[Из песочницы] Система мониторинга активного сетевого оборудования федеральной сети
 Во время написания статьи пришел к выводу, что объяснить всю техническую часть по данной теме в одном посте практически невозможно, а может и никому не надо. Поэтому решил сделать данный пост обзорным над моей работой. Цель поста — показать, как не используя дополнительное финансирование компании и выпросив пару виртуальных серверов можно построить эффективную среду мониторинга активного оборудования большой сети в крупной компании.
Во время написания статьи пришел к выводу, что объяснить всю техническую часть по данной теме в одном посте практически невозможно, а может и никому не надо. Поэтому решил сделать данный пост обзорным над моей работой. Цель поста — показать, как не используя дополнительное финансирование компании и выпросив пару виртуальных серверов можно построить эффективную среду мониторинга активного оборудования большой сети в крупной компании.
Если вас интересует тема мониторинга сети или есть желание сравнить мою работу с имеющейся у вас, приглашаю под кат.В маленькой «домашней» сети задачу мониторинга сети можно решить, используя любую из имеющихся свободных платформ для мониторинга. Однако, когда дело касается большого предприятия с больших количеством узлов, все не так прозрачно. И основная проблема — это нехватка физических ресурсов и отсутствие адаптированной под ваши требования системы. Чуть лучше ситуация обстоит с платными продуктами, но платные системы очень редко входят в расходы бизнеса на какой-то там мониторинг.
Система управленияСкелетом всего мониторинга будет система управления, позволяющая мышкой вносить изменение, удалять или добавлять новые узлы или связи.При разработке всей системы в целом, учитывались следующие требования:
Минимальные настройка/перенастройка на активном оборудовании; Обработка большого объема трафика по netflow; Возможность детально исследовать какую-либо сетевую активность; Оперативное обновление о происходящих инцидентах. Будь то падение канала или большая загрузка канала; Возможность дорабатывать модули или отчеты для все возможных выборок; Задействовать минимальное количество инфраструктуры; Как можно меньше писать функционал самостоятельно. Инфраструктура пробовалась разная, до тех пор, пока не была достигнута текущая конфигурация. Все испробованные варианты я описывать не буду, чтобы не растягивать пост.
Итог таков: Два виртуальных сервера под управлением CentOS 6.Один для системы управления и отображения. 2 процессора, 4ГБ ОЗУ, 250ГБ диск.Второй выполняющий функции коллектора netflow. 2 процессора, 4ГБ ОЗУ 150ГБ диск.Конфигурация серверов вполне стандартная, веб сервер apache с php + mysql.
Кактус Для системы управления был выбран Кактус. Чем привлек кактус: Отсутствием сложного кода в WEB отображении (никакого flash, aciveX и прочих активных компонентов, что дает преимущество использования на мобильных устройствах); Простая и понятная структура БД, к который можно легко привязать свой функционал; Много плагинов именно для мониторинга активного оборудования; Встроенная поддержка SNMP; RRDTool в качестве источника для графиков (привет заббиксу); отсутствует клиентская часть. Установка Кактуса не представляет из себя никакой сложности. По этой теме очень много информации в интернете, ну и самой лучшей, конечно, является официальная документация.Настройка так же не требует глубоких ИТ знаний. На странице Devices добавляются устройства, указывается тип SNMP и авторизация. Привязываются стандартные шаблоны.
