[Из песочницы] Варим ML Boot Camp III: Starter Kit

16 марта закончилось соревнование по машинному обучению ML Boot Camp III. Я не настоящий сварщик, но, тем не менее, смог добиться 7 го места в финальной таблице результатов. В данной статье я хотел бы поделиться тем, как начать участвовать в такого рода чемпионатах, на что стоит обратить внимание в первый раз при решении задачи и рассказать о своем подходе.
ML Boot Camp III
Это открытый чемпионат по машинному обучению организованный Mail.Ru Group. В качестве задания предлагалось предсказать, останется игрок в онлайн игре или уйдет из нее. В качестве данных организаторы дали уже обработанную статистику по пользователям за последние 2 недели.
- maxPlayerLevel — максимальный уровень игры, который прошел игрок;
- numberOfAttemptedLevels — количество уровней, которые попытался пройти игрок;
- attemptsOnTheHighestLevel — число попыток, сделанных на самом высоком уровне;
- totalNumOfAttempts — общее число попыток;
- averageNumOfTurnsPerCompletedLevel — среднее количество ходов, выполненных на успешно пройденных уровнях;
- doReturnOnLowerLevels — делал ли игрок возвраты к игре на уже пройденных уровнях;
- numberOfBoostersUsed — количество использованных бустеров;
- fractionOfUsefullBoosters — количество бустеров, использованных во время успешных попыток (игрок прошел уровнь);
- totalScore — общее количество набранных очков;
- totalBonusScore — общее количество набранных бонусных очков;
- totalStarsCount — общее количество набранных звезд;
- numberOfDaysActuallyPlayed — количество дней, когда пользователь играл в игру.
Более подробно о чемпионате можно узнать на сайте проекта.
Читаем правила

В отличии от инструкций к бытовой технике, тут есть полезная информация. На что обратить внимание:
- форматы входных и выходных данных;
- максимальное количество посылок в день;
- критерий качества/функция оценки.
Последняя, пожалуй, самая важная часть правил, т.к. именно эту функцию нам и нужно будет минимизировать (иногда максимизировать). В этот раз была использована логарифмическая функция потерь:
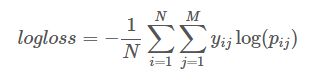
Здесь
N — это количество примеров
M — это количество классов (их всего два)
Pij — это предсказанная вероятность принадлежности примера i к классу j
Yij — равняется 1 если пример i действительно принадлежит классу j и 0 в противном случае
Важно отметить, что данная формула сильно «наказывает» самоуверенность в ответах. Поэтому в качестве решения выгоднее посылать вероятность того, что игрок продолжит играть вместо однозначных »1» и »0».
Иногда изучение функции оценки позволяет слегка схитрить и получить дополнительные баллы (как это сделал победитель прошлого и текущего соревнований).
Больше информации по разным метрикам можно прочитать здесь.
Инструментарий

Существует много инструментов, которые можно использовать во время чемпионата. Если же разговоры людей про машинное обучение звучат для вас как ругательства, то могу посоветовать проскакать галопом по ML и ознакомиться с основными алгоритмами тут.
В этот раз, большинство участников выбирали между Python и R. Общая рекомендация — придерживаться одного языка и более глубоко изучать возможности доступных инструментов. Для обоих языков есть хорошие решения, а самые популярные библиотеки (например XGBoost) доступны и там и там.
В случае же острой необходимости всегда можно сделать какой-то отдельный расчет используя другой пакет. Например, t-SNE преобразование, которое в python реализации беспомощно падает съедая всю память.
Я выбрал python и мое финальное решение использовало следующие библиотеки:
- scikit learn — большой набор инструментов для машинного обучения. Изначально можно ограничится только ей.
- XGBoost — градиентный бустинг. Одна из самых любимых библиотек участников чемпионатов по машинному обучению.
- LightGBM — альтернатива XGBoost, в моем случае она работала на порядок быстрее последнего, но выдавала чуть менее точные результаты.
- Lasagne — библиотека для создания и обучения нейронных сетей с использованием Theano. Как альтернативу можно попробовать Keras — она выглядит чуть более простой и документации по ней попадалось больше. Но коней на переправе не меняют и я решил придерживаться первоначального выбора.
Первый сабмит

