[Из песочницы] Сотворение мира Опыт создания разумной жизни своими руками

TL; DR
Под катом история о том, как я в качестве практики для изучения Python разрабатываю свою библиотеку для агентного моделирования с машинным обучением и богами.
Ссылка на github. Для работы из коробки нужен pygame. Для ознакомительного примера понадобится sklearn.
Зарождение идеи
Идея соорудить велосипед, о котором я буду рассказывать, появлялась постепенно. Во-первых, популярность темы машинного обучения не обошла меня стороной. Несколько курсов на курсере дали обманчивое ощущение причастности. Несколько открытых конкурсов и регистрация на kaggle немного откорректировали самомнение, однако, не охладили энтузиазм.
Во-вторых, будучи представителем касты неприкасаемых отечественного IT сообщества, я нечасто имею возможность попрактиковать нежно любимый мной Python. А от умных людей я слышал, что свой проект в этом плане — это как раз то, что надо.
Но толчком послужило разочарование No Man«s Sky. Технически шикарная идея, но процедурно сгенерированный мир оказался пустым. И как любой разочаровавшийся болельщик, я начал думать, что бы сделал я, если бы меня спрашивали. И придумал, что мир оказался пустым потому, что в нем на самом деле очень мало разумной жизни. Бескрайние просторы, привычка полагаться только на себя, радость первооткрывателя — это все, конечно, хорошо. Но не хватает возможности вернуться на базу, послоняться по рынку, узнать последние сплетни в забегаловке. Доставить посылку и получить за это свои 100 золотых, в конце концов. Понятно, что любой город, любой диалог или квест в играх — плод труда живого человека и населить жизнью такой огромный мир силами людей не представляется возможным. Но что если мы бы могли так же процедурно генерировать NPC с их потребностями, маленькими историями и квестами?
План в общих чертах
Так появилась идея некоторой библиотеки, или даже, если позволите, фреймворка, у которого были бы следующие сценарии использования:
- Классическое агентное моделирование (о существовании которого я узнал только тогда, когда сел писать эту статью). Создаем мир, описываем действия агентов в этом мире, смотрим, что получилось, меняем какие-то параметры, запускаем симуляцию еще раз. И так по кругу, пока не выясним, как изменения в действиях отдельных агентов влияют на общую картину. Очень полезная штука.
- Обучение с подкреплением (оно же reinforcement learning). Построение моделей обучения, адаптирующихся ко взаимодействию с определенной средой. Простой пример — обучение игре, правил которой вы не знаете, но в любой момент можете получить информацию о состоянии партии, выбрать одно из определенного набора действий и посмотреть, как это повлияло на количество заработанных вами очков (конкурс на эту тему, правда, уже закончился). Тут много отличий от обычных моделей классификаторов или регрессий. Это и возможная отложенность результата, и необходимость планирования, и много других особенностей.
- И, наконец, после того, как мы создадим мир и населим его живностью, разумной и не очень, неплохо было бы иметь возможность отправиться туда лично, прихватив свой верный бластер, любимый меч, многофункциональную кирку или красный гвоздодер.
Немного технических подробностей
Итак, для начала надо определиться с низкоуровневой физикой нашего мира. Она должна быть простой, но достаточно гибкой для моделирования разных ситуаций:
- Возьмем за основу обычный клеточный автомат — двумерный прямоугольный дискретный мир, каждый объект которого занимает одну планковскую длину в квадрате. Расстояния меньше планковской длины не будут иметь смысла — нельзя поместить объект между двумя клетками, нельзя расположить его так, чтобы он занимал больше одной клетки, даже не полностью.
- Расстояние будем измерять шагами только в четырех направлениях, то есть у клетки соседними будут 4, а не 8. До тех, что по диагонали, будет по 2 шага.
- Чтобы немного разбавить монолитность получившейся конструкции добавим немного глубины: каждый объект будет обладать признаком проходимости. По одним и тем же пространственным координатам в мире может находиться не менее одного, но не более двух объектов: проходимый и/или непроходимый. Можно представить это как поверхность, на которой стоят и по которой перемещаются объекты. Типы поверхностей бывают разные, типы объектов тоже. Можно на ковер (проходимый объект) поставить тумбу (непроходимый объект). Но нельзя постелить линолеум на ламинат (потому что, кто так делает вообще?) и нельзя поставить стул на тумбу.
- Зато в тумбе могут храниться разные предметы. И в ковре могут, и в карманах у активных объектов тоже. То есть, любой объект может быть контейнером для предметов. Но не для других объектов, иначе мы нарушим третий закон.
