[Перевод] Анатомия тысячи шрифтов

Перевод статьи The anatomy of a thousand typefaces.
Даже годы спустя после выхода фильма Avatar остаётся кое-что, с чем не может справиться даже Райан Гослинг — использование шрифта Papyrus в логотипе фильма. В пародии, снятой Saturday Night Live, дизайнер шрифтов открывает меню, перебирает шрифты и случайным образом выбирает Papyrus.
Главная проблема выбора шрифтов — одновременно слишком много и слишком мало вариантов.
С одной стороны, выбор только из системных шрифтов может привести к плохому решению, потому что среди стандартных шрифтов ничего интересного просто не представлено.
С другой стороны, библиотеки веб-шрифтов с сотнями и тысячами наименований поражают изобилием, что иногда приводит к парадоксальным выборам шрифтов.
Горький привкус меню выбора шрифтов
В среднестатистическом меню шрифты отсортированы по имени, но при этом никак не взаимосвязаны друг с другом: за шрифтом, созданным для жирных заголовков, идёт шрифт, разработанный для маленьких экранных интерфейсов, а за ним следует вычурный рукописный шрифт для свадебных приглашений. И приходится терять время на листание всего списка от начала до конца, либо просто выбирать первый подходящий шрифт из начала списка и закругляться.
Очевидно, что такое интерфейсное решение создано не для систематической работы, а для бесконечных сюрпризов. И хотя многие любят сюрпризы, но все же хочется повлиять на успех поиска хорошего шрифта.

Меню выбора шрифтов из видеоролика «Papyrus». Ограниченный выбор, всевозможные стили, но далеко не лучшие шрифты из всех возможных.
Систематический подход к поиску шрифтов
Есть разные способы ограничить избыточность выбора. Прежде чем заниматься анализом шрифтовых файлов, глифов и таблиц метаданных, давайте сначала поговорим о классификации, отобранных списках и анатомии.
1. Классификация
Существует сложная система классификации шрифтов. Простейшее деление на категории: шрифты с засечками (serif), гротески (sans-serif), моноширинные (monospaced), рукописные (script) и шрифты для дисплеев (display). Обычно эти категории используются в качестве фильтров на разных шрифтовых сайтах:

Но даже эти простые фильтры всё ещё ставят нас перед слишком богатым выбором шрифтов. Здесь уже возникают более дробные градации, например, шрифты с засечками делятся на переходные, гуманистические и готические.
Иногда эти подкатегории доступны в виде тегов. Но иногда авторы шрифтовых сайтов вообще их игнорируют. Возможно, категорий слишком много? Быть может, пользователи просто не разбираются во всех этих подробностях? Или просто у авторов нет полной и последовательной информации для подробной классификации шрифтов?
2. Отобранные списки
Альтернативный способ наведения порядка заключается в том, чтобы положиться на знания других людей: можно использовать списки шрифтов, кем-то отобранных. Такие списки есть, к примеру, на Fontshop. Вы можете найти здесь коллекции, отсортированные по десятилетиям, по степени схожести или по сфере применения.
Подобные списки есть также на Typekit, TypeWolf и FontsInUse. Это замечательная идея, и можно порекомендовать всем начать составлять собственные списки шрифтов, с которыми вы уже работали или видели. В будущем эти наработки вам очень пригодятся.
3. Анатомия
Самое трудное в поиске хорошего шрифта — ориентироваться на особенности дизайна и понимать, какие свойства делают шрифт хорошим или особенным. К счастью, есть достаточно книг по шрифтовому дизайну, шрифтам и типографике. Эти книги могут научить нас, как создавать шрифты, как их выбирать и использовать.
Например, книга «The Anatomy of Type» Стивена Коулза. В ней собрана информация о 100 хорошо проработанных гарнитурах. Для описания качества шрифтов Стивен использует такие термины, как высота строчных литер (х-height, х-высота), ширина, вес, ball terminal, форма засечек и многие другие.

