[Перевод] Apache Kafka: обзор
Привет, Хабр!
Сегодня мы предлагаем вам сравнительно краткую, но при этом толковую и информативную статью об устройстве и вариантах применения Apache Kafka. Рассчитываем перевести и выпустить книгу Нии Нархид (Neha Narkhede) et. al до конца лета.

Приятного чтения!
Введение
Сегодня много говорят о Kafka. Многие ведущие айтишные компании уже активно и успешно пользуются этим инструментом. Но что же такое Kafka?
Kafka был разработан в компании LinkedIn в 2011 году и с тех пор значительно усовершенствовался. Сегодня Kafka — это целая платформа, обеспечивающая избыточность, достаточную для хранения абсурдно огромных объемов данных. Здесь предоставляется шина сообщений с колоссальной пропускной способностью, на которой можно в реальном времени обрабатывать абсолютно все проходящие через нее данные.
Все это классно, однако, если свести Kafka к сухому остатку, то получится распределенный горизонтально масштабируемый отказоустойчивый журнал коммитов.
Мудрено звучит. Давайте рассмотрим каждый из этих терминов и разберемся, что он означает. А затем подробно исследуем, как все это работает.
Распределенный
Распределенной называется такая система, которая в сегментированном виде работает сразу на множестве машин, образующих цельный кластер; поэтому для конечного пользователя они выглядят как единый узел. Распределенность Kafka заключается в том, что хранение, получение и рассылка сообщений у него организовано на разных узлах (так называемых «брокерах»).
Важнейшие плюсы такого подхода — высокодоступность и отказоустойчивость.
Горизонтально масштабируемый
Давайте сначала определимся с тем, что такое вертикальная масштабируемость. Допустим, у нас есть традиционный сервер базы данных, и он постепенно перестает справляться с нарастающей нагрузкой. Чтобы справиться с этой проблемой, можно просто нарастить ресурсы (CPU, RAM, SSD) на сервере. Это и есть вертикальное масштабирование — на машину навешиваются дополнительные ресурсы. При таком «масштабировании вверх» возникает два серьезных недостатка:
- Есть определенные пределы, связанные с возможностями оборудования. Бесконечно наращиваться нельзя.
- Такая работа обычно связана с простоями, а большие компании не могут позволить себе простоев.
Горизонтальная масштабируемость решает ровно ту же проблему, просто мы подключаем к делу все больше машин. При добавлении новой машины никаких простоев не происходит, при этом, количество машин, которые можно добавить в кластер, ничем не ограничено. Загвоздка в том, что не во всех системах поддерживается горизонтальная масштабируемость, многие системы не рассчитаны на работу с кластерами, а те, что рассчитаны — обычно очень сложны в эксплуатации.

После определенного порога горизонтальное масштабирование становится гораздо дешевле вертикального
Отказоустойчивость
Для нераспределенных систем характерно наличие так называемой единой точки отказа. Если единственный сервер вашей базы данных по какой-то причине откажет — вы попали.
Распределенные системы проектируются таким образом, чтобы их конфигурацию можно было корректировать, подстраиваясь под отказы. Кластер Kafka из пяти узлов остается работоспособным, даже если два узла лягут. Необходимо отметить, что для обеспечения отказоустойчивости обязательно приходится частично жертвовать производительностью, поскольку чем лучше ваша система переносит отказы, тем ниже ее производительность.
Журнал коммитов
Журнал коммитов (также именуемый «журнал опережающей записи», «журнал транзакций») — это долговременная упорядоченная структура данных, причем, данные в такую структуру можно только добавлять. Записи из этого журнала нельзя ни изменять, ни удалять. Информация считывается слева направо; таким образом гарантируется правильный порядок элементов.
Схема журнала коммитов
— Вы имеете в виду, что структура данных в Kafka настолько проста?
Во многих отношениях — да. Эта структура образует самую сердцевину Kafka и абсолютно бесценна, поскольку обеспечивает упорядоченность, а упорядоченность — детерминированную обработку. Обе эти проблемы в распределенных системах решаются с трудом.
В сущности, Kafka хранит все свои сообщения на диске (подробнее об этом ниже), а при упорядочивании сообщений в виде вышеописанной структуры можно пользоваться последовательным считыванием с диска.
- Операции считывания и записи выполняются за постоянное время O (1) (если известен ID записи), что, по сравнению с операциями O (log N) на диске в другой структуре, невероятно экономит время, так как каждая операция подвода головок затратна.
- Операции считывания и записи не влияют друг на друга (операция считывания не блокирует операцию записи и наоборот, чего не скажешь об операциях со сбалансированными деревьями).