- Время также идет дискретно. Каждый шаг каждый объект живет одно планковское время, в течение которого он может получить извне информацию о мире вокруг него по состоянию на данную эпоху. Сейчас это самое слабое место — объектам приходится действовать по очереди, из-за этого получается некоторый рассинхрон. Объектам, до которых «ход» доходит позже, приходится учитывать состояние объектов, уже «походивших» в эту эпоху. Если позволять объектам ориентироваться только на начало эпохи, то это может привести к тому, что два непроходимых объекта, например, встанут на одну и ту же свободную в начале эпохи клетку. Или извлекут из комода один и тот же носок. Это можно немного нивелировать, обращаясь к объектам каждую эпоху в случайном порядке, но такой подход не решает проблему целиком.
Это дает нам несколько необходимых базовых объектов: сам мир (Field), объект этого мира (Entity) и предмет (Substance). Здесь и далее код в статье — просто иллюстрация. Полностью его можно посмотреть в библиотеке на github.
class Entity(object):
def __init__(self):
# home universe
self.board = None
# time-space coordinates
self.x = None
self.y = None
self.z = None
# lifecycle properties
self.age = 0
self.alive = False
self.time_of_death = None
# common properties
self.passable = False
self.scenery = True
self._container = []
# visualization properties
self.color = None
def contains(self, substance_type):
for element in self._container:
if type(element) == substance_type:
return True
return False
def live(self):
self.z += 1
self.age += 1
class Blank(Entity):
def __init__(self):
super(Blank, self).__init__()
self.passable = True
self.color = "#004400"
def live(self):
super(Blank, self).live()
if random.random() <= 0.0004:
self._container.append(substances.Substance())
if len(self._container) > 0:
self.color = "#224444"
else:
self.color = "#004400"
class Block(Entity):
def __init__(self):
super(Block, self).__init__()
self.passable = False
self.color = "#000000"
class Field(object):
def __init__(self, length, height):
self.__length = length
self.__height = height
self.__field = []
self.__epoch = 0
self.pause = False
for y in range(self.__height):
row = []
self.__field.append(row)
for x in range(self.__length):
if y == 0 or x == 0 or y == (height - 1) or x == (length - 1):
init_object = Block()
else:
init_object = Blank()
init_object.x = x
init_object.y = y
init_object.z = 0
row.append([init_object])
Класс Substance описывать смысла не имеет, в нем ничего нет.
За время у нас будет отвечать сам мир. Каждую эпоху он будет опрашивать все находящиеся в нем объекты и заставлять их делать ход. Как они проведут этот ход, уже их дело:
class Field(object):
...
def make_time(self):
if self.pause:
return
for y in range(self.height):
for x in range(self.length):
for element in self.__field[y][x]:
if element.z == self.epoch:
element.live()
self.__epoch += 1
...
Но зачем нам мир, да еще и с запланированной возможностью поместить в него протагониста, если мы не можем его увидеть? С другой стороны, если начать разбираться с графикой, можно сильно отвлечься, и правление миром отложится на неопределенный срок. Поэтому не тратя времени осваиваем вот эту замечательную статью про написание платформера с помощью pygame (на самом деле, нам понадобится только первая треть статьи), выдаем каждому объекту признак цвета, и вот у нас уже есть какое-то подобие карты.
class Field(object):
...
def list_obj_representation(self):
representation = []
for y in range(self.height):
row_list = []
for cell in self.__field[y]:
row_list.append(cell[-1])
representation.append(row_list)
return representation
....
def visualize(field):
pygame.init()
screen = pygame.display.set_mode(DISPLAY)
pygame.display.set_caption("Field game")
bg = Surface((WIN_WIDTH, WIN_HEIGHT))
bg.fill(Color(BACKGROUND_COLOR))
myfont = pygame.font.SysFont("monospace", 15)
f = field
tick = 10
timer = pygame.time.Clock()
go_on = True
while go_on:
timer.tick(tick)
for e in pygame.event.get():
if e.type == QUIT:
raise SystemExit, "QUIT"
if e.type == pygame.KEYDOWN:
if e.key == pygame.K_SPACE:
f.pause = not f.pause
elif e.key == pygame.K_UP:
tick += 10
elif e.key == pygame.K_DOWN and tick >= 11:
tick -= 10
elif e.key == pygame.K_ESCAPE:
go_on = False
screen.blit(bg, (0, 0))
f.integrity_check()
f.make_time()
level = f.list_obj_representation()
label = myfont.render("Epoch: {0}".format(f.epoch), 1, (255, 255, 0))
screen.blit(label, (630, 10))
stats = f.get_stats()
for i, element in enumerate(stats):
label = myfont.render("{0}: {1}".format(element, stats[element]), 1, (255, 255, 0))
screen.blit(label, (630, 25 + (i * 15)))
x = y = 0
for row in level:
for element in row:
pf = Surface((PLATFORM_WIDTH, PLATFORM_HEIGHT))
pf.fill(Color(element.color))
screen.blit(pf, (x, y))
x += PLATFORM_WIDTH
y += PLATFORM_HEIGHT
x = 0
pygame.display.update()
Конечно, позже можно будет написать несколько более вразумительный модуль визуализации, да не один. Но пока разноцветных бегающих квадратиков вполне хватает для того, чтобы погрузиться в атмосферу зарождающегося бытия. К тому же, это развивает фантазию.