«The Anatomy of Type» — графическое руководство Стивена Коулза по 100 гарнитурам. Замечательная книга для изучения истории и особенностей дизайна популярных гарнитур.
Но здесь описаны лишь 100 шрифтов, а как быть с остальными? Что насчёт установленных на ваших компьютерах? А используемых в сети? Какие у них х-высоты, ширины, веса и контрасты? Как это можно узнать?
Внутри шрифтового файла: нехватка метаданных
Прежде чем я начал кодить, я считал, что можно быстро получить нужную информацию о свойствах шрифтов. Теоретически, каждый шрифтовой файл должен содержать разные таблицы метаданных с названием, именем автора, поддерживаемыми языками и визуальными свойствами. Самые очевидные — ширина, вес и класс шрифта. Там же можно найти информацию об х-высоте, высоте заглавных букв, средней ширине символа, верхних и нижних выносных элементах букв. Другой набор метаданных под названием Panose описывает ещё больше свойств: форму засечек, пропорции, контраст и прочее. Для просмотра всей этой информации можно использовать приложения для шрифтового дизайна, например, Glyphs:

Скриншот панели с информацией о шрифте. Здесь указано название семейства, имя дизайнера, ссылка, версия, дата. Также можно посмотреть диапазон Unicode и Panose-данные. 10-значный код описывает многие характеристики, но информация не всегда доступна, так как ее вносит дизайнер или создатель файла. На правом скриншоте вы можете увидеть такие метрики, как верхние и нижние выносные элементы, х-высоту и угол наклона.
Но доступность этой информации зависит от того, насколько ответственно подошел к своей работе создатель шрифта. В каких-то шрифтовых файлах есть много данных, но часто информации не хватает, особенно в бесплатных или open source-шрифтах. И даже если в файле есть информация, она может быть некорректной или неполной.

Сравнение Panose-данных для шрифтов Roboto и Fira Sans, оба доступны на Google Fonts. Для Fira Sans указано много информации, а для Roboto — мало. Эти метаданные не получится использовать для сравнения шрифтов.
DIY: Анализируем шрифты с помощью opentype.js
Давайте проанализируем шрифтовые файлы и придумаем, как автоматически извлекать нужную информацию. Файлы имеют разные форматы, но почти всегда можно найти версии в TTF (TrueType Font).
В файлах формата OTF (OpenType) можно найти информацию о дополнительных свойствах, например, лигатурах. В файлах WOFF (Web Open Font Format) есть дополнительные метаданные, а шрифты хранятся в сжатом виде.
Благодаря opentype.js можно анализировать шрифтовые файлы прямо в браузере с помощью JavaScript. Opentype.js предоставляет доступ к векторной информации всех наборных знаков, входящих в файл, а также к основным метрикам и таблицам метаданных.
База данных характеристик шрифтов
Ниже мы рассмотрим, как можно измерить контраст, х-высоту, ширину и вес всех шрифтов из библиотеки Google Fonts. Те же методы можно применить и к другим шрифтовым библиотекам, например, Typekit или шрифтам на вашем компьютере.
Контраст
Контраст описывает соотношение тонких и толстых штрихов символа. Есть шрифты с низким контрастом, например, брусковые, или многие гротески, созданные для интерфейсов, например, Roboto или San Francisco. А есть шрифты с высоким контрастом, например, Bodoni или Didot. Для измерения контраста мы можем посмотреть на контуры буквы «о» и сравнить самое большое и самое маленькое расстояние между внутренним и внешним контуром.

Контраст шрифта можно измерить в самой толстой и самой тонкой части буквы «о».
Это простая и легко поддающаяся сравнению буква почти всегда состоит из двух частей. Она хороший кандидат на оценку контраста шрифта (примечание: форма у «о» простая лишь на первый взгляд, на самом деле её довольно трудно хорошо нарисовать, потому что штрихи должны плавно менять свою толщину).

С помощью opentype.js удобно получить данные для отрисовки символов в виде SVG-элементов. Например, можно отдельно нарисовать внешний и внутренний контуры. Затем с помощью одного алгоритма можно пройти по каждому контуру, измеряя расстояние между ними. После этого вычисляем соотношение между самым длинным и самым коротким расстоянием, и вуаля — получили значение контраста, по которому можно сравнивать шрифты.
х-высота
х-высота — важная характеристика, которая может быть индикатором удобочитаемости и субъективно воспринимаемого размера шрифта. Обычно этот параметр измеряется как высота строчной буквы «х».

