[Из песочницы] Создаем EXE
Самоизоляция это отличное время приступить к тому, что требует много времени и сил. Поэтому я решил заняться тем, чем всегда хотел — написать свой компилятор.
Сейчас он способен собрать Hello World, но в этой статье я хочу рассказать не про парсинг и внутреннее устройство компилятора, а про такую важную часть как побайтовая сборка exe файла.
Начало
Хотите спойлер? Наша программа будет занимать 2048 байт.
Обычно работа с exe файлами заключается в изучении или модификации их структуры. Сами же исполняемые файлы при этом формируют компиляторы, и этот процесс, кажется, немного магическим для разработчиков.
Но сейчас мы с вами попробуем это исправить!
Для сборки нашей программы нам потребуется любой HEX редактор (лично я использовал HxD).
Для старта возьмем псевдокод:
func MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll']
func ExitProcess(u32 code) ['kernel32.dll']
func main()
{
MessageBoxA(0, 'Hello World!', 'MyApp', 64)
ExitProcess(0)
}
Первые две строки указывают на функции импортируемые из библиотек WinAPI. Функция MessageBoxA выводит диалоговое окно с нашим текстом, а ExitProcess сообщает системе о завершении программы.
Рассматривать отдельно функцию main нет смысла, так как в ней используются функции, описанные выше.
DOS Header
Для начала нам нужно сформировать корректный DOS Header, это заголовок для DOS программ и влиять на запуск exe под Windows не должен.
Более-менее важные поля я отметил, остальные заполнены нулями.
Struct IMAGE_DOS_HEADER
{
u16 e_magic // 0x5A4D "MZ"
u16 e_cblp // 0x0080 128
u16 e_cp // 0x0001 1
u16 e_crlc
u16 e_cparhdr // 0x0004 4
u16 e_minalloc // 0x0010 16
u16 e_maxalloc // 0xFFFF 65535
u16 e_ss
u16 e_sp // 0x0140 320
u16 e_csum
u16 e_ip
u16 e_cs
u16 e_lfarlc // 0x0040 64
u16 e_ovno
u16[4] e_res
u16 e_oemid
u16 e_oeminfo
u16[10] e_res2
u32 e_lfanew // 0x0080 128
}
Самое главное, что этот заголовок содержит поле e_magic означающее, что это исполняемый файл, и e_lfanew — указывающее на смещение PE-заголовка от начала файла (в нашем файле это смещение равно 0×80 = 128 байт).
Отлично, теперь, когда нам известна структура заголовка DOS Header запишем ее в наш файл.
4D 5A 80 00 01 00 00 00 04 00 10 00 FF FF 00 00
40 01 00 00 00 00 00 00 40 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 80 00 00 00

УточнениеСначала я использовал левую колонку как на скриншоте для указания смещения внутри файла, но тогда неудобно копировать исходный текст, приходится обрезать каждую строку.
Поэтому для удобства в первой скобке каждого блока указан порядок добавления в файл, а в последней смещение в файле (Offset) по которому должен располагаться данный блок.
Например, первый блок мы вставляем по смещению 0×00000000, и он займет 64 байта (0×40 в 16-ричной системе), следующий блок мы будем вставлять уже по этому смещению 0×00000040 и т.д.
Готово, первые 64 байта записали. Теперь нужно добавить еще 64, это так называемый DOS Stub (Заглушка). Во время запуска из-под DOS, она должна уведомить пользователя что программа не предназначена для работы в этом режиме.
Но в целом, это маленькая программа под DOS которая выводит строку и выходит из программы.
Запишем наш Stub в файл и рассмотрим его детальнее.
