[Перевод] Анализ инцидента 21 октября на GitHub
Роковые 43 секунды, которые вызвали суточную деградацию сервиса
На прошлой неделе в GitHub произошёл инцидент, который привёл к деградации сервиса на 24 часа и 11 минут. Инцидент затронул не всю платформу, а только несколько внутренних систем, что привело к отображению устаревшей и непоследовательной информации. В конечном счете данные пользователей не были потеряны, но ручная сверка нескольких секунд записи в БД выполняется до сих пор. На протяжении почти всего сбоя GitHub также не мог обрабатывать вебхуки, создавать и публиковать сайты GitHub Pages.
Все мы в GitHub хотели бы искренне извиниться за проблемы, которые возникли у всех вас. Мы знаем о вашем доверии GitHub и гордимся созданием устойчивых систем, которые поддерживают высокую доступность нашей платформы. С этим инцидентом мы вас подвели и глубоко сожалеем. Хотя мы не можем отменить проблемы из-за деградации платформы GitHub в течение длительного времени, но можем объяснить причины произошедшего, рассказать об усвоенных уроках и о мерах, которые позволят компании лучше защититься от подобных сбоев в будущем.
Большинство пользовательских сервисов GitHub работают в наших собственных центрах обработки данных. Топология ЦОД предназначена для обеспечения надёжной и расширяемой граничной сети перед несколькими региональными ЦОД, которые обеспечивают работу вычислительных систем и систем хранения данных. Несмотря на уровни избыточности, встроенные в физические и логические компоненты проекта, по-прежнему возможна ситуация, когда сайты не смогут взаимодействовать друг с другом в течение некоторого времени.
