[Из песочницы] Тестирование в React

Каждый JS-разработчик рано или поздно начинает писать тесты и сожалеть, что не стал делать этого раньше. Поскольку за последние пару лет все постепенно перешли к компонентной разработке на основе React, Angular или, например, Vue, это дало очередной толчок для популяризации тестирования, так как компоненты обычно малы и тестировать их гораздо проще. В данной статье мы рассмотрим компонентное тестирование в React.
Заранее приношу извинения за то, что в данной статье вынужден использовать английские термины. Перевод некоторых фраз, которые стали стандартом в области тестирования, привел бы к потере понимания и усложнению поиска дополнительной информации.
Начнем с рассмотрения утилит, которые необходимы для организации тестирования в JS-проекте:
- Test Runner — утилита, которая берет файлы с нашими тестами, запускает их и выводит результаты тестирования. Наиболее популярные утилиты в этой области — Mocha и Karma.
- Assertion library — библиотеки с набором функций для проверки условий ваших тестов. Chai и Expect — наиболее используемые библиотеки из данной области.
- Mock library — библиотека, используемая для создания «заглушек» (mock) при тестировании. Утилита позволяет заменять связанные части тестируемого компонента «заглушками», имитирующими нужное поведение. Здесь наиболее популярный выбор — Sinon.
Рассмотрим существующие инструменты тестирования для React, и приведем примеры несложных тестов с использованием этих инструментов. Сразу скажу, что не стану описывать, как настроить сборку проекта, «транспалинг» ES6 и прочее: все это при желании вы можете изучить самостоятельно или найти нужные статьи на «Хабре». В крайнем случае — пишите, и я постараюсь вам помочь.
Также в рамках данной статьи мы не пойдем по распространенному в области тестирования пути «слепого» использования наиболее популярных библиотек, а посмотрим на те, что появились недавно, и постараемся понять, достойны ли они внимания.
Акт 1
Первое, что нам необходимо — это TestRunner для наших будущих тестов. Как и обещал, в данном обзоре не будут рассматриваться популярные утилиты, такие как Karma или Mocha. Рассмотрим новый инструмент: Jest от Facebook. В отличие от Mocha, Jest довольно прост в настройке, интеграции в проект и при этом довольно функционален. Это молодой проект, который еще год назад был довольно «печален» в использовании: в нем отсутствовало многое из необходимой для тестов функциональности, например, не было тестирования асинхронных функций или watch-режима, который следил бы за изменяемыми файлами. Сейчас этот продукт уже изрядно «пожирнел» и может тягаться с такими монстрами, как Mocha или Karma. Кроме того, мейнтейнеры начали оперативно исправлять дефекты, чего совсем не хватало несколько лет назад. Итак, давайте взглянем на то, что умеет Jest:
- Удивительно прост в интеграции в проект
Не нужно ставить десяток мелких библиотек и настраивать их взаимодействие между собой, так как Jest уже содержит в себе все необходимое. Меня поймут те, кто хоть раз использовал популярную связку Karma + Mocha + Sinon для тестов, остальным придётся поверить мне на слово. - Запуск тестов и вывод результатов тестирования
Jest содержит достаточно параметров для настройки поиска и запуска тестов, так что вы всегда сможете настроить его для вашего проекта и задач. - Содержит assert-библиотеку, которую, тем не менее, можно заменить любой другой
Jest базируется на второй версии библиотеки Jasmine, так что если вы когда-то работали с ней, то синтаксис покажется знакомым. Если же вам не нравится Jasmine, вы можете использовать свою любимую библиотеку. - Умеет запускать каждый тест в отдельном процессе, ускоряя тем самым выполнение тестов
- Умеет работать с асинхронным кодом и тестировать код, использующий таймеры
- Умеет автоматически создавать «заглушки» для импортируемых компонентов
По сути, это одна из killer-фич Jest, но довольно сложная для настройки. Именно из-за нее многие в свое время отказались от использования Jest, и в новых версиях она теперь отключена по умолчанию.
