[Перевод] AlphaStar — новая система искусственного интеллекта для StarCraft II от DeepMind (полный перевод)
Игры десятилетиями использовались как один из главных способов тестирования и оценки успешности систем искусственного интеллекта. По мере того как росли возможности, исследователи искали игры с постоянно возрастающей сложностью, которые бы отражали различные элементы мышления, необходимые для решения научных или прикладных проблем реального мира. В последние годы StarCraft считается одной из самых многогранных и сложных стратегий реального времени и одной из самых популярных на сцене киберспорта за всю историю, а сейчас StarCraft стал еще и главным вызовом для исследований ИИ.
AlphaStar — первая система искусственного интеллекта, способная победить лучших профессиональных игроков. В серии матчей, которые состоялись 19 декабря, AlphaStar одержала уверенную победу над Grzegorz Komincz (MaNa) из команды Liquid, одного из сильнейших игроков в мире, со счетом 5:0. Перед этим также был сыгран успешный показательный матч против его товарища по команде Dario Wünsch (TLO). Матчи прошли по всем профессиональным правилам на специальной турнирной карте и без каких-либо ограничений.
Несмотря на значительные успехи в таких играх как Atari, Mario, Quake III Arena и Dota 2, техники ИИ безуспешно боролись со сложностью StarCraft’а. Лучшие результаты достигались путем ручного конструирования основных элементов системы, наложением разных ограничений на правила игры, предоставлением системе сверхчеловеческих способностей или игрой на упрощенных картах. Но даже эти нюансы не дали возможности приблизиться к уровню профессиональных игроков. В разрез этого, AlphaStar играет в полноценную игру, используя глубокие нейронные сети, которые обучаются на основе необработанных игровых данных, с помощью методов обучения с учителем и обучения с подкреплением.
Главный вызов
StarCraft II — это выдуманная фантастическая вселенная с богатым, многоуровневым геймплеем. Наряду с оригинальным изданием, это самая большая и успешная игра всех времен, в которую сражаются в турнирах уже больше 20 лет.

Существует множество способов игры, но самый распространенный в киберспорте — это турниры «один-на-один», состоящие из 5 матчей. Для начала игрок должен выбрать одну из трех рас — зергов, протоссов или терранов, каждая из которых имеет свои особенности и возможности. Поэтому профессиональные игроки чаще всего специализируются на одной расе. Каждый игрок начинает с нескольких рабочих юнитов, которые добывают ресурсы для постройки зданий, других юнитов или развития технологий. Это позволяет игроку захватывать другие ресурсы, строить все более изощренные базы и развивать новые способности, чтобы перехитрить оппонента. Для победы игрок должен очень изящно балансировать картину общей экономики, называемую «макро», и низкоуровневый контроль отдельных юнитов, называемый «микро».
Необходимость балансирования краткосрочных и долгосрочных целей и адаптация к непредвиденным ситуациям ставит большой вызов перед системами, которые на поверку часто оказываются совершенно негибкими. Решение этой проблемы требует прорыва в нескольких областях ИИ:
Теория игр: StarCraft — это игра, где как в «Камень, ножницы, бумага» нет единой победной стратегии. Поэтому в процесс обучения ИИ должен постоянно исследовать и расширять горизонты своих стратегических знаний.
Неполная информация: В отличие от шахмат или го, где игроки видят всё происходящее, в StarCraft’е важная информация часто скрыта и должна активно добываться путем разведки.
Долгосрочное планирование: Как и в реальных задачах, причинно-следственные связи могут не быть мгновенными. Игра также может длиться часа и больше, поэтому действия, совершенные в начале игры, могут не иметь в том числе абсолютно никакого значения в долгосрочной перспективе.
Реальное время: В разрез с традиционными настольными играми, где участники делают ходы по очереди, в StarCraft’е игроки совершают действия непрерывно, наряду с ходом времени.
Огромное пространство действий: Сотни различных юнитов и зданий должны контролироваться одновременно, в реальном времени, что дает поистине огромное комбинаторное пространство возможностей. В дополнение к этому, многие действия являются иерархическими и могут изменяться и дополняться по ходу. Наша параметризация игры дает в среднем примерно от 10 до 26 действий в единицу времени.
