[Из песочницы] Выбор между XML и SQL для накатывания скриптов LiquiBase на примере Java/Spring/H2
В процессе работы над очередным проектом в команде возникли споры по поводу использования формата XML или SQL в Liquibase. Естественно про Liquibase уже написано много статей, но как всегда хочется добавить свои наблюдения. В статье будет представлен маленький туториал по созданию простенького приложения с бд и рассмотрим разницу метаинформации по данным типам.
Liquibase — это независимая от базы данных библиотека для отслеживания, управления и применения изменений схем базы данных. Для того, чтобы внести изменения в БД, создается файл миграции (*changeset*), который подключается в главный файл (*changeLog*), который контролирует версии и управляет всеми изменениями. В качестве описания структуры и изменений базы данных используется XML, YAML, JSON и SQL форматы.
Основная концепция миграций БД, выглядит следующим образом:
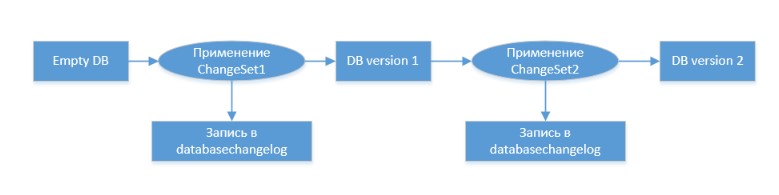
Более подробную информацию по Liquibase можно узнать тут или тут. Надеюсь общая картинка ясна, так что перейдем к созданию проекта.
В тестовом проекте используется
- Java 8
- Spring-boot
- Maven
- H2
- ну и сам liquibase
Создание проекта и зависимости
Использование Spring-boot здесь ничем не обусловлено, можно обойтись просто maven-plugin для накатывания скриптов. Итак, приступим.
1. Создаем в IDE maven-проект и в pom файл добавляем следующие зависимости:
org.springframework.boot
spring-boot-starter-web
org.liquibase
liquibase-core
3.6.3
org.springframework.boot
spring-boot-starter-test
test
com.h2database
h2
runtime
2. В папке resources создать файл application.yml и добавить следующие строчки:
spring:
liquibase:
change-log: classpath:/db/changelog/db.changelog-master.yaml
datasource:
url: jdbc:h2:mem:test;
platform: h2
username: sa
password:
driverClassName: org.h2.Driver
h2:
console:
enabled: true
Строка liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml — сообщает нам, где находится файл со списком скриптов liquibase.
3. В папке resources по пути db.changelog-master создаем cследующие файлы:
- xmlSchema.xml — скрипт изменений в формате xml
- sqlSchema.sql — скрипт изменений в формате sql
- data.xml — добавление данных в таблицу
- db.changelog-master.yml — список changeSet –ов
4. Добавление данных в файлы:
Для теста необходимо создать две несвязанные т
аблицы и минимальный набор данных.
В файл sqlSchema.sql добавляем всеми известный sql синтаксис:
--liquibase formatted sql
--changeset TestUsers_sql:1
CREATE TABLE test_sql_table
(
name VARCHAR NOT NULL,
description VARCHAR
);
--changeset TestUsers_sql:2
CREATE TABLE test_sql_table_2
(
name VARCHAR NOT NULL,
description VARCHAR
);
Использование sql в качестве changeset-ов обуславливается легким написанием скриптов. В файлах всем понятный, обычный sql.
Для разделения changeset используется комментарий:
--changeset TestUsers_sql:1 с указанием номера изменений и фамилии
(параметры можно посмотреть тут.)
В файл xmlSchema.sql добавляем DSL, который предоставляет liquibase:
Данный формат описания создания таблиц является универсальным для разных баз данных. Прям как лозунг джавы: «Написано однажды, работает везде». Liquibase использует xml-описание и компилирует его в определенных sql код, в зависимости от выбранной базы данных. Что очень удобно, для общих параметров.
Каждая операция выполняется в отдельном changeSet, с указанием id и имени автора. Думаю, язык, используемый в xml, очень прост к пониманию и даже не требует объяснения.
5. Загрузим в наши таблички данные, это делать не обязательно, но раз уж сделали таблички, надо в них чего-нить положить. Заполняем файл data.xml, следующими данными:
Файлы для накатывания таблиц созданы, данные для таблиц созданы. Пришло время объединить все это в общий порядок накатывания и запустить наше приложение.
В файл db.changelog-master.yml добавляем наши sql и xml файлы:
databaseChangeLog:
- include:
# schema
file: db/changelog/xmlSchema.xml
- include:
file: db/changelog/sqlSchema.sql
# data
- include:
file: db/changelog/data.xml
И теперь, когда у нас все создано. Просто запустим наше приложение. Для запуска можно использовать командную строку или плагин, но мы создадим просто main метод и запустим наше SpringApplication.
Просмотр метаинформации
Теперь, когда мы запустили наши два скриптика на создание и заполнение таблиц, мы можем посмотреть таблицу databaseChangeLog и увидеть, что накатилось.

Результат накатывания xml:
- В поле id от файлов xml попадает заголовок, который разработчик указывает в changeSet, каждый отдельный changeSet является отдельной строчкой в базе с указанием заголовка и описания.
- Указывается автор каждого изменения.
Результат накатывания sql:
- В поле id от файлов sql нет подробной информации об changeSet.
- Не указывается автор каждого изменения.
Еще одно важное заключение в сторону использования xml — это rollback. Такие команды как create table, alter table, add column имеют автоматический откат, при использовании xml. Для sql файлов каждый rollback необходимо писать вручную.
Вывод
Каждый выбирает для себя сам, что ему использовать. Но наш выбор пал все таки на сторону xml. Подробная метаинформация и легкий переход на другие БД, перевесили чашу весов от всеми любимого sql-формата.