Два этих момента радикально увеличивают производительность, поскольку она совершенно не зависит от размера данных. Kafka работает одинаково хорошо, будь у вас на сервере 100KB или 100TB данных.
Как все это работает?
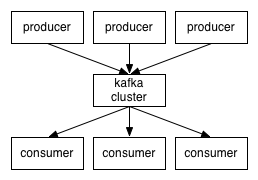
Приложения (генераторы) посылают сообщения (записи) на узел Kafka (брокер), и указанные сообщения обрабатываются другими приложениями, так называемыми потребителями. Указанные сообщения сохраняются в теме, a потребители подписываются на тему для получения новых сообщений.
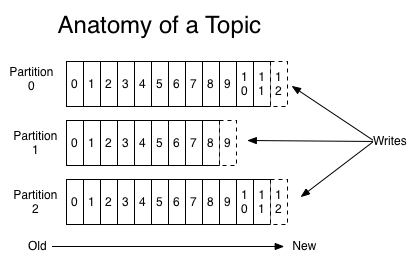
Темы могут разрастаться, поэтому крупные темы подразделяются на более мелкие секции для улучшения производительности и масштабируемости. (пример: допустим, вы сохраняли пользовательские запросы на вход в систему; в таком случае можно распределить их по первому символу в имени пользователя)
Kafka гарантирует, что все сообщения в пределах секции будут упорядочены именно в той последовательности, в которой поступили. Конкретное сообщение можно найти по его смещению, которое можно считать обычным индексом в массиве, порядковым номером, который увеличивается на единицу для каждого нового сообщения в данной секции.
В Kafka соблюдается принцип «тупой брокер — умный потребитель». Таким образом, Kafka не отслеживает, какие записи считываются потребителем и после этого удаляются, а просто хранит их в течение заданного периода времени (например, суток), либо до тех пор, пока не будет достигнут некоторый порог. Потребители сами опрашивают Kafka, не появилось ли у него новых сообщений, и указывают, какие записи им нужно прочесть. Таким образом, они могут увеличивать или уменьшать смещение, переходя к нужной записи; при этом события могут переигрываться или повторно обрабатываться.
Следует отметить, что на самом деле речь идет не об одиночных потребителях, а о группах, в каждой из которых — один или более процессов-потребителей. Чтобы не допустить ситуации, когда два процесса могли бы дважды прочесть одно и то же сообщение, каждая секция привязывается лишь к одному процессу-потребителю в пределах группы.
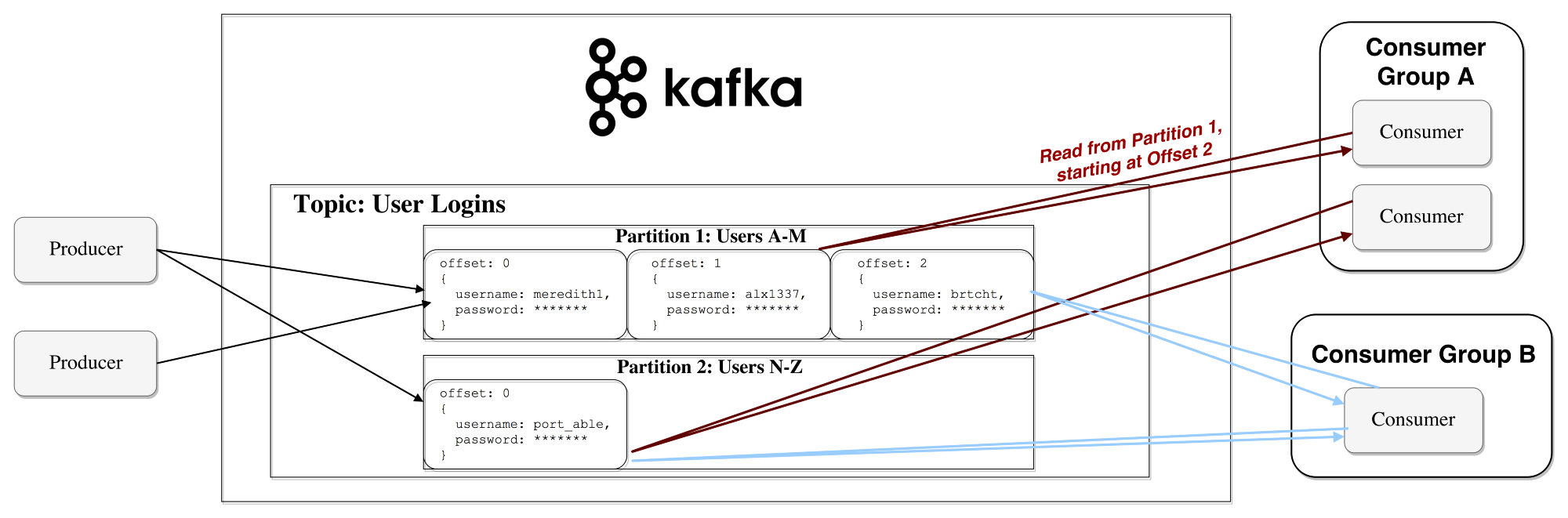
Так устроен поток данных
Долговременное хранение на диске
Как упоминалось выше, Kafka на самом деле хранит свои записи на диске и ничего не держит в оперативной памяти. Да, возможен вопрос, есть ли в этом хоть капля смысла. Но в Kafka действует множество оптимизаций, благодаря которым такое становится осуществимым:
- В Kafka есть протокол, объединяющий сообщения в группы. Поэтому при сетевых запросах сообщения складываются в группы, что позволяет снизить сетевые издержки, а сервер, в свою очередь, сохраняет партию сообщений за один присест, после чего потребители могут сразу выбирать большие линейные последовательности таких сообщений.