Ввиду этих задач, StarCraft превратился в большой вызов для исследователей ИИ. Текущие соревнования StarCraft и StarCraft II берут свое начало с момента запуска BroodWar API в 2009 году. Среди них — AIIDE StarCraft AI Competition, CIG StarCraft Competition, Student StarCraft AI Tournament и Starcraft II AI Ladder.
Примечание: В 2017 году PatientZero публиковал на Хабре отличный перевод «История соревнований ИИ по Starcraft».
Чтобы помочь сообществу исследовать эти проблемы в дальнейшем, мы, работая совместно с компанией Blizzard в 2016 и 2017 году, опубликовали набор инструментов PySC2, включающий самый большой из когда-либо изданных массив анонимизированных реплеев. Опираясь на эту работу, мы объединили наши инженерные и алгоритмические достижения, чтобы создать AlphaStar.

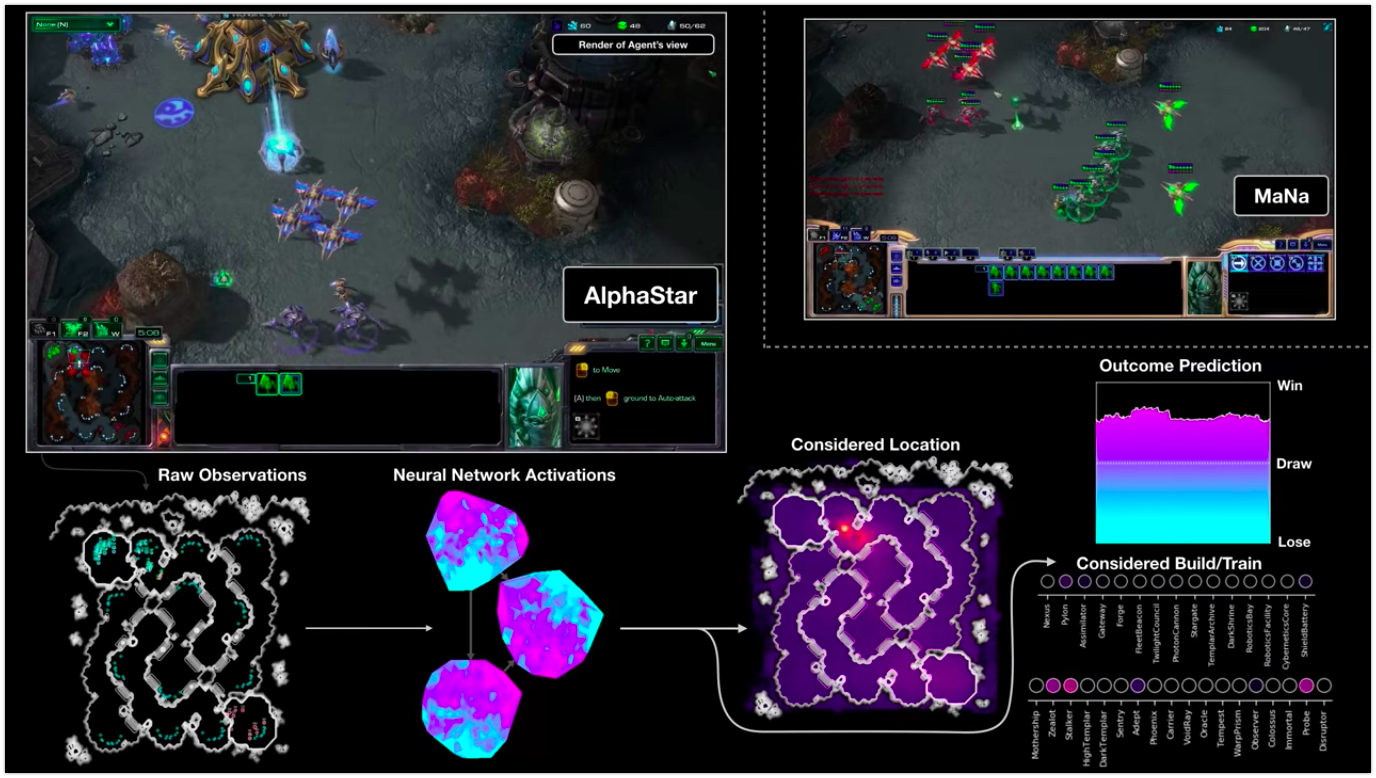
Визуализация AlphaStar во время поединка против MaNa, демонстрирует игру от лица агента — исходные наблюдаемые данные, активность нейронной сети, некоторые из предполагаемых действий и требуемых координат, а также предполагаемый исход матча. Также показан вид игрока MaNa, но он, разумеется, недоступен для агента.