Для начала попробуем прочитать все входные данные и вывести пробный ответ состоящий из одних нулей.
>>> import numpy as np
>>> import pandas as pd
>>> X_train = pd.read_csv('x_train.csv', sep=';')
>>> X_test = pd.read_csv('x_test.csv', sep=';')
>>> y_train = pd.read_csv('y_train.csv', header=None).values.ravel()
>>> print(X_train.shape, X_test.shape, y_train.shape)
(25289, 12) (25289, 12) (25289,)
>>> result = np.zeros((X_test.shape[0]))
>>> pd.DataFrame(result).to_csv('submit.csv', index=False, header=False)После того как проверили загрузку/сохранение данных и получили точку отсчета для оценки, можно обучить несложную модель. В качестве примера, я взял RandomForestClassifier.
>>> from sklearn.ensemble import RandomForestClassifier
>>> clf = RandomForestClassifier()
>>> clf.fit(X_train, y_train)
>>> result = clf.predict_proba(X_test)[:,1]
>>> pd.DataFrame(result).to_csv('submit.csv', index=False, header=False)Если запустить предыдущий пример еще раз и отправить результат на проверку, то, с большой вероятностью, мы получим другую оценку. Это связано с тем, что внутри многих алгоритмов используется генератор случайных чисел. Такое поведение сильно усложняет оценку влияния будущих изменений в модель на итоговый результат. Чтобы избежать подобной проблемы мы можем:
>>> np.random.seed(2707)
>>> clf = RandomForestClassifier(random_state=2707)
...или
>>> runs = 1000
>>> results = np.zeros((runs, X_test.shape[0]))
>>> for i in range(runs):
… clf = RandomForestClassifier(random_state=2707+i)
… clf.fit(X_train, y_train)
… results[i, :]=clf.predict_proba(X_test)[:,1]
>>> result = results.mean(axis=0)Во втором варианте мы получаем более стабильный результат, но очевидно, что он требует гораздо больше времени на вычисления, поэтому использовал я его уже для финальных проверок.
Еще больше примеров можно посмотреть в обучающей статье от организаторов. Там же можно найти информацию про работу с категориальными признаками, которую я не затрагиваю в данной статье.
Подготовка данных