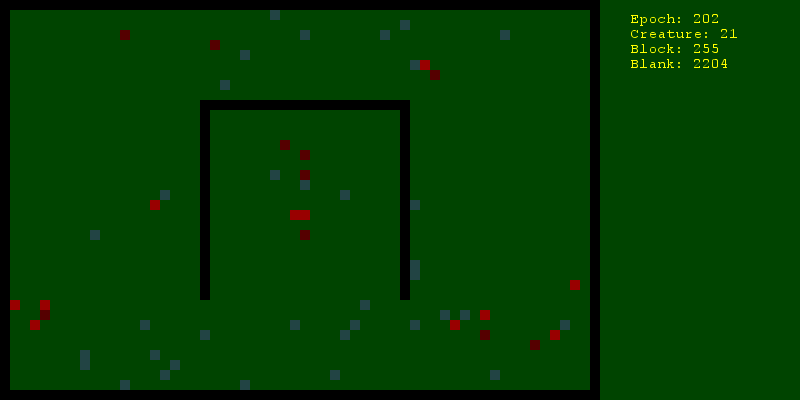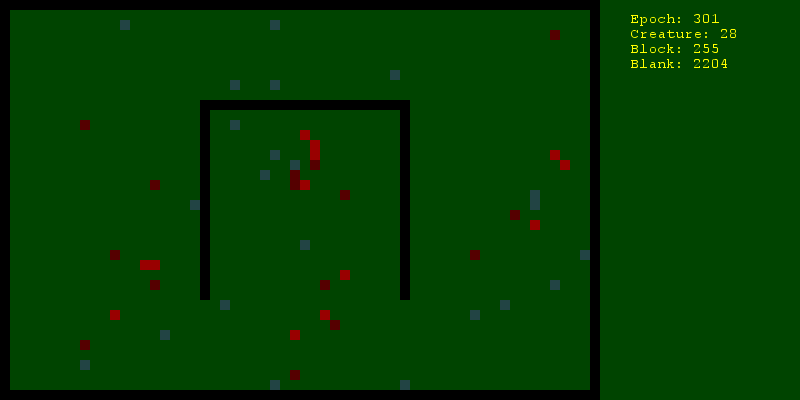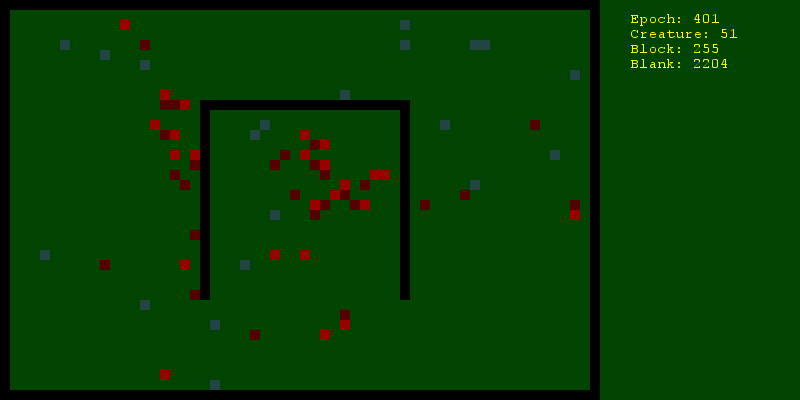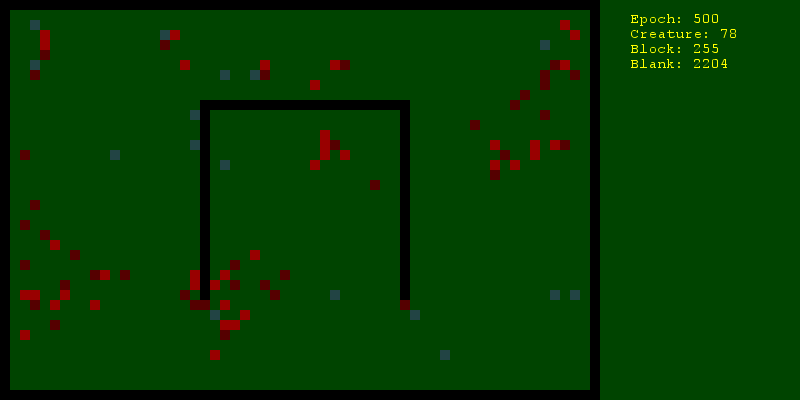
Теперь надо продумать, как активные агенты будут действовать. Во-первых, все значимые действия будут объектами (объектами Python, не объектами мира, приношу извинения за неоднозначность). Так можно хранить историю, манипулировать их состоянием, отличать одно действие от другого, даже если они однотипные. Итак, действия будут выглядеть следующим образом:
- Каждое действие должно иметь субъект. Субъектом действия может являться только объект нашего мира (Entity).