21 октября в 22:52 UTC плановые ремонтные работы по замене неисправного оптического оборудования 100G привели к потере связи между сетевым узлом на Восточном побережье (US East Coast) и основным дата-центром на Восточном побережье. Подключение между ними восстановилось через 43 секунды, но это короткое отключение вызвало цепочку событий, которые привели к 24 часам и 11 минутам деградации сервиса.
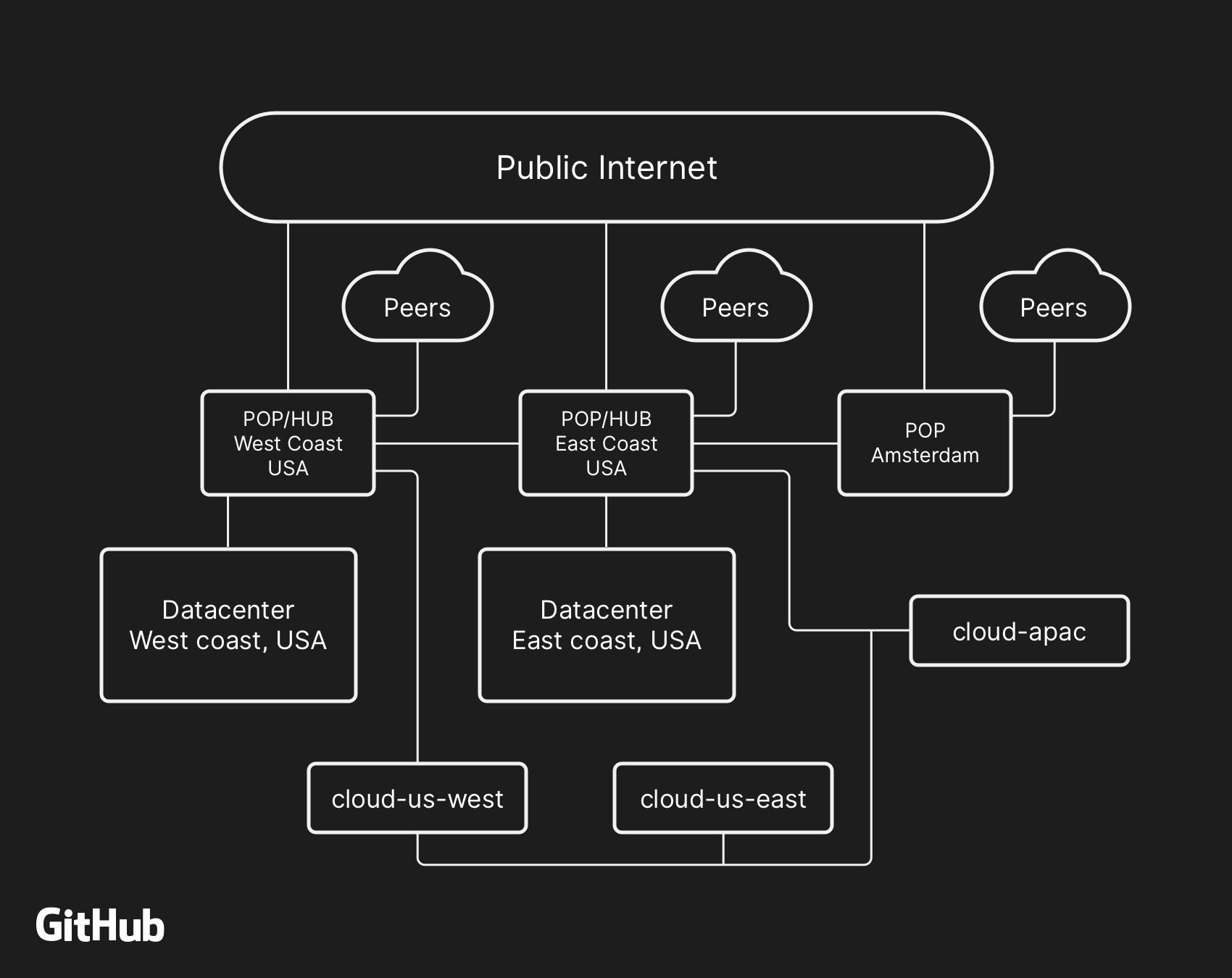
Высокоуровневая сетевая архитектура GitHub, включая два физических центра обработки данных, 3 POP и облачные хранилища в нескольких регионах, подключённые через пиринг
В прошлом мы обсуждали, как используем MySQL для хранения метаданных GitHub, а также наш подход к обеспечению высокой доступности MySQL. GitHub управляет несколькими кластерами MySQL размером от сотен гигабайт до почти пяти терабайт. В каждом кластере десятки реплик чтения для хранения метаданных, отличных от Git, поэтому наши приложения обеспечивают пул-реквесты, тикеты (issues), аутентификацию, фоновую обработку и дополнительные функции за пределами хранилища объектов Git. Различные данные в разных частях приложения хранятся в различных кластерах с помощью функционального сегментирования.
Для повышения производительности в большом масштабе приложения направляют записи на соответствующий первичный сервер для каждого кластера, но в подавляющем большинстве случаев делегируют запросы на чтение подмножеству серверов-реплик. Мы используем Orchestrator для управления топологиями кластеров MySQL и автоматической отработки отказов. В ходе этого процесса Orchestrator учитывает ряд переменных и собран поверх Raft для согласованности. Orchestrator потенциально может реализовать топологии, которые приложения не поддерживают, поэтому необходимо следить за соответствием конфигурации Orchestrator ожиданиям на уровне приложений.
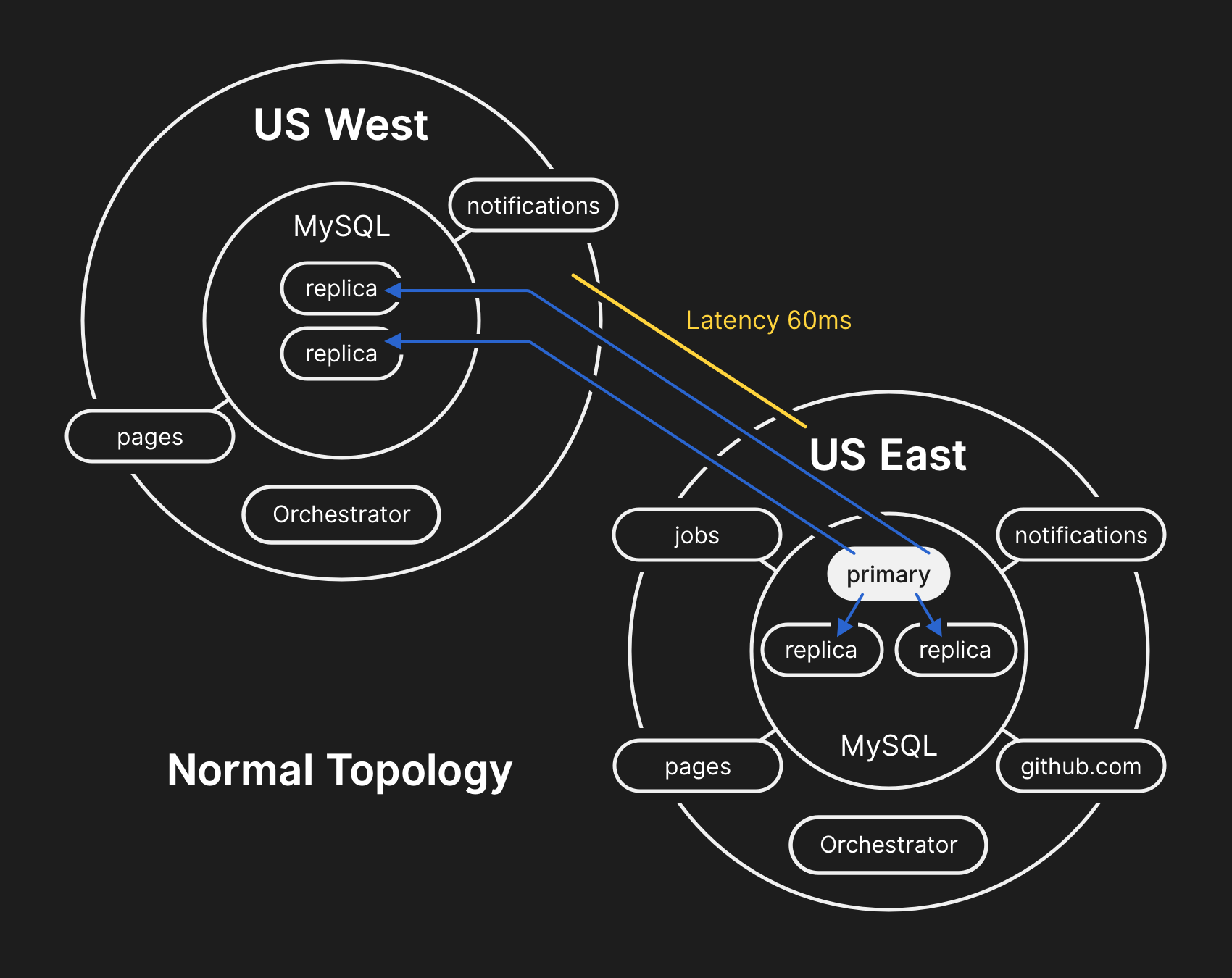
В обычной топологии все приложения выполняют чтение локально с низкой задержкой
21.10.2018, 22:52 UTC
Во время упомянутого разделения сети Orchestrator в основном дата-центре начал процесс отмены выбора руководства согласно алгоритму консенсуса Raft. Дата-центр Западного побережья и узлы Orchestrator публичного облака на Восточном побережье сумели достичь консенсуса — и начали отработку отказа кластеров для направления записей в западный дата-центр. Orchestrator начал создавать топологию кластера БД на Западе. После восстановления подключения приложения сразу направили трафик по записи на новые основные сервера в US West.
На серверах БД в восточном дата-центре остались записи за краткий период, которые не реплицировались в западный ЦОД. Поскольку кластеры БД в обоих ЦОД теперь содержали записи, которых не было в другом ЦОД, мы не смогли безопасно вернуть первичный сервер обратно в восточный дата-центр.