х-высоту можно измерить с помощью информации, предоставленной opentype.js.
opentype.js для каждого символа предоставляет параметр yMax.
Помимо абсолютного измерения х-высоты может понадобиться сравнить х-высоту и с высотой выступающих надстрочных элементов. То есть получить значения вроде «х-высота составляет 60% прописных букв».
Чтобы полученные значения можно было использовать для сравнения (в одних шрифтах используется 1000 юнитов на Em (типографская единица измерения), в других 2048), необходимо нормализовать их и сопоставить с диапазоном от 0 до 1.
Ширина / Пропорция
С помощью этого значения можно оценить плотность шрифта. Насколько он плотный, сжатый, или напротив, растянутый, свободный? Можно было бы, к примеру, измерять ширину буквы «М» в разных шрифтах, но тогда пришлось бы учитывать и общий размер или х-высоту. К тому же в некоторых шрифтах «М» весьма специфична и не характерна для всего остального набора символов.
Ещё можно вычислять среднюю ширину символа на основе эталонного слова вроде «Hamburgefontsiv». Это неплохой вариант, но всё равно понадобится делать нормализацию с учётом общего дизайна и высоты шрифта.
Другой подход заключается в определении пропорции буквы «о». Это даёт нам на удивление хорошие значения, по которым можно сравнивать ширины разных гарнитур.

Вес
Для измерения веса можно вывести на HTML-странице строчную «о», залить её чёрным, а фон — белым. Затем вычислить отношение чёрных и белых пикселей. У рукописного или очень тонкого шрифта это значение будет совсем маленьким, а у тяжёлого, громоздкого шрифта отношение будет большим. Результаты вполне удовлетворительные, но их можно ещё больше улучшить, измеряя полную ширину символов.