- Каждое действие должно иметь результаты. Как минимум «завершено/не завершено» и «цель достигнута/цель не достигнута». Но могут быть и дополнительные в зависимости от типа действия: например, действие «НайтиБлижайшуюПиццерию» может в качестве результатов, помимо обязательных, иметь координаты или сам объект пиццерии.
- Каждое действие может иметь, а может не иметь набор параметров. Например, действие «НалитьЧашечкуКофе» может не иметь параметров, так как не требует уточнения, в то время как для действия «Налить» необходима возможность уточнить, что налить и куда.
- Действие может быть мгновенным или не мгновенным. В течение одной эпохи один объект может совершить не более одного не мгновенного действия и любое количество мгновенных. Это спорный момент — если у нас дискретно пространство и мы не можем подвинуться на полклетки, то возможность производить неограниченное количество действий в течение одной эпохи выглядит странным и несколько размывает четкое дискретное течение времени. Была также идея задавать каждому типу действий время, которое необходимо на него потратить, в пределах от 0 до 1, где действие длительностью в 1 занимает всю эпоху целиком. Пока я остановился на варианте с признаком мгновенности, так как для четкости дискретного времени всегда можно все действия, необходимые для симуляции, сделать не мгновенными, а вариант с длительностью все слишком усложняет.
Таким образом, с технической точки зрения объект действия (Action) представляет собой некоторое подобие функции, которой можно задать параметры, выполнить, получить результат, и которая при этом сама в себе хранит и переданные ей параметры, и результат, и все что угодно, что связано с ее выполнением, начиная с того, кто ее вызвал, и заканчивая состоянием мира вокруг во время ее выполнения. Поэтому мы можем в одно время ее создать, в другое задать параметры, в третье выполнить, получить возвращаемое значение и положить на полочку для последующего анализа.
class Action(object):
def __init__(self, subject):
self.subject = subject
self.accomplished = False
self._done = False
self.instant = False
def get_objective(self):
return {}
def set_objective(self, control=False, **kwargs):
valid_objectives = self.get_objective().keys()
for key in kwargs.keys():
if key not in valid_objectives:
if control:
raise ValueError("{0} is not a valid objective".format(key))
else:
pass # maybe need to print
else:
setattr(self, "_{0}".format(key), kwargs[key])
def action_possible(self):
return True
def do(self):
self.check_set_results()
self._done = True
def check_set_results(self):
self.accomplished = True
@property
def results(self):
out = {"done": self._done, "accomplished": self.accomplished}
return out
def do_results(self):
self.do()
return self.results
Если кто-нибудь кроме меня вдруг захочет создать себе уютный мирок с помощью этой библиотеки, то предполагается, что из коробки она будет содержать набор необходимых низкоуровневых действий — отправиться по координатам, следовать за объектом, найти определенный объект или предмет, подобрать предмет и т.д. Этими действиями можно будет пользоваться как самими по себе, так и комбинировать их для произведения каких-то сложных манипуляций. Пример таких комплексных действий будет далее, в описании первого эксперимента.
Во-вторых, каждый уважающий себя активный агент должен уметь планировать свои действия. Поэтому разделим фазу его активности в течение эпохи на 2 этапа: планирование и действие. В качестве инструмента планирования у нас будет простая очередь действий, которые мы собираемся последовательно выполнять. Однако если у нас уже есть план, то нечего лишний раз размышлять, надо действовать быстро, решительно. Получается, что в начале хода активный объект определяет, надо ли на этот ход планировать (для начала будем считать, что надо, когда очередь действий пуста), затем планирует, если решил, что это необходимо, и в конце выполняет действия. Должно ли планирование, как серьезный процесс, не терпящий спешки, занимать весь ход — вопрос дискуссионный. Для своих целей я пока остановился на том, что нет — мои агенты долго не размышляют и приступают к выполнению плана в тот же ход.
class Agent(Entity):
...
def live(self):
...
if self.need_to_update_plan():
self.plan()
if len(self.action_queue) > 0:
current_action = self.action_queue[0]
self.perform_action(current_action)
while len(self.action_queue) > 0 and self.action_queue[0].instant:
current_action = self.action_queue[0]
self.perform_action(current_action)
def need_to_update_plan(self):
return len(self.action_queue) == 0
def perform_action(self, action):
results = action.do_results()
if results["done"] or not action.action_possible():
self.action_log.append(self.action_queue.pop(0))
return results
...
...
Вдобавок к этому мне показалось удобным ввести такую сущность как состояние объекта, которое могло бы влиять на его действия. Ведь, агент может устать, быть не в настроении, намокнуть, отравиться или наоборот, быть веселым и полным сил. Иногда даже одновременно. Поэтому добавим нашим объектам массив состояний, каждое из которых будет влиять на объект в начале эпохи.
class State(object):
def __init__(self, subject):
self.subject = subject
self.duration = 0
def affect(self):
self.duration += 1
class Entity(object):
def __init__(self):
...
self._states_list = []
...