- Умеет работать в интерактивном watch-режиме
Jest имеет довольно крутой интерактивный режим, позволяющий вам запускать не только тесты на изменившиеся компоненты, но и, например, из последнего коммита в git, последние «провалившиеся» тесты или же с использованием «паттерна» для поиска по имени.
- Умеет собирать покрытие проекта тестами (coverage)
- Содержит jsdom и, как следствие, умеет запускать тесты без браузера
- Умеет тестировать компоненты с использованием слепков (snapshot)
Это далеко не все, что умеет Jest. Более подробно о данной утилите вы можете прочитать на их официальном сайте — facebook.github.io/jest. Тем не менее, Jest также содержит и некоторые минусы, которые я отметил для себя:
- Документация Jest довольно «скудная», часто приходится искать ответ самому, роясь на github или на stack overflow.
- Не умеет запускать тесты в браузерах
Да, его плюс является и его же минусом. Правда, для меня это совсем не критичный минус, т.к. я стараюсь избегать ситуаций, когда отображение может отличаться в разных браузерах. - Медленно стартует запуск тестов.
Насчет медленного запуска. Разрабатывающая Jest команда постоянно вносит улучшения, ускоряющие запуск тестов. После того, как к ним присоединился Dmitrii Abramov, ситуация сильно улучшилась, этому есть подтверждение. Тем не менее, по моим личным ощущениям, тесты, которые я писал с использованием Karma + Mocha, все же стартовали и отрабатывали быстрей, чем написанные с использованием Jest. Надеюсь, со временем ребята устранят и этот недостаток.
Итак, давайте напишем несколько тестов и посмотрим, как они выглядят на практике. Для начала возьмем несложную функцию, которая вычисляет сумму двух чисел:
function sum(a, b) {
return a + b;
}
Тест для данной функции будет выглядеть следующим образом:
describe(‘function tests’, () => {
it(‘should return 3 for arguments 1 and 2’, () => {
expect(sum(1, 2)).toBe(3);
});
});
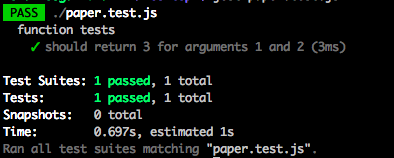
Все просто и знакомо. Давайте теперь усложним нашу функцию, добавив в неё вызов другой функции:
function initial() {
return 1;
}
function sum(a, b) {
return initial() + a + b;
}
Правильно построенный тест для атомарного элемента должен исключать все зависимости от остального кода. Поэтому нам нужно исключить возможную некорректную работу функции initial из нашего теста функции sum. Для этого мы сделаем «заглушку» для функции initial, которая будет возвращать нужное нам значение. Тест у нас получится следующим:
describe(‘function tests’, () => {
it(‘should return 4 for arguments 1 and 2’, () => {
initial = jest.fn((cb) => 1);
expect(sum(1, 2)).toBe(4);
});
});
Теперь давайте еще усложним нашу функцию и предположим, что, во-первых, наша функция sum должна быть асинхронной, а во-вторых, она должна подумать, прежде чем вернуть нам нужный результат:
function initial(salt) {
return 1;
}
function sum(a, b) {
return new Promise((resolve, reject) => {
setTimeout(function(){
resolve({
value: initial(1) + a + b,
param1: a,
param2: b,
});
}, 100);
});
}
Доработаем тест, чтобы он учитывал наши изменения:
describe(‘function tests’, () => {
beforeAll(() => {
jest.useFakeTimers();
});
afterAll(() => {
jest.useRealTimers();
});
it(‘should return 4 for arguments 1 and 2’, () => {
initial = jest.fn((cb) => 1);
const result = sum(1, 2);
result.then((result) => {
expect(result).not.toEqual({
value: 3,
param1: 1,
param2: 2,
});
expect(initial).toHaveBeCalledWith(1);
});
jest.runTimersToTime(100);
return result;
})
});
В данном тесте мы применили несколько новых возможностей Jest:
- Во-первых, мы попросили его использовать fake-таймеры, чтобы мы сами могли управлять временем
- Во-вторых, мы увидели, как тестировать асинхронные функции
- В-третьих, мы увидели, как использовать отрицания и сравнение объектов в проверке тестов
- В-четвертых, мы увидели, как протестировать, что наша mock-функция вызывалась и с нужными параметрами
Давайте посмотрим, как же тестировать React-компоненты. Предположим, у нас есть несложный компонент, который выводит приветствие пользователю и отлавливает клик по выведенному тексту:
export default class Wellcome extends React.Component {
onClick() {
this.props.someFunction(this.props.username);
}
render() {
return (
Wellcome {this.props.username}
);
}
}
Давайте его протестируем:
import React from 'react';
import TestUtils from 'react-addons-test-utils'
import Wellcome from './welcome.jsx';
describe(‘Как мы видим, ничего сложного здесь нет. Мы используем React Test Utils для рендеринга нашего компонента и поиска Dom-узлов. В остальном, тест ничем не отличается от обычного теста на Jest.