0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68
69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F
74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20
6D 6F 64 65 2E 0D 0A 24 00 00 00 00 00 00 00 00

А теперь этот же код, но уже в дизассемблированном виде
0000 push cs ; Запоминаем Code Segment(CS) (где мы находимся в памяти)
0001 pop ds ; Указываем что Data Segment(DS) = CS
0002 mov dx, 0x0E ; Указываем адрес начала строки DS+DX, которая будет выводится до символа $(Конец строки)
0005 mov ah, 0x09 ; Номер инструкции (Вывод строки)
0007 int 0x21 ; Вызов системного прерывания 0x21
0009 mov ax, 0x4C01 ; Номер инструкции 0x4C (Выход из программы)
; Код выхода из программы 0x01 (Неудача)
000c int 0x21 ; Вызов системного прерывания 0x21
000e "This program cannot be run in DOS mode.\x0D\x0A$" ; Выводимая строка
Это работает так: сначала заглушка выводит строку о том, что программа не может быть запущена, а затем выходит из программы с кодом 1. Что отличается от нормального завершения (Код 0).
Код заглушки может немного отличатся (от компилятора к компилятору) я сравнивал gcc и delphi, но общий смысл одинаковый.
А еще забавно, что строка заглушки заканчивается как \x0D\x0D\x0A$. Скорее всего причина такого поведения в том, что c++ по умолчанию открывает файл в текстовом режиме. В результате символ \x0A заменяется на последовательность \x0D\x0A. В результате получаем 3 байта: 2 байта возврата каретки Carriage Return (0×0D) что бессмысленно, и 1 на перевод строки Line Feed (0×0A). В бинарном режиме записи (std: ios: binary) такой подмены не происходит.
Для проверки корректности записи значений я буду использовать Far с плагином ImpEx:

NT Header
Спустя 128 (0×80) байт мы добрались до NT заголовка (IMAGE_NT_HEADERS64), который содержит в себе и PE заголовок (IMAGE_OPTIONAL_HEADER64). Несмотря на название IMAGE_OPTIONAL_HEADER64 является обязательным, но различным для архитектур x64 и x86.
Struct IMAGE_NT_HEADERS64
{
u32 Signature // 0x4550 "PE"
Struct IMAGE_FILE_HEADER
{
u16 Machine // 0x8664 архитектура x86-64
u16 NumberOfSections // 0x03 Количество секций в файле
u32 TimeDateStamp // Дата создания файла
u32 PointerToSymbolTable
u32 NumberOfSymbols
u16 SizeOfOptionalHeader // Размер IMAGE_OPTIONAL_HEADER64 (Ниже)
u16 Characteristics // 0x2F
}
Struct IMAGE_OPTIONAL_HEADER64
{
u16 Magic // 0x020B Указывает что наш заголовок для PE64
u8 MajorLinkerVersion
u8 MinorLinkerVersion
u32 SizeOfCode
u32 SizeOfInitializedData
u32 SizeOfUninitializedData
u32 AddressOfEntryPoint // 0x1000
u32 BaseOfCode // 0x1000
u64 ImageBase // 0x400000
u32 SectionAlignment // 0x1000 (4096 байт)
u32 FileAlignment // 0x200
u16 MajorOperatingSystemVersion // 0x05 Windows XP
u16 MinorOperatingSystemVersion // 0x02 Windows XP
u16 MajorImageVersion
u16 MinorImageVersion
u16 MajorSubsystemVersion // 0x05 Windows XP
u16 MinorSubsystemVersion // 0x02 Windows XP
u32 Win32VersionValue
u32 SizeOfImage // 0x4000
u32 SizeOfHeaders // 0x200 (512 байт)
u32 CheckSum
u16 Subsystem // 0x02 (GUI) или 0x03 (Console)
u16 DllCharacteristics
u64 SizeOfStackReserve // 0x100000
u64 SizeOfStackCommit // 0x1000
u64 SizeOfHeapReserve // 0x100000
u64 SizeOfHeapCommit // 0x1000
u32 LoaderFlags
u32 NumberOfRvaAndSizes // 0x16
Struct IMAGE_DATA_DIRECTORY [16]
{
u32 VirtualAddress
u32 Size
}
}
}
Разберемся что хранится в этой структуре:
Далее идет заголовок IMAGE_FILE_HEADER общий для архитектур x86 и x64.
