[Перевод] 1000-мерный куб: можно ли сегодня создать вычислительную модель человеческой памяти?
Сегодня утром на пути к кампусу Беркли я провёл пальцами по листьям ароматного куста, а затем вдохнул знакомый запах. Я делаю так каждый день, и каждый день первое слово, которое всплывает в голове и приветственно машет рукой — это шалфей (sage). Но я знаю, что это растение — не шалфей, а розмарин, поэтому я приказываю шалфею успокоиться. Но слишком поздно. После rosemary и sage я не могу помешать появлению на сцене петрушки (parsley) и чабреца (thyme), после чего в голове возникают первые ноты мелодии и лица на обложке альбома, и вот я уже снова оказался в середине 1960-х, одетый в рубашку с огурцами. Тем временем розмарин (rosemary) вызывает в памяти Роуз Мэри Вудс (Rosemary Woods) и 13-минутный пробел (хотя теперь, проконсультировавшись с коллективной памятью, я знаю, что это должны быть Роуз Мэри Вудс и пробел в 18 с половиной минут). От Уотергейта я перепрыгиваю к историям на главной странице. Потом я замечаю в ухоженном саду ещё одно растение с пушистыми серо-зелёными листями. Это тоже не шалфей, а чистец (lamb«s ear). Тем не менее, sage наконец получает свою минуту славы. От трав я переношусь к математическому ПО Sage, а потом к системе противовоздушной обороны 1950-х под названием SAGE, Semi-Automatic Ground Environment, которой управлял самый крупный из когда-либо построенных компьютеров.
В психологии и литературе подобные мыслительные блуждания называются потоком сознания (автор этой метафоры — Уильям Джеймс). Но я бы выбрал другую метафору. Моё сознание, насколько я ощущаю, не течёт плавно от одной темы к другой, а скорее порхает по ландшафту мыслей, больше похожее на бабочку, чем на реку, иногда прибиваясь к одному цветку, а затем к другому, иногда уносимая порывами ветка, иногда посещающая одно и то же место снова и снова.
Чтобы исследовать архитектуру собственной памяти я попытался провести более неспешный эксперимент со свободными ассоциациями. Я начал с того же флорального рецепта — петрушка, шалфей, розмарин и чабрец —, но для этого упражнения не прогуливался по садам холмов Беркли; я сидел за столом и делал заметки. Показанная ниже схема представляет собой наилучшую попытку реконструкции полного хода моих размышлений.
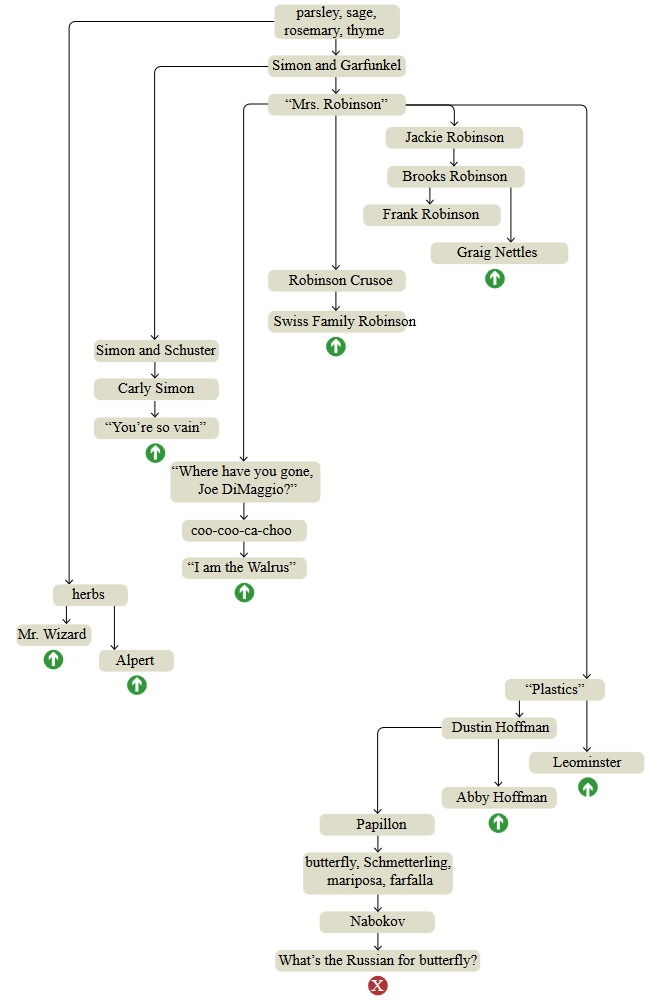
parsley, sage, rosemary, thyme — четыре травы, а также строчка из песни Simon and Garfunkel.
Simon and Garfunkel — Пол Саймон и Арт Гарфанкел, дуэт певцов в жанре фолк-рока 1960-х и 70-х.
Mrs. Robinson — песня Simon and Garfunkel, а также персонаж из фильма Майка Николса «The Graduate».
«Where have you gone, Joe DiMaggio?» — вопрос, задаваемый в «Mrs. Robinson».
Simon and Schuster — издательский дом, основанный в 1924 году Ричардом Саймоном и Максом Шустером (изначально для публикации кроссвордов).
Джеки Робинсон — легендарный игрок Brooklyn Dodgers.
Робинзон Крузо — роман Даниэля Дефо о потерпевшем кораблекрушение (1719 год).
Швейцарская семья Робинзонов — роман Йохана Дэвида Уайсса о потерпевших кораблекрушение (1812 год).
herbs (травы) — ароматные растения
Mr. Wizard — субботнее научное шоу 1950-х для детей, ведущий Дон Херберт.
Alpert — трубач Герб Алперт.
«Plastics» — совет по карьерному росту, предложенный в «The Graduate».
coo-coo-ca-choo — строчка из «Mrs. Robinson».
Фрэнк Робинсон — аутфилдер Baltimore Orioles в 1970-х.
Грэйг Неттлз — третий бейсмен New York Yankees в 1970-х.
Дастин Хоффман — актёр, игравший в «The Graduate».
Эбби Хоффман — «Yipee!»
Леоминстер — город в Массачусетсе, ставший колыбелью производства пластмасс в США.
Брукс Робинсон — третий бейсмен Baltimore Orioles в 1970-х.
Papillon («Мотылёк») — фильм 1973 года, в которой Дастин Хоффман исполнял второстепенную роль; «papillon» по-французски «бабочка».
Nabokov — Владимир Набоков, родившийся в России писатель и изучающий бабочек энтомолог.
butterfly, Schmetterling, mariposa, farfalla — «бабочка» на английском, немецком, испанском и итальянском; похоже, что все они (и французское слово тоже) имеют независимое происхождение.
Как по-русски называется бабочка — я не знаю. Или не знал, когда возник этот вопрос.
«I am the Walrus» — песня Beatles 1967 года, в которой тоже есть фраза «coo-coo-ca-choo».
Карли Саймон — певица. Никакой связи с Полом Саймоном, но является дочерью Ричарда Саймона.
«You«re so vain» — песня Карли Саймон.
График сверху вниз представляет собой темы в том порядке, котором они всплывали в мозгу, но связи между узлами не создают единую линейную последовательность. Структура напоминает дерево с короткими цепочками последовательных ассоциаций, заканчивающиеся резким возвратом к более раннему узлу, как будто меня утащило обратно растянувшейся резиновой лентой. Такие прерывания помечены на графике зелёными стрелками; красный крестик внизу — это место, на котором я решил завершить эксперимент.
Прощу прощения у тех, кто родился позже 1990 года, многие из упомянутых тем могут показаться вам устаревшими или загадочными. Под графиком представлены объяснения, однако не думаю, что они сделают ассоциации более понятными. В конце концов, воспоминания персональны, они живут внутри головы. Если вы хотите собрать коллекцию идей, соответствующих вашему собственному опыту, вам достаточно создать собственный график свободных ассоциаций. Крайне рекомендую сделать это: вы можете обнаружить что вы не знали, что знаете какие-то вещи.
Целью моей ежедневной прогулки вниз по холму в Беркли является Институт Саймонса и курс теории вычислений, в котором я участвую в длящейся один семестр программе, посвящённой мозгу и вычислениям. Такое окружение вызывает мысли о мыслях. Я начал размышлять: каким образом можно построить вычислительную модель процесса свободных ассоциаций? Среди различных задач, предлагаемых для решения искусственным интеллектом, эта выглядит довольно просто. Здесь нет необходимости в глубокой рационализации; всё, что нам нужно симулировать — это просто грёзы и витание в облаках — именно этим занимается мозг, когда он не нагружен. Похоже, что такую задачу решить легко, не правда ли?
Первая идея, которая приходит в голову (по крайней мере, в мою голову), относительно архитектуры такой вычислительной модели — это случайное движение по математическому графу или сети. Узлы сети — это хранящиеся в памяти элементы — идеи, факты, события —, а связи — это различные виды ассоциаций между ними. Например, узел «бабочка» может быть связан с «мотыльком», «гусеницей», «монархом» и «перламутровкой», , а ещё с переходами, упомянутыми в моём графике, и, возможно, иметь и менее очевидные связи, например «Australian crawl», «креветка», «Мохаммед Али», «пеллагра», «дроссель» и «страх сцены». Структура данных узла сети будет содержат список указателей на все эти связанные узлы. Указатели могут быть пронумерованы от 1 до n; программа будет генерировать псевдослучайное число в этом интервале и переходить к соответствующему узлу, в котором вся процедура будет начинаться заново.
Этот алгоритм отражает некоторые основные характеристики свободных ассоциаций, но многие из них не учитывает. Модель предполагает, что все целевые узлы равновероятны, что выглядит неправдоподобно. Чтобы учесть разницу вероятностей, мы можем задать каждому ребру  вес
вес  , а затем сделать вероятности пропорциональными весам.
, а затем сделать вероятности пропорциональными весам.
Ещё больше усложняет всё тот факт, что веса зависят от контекста — от недавней истории умственной активности человека. Если бы у меня не было сочетания Mrs. Robinson и Джеки Робинсона, то подумал ли бы я о Джо Ди Маджо? А сейчас, когда я пишу это, Joltin' Joe (прозвище Ди Маджо) вызывает в памяти Мэрилин Монро, а затем Артура Миллера, и я снова не могу остановить ход размышлений. Для воспроизведения этого эффекта в компьютерной модели потребуется некий механизм динамической регуляции вероятностей целых категорий узлов в зависимости от того, какие другие узлы были посещены недавно.
Также следует учесть эффекты новизны другого вида. В модели должна найти место резиновая лента, постоянно притягивающая меня обратно к Simon and Garfunkel и Mrs. Robinson. Вероятно, каждый недавно посещённый узел необходимо добавить в список вариантов целей, даже если он никак не связан с текущим узлом. С другой стороны, привыкание — это тоже вероятность: слишком часто вспоминаемые мысли становятся скучными, поэтому должны подавляться в модели.
Ещё одно, последнее испытание: некоторые воспоминания являются не изолированными фактами или идеями, а частями истории. У них есть нарративная структура с событиями, разворачивающимися в хронологическом порядке. Для узлов таких эпизодических воспроминаний требуется ребро next, а возможно и previous. Такая цепочка рёбер объединяет всю нашу жизнь, включая в себя всё, что вы помните.
Может ли подобная вычислительная модель воспроизвести мои умственные блуждания? Сбор данных для такой модели окажется довольно долгим процессом, и это неудивительно, ведь мне понадобилась вся жизнь, чтобы заполнить свой череп переплетением трав, Гербов, Саймонов, Робинсонов и Хоффманов. Гораздо больше, чем объём данных, меня волнует кропотливость алгоритма обхода графа. Очень легко сказать: «выбери узел согласо множеству взвешенных вероятностей», но когда я смотрю на грязные подробности реализации этого действия, то с трудом могу представить, что нечто подобное происходит в мозге.
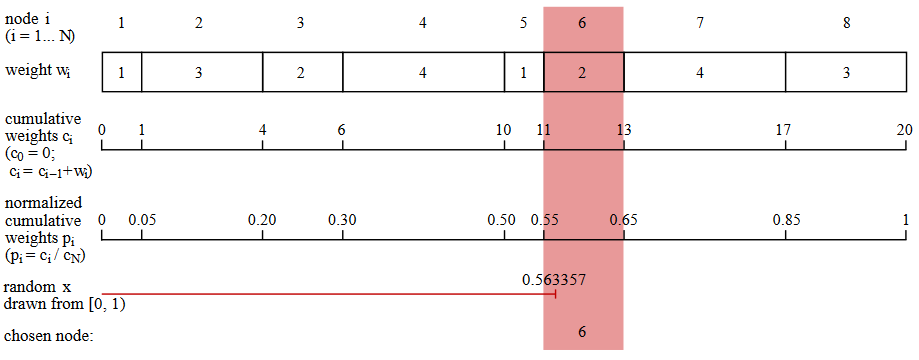
Вот простейший из известных мне алгоритм для случайного взвешенного выбора. (Это не самый эффективный из таких алгоритмов, но методы получше ещё более хаотичны. Кит Шварц написал отличный туториал и обзор по этой теме.) Предположим, что структура данных, имитирующая узел сети, включает в себя список связей с другими узлами и соответствующий список весов. Как показано на рисунке ниже, программа генерирует ряд накапливаемых сумм весов:  . Следующий шаг заключается в нормализации этого ряда делением каждого числа на общую сумму весов. Теперь у нас есть ряд чисел
. Следующий шаг заключается в нормализации этого ряда делением каждого числа на общую сумму весов. Теперь у нас есть ряд чисел  , монотонно возрастающий от нуля до единицы. Далее программа выбирает случайное вещественное число
, монотонно возрастающий от нуля до единицы. Далее программа выбирает случайное вещественное число  из интервала
из интервала  ; должно находиться в одном из нормализованных интервалов , а это значение определяет следующий выбираемый узел.
; должно находиться в одном из нормализованных интервалов , а это значение определяет следующий выбираемый узел.
В коде на языке программирования Julia процедура выбора узла выглядит так:
function select_next(links, weights)
total = sum(weights)
cum_weights = cumsum(weights)
probabilities = cum_weights / total
x = rand()
for i in 1:length(probabilities)
if probabilities[i] >= x
return i
end
end
end
Я так медленно описываю эти скучные подробности накапливаемых сумм и псевдослучайных чисел, чтобы подчеркнуть таким образом, что этот алгоритм обхода графа не так прост, как выглядит на первый взгляд. И мы всё ещё пока не рассмотрели тему изменения вероятностей на лету, хотя наше внимание плавает от темы к теме.
Ещё сложнее постичь процесс обучения — добавления в сеть новых узлов и рёбер. Я закончил мой сеанс свободных ассоциаций, когда пришёл к вопросу, на который не мог ответить: как по-русски называется бабочка? Но теперь я могу на него ответить. В следующий раз, когда я буду играть в эту игру, я добавлю в список слово babochka. В вычислительной модели вставка узла для слова babochka — это довольно простая задача, но наш новый узел также должен быть связан со всеми уже существующими узлами о бабочках. Более того, babochka сама по себе добавляет новые рёбра. Она фонетически близка к babushka (бабушка) — одному из нескольких русских слов в моём словаре. Суффикс -ochka уменьшительный, поэтому его нужно ассоциировать с французским -ette и итальянским -ini. Буквальное значение слова babochka — «маленькая душа», что предполагает ещё большее количество ассоциаций. В конце концов, изучение единственного нового слова может потребовать полной переиндексации всего дерева знаний.
Давайте попробуем другой метод. Забудем о случайном обходе сети с её спагетти из указателей на узлы. Вместо этого давайте просто хранить все схожие вещи по соседству. С точки зрения банков памяти цифрового компьютера это значит, что схожие вещи будут храниться по соседним адресам. Вот гипотетический сегмент памяти, центрированный на концепции dog. Соседние места заняты другими словами, понятиями и категориями, которые скорее всего будут вызваны мыслью о собаке (dog): очевидные cat (кошка) и puppy (щенок), различные породы собак и несколько конкретных собак (Скиппи — это наш семейный пёс, который был у меня в детстве), а также, возможно, более сложные ассоциации. У каждого элемента есть цифровой адрес. Адрес не имеет какого-то глубинного значения, но важно то, что все ячейки памяти пронумерованы по порядку.
| адрес | содержимое |
|---|---|
| 19216805 | god |
| 19216806 | the dog that didn«t bark in the night |
| 19216807 | Skippy |
| 19216808 | Lassie |
| 19216809 | canine |
| 19216810 | cat |
| 19216811 | dog |
| 19216812 | puppy |
| 19216813 | wolf |
| 19216814 | cave canem |
| 19216815 | Basset Hound |
| 19216816 | Weimaraner |
| 19216817 | dogmatic |
Задача неторопливого блуждания по этому массиву в памяти может быть довольно простой. Она может выполнять случайный обход адресов памяти, но преимущество будет отдаваться небольшим шагам. Например, следующий посещаемый адрес может определяться сэмплированием из нормального распределения, центрированного относительно текущего места. Вот код на Julia. (Функция randn() возвращает случайное вещественное число, полученное из нормального распределения со средним значением  и стандартным отклонением
и стандартным отклонением  .)
.)
function gaussian_ramble(addr, sigma)
r = randn() * sigma
return addr + round(Int, r)
end
У такой схемы есть привлекательные черты. Нет необходимости сводить в таблицу все возможные целевые узлы, прежде чем выбирать один из них. Вероятности не хранятся как числа, а закодированы позицией в массиве, а также модулированы параметром  , который определяет, насколько далеко процедура хочет перемещаться в массиве. Хотя программа всё равно выполняет арифметические действия для сэмлирования из нормального распределения, такая функция, вероятно, будет более простым решением.
, который определяет, насколько далеко процедура хочет перемещаться в массиве. Хотя программа всё равно выполняет арифметические действия для сэмлирования из нормального распределения, такая функция, вероятно, будет более простым решением.
Но всё-таки у этой процедуры есть ужасающий изъян. Окружив dog всеми его непосредственными ассоциациями, мы не оставили места для их ассоциаций. Собачьи термины хороши в своём собственном контексте, но как насчёт cat из списка? Куда нам поместить kitten, tiger, nine lives и Felix? В одномерном массиве нет никакой возможности встроить каждый элемент памяти в подходящее окружение.
Так что давайте перейдём в два измерения! Разделив адреса на два компонента, мы задаём две ортогональные оси. Первая половина каждого адреса становится координатой  , а вторая — координатой . Теперь dog и cat по-прежнему остаются близкими соседями, но также у них появляются личные пространства, в которых они могут играть с собственными «друзьями».
, а вторая — координатой . Теперь dog и cat по-прежнему остаются близкими соседями, но также у них появляются личные пространства, в которых они могут играть с собственными «друзьями».
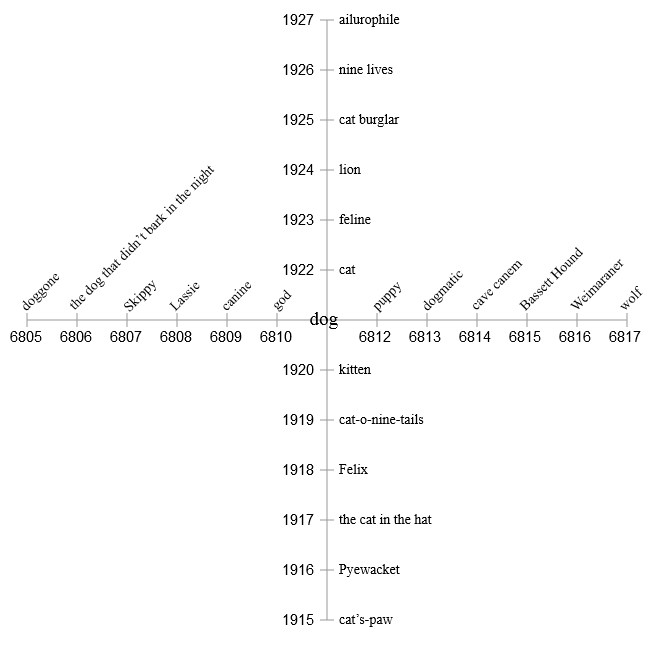
Однако двух измерений тоже недостаточно. Если мы попытаемся заполнить все элементы, связанные с The Cat in the Hat, они неизбежно начнут сталкиваться и конфликтовать с близкими элементами the dog that didn«t bark in the night. Очевидно, нам нужно больше измерений — намного больше.
Сейчас подходящий момент для того, чтобы признаться — я не первый, кто думал о том, как могут быть упорядочены воспоминания в памяти. Список моих предшественников можно начать с Платона, который сравнивал память с птицей; мы распознаём воспоминания по их оперению, но иногда нам трудно достать их, если они начинают порхать в клетке нашего черепа. Иезуит 16-го века Маттео Риччи писал о «дворце памяти», в котором мы блуждаем по различным комнатам и коридорам в поисках сокровищ прошлого. Современные теории памяти обычно менее образны, однако более подробны и нацелены на переход от метафоры к механизму. Лично мне больше всего нравится математическая модель, полученная в 1980-х Пентти Канерва, который сейчас работает в Редвудском центре теоретических нейронаук здесь, в Беркли. Он придумал идею разреженной распределённой памяти (sparse distributed memory), которую я буду называть SDM. В ней удачно применяется удивительная геометрия пространств высокой размерности.
Представьте куб в трёх измерениях. Если принять, что длина стороны равна единице измерения, то восемь векторов можно обозначить векторами из трёх двоичных цифр, начиная с  и заканчивая
и заканчивая  . В любой из вершин изменение единственного бита вектора приводит нас к вершине, являющейся ближайшим соседом. Изменение двух битов перемещает нас к следующему по близости соседу, а замена всех трёх битов приводит к противоположному углу куба — к самой отдалённой вершине.
. В любой из вершин изменение единственного бита вектора приводит нас к вершине, являющейся ближайшим соседом. Изменение двух битов перемещает нас к следующему по близости соседу, а замена всех трёх битов приводит к противоположному углу куба — к самой отдалённой вершине.
Четырёхмерный куб работает аналогичным образом —  вершин обозначены векторами, содержащими все сочетания двоичных цифр, начиная
вершин обозначены векторами, содержащими все сочетания двоичных цифр, начиная  и заканчивая
и заканчивая  . Это описание на самом деле обобщается до
. Это описание на самом деле обобщается до  измерений, где каждая вершина имеет -битный вектор координат. Если мы будем измерять расстояние по манхэттанской метрике — всегда перемещаясь вдоль рёбер куба и никогда не срезая по диагонали — то расстояние между любыми двумя векторами будет количеством позиций, в которых отличаются два вектора координат (оно также известно как расстояние Хэмминга). (Для исключающего ИЛИ обычно используют символ ⊕, иногда называемый булочкой (bun). Он отображает операцию XOR как двоичное сложение по модулю 2. Канерва предпочитает ∗ или ⊗ на том основании, что роль XOR в высокоразмерных вычислениях больше похожа на умножение, чем на сложение. Я решил устраниться от этого противоречия, воспользовавшись символом ⊻ — альтернативным способом записи XOR, привычным в среде логиков. Это модификация ∨ — символа включающего ИЛИ. Удобно, что он также является символом XOR в программах на Julia.) Таким образом, единицей измерения расстояния является один бит, а вычисление расстояния — это задача для оператора двоичного исключающего ИЛИ (XOR, ⊻), который даёт нам для отличающихся битов значение
измерений, где каждая вершина имеет -битный вектор координат. Если мы будем измерять расстояние по манхэттанской метрике — всегда перемещаясь вдоль рёбер куба и никогда не срезая по диагонали — то расстояние между любыми двумя векторами будет количеством позиций, в которых отличаются два вектора координат (оно также известно как расстояние Хэмминга). (Для исключающего ИЛИ обычно используют символ ⊕, иногда называемый булочкой (bun). Он отображает операцию XOR как двоичное сложение по модулю 2. Канерва предпочитает ∗ или ⊗ на том основании, что роль XOR в высокоразмерных вычислениях больше похожа на умножение, чем на сложение. Я решил устраниться от этого противоречия, воспользовавшись символом ⊻ — альтернативным способом записи XOR, привычным в среде логиков. Это модификация ∨ — символа включающего ИЛИ. Удобно, что он также является символом XOR в программах на Julia.) Таким образом, единицей измерения расстояния является один бит, а вычисление расстояния — это задача для оператора двоичного исключающего ИЛИ (XOR, ⊻), который даёт нам для отличающихся битов значение  , а для одинаковых пар — значение
, а для одинаковых пар — значение  :
:
0 ⊻ 0 = 0
0 ⊻ 1 = 1
1 ⊻ 0 = 1
1 ⊻ 1 = 0
Функция на Julia для измерения расстояния между вершинами применяет функцию XOR к двум векторам координат и возвращает в качестве результата количество .
function distance(u, v)
w = u ⊻ v
return count_ones(w)
end
Когда становится достаточно большим, проявляются некоторые любопытные свойства -куба. Рассмотрим  -мерный куб, имеющий
-мерный куб, имеющий  вершин. Если случайным образом выбрать две его вершины, то каким будет ожидаемое расстояние между ними? Хотя это и вопрос о расстоянии, но мы можем ответить на него, не углубляясь в геометрию — это всего лишь задача подсчёта позиций, в которых различаются два двоичных вектора. Для случайных векторов каждый бит может быть с равной вероятностью быть равным или , поэтому ожидается, что векторы будут различаться в половине битовых позиций. В случае -битного вектора стандартное расстояние равно
вершин. Если случайным образом выбрать две его вершины, то каким будет ожидаемое расстояние между ними? Хотя это и вопрос о расстоянии, но мы можем ответить на него, не углубляясь в геометрию — это всего лишь задача подсчёта позиций, в которых различаются два двоичных вектора. Для случайных векторов каждый бит может быть с равной вероятностью быть равным или , поэтому ожидается, что векторы будут различаться в половине битовых позиций. В случае -битного вектора стандартное расстояние равно  битам. Такой результат нас не удивляет. Однако стоит заметить то, что все расстояния между векторами тесно скапливаются вокруг среднего значения в 500.
битам. Такой результат нас не удивляет. Однако стоит заметить то, что все расстояния между векторами тесно скапливаются вокруг среднего значения в 500.
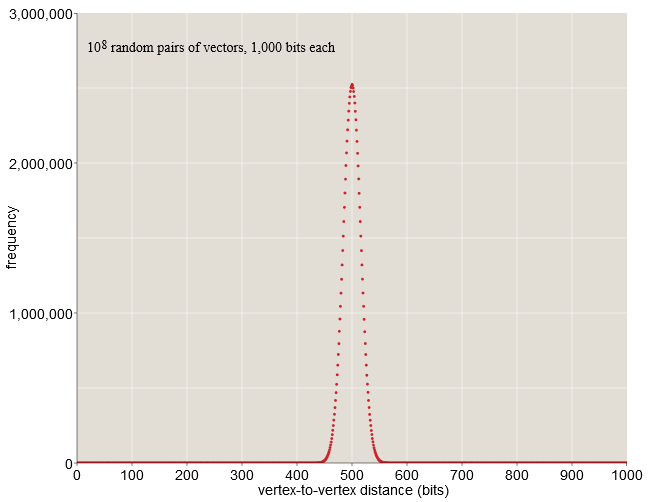
В случае -битных векторов почти все случайно выбранные пары находятся на расстоянии от  до
до  бит. В выборке из ста миллионов случайных пар (см. график выше) ни одна из них не ближе, чем
бит. В выборке из ста миллионов случайных пар (см. график выше) ни одна из них не ближе, чем  бит или дальше, чем
бит или дальше, чем  бит. Ничто в нашей жизни в пространстве низкого разрешения не готовило нас к такому скоплению вероятностей в среднем расстоянии. Здесь, на Земле, мы можем найти место, в котором будем совсем одни, когда почти все находятся в нескольких тысячах километров от нас; однако нет никакого способа перераспределить население планеты таким образом, чтобы каждый одновременно находится в таком состоянии. Но в -мерном пространстве ситуация именно такова.
бит. Ничто в нашей жизни в пространстве низкого разрешения не готовило нас к такому скоплению вероятностей в среднем расстоянии. Здесь, на Земле, мы можем найти место, в котором будем совсем одни, когда почти все находятся в нескольких тысячах километров от нас; однако нет никакого способа перераспределить население планеты таким образом, чтобы каждый одновременно находится в таком состоянии. Но в -мерном пространстве ситуация именно такова.
Не стоит и говорить, что сложно представить себе -мерный куб, но мы можем приобрести небольшое интуитивное понимание геометрии хотя бы на примере пяти измерений. Ниже представлена таблица всех координат вершин в пятимерном кубе единичной размерности, выстроенных в соответствии с расстоянием Хэмминга от исходной точки  . Большинство вершин (20 из 32) находится на средних расстояниях — два или три бита. Таблица имела бы одинаковую форму при любой другой вершине, взятой в качестве исходной точки.
. Большинство вершин (20 из 32) находится на средних расстояниях — два или три бита. Таблица имела бы одинаковую форму при любой другой вершине, взятой в качестве исходной точки.

Серьёзное возражение всем этим обсуждениям -мерных кубов заключается в том, что мы никогда не сможем построить нечто подобное; во Вселенной недостаточно атомов для структуры из частей. Но Канерва указывает на то, что нам нужны пространства для хранения только тех элементов, которые мы хотим хранить. Мы можем сконструировать оборудование для случайной выборки, например  вершин (каждая из которых имеет -битный адрес) и оставить остальную часть куба призрачной, недостроенной инфраструктурой. Канерва называет такое подмножество вершин, существующее в «железе», твёрдыми ячейками (hard locations). Множество из случайных твёрдых ячеек всё равно будет демонстрировать то же сжатое распределение расстояний, что и полный куб; именно это и показано на графике выше.
вершин (каждая из которых имеет -битный адрес) и оставить остальную часть куба призрачной, недостроенной инфраструктурой. Канерва называет такое подмножество вершин, существующее в «железе», твёрдыми ячейками (hard locations). Множество из случайных твёрдых ячеек всё равно будет демонстрировать то же сжатое распределение расстояний, что и полный куб; именно это и показано на графике выше.
Относительная изоляция каждой вершины в высокоразмером кубе даёт нам намёк на одно возможное преимущество разряжённой распределённой памяти: у хранящегося элемента есть достаточно простора и он может распределяться по обширной области, не мешая своим соседям. Это действительно выдающаяся характеристика SDM, но есть и кое-что ещё.
В традиционной компьютерной памяти адреса и хранимые элементы данных сопоставляются один к одному. Адреса — это порядковые целые числа фиксированного диапазона, допустим  . Каждое целое число в этом диапазоне определяет единственное отдельное место в памяти, и каждое место связано ровно с одним адресом. Кроме того, в каждом месте одновременно хранится только одно значение; при записи нового значения старое переписывается.
. Каждое целое число в этом диапазоне определяет единственное отдельное место в памяти, и каждое место связано ровно с одним адресом. Кроме того, в каждом месте одновременно хранится только одно значение; при записи нового значения старое переписывается.
SDM нарушает все эти правила. Она обладает огромным адресным пространством — не менее —, но только крошечная, случайная доля этих мест существует как физические сущности; именно поэтому память называется разреженной. Отдельный элемент информации не хранится всего в одном месте памяти; множество копий распределено по области — поэтому она распределённая. Более того, в каждом отдельном адресе может одновременно храниться несколько элементов данных. То есть информация и размазана по широкой области, и втиснута в одну точку. Такая архитектура также размывает различия между адресами памяти и содержимым памяти; во многих случаях сохраняемый битовый паттерн используется в качестве собственного адреса. Наконец, память может отзываться на частичный или приблизительный адрес и с высокой вероятностью находить правильный элемент. В то время как традиционная память является «механизмом точного совпадения», SDM — это «механизм наилучшего совпадения», возвращающий элемент, наиболее схожий с запрошенным.
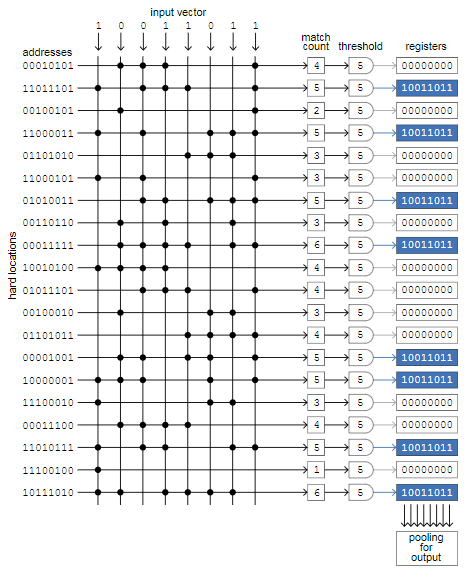
В своей книги 1988 года Канерва даёт подробный количественный анализ разреженной распределённой памяти с измерениями и  твёрдых ячеек. Твёрдые ячейки выбираются случайным образом из всего пространства возможных векторов адресов. Каждая твёрдая ячейка имеет пространство для хранения множества -битных векторов. Память в целом рассчитана на хранение не менее
твёрдых ячеек. Твёрдые ячейки выбираются случайным образом из всего пространства возможных векторов адресов. Каждая твёрдая ячейка имеет пространство для хранения множества -битных векторов. Память в целом рассчитана на хранение не менее  уникальных паттернов. Ниже я буду рассматривать эту память как каноническую SDM-модель, несмотря на то, что по стандартам млекопитающих она маловата, и в более новой своей работе Канерва сделал упор на векторы не менее чем с измерений.
уникальных паттернов. Ниже я буду рассматривать эту память как каноническую SDM-модель, несмотря на то, что по стандартам млекопитающих она маловата, и в более новой своей работе Канерва сделал упор на векторы не менее чем с измерений.
Вот как работает память в простой компьютерной реализации. Команда store(X) записывает в память вектор  , считая его одновременно и адресом, и содержимым. Значение сохраняется во все твёрдые ячейки, находящиеся в пределах определённого расстояния до . В канонической модели это расстояние равно 451 битам. Оно задаёт «круг доступа», предназначенного для объединения в себе примерно твёрдых ячеек; иными словами, каждый вектор хранится примерно в
, считая его одновременно и адресом, и содержимым. Значение сохраняется во все твёрдые ячейки, находящиеся в пределах определённого расстояния до . В канонической модели это расстояние равно 451 битам. Оно задаёт «круг доступа», предназначенного для объединения в себе примерно твёрдых ячеек; иными словами, каждый вектор хранится примерно в  -ной из миллиона твёрдых ячеек.
-ной из миллиона твёрдых ячеек.
Важно также заметить, что хранимый элемент не обязательно выбирать из двоичных векторов, являющихся адресами твёрдых ячеек. Напротив. может быть любым из возможных двоичных паттернов.
Предположим, что в SDM уже записана тысяча копий , после чего поступает новый элемент  , который тоже нужно сохранить в собственном множестве из тысячи твёрдых ячеек. Между двумя этими множествами может быть пересечение — места, в которых хранятся и , и . Новое значение не перезаписывает и не заменяет предыдущее; оба значения сохраняются. Когда память заполняется до своей ёмкости в , каждый из них сохранён раз, а в типичной твёрдой ячейке будут храниться копии
, который тоже нужно сохранить в собственном множестве из тысячи твёрдых ячеек. Между двумя этими множествами может быть пересечение — места, в которых хранятся и , и . Новое значение не перезаписывает и не заменяет предыдущее; оба значения сохраняются. Когда память заполняется до своей ёмкости в , каждый из них сохранён раз, а в типичной твёрдой ячейке будут храниться копии  уникальных паттернов.
уникальных паттернов.
Теперь вопрос заключается в следующем: как же нам воспользоваться этой перемешанной памятью? В частности, как нам получить правильное значение , не влияя на и на все остальные элементы, накопившиеся в одном месте хранения?
В алгоритме считывания будет использоваться свойство любопытного распределения расстояний в высокоразмерном пространстве. Даже если и являются ближайшими соседями из хранящихся паттернов, они скорее всего будут отличаться на 420 или 430 бит; поэтому количество твёрдых ячеек, в которых хранятся оба значения, достаточно мало — обычно четыре, пять или шесть. То же самое относится и ко всем другим паттернам, пересекающимся с . Их тысячи, но ни один из влияющих паттернов не присутствует более чем в нескольких копиях внутри круга доступа .
Команда fetch(X) должна возвращать значение, ранее записанное командой store(X). Первый этап в воссоздании значения — это сбор всей информации, хранящейся внутри 451-битного круга доступа, центрированного на . Поскольку ранее был записан во все эти места, мы можем быть уверены, что получим его копий. Мы также получим около копий других векторов, хранящихся в местах, в которых круги доступа пересекаются с с кругами . Но поскольку пересечения малы, каждый из этих векторов присутствует только в нескольких копиях. Тогда в целом каждый из их бит равновероятно может быть или . Если мы применим функцию принципа большинства ко всем данным, собранным в каждой битовой позиции, то в полученном результате будут доминировать копий . Вероятность получения отличающегося от результата примерно равна  .
.
Процедура принципа большинства подробнее показана ниже на небольшом примере из пяти векторов данных по 20 битов каждый. Выходными данными будет являться другой вектор, каждый бит которого отражает большинство соответствующих битов в векторах данных. (Если количество векторов данных чётное, то «ничьи» разрешаются случайным выбором или .) Альтернативная схема записи и чтения, показанная ниже, отказывается от хранения всех паттернов по отдельности. Вместо этого она хранит итоговое количество битов и в каждой позиции. Твёрдая ячейка имеет -битный счётчик, инициализируемый всеми нулями. При записи паттерна в место каждый битовый счётчик увеличивается для или уменьшается для . Алгоритм считывания просто смотрит на знак каждого битового счётчика, возвращая для положительного значения, для отрицательного и случайное значение, когда бит счётчика равен .

Две эти схемы хранения дают идентичные результаты.
С точки зрения вычислительной техники эта версия разреженной распределённой памяти выглядит как тщательно продуманная шутка. Для запоминания © Habrahabr.ru