Расстояние
Если у всех символов шрифта одинаковая ширина, такой шрифт называют моноширинным (monospaced). Важно отметить, что для определения ширины нам не обязательно смотреть на сами символы. Даже в моноширинном шрифте символ точки визуально занимает меньше места, чем «м». Поэтому нужно учитывать свойство advanceWidth, описывающее невидимые поля вокруг символа. Удивительно, но Google Fonts использует термин monospaced в качестве определения стиля, а не технического свойства. Шрифты вроде Lekton или Libre Barcode вообще не отнесены к моноширинным, хотя технически они ими являются.
Схожесть
Получив таблицу значений, можем нормализовать их и вычислить расстояния, чтобы оценить схожесть шрифтов. Здесь приведена самая простая версия расчёта, но результат будет лучше, если повысить точность данных. Кроме того, человек может оценивать схожесть шрифтов не так, как алгоритм, для которого все характеристики одинаковы. В этом случае мы должны учитывать некоторые свойства в большей степени, чем другие.
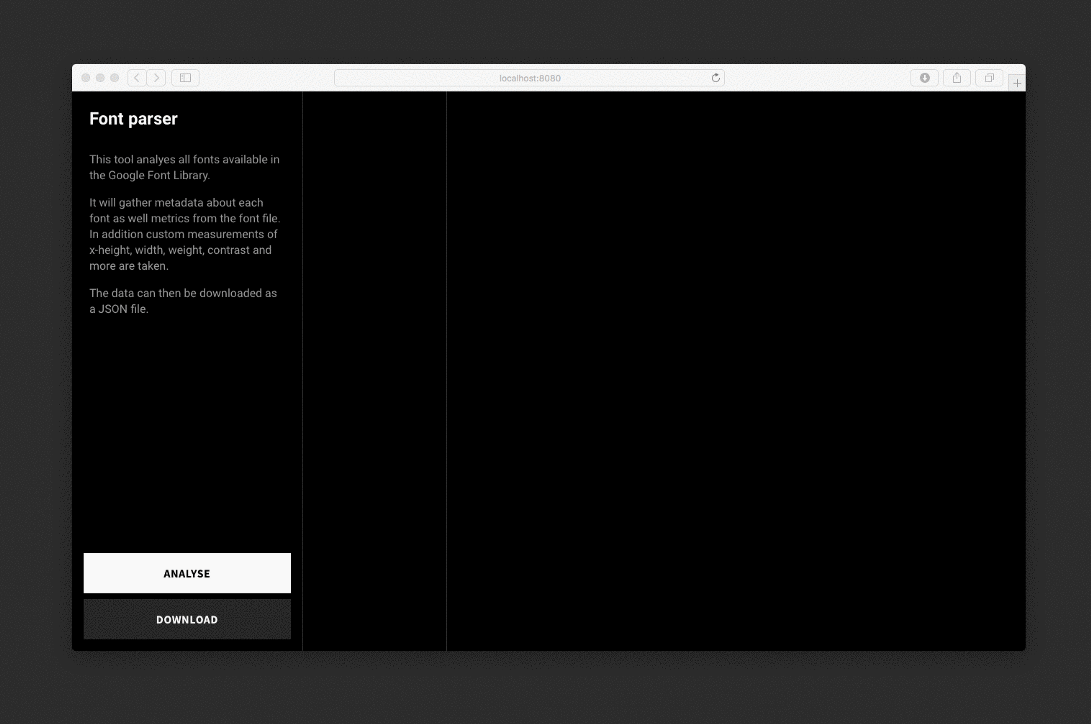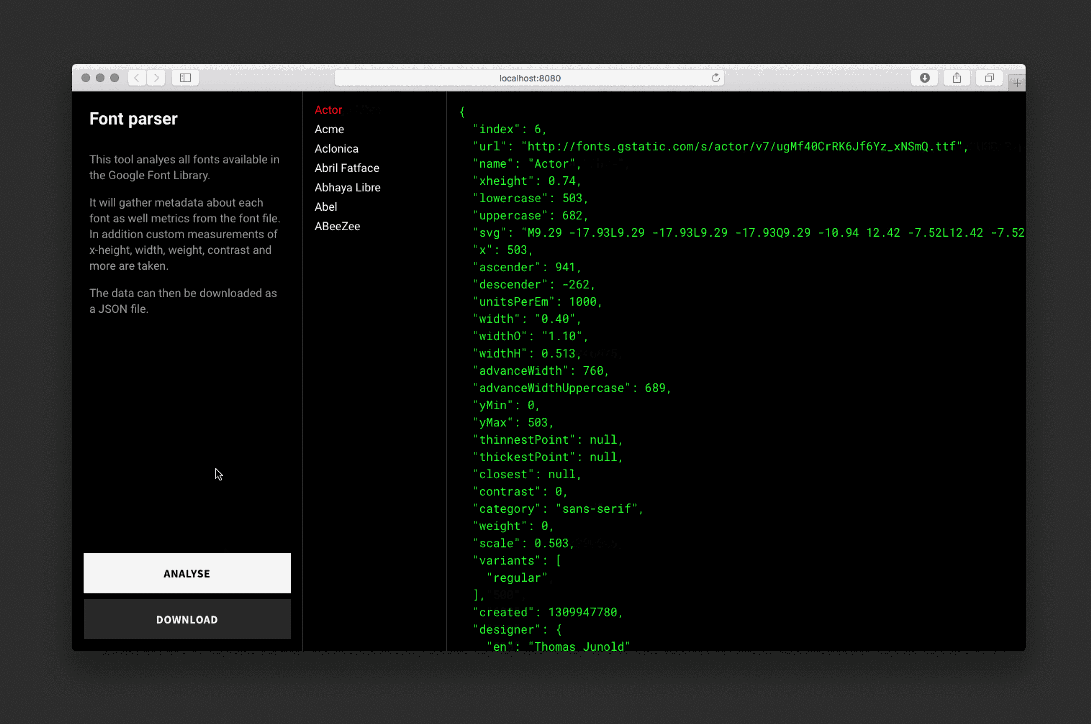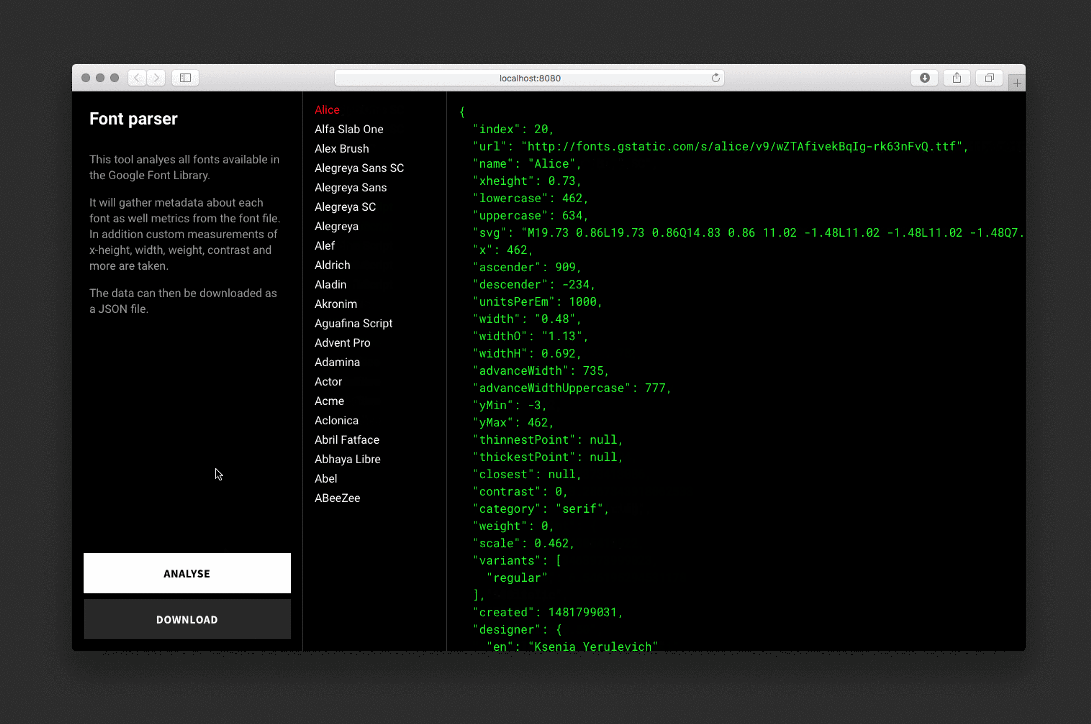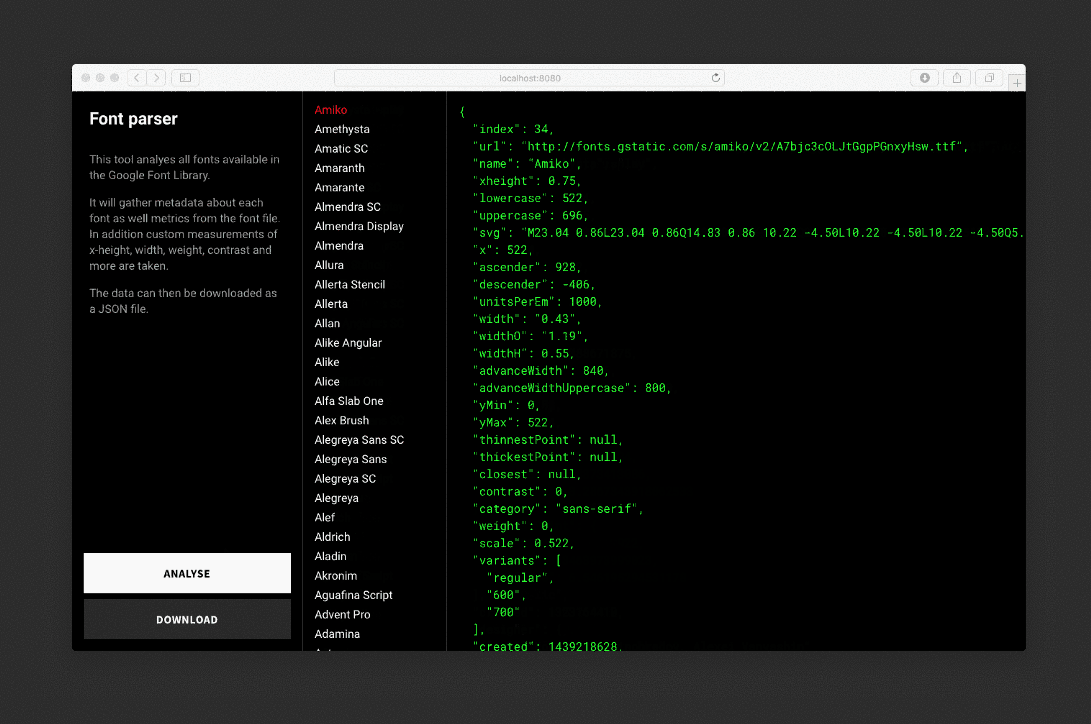
Парсер анализирует каждый шрифт, рисует невидимые SVG и фоновые элементы, проводит измерения и сохраняет данные в JSON-файл.
Демо
Для доступа к базе данных написан интерфейс. Шрифты можно просматривать в виде сетки с ячейкой разного размера, чтобы охватить взглядом сразу много шрифтов или подробнее оценить некоторые из них.
Шрифты можно сортировать по весу, х-высоте, контрасту, ширине, названию и количеству стилей. Диаграммы показывают распределение значений и могут использоваться для отфильтровывания определённых значений. Для каждого шрифта есть подробное отображение с несколькими примерами, символами, метриками, Panose-данными и перечислением схожих шрифтов.

