[Из песочницы] Способы сегментации точек в Point Clouds
Введение
Некоторое время назад мне потребовалось решить задачу сегментации точек в Point Cloud (облака точек — данные, полученные с лидаров).
Пример данных и решаемой задачи: 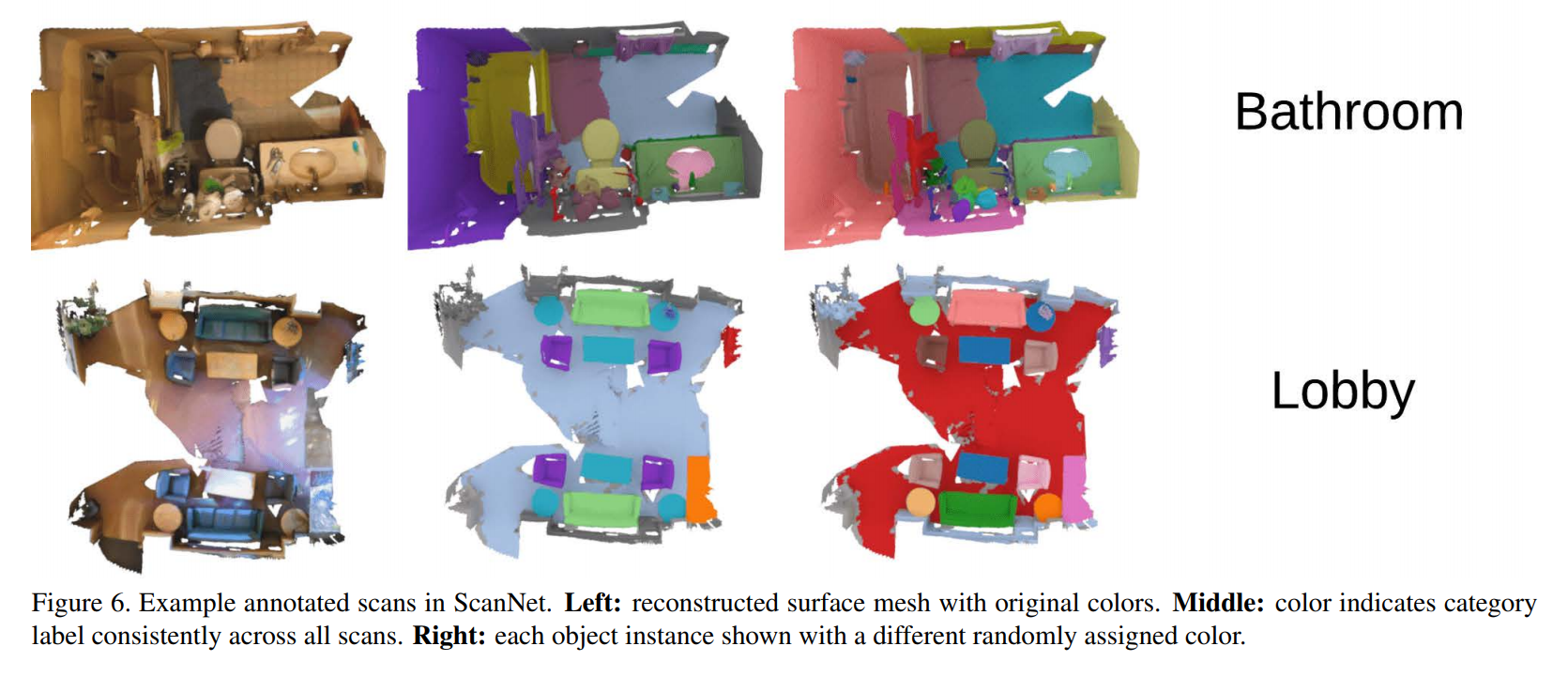
Поиски общего обзора существующих методов оказались неуспешными, поэтому пришлось собирать информацию самостоятельно. Результат вы можете видеть: здесь собраны наиболее важные и интересные (по моему мнению) статьи за последние несколько лет. Все рассмотренные модели решают задачу сегментации облака точек (к какому классу принадлежит каждая точка).
Эта статья будет полезна тем, кто хорошо знаком с нейронными сетями и хочет понять, как применять их к неструктурированным данным (к примеру графам).
Существующие датасеты
Сейчас в открытом доступе есть следующие датасеты по этой теме:
Особенности работы с Point Clouds
Нейронные сети пришли в эту область совсем недавно. И стандартные архитектуры вроде полносвязных и сверточных сетей не применимы для решения этой задачи. Почему?
Потому что здесь не важен порядок точек. Объект — это множество точек и не важно, в каком порядке их просматривают. Если на изображения у каждого пикселя есть своё место, тут мы можем спокойно перемешать точки и объект не измениться. Результат работы стандартных нейронных сетей, наоборот, зависит от местоположения данных. Если перемешать пиксели на изображение, получится новый объект.
А теперь разберемся, как же нейронные сети адаптировали для решения этой задачи
Наиболее важные статьи
Базовых архитектур в этой области не много. Если вы собираетесь работать с графами или неструктурированными данными, вам нужно иметь представление о следующих моделях:
- PointNet
- PointNet++
- DGCNN
Рассмотрим их поподробнее.
- PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Первопроходцы в работе с неструктурированными данными.- как решают: Одна сеть с двумя головами. Модель состоит из следующих блоков:
- сеть для определения преобразования (перевод системы координат), которое потом применится ко всем точкам
- преобразование, применяемое к каждой точке по отдельности (обычный персепторн)
- maxpooling, который объединяет информацию с разных точек и создает глобальный вектор признаков для всего объекта.
- далее сеть делится на две части:
- голова для классификации: глобальный вектор признаков идет на вход полносвязному слою для определения класса всего облака точек
- голова для сегментации: глобальный вектор признаков и подсчитанные признаки для каждой точки идут на полносвязному слою, которая определяет класс для каждой точки.
- код
- как решают: Одна сеть с двумя головами. Модель состоит из следующих блоков:

- PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Те же ребята из Стенфорда, что описали PointNet.- как решают: рекурсивно применяют pointNet к более мелким подоблакам, по аналогии со сверточными сетями. То есть делят пространство кубы, к каждому применяют PointNet, потом из этих кубов составляются новые кубы. Это позволяет выделить локальные признаки, которые теряла предыдущая версия сети.
- код


Статьи на основе PointNet и PointNet++:
В основном статьи отличаются подсчетом ошибки или глубиной и начилием сложных блоков.
PointWise: An Unsupervised Point-wise Feature Learning Network
Особенность работы — обучение без учителя- как решают: для каждой точки обучают вектор эмбедингов, по которому потом и сегментируют.
Основной постулат статьи — похожие объекты должны иметь похожие эмбединги (например две разные ножки стула), несмотря на их удаленность. В качестве базовой модели используют PointNet. Основное новшество — функция ошибки. Она состоит из двух частей: ошибки реконструкции и ошибки гладкости.
Ошибка реконструкции использует информацию о контексте точки. Её задача — сделать эмбединги точек с одинаковым геометрическим контекстом похожими. Для её подсчета на основе вектора эмбедингов для выбранной точки генерируются новые точки около нее. То есть признаковое описание точки должно содержать информацию об форме объекта вокруг точки. Дальше считают, насколько сгенерированные точки выпадают из реальной формы объекта.
Ошибка гладкости нужна для того, чтобы эмбединги были похожими у лежащих рядом точек и непохожими у далеких точек. Тут самое прекрасное — измерение близости не просто как нормы между двумя точками в евклидовом пространстве, а подсчет расстояние через точки объекта. Для каждой точки выбирается одна точка из k ближайших и из k дальнейших.
Текущий эмбединг должен быть ближе к ближайшей минимум на некий margin, чем до дальнейшей.
- как решают: для каждой точки обучают вектор эмбедингов, по которому потом и сегментируют.
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation
- как решают: как и в PointWise тут самое интересное в подсчете ошибки. В качестве основы — PointNet++, вначале считаем вектор признаков и принадлежнсть объекту для каждой точки в отдельности по аналогии с PointNet++.
Далее на основе признаков считаем 3 матрицы (похожести, уверенности и сегментации).
Ошибка обучения будет суммой из трех ошибок, подсчитанных по соответствующим матрицам: L = L1 + L2 + L3
Пусть N — количество точек
Матрица похожести — квадратная, размером N*N. Элемент на пересечении iой строки и jго столбца говорит о том, принадлежат ли эти точки одному объекту или нет. Точки, принадлежащие одному объекту, должны иметь похожие вектора признаков. Элементы матрицы могут принимать одно из трех значений: точки i и j принадлежат одному объекту, точки принадлежат одному классу объектов, но разным объектам (и то, и то стул, но стулья разные), или это вообще точки из объектов разных классов. Эта матрица считается по истинным значениям.
Матрица уверенности — это вектор длинны N. Для каждой точки считают пересечение деленное на объединение (intersection over union — IoU) между множеством точек, которые принадлежат объекту согласно работе нашего алгоритма, и множеством точек, которые в реальности принадлежат объекту с текущей точкой. Ошибка — просто L2 норма между правдой и подсчитанной матрицей. То есть сеть пытается предсказать, насколько она уверена в предсказание класса для точек объекта.
Матрица сегментации имеет размер — N * количество классов. Ошибка здесь считается как кроссэнтропия в задаче многоклассовой классификации. - код
- как решают: как и в PointWise тут самое интересное в подсчете ошибки. В качестве основы — PointNet++, вначале считаем вектор признаков и принадлежнсть объекту для каждой точки в отдельности по аналогии с PointNet++.

- Know What Your Neighbors Do:3D Semantic Segmentation of Point Clouds
- как решают: Вначале долго считают признаки, сложнее чем в PointNet, с кучей residual связей, и сумм, но в общем и целом — то же самое. Небольшое отличие — они считают признаки для каждой точки в глобальных и локальных координатах.
