[Перевод] (Agile vs waterfall) Разработка безопасных алгоритмов: Проектирование
Представьте себе водопад. Мощный. Безупречный. Всегда движется вперед по направлению к неминуемому спуску. Движимый одной из нескольких фундаментальных сил во вселенной.
Водопады потрясают по самой своей сути, так что неудивительно, что инженеры немного одержимы ими. Старый стандарт DOD-STD-2167A рекомендовал использовать водопадную модель, а мое устаревшее инженерное образование основывалось на модели Phase-Gate, которая, по моему мнению, чертовски похожа на водопадную. С другой стороны, те из нас, кто изучал информатику в университете, наверное, знают, что водопадная модель в некоторой мере является анти-паттерном. Наши друзья в академической башне из слоновой кости говорят нам, что нет-нет, Agile — это путь к успеху и похоже, индустрия доказала истинность этого утверждения.
Итак, что же выбрать разработчику между устаревающей водопадной моделью и новомодным Agile? Меняется ли уравнение, когда речь идет о разработке алгоритмов? Или какого-нибудь критического, в плане безопасности, программного обеспечения?
Как обычно в жизни, ответ находится где-то посередине.
Гибридная, спиральная и V-образная модели
Гибридная разработка — тот самый ответ, который находится посередине. Там, где модель водопада не позволяет вернуться назад и изменить требования, гибридная модель позволяет это. А там, где у Agile возникают проблемы с предварительным проектированием, гибридная разработка оставляет для него пространство. Более того, гибридная разработка направлена на уменьшение количества дефектов в конечном продукте, чего мы, вероятно, хотим при разработке алгоритмов для приложений, критичных с точки зрения безопасности.
Звучит неплохо, но насколько это действительно эффективно?
Чтобы ответить на этот вопрос, мы делаем ставку на гибридную разработку в процессе работы над алгоритмом локализации NDT. Локализация является неотъемлемой частью любого стека беспилотной езды, который выходит за рамки чисто реактивного управления. Если вы мне не верите или не знакомы с локализацией, я настоятельно рекомендую вам взглянуть на некоторые проектные документы, которые были разработаны в рамках этого процесса.
Так что же такое гибридная разработка в двух словах? С моей дилетантской точки зрения, я бы сказал, что это идеализированная V-образная, или спиральная модель. Вы планируете, проектируете, внедряете и тестируете, а затем проводите итерацию всего процесса, основываясь на извлеченных уроках и новых знаниях, которые вы приобрели за это время.
Практическое применение
Говоря более конкретно, мы с рабочей группой NDT в Autoware.Auto, закончили наш первый спуск по левому каскаду V-образной модели (то есть совершили первую итерацию через этап проектирования) в рамках подготовки к Autoware Hackathon в Лондоне (его проводит Parkopedia!). Наш первый проход через этап проектирования состоял из следующих этапов:
- Обзор литературы
- Обзор существующих реализаций
- Проектирование компонентов высокого уровня, вариантов использования и требований
- Анализ неисправностей
- Определение метрик
- Архитектура и дизайн API
Вы можете взглянуть на каждый из результирующих документов, если вас интересует нечто подобное, но в оставшейся части этого поста я постараюсь разобрать некоторые из них, а также объясню что и почему из этого вышло на каждом из этих этапов.
Обзор литературы и существующих реализаций
Первый шаг любого достойного начинания (а именно так я бы классифицировал реализацию NDT) — посмотреть, что сделали другие люди. Люди, в конце концов, социальные существа, и все наши достижения стоят на плечах гигантов.
Если отбросить аллюзии, то существует два важных направления, на которые следует обратить внимание при рассмотрении «искусства прошлого»: академическая литература и функциональные реализации.
Всегда полезно посмотреть на то, над чем работали бедные аспиранты в разгар голодных времен. В лучшем случае, вы обнаружите, что существует совершенно превосходный алгоритм, который вы можете реализовать вместо своего. В худшем случае, вы обретете понимание пространства и вариаций решений (что может помочь информационной архитектуре), а также сможете узнать о некоторых теоретических основах алгоритма (и, таким образом, о том, за какими инвариантами вы должны следить).