- Линейные операции считывания и записи на диск происходят быстро. Известна проблема: современные диски работают сравнительно медленно из-за необходимости подвода головок, однако, при крупных линейных операциях такая проблема исчезает.
- Указанные линейные операции сильно оптимизируются операционной системой путем опережающего чтения (заблаговременно выбираются крупные группы блоков) и запаздывающей записи (небольшие логические операции записи объединяются в крупные физические операции записи).
- Современные ОС кэшируют диск в свободной оперативной памяти. Такая техника называется страничный кэш.
- Поскольку Kafka сохраняет сообщения в стандартизированном двоичном формате, который не изменяется на протяжении всей цепочки (генератор→брокер→потребитель), здесь уместна оптимизация нулевого копирования. В таком случае ОС копирует данные из страничного кэша прямо на сокет, практически обходя стороной приложение-брокер, относящееся к Kafka.
Благодаря всем этим оптимизациям Kafka доставляет сообщения практически так же быстро, как и сама сеть.
Распределение и репликация данных
Теперь давайте обсудим, как в Kafka достигается отказоустойчивость, и как он распределяет данные между узлами.
Репликация данных
Данные с сегмента реплицируются на множестве брокеров, чтобы данные сохранились, если один из брокеров откажет.
В любом случае, один из брокеров всегда «владеет» секцией: этот брокер — именно тот, на котором приложения выполняют операции считывания и записи в секцию. Этот брокер называется »ведущим секции». Он реплицирует получаемые данные на N других брокеров, так называемых ведомыми. На ведомых также хранятся данные, и любой из них может быть выбран в качестве ведущего, если актуальный ведущий откажет.
Так можно сконфигурировать гарантии, обеспечивающие, что любое сообщение, которое будет успешно опубликовано, не потеряется. Когда есть возможность изменить коэффициент репликации, можно частично пожертвовать производительностью ради повышенной защиты и долговечности данных (в зависимости от того, насколько они критичны).

Таким образом, если один из ведущих когда-нибудь откажет, его место может занять ведомый.
Однако, логично спросить:
— Как генератор/потребитель узнает, какой брокер — ведущий данной секции?
Чтобы генератор/потребитель мог записывать/считывать информацию в данной секции, приложению нужно знать, какой из брокеров здесь ведущий, верно? Эту информацию нужно где-то взять.
Для хранения таких метаданных в Kafka используется сервис под названием Zookeeper.
Что такое Zookeeper?
Zookeeper — это распределенное хранилище ключей и значений. Оно сильно оптимизировано для считывания, но записи в нем происходят медленнее. Чаще всего Zookeeper применяется для хранения метаданных и обработки механизмов кластеризации (пульс, распределенные операции обновления/конфигурации, т.д.).
Таким образом, клиенты этого сервиса (брокеры Kafka) могут на него подписываться — и будут получать информацию о любых изменениях, которые могут произойти. Именно так брокеры узнают, когда ведущий в секции меняется. Zookeeper исключительно отказоустойчив (как и должно быть), поскольку Kafka сильно от него зависит.
Он используется для хранения всевозможных метаданных, в частности:
- Смещение групп потребителей в рамках секции (хотя, современные клиенты хранят смещения в отдельной теме Kafka)
- ACL (списки контроля доступа) — используются для ограничения доступа /авторизации
- Квоты генераторов и потребителей — максимальные предельные количества сообщений в секунду
- Ведущие секций и уровень их работоспособности
Как генератор/потребитель определяет ведущего брокера данной секции?