Основное отличие тут — это снова подсчет ошибки. Это не стандартная кроссэнтропия, а сумма двух ошибок:- pairwise distance loss — точки из одного объекта должны быть ближе чем τ_near и точки из разных объектов должны быть дольше чем τ_far.
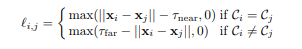
- centroid loss — точки из одного объекта должны быть близки друг к другу
- pairwise distance loss — точки из одного объекта должны быть ближе чем τ_near и точки из разных объектов должны быть дольше чем τ_far.
- как решают: Вначале долго считают признаки, сложнее чем в PointNet, с кучей residual связей, и сумм, но в общем и целом — то же самое. Небольшое отличие — они считают признаки для каждой точки в глобальных и локальных координатах.
статьи на основе DGCNN:
DGCNN была опубликована недавно (2018), поэтому основанных на этой архитектуре статей немного. Я хочу обратить ваше внимание на одну:
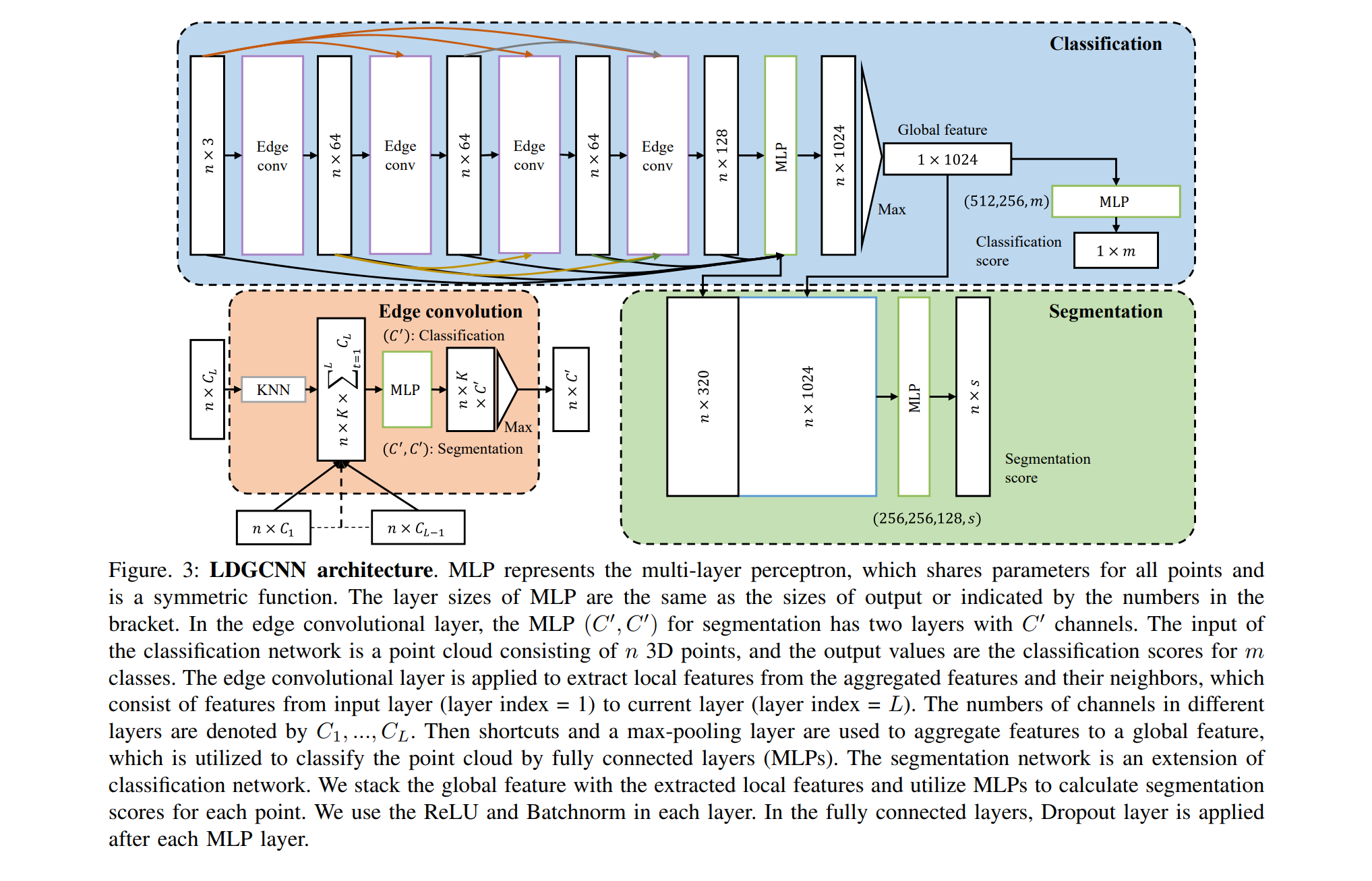
Заключение
Здесь вы могли найти краткую информацию о современных методах решения задач классификации и сегментации в Point Clouds. Существуют две основных модели (PointNet++, DGCNN), модификации которых сейчас используют для решения этих задач. Чаще всего для модификации изменяют функцию ошибки и усложняют эти архитектуры, добавляя слои и связи.