С другой стороны, столь же полезно посмотреть на то, что делают другие люди — в конце концов, всегда проще всего начать что-то делать, имея стартовую подсказку. Вы можете не только безвозмездно заимствовать хорошие архитектурные идеи, но и открывать для себя некоторые догадки и грязные уловки, которые могут понадобиться вам для того, чтобы алгоритм заработал на практике (и, возможно, вы, даже сможете полностью интегрировать их в вашу архитектуру).
Из нашего обзора литературы по NDT, мы собрали следующие полезные фрагменты информации:
- Семейство алгоритмов NDT имеет несколько вариаций:
— P2D
— D2D
— Ограниченный
— Семантический - Существует куча грязных трюков, которые можно использовать, чтобы заставить алгоритм работать лучше.
- NDT обычно сравнивается с ICP
- NDT немного быстрее и немного надежнее.
- NDT надежно работает (имеет высокий коэффициент успешности) в пределах определенной местности
Ничего невероятного, но эти сведения можно сохранить для последующего использования, как в проектировании, так и в реализации.
Аналогичным образом, из нашего обзора существующих реализаций мы увидели не только конкретные шаги, но и некоторые интересные стратегии инициализации.
Варианты использования, требования и механизмы
Неотъемлемой частью любого процесса разработки по методу «дизайн или план в первую очередь» является рассмотрение проблемы, которую вы пытаетесь решить на высоком уровне. В широком смысле, с точки зрения функциональной безопасности (в чем я, признаюсь, далек от эксперта), «взгляд на проблему высокого уровня» организован примерно следующим образом:
- Какие варианты использования вы пытаетесь решить?
- Каковы требования (или ограничения) к решению для удовлетворения вышеуказанных случаев использования?
- Какие механизмы удовлетворяют вышеуказанным требованиям?
Описанный выше процесс обеспечивает дисциплинированный взгляд на проблему с высокого уровня и постепенно становится более подробным.
Чтобы получить представление о том, как это может выглядеть, вы можете взглянуть на высокоуровневый проектный документ по локализации, который мы собрали при подготовке к разработке NDT. Если вы не в настроении для чтения на перед сном, то читайте дальше.
Варианты использования
Мне нравятся три мысленных подхода к вариантам использования (внимание, я не специалист по функциональной безопасности):
- Что вообще должен делать компонент? (помните о SOTIF!)
- Каковы способы, которыми я могу ввести входные данные в компонент? (входные варианты использования, мне нравится называть их восходящими)
- Каковы способы, которыми я могу получать выходные данные? (выходные или нисходящие варианты использования)
- Бонусный вопрос: В каких цельных архитектурах систем может находиться этот компонент?
Собрав всё вместе, мы придумали следующее:
- Большинство алгоритмов могут использовать локализацию, но в конечном итоге их можно разделить на разновидности, которые работают как локально, так и глобально.
- Локальные алгоритмы нуждаются в преемственности в своей истории преобразований.
- В качестве источника данных о локализации можно использовать практически любой датчик.
- Нам нужен способ инициализации и устранения сбоев в наших методах локализации.
Помимо различных вариантов использования, о которых вы можете подумать, мне также нравится думать о некоторых случаях общего использования, предъявляющих очень строгие требования. Для этого у меня есть вариант (или задача) полностью беспилотной поездки по бездорожью, проходящей через несколько туннелей с движением в караване. В этом варианте использования есть пара неприятностей вроде накопления ошибок одометрии, ошибок вычислений с плавающей запятой, коррекции локализации и перебоев в работе.
Требования
Цель разработки вариантов использования, помимо составления обобщенного любой проблемы, которую вы пытаетесь решить, заключается в определении требований. Для того, чтобы сценарий использования состоялся (или был удовлетворен), вероятно, существуют некоторые факторы, которые должны осуществиться или быть возможными. Другими словами, в каждом варианте использования есть определенный набор требований.