Дабы снизить порог вхождения, организаторы довольно хорошо подготовили данные и их дальнейшая очистка не требовалась. Более того, попытки удалить дубликаты или выбросы в обучающей выборке приводили только к ухудшению результата.
Про дубликаты стоит отметить, что они зачастую относились к разным классам (пользователи с одинаковыми данными могли как остаться так и уйти из игры), и не имея дополнительной информации затруднительно сделать точное предсказание. К счастью, большинство моделей справлялись с этим самостоятельно, выводя вероятности, которые минимизируют оценочную функцию, в нашем случае — log loss.
UPD: участнику с третьего места все же удалось использовать этот факт в свою пользу.
Подготовленные организаторами данные — это скорее исключение из правил, а значит, нужно быть готовым самому обработать их. Кроме дубликатов строк и выбросов, данные могут содержать пропущенные значения. Удалять строки с пропущенными значениями слишком расточительно, т.к. они все еще содержат полезную информацию. Следовательно, у нас осталось 2 выхода:
- оставить все как есть: некоторые алгоритмы могут работать с пропущенными (NA) значениями;
- попытаться восстановить их.
Для восстановления можно просто произвести замену на более часто встречаемое (категориальные признаки), среднее или медианное значение. В python для этого можно воспользоваться sklearn.preprocessing.Imputer классом. Есть и более сложные способы с использованием других признаков (например, среднее значение среди пользователей одного уровня), я пробовал даже обучать еще одну модель, которая по другим столбцам предсказывает пропущенное значение. Ах да, выше я писал что данные подготовлены и в них нет пропущенных значений, на самом деле это не совсем так.
Если прочитать правила внимательнее, то становится ясно, что почти все признаки — это статистика, основанная на логах за 2 недели. Более детальное изучение данных показывает, что немало пользователей, которые начали играть раньше чем 2 недели назад. Если их отсеивать, то на кросс валидации я получал невероятно хорошие оценки, это навело меня на мысль, что ключом к победе может быть улучшение предсказаний для оставшихся «грязных» данных. Попытки восстановить данные для пользователя на момент 2х недель назад не дали сильного прироста, но я оставил это решение и позже использовал его вместе с другими.
Другой трюк, который пришел мне в голову — это домножить часть данных для таких пользователей на -1. Это отделяет их от остальной массы при обучении и неплохо себя показывает, особенно учитывая простоту метода.
Все данные: 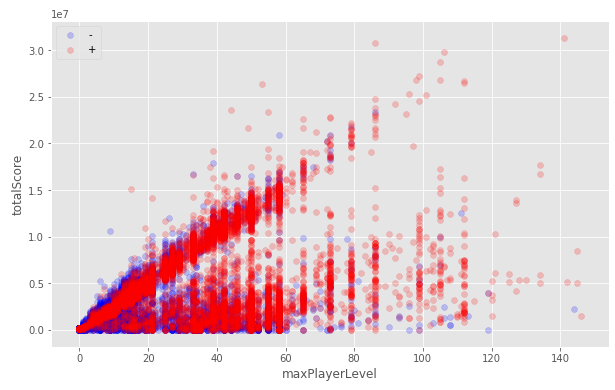
Только пользователи, начавшие играть в течение 2х недельного периода: 
Попытка восстановить данные по другим столбцам: 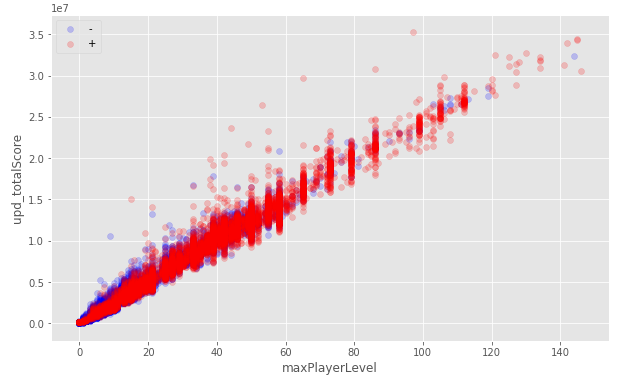
«Инвертирование» для пользователей, начавших играть раньше 2х недель назад: 
В определенных случаях имеет смысл сразу избавиться от некоторых признаков:
- константные признаки;
- два сильно коррелирующих признака (нужен только один из них);
- признаки с близкой к нулевой дисперсией.
Хоть это увеличивает скорость расчетов, а иногда и улучшает общее качество моделей, но с удалением признаков нужно быть предельно осторожным.
Последнее что можно сделать с данными на начальном этапе — это масштабирование. Само по себе оно не меняет зависимости между признаками, но может значительно улучшить предсказания для некоторых (например линейных) моделей. В python для этого можно использовать классы: sklearn.preprocessing.StandardScaler, sklearn.preprocessing.MinMaxScaler и sklearn.preprocessing.MaxAbsScaler.
Каждое из преобразований данных следует тщательно проверять. То, что работает в одному случае может дать отрицательный эффект в другом и наоборот.
Всегда (!) проверяйте, что тестовая выборка проходит через точно такие же преобразования, что и обучающая.
Проверяем себя

Весь набор данных разделен на две части: обучающая и тестовая выборки. Тестовая выборка разделена в соотношении 40/60 на публичную и скрытую. То как хорошо модель предсказала результат для публичной части определяет положение в таблице лидеров на протяжении всего чемпионата, а оценка предсказания для скрытой части становится доступной только в самом конце и определяет финальные позиции участников.
Ориентируясь только на результаты публичной части скорее всего приведет к переобучению модели и сильному падению рейтинга после открытия скрытых результатов. Чтобы этого избежать, а также иметь возможность локально проверять насколько улучшилась/ухудшилась модель, используется кросс-валидация.