Итак, мы рассмотрели, как можно использовать Jest для создания и запуска тестов, но прежде чем пойти дальше, давайте немного остановимся еще на одной его фиче, а именно — тестировании на основе слепков (snapshot). Snapshot-тестирование — это возможность сохранять слепок React-дерева в виде JSON-объекта и сравнивать его при последующих запусках теста с получившейся структурой.
Грубо говоря, первый раз вы запускаете тест, чтобы сформировать такой слепок, проверяете его валидность руками и коммитите его в репозиторий кода. И — вуаля — все последующие запуски теста будут сравнивать ваш слепок из репозитория с тем, что получилось.
Эта фича появилась в Jest совсем недавно, лично у меня нововведение вызвало смешанные чувства. С одной стороны, я нашел ей полезное применение — некоторые тесты действительно стали проще (там, где нет никакой интерактивности и нужно, по сути, просто проверить структуру), мне теперь не надо дублировать код в тестах. С другой стороны, я увидел и минус: тесты для меня — это документация моего кода, а тестирование на основе слепков, по сути, дает мне возможность «схалявить» и, не задумываясь об assert-ах, просто сравнить два дерева компонента. Кроме этого, данный подход лишает меня возможности классического TDD, когда я сначала пишу тесты компонента, а потом пишу сам код. Но я думаю, что данная фича однозначно найдет своих поклонников.
Давайте посмотрим, как она работает для нашего компонента:
import React from 'react';
import renderer from 'react-test-renderer';
import Wellcome from './welcome.jsx';
describe('Отметим, что конкретно наш тест упростился не сильно (он у нас и так был простой). Для более объемного по структуре компонента тест может сократиться наполовину и упроститься в разы. Давайте запустим наш тест и посмотрим, что произойдет:
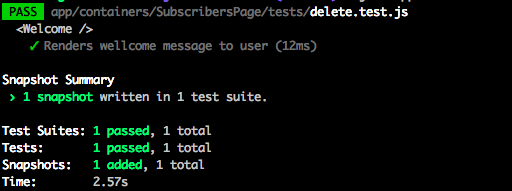
Итак, jest создал для нас слепок. Вот что внутри слепка:
exports[Слепок представляет собой html-структуру компонента и удобен для валидации «на глаз».
Кроме указанных выше минусов, я наткнулся на еще один недостаток тестирования на основе слепков. Если вы используете HOC-компоненты (например, redux-form), слепок будет содержать не тестируемый вами компонент, а обертку от redux-form. Поэтому для тестирования именно компонента мне приходится экспортировать и его, а также имитировать контракт, который требует redux-form.
В принципе, ничего страшного, если HOC-компонент у вас один. Но, например, у меня их может быть в некоторых случаях три: один — от react-redux, второй — от redux-from и третий — от react-intl. С последним, кстати, довольно трудно тестировать код, так как просто обложить «заглушками» компонент не получится, нужно подложить компоненту честный API локализации. Как это делается — вы можете увидеть тут.
Подведем итог. Теперь у нас есть всё, что нужно для запуска тестов наших компонентов. Но давайте еще раз посмотрим, как можно упростить и улучшить наши тесты.
