[Перевод] 96 вычислительных ядер и оптимизация кода муравьиного алгоритма поиска маршрутов

Наша цель заключается в том, чтобы добиться эффективной работы программы на компьютере с четырьмя процессорами Intel Xeon E7–8890 v4. Система оснащена 512 Гб оперативной памяти, на ней установлена Linux 3.10.0–327.el7.x86_64, код компилировался с помощью Intel Parallel Studio XE 2016 U2.
Проблема поиска оптимального маршрута в транспортной сети известна как «задача коммивояжёра». На практике это, например, нахождение оптимальных путей перевозок товаров. Изначально «эффективность» в задачах такого рода означала выбор наиболее дешёвого пути, но за последние несколько десятилетий понятие «стоимость маршрута» расширилось. Теперь сюда включают и воздействие на окружающую среду, и цену энергоресурсов, и время. В дополнение к этому, глобализация бизнеса и цепочек поставок привели к тому, что размеры и сложность транспортных сетей, а значит — и моделей, на которых базируются расчёты, значительно выросли. Теперь типичные задачи оптимизации маршрутов классифицируют как НП-трудные. Обычно для решения таких задач не подходят детерминированные методы.
С развитием распределённых и многоядерных вычислительных систем были разработаны и успешно применены эвристические методы решения задач, в частности — так называемый муравьиный алгоритм (Ant Colony Optimization, ACO). Сейчас мы рассмотрим процесс анализа базовой реализации ACO и расскажем о поэтапном улучшении кода. Забегая вперёд, отметим, что наша методика оптимизация позволила вывести программу на уровни производительности и масштабируемости, близкие к теоретически достижимым.
О муравьином алгоритме
Расскажем об алгоритме, который используется в нашей программе. Он основан на поведении колонии муравьёв. Насекомые ищут источники питания, помечая пройденные пути феромонами, которые привлекают других муравьёв. Со временем феромоны испаряются, то есть, более длинные пути становятся менее привлекательными, чем более короткие, или те, по которым можно пройти быстро. В результате, чем короче или быстрее путь, тем больше муравьёв он способен заинтересовать, при этом, каждый из них, проходя по пути, делает его ещё привлекательнее.
На рисунке ниже показан пример транспортной сети. Сплошными линиями отмечены прямые маршруты между узлами, точечными — непрямые маршруты.

Пример транспортной сети
Простые компьютерные агенты способны, используя вероятностный подход, находить решения транспортных задач с использованием муравьиного алгоритма. Параллельные реализации этого алгоритма, отличающиеся, однако, некоторыми ограничениями, уже были исследованы в прошлом.
Так, в 2002-м году Маркус Рэндалл с соавторами опубликовал материал (A Parallel Implementation of Ant ColonyOptimization, Journal of Parallel and Distributed Computing 62), в котором показан подход к распараллеливанию задачи, приведший к приемлемому ускорению вычислений. Однако, в данной реализации для поддержания матрицы феромонов требовалось большое количество взаимодействий между «муравьями», которые действовали параллельно, при этом каждый из них был самостоятельной единицей модели. В результате производительность решения оказалась ограничена интерфейсом передачи сообщений (Message Passing Interface, MPI) между «муравьями».
В 2015-м был опубликован материал (Veluscek, M., T. Kalganova, P. Broomhead, A. Grichnik, Composite goal methods for transportation network optimization, Expert Systems with Applications 42), в котором описана методика оптимизации транспортной сети с использованием технологии OpenMP и общей памяти. Однако, такой подход хорошо подходит лишь для систем со сравнительно небольшим числом вычислительных ядер и потоков.
Базовая реализация алгоритма
Вот блок-схема базовой архитектуры параллельной реализации муравьиного алгоритма. Именно с неё мы начали эксперименты.

Схема неоптимизированной реализации муравьиного алгоритма
На этой схеме показано, как каждый «месяц» запускается множество итеративных процессов. В каждом из них в сеть «выпускают» группу «муравьёв», которые строят матрицы феромонов. Каждый итеративный процесс полностью независим, он исполняется в собственном потоке.
Здесь используется статическое распределение заданий, каждый поток OpenMP выполняет свою часть работы, находя локальное решение. После того, как все потоки завершат исполнение, главный поток сравнивает найденные ими локальные решения и выбирает лучшее, которое становится глобальным.
Результаты испытаний базовой версии
Один из самых быстрых способов выяснить, эффективно ли масштабируется приложение при увеличении числа доступных ему вычислительных ядер, заключается в следующем. Сначала получают базовый показатель производительности на одном процессоре (узле NUMA). Затем этот показатель сравнивают с результатами измерения производительности при запуске на нескольких процессорах, причём, как с применением технологии Hyper-Threading, так и без неё. В идеальном сценарии, если предположить, что производительность зависит лишь от числа вычислительных ядер, система с двумя сокетами должна показать производительность, которая вдвое больше, чем производительность системы с одним.Соответственно, четыре сокета должны дать четырёхкратный рост производительности.
На рисунке ниже можно увидеть результаты испытаний базовой версии приложения. Сейчас наш код далёк от идеала. После того, как число сокетов превысило два (48 ядер), программа масштабируется не слишком хорошо. На четырёх же сокетах с включенной технологией Hyper-Threading (192 логических ядра) производительность даже ниже чем при использовании одного сокета.

Испытание базовой неоптимизированной реализации алгоритма
Это совсем не то, что нам нужно, поэтому пришло время исследовать программу с использованием VTune Amplifier.
Анализ базовой реализации алгоритма с помощью VTune Amplifier XE
Для того, чтобы выяснить, что же мешает приложению нормально работать на нескольких процессорах, мы воспользуемся Hotspot-анализом VTune Amplifier XE 2016. Будем искать наиболее нагруженные участки программы. При проведении замеров в VTune Amplifier использовалась уменьшенная рабочая нагрузка (384 итеративных процесса) для того, чтобы ограничить размер собираемых данных. В других испытаниях применялась полная нагрузка (1000 итераций).
На рисунке ниже показан отчёт VTune. В частности, нас интересуют показатели в группе Top Hotspots и показатель Serial Time, который позволяет узнать время, приходящееся на последовательное исполнение кода.

Отчёт Top Hotspots
Из отчёта видно, что приложение тратит много времени на последовательное исполнение кода, что напрямую воздействует на параллельное использование ресурсов системы. Самый нагруженный участок программы — это модуль выделения памяти из стандартной библиотеки для работы со строками, который не масштабируется достаточно хорошо при большом числе ядер. Это важная находка. Дело в том, что OpenMP использует один разделяемый пул памяти, поэтому огромное количество параллельных обращений из разных потоков к конструктору строк или к модулю выделения памяти для объектов (с использованием оператора new), делают память узким местом. Если посмотреть на показатель СPU Usage, приведённый ниже, можно обнаружить, что приложение, хотя и использует все 96 доступных ядер, делает это неэффективно, нагружая их лишь в коротких промежутках времени.

Использование процессора
Если же взглянуть на то, чем заняты потоки, мы увидим, что нагрузка на них не сбалансирована.

Несбалансированная нагрузка
Так, главный поток (Master) в конце каждого «месяца» выполняет вычисления, а остальные потоки ничего полезного в это время не делают.
Теперь, после анализа кода, займёмся его оптимизацией.
Оптимизация №1. Совместное использование MPI и OpenMP
Для того, чтобы избавиться от большого набора потоков OpenMP, который присутствует в базовой реализации, мы использовали стандартный подход «главный-подчинённый» и добавили в наше приложение ещё один уровень параллелизма. А именно, теперь за вычисления в рамках отдельных итераций отвечают MPI-процессы, исполняемые параллельно, каждый из которых, в свою очередь, содержит некоторое количество OpenMP-потоков. Теперь нагрузки, связанные с выделением памяти под строки и объекты, распределены по MPI-процессам. Такая гибридная MPI-OpenMP реализация алгоритма ACO показана на блок-схеме ниже.

Оптимизированная реализация №1
Протестируем то, что у нас получилось, с использованием VTune Amplifier
Анализ оптимизированной реализации алгоритма с помощью VTune Amplifier XE
Мы исследуем оптимизированный вариант приложения по той же методике, по которой изучали его базовую версию. На рисунке ниже показан отчёт Top Hotspots, по которому можно судить о том, что теперь программа тратит меньше времени на операции по выделению памяти для строк.

Отчёт Top Hotspots
А вот — гистограммы использования процессора в базовой (слева) и оптимизированной версии программы.

Гистограммы использования процессора
Вот как теперь выглядит загрузка потоков. Видно, что она сбалансирована значительно лучше, чем ранее.

Сбалансированная нагрузка
На рисунке ниже можно видеть, что все доступные 96 ядер загружены практически полностью.
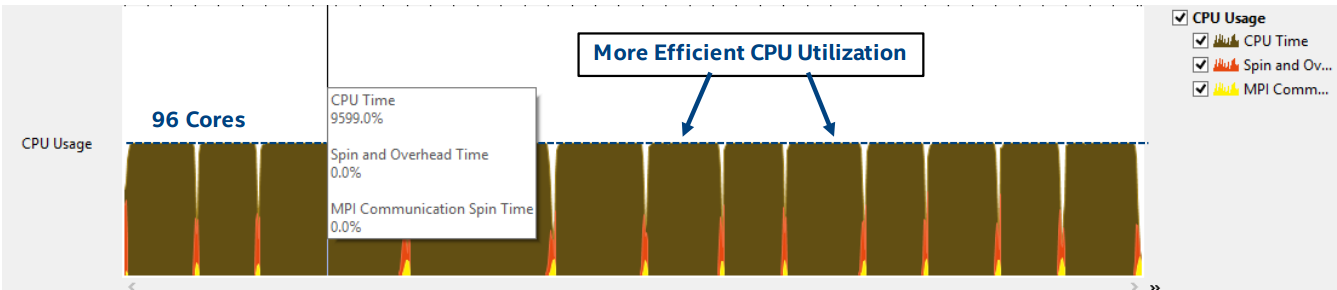
Использование процессора
К сожалению, пока ещё слишком много времени тратится на ожидания в потоках OpenMP и при обмене данными MPI, когда MPI-процесс, который находит наилучшее решение, отправляет данные главному процессу для обновления файла с результатами. Мы предположили, что это происходит из-за того, что система оказывается перегружена коммуникационными операциями MPI.
MPI использует интерфейс распределённой памяти, при этом каждый процесс работает с отдельным пулом памяти. В результате, модификация объектов и структур данных одним процессом не видна другим, но при этом данные между процессами должны передаваться с использованием механизмов MPI Send и Receive. То же самое касается и передачи главному процессу наилучшего решения, найденного в текущем «месяце».
Найденное глобальное решение — это сложный объект C++, который состоит из некоторого количества объектов производных классов, умных указателей с данными и других объектов из шаблона STL. Так как по умолчанию коммуникационные операции MPI не поддерживают обмен сложными объектами C++, для использования механизмов Send и Receive требуется сериализация, в ходе которой объекты конвертируются в байтовые потоки перед отправкой, а затем, после получения, потоки снова преобразуются в объекты.
Нагрузка, создаваемая сериализацией, постоянна. Она возникает, самое большее, раз в «месяц» (или вовсе не возникает, если главный процесс, имеющий ранг 0, найдёт наилучшее решение, которое будет признано глобальным), независимо от числа запущенных MPI-процессов. Это очень важно для того, чтобы свести к минимуму коммуникационные операции MPI при переходе к исполнению программы на множестве ядер.
На вышеприведённом рисунке дополнительные нагрузки выделены жёлтым (коммуникационные операции MPI) и красным цветами (ожидания и перегрузки).
Результаты оптимизации №1
Гибридная MPI-OpenMP версия программы показала гораздо лучшие результаты в плане балансировки нагрузки между MPI-процессами и потоками OpenMP. Так же она продемонстрировала гораздо более эффективное использование большого числа ядер, доступных в системах с процессорами Intel Xeon E7–8890. Вот как выглядят результаты тестирования текущего варианта программы в сравнении с базовым.
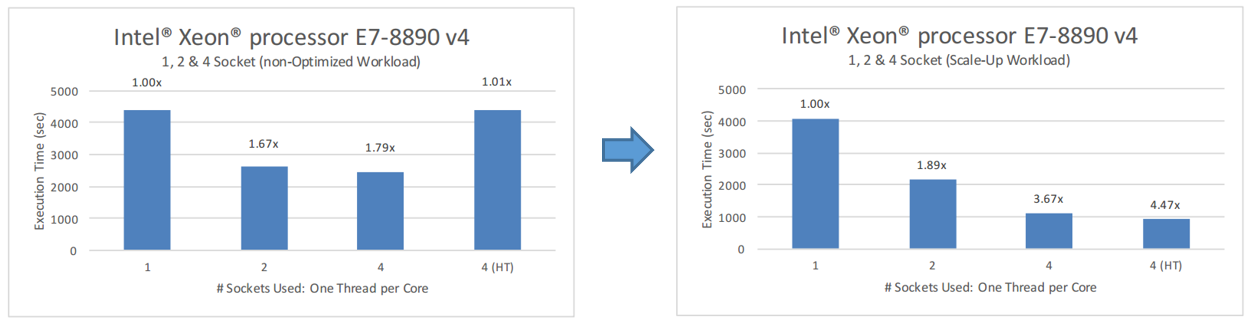
Сравнение результатов базовой и оптимизированной версий программы
Здесь можно видеть, что программа значительно лучше масштабируется при росте числа доступных ядер. Рост производительности наблюдается и при включении Hyper-Threading.
Мы достигли неплохих результатов, но работы по оптимизации пока не завершены. Воспользуемся библиотекой Intel TBB для дальнейшего улучшения производительности нашего кода.
Оптимизация №2. Применение Intel TBB
Изучая наиболее нагруженные участки кода для гибридной MPI-OpenMP реализации приложения, мы заметили, что значительная доля времени исполнения всё ещё приходится на стандартную библиотеку для работы со строками. Мы решили проверить, улучшит ли ситуацию использование библиотеки динамического выделения памяти из Intel TBB. Эта библиотека предлагает несколько шаблонов выделения памяти, которые похожи на стандартный класс std: allocator из STL, кроме того, сюда же входят scalable_allocator и cache_aligned_allocator. Эти шаблоны помогают решить две важнейших группы проблем параллельного программирования.
Первая группа — проблемы масштабирования. Они возникаю из-за того, что механизмы выделения памяти иногда вынуждены конкурировать за единственный общий пул, причём, из-за исходного последовательного устройства программы, за один раз память может выделить лишь один поток.
Вторая группа проблем связана с общим доступом к ресурсам. Например, возможна ситуация, когда два потока пытаются получить доступ к разным словам одной и той же строки кэша. Так как наименьшая единица обмена информации между процессорными кэшами — это строка, она будет передаваться между процессорами даже тогда, когда каждый из них работает с различными словами в этой строке. Ложный общий доступ способен повредить производительности, так как перемещение строки кэша может занимать сотни тактовых циклов.
Особенности работы с Intel TBB
Один из самых простых способов выяснить, пойдёт ли приложению на пользу использование Intel TBB, заключается в замене стандартной функции динамического выделения памяти на функцию из библиотеки Intel TBB libtbbmalloc_proxy.so.2. Для этого достаточно загрузить библиотеку при запуске программы используя переменную окружения LB_PRELOAD (не меняя исполняемый файл) или связать исполняемый файл с библиотекой.
Настройка связи файла с библиотекой:
-ltbbmalloc_proxy
Установка переменной окружения LD_PRELOAD для загрузки библиотеки
$ export LD_PRELOAD=libtbbmalloc_proxy.so.2Результаты оптимизации №2
Решая важнейшую проблему масштабирования, возникающую при использовании стандартных механизмов выделения памяти, библиотека динамического выделения памяти из Intel TBB даёт дополнительно 6% производительности в сравнении с гибридной MPI-OpenMP версией приложения.

Улучшение производительности в результате использования Intel TBB
Оптимизация №3. Поиск наилучшей комбинации процессов MPI и потоков OpenMP
На данном этапе мы решили заняться исследованием влияния на производительность различных комбинаций процессов MPI и потоков OpenMP при одинаковой нагрузке. В эксперименте использовались все 192 доступных логических ядра, то есть, были задействованы 4 процессора и включена технология Hyper-Threading. В ходе испытаний мы обнаружили оптимальное соотношение процессов MPI и потоков OpenMP. А именно, наилучшего результата удалось достичь, используя 64 процесса MPI, каждый из которых исполнял 3 потока OpenMP.

Сравнение производительности для различных комбинаций процессов MPI и потоков OpenMP.
Итоги
Исследование базовой параллельной реализации муравьиного алгоритма позволило выявить проблемы с масштабированием, связанные с механизмами выделения памяти для строк и конструкторами объектов.
Первый этап оптимизации, благодаря применению гибридного подхода, использующего MPI и OpenMP, позволил достичь лучшего использования ресурсов процессора, что значительно повысило производительность. Однако, программа всё ещё тратила слишком много времени на выделение памяти.
На втором этапе, благодаря библиотеке для динамического выделения памяти из Intel TBB, удалось повысить производительность ещё на 6%.
В ходе третьего этапа улучшения производительности было выяснено, что для нашей программы лучше всего подходит комбинация из 64 процессов MPI, в каждом из которых исполняется по 3 потока OpenMP. При этом код хорошо работает на всех 192-х логических ядрах. Вот итоговые результаты оптимизации.

Результаты оптимизации
В итоге, после всех улучшений, программа заработала в 5.3 раза быстрее, чем её базовая версия. Полагаем, это достойный результат, который стоит усилий, затраченных на исследование и оптимизацию кода.