Разбиваем данные на K фолдов: на К-1 фолдах обучаем, а для оставшегося предсказываем и считаем оценку предсказания. Так повторяем для всех К фолдов. Финальная оценка считается как среднее оценок для каждого фолда.
Кроме среднего значения стоит обратить внимание на среднеквадратичное отклонение оценок (std), этот параметр может быть даже более важным чем средняя оценка по фолдам, т.к. показывает насколько сильный разброс в предсказаниях по разным фолдам. Значение std может сильно расти с увеличением К, стоит иметь это ввиду и не пугаться.
Важную роль играет и качество разбиения на фолды. Чтобы сохранить распределение классов при разбивке, я использовал sklearn.model_selection.StratifiedKFold. Это особенно важно если классы изначально сильно не сбалансированы. Кроме этого могут возникнуть и другие проблемы с распределением данных по фолдам (дни недели, время, пользователи и т.д.), которые нужно проверять и исправлять отдельно.
Как и ранее, везде, где используется генератор случайных чисел, мы фиксируем значение seed, чтобы любой результат можно было воспроизвести.
>>> from sklearn.model_selection import StratifiedKFold, cross_val_score
>>> clf = RandomForestClassifier(random_state=2707)
>>> kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True)
>>> scores = cross_val_score(clf, X_train, y_train, cv=kf)
>>> print("CV scores:", scores)
CV scores: [ 0.8082625 0.81059707 0.8024911 0.81431679 0.81926043]
>>> print("mean:", np.mean(scores))
mean: 0.810985579862
>>> print("std:", np.std(scores))
std: 0.00564433052781Используя разные схемы для кросс-валидации желательно добиться минимальной разницы локальной оценки и публичной. В случае если оценки не совпадают и локальная кросс-валидация считается правильно, то принято полагаться на локальную оценку.
Усложняем модель (что работает, то не безобразно)

