[Перевод] Ampere — новейшая игровая архитектура NVIDIA. Самое важное из вайт пейпера

С момента изобретения своего первого графического процессора в 1999 году NVIDIA находится в авангарде трехмерной графики и вычислений с ускорением на графическом процессоре. Каждая архитектура NVIDIA тщательно разработана для обеспечения революционного уровня производительности и эффективности.
A100, первый графический процессор с архитектурой NVIDIA Ampere, был выпущен в мае 2020 года. Он обеспечивает колоссальное ускорение для обучения ИИ, высокопроизводительных вычислений и анализа данных. В основе A100 лежит чип GA100 — чисто вычислительный и, в отличие от GA102, еще не игровой.
Графические процессоры GA10x основаны на архитектуре графических процессоров NVIDIA Turing. Turing — первая архитектура в мире, предлагающая высокопроизводительную трассировку лучей в реальном времени, графику с ИИ-ускорением и профессиональный рендеринг графики — все в одном устройстве.
В этой статье мы разберем основные изменения в архитектуре новых видеокарт NVIDIA по сравнению с предшественницей. 
Рисунок 1. Архитектура Ampere GA10x
Основные характеристики GA102
GA102 изготовлен по собственной технологии NVIDIA на базе 8 нм — 8N NVIDIA Custom. Чип содержит 28,3 миллиарда транзисторов на кристалле размером 628,4 мм2. Как и во всех GeForce RTX, в основе GA102 лежит процессор, содержащий три различных типа вычислительных ресурсов:
- CUDA-ядра для программируемого шейдинга;
- RT-ядра, ускоряющие расчет пересечений геометрии сцены с ограничивающими объемами (BVH) во время трассировки лучей;
- Тензорные ядра, значительно ускоряющие вывод и обучение нейронной сети.
Описание архитектуры Ampere
Высокоуровневая архитектура GPC, TPC и SM
Как и предшественники, GA102 состоит из графических кластеров Graphics Processing Cluster (GPC), кластеров обработки текстур Texture Processing Cluster (TPC), потоковых мультипроцессоров (SM), блоков растеризации Raster Operator (ROP) и контроллеров памяти. Полный чип имеет семь блоков GPC, 42 TPC и 84 SM.
GPC — это доминирующий высокоуровневый блок, включающий все ключевые графические составляющие. Каждый GPC имеет выделенный движок Raster Engine, а теперь еще и по два раздела ROP из восьми блоков каждый, что является новшеством архитектуры Ampere. Кроме того, GPC содержит шесть TPC, в каждом из которых расположено по два мультипроцессора и по одному PolyMorph Engine.
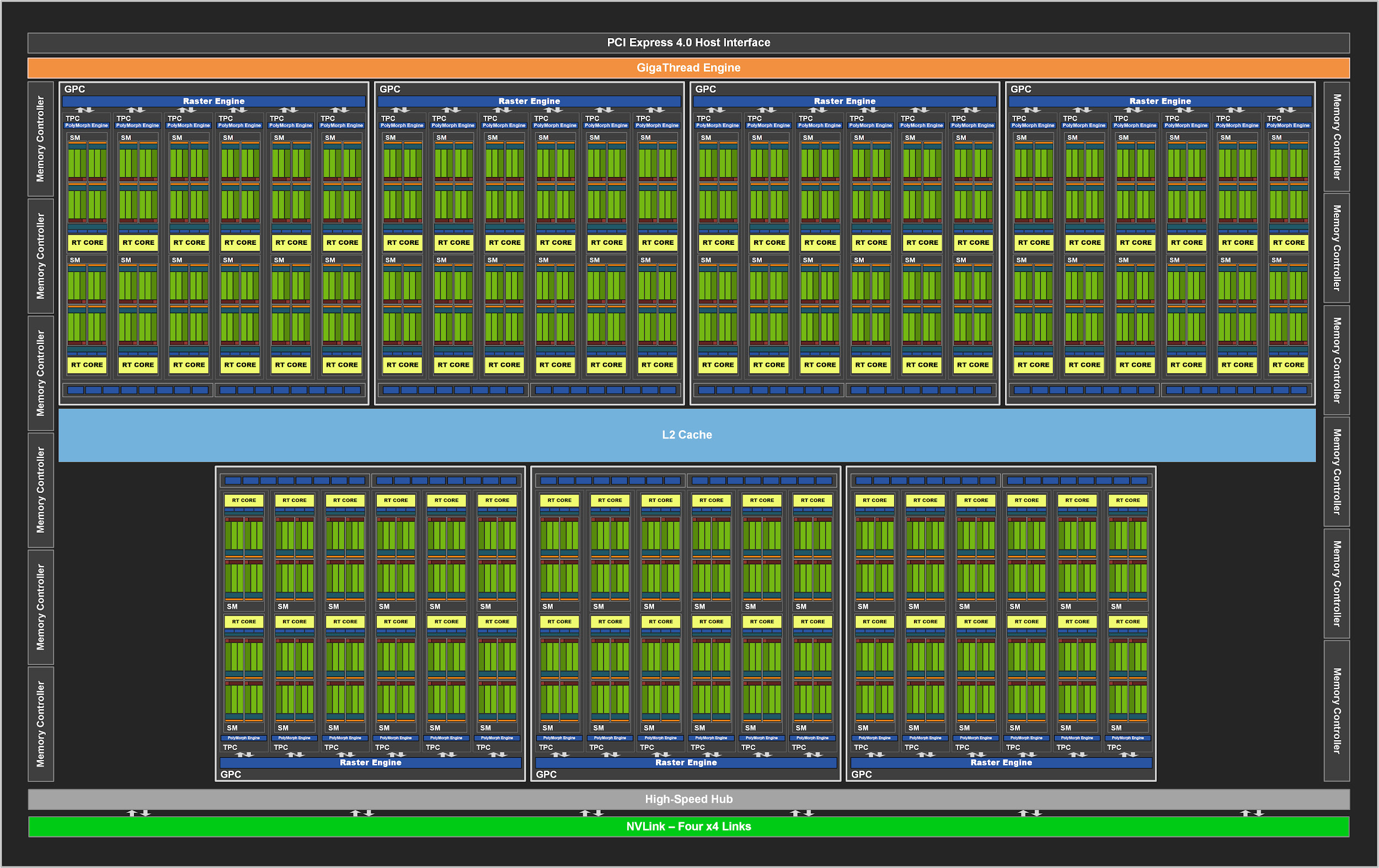
Рисунок 2. Полный GPU GA102 с 84 блоками SM
В свою очередь, каждый SM в GA10x содержит 128 CUDA-ядра, четыре тензорных ядра третьего поколения, регистровый файл 256 КБ, четыре текстурных блока, одно ядро трассировки лучей второго поколения и 128 КБ L1/общей памяти, которые могут быть настроены для различных мощностей в зависимости от потребностей вычислительных или графических задач.
Оптимизация блоков растеризации (ROP)
В предыдущих графических процессорах NVIDIA ROP были привязаны к контроллеру памяти и кэшу L2. Начиная с GA10x, они являются частью GPC, что повышает производительность растровых операций за счет увеличения общего числа ROP.
Итого, имея по семь кластеров GPC и 16 блоков ROP в каждом GPC, графический процессор GA102 состоит из 112 ROP вместо 96, например, в TU102. Все это оказывает положительное влияние на мультисэмпловое сглаживание, скорость заполнения пикселей и блендинг.
NVLink третьего поколения
Графические процессоры GA102 поддерживают интерфейс NVIDIA NVLink третьего поколения, включающий в себя четыре канала x4, каждый из которых обеспечивает пропускную способность 14,0625 ГБ/с между двумя графическими процессорами в любом направлении. Четыре канала вместе дают пропускную способность 56,25 ГБ/с в каждом направлении и в целом 112,5 ГБ/с между двумя графическими процессорами. Так, с помощью NVLink можно соединить два графических процессора RTX 3090.
PCIe четвертого поколения
Графические процессоры GA10x оснащены интерфейсом PCI Express 4.0, который обеспечивает вдвое большую пропускную способность по сравнению с PCIe 3.0, скорость передачи данных до 16 гигатрансферов в секунду, а благодаря слоту x16 PCIe 4.0 пиковая пропускная способность достигает 64 ГБ/с.
Архитектура мультипроцессоров GA10x
Архитектура мультипроцессоров Turing стала первой в NVIDIA, у которой имелись отдельные ядра для ускорения операций трассировки лучей. Затем в Volta появились первые тензорные ядра, а в Turing — усовершенствованные тензорные ядра второго поколения. Еще одним нововведением в Turing и Volta стала возможность одновременного выполнения операций FP32 и INT32. Мультипроцессор в GA10x поддерживает все вышеперечисленные возможности, а также имеет ряд собственных улучшений.
В отличие от TU102, состоящего из восьми тензорных ядер второго поколения, мультипроцессор GA10x имеет четыре тензорных ядра третьего поколения, причем каждое тензорное ядро GA10x в два раза мощнее, чем у Turing.
