[Перевод] Алгоритм FSDP: ускорение обучения ИИ-моделей и сокращение количества GPU
Прим. Wunder Fund: В статье описан относительно новый подход к ускорению обучения больших моделей. Сами мы его не применяем, но над скоростью обучения моделей работаем постоянно, и если вам интересна эта тема, будем рады с вами пообщаться)

Обучение крупномасштабных ИИ-моделей — это не так уж и просто. Помимо того, что для этого нужны серьёзные вычислительные мощности и ресурсы, задачи обучения очень больших моделей сопряжены с немалыми технологическими сложностями. Мы, в команде Facebook AI Research (FAIR), работаем над созданием инструментов и инфраструктурных решений, нацеленных на упрощение обучения больших моделей. Среди наших недавних проектов в этой области можно отметить модели с внутрислойным параллелизмом, модели с конвейерным параллелизмом, модели с шардингом состояния оптимизатора и данных, относящихся к вычислению градиента, архитектуру «смесь экспертов». Всё это — лишь часть нашей работы, направленной на то, чтобы сделать более эффективным обучение продвинутых ИИ-моделей для любого количества задач.
FSDP (Fully Sharded Data Parallel, параллелизм с полным шардингом данных) — это наш новейший инструмент. Он выполняет шардинг (распределение) параметров ИИ-модели между рабочими процессами (воркерами) с параллелизмом по данным, работающими на GPU. При этом он, что необязательно, способен передавать часть вычислений, связанных с обучением моделей, CPU. FSDP, как следует из названия, это — разновидность алгоритма обучения с параллелизмом по данным. Хотя параметры и распределены по различным GPU, вычисления для каждого микропакета данных по-прежнему остаются локальными для каждого из GPU-воркеров. Подобная концептуальная простота упрощает понимание FSDP. Это способствует тому, что наш алгоритм можно применять к более широкому диапазону задач (в сравнении с методами, где используется внутрислойный или конвейерный параллелизм). В сравнении же с методами, в которых используется шардинг состояния оптимизатора и данных, относящихся к вычислению градиента, FSDP распределяет параметры более однородно. Применение этого алгоритма способно улучшить производительность решений за счёт совмещения коммуникационных и вычислительных задач в процессе обучения моделей.
Теперь, благодаря FSDP, можно эффективнее обучать модели, размеры которых на порядки превосходят размеры моделей, с которыми работали раньше, используя при этом меньшее количество GPU. Алгоритм FSDP реализован в библиотеке FairScale. Он позволяет инженерам и разработчикам масштабировать и оптимизировать обучение их моделей с применение простых API. В Facebook FSDP уже интегрирован в некоторые из моделей, используемых для решения задач обработки естественного языка и компьютерного зрения. Мы протестировали его на этих моделях.
Высокие вычислительные затраты крупномасштабных задач по обучению ИИ-моделей
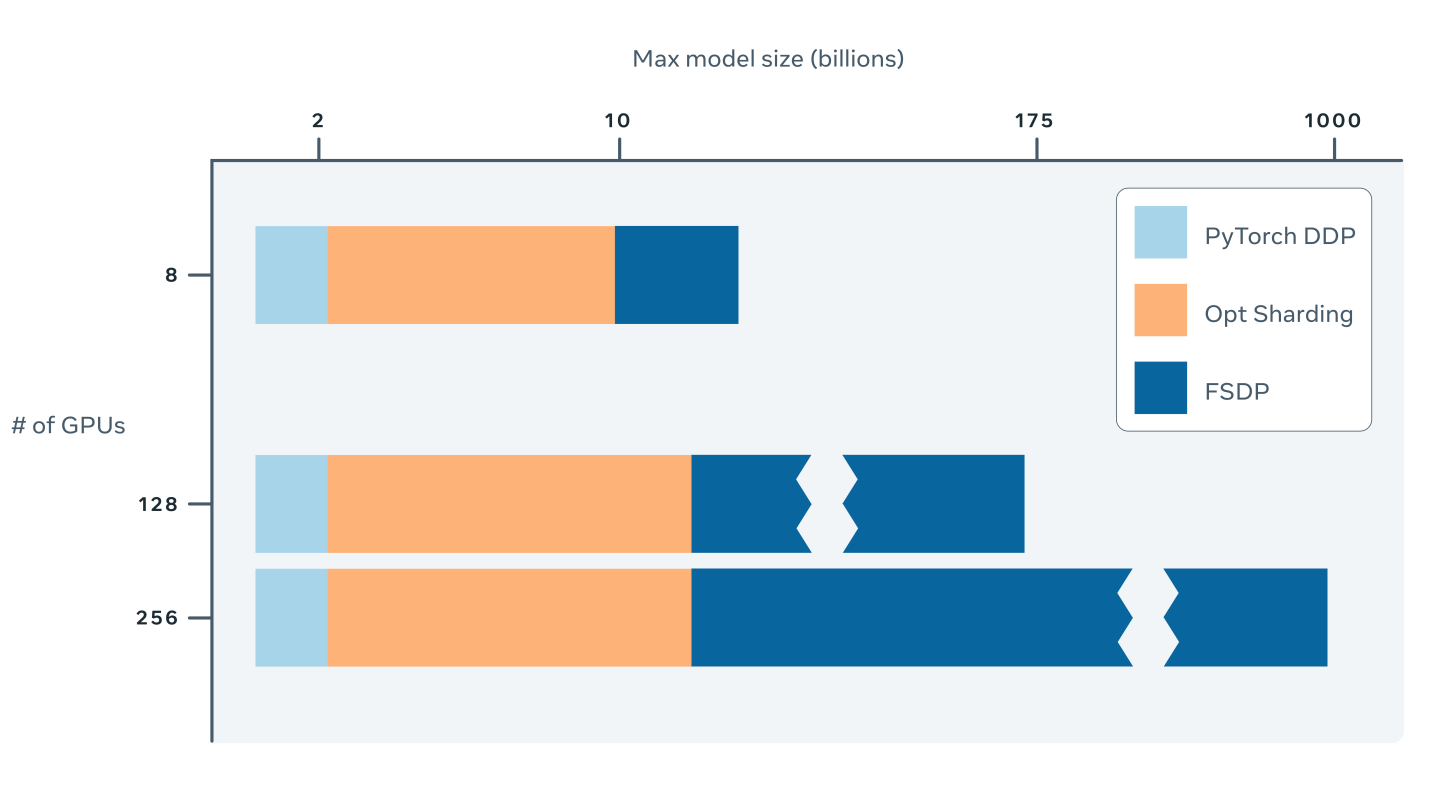
Исследования в сфере обработки естественного языка — это одна из конкретных областей, демонстрирующая важность эффективного применения вычислений при обучении ИИ-моделей. В прошлом году компания OpenAI сообщила об успешном обучении модели GPT-3 — крупнейшей в мире нейросетевой языковой модели, имеющей 175 миллиардов параметров. По некоторым оценкам, на обучение GPT-3 ушло примерно 355 GPU-лет, или затраты вычислительных ресурсов, эквивалентные непрерывной работе 1000 GPU в течение более чем 4-х месяцев.
Подходы к масштабированию обучения моделей, подобные вышеописанному, нуждаются в серьёзных вычислительных и инженерных ресурсах. Они, кроме того, сопряжены с появлением дополнительных коммуникационных затрат, их применение требует от инженеров тщательно оценивать последствия компромиссов между используемой памятью и вычислительной эффективностью. Например, обычное обучение с параллелизмом по данным требует наличия копий модели на каждом GPU. А параллельное обучение моделей означает наличие дополнительных коммуникационных затрат, которые связаны с необходимостью перемещения данных между воркерами (GPU).
Алгоритм FSDP, в сравнении с такими подходами, относительно свободен от необходимости подобных компромиссов. Его применение улучшает эффективность использования памяти за счёт шардинга по GPU параметров моделей, градиентов, состояний оптимизатора. Он повышает вычислительную эффективность благодаря декомпозиции коммуникации и совмещения задач передачи данных и задач по выполнению прямого и обратного проходов по модели. FSDP даёт точно такие же результаты, что и стандартное распределённое обучение с параллелизмом по данным (distributed data parallel, DDP). Реализацией этого алгоритма можно пользоваться через простой в применении интерфейс, способный стать прямой заменой PyTorch-модуля DistributedDataParallel. Тестирование, проведённое нами на ранней стадии развития FSDP, показало, что этот алгоритм способен обеспечить масштабирование моделей до размеров, соответствующих триллионам параметров.
Как работает FSDP
При стандартном DDP-обучении каждый воркер обрабатывает отдельный пакет данных, а градиенты суммируются по всем воркерам с применении операции AllReduce. Когда DDP-обучение стало весьма популярным, применение этого механизма требовало больше GPU-памяти, чем ему было нужно на самом деле. Всё дело в том, что веса модели и состояния оптимизатора дублируются на всех DDP-воркерах.
Один из методов уменьшения уровня дублирования данных заключается в применении полного шардинга параметров. При таком подходе воркерам доступно лишь подмножество параметров модели, данных для вычисления градиентов и состояний оптимизатора, только то, что необходимо для выполнения локальных вычислений. Реализация этого метода, ZeRO-3, уже была популяризована Microsoft.
Ключевой аспект перехода к полному шардингу параметров заключается в понимании того, что операцию AllReduce, применяемую в DDP, можно разделить на отдельные операции ReduceScatter и AllGather.
 Операция AllReduce, представленная в виде комбинации операций ReduceScatter и AllGather. Стандартная операция AllReduce, используемая для агрегирования градиентов, может быть разделена на две отдельных фазы — ReduceScatter и AllGather. На фазе ReduceScatter градиенты суммируются в виде одинаковых блоков по рангам на каждом GPU на основании индексов их рангов. На фазе AllGather шард-порция агрегированных градиентов, имеющаяся на каждом GPU, делается доступной всем GPU (подробности об этих операциях можно найти по ссылкам, приведённым выше)
Операция AllReduce, представленная в виде комбинации операций ReduceScatter и AllGather. Стандартная операция AllReduce, используемая для агрегирования градиентов, может быть разделена на две отдельных фазы — ReduceScatter и AllGather. На фазе ReduceScatter градиенты суммируются в виде одинаковых блоков по рангам на каждом GPU на основании индексов их рангов. На фазе AllGather шард-порция агрегированных градиентов, имеющаяся на каждом GPU, делается доступной всем GPU (подробности об этих операциях можно найти по ссылкам, приведённым выше)
Затем можно перегруппировать операции ReduceScatter и AllGather таким образом, чтобы каждому DDP-воркеру нужно было бы хранить лишь единственный шард параметров и состояний оптимизатора. Следующий рисунок иллюстрирует процессы стандартного DDP-обучения (вверху) и FSDP-обучения (внизу).
 Сравнение стандартного DDP-обучения и FSDP-обучения. При использовании стандартного метода DDP копия модели имеется на каждом GPU, а последовательность вычислений, необходимых для выполнения прямых и обратных проходов по модели, выполняется лишь на фрагменте данных. После выполнения таких вот локальных вычислений, значения параметров и состояния оптимизаторов локальных процессов делаются доступными другим GPU для вычисления значений, необходимых для глобального обновления весов. При применении FSDP на GPU имеется лишь шард модели. Сведения о весах, для выполнения прямого прохода по модели, собирают с других GPU посредством шага AllGather. Потом, до выполнения обратного прохода, сбор данных о весах выполняется снова. После выполнения обратного прохода локальные градиенты усредняются и распространяются между всеми GPU посредством шага ReduceScatter. Это позволяет каждому GPU обновить свой локальный шард весов
Сравнение стандартного DDP-обучения и FSDP-обучения. При использовании стандартного метода DDP копия модели имеется на каждом GPU, а последовательность вычислений, необходимых для выполнения прямых и обратных проходов по модели, выполняется лишь на фрагменте данных. После выполнения таких вот локальных вычислений, значения параметров и состояния оптимизаторов локальных процессов делаются доступными другим GPU для вычисления значений, необходимых для глобального обновления весов. При применении FSDP на GPU имеется лишь шард модели. Сведения о весах, для выполнения прямого прохода по модели, собирают с других GPU посредством шага AllGather. Потом, до выполнения обратного прохода, сбор данных о весах выполняется снова. После выполнения обратного прохода локальные градиенты усредняются и распространяются между всеми GPU посредством шага ReduceScatter. Это позволяет каждому GPU обновить свой локальный шард весов
Для максимально эффективного использования памяти мы можем, после прямого прохода по каждому слою, отбрасывать полные веса, экономя память для следующих слоёв. Это может быть реализовано путём применения обёртки FSDP к каждому слою в сети (с помощью reshard_after_forward=True).
Это можно представить в виде следующего псевдокода:
Прямой проход FSDP:
for layer_i in layers:
all-gather полные веса для layer_i
прямой проход для layer_i
отбросить полные веса для layer_i
Обратный проход FSDP:
for layer_i in layers:
all-gather полные веса для layer_i
обратный проход для layer_i
отбросить полные веса для layer_i
reduce-scatter градиентов дляr layer_iКак пользоваться FSDP
Существуют различные способы использования FSDP в крупномасштабных ИИ-исследованиях. В настоящий момент мы предлагаем четыре решения, которые адаптированы для различных нужд.
1. Использование FSDP в языковых моделях
В языковых моделях FSDP можно использовать посредством фреймворка fairseq, применяя следующие новые аргументы:
–ddp-backend=fully_sharded: включает полный шардинг посредством FSDP.–cpu-offload: передаёт состояние оптимизатора и FP32-копию модели CPU (комбинируется с–optimizer=cpu_adam).–no-reshard-after-forward: увеличивает скорость обучения для больших моделей (более 1 миллиарда параметров), похож на ZeRO Stage 2.Другие популярные опции
(–fp16,–update-freq,–checkpoint-activations,–offload-activationsи другие) позволяют продолжить работу в обычном режиме.
В руководстве по fairseq вы можете найти пример, демонстрирующий обучение модели с 13 миллиардами параметров на восьми GPU, а так же — на одном GPU с применением FSDP и CPU.
2. Использование FSDP в моделях машинного зрения
В моделях машинного зрения FSDP можно применить через VISSL. В частности, использование FSDP протестировано на архитектурах RegNets. Слои, вроде BatchNorm и ReLU, без проблем обрабатывались и были протестированы на сходимость.
Для включения FSDP воспользуйтесь следующими опциями:
config.MODEL.FSDP_CONFIG.AUTO_SETUP_FSDP=Trueconfig.MODEL.SYNC_BN_CONFIG.SYNC_BN_TYPE=pytorchconfig.MODEL.AMP_PARAMS.AMP_TYPE=pytorch
В этом разделе конфигурационного yaml-файла можно найти дополнительные настройки FSDP в VISSL.
3. Использование FSDP из PyTorch Lightning
На то, чтобы облегчить использование FSDP при решении более широкого круга задач, направлена бета-версия поддержки FSDP в PyTorch Lightning. В этом руководстве можно найти подробный пример использования FSDP в PyTorch Lightning. Если в двух словах, то включить FSDP можно, воспользовавшись аргументом plugins=’fsdp’:
model = MyModel()
trainer = Trainer(gpus=4, plugins='fsdp', precision=16)
trainer.fit(model)
trainer.test()
trainer.predict()4. Использование библиотеки FSDP непосредственно из FairScale
FairScale — это главная библиотека, в рамках которой был реализован FSDP, и в которой можно найти последние обновления этого алгоритма. FSDP можно использовать прямо из FairScale. Например, в следующем фрагменте кода для этого достаточно заменить DDP(my_module) на FSDP(my_module):
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
...
sharded_module = D̶D̶P̶(̶m̶y̶_̶m̶o̶d̶u̶l̶e̶)̶FSDP(my_module)
optim = torch.optim.Adam(sharded_module.parameters(), lr=0.0001)
for sample, label in dataload.next_batch:
out = sharded_module(x=sample, y=3, z=torch.Tensor([1]))
loss = criterion(out, label)
loss.backward()
optim.step()Библиотека FSDP в FairScale предлагает разработчику низкоуровневые опции, ориентированные на многие важные аспекты крупномасштабного обучения моделей. Вот несколько важных моментов, на которые стоит обратить внимание тому, кто стремится выжать из FSDP всё, что можно.
Оборачивание модели. Для того чтобы свести к минимуму пики потребления памяти GPU, пользователю нужно организовать «вложенное» обёртывание модели. Это ведёт к дополнительному усложнению модели. Утилита auto_wrap способна принести пользу в деле аннотирования кода существующих PyTorch-моделей для целей их «вложенного» оборачивания.
Инициализация модели. FSDP, в отличие от DDP, не выполняет автоматическую синхронизацию весов модели между GPU-воркерами. Это означает, что инициализацию модели нужно проводить аккуратно, так — чтобы все GPU-воркеры имели бы идентичные начальные веса.
Параметры оптимизатора. FSDP, из-за применения шардинга и обёртывания моделей, поддерживает лишь определённые типы оптимизаторов и параметров оптимизаторов. В частности, если модуль обёрнут с помощью FSDP, а его параметры преобразованы в единственный тензор, пользователи не смогут использовать различные гиперпараметры для различных групп параметров такого модуля.
Смешанная точность. FSDP поддерживает продвинутое обучение со смешанной точностью с применением мастер-версий весов в FP16 (с половинной точностью), а так же с применением FP16-операций reduce и scatter над градиентами. Определённые части модели могут сойтись только при использовании полной точности (FP32). В подобных случаях необходимы дополнительные обёртки, позволяющие избирательно обрабатывать некоторые части модели с полной точностью.
Создание контрольных точек состояния и извлечение сведений о состоянии модели. Если модель достаточно велика, сохранение и загрузка состояния модели могут оказаться непростыми задачами. FSDP поддерживает несколько способов решения подобных задач, но их никоим образом нельзя назвать тривиальными.
И наконец, FSDP часто используется вместе с функциями наподобие checkpoint_wrapper из FairScale, ориентированными на оптимизацию работы с памятью (activation checkpointing). Пользователю, который стремится уместить большую модель в ограниченную память GPU, может понадобиться тщательное планирование стратегии оптимизации.
Следующие шаги
FSDP — это опенсорсный проект, и ранние пользователи этого проекта опробовали его и сделали вклад в его развитие. Мы полагаем, что алгоритм FSDP способен принести пользу всему сообществу ИИ-исследователей. Мы стремимся к сотрудничеству со всеми, кто хочет улучшить FSDP. В частности, вот несколько важных направлений развития FSDP:
Нужно сделать алгоритм FSDP универсальнее. До сих пор FSDP использовался в моделях обработки естественного языка и в сфере машинного зрения с применением оптимизаторов SGD и Adam. По мере появления новых моделей и оптимизаторов нужно, чтобы FSDP поддерживал бы и их. FSDP, будучи полностью параллельной по данным схемой обучения моделей, имеет огромнейший потенциал универсальной поддержки широкого диапазона ИИ-алгоритмов.
Нужно сделать так, чтобы FSDP поддерживал бы возможности автоматической настройки. Существует множество «рычагов», за которые может «потянуть» пользователь, настраивающий FSDP. Эти «рычаги» имеют отношение к масштабированию моделей и к производительности. Мы стремимся к созданию механизмов автоматической настройки и использования памяти GPU, и производительности обучения моделей.
Помимо обучения моделей важным направлением развития FSDP можно счесть улучшение масштабирования развёртывания и обеспечения работы моделей в реальных условиях.
Последним в этом списке, но не последним по важности мы считаем рефакторинг кода и продолжение улучшения модульности FSDP и его основных компонентов. Это важно как в применении к существующему коду, так и для новых и улучшенных возможностей алгоритма.
Попробуйте FSDP и сделайте вклад в его развитие!
В настоящее время реализацию FSDP можно найти в библиотеке FairScale.
Благодарим всех, кто дочитал до этого места. Пожалуйста, попробуйте FSDP в своих исследованиях или в реальных проектах. Мы будем рады отзывам, и, как всегда, приветствуем PR в репозиторий проекта.
О, а приходите к нам работать?