Machine — Указывает для какой архитектуры предназначен код в нашем случае для x64
NumberOfSections — Количество секции в файле (О секциях чуть ниже)
TimeDateStamp — Дата создания файла
SizeOfOptionalHeader — Указывает размер следующего заголовка IMAGE_OPTIONAL_HEADER64, ведь он может быть заголовком IMAGE_OPTIONAL_HEADER32.
Characteristics — Здесь мы указываем некоторые атрибуты нашего приложения, например, что оно является исполняемым (EXECUTABLE_IMAGE) и может работать более чем с 2 Гб RAM (LARGE_ADDRESS_AWARE), а также что некоторая информация была удалена (на самом деле даже не была добавлена) в файл (RELOCS_STRIPPED | LINE_NUMS_STRIPPED | LOCAL_SYMS_STRIPPED).
SizeOfCode — Размер исполняемого кода в байтах (секция .text)
SizeOfInitializedData — Размер инициализированных данных (секция .rodata)
SizeOfUninitializedData — Размер не инициализированных данных (секция .bss)
BaseOfCode — указывает на начало секции кода блок
SectionAlignment — Размер по которому нужно выровнять секции в памяти
FileAlignment — Размер по которому нужно выровнять секции внутри файла
SizeOfImage — Размер всех секций программы
SizeOfHeaders — Размер всех заголовков вместе (IMAGE_DOS_HEADER, DOS Stub, IMAGE_NT_HEADERS64, IMAGE_SECTION_HEADER[IMAGE_FILE_HEADER.NumberOfSections]) выровненный по FileAlignment
Subsystem — Указывает тип нашей программы GUI или Console
MajorOperatingSystemVersion, MinorOperatingSystemVersion, MajorSubsystemVersion, MinorSubsystemVersion — Говорят о том на какой системе можно запускать данный exe, и что он может поддерживать. В нашем случае мы берем значение 5.2 от Windows XP (x64).
SizeOfStackReserve — Указывает сколько приложению нужно зарезервировать памяти под стек. Этот параметр по умолчанию составляет 1 Мб, максимально можно указать 1Гб. Вроде как умные программы на Rust умеют считать необходимый размер стека, в отличии от программ на C++ где этот размер нужно править вручную.
SizeOfStackCommit — Размер по умолчанию составляет 4 Кб. Как должен работать данный параметр пока не разобрался.
SizeOfHeapReserve — Указывает сколько резервировать памяти под кучу. Равен 1 Мб по умолчанию.
SizeOfHeapCommit — Размер по умолчанию равен 4 Кб. Подозреваю что работает аналогично SizeOfStackCommit, то есть пока неизвестно как.
IMAGE_DATA_DIRECTORY — массив записей о каталогах. В теории его можно уменьшить, сэкономив пару байт, но вроде как все описывают все 16 полей даже если они не нужны. А теперь чуть подробнее.
У каждого каталога есть свой номер, который описывает, где хранится его содержимое. Пример:
Export (0) — Содержит ссылку на сегмент который хранит экспортируемые функции. Для нас это было бы актуально если бы мы создавали DLL. Как это примерно должно работать можно посмотреть на примере следующего каталога.
Import (1) — Этот каталог указывает на сегмент с импортируемыми функциями из других DLL. В нашем случае значения VirtualAddress = 0×3000 и Size = 0xB8. Это единственный каталог, который мы опишем.
Resource (2) — Каталог с ресурсами программы (Изображения, Текст, Файлы и т.д.)
Значения других каталогов можно посмотреть в документации.
Теперь когда мы посмотрели из чего состоит NT-заголовок запишем и его в файл по аналогии с остальными по адресу 0×80.