Акт 2
Впервые задумавшись о тестировании компонентов React и начав искать информацию о том, как это сделать, вы, скорее всего, наткнетесь на пакет тестовых утилит React Test Utilites. Данный пакет разработан командой Facebook и позволяет писать тесты компонентов. Этот пакет предоставляет следующие возможности:
- Рендеринг компонента в DOM
- Симуляция событий для DOM-элементов
- «Mock-инг» компонентов
- Поиск элементов в DOM
- Поверхностный (shallow) рендеринг компонента
Как мы видим, набор возможностей довольно широкий, достаточный для написания тестов для любых компонентов. Пример того, как выглядел бы наш тест с использованием React Test Utilites, мы разбирали в предыдущем разделе:
import React from 'react';
import TestUtils from 'react-addons-test-utils'
import Wellcome from './welcome.jsx';
describe(‘Но мы не пойдем «стандартным путем» и не станем использовать для наших тестов React Test Utilites по нескольким причинам. Во-первых, у данной библиотеки очень скудная документация, и для того, чтобы разобраться с ней, новичку придётся активно попользоваться поиском ответов в Интернете. Во-вторых, самая «вкусная» для нас фича shallow рендеринга компонентов уже давно находится в экспериментальной стадии и никак из нее не выходит. Вместо этого мы воспользуемся замечательной библиотекой Enzyme, которая была разработана командой Arbnb и уже стала довольно популярной при тестировании React-приложений. По сути, Enzyme — это библиотека, которая является надстройкой над тремя другими библиотеками: React TestUtils, JSDOM и CheerIO:
- TestUtils — библиотека, созданная Facebook для тестирования React-компонентов
- JSDOM — это JS-реализация DOM. Позволяет нам эмулировать браузер
- CheerIO — аналог Jquery для работы с DOM-элементами
Объединив всё вместе и немного дополнив, Enzyme позволяет просто и понятно строить тесты для React-компонентов и, кроме функциональности Test Utilites, также дает нам:
- Три варианта рендеринга компонента: shallow, mount и render
- Jquery-подобный синтаксис поиска компонентов
- Поиск компонента, используя имя компонента (только если вы задали это имя через параметр DisplayName)
- Поиск компонента, используя значения его параметров (props)
Да, Enzyme не содержит в себе TestRunner, а также не умеет делать «заглушки» для компонентов, но для этого у нас уже есть Jest.
Давайте поподробнее рассмотрим три варианта рендеринга компонента и то, что нам это дает. Итак, в Enzyme есть три метода, которые рендерят компонент и возвращают похожие обертки с набором методов в стиле Jquery:
- Поверхностный (shallow) рендеринг — Enzyme отрендерит только сам компонент, игнорируя рендеринг вложенных в него компонентов
- Full Dom Rendering — полный рендеринг компонента и всех его вложенных компонентов
- Static рендеринг — рендерит статический HTML для переданного компонента
Я не стану приводить весь список методов, которые дает нам Enzyme, скажу лишь, что с его помощью вы сможете:
- Находить компоненты или DOM-элементы
- Сравнивать содержимое компонента с JSX-разметкой
- Проверять свойства компонента
- Обновлять состояние компонента
- Эмулировать события
Это далеко не все возможности Enzyme. Полный список вы сможете найти в документации библиотеки, а мы сконцентрируем внимание на отличиях между тремя видами рендеринга.