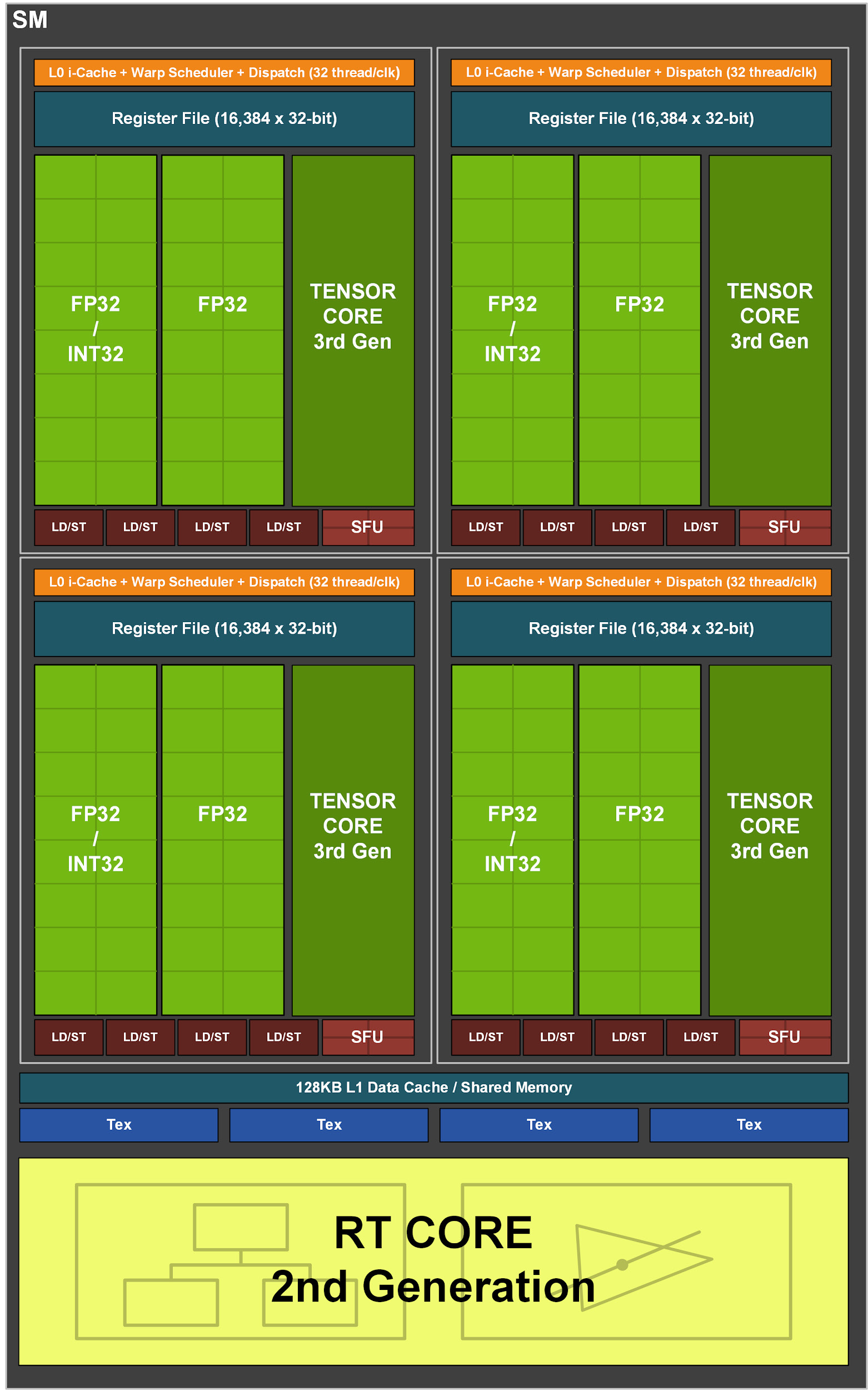
Рисунок 3. Потоковый мультипроцессор GA10x
Удвоенная скорость вычислений FP32
Большинство графических вычислений приходится на 32-битные операции с плавающей запятой (FP32). Потоковый мультипроцессор в архитектуре Ampere GA10x обеспечивает в два раза более быструю обработку операций FP32 в обоих каналах данных. В результате в разрезе FP32 GeForce RTX 3090 обеспечивает более 35 терафлопс, что более чем в 2 раза превышает возможности Turing.
GA10X может выполнять 128 FP32-операций или 64 операции FP32 и 64 INT32 за такт, что вдвое превышает скорость вычислений Turing.
Задачи современного гейминга имеют широкий спектр потребностей в обработке. Многие вычисления требуют связки операций FP32 (таких как FFMA, сложение с плавающей запятой (FADD) или умножение с плавающей запятой (FMUL)), а также выполнения множества более простых целочисленных вычислений.
Мультипроцессоры GA10x продолжают поддерживать двухскоростные операции FP16 (HFMA), которые поддерживались и в Turing. И, аналогично графическим процессорам TU102, TU104 и TU106, в GA10x стандартные операции FP16 тоже обрабатываются тензорными ядрами.
Разделяемая память и кэш данных L1
GA10x имеет унифицированную архитектуру для разделяемой памяти, кэша данных L1 и кэша текстур. Этот унифицированный дизайн можно изменить в зависимости от рабочей нагрузки и потребностей.
Чип GA102 содержит 10752 КБ кэша L1 (по сравнению с 6912 КБ в TU102). Помимо этого, GA10x также имеет удвоенную пропускную способность разделяемой памяти по сравнению с Turing (128 байт/такт против 64 байт/такт). Общая пропускная способность L1 для GeForce RTX 3080 составляет 219 ГБ/с против 116 ГБ/с у GeForce RTX 2080 Super.
Производительность на ватт
Все архитектура NVIDIA Ampere создана для повышения эффективности — от логики, памяти, питания и теплового режима до конструкции печатной платы, программного обеспечения и алгоритмов. При том же уровне производительности графические процессоры с архитектурой Ampere до 1,9 раз более энергоэффективны, чем аналогичные устройства Turing.
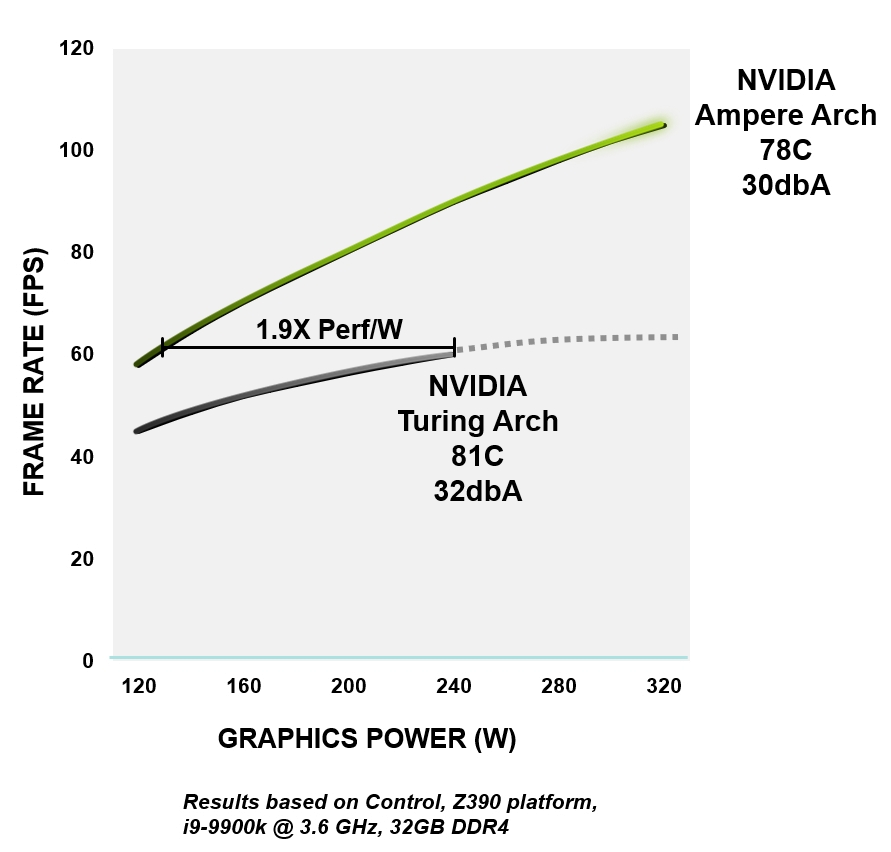
Рисунок 4. Эффективность энергопотребления RTX 3080 по сравнению с архитектурой GeForce RTX 2080 Super
RT-ядра второго поколения
Новые RT-ядра имеют ряд улучшений, которые в совокупности с обновленными системами кэширования эффективно удваивают производительность процессоров Ampere по сравнению с Turing в вопросах трассировки лучей. Кроме того, GA10x позволяет запускать одновременно с RT-вычислениями и другие процессы, тем самым значительно ускоряя многие задачи.
Трассировка лучей второго поколения в GA10x
GeForce RTX на основе архитектуры Turing стали первыми графическими процессорами, с которыми кинематографическая трассировка лучей стала реальностью в компьютерных играх. GA10x оснащены технологией трассировки лучей уже второго поколения. Как и у Turing, мультипроцессоры в GA10x имеют специализированные аппаратные блоки для проверки на пересечения лучей с BVH и треугольниками. При этом ядра мультипроцессоров Ampere имеют вдвое большую скорость тестирования пересечения лучей и треугольников по сравнению с Turing.
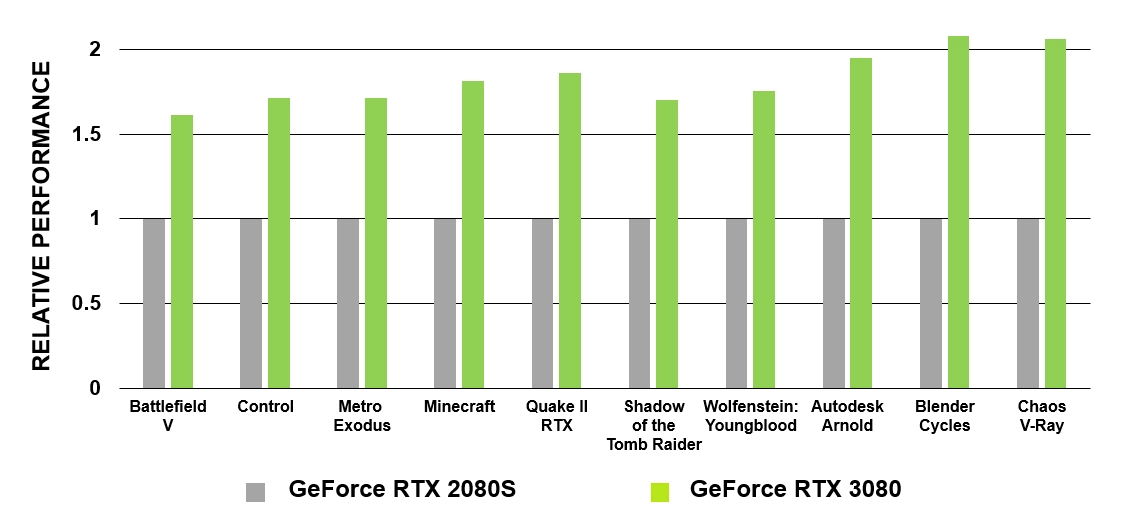
Рисунок 5. Сравнение производительности RT-ядер GeForce RTX 3080 и GeForce RTX 2080 Super
Мультипроцессор GA10x может выполнять операции одновременно и при этом не ограничивается только вычислениями и графикой, как это было в предыдущих поколениях графических процессоров. Так, например, в GA10x алгоритм шумоподавления может выполняться одновременно с трассировкой лучей.