50 45 00 00 64 86 03 00 F4 70 E8 5E 00 00 00 00
00 00 00 00 F0 00 2F 00 0B 02 00 00 3D 00 00 00
13 00 00 00 00 00 00 00 00 10 00 00 00 10 00 00
00 00 40 00 00 00 00 00 00 10 00 00 00 02 00 00
05 00 02 00 00 00 00 00 05 00 02 00 00 00 00 00
00 40 00 00 00 02 00 00 00 00 00 00 02 00 00 00
00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00
00 00 10 00 00 00 00 00 00 10 00 00 00 00 00 00
00 00 00 00 10 00 00 00 00 00 00 00 00 00 00 00
00 30 00 00 B8 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
В результате получаем вот такой вид IMAGE_FILE_HEADER, IMAGE_OPTIONAL_HEADER64 и IMAGE_DATA_DIRECTORY заголовков:

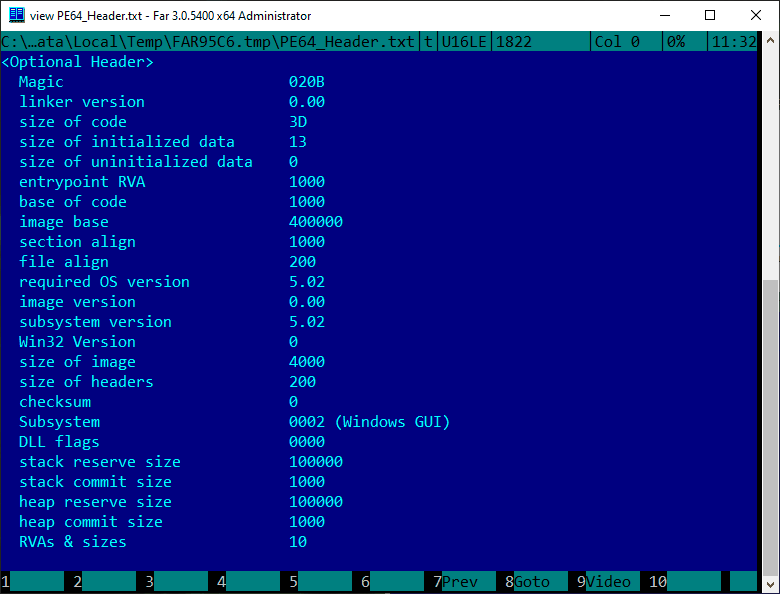

Далее описываем все секции нашего приложения согласно структуре IMAGE_SECTION_HEADER
Struct IMAGE_SECTION_HEADER
{
i8[8] Name
u32 VirtualSize
u32 VirtualAddress
u32 SizeOfRawData
u32 PointerToRawData
u32 PointerToRelocations
u32 PointerToLinenumbers
u16 NumberOfRelocations
u16 NumberOfLinenumbers
u32 Characteristics
}
Name — имя секции из 8 байт, может быть любым
VirtualSize — сколько байт копировать из файла в память
VirtualAddress — адрес секции в памяти выровненный по SectionAlignment
SizeOfRawData — размер сырых данных выровненных по FileAlignment
PointerToRawData — адрес секции в файле выровненный по FileAlignment
Characteristics — Указывает какие данные хранит секция (Код, инициализированные или нет данные, для чтения, для записи, для исполнения и др.)
В нашем случае у нaс будет 3 секции.
Почему Virtual Address (VA) начинается с 1000, а не с нуля я не знаю, но так делают все компиляторы, которые я рассматривал. В результате 1000 + 3 секции * 1000 (SectionAlignment) = 4000 что мы и записали в SizeOfImage. Это полный размер нашей программы в виртуальной памяти. Вероятно, используется для выделения места под программу в памяти.