Что же дает нам shallow-рендеринг и в чем его прелести? А дает он нам возможность сконцентрироваться при тестировании только на самом компоненте и не думать о вложенных компонентах. Нам абсолютно неважно, как будет меняться структура, выдаваемая вложенными компонентами: это никак не должно сломать нам наши тесты. Таким образом, мы можем тестировать наш компонент изолированно от других компонентов. Но это не значит, что мы совсем не тестируем вложенные компоненты. Нет, мы можем проверить в тестах, что правильно передаем свойства во вложенные компоненты. Кроме этого, еще один плюс такого тестирования состоит в том, что скорость выполнения таких тестов гораздо выше, чем при использовании Full Dom-рендеринга, так как не требует наличия DOM. Но к сожалению, не всегда мы можем использовать только поверхностный рендеринг. Например, пусть кроме используемого нами компонента Wellcome у нас есть еще компонент Home со следующим содержимым:
import React, { PropTypes, Component } from 'react'
import Wellcome from './Wellcome'
class Home extends Component {
onChangeUsername(e) {
this.props.changeUsername(e.target.value);
}
render() {
return (
Home
)
}
}
Home.propTypes = {
changeUsername: PropTypes.func.isRequired
}
export default Home
Давайте напишем теперь тест для данного компонента:
import React from 'react'
import { shallow } from 'enzyme'
import Home from './Home'
import Wellcome from './Wellcome';
describe('Для того, чтобы увидеть, как в Enzyme работает shallow-рендеринг, воспользуемся функцией debug и посмотрим, что нам выведет следующий код.
Home
Как мы видим, Enzyme отрендерил наш компонент, но не стал рендерить вложенные компоненты. Тем не менее, он сформировал правильные параметры для них и мы можем их проверять при необходимости.
Теперь давайте разберем вариант, когда нам не подходит поверхностный рендеринг и может потребоваться использовать полный рендеринг через вызов метода mount. А поверхностный рендеринг не подойдет нам, если:
- наш компонент содержит логику в Lifecycle-методах, например таких, как componentWillMount и componentDidMount. Мы, конечно, можем вызвать их вручную, но не уверен, что это всегда хороший способ;
- наш компонент должен взаимодействовать с DOM. Дело в том, что поверхностный рендеринг не использует JSDOM и всё взаимодействие с DOM просто не будет работать;
- нам нужно проверить интеграцию нескольких компонентов между собой — например, мы используем компонент создания ToDo и компонент списка ToDo на одной странице
В этих случаях нам придётся использовать mount вместо shallow, который, к сожалению, сделает наши тесты медленнее, так как ему уже необходимы DOM и загрузка библиотеки Jsdom. Итак, привожу пример, когда нам требуется полный рендеринг:
import React, { PropTypes, Component } from 'react'
import Wellcome from './Wellcome'
class Home extends Component {
componentWillMount() {
this.props.fetchUsername();
}
onChangeUsername(e) {
this.props.changeUsername(e.target.value);
}
render() {
return (
Home
);
}
}
Home.propTypes = {
changeUsername: PropTypes.func.isRequired,
fetchUsername: PropTypes.func,
};
export default Home;
И наш тест:
import React from 'react'
import { mount } from 'enzyme'
import Home from './Home'
import Wellcome from './Wellcome';
describe('Давайте посмотрим, что нам вернул вызов debug:
Home
Wellcome
Alise
Как мы видим, при полном рендеринге Enzyme отрендерил еще и вложенные компоненты, а также запустились все методы LifeCycle-компонента.
Нам осталось рассмотреть последний тип рендеринга, который есть в Enzyme: static-рендеринг. Он рендерит компонент в HTML-строку, используя библиотеку Cherio, и возвращает нам обратно объект, который похож на тот, что нам отдают shallow и mount-методы. Тест будет отличаться от предыдущего только заменой вызова mount на render, поэтому его, если что, вы сможете написать сами.
Я вижу только одно применение данному методу, когда необходимо проанализировать только HTML-структуру компонента и важна скорость работы теста. При использовании статического рендеринга тест отработает быстрее, чем при использовании полного рендеринга. Других применений данному типу рендеринга я не нашел.
Антракт
Итак, в данной статье мы рассмотрели тестирование React-компонентов, «пощупали» новые утилиты, используемые для тестирования, и собрали готовый «комбайн» для создания тестов. Если данная тема будет интересна, то в следующих статьях мы попробуем серьезно протестировать более сложное приложение, использующее redux, redux-saga, react-intl, модальные окошки и прочие элементы, усложняющие тестирование.
Зеленых вам тестов и попутного 100%-го покрытия!