21.10.2018, 22:54 UTC
Наши внутренние системы мониторинга начали генерировать оповещения, указывающие на многочисленные сбои в работе систем. В это время несколько инженеров отвечали и работали над сортировкой входящих уведомлений. К 23:02 инженеры первой группы реагирования определили, что топологии для многочисленных кластеров БД находятся в неожиданном состоянии. При запросе API Orchestrator отображалась топология репликации БД, содержащая только серверы из западного ЦОД.
21.10.2018, 23:07 UTC
К этому моменту группа реагирования решила вручную заблокировать внутренние средства развёртывания, чтобы предотвратить внесение дополнительных изменений. В 23:09 группа установила жёлтый статус работоспособности сайта. Это действие автоматически присвоило ситуации статус активного инцидента и отправило предупреждение координатору инцидентов. В 23:11 координатор присоединился к работе и через две минуты принял решение изменить статус на красный.
21.10.2018, 23:13 UTC
На тот момент было понятно, что проблема затрагивает несколько кластеров БД. К работе привлекли дополнительных разработчиков из инженерной группы БД. Они начали исследовать текущее состояние, чтобы определить, какие действия необходимо предпринять, чтобы вручную настроить базу данных Восточного побережья США в качестве основной для каждого кластера и перестроить топологию репликации. Это было непросто, поскольку к этому моменту западный кластер баз данных принимал записи с уровня приложений в течение почти 40 минут. Кроме того, в восточном кластере существовало несколько секунд записей, которые не были реплицированы на запад и не позволяли реплицировать новые записи обратно на восток.