Name | RAW Addr | RAW Size | VA | VA Size | Attr
--------+---------------+---------------+-------+---------+--------
.text | 200 | 200 | 1000 | 3D | CER
.rdata | 400 | 200 | 2000 | 13 | I R
.idata | 600 | 200 | 3000 | B8 | I R
Расшифровка атрибутов:
I — Initialized data, инициализированные данные
U — Uninitialized data, не инициализированные данные
C — Code, содержит исполняемый код
E — Execute, позволяет исполнять код
R — Read, позволяет читать данные из секции
W — Write, позволяет записывать данные в секцию
.text (.code) — хранит в себе исполняемый код (саму программу), атрибуты CE
.rdata (.rodata) — хранит в себе данные только для чтения, например константы, строки и т.п., атрибуты IR
.data — хранит данные которые можно читать и записывать, такие как статические или глобальные переменные. Атрибуты IRW
.bss — хранит не инициализированные данные, такие как статические или глобальные переменные. Кроме того, данная секция обычно имеет нулевой RAW размер и ненулевой VA Size, благодаря чему не занимает места в файле. Атрибуты URW
.idata — секция содержащая в себе импортируемые из других библиотек функции. Атрибуты IR
Важный момент, секции должны следовать друг за другом. При чем как в файле, так и в памяти. По крайней мере когда я менял их порядок произвольно программа переставала запускаться.
Теперь, когда нам известно какие секции будет содержать наша программа запишем их в наш файл. Тут смещение оканчивается на 8 и запись будет начинаться с середины файла.
2E 74 65 78 74 00 00 00
3D 00 00 00 00 10 00 00 00 02 00 00 00 02 00 00
00 00 00 00 00 00 00 00 00 00 00 00 20 00 00 60
2E 72 64 61 74 61 00 00 13 00 00 00 00 20 00 00
00 02 00 00 00 04 00 00 00 00 00 00 00 00 00 00
00 00 00 00 40 00 00 40 2E 69 64 61 74 61 00 00
B8 00 00 00 00 30 00 00 00 02 00 00 00 06 00 00
00 00 00 00 00 00 00 00 00 00 00 00 40 00 00 40

Следующий адрес для записи будет 00000200 что соответствует полю SizeOfHeaders PE-Заголовка. Если бы мы добавили еще одну секцию, а это плюс 40 байт, то наши заголовки не уложились бы в 512 (0×200) байт и пришлось бы использовать уже 512+40 = 552 байта выровненные по FileAlignment, то есть 1024 (0×400) байта. А все что останется от 0×228 (552) до адреса 0×400 нужно чем-то заполнить, лучше конечно нулями.
Взглянем как выглядит блок секций в Far:
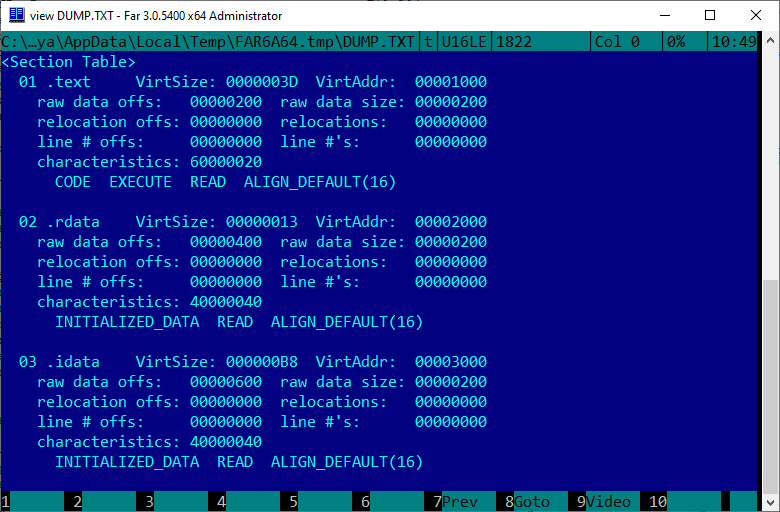
Далее мы запишем в наш файл сами секции, но тут есть один нюанс.
Как вы могли заметить на примере SizeOfHeaders, мы не можем просто записать заголовок и перейти к записи следующего раздела. Так как что бы записать заголовок мы должны знать сколько займут все заголовки вместе. В результате нам нужно либо посчитать заранее сколько понадобиться места, либо записать пустые (нулевые) значения, а после записи всех заголовков вернуться и записать уже их реальный размер.
Поэтому программы компилируются в несколько проходов. Например секция .rdata идет после секции .text, при этом мы не можем узнать виртуальный адрес переменной в .rdata, ведь если секция .text разрастется больше чем на 0×1000 (SectionAlignment) байт, она займет адреса 0×2000 диапазона. И соответственно секция .rdata будет находиться уже не в адресе 0×2000, а в адресе 0×3000. И нам будет необходимо вернуться и пересчитать адреса всех переменных в секции .text которая идет перед .rdata.
Но в данном случае я уже все рассчитал, поэтому будем сразу записывать блоки кода.
Секция .text
0000 push rbp
0001 mov rbp, rsp
0004 sub rsp, 0x20
0008 mov rcx, 0x0
000F mov rdx, 0x402000
0016 mov r8, 0x40200D
001D mov r9, 0x40
0024 call QWORD PTR [rip + 0x203E]
002A mov rcx, 0x0
0031 call QWORD PTR [rip + 0x2061]
0037 add rsp, 0x20
003B pop rbp
003C ret
Конкретно для этой программы первые 3 строки, ровно, как и 3 последние не обязательны.
Последние 3 даже не будут исполнены, так как выход из программы произойдет еще на второй функции call.
Но скажем так, если бы это была не функция main, а подфункция следовало бы сделать именно так.
А вот первые 3 в данном случае хоть и не обязательны, но желательны. Например, если бы мы использовали не MessageBoxA, а printf то без этих строк получили бы ошибку.
Согласно соглашению о вызовах для 64-разрядных систем MSDN, первые 4 параметра передаются в регистрах RCX, RDX, R8, R9. Если они туда помещаются и не являются, например числом с плавающей точкой. А остальные передаются через стек.
По идее если мы передаем 2 аргумента функции, то должны передать их через регистры и зарезервировать под них два места в стеке, что бы при необходимости функция могла скинуть регистры в стек. Так же мы не должны рассчитывать, что нам вернут эти регистры в исходном состоянии.
Так вот проблема функции printf заключается в том, что, если мы передаем ей всего 1 аргумент, она все равно перезапишет все 4 места в стеке, хотя вроде бы должна перезаписать только одно, по количеству аргументов.
Поэтому если не хотите, чтобы программа себя странно вела, всегда резервируйте как минимум 8 байт * 4 аргумента = 32(0×20) байт, если передаете функции хотя бы 1 аргумент.
Рассмотрим блок кода с вызовами функций
MessageBoxA(0, 'Hello World!', 'MyApp', 64)
ExitProcess(0)
Сначала мы передаем наши аргументы:
rcx = 0
rdx = абсолютный адрес строки в памяти ImageBase + Sections[».rdata»].VirtualAddress + Смещение строки от начала секции, строка читается до нулевого байта
r8 = аналогично предыдущему
r9 = 64(0×40) MB_ICONINFORMATION, значок информации
А далее идет вызов функции MessageBoxA, с которым не все так просто. Дело в том, что компиляторы стараются использовать как можно более короткие команды. Чем меньше размер команды, тем больше таких команд влезет в кэш процессора, соответственно, будет меньше промахов кэша, подзагрузок и выше скорость работы программы. Для более подробной информации по командам и внутренней работе процессора можно обратится к документации Intel 64 and IA-32 Architectures Software Developer«s Manuals.
Мы могли бы вызвать функцию по полному адресу, но это заняло бы как минимум (1 опкод + 8 адрес = 9 байт), а с относительным адресом команда call занимает всего 6 байт.
Давайте взглянем на эту магию поближе: rip + 0×203E, это ни что иное, как вызов функции по адресу, указанному нашим смещением.
Я подсмотрел немного вперед и узнал адреса нужных нам смещений. Для MessageBoxA это 0×3068, а для ExitProcess это 0×3098.
Пора превратить магию в науку. Каждый раз, когда опкод попадает в процессор, он высчитывает его длину и прибавляет к текущему адресу инструкции (RIP). Поэтому, когда мы используем RIP внутри инструкции, этот адрес указывает на конец текущей инструкции / начало следующей.
Для первого call смещение будет указывать на конец команды call это 002A не забываем что в памяти этот адрес будет по смещению Sections[».text»].VirtualAddress, т.е. 0×1000. Следовательно, RIP для нашего call будет равен 102A. Нужный нам адрес для MessageBoxA находится по адресу 0×3068. Считаем 0×3068 — 0×102A = 0×203E. Для второго адреса все аналогично 0×1000 + 0×0037 = 0×1037, 0×3098 — 0×1037 = 0×2061.
Именно эти смещения мы и видели в командах ассемблера.
0024 call QWORD PTR [rip + 0x203E]
002A mov rcx, 0x0
0031 call QWORD PTR [rip + 0x2061]
0037 add rsp, 0x20
Запишем в наш файл секцию .text, дополнив нулями до адреса 0×400:
55 48 89 E5 48 83 EC 20 48 C7 C1 00 00 00 00 48
C7 C2 00 20 40 00 49 C7 C0 0D 20 40 00 49 C7 C1
40 00 00 00 FF 15 3E 20 00 00 48 C7 C1 00 00 00
00 FF 15 61 20 00 00 48 83 C4 20 5D C3 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Хочется отметить что всего лишь 4 строки реального кода содержат весь наш код на ассемблере. А все остальное нули что бы набрать FileAlignment. Последней строкой заполненной нулями будет 0×000003F0, после идет 0×00000400, но это будет уже следующий блок. Итого в файле уже 1024 байта, наша программа весит уже целый Килобайт! Осталось совсем немного и ее можно будет запустить.
Секция .rdata
Это, пожалуй, самая простая секция. Мы просто положим сюда две строки добив нулями до 512 байт.
0400 "Hello World!\0"
040D "MyApp\0"
48 65 6C 6C 6F 20 57 6F 72 6C 64 21 00 4D 79 41
70 70 00 00 00 00 00 00 00 00 00 00 00 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Секция .idata
Ну вот осталась последняя секция, которая описывает импортируемые функции из библиотек.
Первое что нас ждет новая структура IMAGE_IMPORT_DESCRIPTOR
Struct IMAGE_IMPORT_DESCRIPTOR
{
u32 OriginalFirstThunk (INT)
u32 TimeDateStamp
u32 ForwarderChain
u32 Name
u32 FirstThunk (IAT)
}
OriginalFirstThunk — Адрес указывает на список имен импортируемых функций, он же Import Name Table (INT)
Name — Адрес, указывающий на название библиотеки
FirstThunk — Адрес указывает на список адресов импортируемых функций, он же Import Address Table (IAT)
Для начала нам нужно добавить 2 импортируемых библиотеки. Напомним:
func MessageBoxA(u32 handle, PChar text, PChar caption, u32 type) i32 ['user32.dll']
func ExitProcess(u32 code) ['kernel32.dll']
58 30 00 00 00 00 00 00 00 00 00 00 3C 30 00 00
68 30 00 00 88 30 00 00 00 00 00 00 00 00 00 00
48 30 00 00 98 30 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00
У нас используется 2 библиотеки, а что бы сказать что мы закончили их перечислять. Последняя структура заполняется нулями.
INT | Time | Forward | Name | IAT
--------+--------+----------+--------+--------
0x3058 | 0x0 | 0x0 | 0x303C | 0x3068
0x3088 | 0x0 | 0x0 | 0x3048 | 0x3098
0x0000 | 0x0 | 0x0 | 0x0000 | 0x0000
Теперь добавим имена самих библиотек:
063С "user32.dll\0"
0648 "kernel32.dll\0"
75 73 65 72
33 32 2E 64 6C 6C 00 00 6B 65 72 6E 65 6C 33 32
2E 64 6C 6C 00 00 00 00
Далее опишем библиотеку user32:
78 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 78 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 4D 65 73 73 61 67
65 42 6F 78 41 00 00 00
Поле Name первой библиотеки указывает на 0×303C если мы посмотрим чуть выше, то увидим что по адресу 0×063C находится библиотека «user32.dll\0».
