[Из песочницы] Собственный поисковик по раздачам The Pirate Bay
В последнее время на хабре стало популярно делать собственные поисковики по RuTracker. Мне это показалось прекрасным поводом для того, чтобы отойти от скучной enterprise разработки и попробовать что-нибудь новое.
Итак, задача: реализовать на локалхосте поисковик по базе The Pirate Bay и попутно попробовать, что же такое frontend разработка и с чем её едят. Задача осложняется тем, что TPB не публикует своих дампов, в отличие от RuTracker, и для получения дампов требуется распарсить их сайт. В результате гугления и осмысления задачи я решил в качестве поисковика использовать Elasticsearch, для которого написать client-side only фронтенд на AngularJS. Для получения данных я решил написать собственный парсер сайта TPB и отдельный загружатель дампа в индекс, оба на Go. Пикантность выбору придавал тот факт, что ни к Elasticsearch, ни к AngularJS я до этого ни разу не прикасался и именно их опробывание было моей настоящей целью.
Парсер
Краткий осмотр сайта TPB показал, что каждый торрент имеет свою страницу по адресу »/torrent/{id}». Где id во-первых численные, во-вторых увеличиваются, в-третьих последний id можно посмотреть на странице »/recent» и потом перепробовать все id меньше последнего. Практика показала, что id увеличиваются не монотонно и не для каждого id есть корректная страница с торрентом, что потребовало дополнительной проверки и пропуска id.
Так как парсер подразумевает работу с сетью в несколько потоков, выбор Go был очевиден. Для разбора HTML я использовал модуль goquery.

Устройство парсера весьма просто: вначале запрашивается »/recent» и из неё получается максимальный id:
func getRecentId(topUrl string) int {
var url bytes.Buffer
url.WriteString(topUrl)
url.WriteString("/recent")
log.Info("Processing recent torrents page at: %s", url.String())
doc, err := goquery.NewDocument(url.String())
if err != nil {
log.Critical("Can't download recent torrents page from TPB: %v", err)
return 0
}
topTorrent := doc.Find("#searchResult .detName a").First()
t, pT := topTorrent.Attr("title")
u, pU := topTorrent.Attr("href")
if pT && pU {
rx, _ := regexp.Compile(`\/torrent\/(\d+)\/.*`)
if rx.MatchString(u) {
id, err := strconv.Atoi(rx.FindStringSubmatch(u)[1])
if err != nil {
log.Critical("Can't retrieve latest torrent id")
return 0
}
log.Info("The most recent torrent is %s and it's id is %d", t, id)
return id
}
}
return 0
}
Затем мы просто бежим по всем значениям id от максимального до нулевого и скармливаем полученные цифры в канал:
func (d *Downloader) run() {
d.wg.Add(streams)
for w := 0; w <= streams; w++ {
go d.processPage()
}
for w := d.initialId; w >= 0; w-- {
d.pageId <- w
}
close(d.pageId)
log.Info("Processing complete, waiting for goroutines to finish")
d.wg.Wait()
d.output.Done()
}
Как видно из кода, с другой стороны канала запущено некоторое количество горутин, принимающих id торрента, скачивающих соответствующую страницу и обрабатывающую её:
func (d *Downloader) processPage() {
for id := range d.pageId {
var url bytes.Buffer
url.WriteString(d.topUrl)
url.WriteString("/torrent/")
url.WriteString(strconv.Itoa(id))
log.Info("Parsing torrent page at: %s", url.String())
doc, err := goquery.NewDocument(url.String())
if err != nil {
log.Warning("Can't download torrent page %s from TPB: %v", url, err)
continue
}
torrentData := doc.Find("#detailsframe")
if torrentData.Length() < 1 {
log.Warning("Erroneous torrent %d: \"%s\"", id, url.String())
continue
}
torrent := TorrentEntry{Id: id}
torrent.processTitle(torrentData)
torrent.processFirstColumn(torrentData)
torrent.processSecondColumn(torrentData)
torrent.processHash(torrentData)
torrent.processMagnet(torrentData)
torrent.processInfo(torrentData)
d.output.Put(&torrent)
log.Info("Processed torrent %d: \"%s\"", id, torrent.Title)
}
d.wg.Done()
}
После обработки результат отправляется в OutputModule, который уже сохраняет его в том или ином формате. Я написал два модуля вывода, в csv и в «почти» json.