Ранее Генератор и Потребители непосредственно подключались к Zookeeper и узнавали у него эту (а также другую) информацию. Теперь Kafka уходит от такой связки и, начиная, соответственно, с версий 0.8 и 0.9 клиенты, во-первых, выбирают метаданные непосредственно у брокеров Kafka, а брокеры обращаются к Zookeeper.
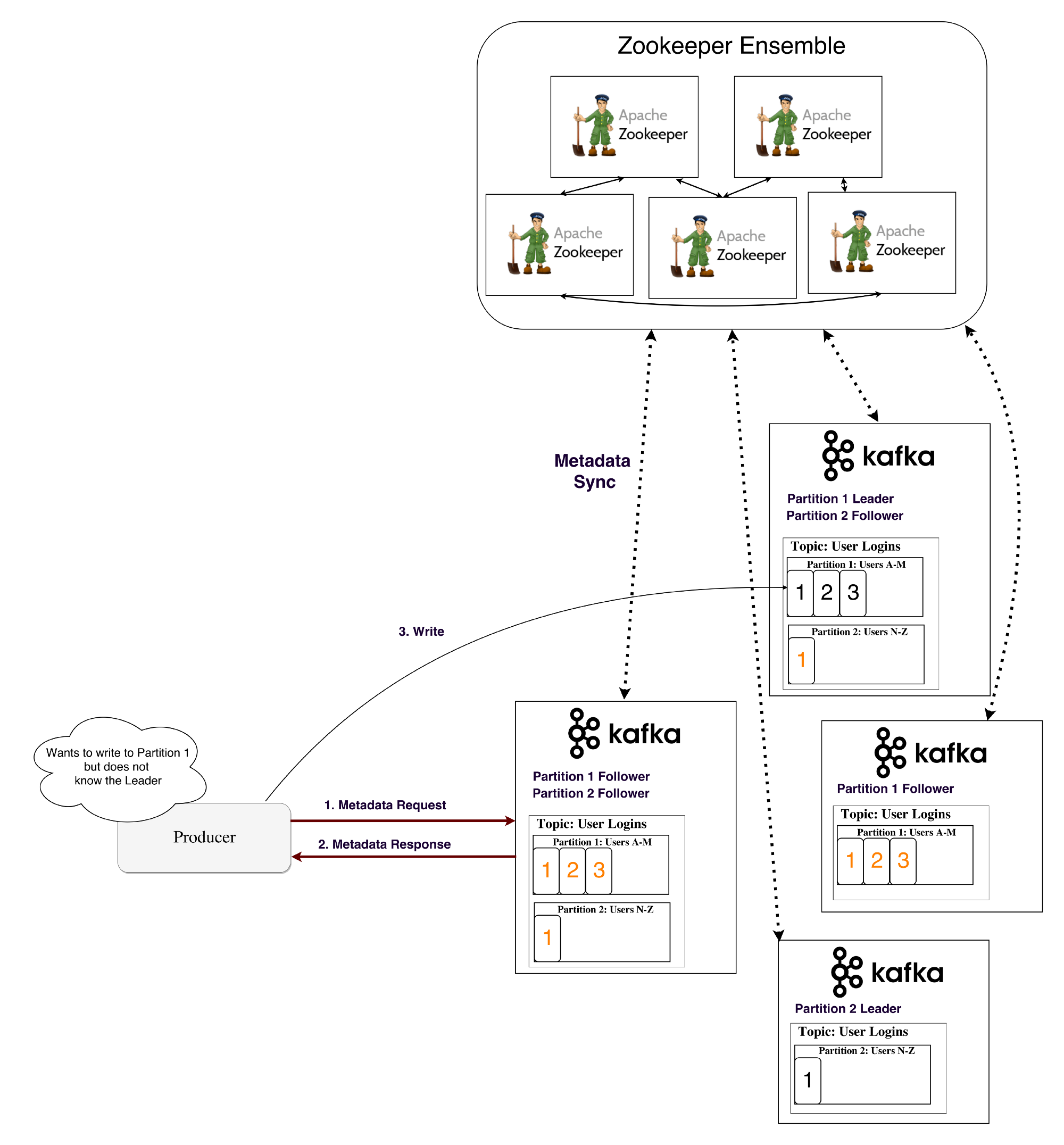
Поток метаданных
Потоки
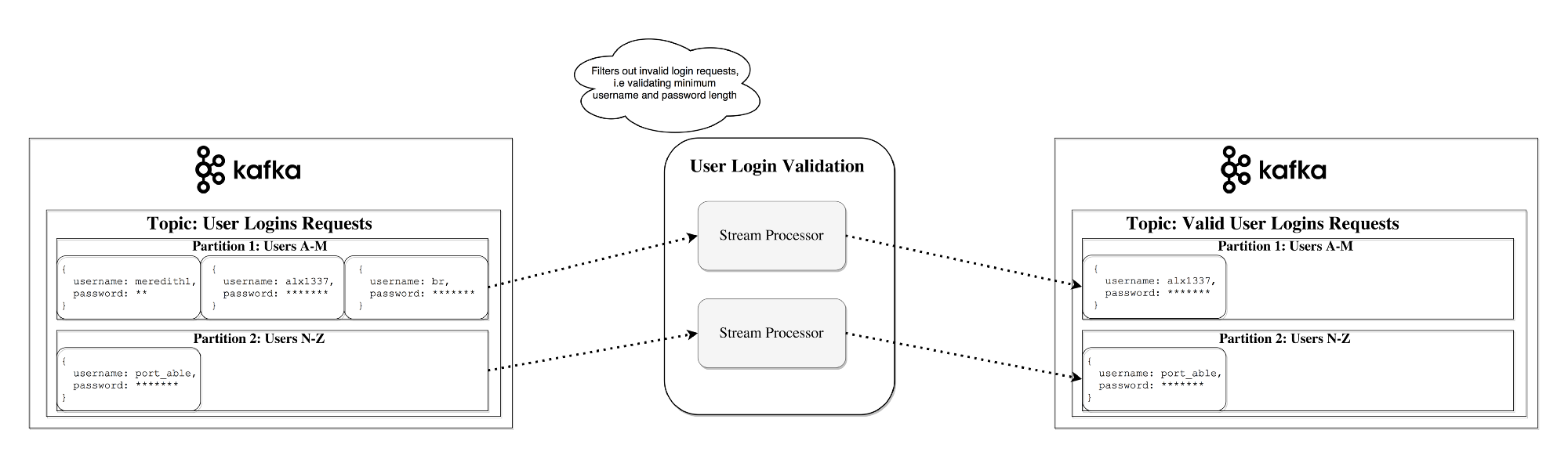
Потоковый процессор в Kafka отвечает за всю следующую работу: принимает непрерывные потоки данных от входных тем, каким-то образом обрабатывает этот ввод и подает поток данных на выходные темы (либо на внешние сервисы, базы данных, в корзину, да куда угодно…)
Простую обработку можно выполнять непосредственно на API генераторов/потребителей, однако, более сложные преобразования — например, объединение потоков, в Kafka выполняется при помощи интегрированной библиотеки Streams API.
Этот API предназначен для использования в рамках вашей собственной базы кода, на брокере он не работает. Функционально он подобен API потребителя, облегчает горизонтальное масштабирование обработки потоков и распределение его между несколькими приложениями (подобными группам потребителей).
Обработка без сохранения состояния
Обработка без сохранения состояния — это поток детерминированной обработки, не зависящий ни от каких внешних факторов. В качестве примера рассмотрим вот такое простое преобразование данных: прикрепляем информацию к строке
"Hello" -> "Hello, World!"
Потоково-табличный дуализм
Важно понимать, что потоки и таблицы — это, в сущности, одно и то же. Поток можно интерпретировать как таблицу, а таблицу — как поток.
Поток как таблица
Если обратить внимание, как выполняется синхронная репликация базы данных, то очевидно, что речь идет о потоковой репликации, где любые изменения в таблицах отправляются на сервер копий (реплику). Поток Kafka можно интерпретировать точно так же — как поток обновлений для данных, которые агрегируются и дают конечный результат, фигурирующий в таблице. Такие потоки сохраняются в локальной RocksDB (по умолчанию) и называются KTable.