Защита конфиденциальности и целостности пользовательских данных является наивысшим приоритетом GitHub. Поэтому мы решили, что более 30 минут данных, записанных в западный ЦОД, оставляют нам только один вариант решения ситуации, чтобы сохранить эти данные: перенос вперёд (failing-forward). Однако приложения на востоке, которые зависят от записи информации в западный кластер MySQL, в настоящее время не способны справиться с дополнительной задержкой из-за передачи большинства их вызовов БД туда и обратно. Это решение приведёт к тому, что наш сервис станет непригодным для многих пользователей. Мы считаем, что длительная деградация качества обслуживания стоила того, чтобы обеспечить согласованность данных наших пользователей.
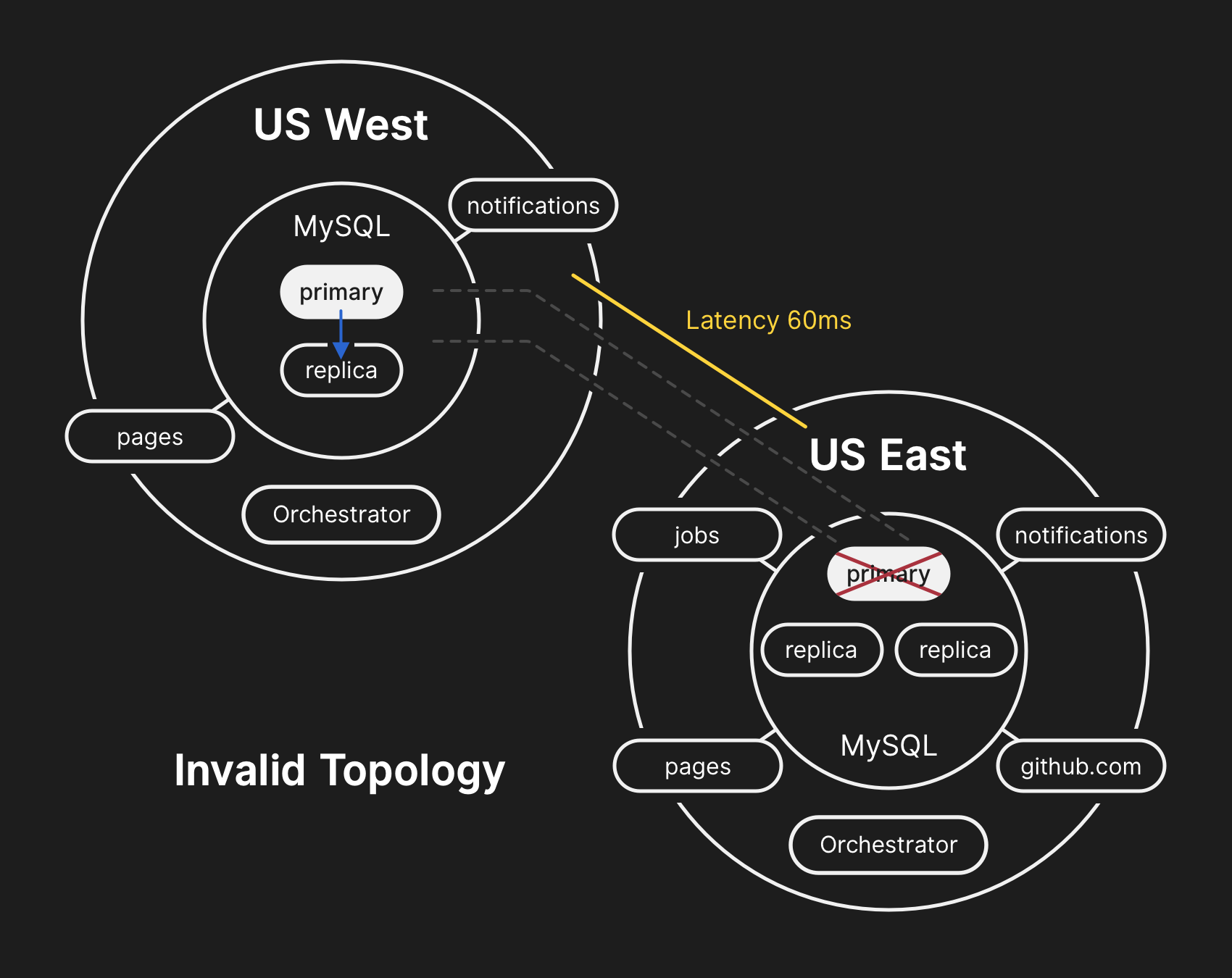
В неправильной топологии нарушена репликация с Запада на Восток, а приложения не могут считывать данные из текущих реплик, поскольку зависят от низкой задержки для поддержания производительности транзакций
21.10.2018, 23:19 UTC
Запросы о состоянии кластеров БД показали, что необходимо остановить выполнение заданий, которые пишут метаданные типа пуш-запросов. Мы сделали выбор и сознательно пошли на частичную деградацию сервиса, приостановив вебхуки и сборку GitHub Pages, чтобы не ставить под угрозу данные, которые уже получили от пользователей. Другими словами, стратегия заключалась в расстановке приоритетов: целостность данных вместо удобства использования сайта и быстрого восстановления.
22.10.2018, 00:05 UTC
Инженеры из группы реагирования начали разрабатывать план устранения несогласованности данных и запустили процедуры отработки отказа для MySQL. План состоял в том, чтобы восстановить файлы из бэкапа, синхронизировать реплики на обоих сайтах, вернуться к стабильной топологии обслуживания, а затем возобновить обработку заданий в очереди. Мы обновили статус, чтобы сообщить пользователям, что собираемся выполнить управляемую отработку отказа внутренней системы хранения данных.
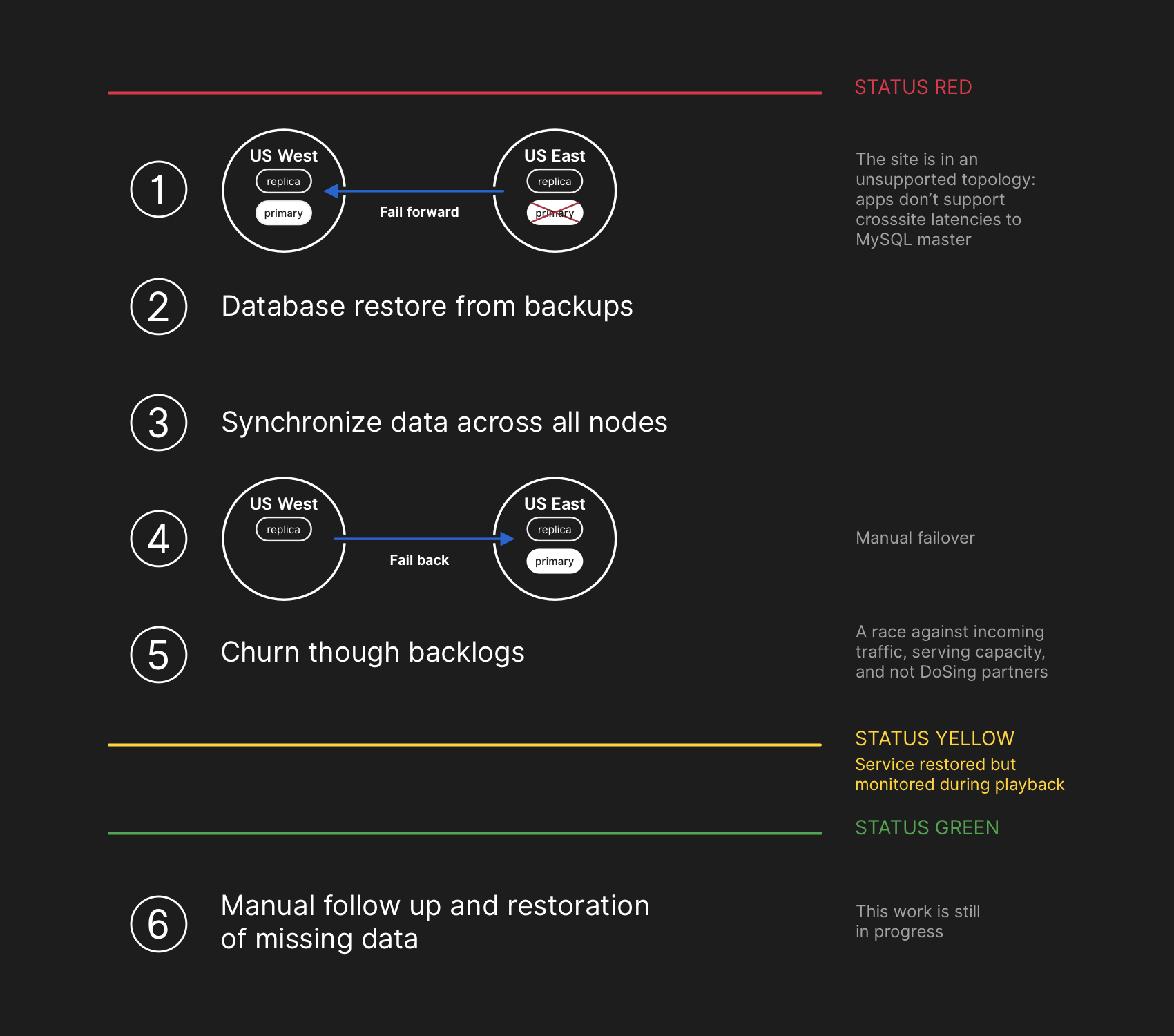
План восстановления предполагал перенос вперёд, восстановление из бэкапов, синхронизацию, откат назад и отработку просрочки, прежде чем вернуться на зелёный статус
Хотя резервные копии MySQL делаются каждые четыре часа и сохраняются в течение многих лет, но они лежат в удалённом облачном хранилище блоб-объектов. Восстановление нескольких терабайт из бэкапа заняло несколько часов. Долго шла передача данных из службы удалённого резервного копирования. Основная часть времени ушла на процесс распаковки, проверки контрольной суммы, подготовки и загрузки больших файлов бэкапа на свежеподготовленные серверы MySQL. Эта процедура тестируется ежедневно, поэтому все хорошо представляли, сколько времени займёт восстановление. Однако до этого инцидента нам никогда не приходилось полностью перестраивать весь кластер из резервной копии. Всегда работали другие стратегии, такие как отложенные реплики.
22.10.2018, 00:41 UTC
К этому времени был инициирован процесс резервного копирования для всех затронутых кластеров MySQL, и инженеры отслеживали прогресс. Одновременно несколько групп инженеров изучали способы ускорения передачи и восстановления без дальнейшей деградации сайта или риска повреждения данных.
22.10.2018, 06:51 UTC
Несколько кластеров в восточном ЦОД завершили восстановление из резервных копий и начали реплицировать новые данные с Западным побережьем. Это привело к замедлению загрузки страниц, которые выполняли операцию записи через всю страну, но чтение страниц из этих кластеров БД возвращало актуальные результаты, если запрос чтения попадал на только что восстановленную реплику. Другие более крупные кластеры БД продолжали восстанавливаться.
Наши команды определили способ восстановления непосредственно с Западного побережья, чтобы преодолеть ограничения пропускной способности, вызванные загрузкой из внешнего хранилища. Стало практически на 100% понятно, что восстановление завершится успешно, а время для создания здоровой топологии репликации зависит от того, сколько займёт догоняющая репликация. Эта оценка была линейно интерполирована на основе доступной телеметрии репликации, и страница состояния была обновлена, чтобы установить ожидание в два часа в качестве расчётного времени восстановления.
22.10.2018, 07:46 UTC
GitHub опубликовал информационное сообщение в блоге. Мы сами используем GitHub Pages, и все сборки поставили на паузу несколько часов назад, поэтому публикация потребовала дополнительных усилий. Приносим извинения за задержку. Мы намеревались разослать это сообщение гораздо раньше и в будущем обеспечим публикации обновлений в условиях таких ограничений.
22.10.2018, 11:12 UTC
Все первичные БД вновь переведены на Восток. Это привело к тому, что сайт стал гораздо более отзывчивым, так как записи теперь были направлялись на сервер БД, расположенный в том же физическом ЦОД, что и наш уровень приложений. Хотя это существенно повысило производительность, всё ещё остались десятки реплик чтения БД, которые отставали от основной копии на несколько часов. Эти отложенные реплики привели к тому, что пользователи видели несогласованные данные при взаимодействии с нашими службами. Мы распределяем нагрузку чтения по большому пулу реплик чтения, и каждый запрос к нашим службам имеет хорошие шансы попасть в реплику чтения с задержкой в несколько часов.
На самом деле время догона отстающей реплики сокращается по экспоненте, а не линейно. Когда проснулись пользователи в США и Европе, из-за увеличения нагрузки на записи в кластерах БД процесс восстановления занял больше времени, чем предполагалось.
22.10.2018, 13:15 UTC
Мы приближались к пику нагрузки на GitHub.com. В команде реагирования прошло обсуждение дальнейших действий. Было ясно, что отставание репликации до согласованного состояния увеличивается, а не уменьшается. Ранее мы начали подготовку дополнительных реплик чтения MySQL в общедоступном облаке Восточного побережья. Как только они стали доступны, стало легче распределять поток запросов на чтение между несколькими серверами. Уменьшение средней нагрузки на реплики чтения ускорило догон репликации.
22.10.2018, 16:24 UTC
После синхронизации реплик мы вернулись к исходной топологии, устранив проблемы задержки и доступности. В рамках сознательного решения о приоритете целостности данных над быстрым исправлением ситуации мы сохранили красный статус сайта, когда начали обрабатывать накопленные данные.
22.10.2018, 16:45 UTC
На этапе восстановления нужно было сбалансировать возросшую нагрузку, связанную с отставанием, потенциально перегружая наших партнёров по экосистеме уведомлениями и как можно быстрее возвращаясь к стопроцентной работоспособности. В очереди оставалось более пяти миллионов событий хуков и 80 тыс. запросов на построение веб-страниц.
Когда мы повторно включили обработку этих данных, то обработали около 200 000 полезных задач с вебхуками, которые превысили внутренний TTL и были отброшены. Узнав об этом, мы остановили обработку и запушили увеличение TTL.
Чтобы избежать дальнейшего снижения надёжности наших обновлений статуса, мы оставили статус деградации до тех пор, пока не завершим обработку всего накопившегося объёма данных и не убедимся, что сервисы чётко вернулись к нормальному уровню производительности.
22.10.2018, 23:03 UTC
Все незавершённые события вебхуков и сборки Pages обработаны, а целостность и правильная работа всех систем подтверждена. Статус сайта обновлён на зелёный.
Устранение несоответствия данных
Во время восстановления мы зафиксировали бинарные логи MySQL c записями в основном ЦОД, которые не реплицировались на западный. Общее число таких записей относительно невелико. Например, в одном из самых загруженных кластеров всего 954 записи за эти секунды. В настоящее время мы анализируем эти логи и определяем, какие записи могут быть автоматически согласованы, а какие потребуют содействия пользователей. В этой работе участвует несколько команд, и наш анализ уже определил категорию записей, которые пользователь затем повторил — и они успешно сохранились. Как указано в этом анализе, нашей основной целью является сохранение целостности и точности данных, которые вы храните на GitHub.
Коммуникация
Пытаясь донести до вас важную информацию во время инцидента, мы сделали несколько публичных оценок по времени восстановления на основе скорости обработки накопившихся данных. Оглядываясь назад, наши оценки не учитывали всех переменных. Приносим извинения за возникшую путаницу и будем стремиться предоставлять более точную информацию в будущем.
Технические меры
В ходе этого анализа был выявлен ряд технических мер. Анализ продолжается, список может быть дополнен.
- Отрегулировать конфигурацию Orchestrator, чтобы запретить перемещение первичных БД за границы региона. Orchestrator работал в соответствии с настройками, хотя уровень приложений не поддерживал такое изменение топологии. Выбор лидера внутри региона обычно безопасен, но внезапное появление задержки из-за передачи трафика через весь континент стало основной причиной этого инцидента. Это эмерджентное, новое поведение системы, ведь раньше мы не сталкивались с внутренним разделом сети такого масштаба.
- Мы ускорили миграцию на новую систему отчётности по статусам, которая предоставит более подходящую площадку для обсуждения активных инцидентов более чёткими и ясными формулировками. Хотя многие части GitHub были доступны на протяжении всего инцидента, мы могли выбрать только зелёный, жёлтый и красный статусы для всего сайта. Признаём, что это не даёт точной картины: что работает, а что нет. Новая система будет отображать различные компоненты платформы, чтобы вы знали статус каждой службы.
- За несколько недель до этого инцидента мы запустили общекорпоративную инженерную инициативу для поддержки обслуживания трафика GitHub из нескольких ЦОД по архитектуре active/active/active. Цель данного проекта — поддержка избыточности N+1 на уровне ЦОД, чтобы выдерживать отказ одного ЦОД без вмешательства со стороны. Это большая работа и займёт некоторое время, но мы считаем, что несколько хорошо связанных дата-центров в разных регионах обеспечат хороший компромисс. Последний инцидент ещё сильнее подтолкнул данную инициативу.
- Мы займём более активную позицию в проверке своих предположений. GitHub быстро растёт и накопил немалую долю сложности за последнее десятилетие. Становится всё труднее уловить и передать новому поколению сотрудников исторический контекст компромиссов и принятых решений.
Организационные меры
Этот инцидент сильно повлиял на наше представление о надёжности сайта. Мы узнали, что ужесточение оперативного контроля или улучшение времени реагирования являются недостаточными гарантиями надёжности в такой сложной системе сервисов, как наша. Чтобы поддержать эти усилия, мы также начнём системную практику проверки сценариев сбоев, прежде чем они возникнут в реальности. Эта работа включает умышленное внесение неисправностей и применение инструментов хаос-инжиниринга.
Знаем, как вы полагаетесь на GitHub в своих проектах и бизнесе. Мы как никто заботимся о доступности нашего сервиса и сохранности ваших данных. Анализ этого инцидента продолжится, чтобы найти возможность лучше вам служить и оправдать ваше доверие.