Рисунок 6. Ядро RT второго поколения в графических процессорах GA10x
Обратите внимание, что рабочие нагрузки с интенсивным использованием RT-ядер не вызывают значительного повышения нагрузки на ядра мультипроцессора, тем самым позволяя использовать мультипроцессорную вычислительную мощность для других задач. Это большое преимущество перед другими конкурирующими архитектурами, которые не имеют выделенных RT -ядер, отчего вынуждены использовать свои стандартные блоки для выполнения как графических операций, так и трассировки лучей.
Процессоры RTX с архитектурой Ampere в действии
Трассировка лучей и работа шейдеров требуют больших вычислительных ресурсов. Но было бы намного дороже запускать все с помощью одних только CUDA-ядер, так что включение в работу тензорных и RT-ядер помогает значительно ускорить обработку. На рисунке 7 для примера показана игра Wolfenstein: Youngblood с включенной трассировкой лучей при различных сценариях работы.

Рисунок 7. Рендеринг одного кадра Wolfenstein: Youngblood на RTX 2080 Super GPU с использованием а) шейдерных ядер (CUDA), б) шейдерных ядер и RT-ядер, в) шейдерных ядер, тензорных и RT-ядер. Обратите внимание на постепенно сокращающееся время кадра при добавлении мощностей различных процессорных ядер RTX.
В первом случае для запуска одного кадра требуется 51 мс (~ 20 fps). При включении в работу RT-ядер рендеринг кадра происходит намного быстрее — за 20 мс (50 fps). Использование же DLSS на тензорных ядрах сокращает время кадра до 12 мс (~ 83 fps).
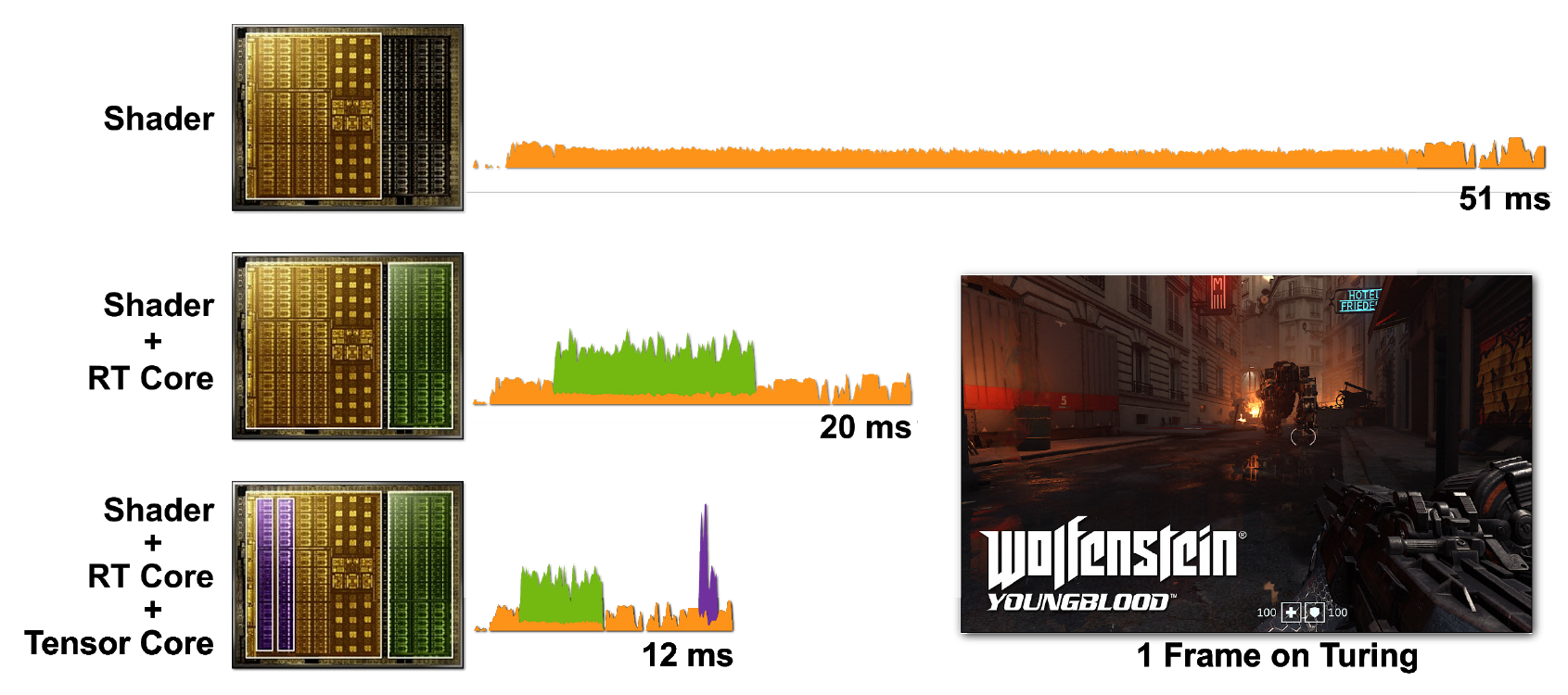
Рисунок 8. Рендеринг одного кадра Wolfenstein: Youngblood на RTX 3080 с использованием а) шейдерных ядер (CUDA), б) шейдерных ядер и RT-ядер, в) шейдерных ядер, тензорных и RT-ядер.
Итак, технология RTX с архитектурой Ampere еще эффективнее справляется с задачами рендеринга: в RTX 3080 рендеринг кадра происходит за 6,7 мс (150 fps), что является огромным улучшением по сравнению с RTX 2080.
Аппаратное ускорение трассировки лучей с использованием размытия движения
Размытие движения (motion blur) — часто используемый в компьютерной графике ход. Фотографическое изображение создается не мгновенно, а путем воздействия света на пленку в течение ограниченного периода времени. Объекты, движущиеся достаточно быстро по сравнению с продолжительностью выдержки камеры, будут отображаться на фотографии в виде полос или пятен. Чтобы графический процессор создавал реалистично выглядящее размытие движения в случае, когда объекты в сцене быстро перемещаются перед статической камерой, он должен уметь имитировать то, как камера и пленка работают с такими сценами. Размытие движения особенно важно в кинопроизводстве, поскольку фильмы воспроизводятся со скоростью 24 кадра в секунду, и сцена без размытия движения будет выглядеть резкой и прерывистой.
Графические процессоры Turing довольно хорошо справляются с ускорением размытия движения в целом. Однако в случае движущейся геометрии задача может оказаться более сложной, поскольку информация о BVH изменяется вместе с положением объектов в пространстве.
Как видно на рисунке 9, RT-ядро Turing производит аппаратный обход иерархии BVH, проверку пересечения лучей с BBox и треугольниками. GA10x умеет все то же самое, но вдобавок имеет новый блок Interpolate Triangle Position, ускоряющий размытие движения при трассировке лучей.
Оба RT-ядра Turing и GA10x реализуют архитектуру MIMD (Multiple Instruction Multiple Data — множественные команды, множественные данные), благодаря которой можно обрабатывать множество лучей одновременно.
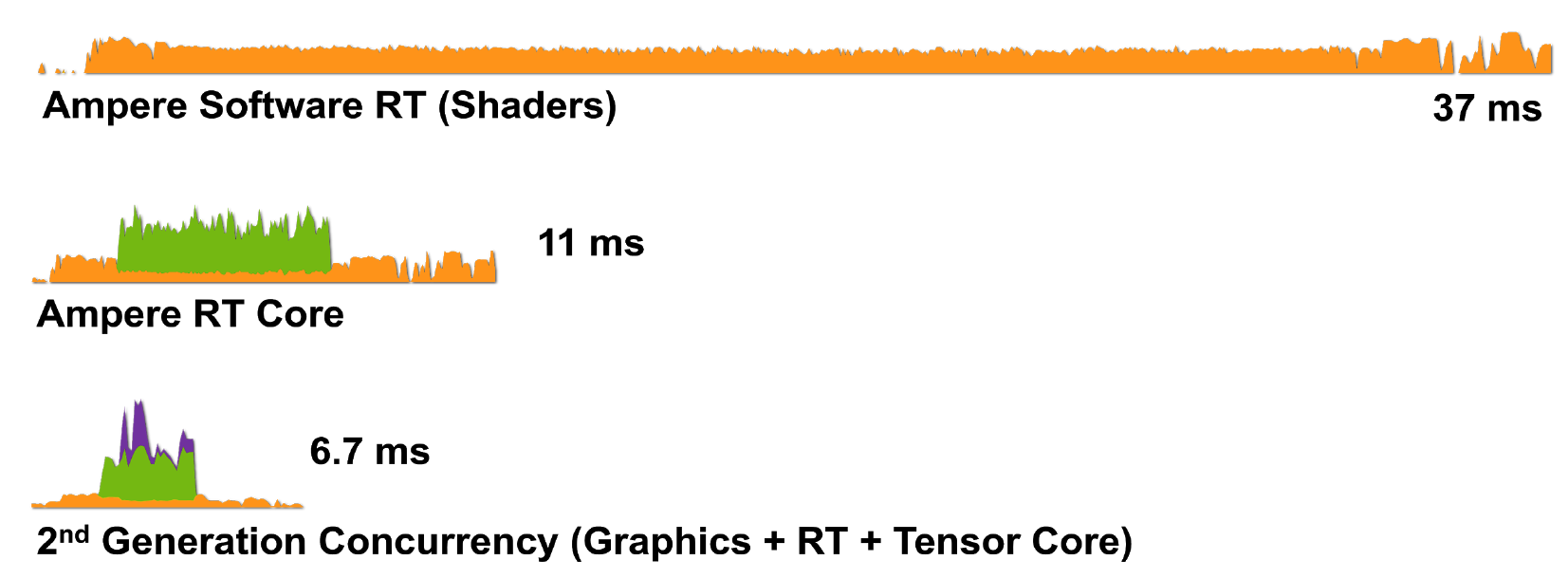
Рисунок 9. Сравнение аппаратного ускорения размытия движения в случае Turing и Ampere
Основная проблема с размытием движения заключается в том, что треугольники в сцене не фиксированы во времени. В базовой трассировке лучей выполняются статичные тесты на пересечение, и при попадании луча в треугольник производится возврат информации об этом попадании. Как показано на рисунке 10, при размытии движения ни у одного треугольника нет фиксированных координат. Каждому лучу присваивается временная метка, указывающая время его отслеживания, и уже из уравнения BVH определяется положение треугольника и пересечения с ним луча.