Подсказка, вспомните что секция .idata соответствует смещению в файле 0×0600, а в памяти 0×3000. Для первой библиотеки INT равен 3058, значит в файле это будет смещение 0×0658. По этому адресу видим запись 0×3078 и вторую нулевую. Означающую конец списка. 3078 ссылается на 0×0678 это RAW-строка
»00 00 4D 65 73 73 61 67 65 42 6F 78 41 00 00 00»
Первые 2 байта нас не интересуют и равны нулю. А вот дальше идет строка с названием функции, заканчивающаяся нулем. То есть мы можем представить её как »\0\0MessageBoxA\0».
При этом IAT ссылается на аналогичную таблице IAT структуру, но только в нее при запуске программы будут загружены адреса функций. Например, для первой записи 0×3068 в памяти будет значение отличное от значения 0×0668 в файле. Там будет адрес функции MessageBoxA загруженный системой к которому мы и будем обращаться через вызов call в коде программы.
И последний кусочек пазла, библиотека kernel32. И не забываем добить нулями до SectionAlignment.
A8 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 A8 30 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 45 78 69 74 50 72
6F 63 65 73 73 00 00 00 00 00 00 00 00 00 00 00
........
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00

Проверяем что Far смог корректно определить какие функции мы импортировали:
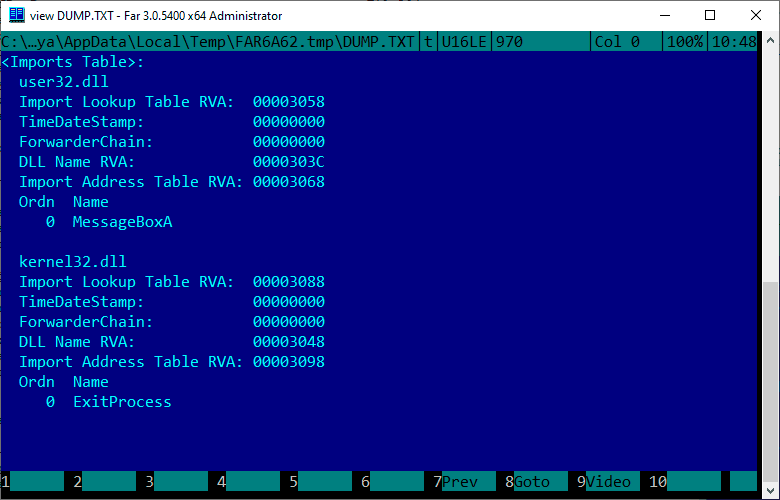
Отлично! Все нормально определилось, значит теперь наш файл готов к запуску.
Барабанная дробь…
Финал

Поздравляю мы справились!
Файл занимает 2 Кб = Заголовки 512 байт + 3 секции по 512 байт.
Число 512(0×200) не что иное как FileAlignment который мы указали в заголовке нашей программы.
Дополнительно:
Если хочется вникнуть чуть глубже, можно заменить надпись «Hello World!» на что-нибудь другое, только не забудьте изменить адрес строки в коде программы (секция .text). Адрес в памяти 0×00402000, но в файле будет обратный порядок байт 00 20 40 00.
Или квест чуть сложнее. Добавить в код вызов ещё одного MessageBox. Для этого придется скопировать предыдущий вызов, и пересчитать в нем относительный адрес (0×3068 — RIP).
Заключение
Статья получилась достаточно скомканной, ей бы, конечно, состоять из 3 отдельных частей: Заголовки, Программа, Таблица импорта.
Если кто-то собрал свой exe значит мой труд был не напрасен.
Думаю в скором времени создать ELF файл похожим образом, интересна ли будет такая статья?)
Ссылки:
