[Перевод] Язык, созданный искусственным интеллектом, начинает портить научную литературу
Исследователи из России и Франции опубликовали любопытное исследование. Оно показывает, что использование современных текстовых генераторов, управляемых ИИ (например, GPT-3), приводит к уродованию языка, «воровству» изображений и цитированию несуществующей литературы в новых научных публикациях. Наибольшее беспокойство вызывает тот факт, что подобные публикации позиционируются как результат объективных и систематических исследований, но при этом содержат некорректный с научной точки зрения или просто непонятный контент.
Доклад, который называется «Сомнительный стиль письма, возникающий в науке», был подготовлен исследователем из Яндекса Александром Магазиновым и группой сотрудников отдела компьютерных наук Тулузского университета. Особое внимание авторы уделили росту бессмысленных научных публикаций, созданных искусственным интеллектом, в принадлежащем Elsevier журналу Microprocessors and Microsystems.
Максимальная синонимизация
Модели авторегрессионного языка наподобие GPT-3 обучаются на больших объёмах данных и предназначены для перефразирования, обобщения, сопоставления и интерпретации этих данных в связные генеративные языковые модели, которые способны воспроизводить естественную речь и шаблоны письма.
Эти модели всегда ищут синонимы — даже для устоявшихся словосочетаний. Неудивительно, что научные материалы, созданные с помощью такого ИИ, содержат невероятное количество примеров неудачного использования синонимов для привычных нам фраз.
Вот самые яркие примеры:
Глубокие нейронные сети: «глубокая нейронная организация»
Искусственная нейронная сеть: «фальшивая|поддельная нейронная организация»
Мобильная сеть: «универсальная организация»
Большие данные: «колоссальные|огромные|необъятные данные»
Ещё примеры:
deep neural network:»profound neural organization»
artificial neural network: »(fake | counterfeit) neural organization»
mobile network: »versatile organization»
network attack: »organization (ambush | assault)»
network connection: «organization association»
big data: »(enormous | huge | immense | colossal) information»
data warehouse: «information (stockroom | distribution center)»
artificial intelligence (AI): »(counterfeit | human-made) consciousness»
high performance computing: «elite figuring»
fog/mist/cloud computing: «haze figuring»
graphics processing unit (GPU): «designs preparing unit»
central processing unit (CPU): «focal preparing unit»
workflow engine: «work process motor»
face recognition: «facial acknowledgement»
voice recognition: «discourse acknowledgement»
mean square error: «mean square (mistake | blunder)»
mean absolute error: «mean (outright | supreme) (mistake | blunder)»
signal to noise: »(motion | flag | indicator | sign | signal) to (clamor | commotion | noise)»
global parameters: «worldwide parameters»
random access: »(arbitrary | irregular) get right of passage to»
random forest: »(arbitrary | irregular) (backwoods | timberland | lush territory)»
random value: »(arbitrary | irregular) esteem»
ant colony: «subterranean insect (state | province | area | region | settlement)»
ant colony: «underground creepy crawly (state | province | area | region | settlement)»
remaining energy: «leftover vitality»
kinetic energy: «motor vitality»
naive Bayes: »(credulous | innocent | gullible) Bayes»
personal digital assistant (PDA): «individual computerized collaborator»
В мае 2021 года исследователи использовали поисковую систему Dimensions для поиска подобных речевых искажений. Им удалось заметить, что журнал Microprocessors and Microsystems чаще других содержал примеры научных работ с неправильными фразами. Попробуйте сами выполнить такой поиск (снимок архива , 15.07.2021). Вы наверняка найдёте вот такие вот примеры:
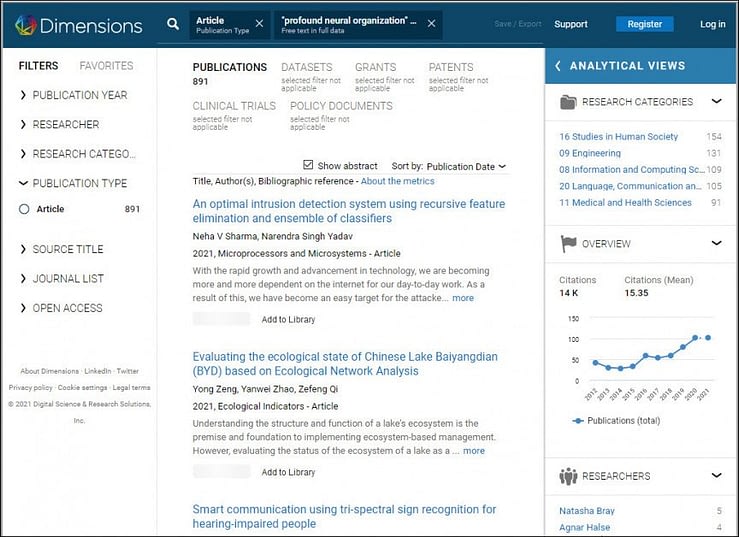 Выдача по запросу «deep neural network»
Выдача по запросу «deep neural network»
Исследователи изучили данные за период с февраля 2018 года по июнь 2021 года и отметили резкий рост количества заявок за последние два года, особенно за последние 6–8 месяцев:
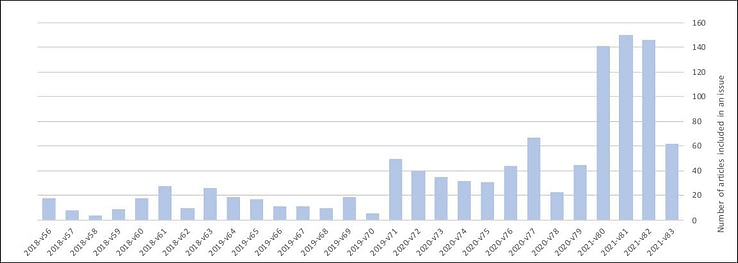 Корреляция или причинно-следственная связь? Увеличение количества публикаций в журнале Microprocessors and Microsystems, похоже, совпадает с ростом количества «бессмысленных» текстов серьёзных научных материалах.
Корреляция или причинно-следственная связь? Увеличение количества публикаций в журнале Microprocessors and Microsystems, похоже, совпадает с ростом количества «бессмысленных» текстов серьёзных научных материалах.
Полный набор данных, собранный авторами исследования, содержит 1078 статей, полученных по подписке Тулузского университета на журнал Elsevier. Частота «загрязненных» материалов в журнале Elsevier составляет (72,1%), что очень много, если провести сравнение с другими изученными научными журналами (максимум 13,6%).
Китайские научные статьи рецензируются поверхностно
В документе отмечается, что период времени, отведенный для редакционной оценки присланных материалов, в 2021 году радикально сокращается и составляет менее 40 дней. Это в шесть раз меньше стандартного времени для рецензирования.
Наибольшее количество странных статей поступает от авторов из Китая. Среди 404 статей, одобренных менее чем за 30 дней, 97,5% относятся к Китаю. А на долю материалов, которые редакция проверяла материалы дольше 40 дней (615 статей), приходится лишь 9,5% заявок из Китая. Разница почти в 10 раз! По мнению авторов доклада, распространение странных научных материалов объясняется недостатками редакционного процесса и возможной нехваткой ресурсов в связи с растущим числом заявок.
Исследователи выдвинули гипотезу о том, что генеративные модели наподобие GPT использовались для создания большей части текста в статьях. Однако доказать эту гипотезу сложно. Главный аргумент заключается в противоречащем здравому смыслу способу использования синонимов и нарушенности логики.
Есть и ещё одна закономерность: модели генеративного языка, которые вносят свой вклад в поток научной бессмыслицы, способны не только создавать проблемные тексты, но также распознавать их и систематически цитировать. То есть ссылаться на другие работы, как это делают люди. Исследователи смогли воссоздать такое решение с использованием GPT-2 и разработать структуру для выявления проблемных научных работ.
Не только семантика
Исследователи установили, что многие из изученных научных журналов не только используют неправильный язык, но и содержат некорректные с научной точки зрения утверждения. Это косвенно подтверждает подозрения, что генеративные языковые модели используются для формулировки некоторых основных теорем и данных в статье.
Исследователи также считают, что в некоторых случаях используется «ресинтез», то есть переделка случайно выбранной (и качественной) работы, опубликованной ранее. Это делается для того, чтобы справиться с давлением научного тренда «публикуй или погибни» и, возможно, с целью улучшить национальные рейтинги за глобальное превосходство в исследованиях ИИ, за счёт чистого объёма публикуемых материалов.

Выше вы можете видеть бессмысленное содержание якобы научной статьи. Исследователи обнаружили, что текст был заимствован из статьи EDN, откуда также была украдена сопровождающая иллюстрация без указания авторства. Переписывание исходного содержания было настолько радикальным, что получилась полная бессмыслица.
Анализируя несколько статей из Elsevier, исследователи обнаружили предложения, которые не имели смысла; ссылки на несуществующую литературу; ссылки на переменные и теоремы в формулах, которые на самом деле не появлялись во вспомогательном материале, а также повторное использование изображений без указания их источников. Это плохо и с точки зрения авторских прав, но по сути отражает недостаточный уровень редакторской проверки.
Ошибки цитирования
Цитаты, предназначенные для поддержки аргументов в научной статье, были обнаружены во многих помеченных примерах как «либо неработающие, либо приводящие к несвязанным публикациям». Кроме того, ссылки на «родственные работы», по-видимому, часто включают авторов, которых, по мнению исследователей, «тоже были созданы с помощью GPT.
Потеря сути
Ещё одним недостатком современных языковых моделей является их тенденция терять фокус во время долгой беседы. Исследователи обнаружили, что некоторые статьи часто поднимают в начале статьи тему, к которой не возвращаются позднее.
Они также предполагают, что некоторые из найденных странных статей получились в результате многократного прогона исходного текста через автоматические переводчики, что очень сильно исказило текст.
Исследователи призывают к более внимательному отношению к редакционной работе и совершенствованию стандартов в области академических публикаций на тему ИИ. Злая ирония в том, что отрасль, занимающаяся изучением ИИ, страдает от последствий злоупотреблении машинного обучения. По мнению авторов, распространение синтетических текстов всерьёз угрожает целостности научной литературы.