Если этот процесс не ускорить аппаратно, он может доставить действительно много проблем, в том числе за счет своей нелинейности.
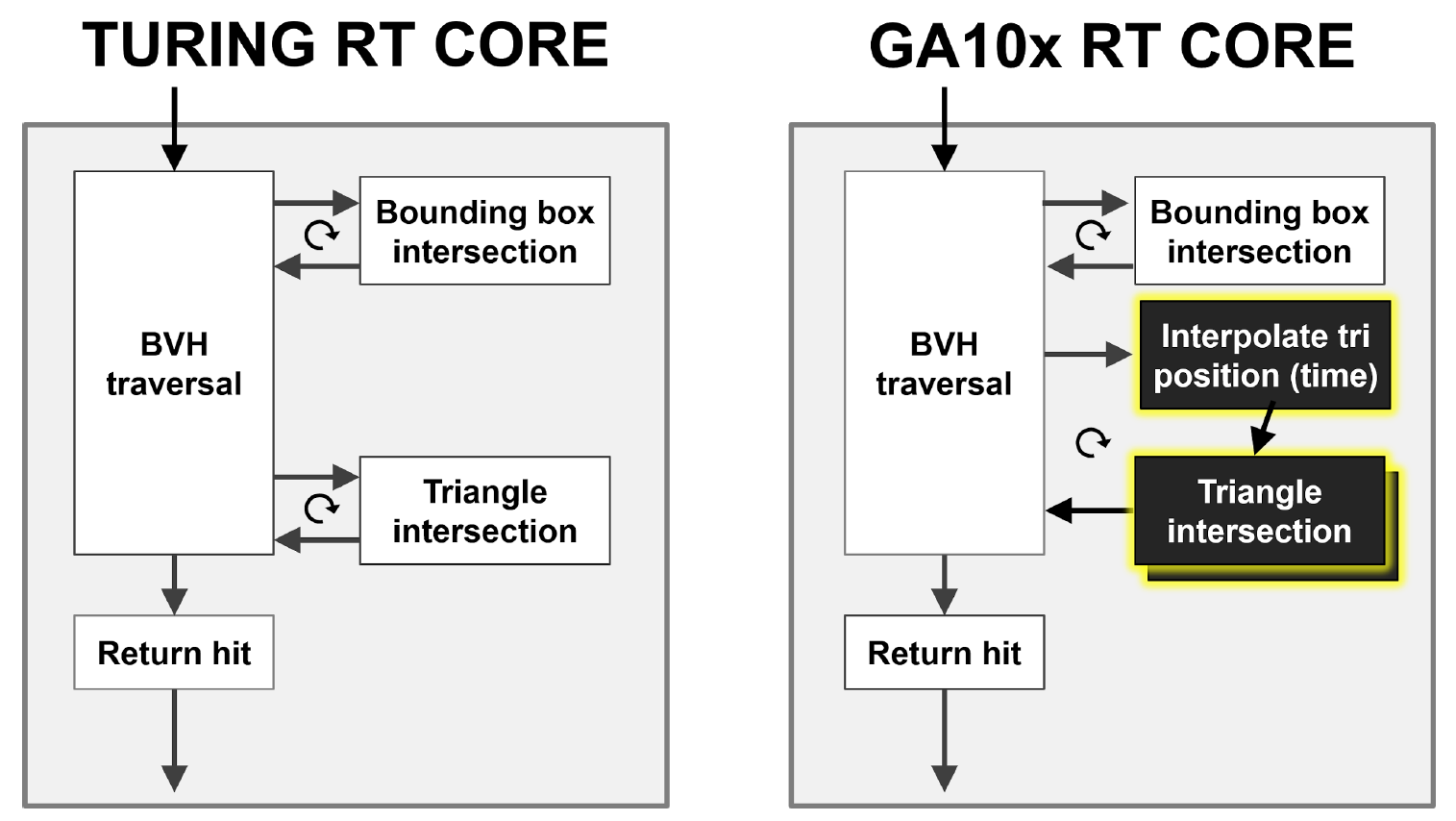
Рисунок. 10. Базовая трассировка лучей и трассировка лучей с размытием движения
В левой части рисунка 11 лучи, отправленные в статичную сцену, попадают в один и тот же треугольник одновременно. Белые точки показывают место попадания, этот результат и возвращается обратно. В случае размытия движения каждый луч существует в свой момент времени. Каждому лучу случайным образом назначается различная временная метка. Например, оранжевые лучи пытаются пересечь оранжевые треугольники в один момент времени, а затем зеленые и синие лучи производят те же самые действия. В конце сэмплы смешиваются, образовывая более математически правильный размытый результат.
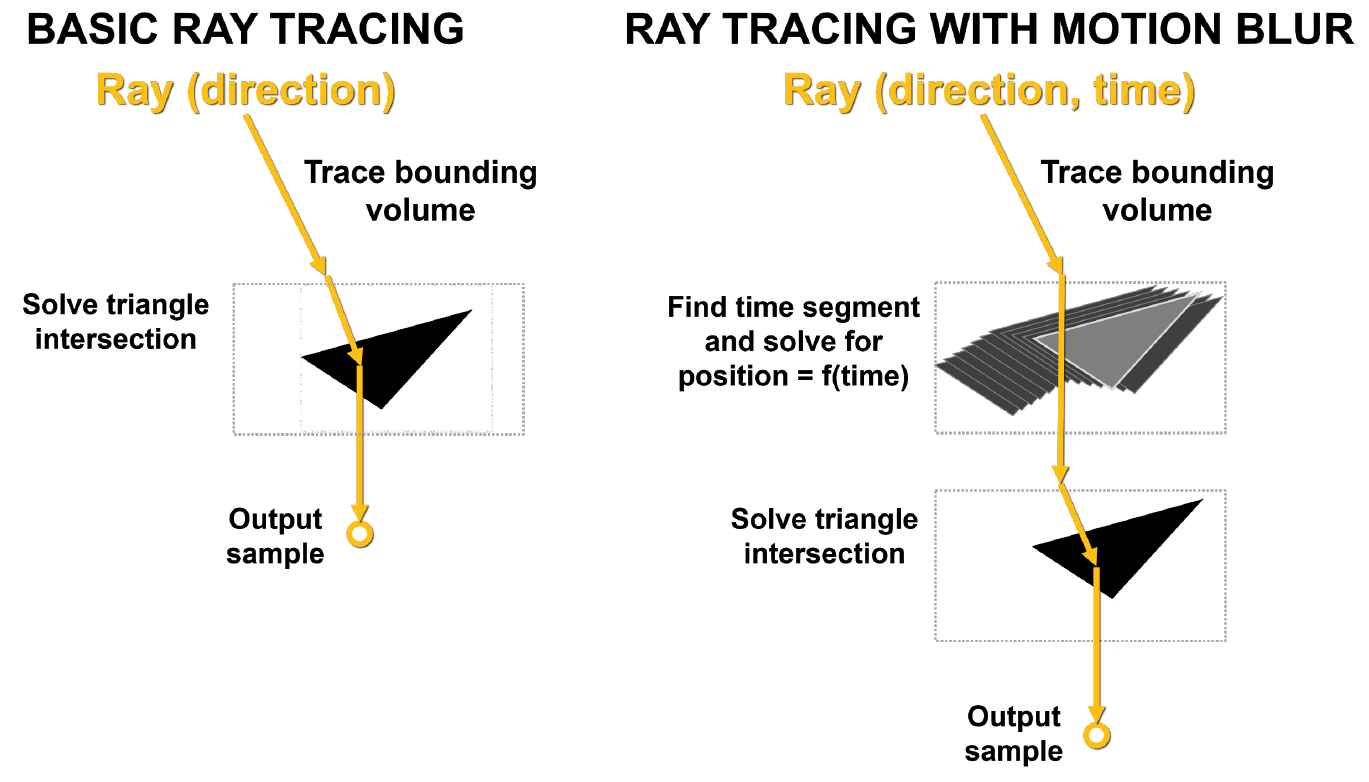
Рисунок 11. Рендеринг без размытия движения и с размытием в GA10x
Блок Interpolate Triangle Position интерполирует треугольники в BVH между уже существующими треугольниками на основе движения объекта, так что лучи будут пересекать их в ожидаемых местах в моменты, определяемые временными метками луча. Такой подход позволяет выполнять точный рендеринг размытия движения с трассировкой лучей до восьми раз быстрее по сравнению с Turing.