Тюнинг
Подбор гипер-параметров для алгоритмов МО можно рассматривать как задачу минимизации функции, возвращающей оценку модели с этими параметрами на кросс-валидации.
Рассмотрим несколько вариантов решения этой задачи.
- Брутфорс (sklearn.model_selection.GridSearchCV). Не смотря на полный перебор, этот метод может быть достаточно эффективным. XGBoost модели я тюнил именно им. А вот тут хороший гайд как можно это сделать и не ждать несколько суток. Метод хорош еще и тем, что для экономии времени заставляет получше разобраться в значении гипер параметров.
- Рандомизированный перебор (sklearn.model_selection.RandomizedSearchCV). В качестве плюсов можно отметить, что можно задавать количество подборов, независимо от количества параметров.
- hyperopt. Позволяет подбирать сразу много гипер-параметров, в том числе и для нейронных сетей с разным количество слоев, что особенно удобно если нужно найти конфигураци от которой будешь потом отталкиваться.
- Дифференциальная эволюция.
- Ручная подгонка и т.д.
Кстати, если для кросс-валидации вы используете метод cros_val_score библиотеки Scikit Learn, то стоит обратить внимание, что некоторые алгоритмы могут принимать в свой метод fit метрику которую они будут минимизировать при обучении. И для того, чтобы задать этот параметр при кросс-валидации нужно использовать fit_params.
clf = xgb.XGBClassifier(seed=2707)
kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True)
scores = cross_val_score(clf, X_train, y_train, cv=kf, scoring='neg_log_loss', fit_params={'eval_metric':'logloss'})Калибровка (привет Гарусу!)
Идея калибровки состоит в том, что если модель дает предсказание принадлежности к классу 0,6, то среди всех семплов которым она дала это предсказание 60% действительно принадлежат этому классу. В Scikit Learn библиотека содержит для этого sklearn.calibration.CalibratedClassifierCV класс. Это может улучшить оценку, но надо помнить, что для калибровки используется механизм кросс-валидации, а значит это сильно увеличит время обучения.
kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True)
clf = KNeighborsClassifier(n_neighbors=62)
scores = cross_val_score(clf, X_train, y_train, cv=kf)
print("CV scores:", scores)
print("mean:", np.mean(scores))
clf = CalibratedClassifierCV(clf,method='sigmoid', cv=StratifiedKFold(random_state=42, n_splits=5, shuffle=True))
scores = cross_val_score(clf, X_train, y_train, cv=kf)
print("CV scores:", scores)
print("mean:", np.mean(scores))
CV scores: [ 0.769915 0.78054567 0.75958877 0.77338343 0.78168875]
mean: 0.773024324127
CV scores: [ 0.77208935 0.77876631 0.75800712 0.77397667 0.781491 ]
mean: 0.772866088506 <--- небольшое улучшениеBagging
Идея заключается в том, чтобы запускать один и тот же алгоритм на разных (не полных) наборах обучающих семплов и признаков и затем использовать среднее предсказание таких моделей. Как и всегда Scikit Learn уже содержит все, что нам нужно, что сильно экономит наше время, достаточно просто использовать sklearn.ensemble.BaggingClassifier класс.
kf = StratifiedKFold(random_state=2707, n_splits=5, shuffle=True)
clf = KNeighborsClassifier(n_neighbors=62)
scores = cross_val_score(clf, X_train, y_train, cv=kf)
print("CV scores:", scores)
print("mean:", np.mean(scores))
clf = BaggingClassifier(clf, random_state=42)
scores = cross_val_score(clf, X_train, y_train, cv=kf)
print("CV scores:", scores)
print("mean:", np.mean(scores))
CV scores: [ 0.769915 0.78054567 0.75958877 0.77338343 0.78168875]
mean: 0.773024324127
CV scores: [ 0.769915 0.77995255 0.75780941 0.77397667 0.781491 ]
mean: 0.772628926559Разумеется никто не запрещает использовать это совместно с калибровкой.
Составные модели
Не редкая ситуация, когда данные могут быть поделены на группы, для которых выгоднее предсказывать используя разные модели. Например, некоторые участники делили на разные группы по уровню игрока и предсказывали их разными моделями.
Самая лучшая моя модель как раз использовала такой принцип. Делил я на две группы: те, кто начал играть в течении 2-х недель и те, кто начал раньше. Причем в первую группу я добавил еще и тех, кто на момент начала логирования был 1 го уровня, т.к. это улучшало общую оценку. В качестве моделей я взял xgboost с разными гипер-параметрами и использовал для них разные наборы признаков. Причем при обучении второй модели я использовал все данные, но для пользователей начавших играть раньше чем 2 недели назад я давал вес равный 3.
Грязные приемчики
Стоит понимать, что соревнования и реальное использование алгоритмов машинного обучения это совсем разные вещи. Тут можно делать огромные и медленные модели, которые за счет лишних суток расчетов дадут доли процентов точности в оценке, или даже использовать ручную корректировку ответов для увеличения точности. Главное остерегайтесь переобучения на публичной оценке.
Больше данных!