...
def get_affected(self):
for state in self._states_list:
state.affect()
def live(self):
self.get_affected()
self.z += 1
self.age += 1
...
Для моделирования и обучения необходимо иметь возможность оценить, насколько удачно мы написали алгоритм действий или выбрали модель обучения. Для этого добавим простой модуль симуляции и оценки с возможностью описывать способ определения конца симуляции и сбора результатов.
import copy
def run_simulation(initial_field, check_stop_function, score_function, times=5, verbose=False):
list_results = []
for iteration in range(times):
field = copy.deepcopy(initial_field)
while not check_stop_function(field):
field.make_time()
current_score = score_function(field)
list_results.append(current_score)
if verbose:
print "Iteration: {0} Score: {1})".format(iteration+1, current_score)
return list_results
На этом этапе все, в принципе, готово для закрытия первого сценария использования нашей библиотеки: моделирования, если мы не хотим обучать агентов, а хотим прописывать логику их действий самостоятельно. Порядок действий в таком случае следующий:
- Решаем, какие статические объекты мы хотим видеть в мире: стены, горы, мебель, типы поверхностей и т.д. Описываем их, наследуя класс Entity. То же самое делаем с предметами и классом Substance.
- Создаем мир нужного размера, заполняем его пейзажем из этих объектов и предметов.
- Наследуем класс Action и описываем все нужные нам действия. То же самое делаем с классом State и состояниями, если они нужны для нашей симуляции.
- Создаем класс наших агентов, наследуя Agent. Добавляем в него служебные функции, описываем процесс планирования.
- Населяем наш мир активными агентами.
- Для отладки действий и наслаждения созерцанием своего творения можно погонять визуализацию.
- И в итоге, наигравшись с визуализацией, запускаем симуляцию и оцениваем, насколько удачно созданные нами агенты играют по созданным нами правилам в созданном нами мире.
Proof of concept I
Итак, огласим условия первого эксперимента.
- Мир состоит из: стены, земля. Стены — просто непроходимые стены, больше ничего. С землей интереснее — каждую эпоху есть ненулевая вероятность, что в любой или в нескольких клетках земли появится единица ресурса.
- Население: существа двух полов. Так как для простоты мы пол будем хранить в логической переменной, пол может быть ложный или истинный.
- Существа ложного пола жадины и имеют целью своей жизни собрать как можно больше ресурса. Как только они появляются, они находят ближайшую клетку с ресурсом, идут к ней, собирают ресурс и так по кругу. Однако именно они наделены способностью к деторождению.
- Существа истинного пола несколько разнообразнее. У них на выбор есть два действия: тоже собирать ресурс или искать партнера для спаривания (естественно, противоположного пола, чтобы ненароком не угодить в места, где ресурсов немного, а о возможных партнерах для спаривания лучше даже не думать).
- Когда решившее спариваться существо истинного пола догоняет выбранного партнера и предлагает ему уединиться, существо ложного пола решает, расположено ли оно к спариванию, по определенным правилам, основанным на количестве ресурса у обоих участников. Если у предлагающего ресурсов больше, то он получает согласие. Если меньше или одинаково, то вероятность спаривания зависит от разницы в количестве ресурсов.
- Через десять эпох после зачатия рождается существо случайного пола. Оно появляется на свет сразу, взрослым, и действует в соответствии с правилами для своего пола.
- Все существа должны умереть. У каждого существа каждую эпоху, начиная с десятой после его рождения, есть ненулевая и постоянная вероятность прекратить свое активное существование.
Нашей задачей будет написать процедуру планирования для существ истинного пола таким образом чтобы популяция существ размножалась как можно быстрее.
Дочитавших до этого места я из благодарности не буду утомлять длинными иллюстрациями, покажу только:
class GoMating(Action):
def __init__(self, subject):
super(GoMating, self).__init__(subject)
self.search_action = SearchMatingPartner(subject)
self.move_action = MovementToEntity(subject)
self.mate_action = Mate(subject)
self.current_action = self.search_action
def action_possible(self):
if not self.current_action:
return False
return self.current_action.action_possible()
def do(self):
if self.subject.has_state(states.NotTheRightMood):
self._done = True
return
if self.results["done"]:
return
if not self.action_possible():
self._done = True
return
first = True
while first or (self.current_action and self.current_action.instant) and not self.results["done"]:
first = False
current_results = self.current_action.do_results()
if current_results["done"]:
if current_results["accomplished"]:
if isinstance(self.current_action, SearchMatingPartner):
if current_results["accomplished"]:
self.current_action = self.move_action
self.current_action.set_objective(**{"target_entity": current_results["partner"]})
elif isinstance(self.current_action, MovementXY):
self.current_action = self.mate_action
self.current_action.set_objective(**{"target_entity": self.search_action.results["partner"]})
elif isinstance(self.current_action, Mate):
self.current_action = None
self.accomplished = True
self._done = True
else:
self.current_action = None
self._done = True
else:
break
def check_set_results(self):
self.accomplished = self._done
class Creature(Agent):
...