Размытие движения с аппаратным ускорением GA10x поддерживается Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold и Redshift Renderer 3.0.X с использованием NVIDIA OptiX 7.0 API.
Скорость рендеринга размытия движения до 5 раз выше в случае RTX 3080 по сравнению с RTX 2080 Super.
Тензорные ядра третьего поколения в графических процессорах GA10x
GA10x содержит в себе новые тензорные ядра NVIDIA третьего поколения, отличающиеся поддержкой новых типов данных, улучшенной производительностью, эффективностью и гибкостью программирования. Новая функция разреженности позволяет удвоить производительность тензорных ядер по сравнению с Turing предыдущего поколения. Быстрее происходит и выполнение функций ИИ, таких как NVIDIA DLSS для сверхразрешения ИИ (теперь и с поддержкой 8K), NVIDIA Broadcast для обработки голоса и видео и NVIDIA Canvas для рисования.
Тензорные ядра — это специализированные исполнительные блоки, разработанные для выполнения тензорных/матричных операций — основной вычислительной функции в глубоком обучении. Они необходимы для улучшения качества графики с помощью DLSS (Deep Learning Super Sampling), шумоподавления на основе ИИ, удаления фонового шума внутри игровых голосовых чатов с помощью RTX Voice и еще множества применений.
Внедрение тензорных ядер в игровые графические процессоры GeForce впервые позволило реализовать глубокое обучение в реальном времени в игровых приложениях. Конструкция тензорного ядра третьего поколения в графических процессорах GA10x дополнительно увеличивает чистую производительность и задействует новые режимы вычислительной точности, такие как TF32 и BFloat16. Это играет большую роль для основанных на ИИ приложений нейронных служб NVIDIA NGX, направленных на улучшение графики, рендеринга и другие функции.
Сравнение тензорных ядер Turing и Ampere
Тензорные ядра Ampere были реорганизованы в сравнении с Turing для повышения эффективности и снижения энергопотребления. Архитектура SM-ядер Ampere имеет меньшее количество тензорных ядер, но каждое из них оказывается более мощным.
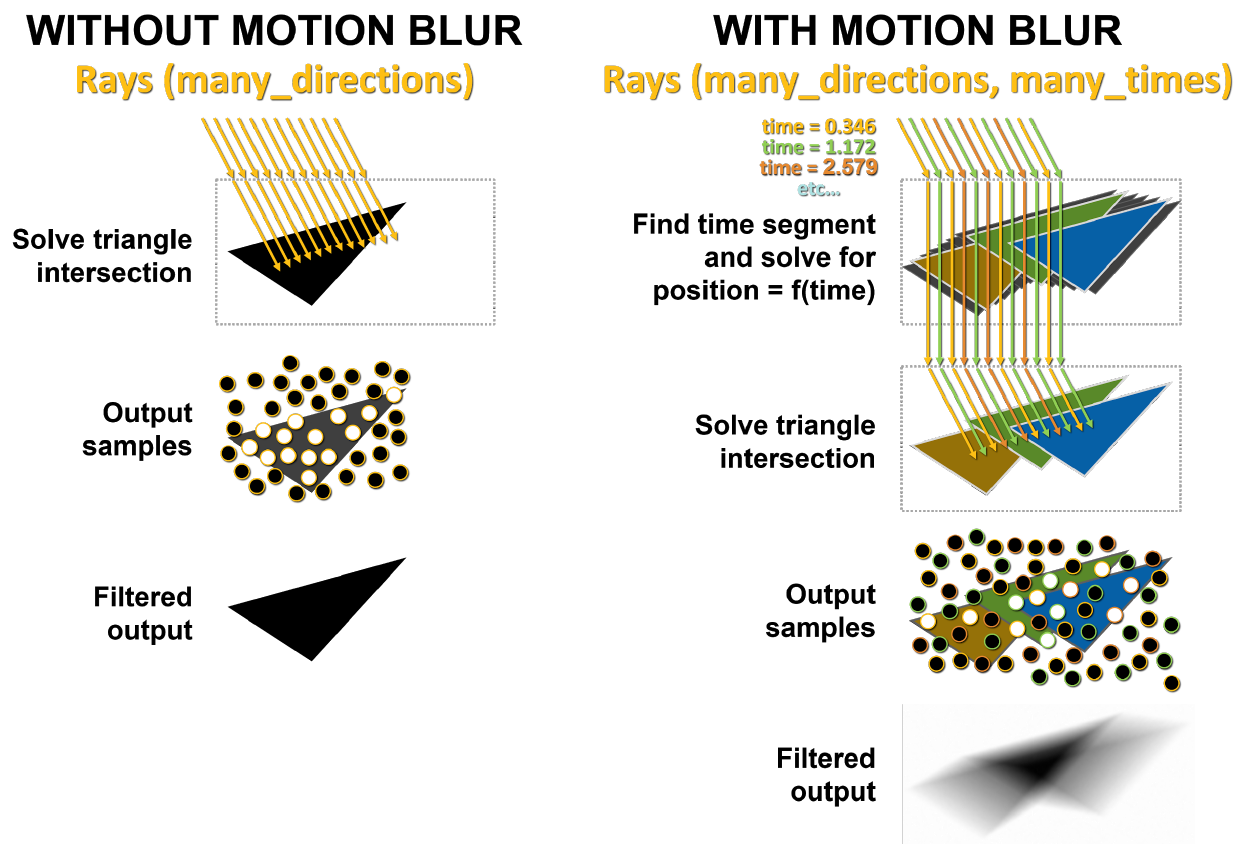
Рисунок 12. Тензорные ядра с архитектурой Turing и Ampere. GeForce RTX 3080 обеспечивает в 2,7 раза более высокую пиковую пропускную способность тензорного ядра в FP16-операциях по сравнению с GeForce RTX 2080 Super
Мелкозернистая структурированная разреженность
С графическим процессором A100 NVIDIA представила Fine-Grained Structured Sparsity — новый подход, способствующий удвоению вычислительной пропускной способности для глубоких нейронных сетей. Эта функция также поддерживается графическими процессорами GA10x и помогает ускорить некоторые операции вывода графики на основе ИИ.
Поскольку сети глубокого обучения могут адаптировать веса в процессе обучения на основе обратной связи, в целом структурные ограничения не влияют на точность обучаемых моделей.
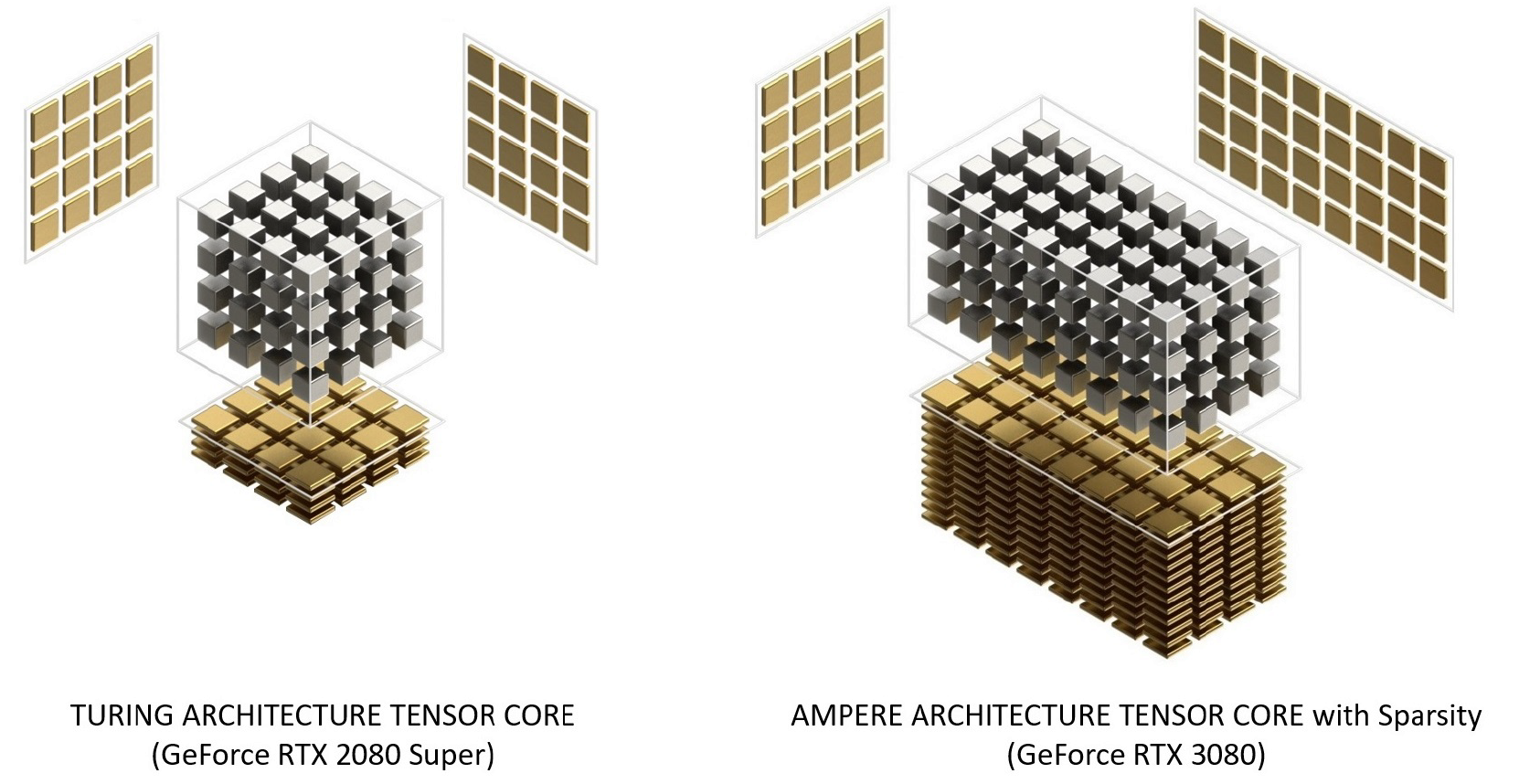
Рисунок 13. Мелкозернистая структурированная разреженность
NVIDIA разработала простой и универсальный алгоритм разреживания глубоких нейронных сетей с использованием структурированного шаблона разреженности 2:4. Сеть сначала обучается при помощи плотных весов, затем происходит мелкозернистая структурированная обрезка, после чего нулевые значения можно отбросить, а оставшаяся математика сжимается с целью повышения пропускной способности. Алгоритм не влияет на точность обученной сети для вывода, только ускоряет ее.