В конце концов, общие требования к системе локализации не так уж и страшны:
- Обеспечить преобразования для локальных алгоритмов
- Обеспечить преобразования для глобальных алгоритмов
- Обеспечить работу механизма для инициализации алгоритмов относительной локализации
- Убедиться, что преобразования не разрастаются
- Обеспечить соответствие REP105
Квалифицированные специалисты по функциональной безопасности, скорее всего, сформулируют гораздо больше требований. Ценность этой работы заключается в том, что мы четко формулируем определенные требования (или ограничения) к нашей конструкции, которые, как и механизмы, будут удовлетворять нашим требованиям к работе алгоритма.
Механизмы
Итоговым результатом любого рода анализа должен быть практический набор уроков или материалов. Если в результате анализа мы ничего не можем использовать результат (даже отрицательный!), то анализ был проведен впустую.
В случае с высокоуровневым инженерным документом, речь идет о наборе механизмов или конструкции, инкапсулирующей эти механизмы, которые могут адекватно удовлетворять нашим вариантам использования.
Этот специфический высокоуровневый дизайн локализации позволил получить набор программных компонентов, интерфейсов и схем поведения, которые составляют архитектуру системы локализации. Простая блок-схема предлагаемой архитектуры приведена ниже.
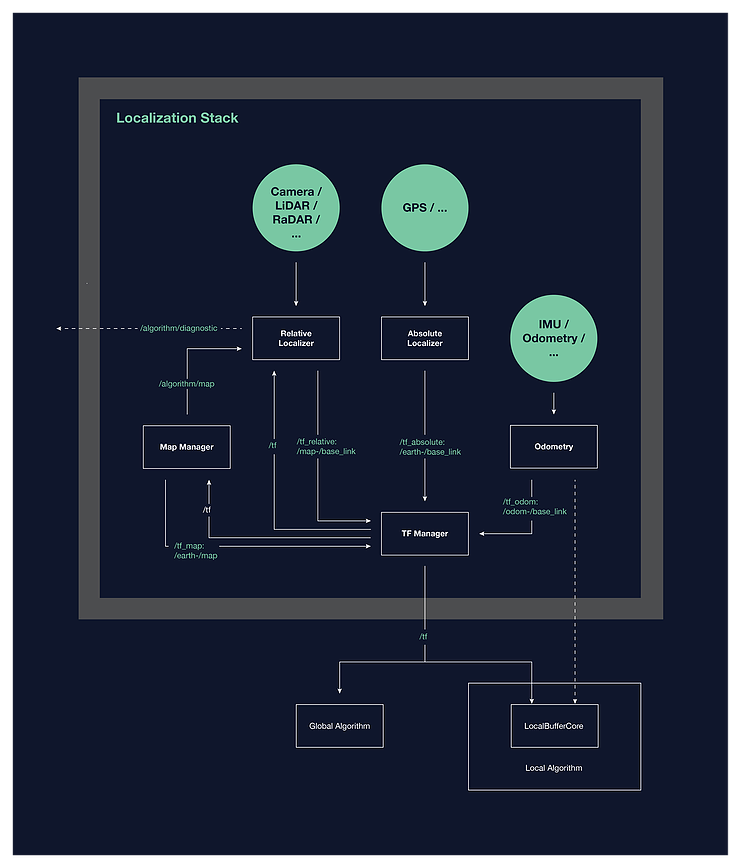
Если вас интересует более подробная информация об архитектуре или дизайне, я настоятельно рекомендую вам ознакомиться с полным текстом документа.
Анализ неисправностей
Поскольку мы занимаемся созданием компонентов в системах, критичных с точки зрения безопасности, сбои — это то, чего мы должны стараться избегать или, по крайней мере, смягчать их последствия. Поэтому, прежде чем мы попытаемся спроектировать или построить что-либо, мы должны, по крайней мере, знать о том, как все может сломаться.
При анализе неисправностей, как и в большинстве случаев, полезно смотреть на компонент с нескольких точек зрения. Для анализа сбоев алгоритма NDT мы рассматривали его двумя разными способами: как общий (относительный) механизм локализации, и конкретно как экземпляр алгоритма NDT.
При рассмотрении с точки зрения механизма локализации, основной режим сбоя формулируется следующим образом — «что делать, если на вход подаются неправильные данные?» Действительно, с точки зрения отдельного компонента, сделать можно немногое, разве что провести базовую проверку на адекватность работы системы. На системном уровне у вас появляются дополнительные возможности (например, включение функций безопасности).
Рассматривая NDT как алгоритм в отрыве, полезно абстрагироваться от алгоритма, выделяя соответствующее количество аспектов. Будет полезно обратить внимание на версию алгоритма, написанную на псевдокоде (это поможет вам, разработчику, лучше понять алгоритм). В данном случае мы подробно разобрали алгоритм и изучили все ситуации, в которых он может сломаться.
Ошибка реализации — это совершенно разумный вариант сбоя, хотя его можно исправить с помощью соответствующего тестирования. Чуть чаще и коварнее стали проявляться некоторые нюансы относительно числовых алгоритмов. В частности, речь идет о нахождении обратных матриц или, в более общем случае, решении систем линейных уравнений, которое может привести к числовым погрешностям. Это довольно чувствительный вариант сбоя, и на него нужно обратить внимание.
Два других важных варианта сбоя, которые мы также определили — это проверка того, что определенные выражения не являются неограниченными по величине (контроль точности вычислений с плавающей точкой), а также проверка того, что величина или размер входов постоянно контролируется.
Всего мы выработали 15 рекомендаций. Я бы рекомендовал вам ознакомиться с ними.
Также добавлю, что хоть мы и не использовали этот метод, но анализ дерева неисправностей является отличным инструментом для структурирования и количественной оценки проблемы анализа сбоев.
Определение метрик
«То, что измеряется поддается управлению»
— Популярная фраза менеджеров
К сожалению, в профессиональной разработке недостаточно пожимать плечами и говорить «Сделано», когда тебе надоело над чем-то работать. По сути, любой пакет работ (которым опять-таки является разработка NDT) предполагает наличие критериев принятия, которые должны быть согласованы и заказчиком, и поставщиком (если вы и заказчик, и продавец, пропустите этот шаг). Вся юриспруденция существует, чтобы поддерживать эти аспекты, но как инженеры, мы можем просто вырезать посредников, создавая метрики для определения степени готовности наших компонентов. В конце концов, цифры (в основном) однозначны и неопровержимы.
Даже если критерии принятия работы не нужны или не имеют значения, все равно приятно иметь хорошо определенный набор метрик, который характеризует и улучшает качество и производительность проекта. В конце концов, то, что измеряется, поддается контролю.
Для нашей реализации NDT мы разбили метрики на четыре широкие группы:
- Общие метрики качества программного обеспечения
- Общие метрики качества встроенного программного обеспечения
- Общие метрики алгоритма
- Специфические для локализации метрики
Я не буду вдаваться в подробности, потому что все эти метрики относительно стандартны. Важно то, что метрики были определены и идентифицированы для нашей конкретной проблемы, и это примерно то, чего мы можем добиться как разработчики проекта с открытым исходным кодом. В конечном счете, планка для принятия должна быть определена исходя из специфики проекта тем, кто разворачивает систему.
И последнее, что я повторю здесь, это то, что хотя метрики и являются фантастическими для тестов, они не являются заменой проверки понимания реализации и требований к использованию.
Архитектура и API
После проведения кропотливой работы над характеристикой проблемы, которую мы пытаемся решить, и формированием понимания пространства решений, мы можем, наконец, погрузиться в область, граничащую с реализацией.
В последнее время я был фанатом разработки на основе тестов. Как и большинству инженеров, мне нравятся процессы разработки, и идея написания тестов в первую очередь казалась мне громоздкой. Когда я начинал программировать профессионально, я шел напрямик и проводил тестирование после разработки (несмотря на то, что мои преподаватели в университете говорили мне делать наоборот). Исследования показывают, что написание тестов перед внедрением, как правило, приводит к меньшему количеству ошибок, более высокому тестовому покрытию и, в целом, более качественному коду. Наверное, что более важно, я считаю, что разработка, основанная на тестах, помогает разобраться с весомой проблемой реализации алгоритма.
Как это выглядит?
Вместо внесения монолитного тикета под названием «Реализовать NDT» (включая тесты), в результате которого будет написано несколько тысяч строк кода (которые невозможно эффективно просмотреть и изучить), можно разбить проблему на более содержательные фрагменты:
- Написать классы и публичные методы для алгоритма (создать архитектуру)
- Написать тесты для алгоритма с использованием публичного API (они должны проваливаться!).
- Реализовать логику алгоритма
Итак, первый шаг — написать архитектуру и API для алгоритма. О других шагах я расскажу в другой заметке.
Несмотря на то, что существует множество работ, которые рассказывают о том, как «создавать архитектуру», мне кажется, что проектирование архитектуры программного обеспечения имеет нечто общее с черной магией. Лично мне нравится думать воспринимать разработку архитектуры программ как рисование границ между концепциями и попытку охарактеризовать степени свободы в постановке проблемы и способах ее решения с точки зрения концепций.
Каковы же тогда степени свободы в NDT?
Обзор литературы говорит нам о том, что существуют различные способы представления сканирования и наблюдения (например, P2D-NDT и D2D-NDT). Аналогичным образом, наш инженерный документ высокого уровня говорит о том, что у нас имеется несколько способов представления карты (статический и динамический), так что это тоже степень свободы. В более свежей литературе также говорится о том, что задача оптимизации может быть пересмотрена. Тем не менее, сравнивая практическую реализацию и литературу, мы видим, что даже детали решения для оптимизации могут отличаться.
И список можно продолжать и продолжать.
По итогам первичного проектировании мы остановились на следующих концепциях:
- Проблемы оптимизации
- Решения для оптимизации
- Представление сканирования
- Представление карты
- Первоначальные системы генерации гипотез
- Алгоритм и узловые интерфейсы
С некоторым подразделением внутри этих пунктов.
Конечные ожидания от архитектуры заключаются в том, что она должна быть расширяемой и поддерживаемой. Соответствует ли наша предлагаемая архитектура этой надежде, покажет только время.
Далее
После проектирования, конечно, приходит время реализации. Официальная работа по внедрению NDT в Autoware.Auto была проведена на хакатоне Autoware, организованном Parkopedia.
Следует повторить, что то, что было представлено в этом тексте, является только первым проходом через фазу проектирования. Известно, что ни один план боя не выдерживает встречи с врагом, и то же самое можно сказать и о дизайне программного обеспечения. Окончательный провал водопадной модели был проведен исходя из предположения, что спецификация и дизайн были реализованы идеально. Нет нужды говорить, что ни спецификация, ни дизайн не совершенны, а по мере внедрения и тестирования будут обнаруживаться недочеты, и придется вносить изменения в проекты и документы, изложенные здесь.
И это нормально. Мы, как инженеры, не являемся нашей работой и не отождествляемся с ней, и все, что мы можем попытаться сделать — это итерировать и стремиться к совершенным системам. После всех слов, сказанных о разработке NDT, я думаю, что мы сделали хороший первый шаг.
Подписывайтесь на каналы:
@TeslaHackers — сообщество российских Tesla-хакеров, прокат и обучение дрифту на Tesla
@AutomotiveRu — новости автоиндустрии, железо и психология вождения

Мы, пожалуй, самый сильный в России центр компетенций по разработке автомобильной электроники. Сейчас активно растем и открыли много вакансий (порядка 30, в том числе в регионах), таких как инженер-программист, инженер-конструктор, ведущий инженер-разработчик (DSP-программист) и др.
У нас много интересных задач от автопроизводителей и концернов, двигающих индустрию. Если хотите расти, как специалист, и учиться у лучших, будем рады видеть вас в нашей команде. Также мы готовы делиться экспертизой, самым важным что происходит в automotive. Задавайте нам любые вопросы, ответим, пообсуждаем.
Читать еще полезные статьи:
