[Из песочницы] Учебник по языку SQL (DDL, DML). Часть первая
О чем данный учебник Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется в работе наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды для работы с БД, и нет надобности изучать визуальный инструмент для работы с конкретной БД. При постоянной работе с БД, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение).Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части: DDL — Data Definition Language (язык описания данных) DML — Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции: SELECT — выборка данных INSERT — вставка новых данных UPDATE — обновление данных DELETE — удаление данных MERGE — слияние данных Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данной книги использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS) SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:
Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
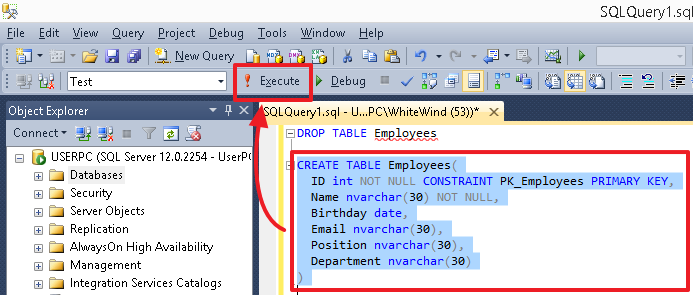
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.

Собственно, это все, что нам будет необходимо знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой.Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица — это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи — тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов. Для справки — в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
— однострочный комментарий и /* многострочный комментарий */ Собственно, все для теории этого будет достаточно.
DDL — Data Definition Language (язык описания данных) Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде: Табельный номер ФИО Дата рождения E-mail Должность Отдел 1000 Иванов И.И. 19.02.1955 i.ivanov@test.tt Директор Администрация 1001 Петров П.П. 03.12.1983 p.petrov@test.tt Программист ИТ 1002 Сидоров С.С. 07.06.1976 s.sidorov@test.tt Бухгалтер Бухгалтерия 1003 Андреев А.А. 17.04.1982 a.andreev@test.tt Старший программист ИТ В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
Табельный номер — целое число ФИО — строка Дата рождения — дата E-mail — строка Должность — строка Отдел — строка Тип столбца — характеристика, которая говорит о том какого рода данные может хранить данный столбец.Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
Значение Обозначение в MS SQL Описание Строка переменной длины varchar (N)иnvarchar (N) При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar (30).Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта.Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы.
Строка фиксированной длины char (N)иnchar (N) От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char (1), т.е. когда поле определяется одним символом. Целое число int Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) — диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. Вещественное или действительное число float Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). Дата date Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. Время time Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603Например, ежедневное «Время отправления рейса». Дата и время datetime Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.3231603Для примера это может быть дата и время какого-нибудь события. Флаг bit Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 1. Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test Удалить базу данных можно командой (стоит быть очень осторожны с данной командой): DROP DATABASE Test Для того, чтобы переключиться на нашу базу данных, можно выполнить команду: USE Test Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники]( [Табельный номер] int, [ФИО] nvarchar (30), [Дата рождения] date, [E-mail] nvarchar (30), [Должность] nvarchar (30), [Отдел] nvarchar (30) ) В данном случае нам придется заключать имена в квадратные скобки […].Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1. Так же в некоторых базах более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в БД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники] Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования: ID — Табельный номер (Идентификатор сотрудника) Name — ФИО Birthday — Дата рождения Email — E-mail Position — Должность Department — Отдел Очень часто для наименования поля идентификатора используется слово ID.Теперь создадим нашу таблицу:
CREATE TABLE Employees ( ID int, Name nvarchar (30), Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30) ) Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
— обновление поля ID ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name ALTER TABLE Employees ALTER COLUMN Name nvarchar (30) NOT NULL Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом: INSERT Employees (ID, Position, Department) VALUES (1000, N’Директор', N’Администрация'), (1001, N’Программист', N’ИТ'), (1002, N’Бухгалтер', N’Бухгалтерия'), (1003, N’Старший программист', N’ИТ') Теперь команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнится успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдаст сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.Добавим значения для полю Name и снова зальем данные:
INSERT Employees (ID, Position, Department, Name) VALUES (1000, N’Директор', N’Администрация', N’Иванов И.И.'), (1001, N’Программист', N’ИТ', N’Петров П.П.'), (1002, N’Бухгалтер', N’Бухгалтерия', N’Сидоров С.С.'), (1003, N’Старший программист', N’ИТ', N’Андреев А.А.') Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.Сначала удалим таблицу при помощи команды:
DROP TABLE Employees Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name: CREATE TABLE Employees ( ID int NOT NULL, Name nvarchar (30) NOT NULL, Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30) ) Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar (30) NULL Или просто: ALTER TABLE Employees ALTER COLUMN Name nvarchar (30) Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов: ALTER TABLE Employees ALTER COLUMN Name nvarchar (50) Первичный ключ При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки — по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY (ID) Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY (поле1, поле2, …) Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees А затем создадим ее, используя следующий синтаксис: CREATE TABLE Employees ( ID int NOT NULL, Name nvarchar (30) NOT NULL, Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30), CONSTRAINT PK_Employees PRIMARY KEY (ID) — описываем PK после всех полей, как ограничение ) После создания зальем в таблицу данные: INSERT Employees (ID, Position, Department, Name) VALUES (1000, N’Директор', N’Администрация', N’Иванов И.И.'), (1001, N’Программист', N’ИТ', N’Петров П.П.'), (1002, N’Бухгалтер', N’Бухгалтерия', N’Сидоров С.С.'), (1003, N’Старший программист', N’ИТ', N’Андреев А.А.') Если первичный ключ в таблице состоит только из значений только одного столбца, то можно использовать следующий синтаксис: CREATE TABLE Employees ( ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, — указываем как характеристику поля Name nvarchar (30) NOT NULL, Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30) ) На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»): CREATE TABLE Employees ( ID int NOT NULL, Name nvarchar (30) NOT NULL, Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30), PRIMARY KEY (ID) ) Или: CREATE TABLE Employees ( ID int NOT NULL PRIMARY KEY, Name nvarchar (30) NOT NULL, Birthday date, Email nvarchar (30), Position nvarchar (30), Department nvarchar (30) ) Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление: ALTER TABLE Employees DROP CONSTRAINT PK_Employees Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.Подытожим На данный момент мы рассмотрели следующие команды: CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) — служит для создания новой таблицы в текущей БД; DROP TABLE имя_таблицы — служит для удаления таблицы из текущей БД; ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … — служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL); ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY;(поле1, поле2, …) — добавление первичного ключа к уже существующей таблице; ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения — удаление ограничения из таблицы. Немного про временные таблицы Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp ( ID int, Name nvarchar (30) ) Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить ее данными используя синтаксис SELECT… INTO: SELECT ID, Name INTO #Temp FROM Employees Нормализация БД — дробление на подтаблицы (справочники) и определение связей Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток — сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных — дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions ( ID int IDENTITY (1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar (30) NOT NULL )
CREATE TABLE Departments ( ID int IDENTITY (1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar (30) NOT NULL ) Заметим, что здесь мы использовали новую опцию IDENTITY, которое говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
— заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees INSERT Positions (Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL — отбрасываем записи у которых позиция не указана То же самое проделаем для таблицы Departments: INSERT Departments (Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID: SELECT * FROM Positions ID Name 1 Бухгалтер 2 Директор 3 Программист 4 Старший программист SELECT * FROM Departments ID Name 1 Администрация 2 Бухгалтерия 3 ИТ Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов: — добавляем поле для ID должности ALTER TABLE Employees ADD PositionID int — добавляем поле для ID отдела ALTER TABLE Employees ADD DepartmentID int Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках. ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY (PositionID) REFERENCES Positions (ID) И то же самое сделаем для второго поля: ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY (DepartmentID) REFERENCES Departments (ID) Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения FOREIGN KEY (поле1, поле2, …) REFERENCES таблица_справочник (поле1, поле2, …) В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2, …).Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
ID
Name
Birthday
Email
Position
Department
PositionID
DepartmentID
1000
Иванов И.И.
NULL
NULL
Директор
Администрация
2
1
1001
Петров П.П.
NULL
NULL
Программист
ИТ
3
3
1002
Сидоров С.С.
NULL
NULL
Бухгалтер
Бухгалтерия
1
2
1003
Андреев А.А.
NULL
NULL
Старший программист
ИТ
4
3
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position, Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
ID
Name
Birthday
Email
PositionID
DepartmentID
1000
Иванов И.И.
NULL
NULL
2
1
1001
Петров П.П.
NULL
NULL
3
3
1002
Сидоров С.С.
NULL
NULL
1
2
1003
Андреев А.А.
NULL
NULL
4
3
Т.е. мы в итоге избавились от хранения избыточной информации и по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID, e.Name, p.Name PositionName, d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
ID
Name
PositionName
DepartmentName
1000
Иванов И.И.
Директор
Администрация
1001
Петров П.П.
Программист
ИТ
1002
Сидоров С.С.
Бухгалтер
Бухгалтерия
1003
Андреев А.А.
Старший программист
ИТ
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами — например, переименовывать или удалять объекты.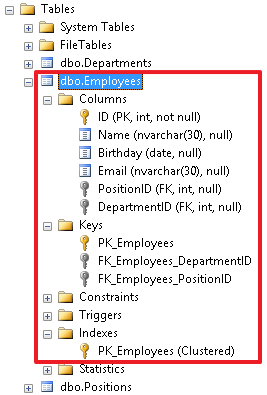
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees (ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами: 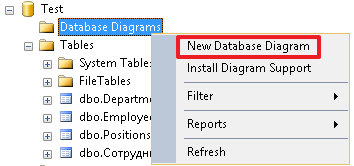
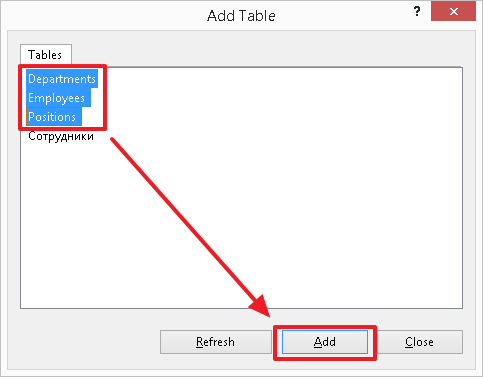
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
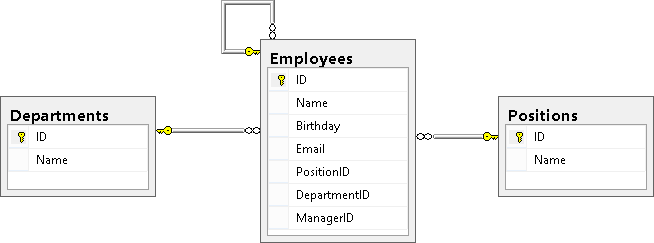
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees ( ID int NOT NULL, Name nvarchar (30), Birthday date, Email nvarchar (30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY (DepartmentID) REFERENCES Departments (ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY (PositionID) REFERENCES Positions (ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees (ID) )
INSERT Employees (ID, Name, Birthday, PositionID, DepartmentID, ManagerID)VALUES (1000, N’Иванов И.И.','19550219',2,1, NULL), (1001, N’Петров П.П.','19831203',3,3,1003), (1002, N’Сидоров С.С.','19760607',1,2,1000), (1003, N’Андреев А.А.','19820417',4,3,1000) Удалим отдел с идентификатором 3 из таблицы Departments: DELETE Departments WHERE ID=3 Посмотрим на данные таблицы Employees: SELECT * FROM Employees ID Name Birthday Email PositionID DepartmentID ManagerID 1000 Иванов И.И. 1955–02–19 NULL 2 1 NULL 1002 Сидоров С.С. 1976–06–07 NULL 1 2 1000 Как видим, данные по отделу 3 из таблицы Employees так же удалились.Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments SET ID=30 WHERE ID=3 Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.Восстановим отдел 3:
— даем разрешение на добавление/изменение IDENTITY значения SET IDENTITY_INSERT Departments ON
INSERT Departments (ID, Name) VALUES (3, N’ИТ')
-- запрещаем добавление/изменение IDENTITY значения SET IDENTITY_INSERT Departments OFF Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE: TRUNCATE TABLE Employees И снова перезальем в нее данные используя предыдущую команду INSERT: INSERT Employees (ID, Name, Birthday, PositionID, DepartmentID, ManagerID)VALUES (1000, N’Иванов И.И.','19550219',2,1, NULL), (1001, N’Петров П.П.','19831203',3,3,1003), (1002, N’Сидоров С.С.','19760607',1,2,1000), (1003, N’Андреев А.А.','19820417',4,3,1000) Подытожим На данным момент к нашим знаниям добавилось еще несколько команд DDL: Добавление свойства IDENTITY к полю — позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы; ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками — позволяет добавить новые поля в таблицу; ALTER TABLE имя_таблицы DROP COLUMN перечень_полей — позволяет удалить поля из таблицы; ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY (поля) REFERENCES таблица_справочник (поля) — позволяет определить связь между таблицей и таблицей справочником. Прочие ограничения — UNIQUE, DEFAULT, CHECK При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены: UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000 UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001 UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002 UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003 А теперь можно наложить на это поле ограничение-уникальности: ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE (Email) Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.Ограничение уникальности обычно именуется следующим образом — сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE (поле1, поле2, …) При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME () Или если столбец HireDate уже существует, то можно использовать следующий синтаксис: ALTER TABLE Employees ADD DEFAULT SYSDATETIME () FOR HireDate Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом: ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME () FOR HireDate Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees (ID, Name, Email)VALUES (1004, N’Сергеев С.С.','s.sergeev@test.tt') Посмотрим, что получилось: SELECT * FROM Employees ID Name Birthday Email PositionID DepartmentID ManagerID HireDate 1000 Иванов И.И. 1955–02–19 i.ivanov@test.tt 2 1 NULL 2015–04–08 1001 Петров П.П. 1983–12–03 p.petrov@test.tt 3 4 1003 2015–04–08 1002 Сидоров С.С. 1976–06–07 s.sidorov@test.tt 1 2 1000 2015–04–08 1003 Андреев А.А. 1982–04–17 a.andreev@test.tt 4 3 1000 2015–04–08 1004 Сергеев С.С. NULL s.sergeev@test.tt NULL NULL NULL 2015–04–08 Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999: ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees (ID, Email) VALUES (2000,'test@test.tt') А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится: INSERT Employees (ID, Email) VALUES (1500,'test@test.tt') Можно так же создать ограничения UNIQUE и CHECK без указания имени: ALTER TABLE Employees ADD UNIQUE (Email) ALTER TABLE Employees ADD CHECK (ID BETWEEN 1000 AND 1999) Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.А при хорошем наименовании много информацию об ограничении можно узнать непосредственно по его имени.
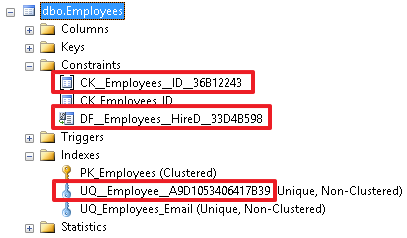
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE: CREATE TABLE Employees ( ID int NOT NULL, Name nvarchar (30), Birthday date, Email nvarchar (30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME (), — для DEFAULT я сделаю исключение CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY (DepartmentID) REFERENCES Departments (ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY (PositionID) REFERENCES Positions (ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) ) Напоследок вставим в таблицу наших сотрудников: INSERT Employees (ID, Name, Birthday, Email, PositionID, DepartmentID)VALUES (1000, N’Иванов И.И.','19550219','i.ivanov@test.tt',2,1), (1001, N’Петров П.П.','19831203','p.petrov@test.tt',3,3), (1002, N’Сидоров С.С.','19760607','s.sidorov@test.tt',1,2), (1003, N’Андреев А.А.','19820417','a.andreev@test.tt',4,3) Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями. По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех БД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED — означает, что записи таблицы будут сортироваться по&