NVIDIA DLSS 8K
Рендеринг изображения с трассировкой лучей и высокой частотой кадров — чрезвычайно затратный с вычислительной точки зрения процесс. До появления NVIDIA Turing считалось, что его реализацию стоит ждать годы. Чтобы помочь с решением этой проблемы, NVIDIA создала суперсэмплинг при помощи глубокого обучения (DLSS).
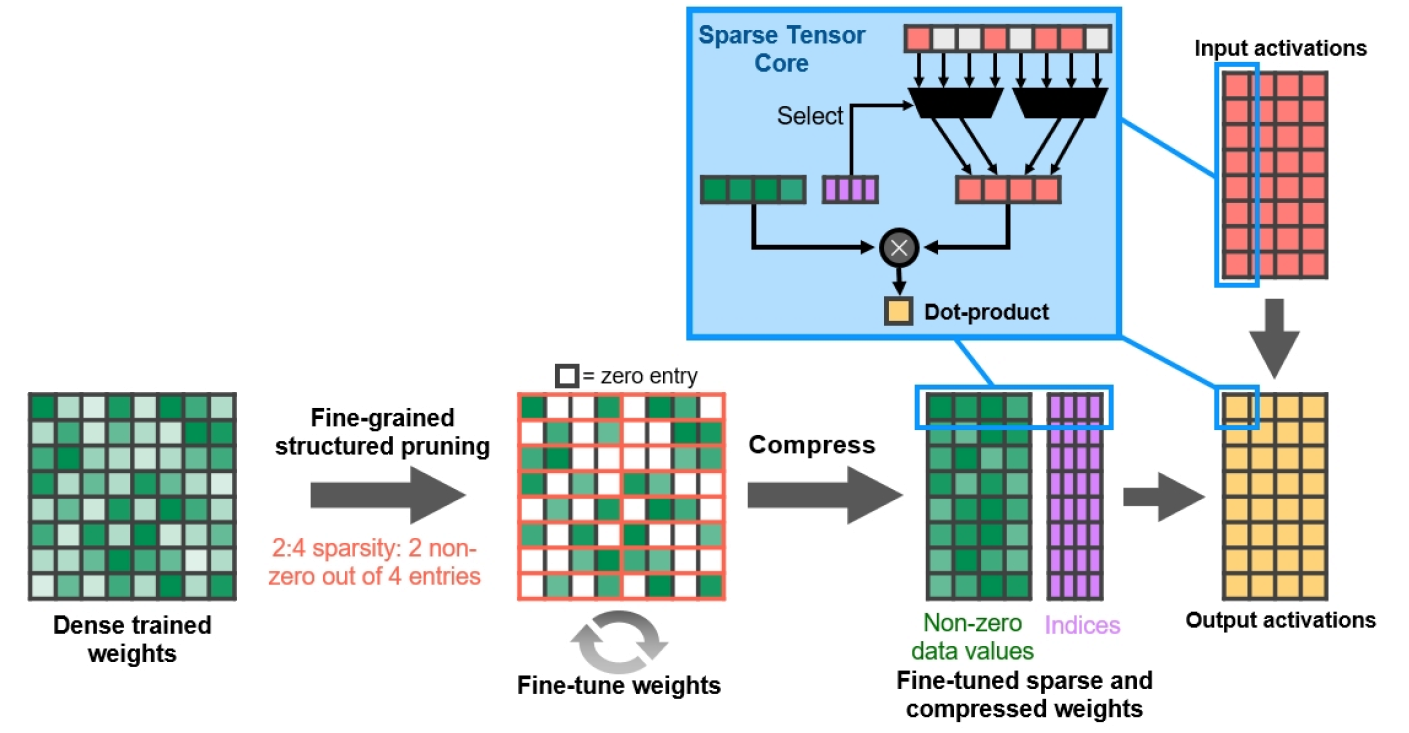
Рисунок 14. Watch Dogs: Legion с DLSS с разрешением 1080p, 4К и 8К. Обратите внимание на более четкий текст и детализацию, обеспечиваемую DLSS в 8K
DLSS стал только лучше в случае NVIDIA Ampere за счет использования тензорных ядер третьего поколения и девятикратного коэффициента масштабирования сверхразрешения, который впервые делает возможными запуск игры с трассировкой лучей в разрешении 8K с 60 fps.
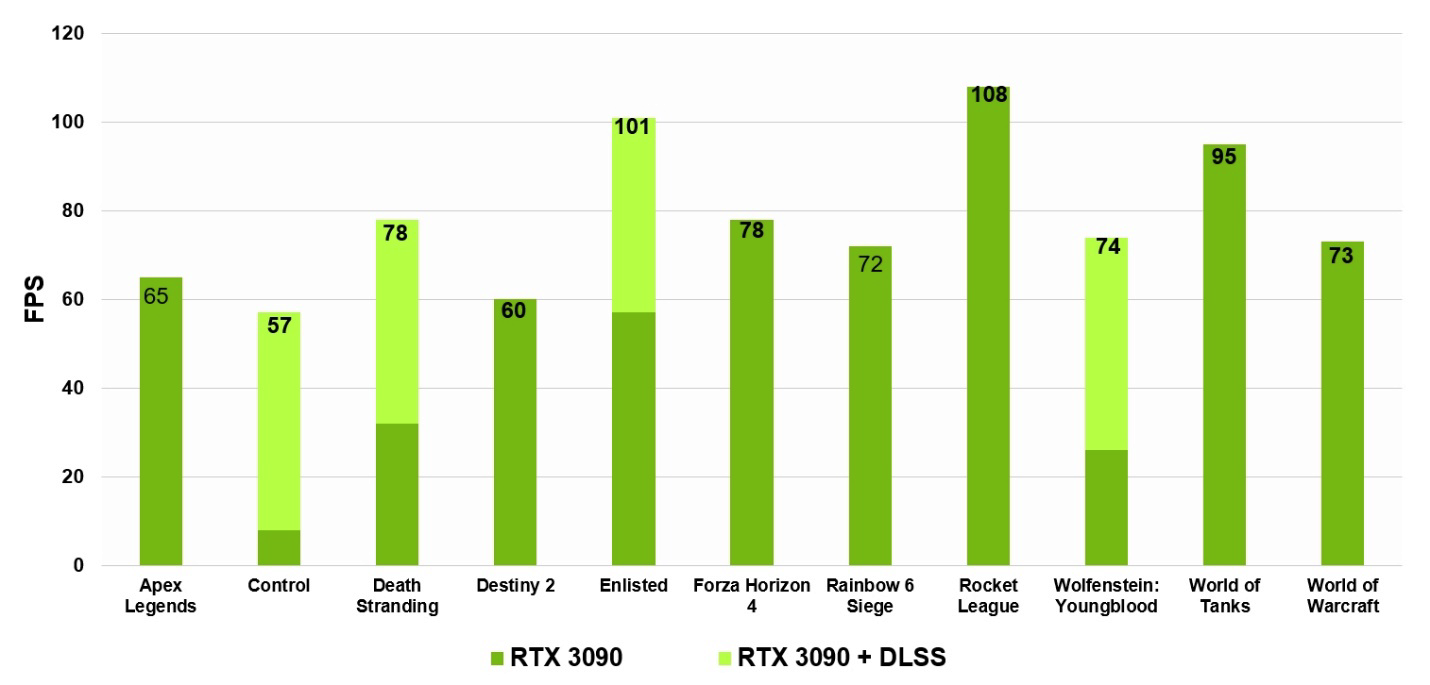
Рисунок 15. GeForce RTX 3090 может обеспечить частоту кадров 60 fps во многих играх с разрешением 8K с DLSS и без него. В перечисленных играх использовались высокие настройки графики и включена трассировка лучей, где это возможно. Протестировано на процессоре Core i9–10900K
Память GDDR6X
Современные компьютерные игры и творческие приложения требуют значительно большей пропускной способности памяти для обработки все более сложной геометрии сцены, более детальных текстур, трассировки лучей, операций вывода ИИ и, конечно же, затенения и суперсэмплинга.
GDDR6X — первая графическая память, пропускная способность которой превышает 900 ГБ/с. Чтобы этого достичь, была задействована инновационная технология передачи сигналов и четырехуровневая амплитудно-импульсная модуляция (PAM4), в совокупности полностью меняющие способ перемещения данных в памяти. При помощи алгоритма PAM4 GDDR6X передает большее количество данных с гораздо более высокой скоростью, перемещая по два бита данных за раз, что удваивает скорость передачи данных ввода/вывода по сравнению с предыдущей схемой PAM2/NRZ.
В настоящее время GDDR6X поддерживает скорость 19,5 Гбит/с для GeForce RTX 3090 и 19 Гбит/с для GeForce RTX 3080. Благодаря этому GeForce RTX 3080 обеспечивает в 1,5 раза большую производительность в операциях с памятью, чем предшественник — RTX 2080 Super.
На рисунке 16 показано сравнение структуры GDDR6 (слева) и GDDR6X (справа). GDDR6X передает те же данные на частоте вдвое меньшей, чем у GDDR6. Или, в качестве альтернативы, GDDR6X может удвоить эффективную полосу пропускания, сохранив той же частоту.
Рисунок 16. GDDR6X с использованием сигналов PAM4 показывает большую производительность и эффективность, чем GDDR6
Для решения проблем с отношением сигнал/шум (SNR), возникающих при передаче сигналов PAM4, была разработана новая схема кодирования MTA (максимальное предотвращение перехода). MTA предотвращает переход высокоскоростных сигналов с самого высокого уровня на самый низкий и наоборот.

Рисунок 17. Новое кодирование в GDDR6X
Поддерживая скорость передачи данных до 19,5 Гбит/с на чипах GA10x, GDDR6X обеспечивает пиковую пропускную способность памяти до 936 ГБ/с, что на 52% больше по сравнению с графическим процессором TU102, используемым в GeForce RTX 2080 Ti. GDDR6X имеет самый большой скачок пропускной способности за 10 лет после графических процессоров серии GeForce 200.
RTX IO
Современные игры содержат в себе огромные миры. С развитием таких технологий, как фотограмметрия, они все лучше имитируют реальность и, как следствие, содержатся в файлах с все большим объемом. Крупнейшие игровые проекты занимают более 200 ГБ, что в 3 раза больше, чем четыре года назад, и со временем их это число будет только расти.
Геймеры все чаще обращаются к твердотельным накопителям, чтобы сократить время загрузки игр: в то время, как жесткие диски ограничены пропускной способностью 50–100 МБ/с, новейшие твердотельные накопители M.2 PCIe Gen4 считывают данные на скорости до 7 ГБ/с.

Рисунок 18. Игры, ограниченные традиционными системами ввода-вывода
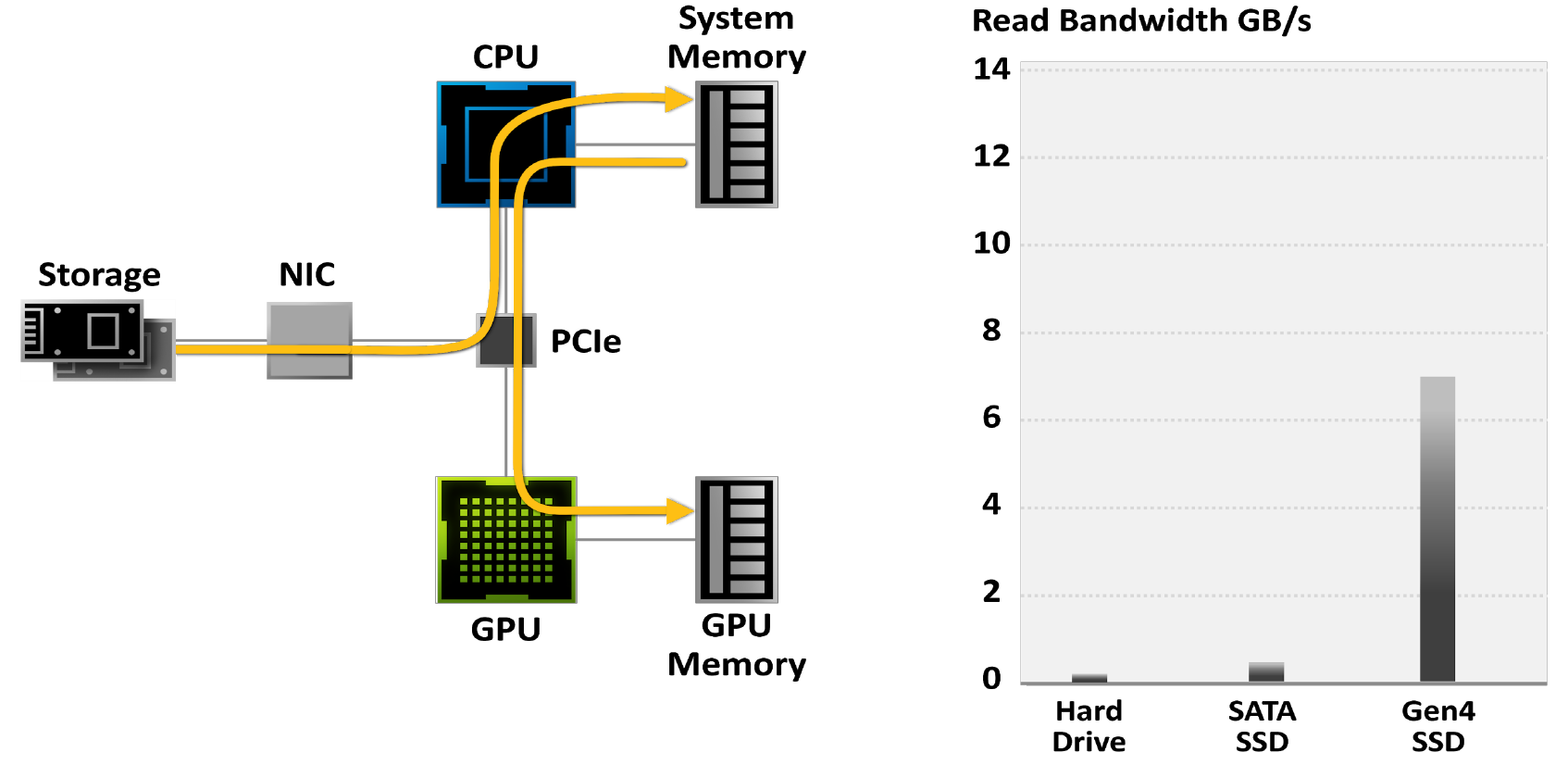
Рисунок 19. При использовании традиционной модели хранения распаковка игры может занять все 24 ядра процессора. Современные игровые движки превзошли возможности традиционных API-хранилищ. Вот почему необходимо новое поколение архитектуры ввода-вывода. Здесь серые полосы обозначают скорость передачи данных, черно-синие блоки — необходимые на это ядра ЦП.
NVIDIA RTX IO — это набор технологий, обеспечивающих быструю загрузку и распаковку ресурсов на базе ГП и повышающих производительность ввода-вывода до 100 раз по сравнению с жесткими дисками и традиционными API-хранилищами.
NVIDIA RTX IO работает в связке Microsoft DirectStorage API — хранилищем следующего поколения, разработанным специально для современных игровых ПК с NVMe SSD. NVIDIA RTX IO обеспечивает декомпрессию без потерь, позволяя считывать данные через DirectStorage в сжатом виде и доставлять их на графический процессор. Это снимает нагрузку с ЦП, перемещая данные из хранилища в графический процессор в более эффективной сжатой форме и улучшая производительность ввода-вывода в два раза.
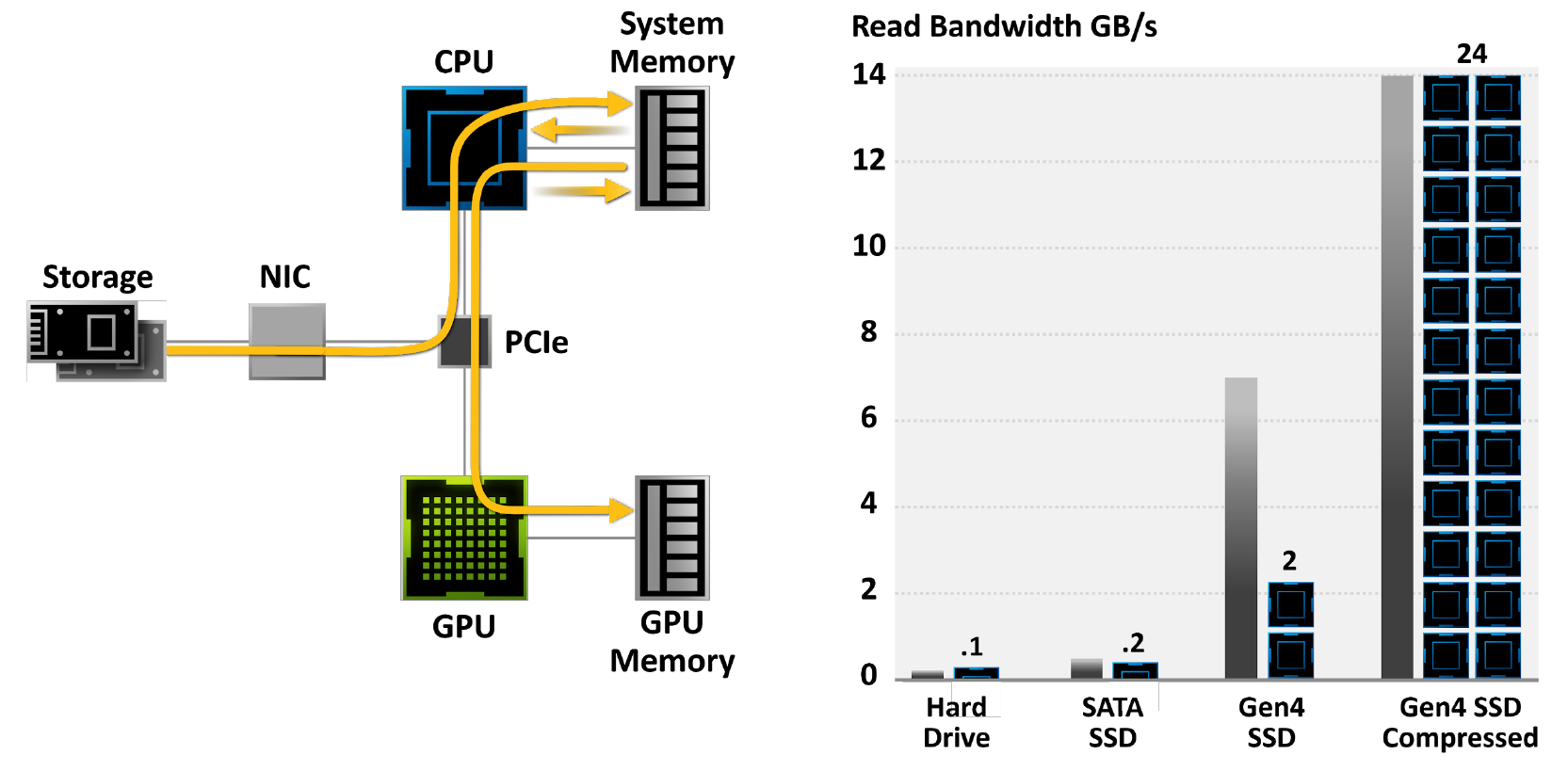
Рисунок 20. RTX IO обеспечивает в 100 раз большую пропускную способность и 20-кратное снижение загрузки ЦП. Серые и зеленые полосы обозначают скорость передачи данных, черно-синие блоки — необходимые для этого ядра ЦП.