Для того чтобы выжать последние капли информации из предоставленных нам данных можно (нужно!) попробовать сгенерировать новые признаки. Создание хорошего набора признаков из предоставленных данных зачастую является ключевым фактором для победы в чемпионатах по машинному обучению.
- Перемножение или деление друг на друга существующих признаков — простой, но действенный способ.
- Извлечение новых признаков. Например, день недели из даты, количество символов из текста и т.д.
- Нелинейная трансформация существующего признака позволяет приблизить распределение величины к нормальной, что в некоторых случаях (те же нейронные сети) дает лучший результат. Примеры: log (x), log (x+1), sqrt (x), sqrt (x+1) и т.д.
- Другое. Все на что у вас хватит фантазии: максимальная степень двойки на которую делится число, разница в возрасте с президентом и т.д. Один из сгенерированных мной признаков, что использовался в финальных моделях, считался по формуле:
raw_data['totalScore'] / (1 + np.log(1+raw_data['maxPlayerLevel']) * raw_data['maxPlayerLevel'])Теперь, когда у нас много новых признаков, нужно из них как-то отобрать оптимальный набор, что дает лучшую оценку.
При помощи PCA или TruncatedSVD можно уменьшить размерность признаково пространства для увеличения скорости работы алгоритмов. Однако есть большой риск проигнорировать нелинейные зависимости между данными, а также потерять важные признаки совсем.
Многие алгоритмы, как например градиентный бустинг, благодаря своему устройству позволяют довольно легко получить информацию о важности того или иного признака в обученной модели. Эту информацию можно использовать для отсеивания маловажных столбцов.
import matplotlib.pyplot as plt
import xgboost as xgb
from xgboost import plot_importance
clf = xgb.XGBClassifier(seed=2707)
clf.fit(X_train, y_train, eval_metric='logloss')
for a, b in sorted(zip(clf.feature_importances_, X_train.columns)):
print(a,b, sep='\t\t')
plot_importance(clf)
plt.show()0.014771 numberOfAttemptedLevels
0.014771 totalStarsCount
0.0221566 totalBonusScore
0.0295421 doReturnOnLowerLevels
0.0354505 fractionOfUsefullBoosters
0.0531758 attemptsOnTheHighestLevel
0.0886263 numberOfBoostersUsed
0.118168 totalScore
0.128508 averageNumOfTurnsPerCompletedLevel
0.144756 maxPlayerLevel
0.172821 numberOfDaysActuallyPlayed
0.177253 totalNumOfAttempts
Как и всегда нужно быть предельно осторожным с удалением признаков. Удаление маловажных признаков можетиспортить точность предсказания, а удаление наиболее важных наоборот — улучшить. Я использовал этот метод для отсеивания совсем безнадежных признаков.
Существуют и более классические подходы для отбора признаков. В этом конкурсе я интенсивно использовал жадный алгоритм, идея которого заключается в поочередном добавлении новых признаков в набор и выбора того, который дает лучшую оценку на кросс-валидации. Также можно выбрасывать признаки по одному. Чередуя эти подходы я и набирал финальные выборки. Это простой в написании алгоритм, но он игнорирует признаки, которые хорошо увеличивают точность в наборе с несколькими другими. С этой точки зрения, более продуктивным было бы кодировать использование признаков бинарным вектором и использовать генетический алгоритм.
Работа над ошибками

Слава и призы это конечно приятно, но основной моей мотивацией в этот раз было получение опыта и знаний. И разумеется процесс обучения не обходится без ошибок. Разбор которых принес мне больше всего понимания о том, что же я такое делаю. И если вы такой же новичок как и я, то мой совет — пробуйте все. Имея несколько разных результатов проще оценивать каждый из них относительно других, сравнивать их друг с другом. А попытки объяснить себе почему происходит то, что происходит, приводят к более глубокому пониманию работы алгоритмов.
Описанный выше в статье процесс работы с данными и моделями не линейный, и за время чемпионата я периодически возвращался то к новым моделям, то генерации новых признаков и тюнингу моделей на них. В результате накопилось несколько хороших моделей результаты которых я и использовал для финального предсказания.
В случае, если вы застряли на мертвой точке:
- помните про локальный минимум — возможно какая-то идея сразу даст результат хуже текущего, но ее дальнейшее развитие или сочетание с другой идей будут вашей «киллер фичей»;
- почти всегда можно найти научные работы по теме задания, что может натолкнуть на мысли;
- изучите решения участников других чемпионатов (kaggle);
- пробуйте разные модели или еще больше генерации признаков.
Больше моделей!

