[Из песочницы] Уравнение Навье-Стокса и симуляция жидкостей на CUDA
Привет, Хабр. В этой статье мы разберемся с уравнением Навье-Стокса для несжимаемой жидкости, численно его решим и сделаем красивую симуляцию, работающую за счет параллельного вычисления на CUDA. Основная цель — показать, как можно применить математику, лежащую в основе уравнения, на практике при решении задачи моделирования жидкостей и газов.

В статье содержится много математики, поэтому те, кто интересуется именно технической стороной вопроса, могут сразу перейти в раздел реализации алгоритма. Однако, я бы все же рекомендовал ознакомиться со статьей целиком и постараться понять принцип решения. Если же у вас к концу прочтения останутся какие-либо вопросы, буду рад ответить на них в комментариях к посту.
Примечание: если вы читаете хабр с мобильного устройства, и у вас не отображаются формулы, воспользуйтесь полной версией сайта
Уравнение Навье-Стокса для несжимаемой жидкости

Я думаю каждый хоть раз слышал об этом уравнении, некоторые, быть может, даже аналитически решали его частные случаи, но в общем виде эта задачи остается неразрешенной до сих пор. Само собой, мы не ставим в этой статье цель решить задачу тысячелетия, однако итеративный метод применить к ней мы все же можем. Но для начала, давайте разберемся с обозначениями в этой формуле.
Условно уравнение Навье-Стокса можно разделить на пять частей:
Также, так как мы будем рассматривать случай несжимаемой и однородной жидкости, мы имеем еще одно уравнение:  . Энергия в среде постоянна, никуда не уходит, ниоткуда не приходит.
. Энергия в среде постоянна, никуда не уходит, ниоткуда не приходит.
Будет неправильно обделить всех читателей, которые не знакомы с векторным анализом, поэтому заодно и бегло пройдемся по всем операторам, присутствующим в уравнении (однако, настоятельно рекомендую вспомнить, что такое производная, дифференциал и вектор, так как они лежат в основе всего того, о чем пойдет речь ниже).
Начнем мы с с оператора набла, представляющего из себя вот такой вектор (в нашем случае он будет двухкомпонентным, так как жидкость мы будет моделировать в двумерном пространстве):

Оператор набла представляет из себя векторный дифференциальный оператор и может быть применен как к скалярной функции, так и к векторной. В случае скаляра мы получаем градиент функции (вектор ее частных производных), а в случае вектора — сумму частых производных по осям. Главная особенность данного оператора в том, что через него можно выразить основные операции векторного анализа — grad (градиент), div (дивергенция), rot (ротор) и  (оператор Лапласа). Стоит сразу же отметить, что выражение
(оператор Лапласа). Стоит сразу же отметить, что выражение  не равносильно
не равносильно  — оператор набла не обладает коммутативностью.
— оператор набла не обладает коммутативностью.
Как мы увидим далее, эти выражения заметно упрощаются при переходе на дискретное пространство, в котором мы и будем проводить все вычисления, так что не пугайтесь, если на данный момент вам не очень понятно, что же со всем этим делать. Разбив задачу на несколько частей, мы последовательно решим каждую из них и представим все это в виде последовательного применения нескольких функций к нашей среде.
Численное решение уравнения Навье-Стокса
Чтобы представить нашу жидкость в программе, нам необходимо получить математическую репрезентацию состояния каждой частицы жидкости в произвольный момент времени. Самый удобный для этого метод — создать векторное поле частиц, хранящее их состояние, в виде координатной плоскости:

В каждой ячейке нашего двумерного массива мы будем хранить скорость частицы в момент времени  , а расстояние между частицами обозначим за
, а расстояние между частицами обозначим за  и
и  соответственно. В коде же нам будет достаточно изменять значение скорости каждую итерацию, решая набор из нескольких уравнений.
соответственно. В коде же нам будет достаточно изменять значение скорости каждую итерацию, решая набор из нескольких уравнений.
Теперь выразим градиент, дивергенцию и оператор Лапласа с учетом нашей координатной сетки ( — индексы в массиве,
— индексы в массиве,  — взятие соответствующих компонентов у вектора):
— взятие соответствующих компонентов у вектора):
Мы можем еще сильнее упростить дискретные формулы векторных операторов, если положим, что  . Данное допущение не будет сильно сказываться на точности алгоритма, однако уменьшает количество операций на каждую итерацию, да и в целом делает выражения приятней взгляду.
. Данное допущение не будет сильно сказываться на точности алгоритма, однако уменьшает количество операций на каждую итерацию, да и в целом делает выражения приятней взгляду.
Перемещение частиц
Данные утверждения работают только в том случае, если мы можем найти ближайшие частицы относительно рассматриваемой на данный момент. Чтобы свести на нет все возможные издержки, связанные с поиском таковых, мы будет отслеживать не их перемещение, а то, откуда приходят частицы в начале итерации путем проекции траектории движения назад во времени (проще говоря, вычитать вектор скорости, помноженный на изменение времени, из текущей позиции). Используя этот прием для каждого элемента массива, мы будем точно уверены, что у любой частицы будут «соседи»:
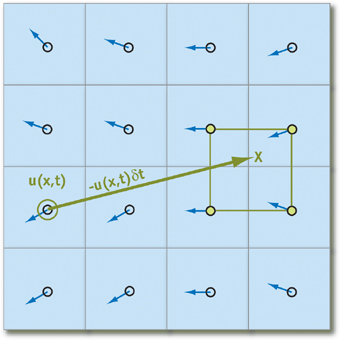
Положив, что  — элемент массива, хранящий состояния частицы, получаем следующую формулу для вычисления ее состояния через время
— элемент массива, хранящий состояния частицы, получаем следующую формулу для вычисления ее состояния через время  (мы полагаем, что все необходимые параметры в виде ускорения и давления уже рассчитаны):
(мы полагаем, что все необходимые параметры в виде ускорения и давления уже рассчитаны):

Заметим сразу же, что при достаточно малом и скорости мы можем так и не выйти за пределы ячейки, поэтому очень важно правильно подобрать ту силу импульса, которую пользователь будет придавать частицам.
Чтобы избежать потери точности в случае попадания проекции на границу клеток или в случае получения нецелых координат, мы будем проводить билинейную интерполяцию состояний четырех ближайших частиц и брать ее за истинное значение в точке. В принципе, такой метод практически не уменьшит точность симуляции, и вместе с тем он достаточно прост в реализации, так что его и будем использовать.
Вязкость
Каждая жидкость обладает некоторой вязкостью, способностью препятствовать воздействию внешних сил на ее части (хорошим примером будет мед и вода, в некоторых случаях их коэффициенты вязкости отличаются на порядок). Вязкость непосредственно влияет на ускорение, приобретаемое жидкостью, и может быть выражено приведенной ниже формулой, если для краткости мы опустим на время другие слагаемые:

. В таком случае итеративное уравнение для скорости примет следующий вид:

Мы несколько преобразуем данное равенство, приведя его к виду  (стандартный вид системы линейных уравнений):
(стандартный вид системы линейных уравнений):

где  — единичная матрица. Такие преобразования нам необходимы, чтобы в последствии применить метод Якоби для решения нескольких схожих систем уравнений. Его мы также обсудим в дальнейшем.
— единичная матрица. Такие преобразования нам необходимы, чтобы в последствии применить метод Якоби для решения нескольких схожих систем уравнений. Его мы также обсудим в дальнейшем.
Внешние силы
Самый простой шаг алгоритма — применение внешних сил к среде. Для пользователя это будет отражаться в виде кликов по экрану мышкой или ее перемещение. Внешнюю силу можно описать следующей формулой, которую мы применим для каждого элемента матрицы ( — импульс-вектор,
— импульс-вектор,  — позиция мыши,
— позиция мыши,  — координаты текущей ячейки,
— координаты текущей ячейки,  — радиус действия, масштабирующий параметр):
— радиус действия, масштабирующий параметр):

Импульс-вектор легко посчитать как разность между предыдущей позицией мыши и текущей (если такая имелась), и здесь как раз-таки можно проявить креативность. Именно в этой части алгоритма мы можем внедрить добавление цветов в жидкость, ее подсветку и т.п. К внешним силам также можно отнести гравитацию и температуру, и хоть реализовать такие параметры несложно, в данной статье рассматривать их мы не будем.
Давление
Давление в уравнении Навье-Стокса — та сила, которая препятствует частицам заполнять все доступное им пространство после применения к ним какой-либо внешней силы. Сходу его расчет весьма затруднителен, однако нашу задачу можно значительно упростить, применив теорему разложения Гельмгольца.
Назовем  векторное поле, полученное после расчета перемещения, внешних сил и вязкости. Оно будет иметь ненулевую дивергенцию, что противоречит условию несжимаемости жидкости (
векторное поле, полученное после расчета перемещения, внешних сил и вязкости. Оно будет иметь ненулевую дивергенцию, что противоречит условию несжимаемости жидкости ( ), и чтобы это исправить, необходимо рассчитать давление. Согласно теореме разложения Гельмгольца, можно представить как сумму двух полей:
), и чтобы это исправить, необходимо рассчитать давление. Согласно теореме разложения Гельмгольца, можно представить как сумму двух полей:

где  — и есть искомое нами векторное поле с нулевой дивергенцией. Доказательство этого равенства в данной статье приводиться не будет, однако в конце вы сможете найти ссылку с подробным объяснением. Мы же можем применить оператор набла к обоим частям выражения, чтобы получить следующую формулу для расчета скалярного поля давления:
— и есть искомое нами векторное поле с нулевой дивергенцией. Доказательство этого равенства в данной статье приводиться не будет, однако в конце вы сможете найти ссылку с подробным объяснением. Мы же можем применить оператор набла к обоим частям выражения, чтобы получить следующую формулу для расчета скалярного поля давления:

Записанное выше выражение представляет из себя уравнение Пуассона для давления. Его мы также можем решить вышеупомянутым методом Якоби, и тем самым найти последнюю неизвестную переменную в уравнении Навье-Стокса. В принципе, системы линейных уравнений можно решать самыми разными и изощренными способами, но мы все же остановимся на самом простом из них, чтобы еще больше не нагружать данную статью.
Граничные и начальные условия
Любое дифференциальное уравнение, моделируемое на конечной области, требует правильно заданных начальных или граничных условий, иначе мы с очень большой вероятностью получим физически неверный результат. Граничные условия устанавливаются для контролирования поведения жидкости близ краев координатной сетки, а начальные условия задают параметры, которые имеют частицы в момент запуска программы.
Начальные условия будут весьма простыми — изначально жидкость неподвижна (скорость частиц равна нулю), и давление также равно нулю. Граничные условия будут задаваться для скорости и давления приведенными формулами:


Тем самым, дивергенция частиц у краев будет равна нулю (что соответствует условию несжимаемости), а давление равно значению непосредственно рядом с границей. Данные операции следует применить ко всем ограничивающим элементам массива (к примеру, есть размер сетки  , то алгоритм мы применим для клеток, отмеченных на рисунке синим):
, то алгоритм мы применим для клеток, отмеченных на рисунке синим):

Краситель
С тем, что мы имеем сейчас, уже можно придумать много интересных вещей. К примеру, реализовать распространение красителя в жидкости. Для этого нам достаточно лишь поддерживать еще одно скалярное поле, которое бы отвечало за количество краски в каждой точке симуляции. Формула для обновления красителя весьма похожа на скорость, и выражается как:

В формуле  отвечает за пополнение красителем области (возможно, в зависимости от того, куда нажмет пользователь),
отвечает за пополнение красителем области (возможно, в зависимости от того, куда нажмет пользователь),  непосредственно является количество красителя в точке, а
непосредственно является количество красителя в точке, а  — коэффициент диффузии. Решить его не составляет большого труда, так как вся основная работа по выводу формул уже проведена, и достаточно лишь сделает несколько подстановок. Краску можно реализовать в коде как цвет в формате RGB, и в таком случае задача сводится к операциям с несколькими вещественными величинами.
— коэффициент диффузии. Решить его не составляет большого труда, так как вся основная работа по выводу формул уже проведена, и достаточно лишь сделает несколько подстановок. Краску можно реализовать в коде как цвет в формате RGB, и в таком случае задача сводится к операциям с несколькими вещественными величинами.
Завихренность
Уравнение для завихренности не является непосредственной частью уравнения Навье-Стокса, однако является важным параметром для правдоподобной симуляции движения красителя в жидкости. Из-за того, что мы производим алгоритм на дискретном поле, а также из-за потерь в точности величин с плавающей точкой, этот эффект теряется, и поэтому нам необходимо восстановить его, применив дополнительную силу к каждой точке пространства. Вектор этой силы обозначен как  и определяется следующими формулами:
и определяется следующими формулами:




 есть результат применения ротора к вектору скорости (его определение дано в начале статьи),
есть результат применения ротора к вектору скорости (его определение дано в начале статьи),  — градиент скалярного поля абсолютных значений .
— градиент скалярного поля абсолютных значений .  представляет нормализованный вектор , а
представляет нормализованный вектор , а  — константа, контролирующая, насколько большими будут завихренности в нашей жидкости.
— константа, контролирующая, насколько большими будут завихренности в нашей жидкости.
Метод Якоби для решения систем линейных уравнений
В ходе разбора уравнения Навье-Стокса мы вышли на две системы уравнений — одно для вязкости, другое для давления. Решить их можно итеративным алгоритмом, который можно описать следующей итеративной формулой:

Для нас  — элементы массива, представляющие скалярное или векторное поле.
— элементы массива, представляющие скалярное или векторное поле.  — номер итерации, его мы можем регулировать, чтобы как увеличить точность расчета или наоборот уменьшить, и повысить производительность.
— номер итерации, его мы можем регулировать, чтобы как увеличить точность расчета или наоборот уменьшить, и повысить производительность.
Для расчет вязкости подставляем:  ,
,  ,
,  , здесь параметр
, здесь параметр  — сумма весов. Таким образом, нам необходимо хранить как минимум два векторных поля скоростей, чтобы независимо считать значения одного поля и записывать их в другое. В среднем, для расчета поля скорости методом Якоби необходимо провести 20–50 итераций, что весьма много, если бы мы выполняли вычисления на CPU.
— сумма весов. Таким образом, нам необходимо хранить как минимум два векторных поля скоростей, чтобы независимо считать значения одного поля и записывать их в другое. В среднем, для расчета поля скорости методом Якоби необходимо провести 20–50 итераций, что весьма много, если бы мы выполняли вычисления на CPU.
Для уравнения давления мы сделаем следующую подстановку:  ,
,  ,
,  ,
,  . В результате мы получим значение
. В результате мы получим значение  в точке. Но так как оно используется только для расчета градиента, вычитаемого из поля скорости, дополнительные преобразования можно не выполнять. Для поля давления лучше всего выполнять 40–80 итераций, потому что при меньших числах расхождение становится заметным.
в точке. Но так как оно используется только для расчета градиента, вычитаемого из поля скорости, дополнительные преобразования можно не выполнять. Для поля давления лучше всего выполнять 40–80 итераций, потому что при меньших числах расхождение становится заметным.
Реализация алгоритма
Реализовывать алгоритм мы будем на C++, также нам потребуется Cuda Toolkit (как его установить вы можете прочитать на сайте Nvidea), а также SFML. CUDA нам потребуется для распараллеливания алгоритма, а SFML будет использоваться только для создания окна и отображения картинки на экране (В принципе, это вполне можно написать на OpenGL, но разница в производительности будет несущественна, а вот код увеличится еще строк на 200).
Cuda Toolkit
Сначала мы немного поговорим о том, как использовать Cuda Toolkit для распараллеливания задач. Более подробный гайд предоставляется самой Nvidea, поэтому здесь мы ограничимся только самым необходимым. Также предполагается, что вы смогли установить компилятор, и у вас получилось собрать тестовый проект без ошибок.
Чтобы создать функцию, исполняющуюся на GPU, для начала необходимо объявить, сколько ядер мы хотим использовать, и сколько блоков ядер нужно выделить. Для этого Cuda Toolkit предоставляет нам специальную структуру — dim3, по умолчанию устанавливающую все свои значения x, y, z равными 1. Указывая ее как аргумент при вызове функции, мы можем управлять количеством выделяемых ядер. Так как работаем мы с двумерным массивом, то в конструкторе необходимо установить только два поля: x и y:
dim3 threadsPerBlock(x_threads, y_threads);
dim3 numBlocks(size_x / x_threads, y_size / y_threads);
где size_x и size_y — размер обрабатываемого массива. Сигнатура и вызов функции выглядят следующим образом (тройные угловые скобки обрабатываются компилятором Cuda):
void __global__ deviceFunction(); // declare
deviceFunction<<>>(); // call from host
В самой функции можно восстановить индексы двумерного массива через номер блока и номер ядра в этом блоке по следующей формуле:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
Следует отметить, что функция, исполняемая на видеокарте, должна быть обязательно помечена тегом __global__, а также возвращать void, поэтому чаще всего результаты вычислений записываются в передаваемый как аргумент и заранее выделенный в памяти видеокарты массив.
За освобождение и выделение памяти на видеокарте отвечают функции CudaMalloc и CudaFree. Мы можем оперировать указателями на область памяти, которые они возвращают, но получить доступ к данным из основного кода не можем. Самый простой способ вернуть результаты вычислений — воспользоваться cudaMemcpy, схожей со стандартным memcpy, но умеющей копировать данные с видеокарты в основную память и наоборот.
SFML и рендер окна
Вооружившись всеми этими знаниями, мы наконец можем перейти к непосредственному написанию кода. Для начала давайте создадим файл main.cpp и разместим туда весь вспомогательный код для рендера окна:
#include
#include
#include
#include
//SFML REQUIRED TO LAUNCH THIS CODE
#define SCALE 2
#define WINDOW_WIDTH 1280
#define WINDOW_HEIGHT 720
#define FIELD_WIDTH WINDOW_WIDTH / SCALE
#define FIELD_HEIGHT WINDOW_HEIGHT / SCALE
static struct Config
{
float velocityDiffusion;
float pressure;
float vorticity;
float colorDiffusion;
float densityDiffusion;
float forceScale;
float bloomIntense;
int radius;
bool bloomEnabled;
} config;
void setConfig(float vDiffusion = 0.8f, float pressure = 1.5f, float vorticity = 50.0f, float cDiffuion = 0.8f,
float dDiffuion = 1.2f, float force = 1000.0f, float bloomIntense = 25000.0f, int radius = 100, bool bloom = true);
void computeField(uint8_t* result, float dt, int x1pos = -1, int y1pos = -1, int x2pos = -1, int y2pos = -1, bool isPressed = false);
void cudaInit(size_t xSize, size_t ySize);
void cudaExit();
int main()
{
cudaInit(FIELD_WIDTH, FIELD_HEIGHT);
srand(time(NULL));
sf::RenderWindow window(sf::VideoMode(WINDOW_WIDTH, WINDOW_HEIGHT), "");
auto start = std::chrono::system_clock::now();
auto end = std::chrono::system_clock::now();
sf::Texture texture;
sf::Sprite sprite;
std::vector pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4);
texture.create(FIELD_WIDTH, FIELD_HEIGHT);
sf::Vector2i mpos1 = { -1, -1 }, mpos2 = { -1, -1 };
bool isPressed = false;
bool isPaused = false;
while (window.isOpen())
{
end = std::chrono::system_clock::now();
std::chrono::duration diff = end - start;
window.setTitle("Fluid simulator " + std::to_string(int(1.0f / diff.count())) + " fps");
start = end;
window.clear(sf::Color::White);
sf::Event event;
while (window.pollEvent(event))
{
if (event.type == sf::Event::Closed)
window.close();
if (event.type == sf::Event::MouseButtonPressed)
{
if (event.mouseButton.button == sf::Mouse::Button::Left)
{
mpos1 = { event.mouseButton.x, event.mouseButton.y };
mpos1 /= SCALE;
isPressed = true;
}
else
{
isPaused = !isPaused;
}
}
if (event.type == sf::Event::MouseButtonReleased)
{
isPressed = false;
}
if (event.type == sf::Event::MouseMoved)
{
std::swap(mpos1, mpos2);
mpos2 = { event.mouseMove.x, event.mouseMove.y };
mpos2 /= SCALE;
}
}
float dt = 0.02f;
if (!isPaused)
computeField(pixelBuffer.data(), dt, mpos1.x, mpos1.y, mpos2.x, mpos2.y, isPressed);
texture.update(pixelBuffer.data());
sprite.setTexture(texture);
sprite.setScale({ SCALE, SCALE });
window.draw(sprite);
window.display();
}
cudaExit();
return 0;
}
строка в начале функции main
std::vector pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4);
создает изображение формата RGBA в виде одномерного массива с константной длиной. Его мы будем передавать вместе с другими параметрами (позиция мыши, разница между кадрами) в функцию computeField. Последняя, как и несколько других функций, объявлены в kernel.cu и вызывают код, исполняемый на GPU. Документацию по любой из функций вы можете найти на сайте SFML, в коде файла не происходит ничего сверхинтересного, поэтому мы не будем надолго на нем останавливаться.
Вычисления на GPU
Чтобы начать писать код под gpu, для начала создадим файл kernel.cu и определим в нем несколько вспомогательных классов: Color3f, Vec2, Config, SystemConfig:
struct Vec2
{
float x = 0.0, y = 0.0;
__device__ Vec2 operator-(Vec2 other)
{
Vec2 res;
res.x = this->x - other.x;
res.y = this->y - other.y;
return res;
}
__device__ Vec2 operator+(Vec2 other)
{
Vec2 res;
res.x = this->x + other.x;
res.y = this->y + other.y;
return res;
}
__device__ Vec2 operator*(float d)
{
Vec2 res;
res.x = this->x * d;
res.y = this->y * d;
return res;
}
};
struct Color3f
{
float R = 0.0f;
float G = 0.0f;
float B = 0.0f;
__host__ __device__ Color3f operator+ (Color3f other)
{
Color3f res;
res.R = this->R + other.R;
res.G = this->G + other.G;
res.B = this->B + other.B;
return res;
}
__host__ __device__ Color3f operator* (float d)
{
Color3f res;
res.R = this->R * d;
res.G = this->G * d;
res.B = this->B * d;
return res;
}
};
struct Particle
{
Vec2 u; // velocity
Color3f color;
};
static struct Config
{
float velocityDiffusion;
float pressure;
float vorticity;
float colorDiffusion;
float densityDiffusion;
float forceScale;
float bloomIntense;
int radius;
bool bloomEnabled;
} config;
static struct SystemConfig
{
int velocityIterations = 20;
int pressureIterations = 40;
int xThreads = 64;
int yThreads = 1;
} sConfig;
void setConfig(
float vDiffusion = 0.8f,
float pressure = 1.5f,
float vorticity = 50.0f,
float cDiffuion = 0.8f,
float dDiffuion = 1.2f,
float force = 5000.0f,
float bloomIntense = 25000.0f,
int radius = 500,
bool bloom = true
)
{
config.velocityDiffusion = vDiffusion;
config.pressure = pressure;
config.vorticity = vorticity;
config.colorDiffusion = cDiffuion;
config.densityDiffusion = dDiffuion;
config.forceScale = force;
config.bloomIntense = bloomIntense;
config.radius = radius;
config.bloomEnabled = bloom;
}
static const int colorArraySize = 7;
Color3f colorArray[colorArraySize];
static Particle* newField;
static Particle* oldField;
static uint8_t* colorField;
static size_t xSize, ySize;
static float* pressureOld;
static float* pressureNew;
static float* vorticityField;
static Color3f currentColor;
static float elapsedTime = 0.0f;
static float timeSincePress = 0.0f;
static float bloomIntense;
int lastXpos = -1, lastYpos = -1;
Атрибут __host__ перед именем метода означает, что код может исполнятся на CPU, __device__, наоборот, обязует компилятор собирать код под GPU. В коде объявляются примитивы для работы с двухкомпонентными векторами, цветом, конфиги с параметрами, которые можно менять в рантайме, а также несколько статических указателей на массивы, которые мы будем использовать как буферы для вычислений.
cudaInit и cudaExit также определяеются достаточно тривиально:
void cudaInit(size_t x, size_t y)
{
setConfig();
colorArray[0] = { 1.0f, 0.0f, 0.0f };
colorArray[1] = { 0.0f, 1.0f, 0.0f };
colorArray[2] = { 1.0f, 0.0f, 1.0f };
colorArray[3] = { 1.0f, 1.0f, 0.0f };
colorArray[4] = { 0.0f, 1.0f, 1.0f };
colorArray[5] = { 1.0f, 0.0f, 1.0f };
colorArray[6] = { 1.0f, 0.5f, 0.3f };
int idx = rand() % colorArraySize;
currentColor = colorArray[idx];
xSize = x, ySize = y;
cudaSetDevice(0);
cudaMalloc(&colorField, xSize * ySize * 4 * sizeof(uint8_t));
cudaMalloc(&oldField, xSize * ySize * sizeof(Particle));
cudaMalloc(&newField, xSize * ySize * sizeof(Particle));
cudaMalloc(&pressureOld, xSize * ySize * sizeof(float));
cudaMalloc(&pressureNew, xSize * ySize * sizeof(float));
cudaMalloc(&vorticityField, xSize * ySize * sizeof(float));
}
void cudaExit()
{
cudaFree(colorField);
cudaFree(oldField);
cudaFree(newField);
cudaFree(pressureOld);
cudaFree(pressureNew);
cudaFree(vorticityField);
}
В функции инициализации мы выделяем память под двумерные массивы, задаем массив цветов, которые мы будем использовать для раскраски жидкости, а также устанавливаем в конфиг значения по умолчанию. В cudaExit мы просто освобождаем все буферы. Как бы это парадоксально не звучало, для хранения двумерных массивов выгоднее всего использовать одномерные, обращение к которым будет осуществляться таким выражением:
array[y * size_x + x]; // equals to array[y][x]
Начнем реализацию непосредственного алгоритма с функции перемещения частиц. В advect передаются поля oldField и newField (то поле, откуда берутся данные и то, куда они записываются), размер массива, а также дельта времени и коэффициент плотности (используется для того, чтобы ускорить растворение красителя в жидкости и сделать среду не сильно чувствительной к действиям пользователя). Функция билинейной интерполяции реализована классическим образом через вычисление промежуточных значений:
// interpolates quantity of grid cells
__device__ Particle interpolate(Vec2 v, Particle* field, size_t xSize, size_t ySize)
{
float x1 = (int)v.x;
float y1 = (int)v.y;
float x2 = (int)v.x + 1;
float y2 = (int)v.y + 1;
Particle q1, q2, q3, q4;
#define CLAMP(val, minv, maxv) min(maxv, max(minv, val))
#define SET(Q, x, y) Q = field[int(CLAMP(y, 0.0f, ySize - 1.0f)) * xSize + int(CLAMP(x, 0.0f, xSize - 1.0f))]
SET(q1, x1, y1);
SET(q2, x1, y2);
SET(q3, x2, y1);
SET(q4, x2, y2);
#undef SET
#undef CLAMP
float t1 = (x2 - v.x) / (x2 - x1);
float t2 = (v.x - x1) / (x2 - x1);
Vec2 f1 = q1.u * t1 + q3.u * t2;
Vec2 f2 = q2.u * t1 + q4.u * t2;
Color3f C1 = q2.color * t1 + q4.color * t2;
Color3f C2 = q2.color * t1 + q4.color * t2;
float t3 = (y2 - v.y) / (y2 - y1);
float t4 = (v.y - y1) / (y2 - y1);
Particle res;
res.u = f1 * t3 + f2 * t4;
res.color = C1 * t3 + C2 * t4;
return res;
}
// adds quantity to particles using bilinear interpolation
__global__ void advect(Particle* newField, Particle* oldField, size_t xSize, size_t ySize, float dDiffusion, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float decay = 1.0f / (1.0f + dDiffusion * dt);
Vec2 pos = { x * 1.0f, y * 1.0f };
Particle& Pold = oldField[y * xSize + x];
// find new particle tracing where it came from
Particle p = interpolate(pos - Pold.u * dt, oldField, xSize, ySize);
p.u = p.u * decay;
p.color = p.color * decay;
newField[y * xSize + x] = p;
}
Функцию диффузии вязкости было решено разделить на несколько частей: из главного кода вызывается computeDiffusion, которая вызывает diffuse и computeColor заранее указанное число раз, а затем меняет местами массив, откуда мы берем данные, и тот, куда мы их записываем. Это самый простой способ реализовать параллельную обработку данных, но мы расходует в два раза больше памяти.
Обе функции вызывают вариации метода Якоби. В теле jacobiColor и jacobiVelocity сразу же идет проверка, что текущие элементы не находятся на границе — в этом случае мы должны установить их в соответствии с формулами, изложенными в разделе Граничные и начальные условия.