def plan(self):
nearest_partner = actions.SearchMatingPartner(self).do_results()["partner"]
if nearest_partner is None:
chosen_action = actions.HarvestSubstance(self)
chosen_action.set_objective(** {"target_substance_type": type(substances.Substance())})
self.queue_action(chosen_action)
else:
self_has_substance = self.count_substance_of_type(substances.Substance)
partner_has_substance = nearest_partner.count_substance_of_type(substances.Substance)
if partner_has_substance - self_has_substance > 2:
self.queue_action(actions.GoMating(self))
else:
chosen_action = actions.HarvestSubstance(self)
chosen_action.set_objective(**{"target_substance_type": type(substances.Substance())})
self.queue_action(chosen_action)
...
Про машинное обучение и богов
Удостоверившись, что простое моделирование работает, начнем повышать градус веселья и добавим возможность машинного бучения. На момент написания статьи не все из планируемых возможностей реализованы, однако, я обещал рассказать про богов.
Но для начала надо определиться с тем, как мы хотим обучать наших существ. Возьмем ту же самую задачу с поисками ресурса и спариванием. Если бы мы решали ее традиционным путем, то сначала нам бы надо было определиться с набором признаков, опираясь на которые мы планируем принимать решения. Затем, действуя случайным образом или еще как-то, собрать тренировочный и тестовый датасеты и сохранить их. Следом обучить на этих датасетах пару моделей, сравнить их и выбрать лучшую. Наконец, переписать процесс планирования с использованием этой модели, запустить симуляцию и посмотреть, что получается. И тут нам бы пришло в голову использовать новый признак, а это значит пересобрать данные, перетренировать модели, пересравнить их между собой и перезапустить, чтобы перепосмотреть, что переполучится.
А что бы нам хотелось в идеале? В идеале хотелось бы определить набор признаков, сконфигурировать модель обучения и запустить симуляцию, которая бы уже сама собрала датасеты, натренировала модель, подключила ее к процессу планирования и выдала нам готовые результаты нескольких прогонов, которые бы мы могли сравнивать с результатами других моделей или других наборов признаков.
И вот как я себе это представляю:
- Для того чтобы набрать датасет и принимать решения, нам надо декларативно описать получение признаков, на которых мы будем тренироваться и которые мы будем использовать для предсказания модели в процессе планирования. Сейчас я реализовал это как массив функций, каждая из которых возвращает значение определенного признака. Для нашего тестового задания это, например, функция, возвращающая наличие возможных партнеров, еще одна, считающая количество ресурса у существа, принимающего решение, еще расстояние до ближайшего ресурса и т.д. Возможно, удачнее была бы функция, возвращающая массив признаков, но на момент написания массив функций показался мне удобнее. Таким образом мы получаем возможность в любой момент времени получить интересующее нас описание окружающего мира.
- Так же декларативно описываем способ получения интересующего нас результата. В случае нашего примера это, допустим, удачно или неудачно прошло спаривание.
- Указываем модель обучения, которую хотим использовать, и ее параметры. Например, стохастический градиентный спуск, случайный лес, какую-нибудь нейросеть или вообще что-то свое.
- Запускаем моделирование. Сначала каждый раз, когда необходимо принять решение, существа по описанным нами правилам получают массив признаков и выбирают какое-то действие без использования модели (которая у нас еще пустая). Выполнив это действие они опять же по описанным нами правилам определяют результат, соединяют его с описанием обстановки, в которой решение было принято (набор признаков, полученный перед действием), и вуаля, у нас готов сэмпл для тренировочного датасета. Проделав это определенное количество раз и накопив достаточно данных, существа, наконец, скармливают тренировочный датасет в модель. После того как модель натренирована, они уже в процессе планирования начинают использовать ее.
- Дальше возможны варианты. Можно на этом и остановиться. А можно продолжать запоминать наборы признаков и результаты действий и кусками скармливать их модели, если модель позволяет доучиваться. Или, например, перетренировывать ее в случае, если процент желательных результатов начинает снижаться.