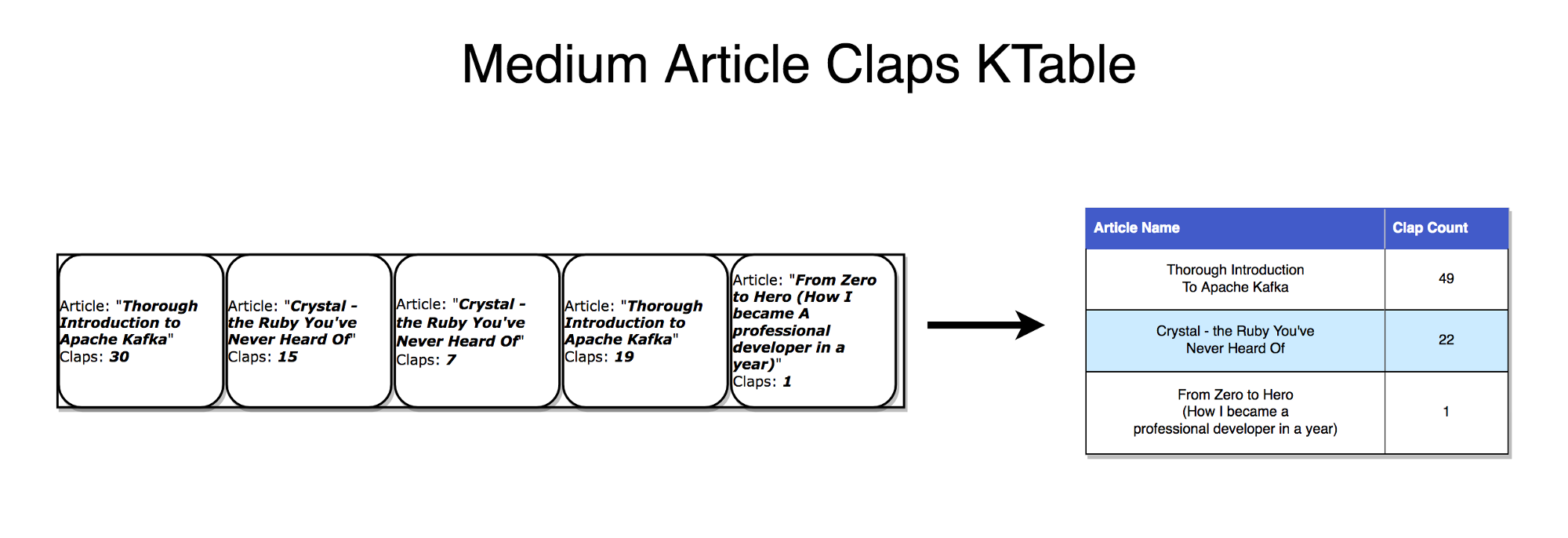
Таблица как поток
Таблицу можно считать мгновенным снимком, отражающим последнее значение для каждого ключа в потоке. Аналогично, из потоковых записей можно составить таблицу, а из обновлений таблицы — сформировать поток с логом изменений.
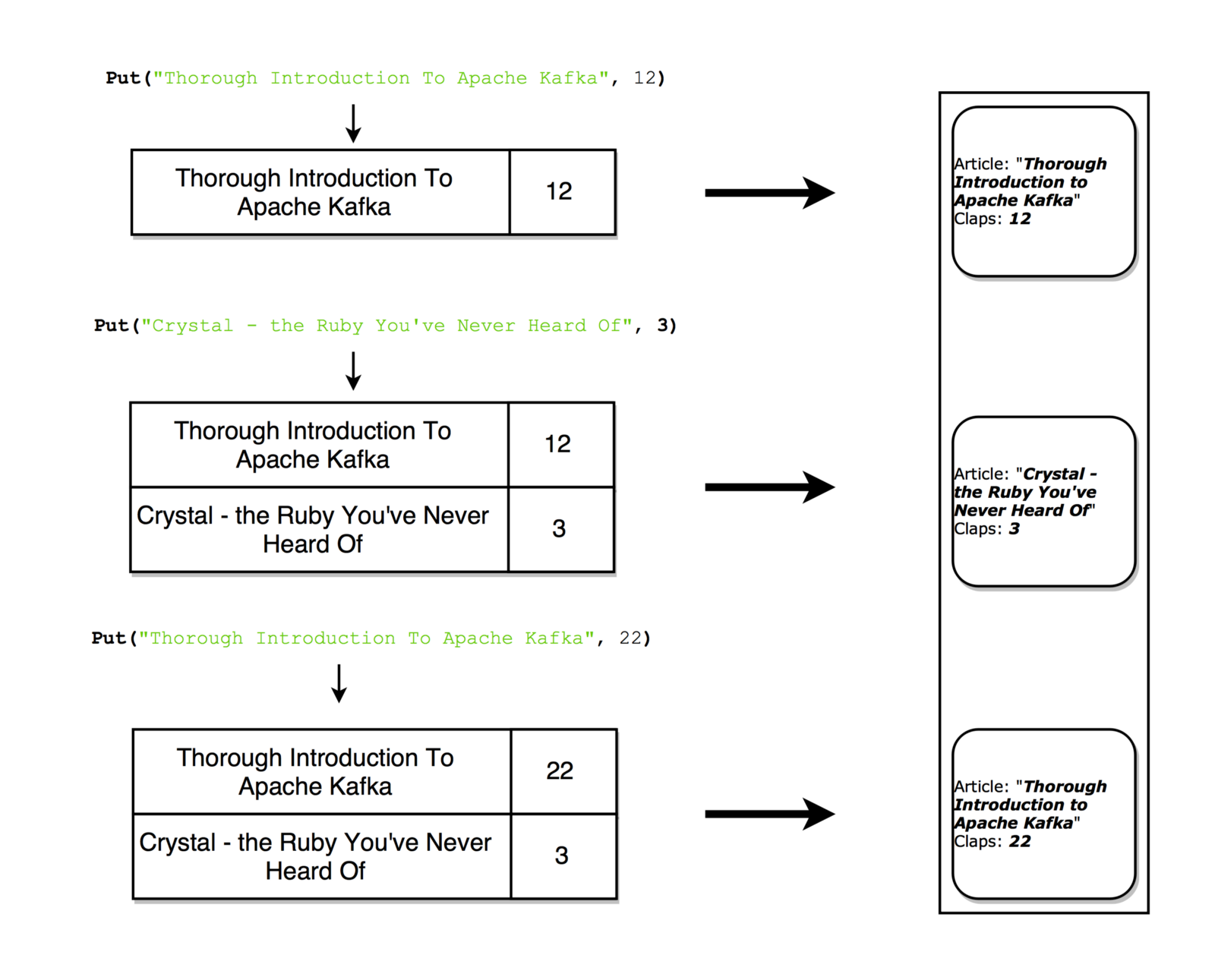
При каждом обновлении можно сделать мгновенный снимок потока (запись)
Обработка с сохранением состояния
Некоторые простые операции, например, map() или filter(), выполняются без сохранения состояния, и нам не приходится хранить каких-либо данных, касающихся их обработки. Однако, на практике большинство операций выполняется с сохранением состояния (напр. count()), поэтому вам, естественно, придется хранить состояние, сложившееся на настоящий момент.
Проблема с поддержанием состояния в потоковых процессорах заключается в том, что эти процессоры иногда отказывают! Где же хранить это состояние, чтобы обеспечить отказоустойчивость?
Упрощенный подход — просто хранить все состояние в удаленной базе данных и подключаться к этому хранилищу по сети. Проблема в том, что тогда теряется локальность данных, а сами данные многократно перегоняются по сети — оба фактора существенно тормозят ваше приложение. Более тонкая, но важная проблема заключается в том, что активность вашего задания потоковой обработки будет жестко зависеть от удаленной базы данных — то есть, это задание будет несамодостаточным (вся ваша обработка может рухнуть, если другая команда внесет в базу данных какие-то изменения).
Итак, какой же подход лучше?
Вновь вспомним о дуализме таблиц и потоков. Именно благодаря этому свойству потоки можно преобразовывать в таблицы, расположенные именно там, где происходит обработка. Также при этом получаем механизм, обеспечивающий отказоустойчивость — мы храним потоки на брокере Kafka.