Дисплей и видеодвижок
DisplayPort 1.4a с DSC 1.2a
Марш в сторону все более высоких разрешений с более высокой частотой обновления кадров продолжается, и графические процессоры на архитектуре NVIDIA Ampere стараются оставаться в числе передовых компаний, готовых обеспечить и то, и другое. Геймеры теперь могут играть на дисплеях с разрешением 4K (3820×2160) с частотой 120 Гц и в 8K (7680×4320) с частотой 60 Гц — с четырехкратным увеличением числа пикселей по сравнению с 4K.
Движок архитектуры Ampere разработан для поддержки многих новых технологий, включенных в самые быстрые на сегодняшний день интерфейсы отображения данных. Сюда входит и DisplayPort 1.4a, обеспечивающий разрешение 8K при 60 Гц с технологией сжатия без визуальных потерь VESA Display Stream Compression (DSC) 1.2a. К новым видеокартам с архитектурой Ampere можно подключить по два дисплеями с 8K и частотой 60 Гц — для этого понадобится всего лишь один кабель на дисплей.
HDMI 2.1 с DSC 1.2a
В архитектуре NVIDIA Ampere впервые для дискретных графических процессоров добавлена поддержка HDMI 2.1 — новейшего обновления спецификации HDMI. В HDMI максимальная пропускная способность увеличена до 48 Гбит/с, что также позволяет использовать динамические форматы HDR. Для поддержки 8K при 60 Гц с HDR необходимо сжатие DSC 1.2a или пиксельный формат 4:2:0.
NVDEC пятого поколения — декодирование видео с аппаратным ускорением
Графические процессоры NVIDIA содержат аппаратный декодер пятого поколения Hardware-Accelerated Video Decoding (NVDEC), обеспечивающий полностью аппаратное декодирование видео для множества популярных кодеков.
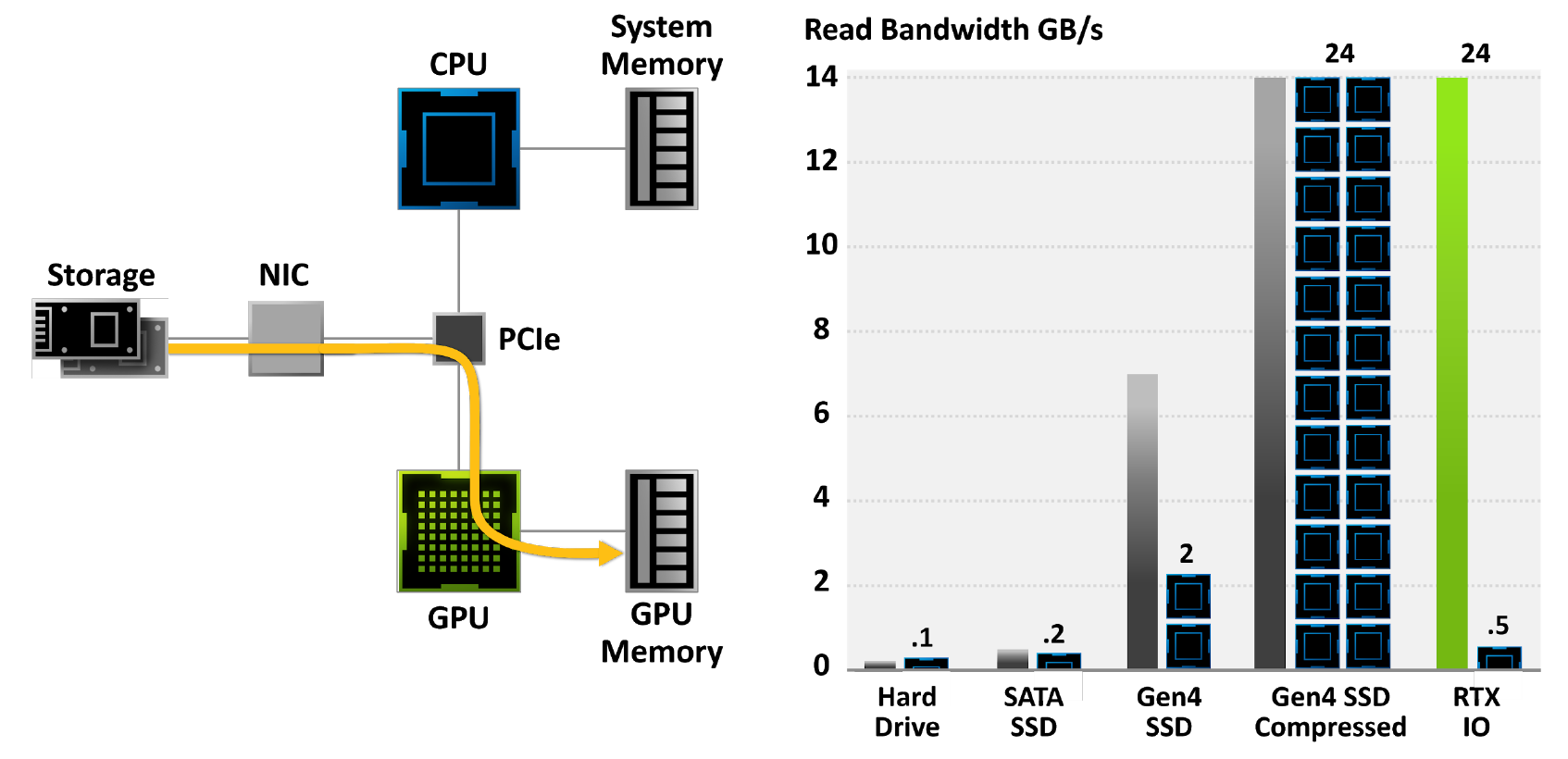
Рисунок 21. Форматы кодирования и декодирования видео, поддерживаемые графическими процессорами GA10x
Декодер NVIDIA пятого поколения в GA10x поддерживает декодирование с аппаратным ускорением следующих видеокодеков на платформах Windows и Linux: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9, и AV1.
NVIDIA — первый производитель графических процессоров, обеспечивающий аппаратную поддержку декодирования AV1.
Аппаратное декодирование AV1
Хотя AV1 очень эффективен при сжатии видео, его декодирование требует значительных вычислительных ресурсов. Современные программные декодеры вызывают высокую загрузку ЦП и затрудняют воспроизведение видео в сверхвысоком разрешении. В тестах NVIDIA процессор Intel i9 9900K в среднем воспроизводил на YouTube 28 кадров в секунду в 8K60 HDR, загрузка процессора при этом была выше 85%. Графические процессоры GA10x могут воспроизводить AV1, передавая декодирование на NVDEC, который способен воспроизводить до 8K60 HDR-контента с очень низкой загрузкой ЦП (~ 4% на том же ЦП, что и в предыдущем тесте).
NVENC седьмого поколения — кодирование видео с аппаратным ускорением
Кодирование видео может быть сложной вычислительной задачей, но, если выгрузить его в NVENC, графический движок и ЦП освободятся для других операций. Например, при потоковой передачи игр на Twitch.tv с использованием Open Broadcaster Software (OBS), выгрузка кодирования видео в NVENC позволит выделить графический движок графического процессора для рендеринга игры, а ЦП — для других задач пользователя.
NVENC позволяет:
- кодирование и потоковую передачу игр и приложений с высоким качеством и сверхнизкой задержкой без использования ЦП;
- кодирование с очень высоким качеством для архивирования, потоковой передачи OTT, веб-видео;
- кодирование со сверхнизким энергопотреблением на поток (Вт/поток).
При общих настройках потоковой передачи Twitch и YouTube аппаратное кодирование на основе NVENC в графических процессорах GA10x превосходит качество кодирования программных кодировщиков x264 с использованием предустановки Fast и находится на одном уровне с x264 Medium — предустановкой, которая обычно требует мощности двух компьютеров. Это резко снимает загрузку ЦП. Кодирование 4K — слишком большая рабочая нагрузка для типичной конфигурации ЦП, но кодировщик GA10x NVENC обеспечивает бесшовное кодирование с высоким разрешением до 4K в H.264 и даже 8K в HEVC.
Заключение
С каждой новой процессорной архитектурой NVIDIA стремится обеспечить революционную производительность для следующего поколения, одновременно вводя новые функции, улучшающие качество изображения. Turing был первым графическим процессором, который представил трассировку лучей с аппаратным ускорением — функцию, некогда считавшуюся святым Граалем компьютерной графики. Сегодня невероятно реалистичные и физически точные эффекты трассировки лучей добавляются во многие новые компьютерные игры класса AAA, а трассировка лучей с ускорением на ГП считается обязательной функцией для большинства компьютерных геймеров. Новые графические процессоры с архитектурой NVIDIA GA10x Ampere обеспечивают необходимые функции и производительность, чтобы наслаждаться этими новыми играми с трассировкой лучей и частотой кадров до 2 раз выше, чем можно достичь сейчас. Еще одна особенность Turing — усовершенствованная обработка ИИ с ускорением на ЦП, улучшающая шумоподавление, рендеринг и другие графические приложения, — тоже выходит на новый уровень благодаря архитектуре Ampere.
Напоследок — ссылка на полный документ.