Как происходит обучение
Поведение AlphaStar генерируется нейронной сетью глубокого обучения, которая получает через интерфейс сырые данные (список юнитов и их свойств) и дает на выходе последовательность инструкций, которые являются действиями в игре. Если говорить точнее, архитектура нейронной сети применяет подход «transformer torso to the units, combined with a deep LSTM core, an auto-regressive policy head with a pointer network, and a centralised value baseline» (для точности терминов оставлено без перевода). Мы верим, что эти модели в дальнейшем помогут справиться с другими важными задачами машинного обучения, включающие моделирование долгосрочных последовательностей и большие выходные пространства, такие как перевод, моделирование языков и визуальные представления.
AlphaStar также использует новый мультиагентный алгоритм обучения. Эта нейронная сеть была изначально обучена с помощью метода обучения с учителем на основе анонимизированных реплеев, которые доступны благодаря компании Blizzard. Это позволило AlphaStar изучать и имитировать основные микро- и макро-стратегии, используемые игроками в турнирах. Данный агент победил встроенного ИИ уровня «Elite», что эквивалентно уровню игрока золотой лиги, в 95% тестовых игр.
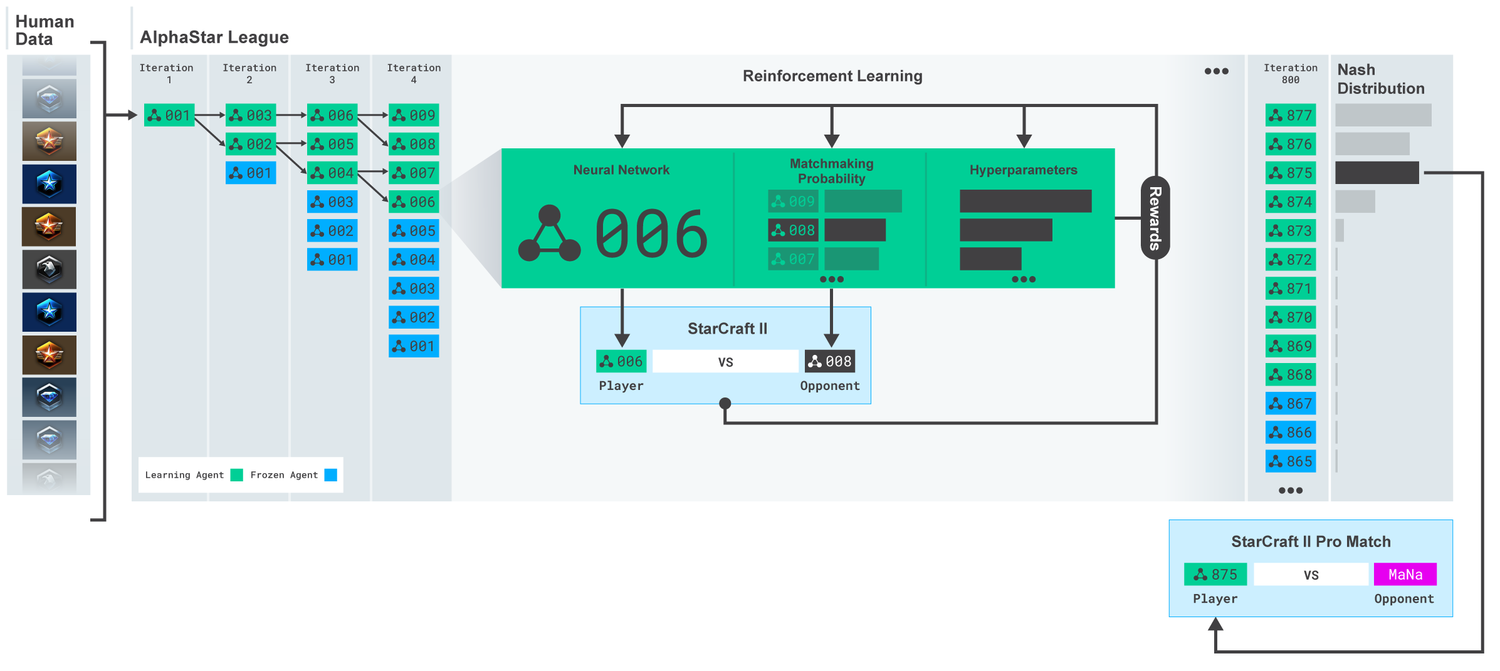
Лига AlphaStar. Агенты изначально обученные на основе реплеев человеческих матчей, а затем на основе соревновательных матчей между собой. На каждой итерации, новые соперники разветвляются, а первоначальные замораживаются. Вероятности встречи с другими оппонентами и гиперпараметры определяют цели обучения для каждого агента, что повышает сложность, которая сохраняет разнообразие. Параметры агента обновляются методом обучения с подкреплением, основываясь на исходе игры против соперников. Конечный агент отбирается (без замены) на основе распределения Нэша.
Эти результаты затем используются, чтобы начать мультиагентный процесс обучения с подкреплением. Для этого была создана лига, где агенты-оппоненты играют против друг друга, подобно тому как люди получают опыт, играя в турниры. Новые соперники добавлялись путем в лигу, путем дублирования текущих агентов. Такая новая форма обучения, заимствуя некоторые идеи из метода обучения с подкреплением с элементами генетических (population-based) алгоритмов, позволяет создать непрерывный процесс исследования огромного стратегического пространства геймплея StarCraft’а, и быть уверенным, что агенты в силах противостоять наиболее сильным стратегиям, не забывая при этом старые.

Оценка MMR (Match Making Rating) — примерный показатель мастерства игрока. Для соперников в лиге AlphaStar в ходе обучения, в сравнении с онлайн-лигами Blizzard’а.
По мере развития лиги и создания новых агентов, появлялись контр-стратегии, которые были способны победить предыдущие. В то время как некоторые агенты лишь усовершенствовали стратегии, которые встречались ранее, другие агенты создавали абсолютно новые, включающие в себя новые необычные билд-ордеры, состав юнитов и макро-менеджмент. К примеру, на ранней стадии процветали «чизы» — быстрые раши с помощью фотонных (Photon Cannons) пушек или темных тамплиеров (Dark Templars). Но по мере того как процесс обучения продвигался вперед, эти рискованные стратегии были отброшены, уступив место другим. Например, производство избыточного количества рабочих для получения дополнительного притока ресурсов или пожертвование двух оракулов (Oracles) для удара по рабочим противника и подрыва его экономики. Этот процесс подобен тому как обычные игроки открывали новые стратегии и побеждали старые популярные подходы, в ходе многих лет с момента выпуска StarCraft’а.
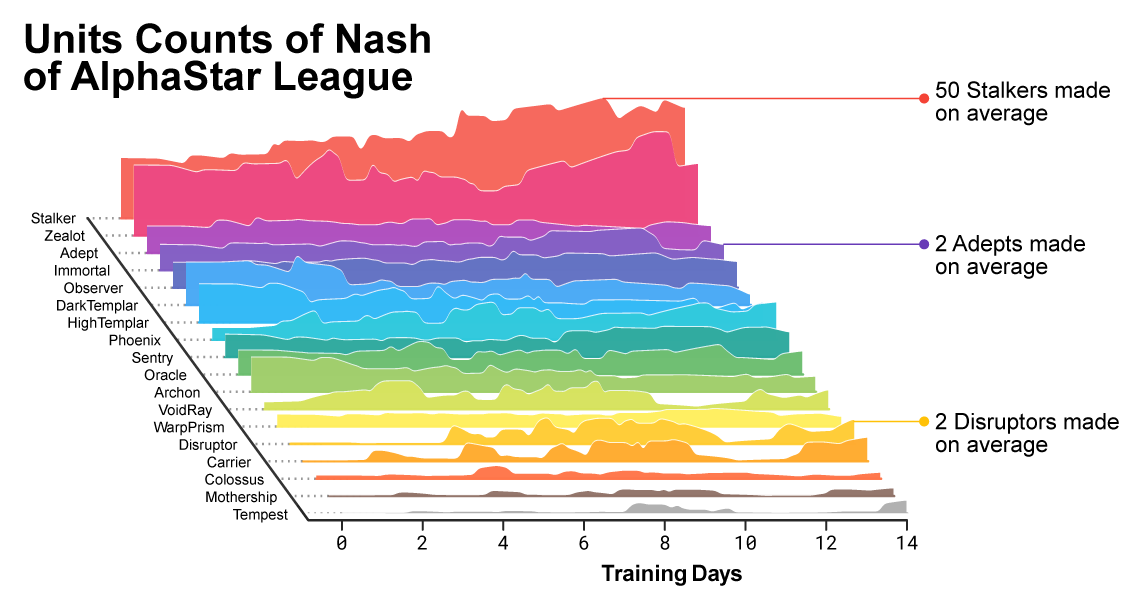
По мере того как обучение продвигалось, было заметно как изменяется состав юнитов, которым пользуются агенты.
Для обеспечения разнообразия, каждый агент наделялся собственной целью обучения. К примеру, каких оппонентов должен победить этот агент, или любая другая внутренняя мотивация, определяющая игру агента. Определенный агент может иметь цель победить одного конкретного противника, а другой — целую выборку оппонентов, но сделать это только конкретными юнитами. Эти цели менялись по ходу процесса обучения.

Интерактивная визуализация (интерактивные функции доступны в оригинале статьи), которая показывает соперников с лиге AlphaStar. Агент, который играл против TLO и MaNa отдельно отмечен.
Коэффициенты (веса) нейронной сети каждого агента обновлялись с помощью обучения с подкреплением на основе игр с оппонентами, чтобы оптимизировать их конкретные цели обучения. Правило обновления веса — это новый эффективный алгоритм обучения «off-policy actor-critic reinforcement learning algorithm with experience replay, self-imitation learning and policy distillation» (для точности терминов оставлено без перевода).

Изображение показывает как один агент (черная точка), который был выбран в итоге для игры против MaNa, развивал свою стратегию в сравнении с оппонентами (цветные точки) в процессе обучения. Каждая точка представляет соперника в лиге. Положение точки показывает стратегию, а размер — частоту, с которой она выбирается в качестве соперника для агента MaNa в процессе обучения.
Для обучения AlphaStar мы создали масштабируемую распределенную систему на основе Google TPU 3, которая обеспечивает процесс параллельного обучения целой популяции агентов с тысячами запущенных копий StarCraft II. Лига AlphaStar проработала 14 дней, используя 16 TPU для каждого агента. В ходе обучения каждый агент испытал до 200 лет опыта игры в StarCraft в реальном времени. Финальная версия агента AlphaStar содержит компоненты распределения Нэша всей лиги. Другими словами, самую эффективную смесь стратегий, которые были обнаружены в ходе игр. И эта конфигурация может быть запущена на одном стандартном настольном GPU. Полное техническое описание сейчас готовится к публикации в рецензируемом научном журнале.
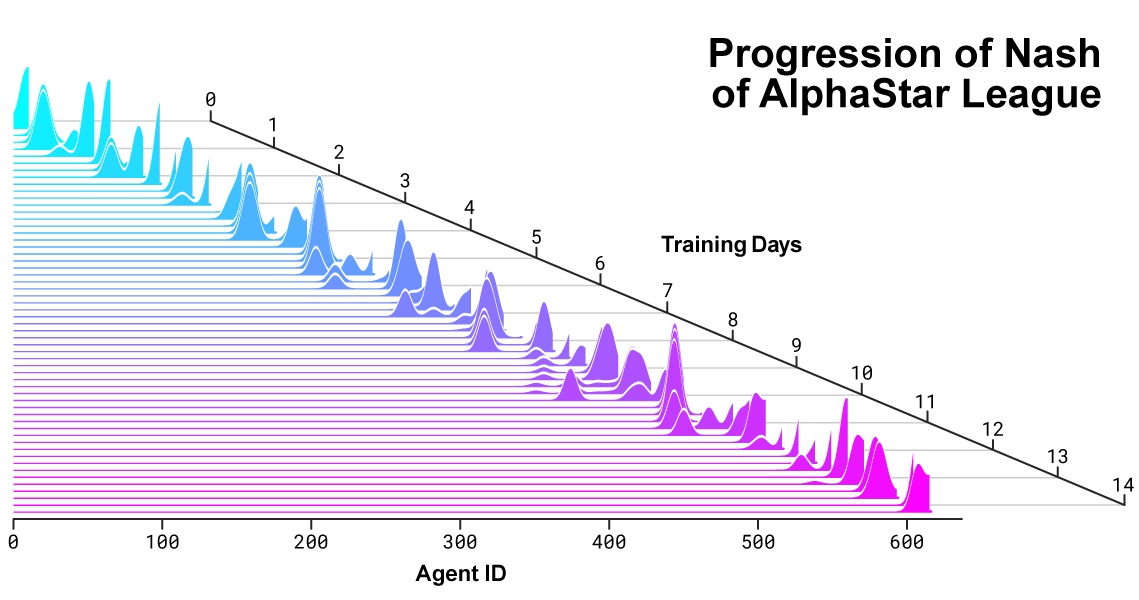
Распределение Нэша между соперниками в ходе развития лиги и создания новых оппонентов. Распределение Нэша, which is the least exploitable set of complementary competitors, высоко оценивает новых игроков, демонстрируя таким образом постоянный прогресс по сравнению со всеми прошлыми конкурентами.
Как AlphaStar действует и видит игру
Профессиональные игроки, как TLO или MaNa, способны совершать сотни действий в минуту (APM). Но это намного меньше, чем у большинства существующих ботов, которые независимо контролируют каждого юнита и генерируют тысячи, если не десятки тысяч действий.
В наших играх против TLO и MaNa, AlphaStar держал APM в среднем на уровне 280, что намного меньше чем у профессиональных игроков, хотя его действия при этом могут быть более точными. Такой низкий APM объясняется в частности тем, что AlphaStar начинал учится на основе реплеев обычных игроков и пытался подражать манере человеческой игры. В дополнение к этому, AlphaStar реагирует с задержкой между наблюдением и действием в среднем около 350 мс.

Распределение APM AlphaStar в матчах против MaNa и TLO, и общая задержка между наблюдением и действием.
В ходе матчей против TLO и MaNa, AlphaStar взаимодействовал с игровым движком StarCraft’а через базовый (raw) интерфейс, то есть он мог видеть атрибуты своих и видимых вражеских юнитов на карте напрямую, без необходимости двигать камеру — эффективно играть с уменьшенным видом всей территории. В разрез с этим, живые люди должны явно управлять «экономикой внимания», чтобы постоянно решать, где сфокусировать камеру. Тем не менее, анализ игр AlphaStar показывает, что он неявно управляет фокусом внимания. В среднем агент переключает свой контекст внимания примерно 30 раз в минуту, подобно MaNa и TLO.
В дополнение мы разработали вторую версию AlphaStar. Как игроки-люди, эта версия AlphaStar явно выбирает, когда и куда двигать камеру. В этом варианте его восприятие ограничено информацией на экране, а действия также допустимы только на видимой области экрана.

Производительность AlphaStar при использовании базового интерфейса и интерфейса с камерой. График показывает, что новый агент, работающий с камерой, быстро достигает сопоставимой производительности агента, использующего базовый интерфейс.
Мы обучили двух новых агентов, одного с использованием базового интерфейса и одного, который должен был научиться управлять камерой, играя против лиги AlphaStar. Каждый агент в начале был обучен с учителем на основе человеческих матчей, с последующим обучением с подкреплением, описанным выше. Версия AlphaStar, использующая интерфейс с камерой, достигла почти таких же результатов, что и версия с базовым интерфейсом, превысив отметку в 7000 MMR на нашей внутренней таблице лидеров. В показательном матче, MaNa победил прототип AlphaStar, использующий камеру. Эту версию мы обучали только 7 дней. Мы надеемся, что сможем оценить полностью обученную версию с камерой в ближайшем будущем.
Эти результаты показывают, что успех AlphaStar в матчах против MaNa и TLO в первую очередь является следствием хорошего макро- и микро-менеджмента, а не просто большого клик-рейта, быстрой реакции или доступа к информации базового интерфейса.
Итоги игры AlphaStar против профессиональных игроков
StarCraft позволяет выбирать игрокам одну из трех рас — терранов, зергов или протоссов. Мы приняли решение, что AlphaStar на данный момент будет специализироваться на одной конкретной расе — протоссах, чтобы снизить время обучения и вариации в оценке результатов нашей внутренней лиги. Но следует отметить, что аналогичный процесс обучения может быть применен для любой расы. Наши агенты были обучены играть в StarCraft II версии 4.6.2 в режиме протосс против протосса, на карте CatalystLE. Для оценки производительности AlphaStar, мы изначально тестировали наших агентов в матчах против TLO — профессионального игрока за зергов и игрока за протоссов уровня «GrandMaster». AlphaStar выиграл матчи со счетом 5:0, используя широкий диапазон юнитов и билд-ордеров. «Я был удивлен, насколько сильным был агент», сказал он. «AlphaStar берет известные стратегии и переворачивает их с ног на голову. Агент показал такие стратегии, о которых я даже никогда не думал. И это показывает, что по-прежнему могут быть способы игры, которые до сих пор не изучены в полной мере».
После дополнительного недельного обучения, мы сыграли против MaNa, одного из самых сильных игроков StarCraft II в мире, и входящего в 10 сильнейших игроков за протоссов. AlphaStar и в этот раз победил со счетом 5:0, продемонстрировав сильные навыки микро-управления и макро-стратегии. «Я был поражен, увидев как AlphaStar использует самые передовые подходы и разные стратегии в каждой игре, показывая очень человеческий стиль игры, который я никак не ожидал увидеть», сказал он. «Я осознал, насколько сильной мой стиль игры зависит от использования ошибок, основанных на человеческих реакциях. И это ставит игру на совершенно новый уровень. Мы все восторженно ожидаем увидеть, что же будет дальше».
AlphaStar и другие сложные проблемы
Несмотря на то что StarCraft — это лишь игра, пусть даже и очень сложная, мы думаем, что техники, лежащие в основе AlphaStar, могут быть полезны в решении других задач. К примеру, такой тип архитектуры нейронной сети способен моделировать очень длинные последовательности вероятных действий, в играх зачастую длящихся до целого часа и содержащих десятки тысяч действий, основанных при этом на неполной информации. Каждый фрейм в StarCraft’е используется как один шаг ввода. При этом нейронная сеть каждый такой шаг предсказывает ожидаемую последовательность действий для всей оставшейся игры. Фундаментальная задача составления сложных прогнозов для очень длинных последовательностей данных встречается во многих задачах реального мира, таких как прогноз погоды, моделирование климата, понимание языка и др. Мы очень рады осознавать огромный потенциал, который может быть применен в этих областях, использую наработки которые мы получили в проекте AlphaStar.
Мы также думаем, что некоторые из наших методов обучения могут оказаться полезными в изучении безопасности и надежности ИИ. Одна из самых сложных проблем в области ИИ — это количество вариантов, при которых система может ошибаться. И профессиональные игроки в прошлом быстро находили способы обойти ИИ, оригинально используя его ошибки. Инновационный подход AlphaStar, основанный на обучении в лиге, находит такие подходы и делает общий процесс более надежным и защищенным от подобных ошибок. Мы рады, что потенциал такого подхода может помочь в улучшении безопасности и надежности ИИ-систем в целом. В особенности, в таких критичных областях, как энергетика, где крайне важно правильно реагировать с сложных ситуациях.
Достижение такого высокого уровня игры в StarCraft представляет собой большой прорыв в одной из самых сложных когда-либо созданных видеоигр. Мы верим, что эти достижения, наряду с успехами в других проектах, будь то AlphaZero или AlphaFold, представляют собой шаг вперед в осуществлении нашей миссии по созданию интеллектуальных систем, которые однажды помогут нам найти решения для самых сложных и фундаментальных научных вопросов.
11 реплеев всех матчей
Видео показательного матча против MaNa
Видео с визуализацией AlphaStar полного второго матча против MaNa