Тут нам потребуется несколько новых объектов. Во-первых, у существ должна быть какая-то память, в которую они будут складывать свои датасеты. Она должна уметь отдельно запоминать набор признаков. Отдельно присоединять к ним результат решения, принятого при этом наборе признаков. Возвращать нам датасет в удобном виде. Ну, и забывать все, чему нас учили в вузе.
class LearningMemory(object):
def __init__(self, host):
self.host = host
self.memories = {}
def save_state(self, state, action):
self.memories[action] = {"state": state}
def save_results(self, results, action):
if action in self.memories:
self.memories[action]["results"] = results
else:
pass
def make_table(self, action_type):
table_list = []
for memory in self.memories:
if isinstance(memory, action_type):
if "state" not in self.memories[memory] or "results" not in self.memories[memory]:
continue
row = self.memories[memory]["state"][:]
row.append(self.memories[memory]["results"])
table_list.append(row)
return table_list
def obliviate(self):
self.memories = {}
Во-вторых, нам надо научить агентов получать задания и запоминать обстановку и результаты своих действий.
class Agent(Entity):
def __init__(self):
...
self.memorize_tasks = {}
....
...
def set_memorize_task(self, action_types, features_list, target):
if isinstance(action_types, list):
for action_type in action_types:
self.memorize_tasks[action_type] = {"features": features_list,
"target": target}
else:
self.memorize_tasks[action_types] = {"features": features_list,
"target": target}
def get_features(self, action_type):
if action_type not in self.memorize_tasks:
return None
features_list_raw = self.memorize_tasks[action_type]["features"]
features_list = []
for feature_raw in features_list_raw:
if isinstance(feature_raw, dict):
if "kwargs" in feature_raw:
features_list.append(feature_raw["func"](**feature_raw["kwargs"]))
else:
features_list.append(feature_raw["func"]())
elif callable(feature_raw):
features_list.append(feature_raw())
else:
features_list.append(feature_raw)
return features_list
def get_target(self, action_type):
if action_type not in self.memorize_tasks:
return None
target_raw = self.memorize_tasks[action_type]["target"]
if callable(target_raw):
return target_raw()
elif isinstance(target_raw, dict):
if "kwargs" in target_raw:
return target_raw["func"](**target_raw["kwargs"])
else:
return target_raw["func"]()
else:
return target_raw
def queue_action(self, action):
if type(action) in self.memorize_tasks:
self.private_learning_memory.save_state(self.get_features(type(action)), action)
self.public_memory.save_state(self.get_features(type(action)), action)
self.action_queue.append(action)
def perform_action_save_memory(self, action):
self.chosen_action = action
if type(action) in self.memorize_tasks:
results = self.perform_action(action)
if results["done"]:
self.private_learning_memory.save_results(self.get_target(type(action)), action)
self.public_memory.save_results(self.get_target(type(action)), action)
else:
results = self.perform_action(action)
...
И, наконец, нам потребуется некий менеджер, по-отечески присматривающий за всеми агентами, раздающий им задания, устанавливающий модели обучения, объясняющий, как их использовать, избавляющий от лукавого, многомилостивый и всеблагой. Проще говоря, чем прописывать всю логику в агентах, а общие объекты хранить где-то в свойствах мира или еще где-нибудь, нам удобнее вклиниваться в момент появления агента в нашем мире и наделять его сознанием, определяя все необходимые свойства типа памяти, способа планирования и модели обучения.
Для этого создадим объект Demiurge, который будет подключаться к создаваемому миру. Все объекты, кроме изначальных, должны появляться в мире посредством метода insert_object. В него и будет вклиниваться наше божество, предварительно обрабатывая свое очередное творение:
class Demiurge(object):
def handle_creation(self, creation, refuse):
pass
class Field(object):
def __init__(self, length, height):
...
self.demiurge = None
...
def insert_object(self, x, y, entity_object, epoch_shift=0):
if self.demiurge is not None:
refuse = False
self.demiurge.handle_creation(entity_object, refuse)
if refuse:
return
assert x < self.length
assert y < self.height
self.__field[y][x][-1] = entity_object
entity_object.z = self.epoch + epoch_shift
entity_object.board = self
entity_object.x = x
entity_object.y = y
...
Такой подход дает много возможностей:
- Вся логика обучения вынесена в отдельное независимое (насколько это возможно) место. Если у нас есть хорошо продуманные и описанные объекты агентов и действий, то мы можем спокойно концентрироваться на нюансах обучения.
- Мы можем быстро и безболезненно заменять одного демиурга другим — для сравнения, или, например, в соревновательных целях. Например, можно создать мир, агентов и действия и устроить конкурс, чей бог самый истинный наиболее эффективно обучит агентов выполнять поставленную задачу.
- Или есть идея (пока нереализованная) создавать целые пантеоны, чтобы демиурги дополняли друг друга (один учит кузнечному делу, другой выращивать виноград, третий плодиться и размножаться). Или чтобы наоборот, конкурировали, и можно было устраивать локальный Рагнарёк силами последователей разных богов.
Дополнительно агентам была добавлена такая функция как использование публичных или приватных памяти и модели обучения. Публичная память — что-то вроде общедоступных описаний экспериментов. В нее описания своих действий и их результатов могут записать все агенты и прочитать тоже может любой. Публичная модель обучения — учебник с описанием того, что надо делать в той или иной ситуации, которым может воспользоваться кто угодно. Ну, а приватные память и модель обучения — это жизненный опыт и умения каждого конкретного агента. Их можно комбинировать — например, черпать примеры из общей памяти, но иметь свою приватную модель обучения.