Потоковый процессор может сохранять свое состояние в локальной таблице (например, в RocksDB), которую будет обновлять входной поток (возможно, после каких-либо произвольных преобразований). Если этот процесс сорвется, то мы сможем восстановить соответствующие данные, повторно воспроизведя поток.
Можно добиться даже того, чтобы удаленная база данных генерировала поток и, фактически, широковещательно передавала лог изменений, на основании которого вы будете перестраивать таблицу на локальной машине.

Обработка с сохранением состояния, соединение KStream с KTable
KSQL
Как правило, код для обработки потоков приходится писать на одном из языков для JVM, поскольку именно с ней работает единственный официальный клиент Kafka Streams API.

Образец установки KSQL
KSQL — это новая фича, позволяющая писать простые потоковые задания на знакомом языке, напоминающем SQL.
Настраиваем сервер KSQL и интерактивно запрашиваем его через CLI для управления обработкой. Он работает точно с теми же абстракциями (KStream и KTable), гарантирует те же преимущества, что и Streams API (масштабируемость, отказоустойчивость) и значительно упрощает работу с потоками.
Возможно, все это звучит не вдохновляюще, но на практике очень полезно для тестирования материала. Более того, такая модель позволяет приобщиться к потоковой обработке даже тем, кто не участвует в разработке как таковой (например, владельцам продукта). Рекомендую посмотреть небольшое вводное видео — сами убедитесь, насколько здесь все просто.
Альтернативны потоковой обработке
Потоки Kafka — идеальное сочетание силы и простоты. Пожалуй, Kafka — лучший инструмент для выполнения потоковых заданий, имеющихся на рынке, а интегрироваться с Kafka гораздо проще, чем с альтернативными инструментами для потоковой обработки (Storm, Samza, Spark, Wallaroo).
Проблема с большинством других инструментов потоковой обработки заключается в том, что их сложно развертывать (и с ними тяжело обращаться). Фреймворк для пакетной обработки, например, Spark, требует:
- Управлять большим количеством заданий на пуле машин и эффективно распределять их в кластере.
