Badoo (maybe you know another one of our brands: Bumble). We have more than 400 million users worldwide and a lot of the features that we have involve searching for the best match for you! For these tasks we use custom-made services that use bitmap indexes, among others.
Now, what is a bitmap index?
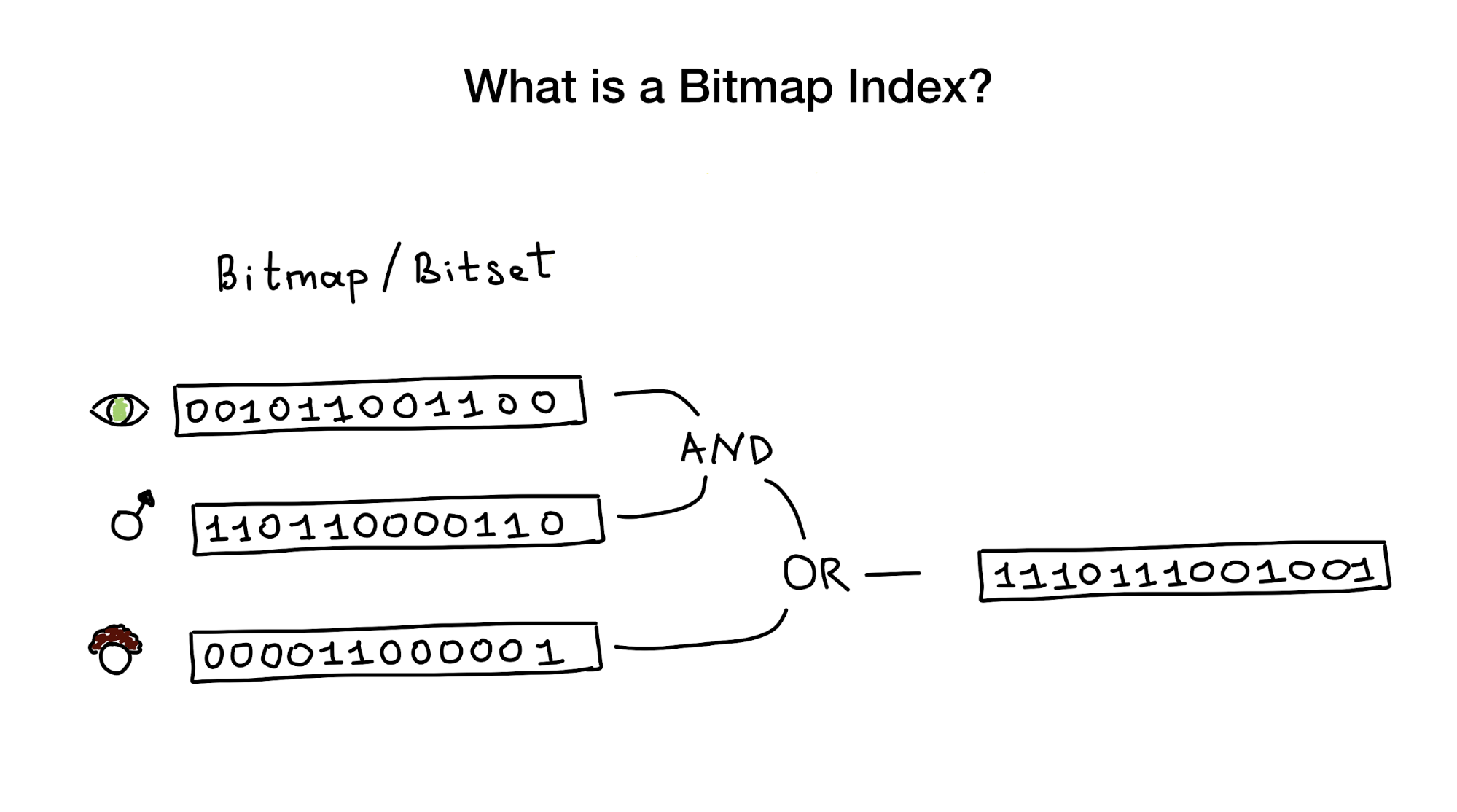
As their name suggests, Bitmap indexes use bitmaps aka bitsets to implement search index. From a bird«s-eye viewpoint this index consists of one or several bitmaps that represent entities (e.g. people) and their parameters (e.g. age, or eye colour) and an algorithm to answer search queries using bitwise operations like AND, OR, NOT, etc.

Bitmap indexes are considered very useful and high-performing if you have a search that has to combine queries by several columns with low cardinality (perhaps, eye color or marital status) versus something like distance to the city center which has infinite cardinality.
But later in the article I will show that bitmap indexes even work with high cardinality columns.
Let’s look at the simplest example of a bitmap index…

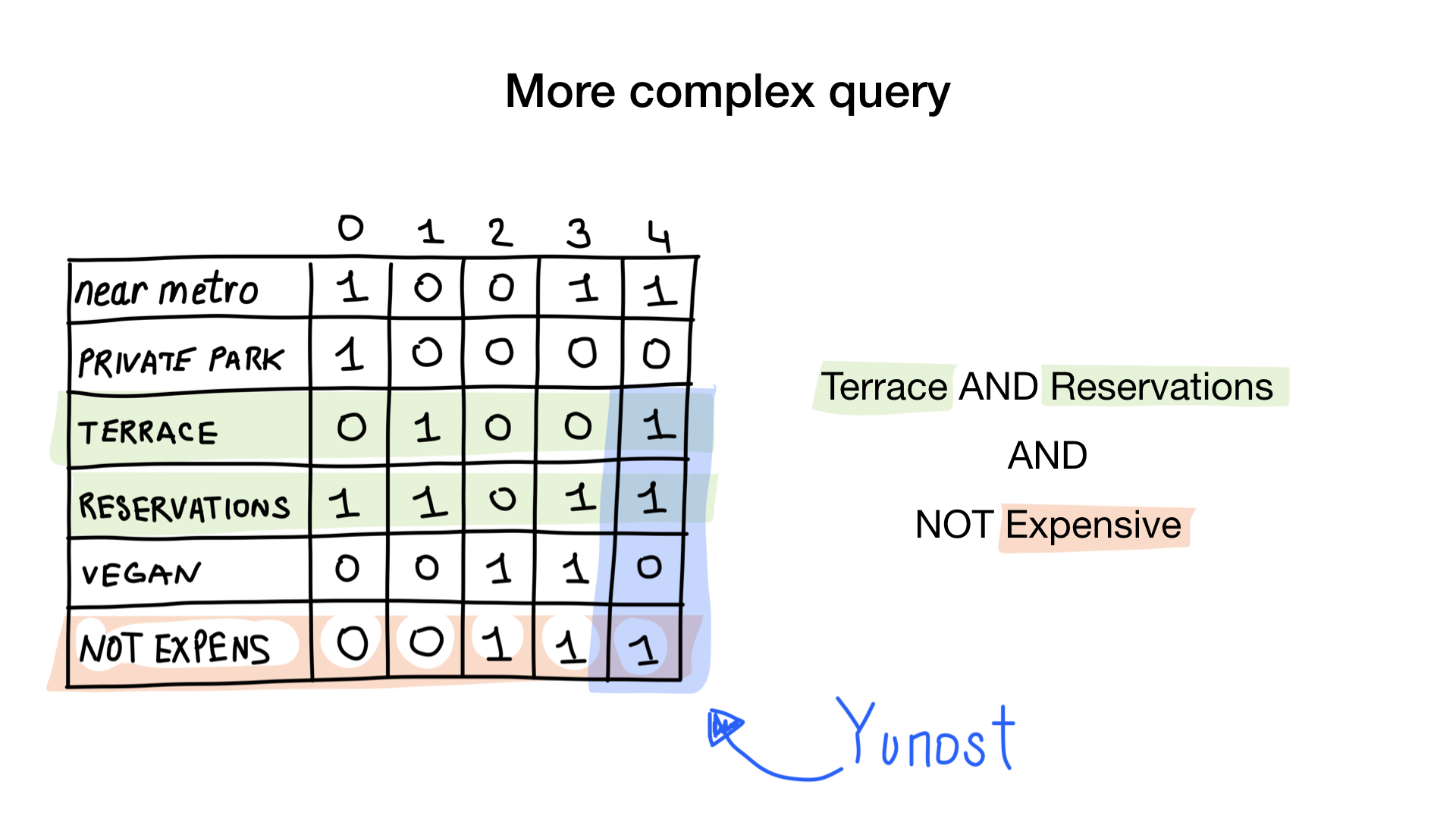
Imagine that we have a list of Moscow restaurants with binary characteristics:
- near metro
- has private parking
- has terrace
- accepts reservations
- vegan-friendly
- expensive
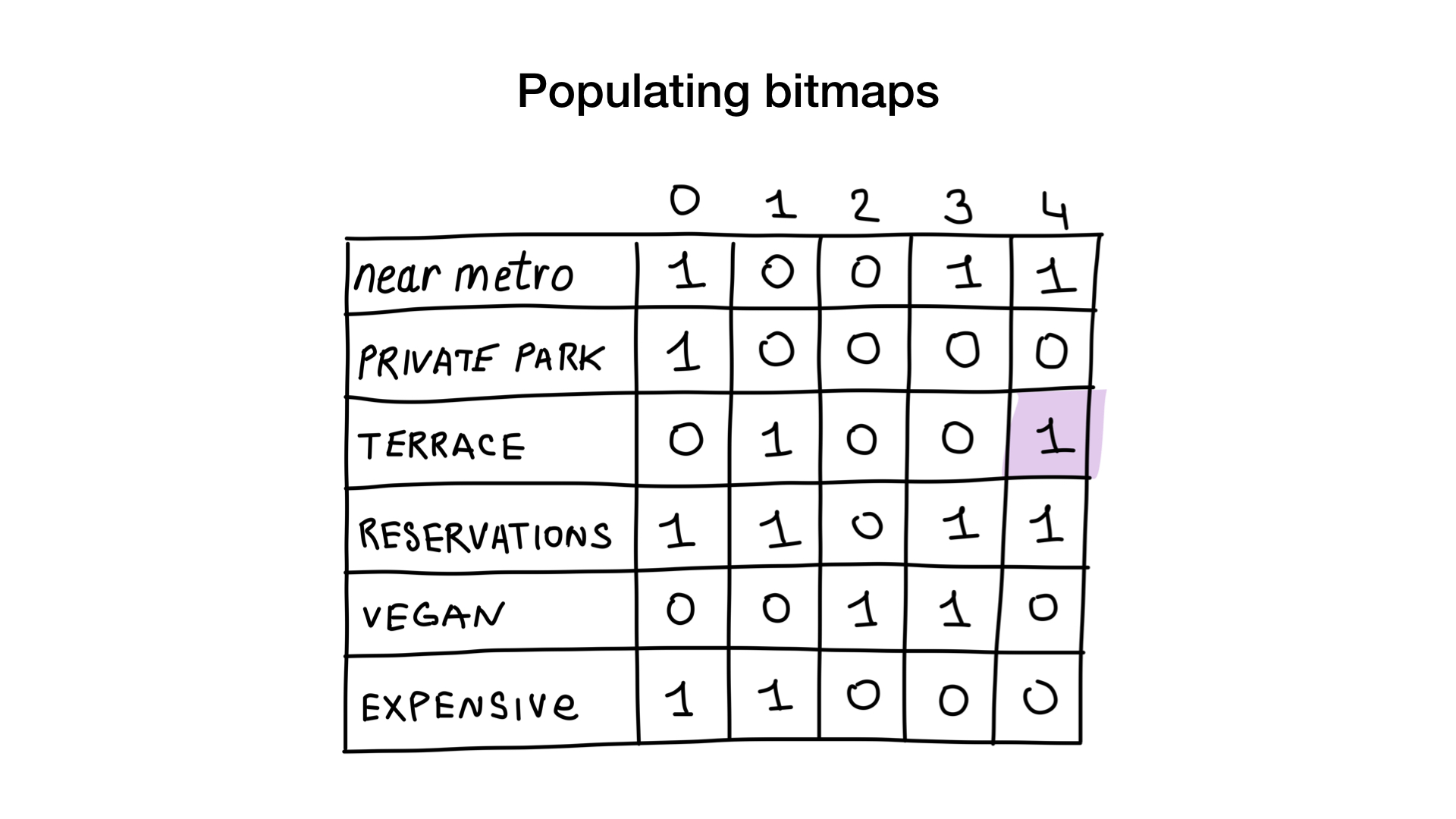
Let’s give each restaurant an index starting from 0 and allocate 6 bitmaps (one for each characteristic). Then we would fill these bitmaps according to whether the restaurant has a specific characteristic or not. If the restaurant number 4 has the terrace, then bit number 4 in «terrace» bitmap will be set to 1 (0 if not).
We now have the simplest bitmap index possible that we can use to answer questions like
- Give me restaurants that are vegan-friendly
- Give me restaurants with a terrace that accept reservations, but are not expensive


How? Let’s see. The first question is a simple one. We just take «vegan-friendly» bitmap and return all indices that have bit set.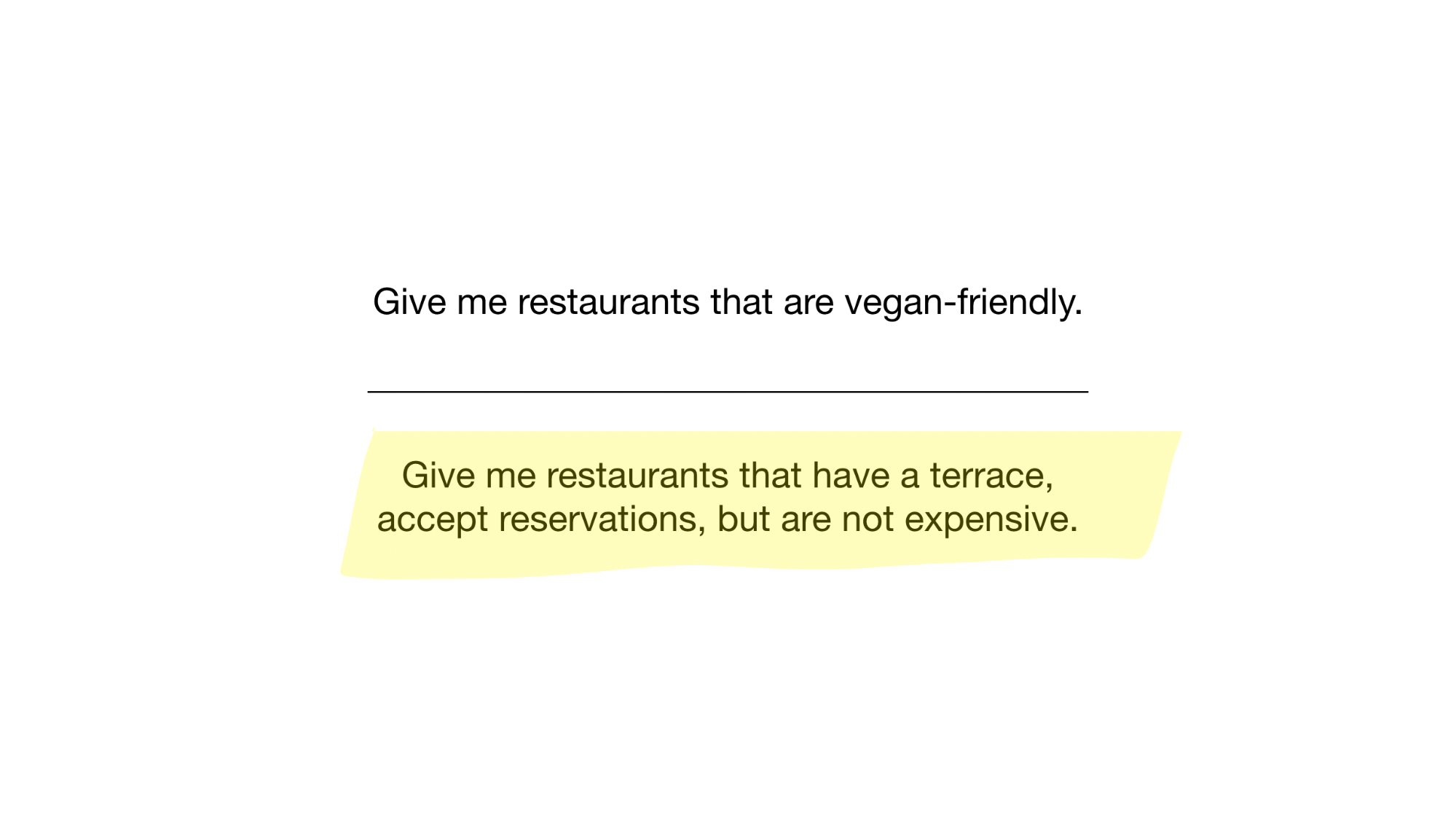

The second question is slightly more complicated. We will use bitwise operation NOT on «expensive» bitmap to get non-expensive restaurants, AND it with «accept reservation» bitmap and AND it with «has terrace bitmap». The resulting bitmap will consist of restaurants that have all these characteristics that we wanted. Here we see that only Yunost has all these characteristics.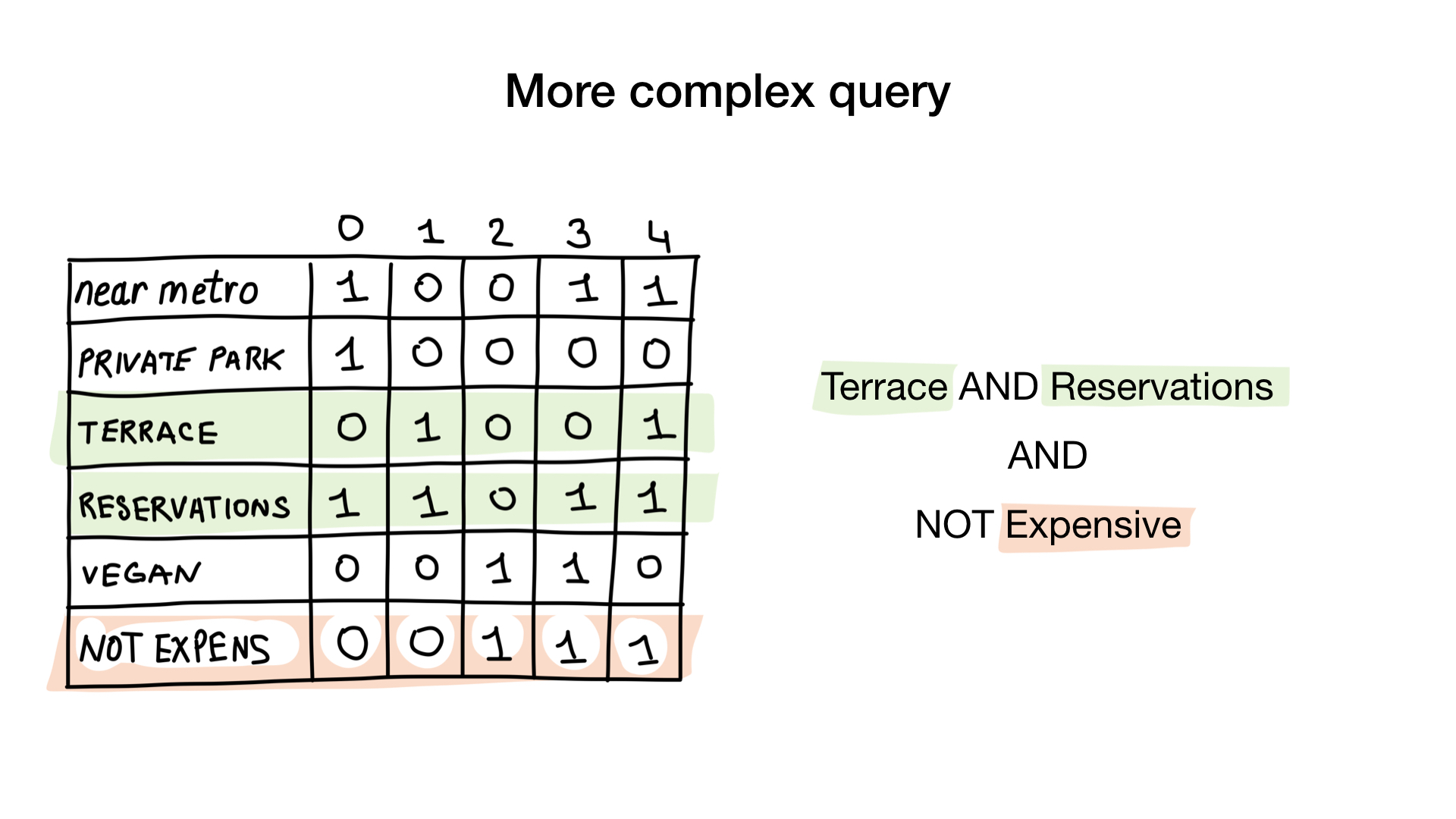
This may look bit theoretical but don’t worry, we«ll get to the code shortly.
Where bitmap indexes are used

If you google «bitmap index», 90% of the results will point to Oracle DB which has basic bitmap indexes. But, surely, other DBMS use bitmap indexes as well, don«t they? No, actually, they don«t. Let’s go through the usual suspects one by one.

- But there is a new boy on the block: Pilosa. Pilosa is a new DBMS written in Go (notice there is no R, it’s not relational) that bases everything on bitmap indexes. And we will talk about Pilosa later.
Implementation in Go
But why? Why are bitmap indexes so rarely used? Before answering that question, I would like to walk you through basic bitmap index implementation in Go.
Bitmap is represented as a chunk of memory. In Go let«s use slice of bytes for that.
We have one bitmap per restaurant characteristic. Each bit in a bitmap represents whether a particular restaurant has this characteristic or not.
We would need two helper functions. One is used to fill the bitmap randomly, but with a specified probability of having the characteristic. For example, I think that there are very few restaurants that don«t accept reservations and approximately 20% are vegan-friendly.
Another function will give us the list of restaurants from a bitmap.

In order to answer the question «give me restaurants with a terrace that accept reservations but are not expensive» we would need two operations: NOT and AND.
We can slightly simplify the code by introducing complex operation AND NOT.
We have the functions for each of these. Both functions go through our slices taking corresponding elements from each, doing the operation and writing the result to the resulting slice.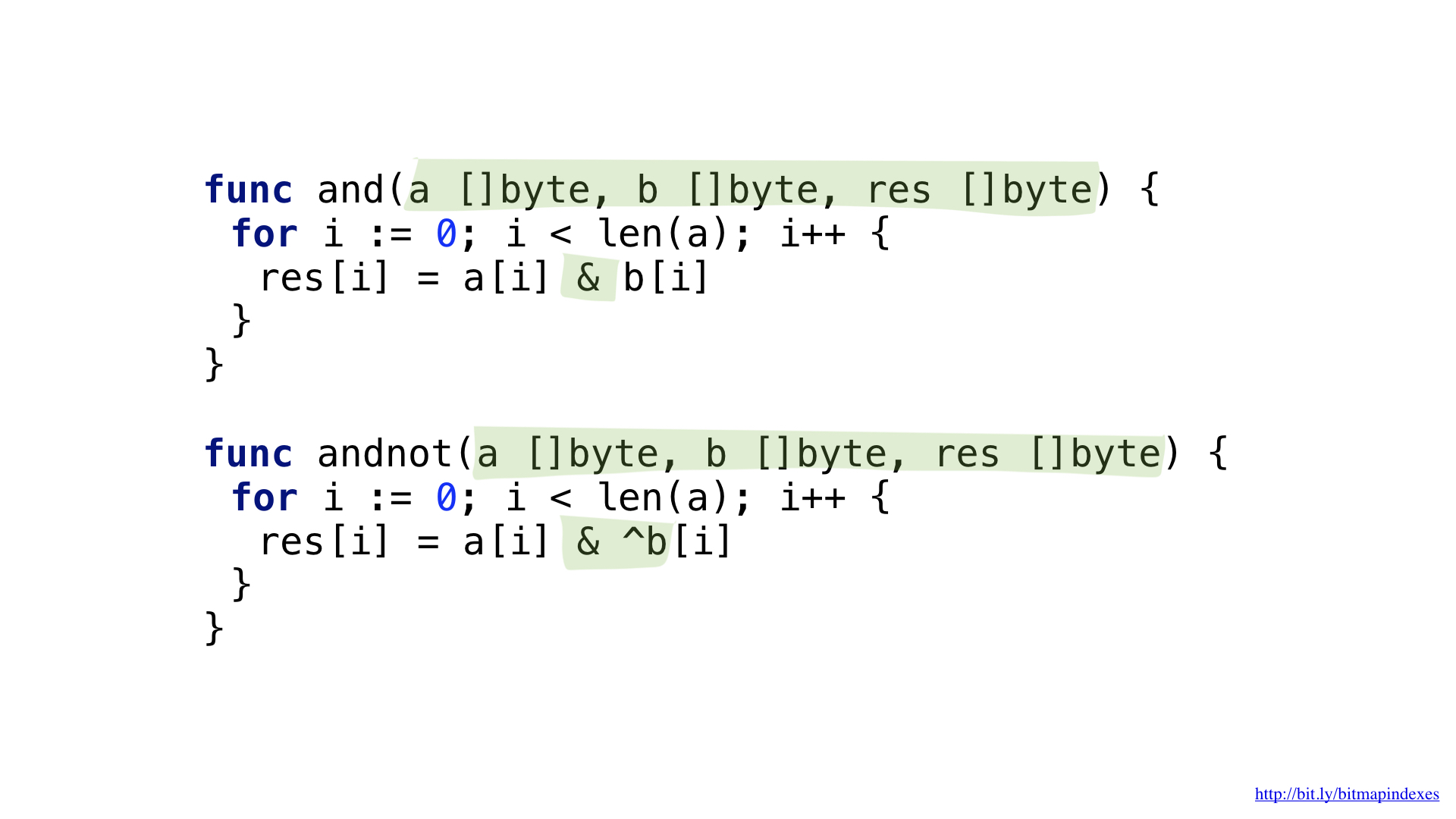
And now we can use our bitmaps and our functions to get the answer.
Performance is not so great here even though our functions are really simple and we saved a lot on allocations by not returning new slice on each function invocation.
After some profiling with pprof, I noticed that go compiler missed one of the very basic optimizations: function inlining.
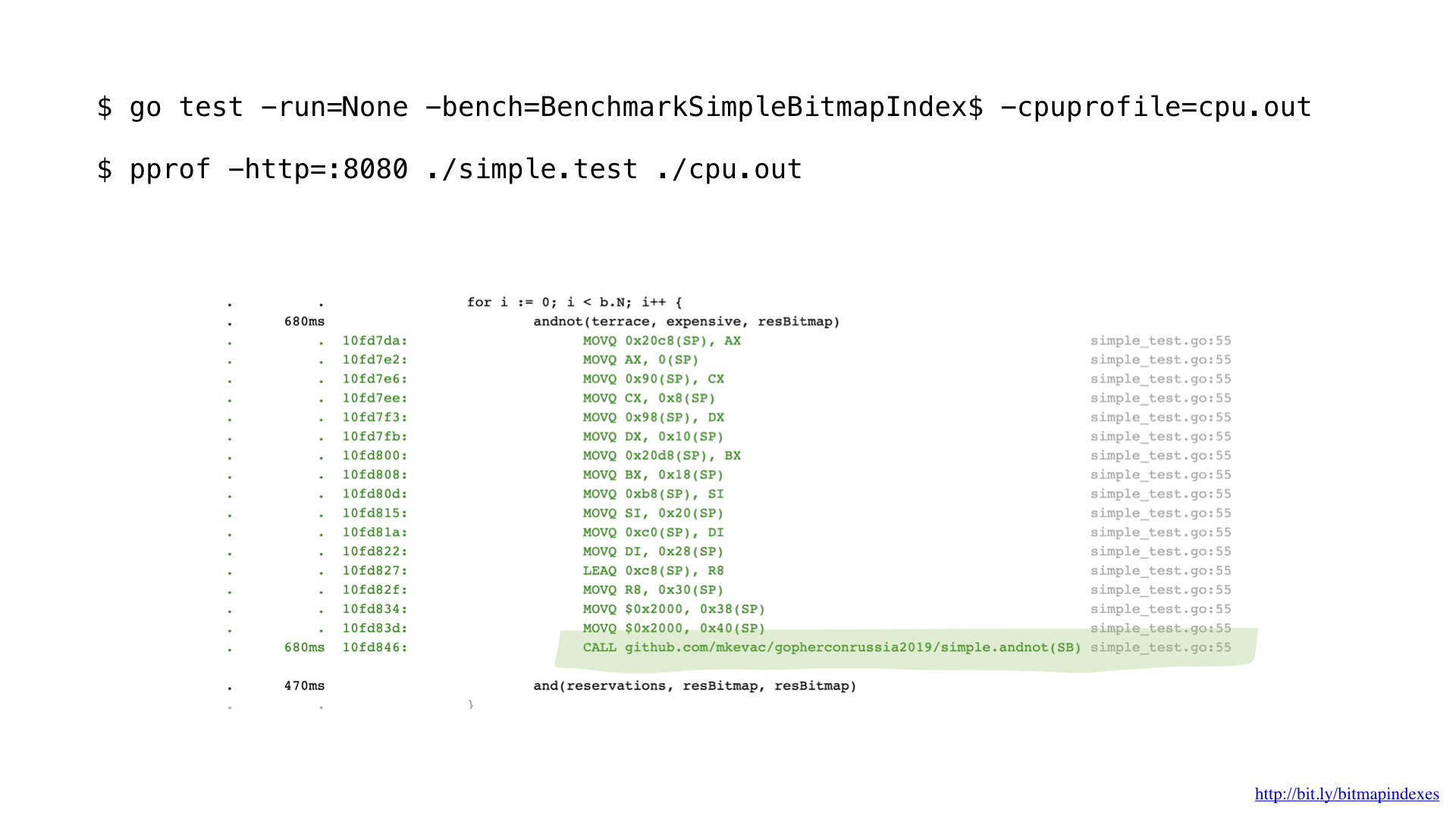
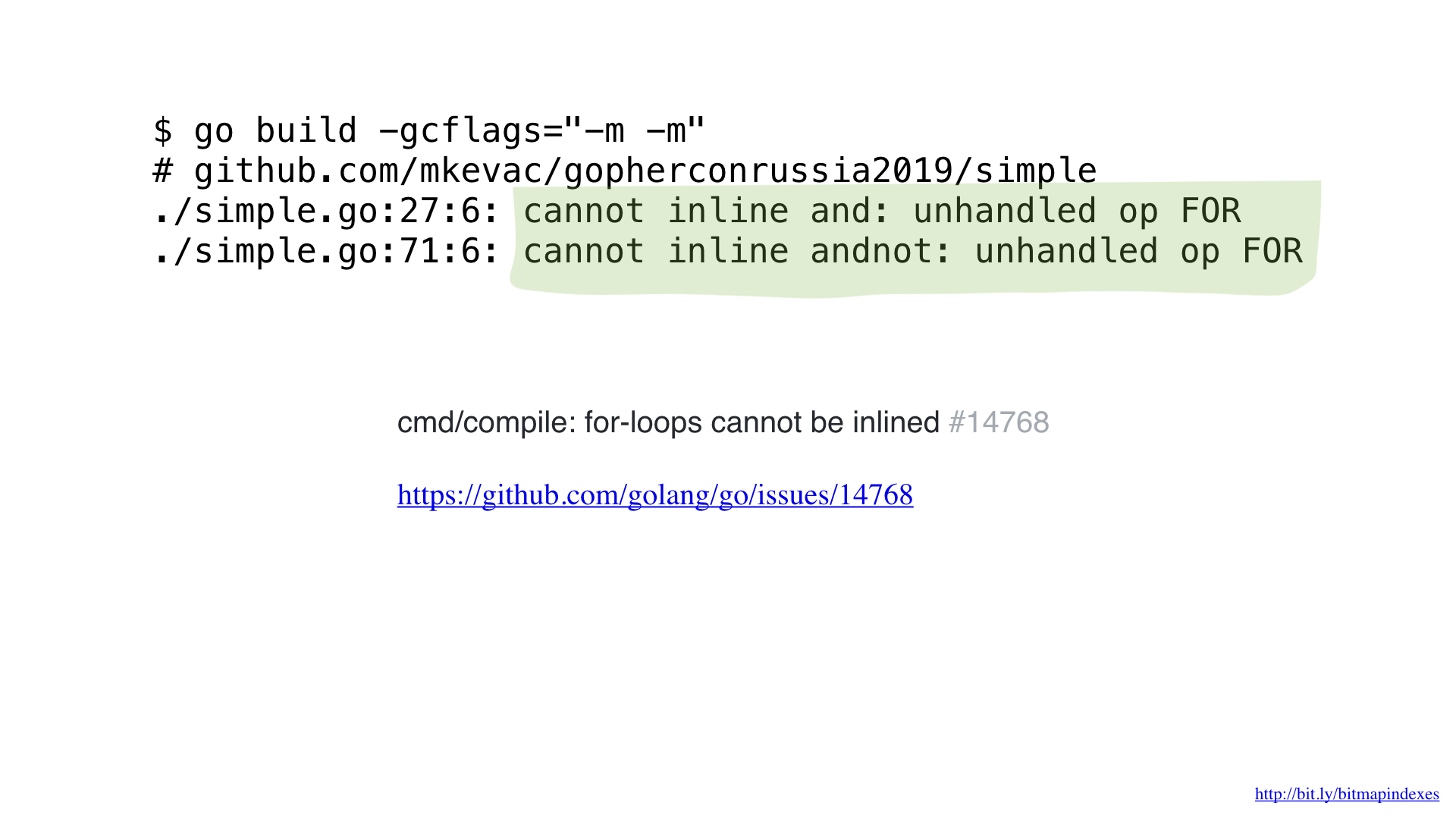
You see, Go compiler is pathologically afraid of loops through slices and refuses to inline any function that has those.
But I am not afraid of them and can fool the compiler by using goto for my loop.


As you can see, inlining saved us about 2 microseconds. Not bad!

Another bottleneck is easy to spot when you take a closer look at assembly output. Go compiler included range checks in our loop. Go is a safe language and the compiler is afraid that my three bitmaps might have different lengths and there might be a buffer overflow.
Let«s calm the compiler down and show it that all my bitmaps are the same length. To do that, we can add a simple check at the beginning of the function.
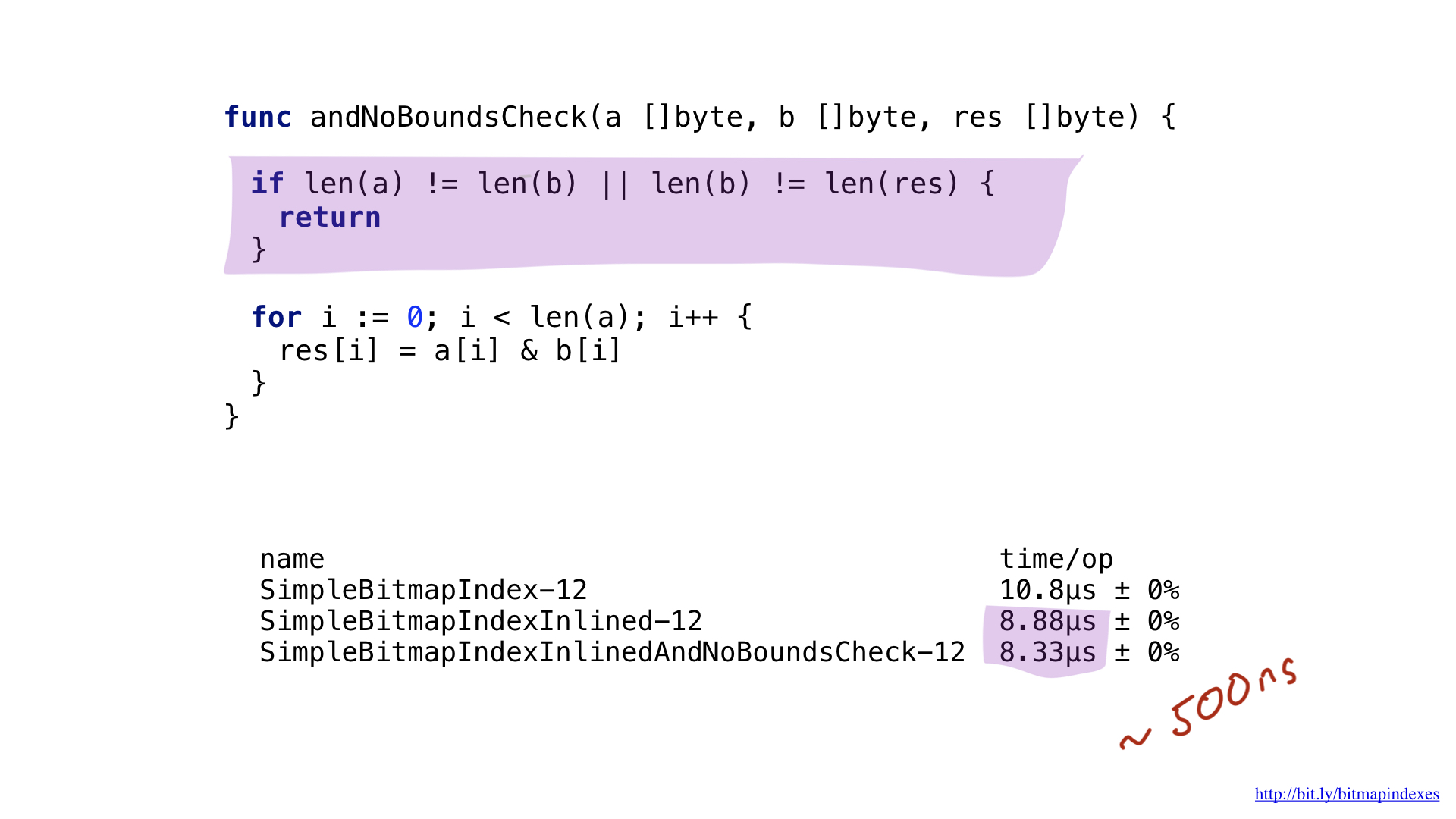
With this check, go compiler will happily skip range checks and we will save a few nanoseconds.
Implementation in Assembly
Alright, so we managed to squeeze a little bit more performance by our simple implementation, but this result is far far worse than what is possible with current hardware.
You see, what we are doing are very basic bitwise operations and our CPUs are very effective with those.
Unfortunately, we are feeding our CPU with very small chunks of work. Our function does operations byte by byte. We can easily tweak our implementation to work with 8-byte chunks by using slices of uint64.

As you can see here, we gained about 8x performance for 8x batch size, so the performance gains are pretty much linear.
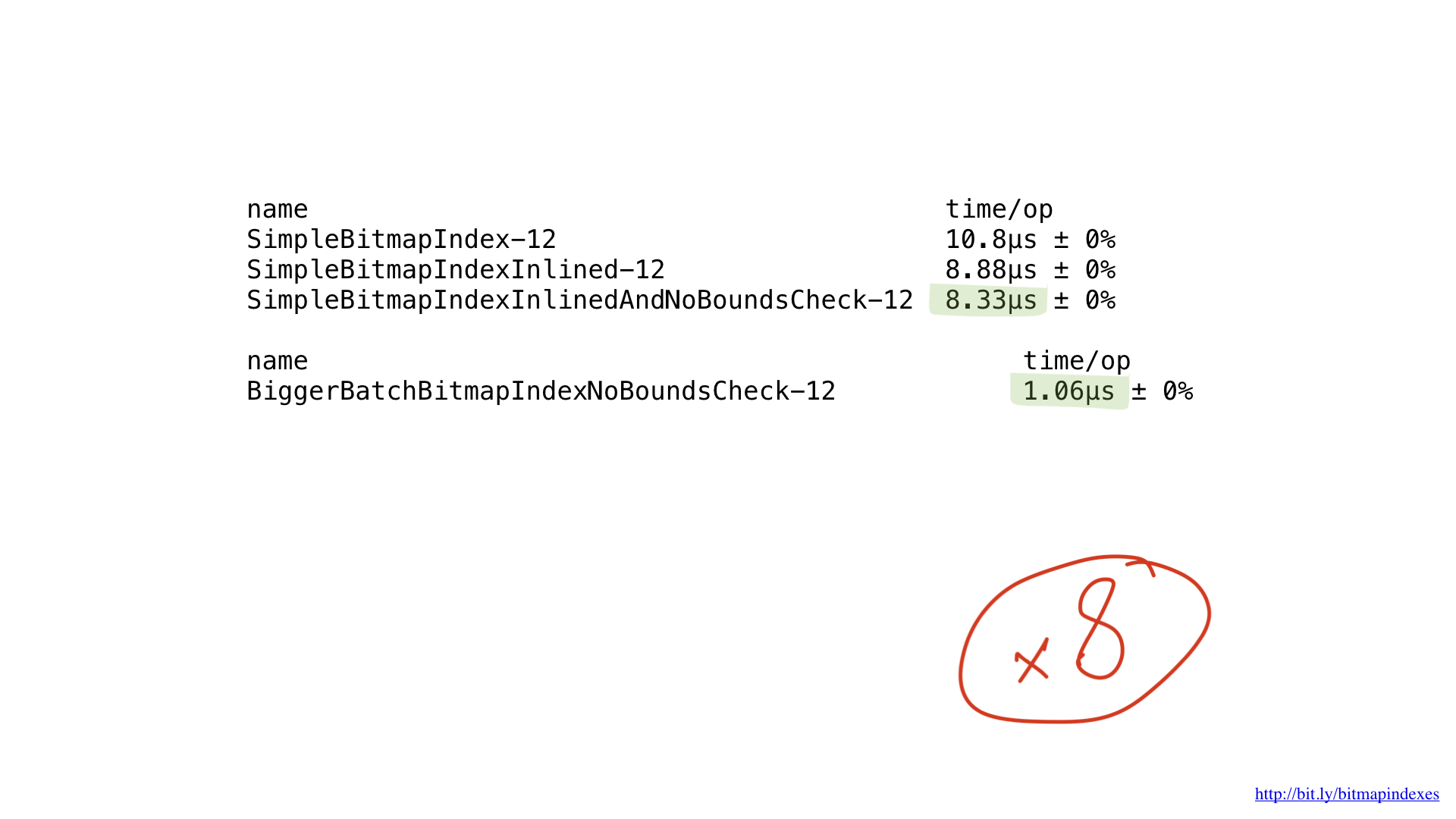

But this isn«t the end of the road. Our CPUs have the ability to work with chunks of 16-byte, 32-byte and even with 64-byte chunks. These operations are called SIMD (Single Instruction Multiple Data) and the process of using such CPU operations is called vectorization.
Unfortunately, Go compiler is not very good with vectorization. And the only thing we can do nowadays to vectorize our code is to use Go assembly and to add these SIMD instructions ourselves.

Go assembly is a strange beast. You«d think that assembly is something that is tied to the architecture you are writing for, but Go’s assembly is more like IRL (intermediate representation language): it is platform-independent. Rob Pike gave an amazing talk on this a few years ago.
Additionally, Go uses an unusual plan9 format which is unlike both AT&T and Intel formats.

It is safe to say that writing Go assembly code is no fun.
Luckily for us, there are already two higher-level tools to help with writing Go assembly: PeachPy and avo. Both of these generate go assembly from a higher level code written in Python and Go respectively.

These tools simplify things like register allocation and loops and all in all reduce the complexity of entering the realm of assembly programming for Go.
We will use avo for this post so our programs look almost like ordinary Go code.

This is the simplest example of an avo program. We have a main () function that defines a function called Add () that adds two numbers. There are helper functions to get parameters by name and to get one of the available general registers. There are functions for each assembly operation like ADDQ here, and there are helper functions to save the result from a register to the resulting value.

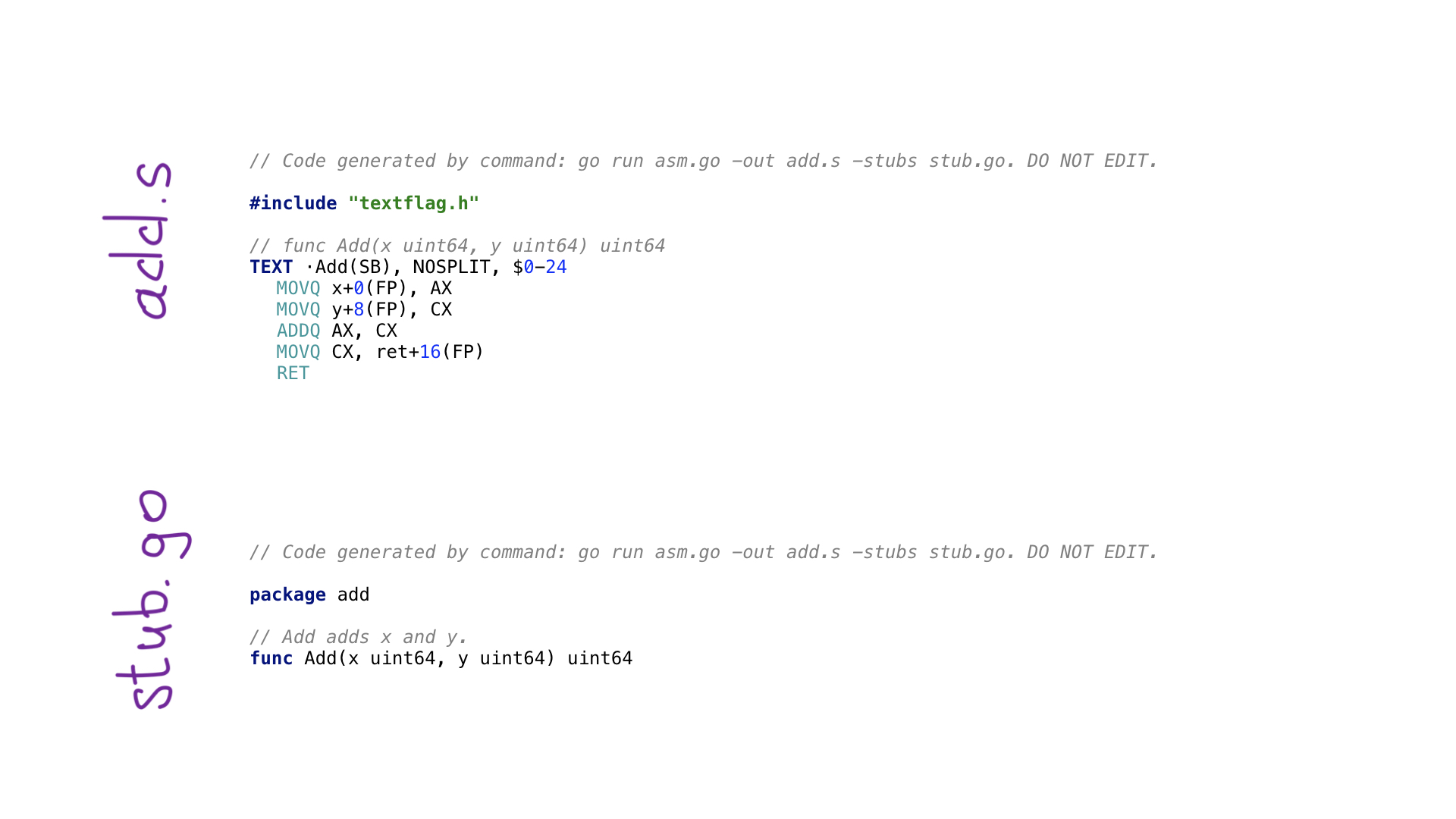
Calling go generate will execute this avo program and two files will be created
- add.s with generated assembly code
- stub.go with function headers that are needed to connect our go and assembly code
Now that we«ve seen what avo does, let’s look at our functions. I’ve implemented both scalar and SIMD (vector) versions of our functions.
Let’s see what the scalar version looks like first.

As in a previous example, we can ask for a general register and avo give us the right one that«s available. We don’t need to track offsets in bytes for our arguments, avo does this for us.

Previously we switched from loops to using goto for performance reasons and to deceive go compiler. Here, we are using goto (jumps) and labels right from the start because loops are higher-level constructs. In assembly we only have jumps.

Other code should be pretty clear. We emulate the loop with jumps and labels, take a small part of our data from our two bitmaps, combine it using one of the bitwise operations and insert the result into the resulting bitmap.

This is a resulting asm code that we get. We didn’t have to calculate offsets and sizes (in green), we didn’t have to deal with specific registers (in red).
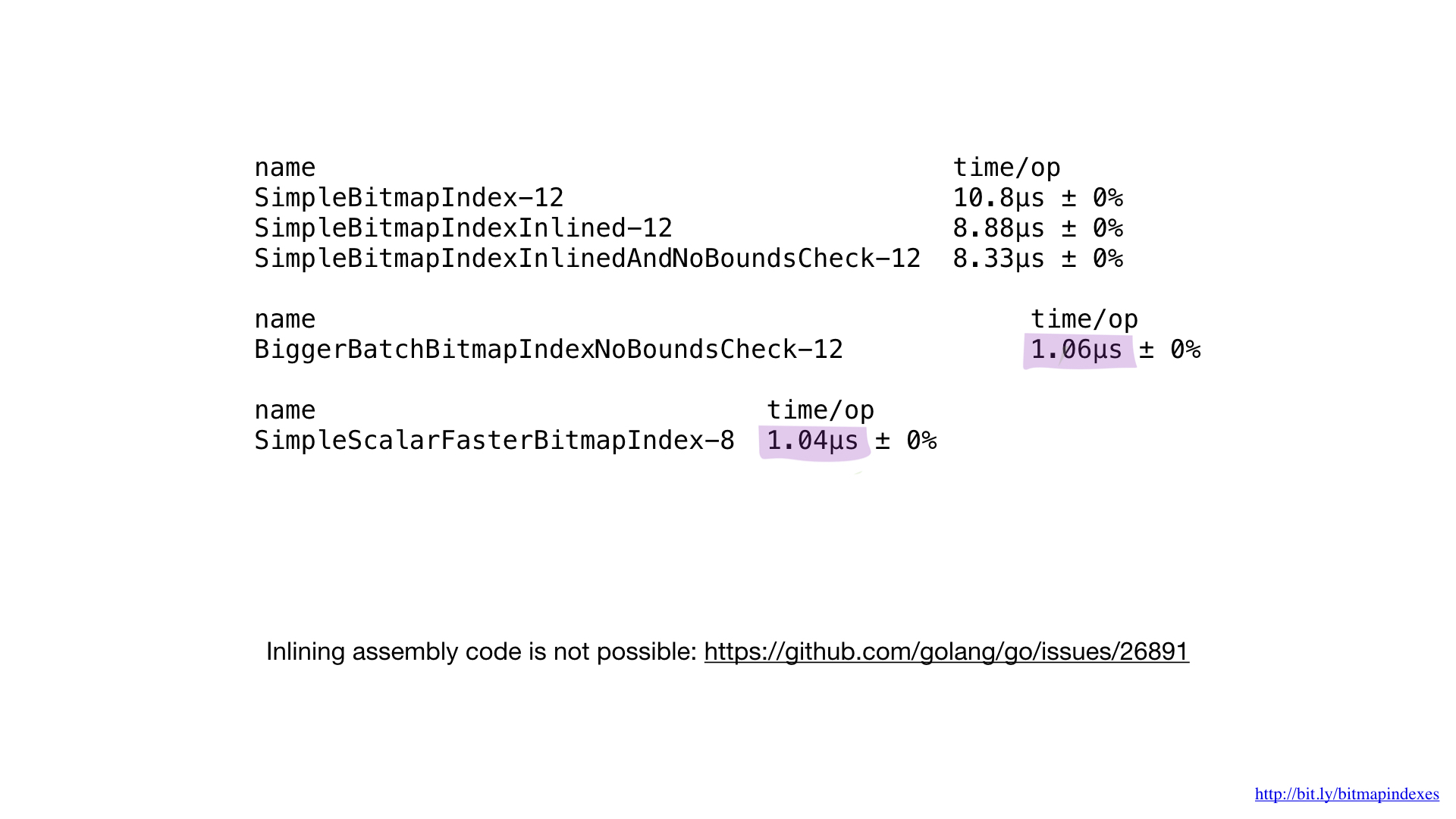
If we compared this implementation in assembly with the previous best one written in go we would see that the performance is the same as expected. We didn’t do anything differently.
Unfortunately, we cannot force Go compiler to inline our functions written in asm. It completely lacks support for it and the request for this feature has existed for some time now. That’s why small asm functions in go give no benefit. You either need to write bigger functions, use new package math/bits or skip asm altogether.
Let’s write vector version of our functions now.

I chose to use AVX2, so we are going to use 32-byte chunks. It is very similar to the scalar in structure. We load out parameters, ask for general registers, etc.
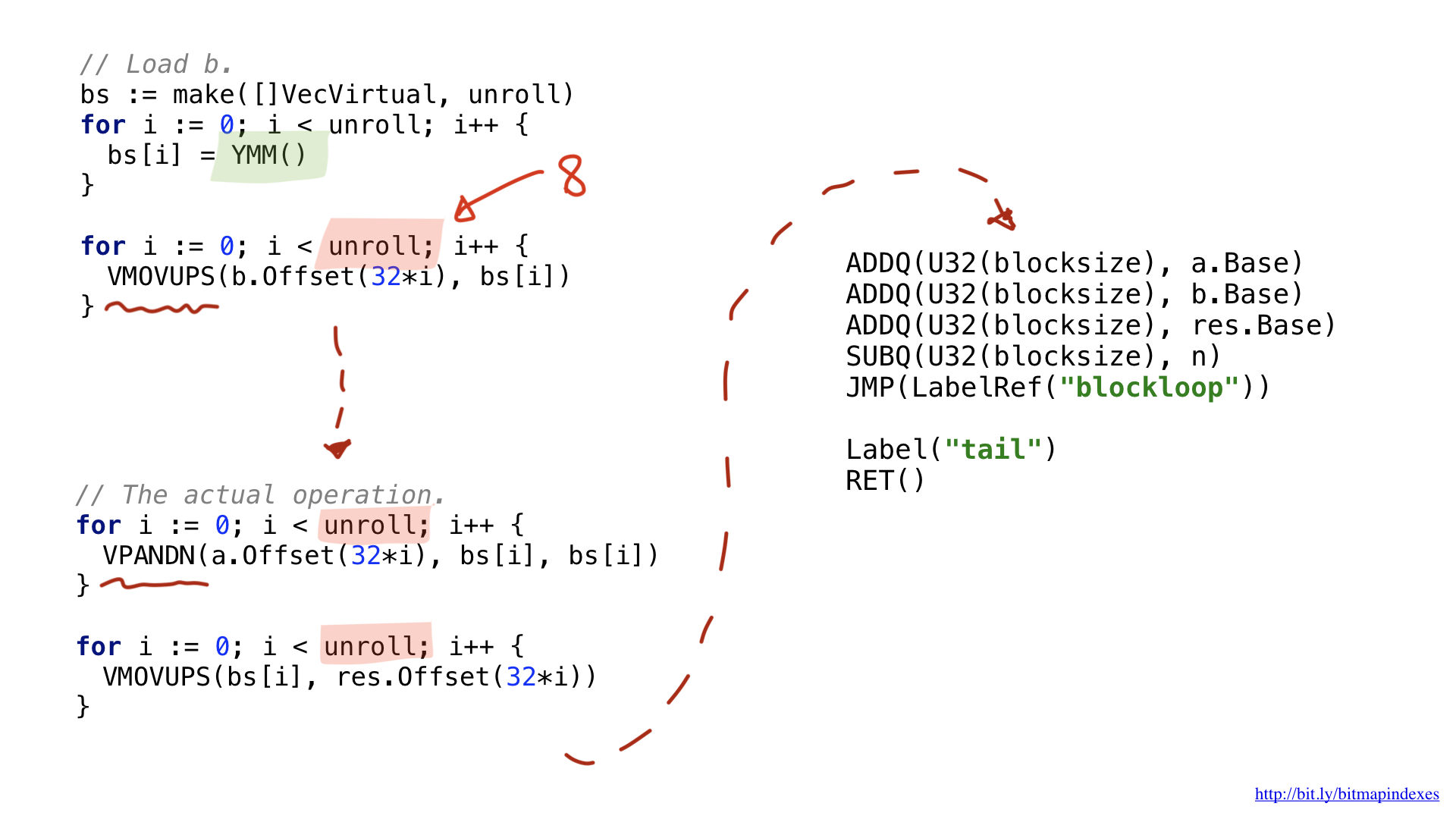
One of the changes has to do with the fact that vector operations use specific wide registers. For 32 bytes they have Y prefix, this is why you see YMM () there. For 64-byte they would have had Z prefix.
Another difference has to do with the optimisation I performed called unrolling or loop unrolling. I chose to partially unroll our loop and to do 8 loop operations in sequence before looping back. This technique speeds up the code by reducing the branches we have and it’s pretty much limited by the number of registers we have available.
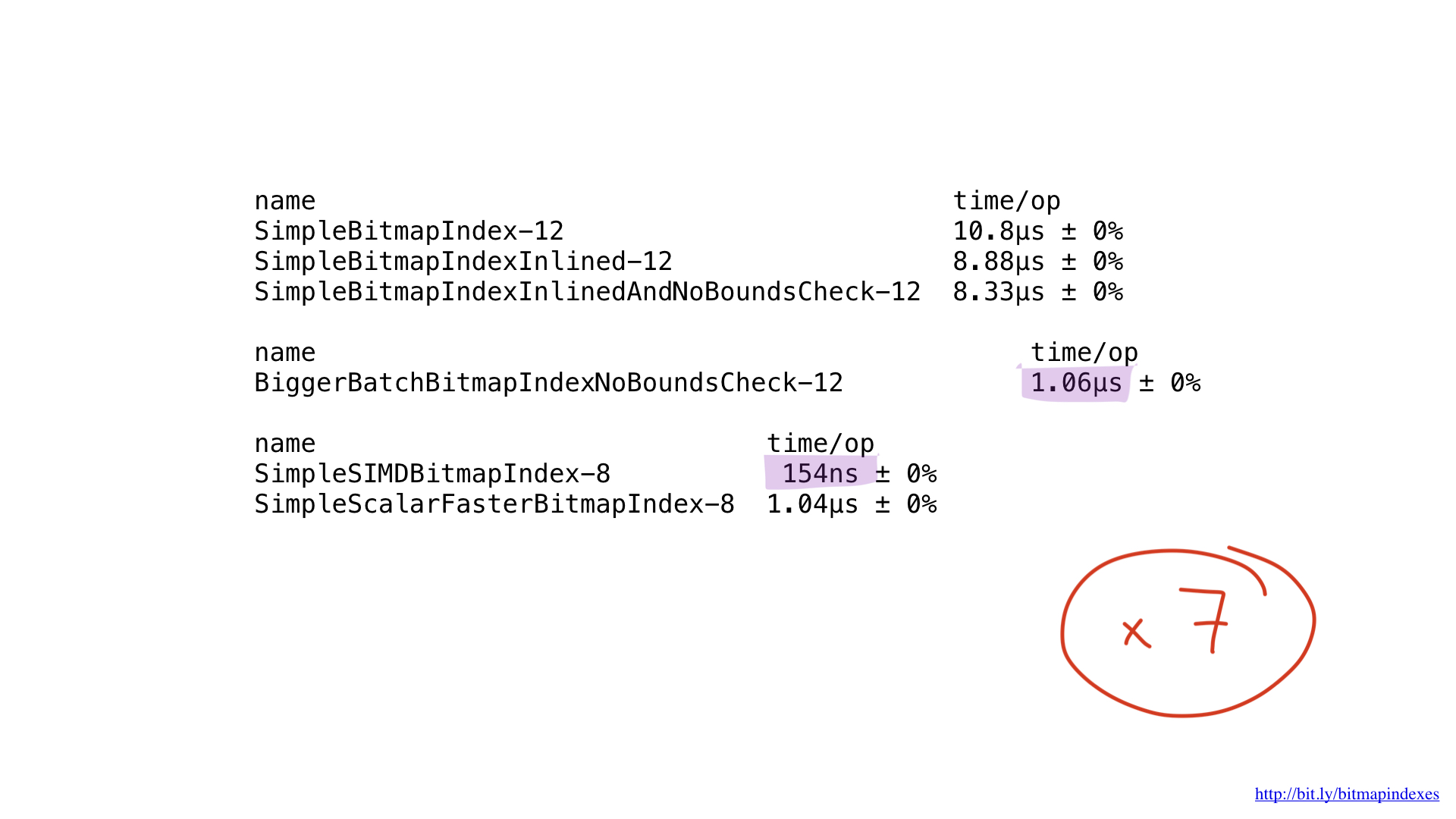
As for performance… it’s amazing. We got about 7x improvement comparing to the previous best. Pretty impressive, right?
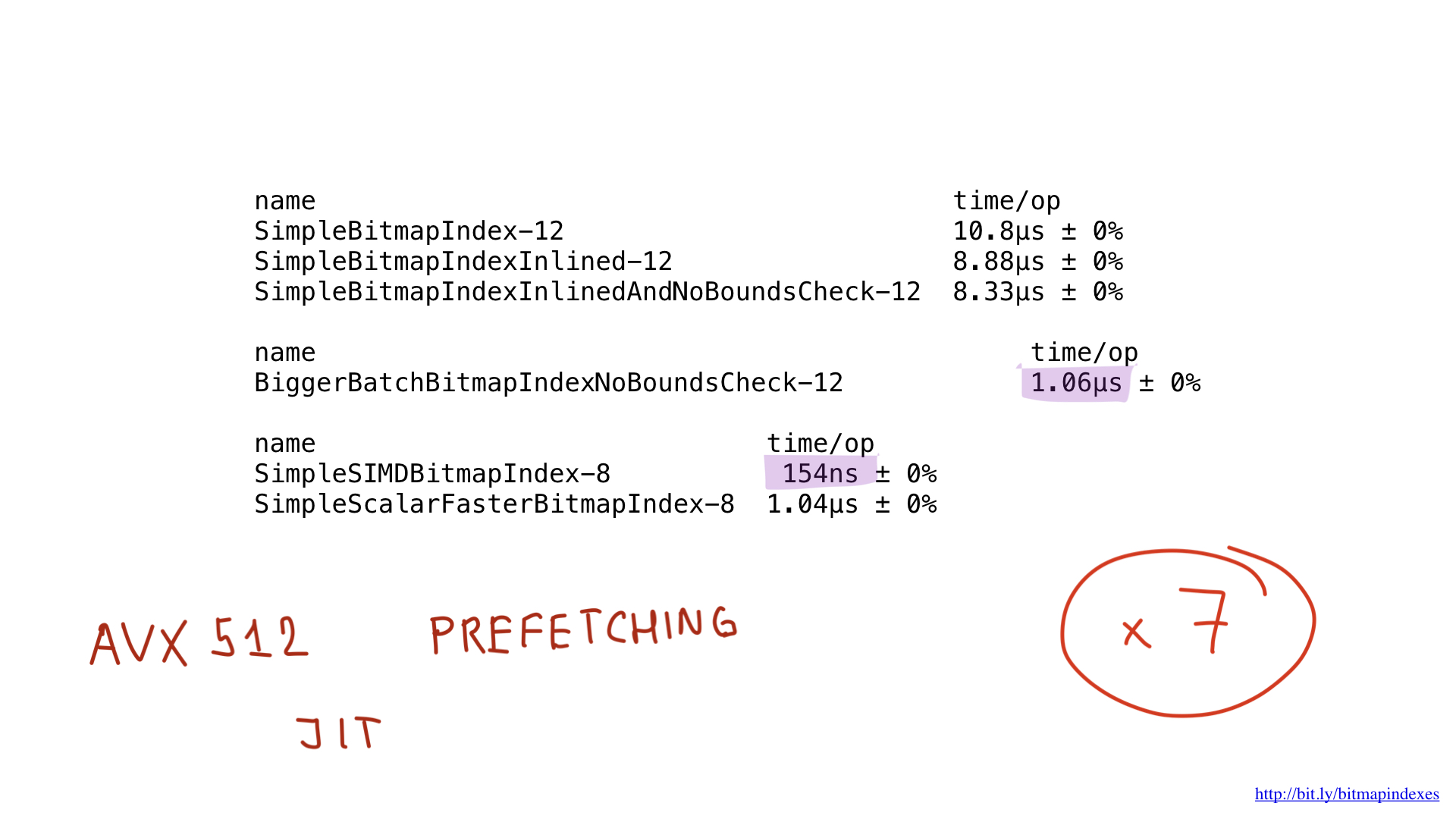
It should be possible to improve these results even more by using AVX512, prefetching and maybe even by using JIT (just in time) compilation instead of «manual» query plan builder, but that would be a subject for a totally different post.
Bitmap Index problems
Now that we«ve seen the basic implementation and the impressive speed of asm implementation, let’s talk about the fact that bitmap indexes are not very widely used. Why is that?

Older publications give us these three reasons. But recent ones and I argue that these have been «fixed» or dealt with by now. I won«t go into a lot of details on this here because we don’t have much time, but it«s certainly worth a quick look.
High-cardinality problem
So, we«ve been told that bitmap indexes are feasible only for low-cardinality fields. i.e. fields that have few distinct values, such as gender or eye color. The reason is that common representation (one bit per distinct value) can get pretty big for high-cardinality values. And, as a result, bitmap can become huge even if sparsely populated.
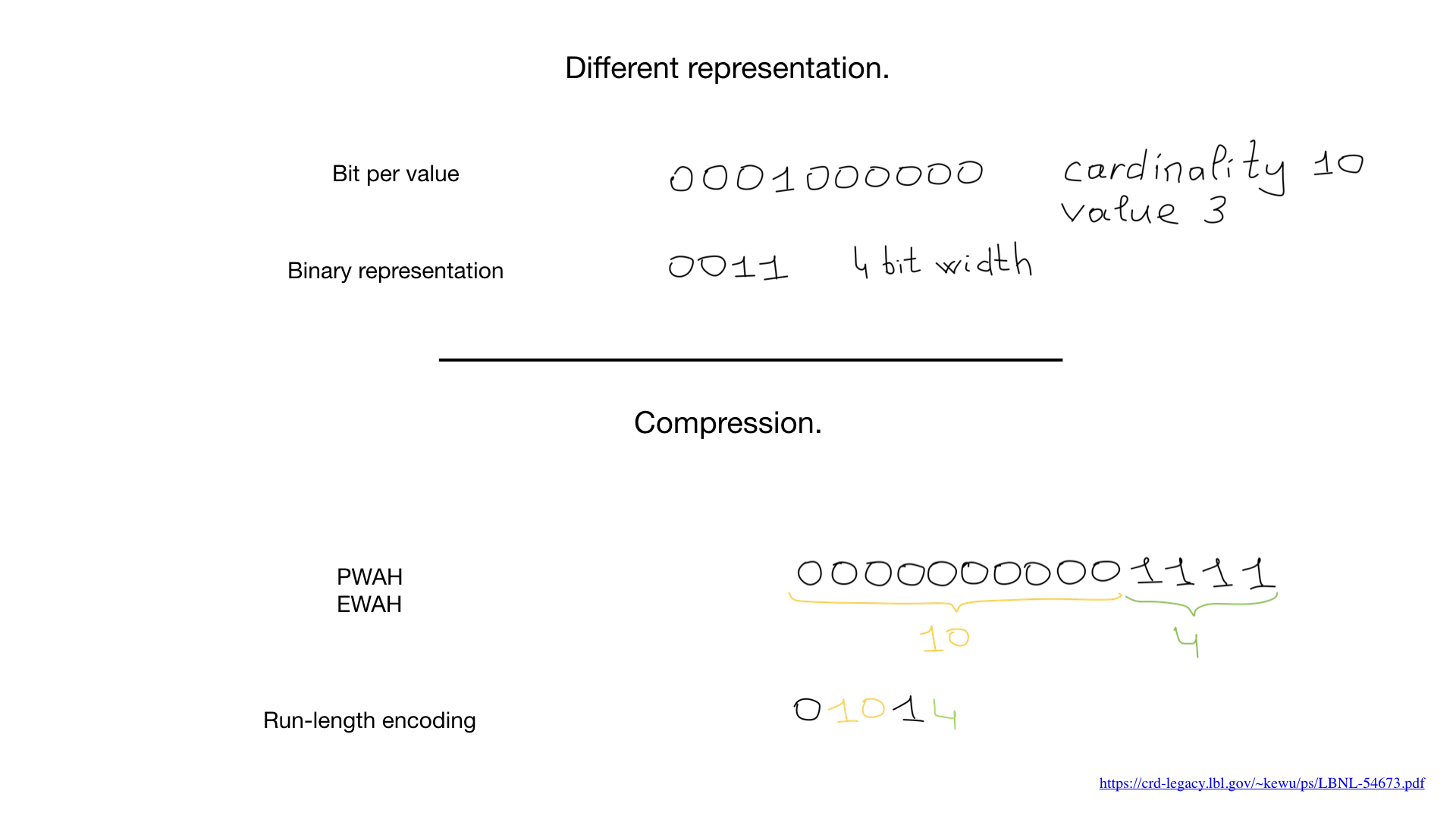
Sometimes a different representation can be used for these fields such as a binary number representation as shown here, but the biggest game changer is a compression. Scientists have come up with amazing compression algorithms. Almost all are based on widespread run-length algorithms, but what is more amazing is that we don’t need to decompress bitmaps in order to do bitwise operations on them. Normal bitwise operations work on compressed bitmaps.

Recently, we’ve seen hybrid approaches appear like «roaring bitmaps». Roaring bitmaps use three separate representations for bitmaps: bitmaps, arrays and «bit runs» and they balance usage of these three representations both to maximize speed and to minimise memory usage.
Roaring bitmaps can be found in some of the most widely-used applications out there and there are implementations for a lot of languages, including several implementations for Go.
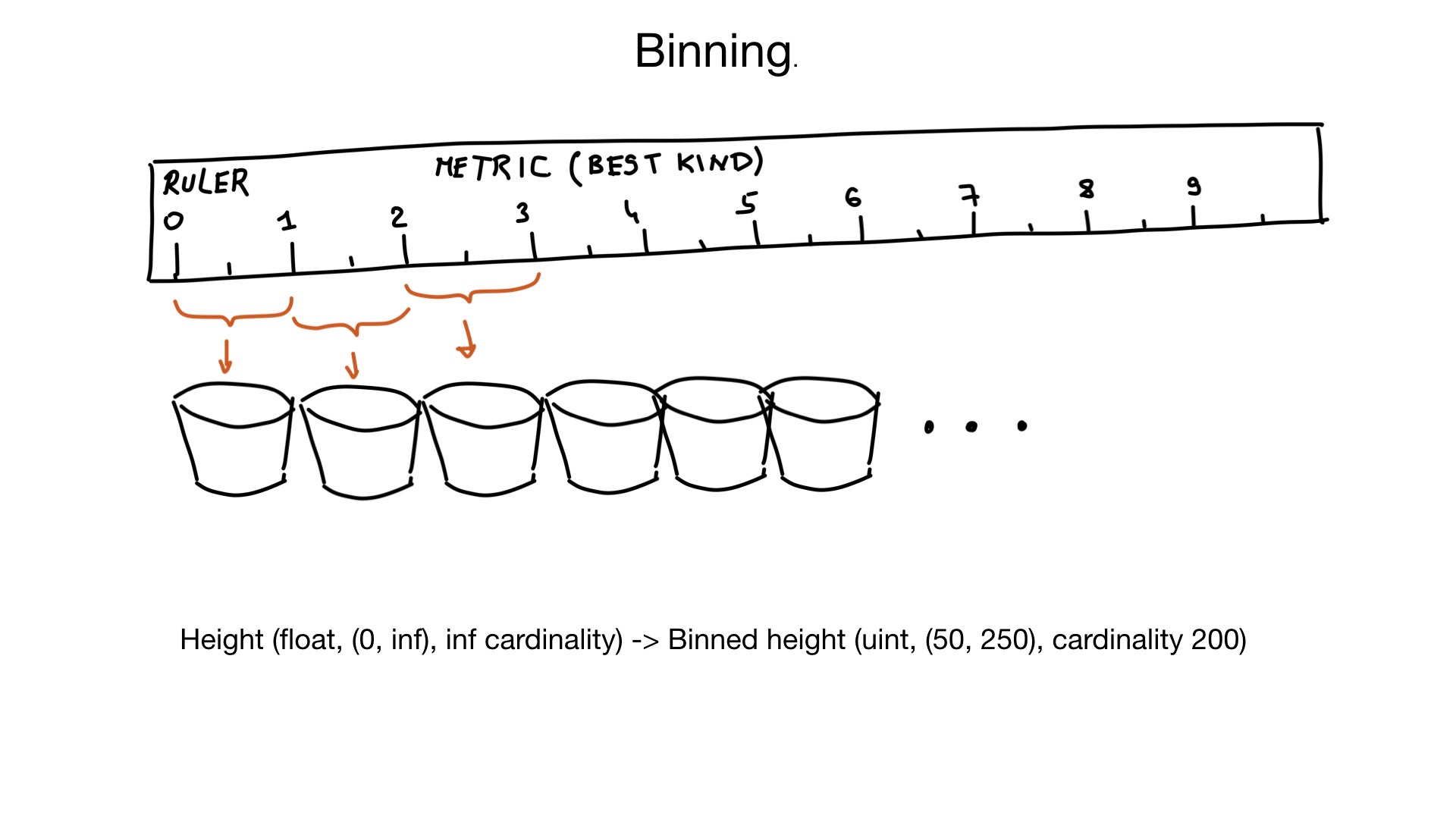
Another approach that can help with high cardinality fields is called binning. Imagine that we have a field representing a person’s height. Height is a float, but we don’t think of it that way. Nobody cares if your height is 185.2 or 185.3 cm. So we can use «virtual bins» to squeeze similar heights into the same bin: the 1 cm bin, in this case. And if you assume that there are very few people with a height of less than 50 cm, or more than 250 cm, we can convert our height into the field with approximately 200 element cardinality, instead of an almost infinite cardinality. If needed, we could do additional filtering on results later.
High-throughput problem
Another reason why bitmap indexes are bad is that it can be expensive to update bitmaps.
Databases do updates and searches in parallel, so you must be able to update the data while there might be hundreds of threads going through bitmaps doing a search. Locks would be needed locks in order to prevent data races or data consistency problems. And where there«s a one big lock, there is lock contention.
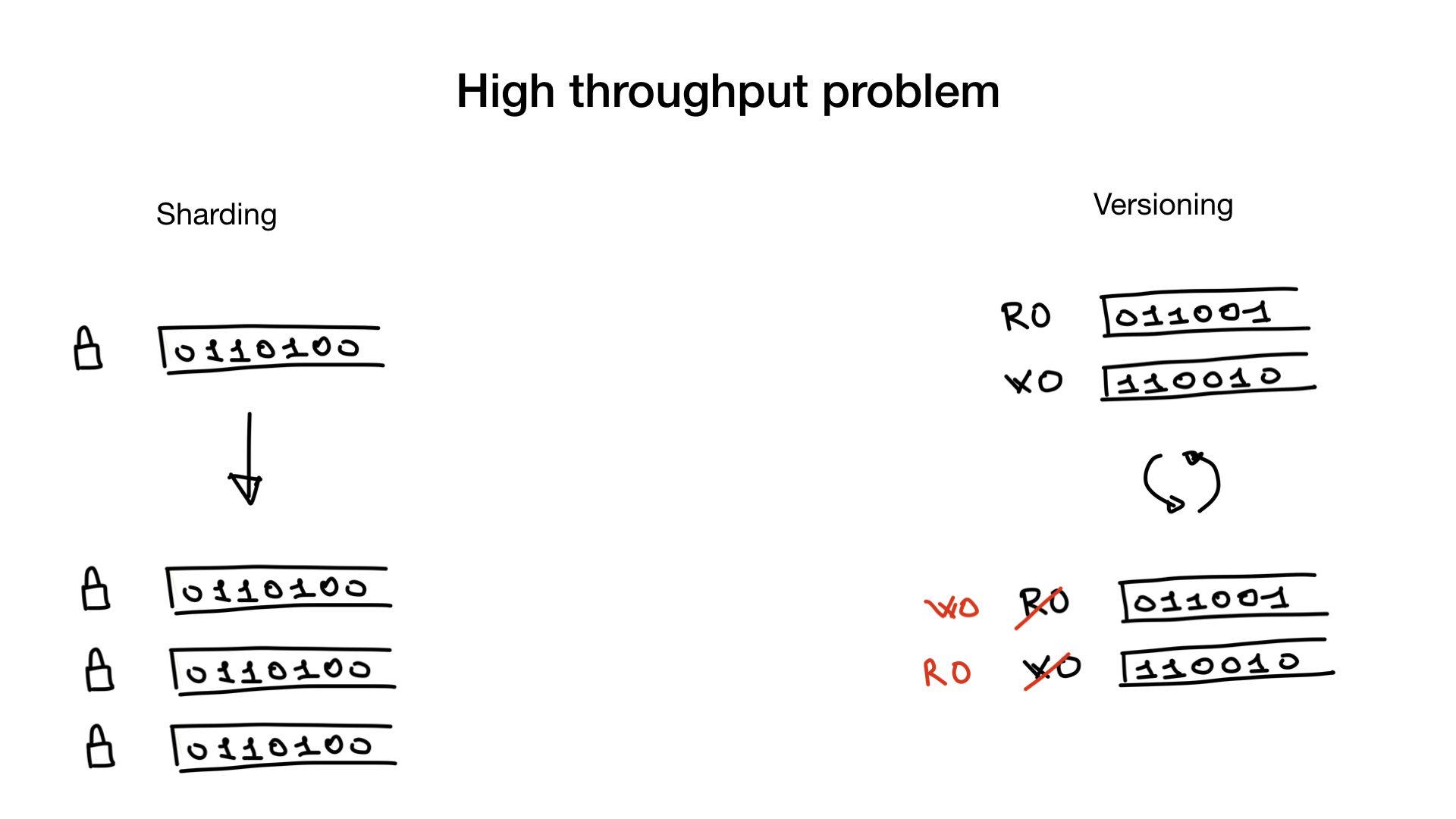
This problem, if you do have it, can be fixed by sharding your indexes or by having index versions, if appropriate.
Sharding is straightforward. You shard them as you would shard users in a database and now, instead of one lock, you have multiple locks which greatly reduces your lock contention.
Another approach that is sometimes feasible is having versioned indexes. You have the index that you use for search and you have an index that you use for writes, for updates. And you copy and switch them at a low frequency, e.g. 100 or 500 ms.
But this approach is only feasible if your app is able to tolerate stale search indexes that are a bit stale.
Of course, these two approaches can also be used together. You can have sharded versioned indexes.
Non-trivial queries
Another bitmap index problem has to do with using bitmap indices with range queries. And at first glance bitwise operations like AND and OR dont seems to be very useful for range queries like «give me hotel rooms that cost from 200 to 300 dollars a night».

A naive and very inefficient solution would be to get results for each price point from 200 to 300 and to OR the results.

A slightly better approach would be to use binning and to put our hotels into price ranges with range widths of, let’s say, 50 dollars. This approach would reduce our search expenses by approximately 50x.
But this problem can also be solved very easily by using a special encoding that makes range queries possible and fast. In the literature, such bitmaps are called range-encoded bitmaps.

In range-encoded bitmaps we don’t just set specific bit for, let’s say, value 200, but set all the bits at 200 and higher. The same for 300.
So, by using this range-encoded bitmap representation range query can be answered with only two passes through bitmap. We get all the hotels that cost less than, or equal to, 300 dollars and remove from the result all the hotels that cost less than, or equal to, 199 dollars. Done.

You would be amazed but even geo queries are possible using bitmaps. The trick is to use representation like Google S2 or similar that encloses a coordinate in a geometric figure that can be represented as three or more indexed lines. If you use such representation, you can then represent geo query as several range queries on these line indexes.
Ready solutions
Well, I hope that I«ve piqued your interest a bit. You now have one more tool under your belt and if you ever need to implement something like this in your service, you«ll know where to look.
That’s all well and good, but not everybody has the time, patience and resources to implement bitmap index themselves especially when it comes to more advanced stuff like SIMD instructions.
Fear not, there are two open source products that can help you in your endeavour.

Roaring
First, there is a library that I«ve already mentioned called «roaring bitmaps». This library implements roaring «container» and all bitwise operations that you would need if you were to implement a full bitmap index.
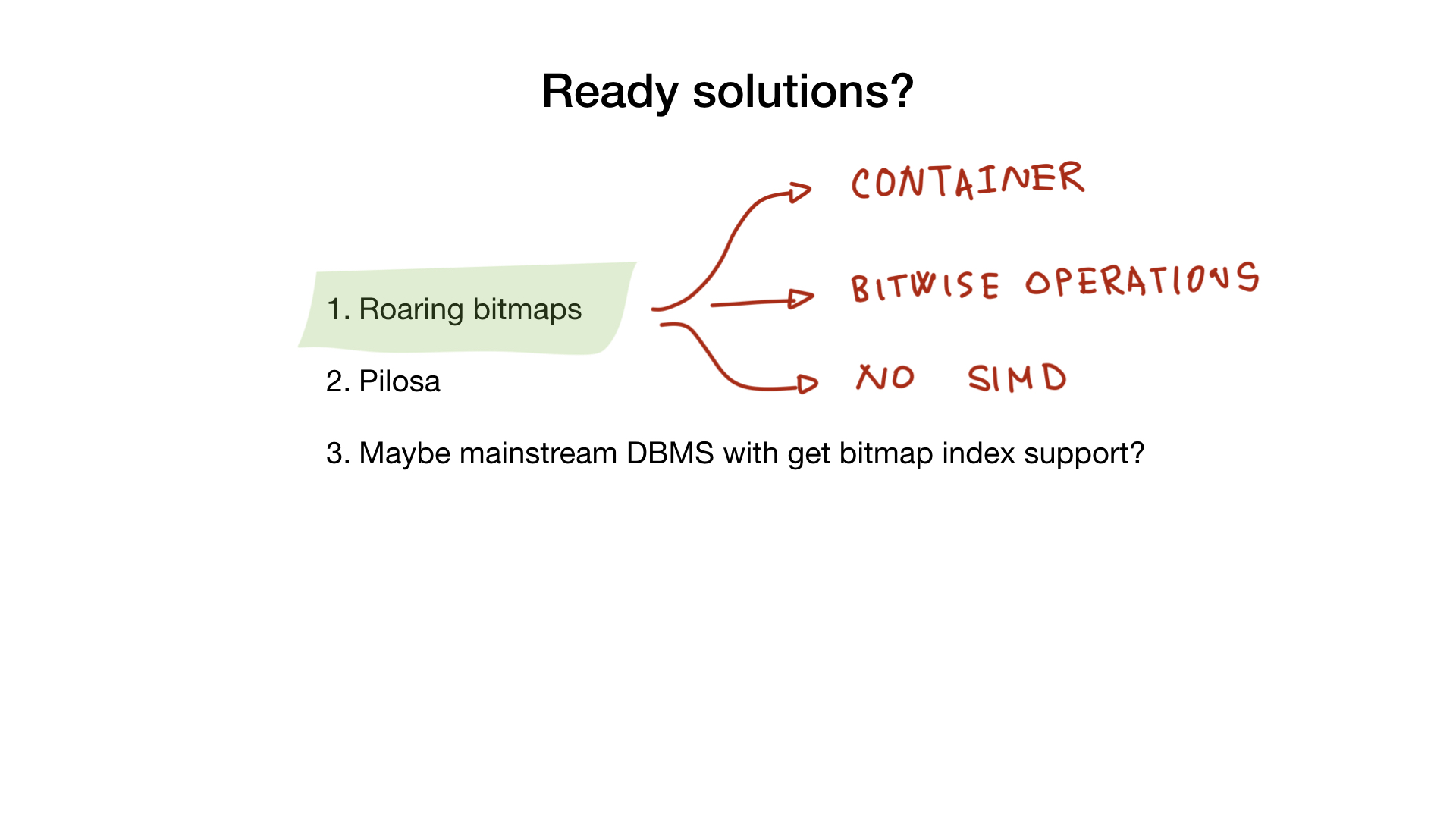
Unfortunately, go implementations don’t use SIMD, so they give a somewhat lesser performance than, say, C implementation.
Pilosa
Another product is a DBMS called Pilosa that only has bitmap indexes. It’s a recent project, but it«s gained a lot of traction lately.
 E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0»>
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0»>
Pilosa uses roaring bitmaps underneath and gives, simplifies or explains almost all the things I«ve been telling you about today: binning, range-encoded bitmaps, the notion of fields, etc.
Let’s briefly look at an example of Pilosa in use…

The example you see is very very similar to what we saw earlier. We create a client to the pilosa server, create an index and fields for our characteristics. We populate the fields with random data with some probabilities as we did earlier and then we execute our search query.
You see the same basic pattern here. NOT expensive intersected or AND-ed with terrace and intersected with reservations.
The result is as expected.

And lastly, I am hoping that sometime in the future, databases like mysql and postgresql will get a new index type: bitmap index.

Closing words

And if you are still awake, I thank you for that. Shortage of time has meant I had to skim over a lot of the stuff in this post, but I hope it’s been useful and maybe even inspiring.
Bitmap indexes are a useful thing to know about and understand even if you don’t need them right now. Keep them as yet another tool in your portfolio.
During my talk, we«ve seen various performance tricks we can use and things which Go struggles with at the moment. These are definitely things that every Go programmer out there needs to know.
And this is all I have for you for now. Thank you very much!