Proof of concept II
Итак, попробуем решить ту же самую задачу с собиранием ресурсов и существами ложного пола. Так как задача достаточно простая, то у нас вряд ли получится решить ее с помощью машинного обучения лучше, чем можно было бы с помощью жестко заданного алгоритма. Однако для признания концепции рабочей нам достаточно того, чтобы наши собиратели не вымерли как вид от нежелания или неумения размножаться.
Ниже полный текст примера решения такой задачи:
- Наследуем демиурга и создаем свое божество (Priapus).
- Память и модель обучения будем использовать общие, поэтому определяем их в объявлении. Модель выберем, например, SGDClassifier из библиотеки sklearn.
- Переопределяем handle_creation.
- В решении о том, спариваться или собирать будем руководствоваться тремя параметрами: в настроении ли мы, существует ли вообще потенциальный партнер и разница в уровнях достатка. Описываем то, как эти параметры получить, и даем задание агенту запоминать их каждый раз, когда он решит спариваться.
- Описываем процесс планирования: пока модель обучения не готова, будем действовать рандомно и все запоминать (кстати, никто не знает, как в sklearn определить, обучена модель или нет?). Как только накопим достаточно опыта (в данном случае 20 попыток на всех, так как мы используем общую память), пытаемся предсказать, хорошая ли идея спариться в текущих обстоятельствах. Если да, то бежим в ближайший киоск за вином и шоколадкой. Если нет, отправляемся добывать ресурс.
- Прогоняем 30 раз по 500 эпох и смотрим среднее количество живущих на 500ю эпоху существ. Делаем то же самое с использованием рандомного планирования и видим, что стохастический градиентный спуск немного, но все же лучше.
- Включаем визуализацию и умиляемся своему творению.
# Create deity
class Priapus(field.Demiurge): # Create deity
def __init__(self):
self.public_memory = brain.LearningMemory(self)
self.public_decision_model = SGDClassifier(warm_start=True)
def handle_creation(self, creation, refuse):
if isinstance(creation, entities.Creature):
creation.public_memory = self.public_memory
creation.public_decision_model = self.public_decision_model
creation.memory_type = "public"
creation.model_type = "public"
creation.memory_batch_size = 20
if creation.sex:
def difference_in_num_substance(entity):
nearest_partner = actions.SearchMatingPartner(entity).do_results()["partner"]
if nearest_partner is None:
return 9e10
else:
self_has_substance = entity.count_substance_of_type(substances.Substance)
partner_has_substance = nearest_partner.count_substance_of_type(substances.Substance)
return partner_has_substance - self_has_substance
def possible_partners_exist(entity):
find_partner = actions.SearchMatingPartner(entity)
search_results = find_partner.do_results()
return float(search_results["accomplished"])
features = [{"func": lambda creation: float(creation.has_state(states.NotTheRightMood)),
"kwargs": {"creation": creation}},
{"func": difference_in_num_substance,
"kwargs": {"entity": creation}},
{"func": possible_partners_exist,
"kwargs": {"entity": creation}}]
creation.set_memorize_task(actions.GoMating, features,
{"func": lambda creation: creation.chosen_action.results["accomplished"],
"kwargs": {"creation": creation}})
def plan(creature):
if creature.sex:
try:
# raise NotFittedError
current_features = creature.get_features(actions.GoMating)
current_features = np.asarray(current_features).reshape(1, -1)
if creature.public_decision_model.predict(current_features):
go_mating = actions.GoMating(creature)
creature.queue_action(go_mating)
return
else:
harvest_substance = actions.HarvestSubstance(creature)
harvest_substance.set_objective(
**{"target_substance_type": type(substances.Substance())})
creature.queue_action(harvest_substance)
return
except NotFittedError:
chosen_action = random.choice(
[actions.GoMating(creature), actions.HarvestSubstance(creature)])
if isinstance(chosen_action, actions.HarvestSubstance):
chosen_action.set_objective(
**{"target_substance_type": type(substances.Substance())})
creature.queue_action(chosen_action)
return
else:
harvest_substance = actions.HarvestSubstance(creature)
harvest_substance.set_objective(**{"target_substance_type": type(substances.Substance())})
creature.queue_action(harvest_substance)
creation.plan_callable = plan
universe = field.Field(60, 40) # Create sample universe (length, height
universe.set_demiurge(Priapus()) # Assign deity to universe
# Fill universe with blanks, blocks, other scenery if necessary
for y in range(10, 30):
universe.insert_object(20, y, field.Block())
for x in range(21, 40):
universe.insert_object(x, 10, field.Block())
for y in range(10, 30):
universe.insert_object(4