Датасет
Почему-то некоторые шрифты не загружаются в Safari, так что рекомендую использовать Chrome.
Открытия
Вы можете сами исследовать датасет в поисках схожестей и несоответствий. Если задать низкий контраст и наличие засечек, то программа выдаст все брусковые шрифты. Если задать низкую х-высоту, то выдача будет состоять по большей части из рукописных шрифтов. Очень высокие значения обычно характерны для шрифтов, состоящих исключительно из прописных букв.
Изгои
При выборе крайних значений обычно «вылезают» очень странные шрифты. Как правило, они относятся к категории экранных шрифтов.
Неприятные различия
Просмотр в виде сетки выявляет ужасные различия между базовыми линиями и выравниваниями. Некоторые шрифты категорически не вписываются в сетку. И даже если различия невелики, становится очевидно, что простая замена шрифтов в проекте вряд ли возможна, если не считать нескольких популярных шрифтов с очень похожим строением.
Золотая середина
Любопытно, что часто используемые шрифты, считающиеся хорошими, программа помещает в список схожих друг с другом. Если подстроить фильтры, то можно уменьшить список примерно вдвое, но все популярные шрифты останутся. Так что если вам нужно отфильтровать странные и экстремальные шрифты, просто выбирайте средние значения.
«Форкнутые» шрифты
Есть шрифты, которые называются по-разному, но выглядят совершенно одинаково. Некоторые из них являются форками с расширенным набором символов для поддержки разных языков, например, Alegreya & Sahitya.
Количество стилей
Количество стилей шрифта — хороший индикатор его качества. На горизонте уже маячат переменные шрифты, и вполне возможно, что будущее за бесконечной кастомизацией. Но до тех пор рекомендуется работать со шрифтами, относящимися к нескольким стилям. Так что сортировка коллекции по количеству стилей — хороший способ узнать о лучших имеющихся шрифтах.
Итоги
Это довольно сложный подход к поиску шрифтов. В целом результаты поиска зависят от качества шрифтов и сопутствующих данных. Если вы пользуетесь только Google Fonts, то сильно ограничиваете себя, поскольку там представлены не лучшие в своём классе шрифты. При анализе содержимого Typekit выяснилось, что у интерфейса возникают проблемы с производительностью при работе с таким количеством шрифтов. Нужно использовать кэширование и предварительную загрузку, но до этого пока не дошли руки.
Вы можете получить хорошее представление о содержимом шрифтовых файлов и недостающих данных безо всяких нейросетей. Чем больше этим занимаешься, тем явственней осознаёшь масштабы шрифтовой истории и стоящей на её плечах индустрии.
Возможности
Что можно сделать с этим датасетом:
- Найти запасные шрифты аналогичной ширины или стиля.
- На основе х-высоты автоматически настроить размеры шрифтов и высоты строк.
- Найти комбинации шрифтов, опираясь на их сходства или различия.
- Создать собственное меню выбора шрифтов для дизайнера постера фильма Avatar.
- …
Приложение
Дополнительные материалы
Panose Classification Metrics Guide
Руководство 1991 года, подробно описывающее, как измерять отдельные символы, чтобы получать подходящие для сравнения метрики. К сожалению, эти измерения надо делать вручную, что потребует много времени.
Taking The Robots To Design School, Part 1 by Jon Gold
В мае 2016 Джон Голд (Jon Gold) написал о своём подходе к анализу шрифтов. Он затронул такие темы, как дизайн на основе правил (rule based design), ИИ и соответствие датасетов инструментам дизайнеров.
Google Fonts Tools
Набор open source-инструментов для анализа шрифтов на сайте Google Fonts. Например, для определения угла наклона шрифта.
Font Bakery
Это набор Python-инструментов для проверки TrueType-файлов и файлов метаданных для шрифтов с Google Fonts.
Почему просто не использовать данные из сервисов веб-шрифтов?
Все подобные сервисы — например, Typekit, Google Fonts, Fontstand, Fontshop, MyFonts и так далее — имеют собственные наборы фильтров с разной степенью настройки. API этих сервисов по каждому шрифту предоставляют разный объём информации.
Например, для шрифта Roboto от веб API Google Fonts можно получить категорию «гротеск» и варианты шрифта. https://gist.github.com/getflourish/d79836b0bebb6b44f76389b623fd7dc1
API Typekit предоставляет ещё ширину, х-высоту, вес, классификацию, контраст, заглавные буквы и рекомендации.
https://gist.github.com/getflourish
