[Из песочницы] Занимательная археология: стилевое руководство R под лупой
Как известно, код читают намного чаще, чем пишут. Чтобы его мог читать хоть кто-то, кроме автора, и существуют стилевые гиды. Для R таковым может быть, например, руководство Хэдли.
Стилевой гид это не просто негласный договор разработчиков — за многими из правил стоит любопытная предыстория. Почему стрелка <- лучше знака равенства =, почему старожилы R не любят нижнее подчеркивание, как рекомендуемая длина строки связана с перфокартой, и о многом другом — далее.
Тем не менее, гид Хэдли можно считать самым распространённым (как встроенная проверка RStudio, например), чему в немалой степени способствует популярность библиотек, созданных самим Хэдли (dplyr, ggplot, tidyr, и других из коллекции tidyverse).
1. Оператор присваивания: <- vs =
Все доступные гиды рекомендуют использовать нестандартный оператор <-, а вовсе не знак равенства =, привычный для других современных языков. Три других оператора (<<-, ->, ->>) даже не упоминаются (как и существовавший в ранних версиях :=). Казалось бы, зачем нужна эта нестандартная стрелка?
История приоткрывает нам карты: в R стрелка пришла из S, который в свою очередь, унаследовал её от APL. В языке APL она позволяла отличить присвоение от равенства. В R оператор равенства стандартный, так что разница в другом. Если стрелка была оператором присвоения изначально, то знак равенства присваивал значения только именованным параметрам. В 2001 году знак равенства стал оператором присвоения, но так и не стал синонимом стрелки.
Что же позволяет считать = полноценной заменой стрелке? Прежде всего, = как оператор присвоения работает только на верхнем уровне. Например, внутри функции всё будет работать по-старому:
mean(x = 1:5)
# [1] 3
x
# Error: object 'x' not found
mean (x <- 1:5)
# [1] 3
x
# [1] 1 2 3 4 5
Здесь = только задаёт параметр функции, в то время как <- ещё и присваивает значение переменной x. Мы можем добиться такого же эффекта, поместив операцию присваивания в скобки (нет, это всё ещё не Lisp):
mean ((x = 1:5))
# [1] 3
x
# [1] 1 2 3 4 5
… или в фигурные скобки:
mean ({x = 1:5})
# [1] 3
x
# [1] 1 2 3 4 5
Помимо этого, стрелка имеет приоритет над знаком равенства:
x <- y <- 1
# OK
x = y = 2
# OK
x = y <- 3
# OK
x <- y = 4
# Error in x <- y = 4 : could not find function "<-<-"
Последнее выражение завершилось ошибкой потому что эквивалентно (x <- y) = 4, и парсер интерпретирует его как
`<-<-`(x, y = 4, value = 4)
Иными словами, мы пытаемся выполнить некорректную операцию: сначала присваиваем x значение y, а затем пытаемся присвоить x и y значение 4. Выражение будет обработано без ошибок только если поменять приоритет операций скобками: x <- (y = 4).
2. Spacing
Гид рекомендует ставить пробелы между операторами (кроме, естественно, квадратных скобок, :, :: и :::), а также перед открывающей скобкой. Вполне очевидно, что это часть стандартов кодирования GNU. Впрочем, этот пункт тесно связан с использованием <- как оператора присвоения. Например,
x <-1
Что это? X меньше -1? Или присвоить x значение 1?
Впрочем, лишний пробел ничуть не лучше недостающего, например:
x <- 0
ifelse(x <-1, T, F)
# [1] TRUE
x <- 0
ifelse(x < -1, T, F)
# [1] FALSE
В первом случае нет пробела между < и -, что создаёт оператор присваивания.
3. Имена функций и переменных
В вопросе имён стилевые руководства расходятся: гид Хэдли рекомендует нижнее подчёркивание для всех имен; Гид Google — разделение точками для переменных и стиль верблюда с первой строчной для функций; Bioconductor рекомендует lowerCamel как для функций, так и для переменных. В этом вопросе в сообществе R нет единства, и можно встретить все возможные стили:
lowerCamel
period.separation
lower_case_with_underscores
allowercase
UpperCamel
Единого стиля нет даже именах base R (например, rownames и row.names это разные функции!). Если не брать во внимание нечитабельный allowercase (его могут любить только пользователи Matlab), можно выделить три самых популярных стиля: lowerCamel, нижний регистр с _, и нижний регистр с разделением точками.
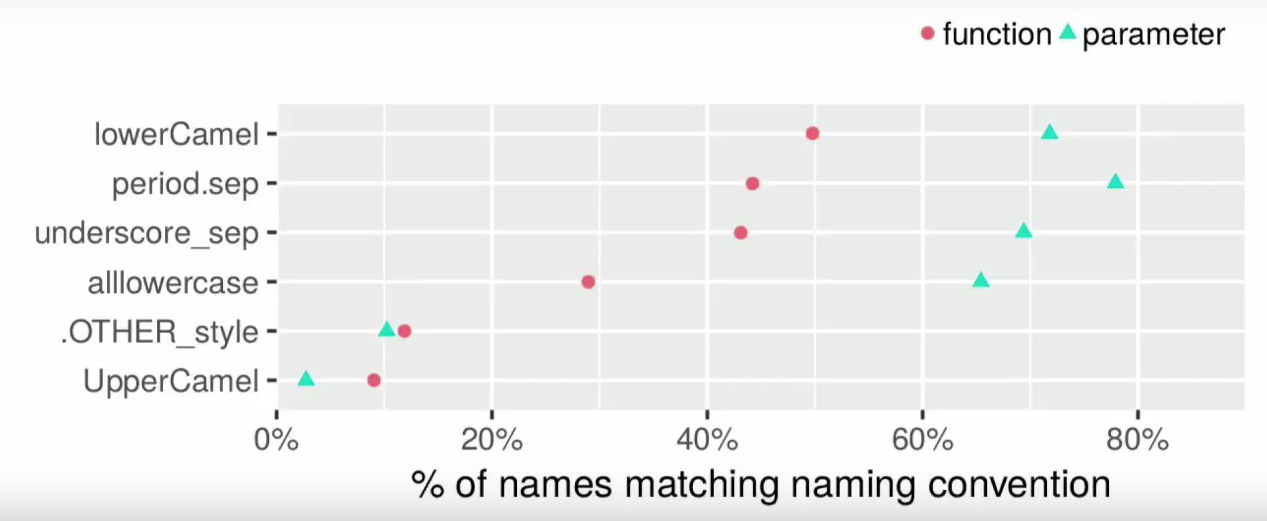
Популярность разных стилей для названий функций и параметров (одно название может отвечать разным стилям). Источник: выступление Rasmus Bååth на useR!2017.
Разделение точками зловеще напоминает использование методов в объектно-ориентированном программировании, но исторически распространено. Настолько распространено, что именно этот стиль можно считать истинно R«вским. Например, большинство базовых функций используют именно его (а с data.table и as.factor точно встречался каждый).
А вот разделение _ является одним из наименее популярных стилей (и здесь Хэдли идёт против большинства). Для многих пользователей R нижнее подчёркивание будет раздражителем: в популярном расширении Emacs Speaks Statistics оно по умолчанию заменяется на оператор присвоения <-. А настройки по умолчанию, конечно же, почти никто не меняет.
Впрочем, влияние Emacs ESS — это всё ещё объяснение из разряда «хвост виляет собакой». Есть и более древняя причина: в ранних версиях R нижнее подчёркивание было синонимом стрелки <-. Например, в 2000 году можно было встретить такое:
# имело место в ранних версиях R
c <- c(1,2,3,4,5)
mean(c)
[1] 3
c_mean <- mean(c)
c
[1] 3
Здесь вместо того, чтобы создать переменную c_mean R присвоил значение 3 сначала переменной mean, а затем переменной c. В современном R такие метаморфозы, конечно же, происходить не будут.
Из-за непопулярности _ функции такого стиля почти не встречаются среди базовых:
# в 3.5.1 всего 25 функций
grep("^[^\\.]*$", apropos("_"), value = T)
Наконец, стиль lowerCamel отличается низкой читабельностью при использовании длинных имён:
# ой!
GrossNationalIncomePerCapitaAtlasMethodCurrentUnitedStatesDollars
Таким образом, в плане имён рекомендации гида нельзя считать однозначными; всё-таки это дело вкуса (до тех пор пока в этом наблюдается последовательность).
4. Фигурные скобки
Согласно гиду, после открывающей фигурной скобки должна следовать новая строка, а закрывающая находиться на отдельной строке (если только за ней не следует else). Т.е. примерно так:
if (x >= 0) {
log(x)
} else {
message("Not applicable!")
}
Здесь всё не очень интересно: это стандартный стиль отступов K&R, восходящий к языку C и знаменитой книге Кернигана и Ритчи «The C Programming Language» (или K&R по именам авторов).
Истоки этого стиля тоже вполне очевидны: он позволяет экономить строки, сохраняя при этом читабельность. Для ранних компьютеров вертикальное пространство было слишком большой роскошью. Например, C был разработан на PDP-11, в терминале которого было всего 24 строки. Да и при печати книги K&R этот стиль экономил бумагу!
5. Строка на 80 символов
Рекомендуемая длина строки согласно гиду — 80 символов. Волшебное число 80 встречаются не только в R, но и огромном количестве других языков (Java, Perl, PHP, и т.д. и т.п.). И не только языков: даже командная строка Windows состоит из 80 символов.
Впервые в программировании это число появилось в 1928 г. вместо со стандартной перфокартой IBM, где было ровно 80 колонок для данных. Куда более интересный вопрос — почему был выбран именно такой стандарт? Ведь ранее использовались и перфокарты другой длины (на 24 или 45 колонок).

Самый популярный ответ связывает длину перфокарты с длиной строки у печатных машинок. Первые машинки были рассчитаны на американский стандарт бумаги 8½ x 11 дюймов, и позволяли печатать от 72 до 90 символов, в зависимости от размера полей. Поэтому версия о 80 символах в строке выглядит вполне правдоподобной, хотя и не правдой в последней инстанции. Вполне возможно, что 80 символов — это просто золотая середина в плане эргономики.
6. Отступ строки: пробелы vs табуляция
Рекомендуемый гидом стиль — это два пробела, а не табуляция. Отказ от табуляции вполне понятен: длина TAB«а варьируется в разных текстовых редакторах (это может быть что угодно от 2 до 8 пробелов). Отказываясь о них, мы получаем сразу два преимущества: во-первых, код будет выглядеть точно также, как мы его набрали; во-вторых, не произойдёт случайного нарушения рекомендуемой длины строки. При этом мы, конечно же, увеличиваем размер файла (кто хочет заниматься такой микрооптимизаций в 2k19 году?)
Спор пробелы vs табуляция имеет давнюю историю, и может приравниваться к религиозным (как, например, Win vs Linux, Android vs iOS, и тому подобные). Впрочем, мы уже знаем, кто в нём победил: согласно исследованию Stack Overflow, разработчики, использующие пробелы, зарабатывают больше, чем те, кто использует табуляцию. Более весомый аргумент, чем правила стилевого гида, не так ли?
Вместо заключения: правила стилевых гидов могут казаться странными и нелогичными. Действительно, зачем стрелка <-, если есть стандартный оператор =? Но если копнуть глубже, то за каждым правилом стоит некоторая логика, часто уже подзабытая.