Формат csv:
id торрента, название, размер, количество файлов, категория, подкатегория, автор закачки, хэш, дата создания, магнет ссылка
Json friendly формат не совсем Json: каждая строка представляет собой отдельный json объект с теми же полями, что и в csv, плюс описание торрента.
Полный дамп содержит 3828894 торрентов и занял почти 30 часов на загрузку.
Индекс
Перед тем как загрузить данные в Elasticsearch, его надо настроить.
Так как я бы хотел получить полнотекстовый поиск по названия и описаниям торрентов, которые написаны на нескольких языках, то в первую очередь создадим Unicode friendly анализатор:
{
"index": {
"analysis": {
"analyzer": {
"customHTMLSnowball": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "icu_tokenizer",
"filter": [
"icu_normalizer",
"icu_folding",
"lowercase",
"stop",
"snowball"
]
}
}
}
}
}
curl -XPUT http://127.0.0.1:9200/tpb -d @tpb-settings.json
Перед созданием анализатора необходимо поставить ICU plugin, а после создания анализатора нужно связать его с полями в описании торрента:
{
"properties" : {
"Id" : {
"type" : "long",
"index" : "no"
},
"Title" : {
"type" : "string",
"index" : "analyzed",
"analyzer" : "customHTMLSnowball"
},
"Size" : {
"type" : "long",
"index" : "no"
},
"Files" : {
"type" : "long",
"index" : "no"
},
"Category" : {
"type" : "string",
"index" : "not_analyzed"
},
"Subcategory" : {
"type" : "string",
"index" : "not_analyzed"
},
"By" : {
"type" : "string",
"index" : "no"
},
"Hash" : {
"type" : "string",
"index" : "not_analyzed"
},
"Uploaded" : {
"type" : "date",
"index" : "no"
},
"Magnet" : {
"type" : "string",
"index" : "no"
},
"Info" : {
"type" : "string",
"index" : "analyzed",
"analyzer" : "customHTMLSnowball"
}
}
}
curl -XPUT http://127.0.0.1:9200/tpb/_mappings/torrent -d @tpb-mapping.json
И теперь самое главное — загрузка данных. Загрузчик я тоже написал на Go, чтобы посмотреть, как работать с Elasticsearch из Go.
Сам загрузчик ещё проще парсера: читаем файл построчно, каждую строчку переводим из json в структуру, отправляем структуру в Elastisearch. Правильнее было бы сделать bulk indexing, но мне, честно говоря, было лень. Кстати, самой сложной частью написания загрузчика был поиск для скриншота достаточно длинного куска лога без порнухи.
func (i *Indexer) Run() {
for i.scaner.Scan() {
var t TorrentEntry
err := json.Unmarshal(i.scaner.Bytes(), &t)
if err != nil {
log.Warning("Failed to parse entry %s", i.scaner.Text())
continue
}
_, err = i.es.Index().Index(i.index).Type("torrent").BodyJson(t).Do()
if err != nil {
log.Warning("Failed to index torrent entry %s with id %d", t.Title, t.Id)
continue
}
log.Info("Indexed %s", t.Title)
}
i.file.Close()
}
Сам индекс занял те же самые ~6GB и строился порядка 2х часов.
Frontend
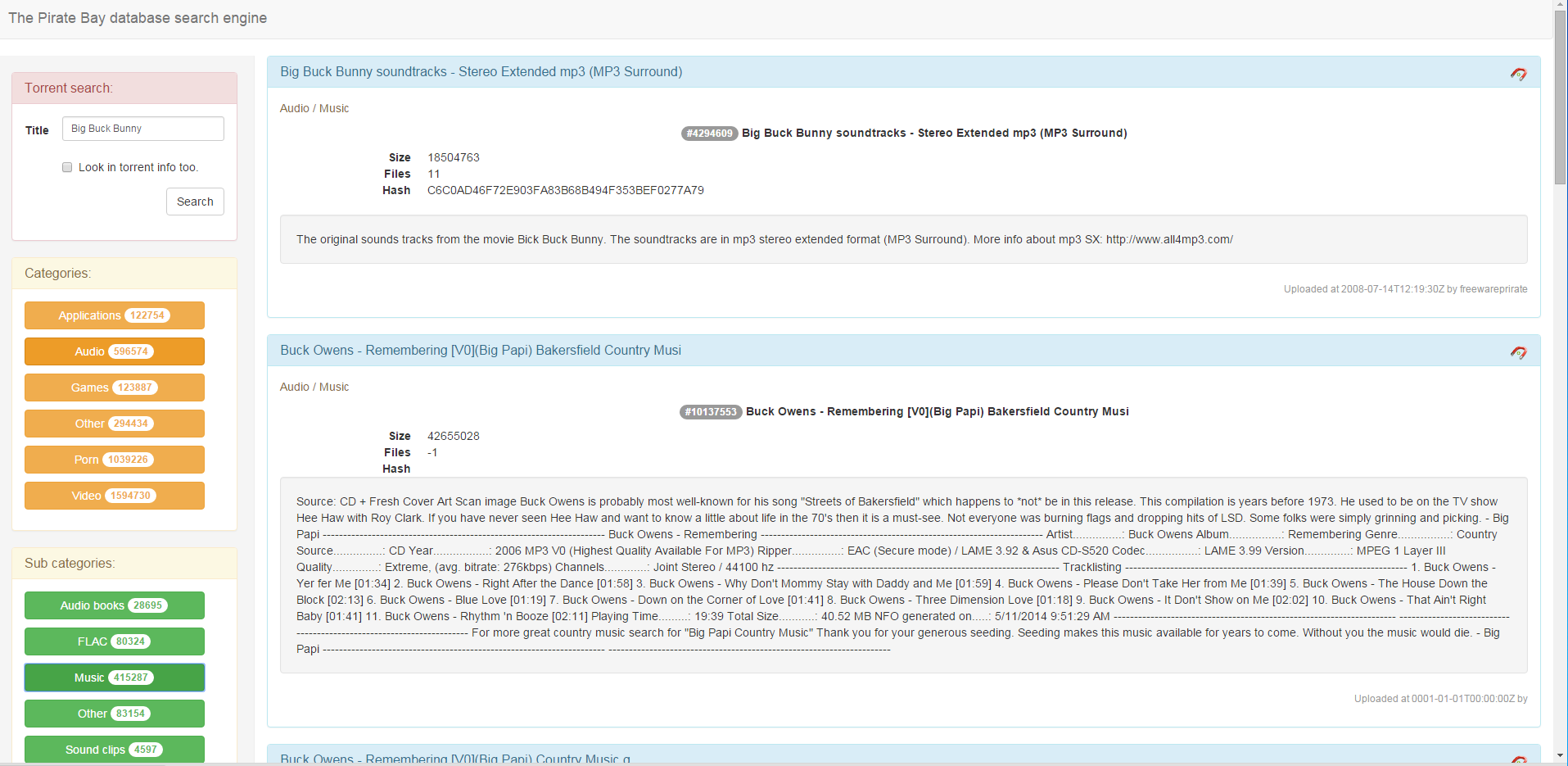
Самая интересная часть для меня. Я хотел бы видеть все торренты в базе и фильтровать их по категориям/подкатегориям и по названию/описанию торрента. Таким образом, слева фильтры, справа торренты.
За основу для вёрстки я взял Bootstrap. Для большинства это видимо боян, но мне в новинку.
Итак, по левую руку у меня фильтр по заголовкам и содержимому:
Под ним фильтры по категориям и субкатегориям:
Categories:
Sub categories:
Список категорий наполняется автоматически при загрузке приложения. Использование TermsAggregation запроса позволяет получить сразу и список категорий и количество торрентов в этих категориях. Говоря более строго — список уникальных значений поля Category и число документов для каждого такого значения.
client.search({
index: 'tpb',
type: 'torrent',
body: ejs.Request().agg(ejs.TermsAggregation('categories').field('Category'))
}).then(function (resp) {
$scope.categories = resp.aggregations.categories.buckets;
$scope.errorCategories = null;
}).catch(function (err) {
$scope.categories = null;
$scope.errorCategories = err;
// if the err is a NoConnections error, then the client was not able to
// connect to elasticsearch. In that case, create a more detailed error
// message
if (err instanceof esFactory.errors.NoConnections) {
$scope.errorCategories = new Error('Unable to connect to elasticsearch.');
}
});
При клике на одну или несколько категорий, они выбираются и загружается список их подкатегорий:
$scope.categoryClick = function (category) {
/* Mark button */
category.active = !category.active;
/* Reload sub categories list */
$scope.filterCategories = [];
$scope.categories.forEach(function (item) {
if (item.active) {
$scope.filterCategories.push(item.key);
}
});
if ($scope.filterCategories.length > 0) {
$scope.loading = true;
client.search({
index: 'tpb',
type: 'torrent',
body: ejs.Request().agg(ejs.FilterAggregation('SubCategoryFilter').filter(ejs.TermsFilter('Category', $scope.filterCategories)).agg(ejs.TermsAggregation('categories').field('Subcategory').size(50)))
}).then(function (resp) {
$scope.SubCategories = resp.aggregations.SubCategoryFilter.categories.buckets;
$scope.errorSubCategories = null;
//Restore selection
$scope.SubCategories.forEach(function (item) {
if ($scope.selectedSubCategories[item.key]) {
item.active = true;
}
});
}
).catch(function (err) {
$scope.SubCategories = null;
$scope.errorSubCategories = err;
// if the err is a NoConnections error, then the client was not able to
// connect to elasticsearch. In that case, create a more detailed error
// message
if (err instanceof esFactory.errors.NoConnections) {
$scope.errorSubCategories = new Error('Unable to connect to elasticsearch.');
}
});
} else {
$scope.selectedSubCategories = {};
$scope.filterSubCategories = [];
}
$scope.searchClick();
};
Подкатегории тоже можно выбирать. При смене выбора категорий/подкатегорий или заполнении формы поиска формируется Elasticsearch query, учитывающий всё выбранное и отправляется в Elasticsearch.
$scope.buildQuery = function () {
var match = null;
if ($scope.query) {
if ($scope.useInfo) {
match = ejs.MultiMatchQuery(['Title', 'Info'], $scope.query);
} else {
match = ejs.MatchQuery('Title', $scope.query);
}
} else {
match = ejs.MatchAllQuery();
}
var filter = null;
if ($scope.filterSubCategories.length > 0) {
filter = ejs.TermsFilter('Subcategory', $scope.filterSubCategories);
}
if ($scope.filterCategories.length > 0) {
var categoriesFilter = ejs.TermsFilter('Category', $scope.filterCategories);
if (filter !== null) {
filter = ejs.AndFilter([categoriesFilter, filter]);
} else {
filter = categoriesFilter;
}
}
var request = ejs.Request();
if (filter !== null) {
request = request.query(ejs.FilteredQuery(match, filter));
} else {
request = request.query(match);
}
request = request.from($scope.pageNo*10);
return request;
};
Результаты отображаются справа:
{{doc._source.Category}} / {{doc._source.Subcategory}}
#{{doc._source.Id}} {{doc._source.Title}}
- Size
- {{doc._source.Size}}
- Files
- {{doc._source.Files}}
- Hash
- {{doc._source.Hash}}
Uploaded at {{doc._source.Uploaded}} by {{doc._source.By}}

Вот и всё. Теперь у меня есть собственный поисковик по The Pirate Bay, и я узнал, что можно сделать современный сайт за пару часов.
