[Перевод] 6 строк глубокого обучения
Привет, Хабр! Такое понятие, как «Глубокое обучение», существует с 1986 года, когда его впервые употребила Рина Дехтер. Развитие технология получила в 2006 после выхода публикации Джеффри Хинтона об эффективном предобучении многослойной нейронной сети. Сегодня deep learning часто живет в связке с распознаванием речи, пониманием языка и компьютерным зрением. Под катом вы узнаете про использование алгоритмов глубокого обучения в SQL. Заглядывайте!

Что добавить?
Применение глубокого обучения достигло таких масштабов, что новая мантра «Глубокое обучение в каждом приложении» вполне может стать реальностью уже в ближайшее десятилетие. Не осталась в стороне и почтенная СУБД SQL Server. На вопрос «Возможно ли использование алгоритмов глубокого обучения в SQL Server?» мы уверенно отвечаем «Да!» В общедоступной предварительной версии нового выпуска SQL Server мы существенно улучшили службы R Services внутри SQL Server и добавили мощный набор инструментов машинного обучения, используемый разработчиками и в самой компании Майкрософт. За счет этого приложения СУБД, созданные на базе SQL Server, получают средства для увеличения скорости работы, производительности и масштабирования, а также доступ к другим новым возможностям машинного обучения и глубокой нейронной сети. Совсем недавно мы продемонстрировали, как SQL Server выполняет более миллиона R-прогнозов в секунду, при его использовании в качестве системы управления моделью на базе машинного обучения, и теперь мы предлагаем вам самим оценить примеры кода R и шаблоны машинного обучения для SQL Server на сайте GitHub.
В этом блоге мне хотелось бы подробно осветить вопросы «что», «зачем» и «как» в отношении глубокого обучения в SQL Server. Прояснив это, нам будет проще увидеть перспективы управляемого данными искусственного интеллекта с использованием такой мощной платформы обработки данных, как SQL Server.
Зачем добавить?
На сегодняшний день все компании и все приложения работают с данными.
Любое приложение можно назвать интеллектуальным, если оно объединяет в себе хранилище данных и интеллект (будь то искусственный интеллект, система машинного обучения или любая другая интеллектуальная система). SQL Server помогает разработчикам и пользователям реализовать самую суть глубокого обучения в своих приложениях, написав лишь несколько строк кода. Кроме того, с его помощью разработчики БД могут развернуть критически важные операционные системы со встроенными моделями глубокого обучения. В этой статье мы собрали десять причин, зачем SQL Server нужны возможности глубокого обучения.
Десять причин, зачем SQL Server нужны возможности глубокого обучения.
- Используя машинный интеллект с системами хранения данных (например, SQL Server), вы получаете безопасность, соответствие требованиям, конфиденциальность, шифрование, службы управления основными данными, группы доступности, продвинутые инструменты бизнес-аналитики, технологии обработки данных в оперативной памяти, виртуализацию, геопространственные, временные, графические и другие потрясающие возможности.
- Вы можете работать в режиме «реального времени» или «пакетной обработки» по аналогии с обработкой транзакций в реальном времени (OLTP) и интерактивной аналитической обработкой (OLAP), но применительно к глубокому обучению и машинному интеллекту.
- Чтобы использовать все преимущества глубокого обучения, вам не придется менять свои приложения, созданные на базе SQL Server. Кроме того, многие мобильные, IoT- и вебприложения могут использовать одни и те же модели глубокого обучения без необходимости дублировать код.
- Вы можете использовать функции библиотек машинного обучения (например, MicrosoftML), чтобы повысить эффективность специалистов по обработке данных, разработчиков, администраторов БД, а также всего вашего бизнеса. Это намного быстрее и эффективнее, чем делать то же самое своими силами.
- Вы сможете разрабатывать прогнозируемые решения, чтобы развертывать или масштабировать их в зависимости от текущих требований. В последнем пакете обновлений SQL Server многие функции, ранее доступные лишь в выпуске Enterprise Edition, теперь поддерживаются и в других выпусках SQL Server, включая Standard/Express/Web Edition. Это означает, что вы сможете использовать глубокое обучение даже в стандартной версии SQL Server без каких-либо дополнительных затрат.
- Вы сможете использовать разнородные источники внешних данных (с помощью PolyBase) для обучения и извлечения сведений из глубинных моделей.
- Вы можете моделировать различные ситуации и создавать сценарии «что если» внутри SQL Server, а затем использовать их для разнообразных моделей глубокого обучения. Таким образом, вы сможете получить интеллектуальное решение даже при сильно ограниченном объеме данных для обучения.
- Вы сможете просто и быстро задействовать модели глубокого обучения с помощью хранимых процедур и триггеров.
- Вы получите все необходимые инструменты, средства мониторинга и отладки, а также экосистему SQL Server, применимые к машинному интеллекту. SQL Server действительно станет вашей системой управления машинным обучением, чтобы контролировать весь жизненный цикл DNN-моделей вместе с данными.
- Вы сможете создавать новые данные и получать аналитику по хранимым данным без увеличения транзакционной рабочей нагрузки (посредством шаблона HTAP).
По правде говоря, вряд ли кто-то будет покупать СУБД только ради управления БД. Покупателю важны возможности, которые она предоставит. Наделяя SQL Server возможностями глубокого обучения, мы можем масштабировать искусственный интеллект и машинное обучение как в традиционном смысле (масштабирование данных, пропускная способность, задержка), так и с точки зрения продуктивности (упрощенное внедрение и более пологая кривая обучаемости). Это приносит ценные результаты сразу во многом, будь то время, взаимодействие с пользователем, продуктивность, уменьшение затрат и рост прибыли, новые возможности, перспективы для бизнеса, идейное лидерство в отрасли и т. д.
На практике технологии глубокого обучения в SQL Server могут использоваться в банковской и финансовой сферах, а также в здравоохранении, производстве, розничной торговле, электронной коммерции и системах Интернета вещей (IoT). А применение этих технологий для выявления мошенничества, прогнозирования заболеваемости, прогнозирования энергопотребления или анализа личной информации позволит улучшить уже существующие отрасли и приложения. Это также означает, что какие бы нагрузки не запускались на SQL Server, будь то управление отношениями с клиентами (CRM), планирование ресурсов предприятия (ERP), хранилище данных (DW), обработка транзакций в реальном времени (OLTP) и др., вы сможете без особых усилий задействовать в них технологию глубокого обучения. При этом речь идет о том, чтобы использовать ее не отдельно, а в сочетании со всеми видами данных и аналитики, которыми так славится SQL Server (например, обработка структурированных, геопространственных, графических, внешних, временных данных, а также JSON-данных). И вам остается добавить сюда лишь… свои идеи.
Как добавить?
Здесь я покажу, как применить все это на практике. В качестве примера возьмем эксперимент по прогнозированию классов галактик по изображениям с помощью мощного языка программирования Microsoft R и его нового пакета MicrosoftML для машинного обучения (созданного нашими специалистами в области разработки алгоритмов, обработки и анализа данных). А сделаем мы это в SQL Server с подключенными службами R Services на общедоступной виртуальной машине Azure NC. Я собираюсь распределить изображения галактик и других космических объектов по 13 классам на основе принятой в астрономии классификации — в основном это эллиптические и спиральные галактики и их разновидности. Форма и другие визуальные характеристики галактик меняются по мере их развития. Изучение форм галактик и их классификация помогают ученым лучше понять процессы развития Вселенной. Рассмотрев эти изображения, человеку не доставит особого труда распределить их по правильным классам. Но чтобы проделать это с 2 триллионами известных галактик, будет сложно обойтись без помощи машинного обучения и интеллектуальных технологий вроде глубоких нейронных сетей, так что именно их я и собираюсь использовать. Легко представить, что вместо астрономических данных у нас есть медицинские, финансовые или IoT-данные, и что нам требуется построить прогнозы с их использованием.
Приложение
Представьте себе простое веб-приложение, которое загружает изображения галактик из папки, а затем распределяет их по различным классам — спиральные и эллиптические, а затем снова распределяет их на классы внутри этих классов (например, это нормальная спиральная галактика или галактика, имеющая в центре структуру типа рукоятки).
Причем оно может классифицировать огромное количество изображений невероятно быстро. Пример выходных данных:

Первые два столбца содержат галактики эллиптического типа, а остальные — различные спиральные галактики.
Так как же простое приложение сможет провести настолько сложную классификацию?
Код такого приложения на деле совершает не так уж и много действий, он лишь прописывает пути к новым файлам для их распределения по классам в таблице базы данных (остальную часть программного кода составляют распределение итоговых данных, компоновка страницы и т. д.).
SqlCommand Cmd = new SqlCommand("INSERT INTO [dbo].[GalaxiesToScore] ([path] ,[PredictedLabel]) "
Что происходит в базе данных?
Часть, отвечающая за прогнозирование и операционализацию
Взглянем на таблицу, куда приложение прописывает пути к файлам изображений. Она содержит столбец с путями к изображениям галактик и столбец для хранения ожидаемых классов галактик. Как только новая строка данных записывается в таблицу, срабатывает триггер:
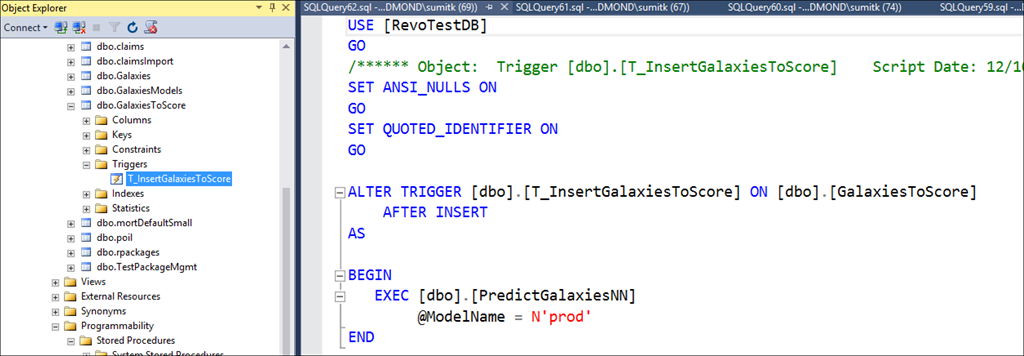
В свою очередь, триггер вызывает хранимую процедуру — PredictGalaxiesNN, как показано ниже (с частью R-сценария, встроенной в хранимую процедуру):
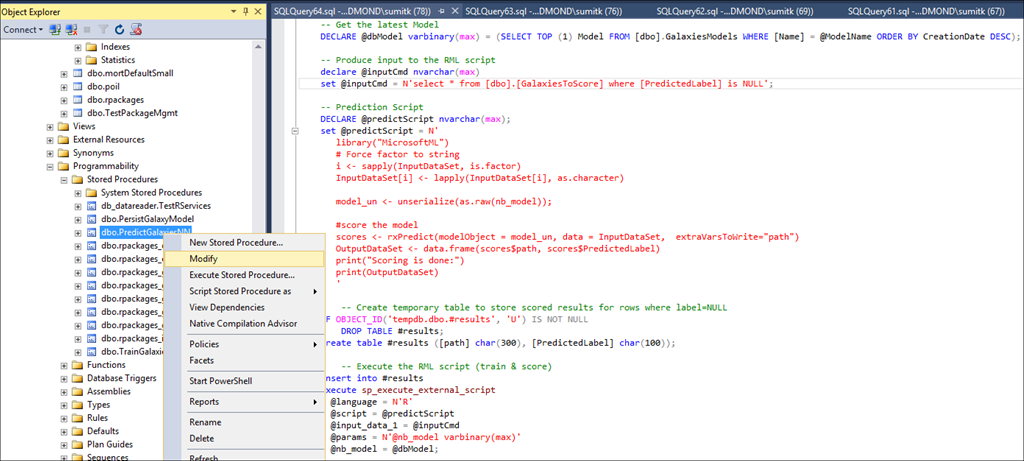
Именно здесь, в нескольких строках кода R, происходит магия. Этот R-сценарий принимает на вход новые строки данных (которые пока не получили оценку) и модель, хранящуюся в таблице в качестве varbinary (max). Чуть позже я вернусь к вопросу, как там оказалась эта модель. Внутри сценария модель подвергается десериализации и используется уже знакомой нам функцией вычисления (rxPredict) в следующей строке, чтобы оценить новые строки и затем записать итоговые выходные данные.
scores <- rxPredict(modelObject = model_un, data = InputDataSet, extraVarsToWrite="path")
Это новый вариант функции rxPredict, которая понимает алгоритмы машинного обучения, включенные в пакет MicrosoftML. Следующая строка загружает пакет, содержащий новые алгоритмы машинного обучения MicrosoftML.
[ library("MicrosoftML") ]
Помимо глубокой нейронной сети (DNN), главной темы данного блога, в пакете содержится еще пять мощных алгоритмов машинного обучения: быстрый линейный, быстрый на базе дерева, быстрый на базе леса, одноклассовый метод обнаружения аномалий SVM, регуляризованная логистическая регрессия (с поддержкой регуляризации L1 и L2) и нейронные сети. Таким образом, с помощью всего 6–7 строк языка R любое приложение может стать интеллектуальным благодаря модели на базе глубокой нейронной сети. От приложения потребуется лишь подключение к SQL Server. Кстати, с помощью пакета sqlrutils стало просто создавать хранимую процедуру для кода R.
А что же насчет обучения модели?
Где модель обучалась? А обучалась она также в SQL Server. Однако обучать ее именно в SQL Server было вовсе не обязательно, это можно сделать и на отдельной машине с автономным решением R Server, работающим локально или через облако. Сегодня все эти новые алгоритмы машинного обучения доступны в версии R Server для Windows, а скоро появится поддержка и других платформ. Мне было удобнее выполнить обучение в поле SQL Server, но я мог бы сделать это и за его пределами. Взглянем на хранимую процедуру с кодом для обучения.
Код для обучения
Обучение модели происходит в этих строках кода:
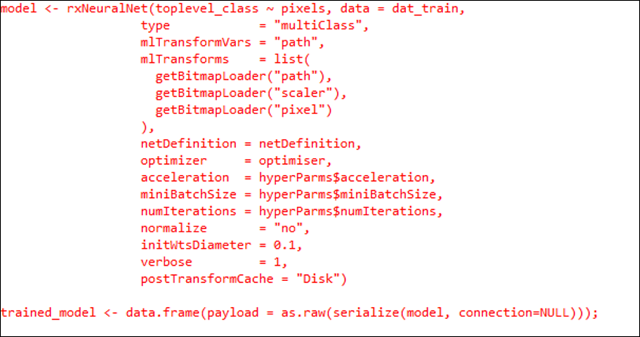
Это новая функция rxNeuralNet из пакета MicrosoftML для обучения глубокой нейронной сети. Данный код похож на другие функции R и rx — он также содержит формулу, входной набор данных и некоторые другие параметры. Один из параметров, которые мы здесь видим — строка netDefinition = netDefinition. Именно в ней определяется нейронная сеть.
Определение сети
Глубокая нейронная сеть определяется в этой части кода:
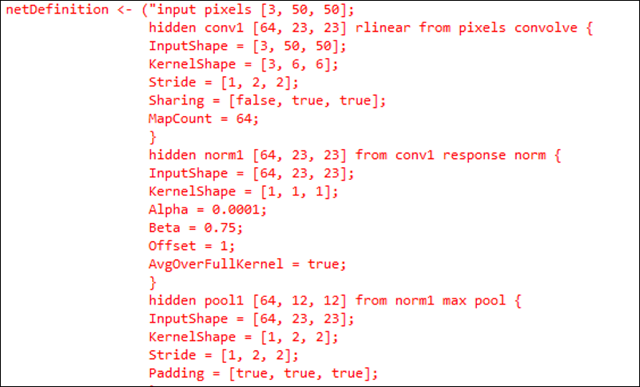
Здесь происходит определение глубокой нейронной сети с использованием языка спецификаций Net#, созданного специально для этого. Нейронная сеть содержит 1 входной, 1 выходной и 8 скрытых слоев. Она начинается с входного слоя размером 50×50 пикселей и графических данных в формате RGB (глубина 3 цвета). Первый скрытый слой представляет собой сверточный слой, где мы задаем размер ядра (небольшая часть изображения) и то, сколько раз ядро должно сопоставляться с остальными ядрами (свертываться). Существуют и другие слои для других видов сверток, а также для нормализации и регулирования количества запросов, помогающих стабилизировать данную нейронную сеть. И наконец, выходной слой, сопоставляющий ее с одним из 13 классов. С помощью примерно 50 строк спецификации Net# мной была определена сложная нейронная сеть. Руководство по Net# находится в разделе MSDN.
Размер обучаемых данных/GPU
Здесь находится код R для обучения модели:
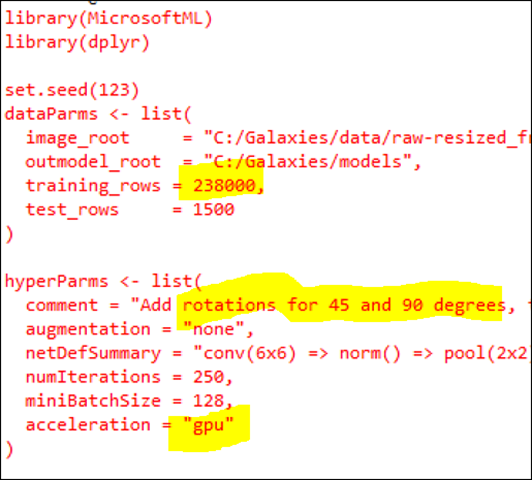
Хотелось бы рассказать еще о нескольких строках — training_rows = 238000. Эта модель обучалась на 238 000 изображений, полученных из базы данных проекта «Слоуновский цифровой небесный обзор» (Sloan Digital Sky Survey). Затем мы создали по два варианта каждого изображения, развернув их на 45 и 90%. Таким образом, всего получилось около 700 000 изображений для обучения. Это очень большой объем данных для обучения, так что встает вопрос, сколько же времени потребовалось, чтобы его обработать? Ответ: мы смогли обучить эту модель за 4 часа, использовав не слишком большую машину c 6-ядерным процессором и 56 ГБ оперативной памяти, а также мощный графический ускоритель Nvidia Tesla K80. Это новая графическая виртуальная машина NC-серии Azure, доступная для всех, кто оформил подписку Azure. Мы смогли оптимизировать скорость вычисления за счет использования графического процессора (GPU), задав один простой параметр: acceleration = «gpu». Без GPU обучение занимает примерно в 10 раз больше времени.
Резюмируя
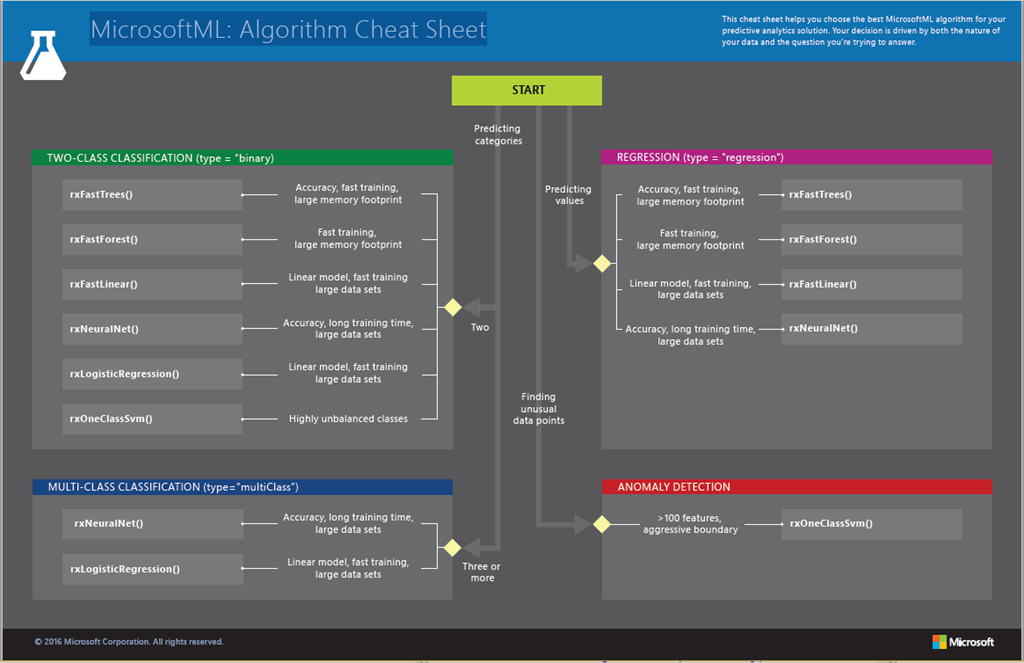
С помощью всего нескольких строк кода R и алгоритмов пакета MicrosoftML мне удалось обучить глубокую нейронную сеть на внушительном объеме графических данных и задействовать обученную модель в SQL с помощью служб R services, которые позволяют любому приложению, подключенному к SQL, легко получить эти интеллектуальные технологии. Вот в чем заключается сила языка Microsoft R и пакета MicrosoftML в сочетании с SQL Server. И это только начало, ведь мы работаем над созданием других алгоритмов, чтобы мощь искусственного интеллекта и машинного обучения стала доступна для всех. Чтобы подобрать подходящий алгоритм машинного обучения для прогнозно-аналитической модели, вы можете загрузить MicrosoftML: Algorithm Cheat Sheet здесь.