[Из песочницы] Сниппеты против Клевера – обыгрываем популярнейшую викторину в реальном времени
Апрель 2018-го года. Мне было 14. Мы с друзьями играли в тогда очень популярную онлайн-викторину «Клевер» от ВКонтакте. Один из нас (обычно я) всегда был за ноутбуком, чтобы пытаться быстро гуглить вопросы и глазами искать в поисковой выдаче правильный ответ. Но вдруг я понял, что каждый раз выполняю одно и то же действие, и решил попробовать написать это на частично известном мне тогда Python 3.
Шаг 0. Что здесь происходит
Для начала я освежу в вашей памяти механику «Клевера».
Игра для всех начинается в одно и то же время — в 13:00 и в 20:00 по Москве. Чтобы сыграть, нужно в это время зайти в приложение и подключиться к прямой трансляции. Игра идет 15 минут, в течение которых участникам на телефон одновременно приходят вопросы. На ответ дается 10 секунд. Затем объявляется верный ответ. Все, кто угадали, проходят дальше. Всего вопросов 12, и если ответить на все — получишь денежный приз.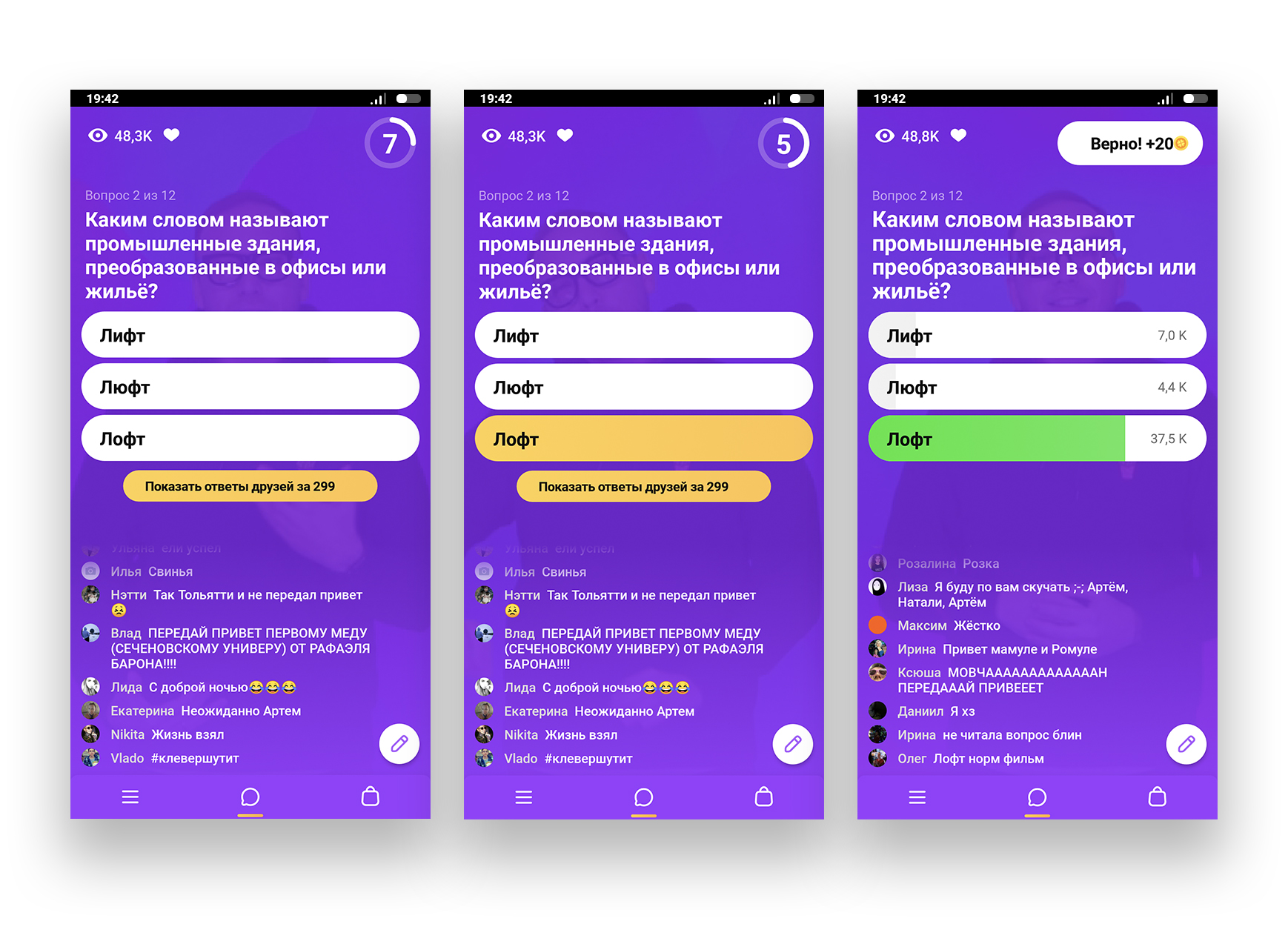
Получается, наша задача — мгновенно ловить новые вопросы от сервера Клевера, обрабатывать их через какой-либо поисковик, а по результатам выдачи определять правильный ответ. Вывод ответа было решено производить в телеграм-бота, чтобы уведомления из него всплывали на телефоне прямо во время игры. И все это желательно за пару секунд, ведь время на ответ сильно ограничено. Если вы хотите увидеть, как довольно простой, но рабочий код (а посмотреть на такой будет полезно новичкам) помогал нам обыгрывать Клевер — добро пожаловать под кат.
Шаг 1. Получаем вопросы с сервера
Сначала это показалось самым сложным этапом. Я уже сделал глубокий вдох и готов был полезть в дебри вроде компьютерного зрения, перехвата трафика или декомпиляции приложения… Как вдруг меня ждал сюрприз — у Клевера открытое API! Оно нигде не задокументировано, но если во время игры, как только всем игрокам задали вопрос, сделать request на api.vk.com, то в ответ мы получим заданный вопрос и варианты ответов к нему в JSON:
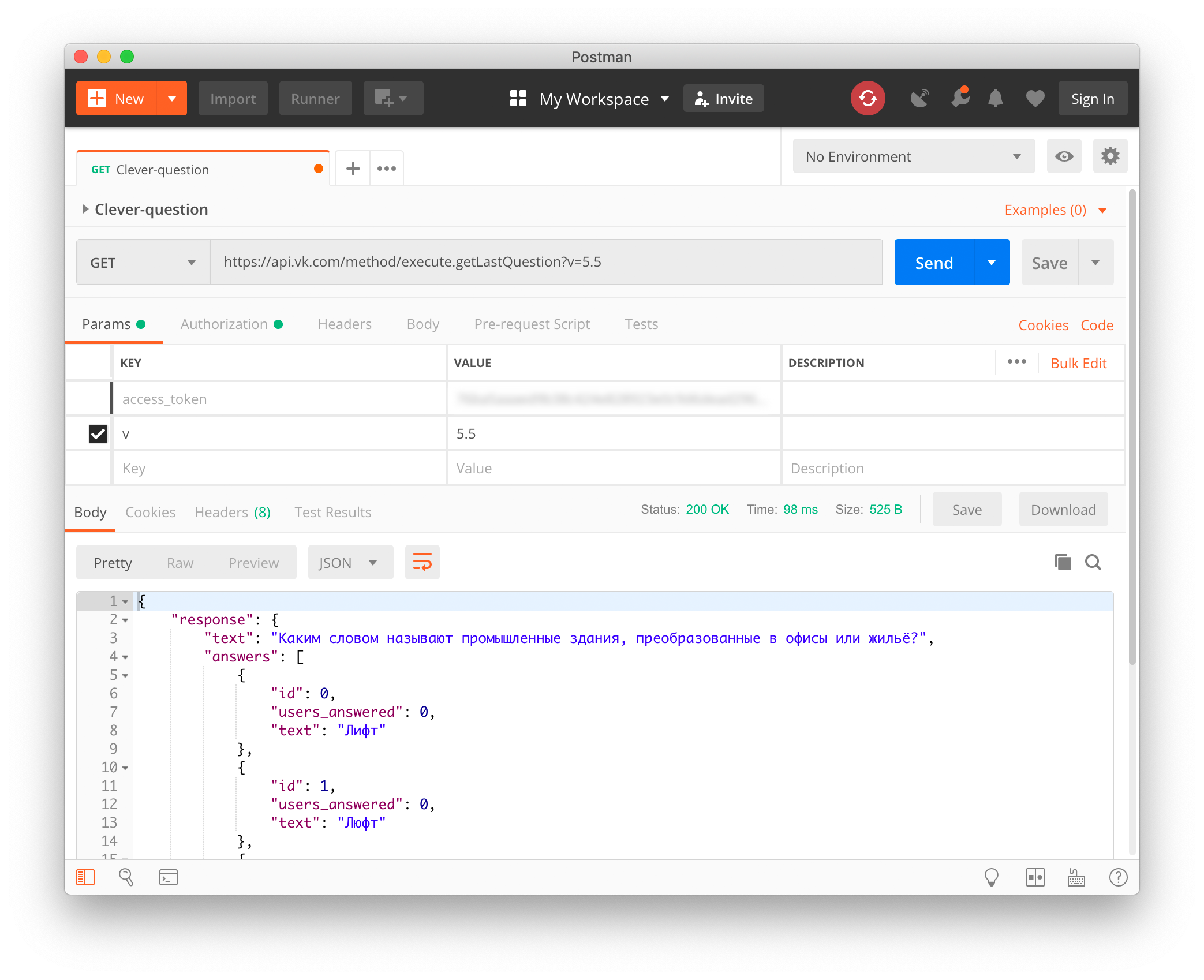
https://api.vk.com/method/execute.getLastQuestion?v=5.5&access_token=VK_USER_TOKEN
В качестве access_token необходимо передавать API-токен любого пользователя ВКонтакте, но важно, чтобы он был изначально выписан именно для Клевера. Его app_id — 6334949.
Шаг 2. Обрабатываем вопрос через поисковик
Было два варианта: использовать официальное API поисковиков или добавлять поисковые аргументы прямо в адресную строку, а результаты парсить. Сначала я опробовал второй, но мало того, что иногда ловил капчу, так еще и терял кучу времени, ведь страницы грузились в среднем за 2 секунды. А я напомню, что нам желательно уложиться в эти самые две секунды. Ну и главное — я не получал от поисковиков больших и структурированных текстов на нужную тему, так как на странице поиска висят лишь небольшие кусочки нужного материала, которые именуются сниппетами:

Поэтому я начал искать API. Google не подошел — их решения были очень ограниченными и возвращали очень мало данных. Самым щедрым оказался Яндекс.XML — он разрешает посылать 10000 запросов в день, не более 5 в секунду, а данные возвращает очень быстро. В запросе к нему опционально количество страниц (вплоть до 100) и количество пассажей — специальных величин, которые используются для формирования сниппетов. Данные мы получаем в XML. Однако это все те же сниппеты.
Чтобы вы могли ознакомиться и поиграть с тем, что возвращает Яндекс, то вот пример ответа на запрос «Как зовут главного антагониста в серии видеоигр «The Legend of Zelda»?»: Яндекс. Диск.
Мне повезло, и оказалось, что в pypi под это уже существует отдельный модуль yandex-search. И вот, я попробовал получить вопрос с сервера, найти его в яндексе, из сниппетов сделать один большой текст и разбить его на предложения:
import requests as req
import yandex_search
import json
apiurl = "https://api.vk.com/method/execute.getLastQuestion?access_token=VK_USER_TOKEN&v=5.5"
clever_response = (json.loads(req.get(apiurl).content))["response"]
# {'text': 'Какой из этих мультфильмов первым получил премию Оскар в номинации «Лучший анимационный полнометражный фильм»?', 'answers': [{'id': 0, 'users_answered': 0, 'text': '«История игрушек»'}, {'id': 1, 'users_answered': 0, 'text': '«Корпорация монстров»'}, {'id': 2, 'users_answered': 0, 'text': '«Шрек»'}], 'stop_time': 0, 'is_first': 0, 'is_last': 1, 'number': 12, 'id': 22, 'sent_time': 1533921436}
question = str(clever_response["text"])
ans1, ans2, ans3 = str(clever_response["answers"][0]["text"]).lower(), str(clever_response["answers"][1]["text"]).lower(), str(clever_response["answers"][2]["text"]).lower()
def yandexfind(question):
finded = yandex.search(question).items
snips = ""
for i in finded:
snips += (i.get("snippet")) + "\n"
return snips
items = yandexfind(question)
itemslist = list(items.split(". "))
Шаг 3. В поисках ответов
Изначально задача точно распознать ответ по сниппетам казалась мне нереальной (напоминаю, что на момент написания кода я был абсолютным новичком). Поэтому я решил сперва упростить ту задачу, которую мы выполняли при ручном поиске.
Что мы с друзьями делали, когда вбивали свой вопрос в поисковик? Начинали бегло искать глазами ответы в результатах. В чем проблема такого подхода? В многабукв наличии большого количества лишних, не содержащих информацию об ответах, предложений. Искать глазами иногда приходилось подолгу. Поэтому первое, что я решил сделать — выделить все предложения с упоминанием любого из ответов и вывести их на экран, чтобы мы искали ответ в совсем небольшом тексте, точно содержащем нужную нам информацию.
hint = [] #Список предложений, содержащих один из вариантов ответа
for sentence in itemslist: #Чекаем каждое предложение из сниппетов
if (ans1 in sentence) or (ans2 in sentence) or (ans3 in sentence):
hint.append(sentence)
if len(hint) > 4:
break
Казалось бы, получай нужные предложения, читай их и отвечай правильно. Но что делать, если мы так и не нашли ни одного нужного предложения? Я решил в таком случае обрезать слова, чтобы не упускать их, если они стоят в другом падеже. А еще чтобы захватить те, которые образованы от исходных. Короче, я просто обрезал их окончание на два символа:
if len(hint) == 0:
def cut(string):
if len(string) > 2:
return string[0:-2]
else:
return string
short_ans1, short_ans2, short_ans3 = cut(ans1), cut(ans2), cut(ans3)
for pred in itemslist: #Чекаем каждое предложение из сниппетов
if (short_ans1 in pred) or (short_ans2 in pred) or (short_ans3 in pred)
hint.append(pred)
Но даже после такой подстраховки все равно были случаи, когда hint оставался пустым, просто потому что в результатах не всегда хоть как-то затрагивались ответы. Скажем, на вопрос «У какого из этих писателей есть повесть, названная так же, как и песня группы Би 2?» точного ответа не найти. В этом случае я прибегал к обратному подходу — наводил справки по ответам и выводил вариант на основе того, как часто в результатах упоминаются слова из вопроса.
if len(hint) == 0:
questionlist = question.split(" ")
blacklist = ["что", "такое", 'как', 'называется', 'в', 'каком', 'году', 'для', 'чего', 'какой', 'какого', 'кого', 'кто', 'зачем', 'является', 'самым', 'большим', 'маленьким', 'из', 'этого', 'входит', 'этих', 'кого', 'у', 'а', 'сколько']
for w in questionlist:
if w in blacklist:
questionlist.remove(w)
yandex_ans1 = yandexfind(ans1)
yandex_ans2 = yandexfind(ans2)
yandex_ans3 = yandexfind(ans3)
#Чуть позже я сделал этот процесс асинхронным, но это было костыльно
count_ans1, count_ans2, count_ans3 = 0, 0, 0
for w in questionlist:
count_ans1 += yandex_ans1.count(w)
count_ans2 += yandex_ans2.count(w)
count_ans3 += yandex_ans3.count(w)
if (count_ans1 + count_ans2 + count_ans3) > 5:
if count_ans1 > (count_ans2 + count_ans3):
print(ans1)
elif count_ans2 > (count_ans1 + count_ans3):
print(ans2)
elif count_ans3 > (count_ans2 + count_ans1):
print(ans3)
На этом месте скрипт обрел базовую функциональность. И вот, спустя всего полторы недели после релиза Клевера, мы сидим и уже играем с таким самописным «читом». Видели бы вы наши с другом лица, когда мы впервые выиграли игру, читая в командной строке как по волшебству появляющиеся предложения!
Шаг 4. Вывод четких ответов
Но скоро такой формат надоел. Во-первых, нужно было каждую игру сидеть с ноутбуком. Во-вторых, скрипт просили себе друзья, и я устал каждому объяснять, как вставить свой токен ВКонтакте, как настроить Яндекс.XML (он привязан к IP, то есть под каждого пользователя скрипта нужно было создавать аккаунт) и как установить питон на компьютер.
Было бы куда лучше, если бы ответы всплывали в пуш-уведомлениях на телефоне прямо во время игры! Просто посмотрел наверх экрана и ответил так, как написано в пуш-уведомлении! А организовать это для всех можно, если создать скрипту свой телеграм-канал! Чудесно!
Но просто выводить в телеграм все те же предложения — не вариант. Читать их с телефона крайне неудобно. Поэтому пришлось учить скрипт самому понимать, какой ответ правильный.
Импортируем telebot и все функции print () меняем на send_tg () и notsure (), который мы будем использовать в последнем методе, так как промахивается он немного чаще остальных:
def send_tg(ans):
bot.send_message("@autoclever", str(ans).capitalize())
print(str(ans))
return
def notsure(ans):
send_tg(ans.capitalize() + ". Это неточно!")
hint.append("WE TRIED!")
И вот на этом моменте я понял, что сниппеты подходят гораздо лучше подробных текстов! Потому что поисковик очень старается именно дать ответ на наш запрос, а не просто найти совпадения по словам. И у него получается — в сниппетах чаще содержались правильные ответы, чем неправильные, то есть анализировать текст потребности не было. Да и я, собственно, не умел.
Так что нехитро подсчитываем упоминания слов в результатах:
anscounts = {
ans1: 0,
ans2: 0,
ans3: 0
}
for s in hint:
for a in [ans1, ans2, ans3]:
anscounts[a] += s.count(a)
right = (max(anscounts, key=anscounts.get))
send_tg(right)
#Ура!
Что получилось в итоге: 
Дальнейшая судьба
Справедливости ради надо сказать, что машина смерти у меня не получилась. В среднем бот отвечал правильно только на 9–10 вопросов из 12ти. Оно и понятно, ведь встречались каверзные, которые не поддавались парсингу Яндексовского поиска. Меня, да и моих друзей утомило постоянно пролетать на парочке вопросов и ждать удачной игры, на которой бот наконец-то на все ответит правильно. Чуда не происходило, скрипт дорабатывать уже не сильно хотелось, и тогда мы, перестав питать надежды на легкую победу, забросили игру.
Со временем моя идея начала закрадываться в головы других молодых разработчиков. К закату 2018-го года насчитывалось как минимум 10 ботов и сайтов, выводящих свои догадки по вопросам в Клевере. Задача-то не такая сложная. Но что удивительно, никто из них так и не перешагнул планку в 9–10 вопросов за игру, а позднее все упали и вовсе до 7–8, как и мой бот. Видимо, составители вопросов просекли, как нужно составлять вопросы, чтобы труд поисковиков был нерелевантен.
К сожалению, бота уже не доработать, ведь 31 го декабря Клевер провел последний эфир, а датасет вопросов у меня не сохранился. Тем не менее, это был отличный опыт для начинающего программиста. И наверняка был бы отличный вызов для продвинутого — только представьте себе дуэт word2vec и text2vec, асинхронные запросы к Яндексу, Гуглу и Википедии одновременно, продвинутый классификатор вопросов и алгоритм переформулировки вопроса в случае неудачи… Эх! Пожалуй, за такие возможности я любил эту игру больше, чем за сам геймплей.