Допустим после многих мучений и бессонных ночей у нас получилась одна неплохая модель с хорошей оценкой на локальной CV и, в идеале, хорошей оценкой на паблике. Кроме того получилась еще парочка моделей чуть худшего качества. Не стоит сразу выкидывать последние. Дело в том, что предсказания нескольких моделей можно скомбинировать разными способами и получить еще более точное. Это довольно большая тема и начать ознакамливаться с ней рекомендую с этой статьи. Тут я поделюсь двумя разными по сложности методами, которые мне удалось довести до ума.
Наиболее простой подход, а в моем случае еще и более эффективный, оказался в банальном среднем арифметическом между решениями нескольких моделей. В качестве вариаций данного метода можно использовать геометрическое среднее, а также добавить веса моделям.
Второй подход — стекинг. Вот тут можно поесть овса… Идея простая — использовать предсказания моделей первого уровня как входные данные для другого алгоритма. Иногда к этим предсказаниям добавляют первоначальные данные или результаты моделей первого уровня используют для генерации новых признаков. Подвох заключается в том, что для обучения модели второго уровня (еще их называют мета-моделями), необходимы предсказания для обучающей выборки. Для их получения есть два основных подхода: houldout set и out-of-fold predictions.
Houldout set — это небольшой (~10%) кусок обучающей выборки, для которого получают предсказания моделей первого уровня, предварительно обучив их на оставшихся данных. Это простой способ, однако модель второго уровня обучается на очень маленькой выборке.
OOF predictions — обучающую выборку делят на K фолдов, и поочередно считают предсказания для каждого фолда, обучая модели на K-1 оставшихся. Таким образом получается полная обучающая выборка для второго уровня. С тестовой выборкой же можно обойтись двумя способами: сделать предсказания, обучив на всей обучающей выборке (Variant В на рисунке), либо делать предсказания для тестовой выборки каждый раз, когда обучаем модели первого уровня на К-1 фолде, а после брать среднее этих предсказаний (Variant A).

def get_oof(clf):
oof_train = np.zeros((X_train.shape[0],))
oof_test = np.zeros((X_test.shape[0],))
oof_test_skf = np.empty((NFOLDS, X_test.shape[0]))
for i, (train_index, test_index) in enumerate(kf.split(X_train, y_train)):
x_tr = X_train[train_index]
y_tr = y_train[train_index]
x_te = X_train[test_index]
clf.train(x_tr, y_tr)
oof_train[test_index] = clf.predict_proba(x_te)[:, 1]
oof_test_skf[i, :] = clf.predict_proba(X_test)[:, 1]
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)Пытаясь разобраться в этом способе я натыкался на предупреждения, что метод может приводить к утечке данных (data leak), а затем и к переобучению на обучающей выборке, но доказательств этому не нашел. Я испытывал ухудшения публичной оценки при улучшении локальной, но как оказалось скрытая оценка все же улучшалась.
Хинт 1: OOF predictions можно совместить с подсчетом оценки и тем самым за один раз посчитать предсказания и получить оценку кросс-валидации.
Хинт 2: если механизм разбиения на фолды всегда одинаковый и K~=10, то всегда можно взять только 1 фолд и использовать его как holdout set.
Нужно понимать, что чем больше различие во внутренней природе моделей, тем лучше будет их комбинация. Если же взять две одинаковые модели со слегка разными гипер параметрами, то, скорее всего, выгоды это не даст.
Don«t Repeat Yourself

Чуть выше я уже дал пару советов как можно сэкономить время на вычислениях. Написание вспомогательных методов тоже будет хорошей идеей. Например для загрузки/сохранения данных и результатов, кросс-валидации, подсчета OOF предсказаний, совмещенного с кросс валидацией и т.д. Другими словами, все, что можно автоматизировать, лучше автоматизировать. Все, что можно не считать лишний раз, лучше не считать.
Кроме очевидной выгоды по времени, такой подход гарантирует однообразие в проверке качества разных моделей, что упрощает их сравнение. Да и следующее соревнование не придется начинать с чистого листа.
Отмечу, что библиотека Scikit Learn уже содержит множество готовых методов для работы с моделями и их можно использовать, написав свою обертку над более сложной моделью (документация). Я так сделал для модели, что отдельно предсказывала для двух групп пользователей, что позволило мне еще и абстрагироваться от внутреннего устройства модели во время ее проверки.
Итоги
Это был очень интересный опыт для меня. Кроме новых знаний я получил много положительных эмоций от общения с другими участниками в официальном telegram канале. Что касается результатов, то от призового 6 места меня отделял 8 знак после запятой и даже страница результатов не смогла показать это различие.

Код с финальным решением можно посмотреть на GitHub.
На данный момент организаторы уже открыли песочницу и вы можете сами попробовать свои силы, а заодно подготовиться к следующему чемпионату, который нам обещали уже этой весной.
Спасибо за внимание, у меня все.