// performs iteration of jacobi method on color grid field
__device__ Color3f jacobiColor(Particle* colorField, size_t xSize, size_t ySize, Vec2 pos, Color3f B, float alpha, float beta)
{
Color3f xU, xD, xL, xR, res;
int x = pos.x;
int y = pos.y;
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = colorField[int(y) * xSize + int(x)]
SET(xU, x, y - 1).color;
SET(xD, x, y + 1).color;
SET(xL, x - 1, y).color;
SET(xR, x + 1, y).color;
#undef SET
res = (xU + xD + xL + xR + B * alpha) * (1.0f / beta);
return res;
}
// calculates color field diffusion
__global__ void computeColor(Particle* newField, Particle* oldField, size_t xSize, size_t ySize, float cDiffusion, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
Vec2 pos = { x * 1.0f, y * 1.0f };
Color3f c = oldField[y * xSize + x].color;
float alpha = cDiffusion * cDiffusion / dt;
float beta = 4.0f + alpha;
// perfom one iteration of jacobi method (diffuse method should be called 20-50 times per cell)
newField[y * xSize + x].color = jacobiColor(oldField, xSize, ySize, pos, c, alpha, beta);
}
// performs iteration of jacobi method on velocity grid field
__device__ Vec2 jacobiVelocity(Particle* field, size_t xSize, size_t ySize, Vec2 v, Vec2 B, float alpha, float beta)
{
Vec2 vU = B * -1.0f, vD = B * -1.0f, vR = B * -1.0f, vL = B * -1.0f;
#define SET(U, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) U = field[int(y) * xSize + int(x)].u
SET(vU, v.x, v.y - 1);
SET(vD, v.x, v.y + 1);
SET(vL, v.x - 1, v.y);
SET(vR, v.x + 1, v.y);
#undef SET
v = (vU + vD + vL + vR + B * alpha) * (1.0f / beta);
return v;
}
// calculates nonzero divergency velocity field u
__global__ void diffuse(Particle* newField, Particle* oldField, size_t xSize, size_t ySize, float vDiffusion, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
Vec2 pos = { x * 1.0f, y * 1.0f };
Vec2 u = oldField[y * xSize + x].u;
// perfoms one iteration of jacobi method (diffuse method should be called 20-50 times per cell)
float alpha = vDiffusion * vDiffusion / dt;
float beta = 4.0f + alpha;
newField[y * xSize + x].u = jacobiVelocity(oldField, xSize, ySize, pos, u, alpha, beta);
}
// performs several iterations over velocity and color fields
void computeDiffusion(dim3 numBlocks, dim3 threadsPerBlock, float dt)
{
// diffuse velocity and color
for (int i = 0; i < sConfig.velocityIterations; i++)
{
diffuse<<>>(newField, oldField, xSize, ySize, config.velocityDiffusion, dt);
computeColor<<>>(newField, oldField, xSize, ySize, config.colorDiffusion, dt);
std::swap(newField, oldField);
}
}
Применение внешней силы реализовано через единственную функцию — applyForce, принимающую как аргументы позицию мыши, цвет красителя, а также радиус действия. С ее помощью мы можем придать скорость частицам, а также красить их. братная экспонента позволяет сделать область не слишком резкой, и при этом достаточно четкой в указанном радиусе.
// applies force and add color dye to the particle field
__global__ void applyForce(Particle* field, size_t xSize, size_t ySize, Color3f color, Vec2 F, Vec2 pos, int r, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float e = expf((-(powf(x - pos.x, 2) + powf(y - pos.y, 2))) / r);
Vec2 uF = F * dt * e;
Particle& p = field[y * xSize + x];
p.u = p.u + uF;
color = color * e + p.color;
p.color.R = min(1.0f, color.R);
p.color.G = min(1.0f, color.G);
p.color.B = min(1.0f, color.B);
}
Расчет завихренности представляет из себя уже более сложный процесс, поэтому его мы реализуем в computeVorticity и applyVorticity, заметим также, что для них необходимо определить два таких векторных оператора, как curl (ротор) и absGradient (градиент абсолютных значений поля). Чтобы задать дополнительные эффекты вихря, мы умножаем  компоненту вектора градиента на
компоненту вектора градиента на  , а затем нормализируем его, разделив на длину (не забыв при этом проверить, что вектор ненулевой):
, а затем нормализируем его, разделив на длину (не забыв при этом проверить, что вектор ненулевой):
// computes curl of velocity field
__device__ float curl(Particle* field, size_t xSize, size_t ySize, int x, int y)
{
Vec2 C = field[int(y) * xSize + int(x)].u;
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = field[int(y) * xSize + int(x)]
float x1 = -C.x, x2 = -C.x, y1 = -C.y, y2 = -C.y;
SET(x1, x + 1, y).u.x;
SET(x2, x - 1, y).u.x;
SET(y1, x, y + 1).u.y;
SET(y2, x, y - 1).u.y;
#undef SET
float res = ((y1 - y2) - (x1 - x2)) * 0.5f;
return res;
}
// computes absolute value gradient of vorticity field
__device__ Vec2 absGradient(float* field, size_t xSize, size_t ySize, int x, int y)
{
float C = field[int(y) * xSize + int(x)];
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = field[int(y) * xSize + int(x)]
float x1 = C, x2 = C, y1 = C, y2 = C;
SET(x1, x + 1, y);
SET(x2, x - 1, y);
SET(y1, x, y + 1);
SET(y2, x, y - 1);
#undef SET
Vec2 res = { (abs(x1) - abs(x2)) * 0.5f, (abs(y1) - abs(y2)) * 0.5f };
return res;
}
// computes vorticity field which should be passed to applyVorticity function
__global__ void computeVorticity(float* vField, Particle* field, size_t xSize, size_t ySize)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
vField[y * xSize + x] = curl(field, xSize, ySize, x, y);
}
// applies vorticity to velocity field
__global__ void applyVorticity(Particle* newField, Particle* oldField, float* vField, size_t xSize, size_t ySize, float vorticity, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
Particle& pOld = oldField[y * xSize + x];
Particle& pNew = newField[y * xSize + x];
Vec2 v = absGradient(vField, xSize, ySize, x, y);
v.y *= -1.0f;
float length = sqrtf(v.x * v.x + v.y * v.y) + 1e-5f;
Vec2 vNorm = v * (1.0f / length);
Vec2 vF = vNorm * vField[y * xSize + x] * vorticity;
pNew = pOld;
pNew.u = pNew.u + vF * dt;
}
Следующим этапом алгоритма будет вычисление скалярного поля давления и его проекция на поле скорости. Для этого нам потребуется реализовать 4 функции: divergency, которая будет считать дивергенцию скорости, jacobiPressure, реализующую метод Якоби для давления, и computePressure c computePressureImpl, проводящие итеративные вычисления поля:
// performs iteration of jacobi method on pressure grid field
__device__ float jacobiPressure(float* pressureField, size_t xSize, size_t ySize, int x, int y, float B, float alpha, float beta)
{
float C = pressureField[int(y) * xSize + int(x)];
float xU = C, xD = C, xL = C, xR = C;
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = pressureField[int(y) * xSize + int(x)]
SET(xU, x, y - 1);
SET(xD, x, y + 1);
SET(xL, x - 1, y);
SET(xR, x + 1, y);
#undef SET
float pressure = (xU + xD + xL + xR + alpha * B) * (1.0f / beta);
return pressure;
}
// computes divergency of velocity field
__device__ float divergency(Particle* field, size_t xSize, size_t ySize, int x, int y)
{
Particle& C = field[int(y) * xSize + int(x)];
float x1 = -1 * C.u.x, x2 = -1 * C.u.x, y1 = -1 * C.u.y, y2 = -1 * C.u.y;
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = field[int(y) * xSize + int(x)]
SET(x1, x + 1, y).u.x;
SET(x2, x - 1, y).u.x;
SET(y1, x, y + 1).u.y;
SET(y2, x, y - 1).u.y;
#undef SET
return (x1 - x2 + y1 - y2) * 0.5f;
}
// performs iteration of jacobi method on pressure field
__global__ void computePressureImpl(Particle* field, size_t xSize, size_t ySize, float* pNew, float* pOld, float pressure, float dt)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float div = divergency(field, xSize, ySize, x, y);
float alpha = -1.0f * pressure * pressure;
float beta = 4.0;
pNew[y * xSize + x] = jacobiPressure(pOld, xSize, ySize, x, y, div, alpha, beta);
}
// performs several iterations over pressure field
void computePressure(dim3 numBlocks, dim3 threadsPerBlock, float dt)
{
for (int i = 0; i < sConfig.pressureIterations; i++)
{
computePressureImpl<<>>(oldField, xSize, ySize, pressureNew, pressureOld, config.pressure, dt);
std::swap(pressureOld, pressureNew);
}
}
Проекция умещается в две небольшие функции — project и вызываемой ей gradient для давления. Это, можно сказать, последний этап нашего алгоритма симуляции:
// computes gradient of pressure field
__device__ Vec2 gradient(float* field, size_t xSize, size_t ySize, int x, int y)
{
float C = field[y * xSize + x];
#define SET(P, x, y) if (x < xSize && x >= 0 && y < ySize && y >= 0) P = field[int(y) * xSize + int(x)]
float x1 = C, x2 = C, y1 = C, y2 = C;
SET(x1, x + 1, y);
SET(x2, x - 1, y);
SET(y1, x, y + 1);
SET(y2, x, y - 1);
#undef SET
Vec2 res = { (x1 - x2) * 0.5f, (y1 - y2) * 0.5f };
return res;
}
// projects pressure field on velocity field
__global__ void project(Particle* newField, size_t xSize, size_t ySize, float* pField)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
Vec2& u = newField[y * xSize + x].u;
u = u - gradient(pField, xSize, ySize, x, y);
}
После проекции мы смело можем перейти к отрисовке изображения в буфер и различным пост-эффектам. В функции paint выполняется копирование цветов из поля частиц в массив RGBA. Также была реализована функция applyBloom, которая подсвечивает жидкость, когда на нее наведен курсор и нажата клавиша мыши. Из опыта, такой прием делает картину более приятной и интересной для глаз пользователя, но он вовсе не обязателен.
В постобработке также можно подсвечивать места, в которых жидкость имеет наибольшую скорость, менять цвет в зависимости от вектора движения, добавлять различные эффекты и прочее, но в нашем случае мы ограничимся своеобразным минимумом, ведь даже с ним изображения п