- Для этого требуется динамически упаковывать код и физически развертывать его на тех узлах, где он будет выполняться (плюс конфигурация, библиотеки, т.д.)
К сожалению, при попытках решать все эти проблемы в рамках одного фреймворка этот фреймворк получается слишком инвазивным. Фреймворк пытается контролировать всевозможные аспекты развертывания, конфигурирования кода, наблюдения за ним и упаковки кода.
Kafka Streams позволяет вам сформулировать собственную стратегию развертывания, когда вам это потребуется, причем, работать с инструментом на ваш вкус: Kubernetes, Mesos, Nomad, Docker Swarm и пр.
Kafka Streams предназначен прежде всего для того, чтобы вы могли организовать в своем приложении потоковую обработку, однако, без эксплуатационных сложностей, связанных с поддержкой очередного кластера. Единственный потенциальный недостаток такого инструмента — его тесная связь с Kafka, однако, в нынешней реальности, когда потоковая обработка в основном выполняется именно при помощи Kafka, этот небольшой недостаток не так страшен.
Когда стоит использовать Kafka?
Как уже говорилось выше, Kafka позволяет пропускать через централизованную среду огромное количество сообщений, а затем хранить их, не беспокоясь о производительности и не опасаясь, что данные будут потеряны.
Таким образом, Kafka отлично устроится в самом центре вашей системы и будет работать как связующее звено, обеспечивающее взаимодействие всех ваших приложений. Kafka может быть центральным элементом событийно-ориентированной архитектуры, что позволит вам как следует отцепить приложения друг от друга.
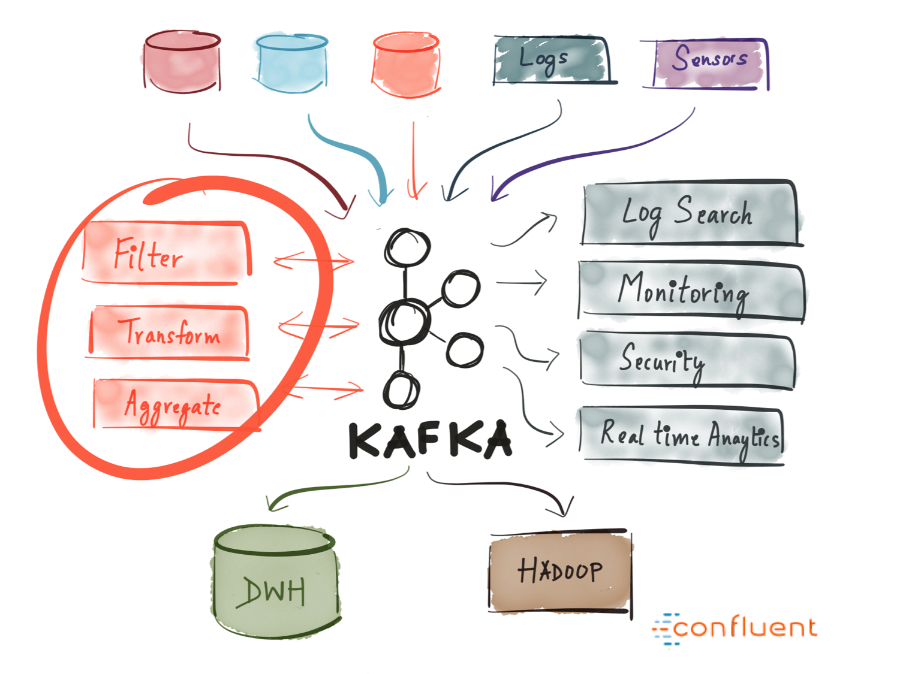
Kafka позволяет с легкостью разграничить коммуникацию между различными (микро)сервисами. Работая Streams API, стало как никогда просто писать бизнес-логику, обогащающую данные из темы Kafka перед тем, как их станут потреблять сервисы. Здесь открываются широчайшие возможности — поэтому настоятельно рекомендую изучить, как Kafka применяется в разных компаниях.
Итоги
Apache Kafka — это распределенная потоковая платформа, позволяющая обрабатывать триллионы событий в день. Kafka гарантирует минимальные задержки, высокую пропускную способность, предоставляет отказоустойчивые конвейеры, работающие по принципу «публикация/подписка» и позволяет обрабатывать потоки событий.
В этой статье мы познакомились с базовой семантикой Kafka (узнали, что такое генератор, брокер, потребитель, тема), узнали о некоторых вариантах оптимизации (страничный кэш), узнали, какую отказоустойчивость гарантирует Kafka при репликации данных и вкратце обсудили его мощные потоковые возможности.