Устройства
 Настройка SNMP
Настройка SNMP
 Шаблоны
Шаблоны
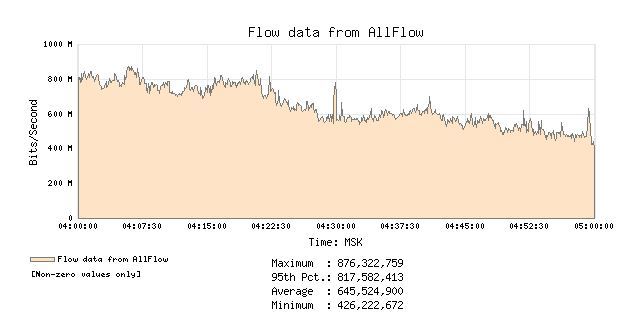
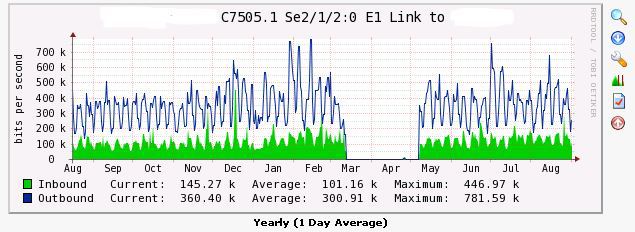
 После опроса кактусом устройства появляется возможность создать график на основе данных с SNMP c конкретного сетевого интерфейса или другого сенсора, будь то напряжение в сети у ИПБ или загрузка процессора у коммутатора.Выбор графиков
После опроса кактусом устройства появляется возможность создать график на основе данных с SNMP c конкретного сетевого интерфейса или другого сенсора, будь то напряжение в сети у ИПБ или загрузка процессора у коммутатора.Выбор графиков

 Плагины к кактусу для работы с активным оборудованием
Плагины к кактусу для работы с активным оборудованием
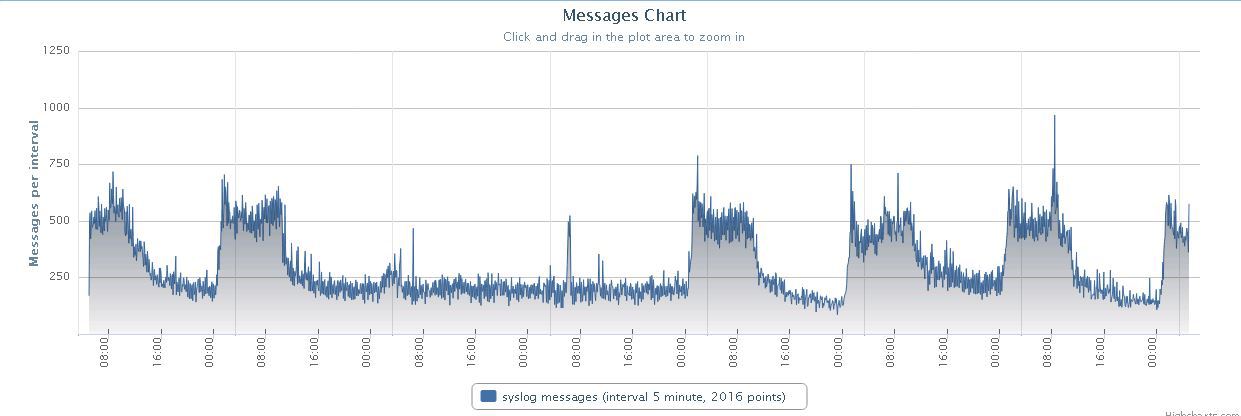
 NetFlow
Основной идей являются отчеты, построенные на основе netflow потоков. Значит, первый нужный нам плагин flowview. Весьма простой плагин, позволяет в графическом режиме настраивать источники flow.flowview config
NetFlow
Основной идей являются отчеты, построенные на основе netflow потоков. Значит, первый нужный нам плагин flowview. Весьма простой плагин, позволяет в графическом режиме настраивать источники flow.flowview config
 А так же делать выборки на основе flow потоков и строить автоматические отчеты по расписанию.flowview schedules
А так же делать выборки на основе flow потоков и строить автоматические отчеты по расписанию.flowview schedules
 Syslog and Traps
Syslog and Traps
 Я использовал два плагина для сбора и анализа traps и syslog с Cisco.Это camm и syslog.camm
Я использовал два плагина для сбора и анализа traps и syslog с Cisco.Это camm и syslog.camm
 Первый меня впечатлил фильтрами и возможностью создавать правила на события (например, мне по критичным событиям приходили сообщения в корпоративный jabber).camm rule
Первый меня впечатлил фильтрами и возможностью создавать правила на события (например, мне по критичным событиям приходили сообщения в корпоративный jabber).camm rule
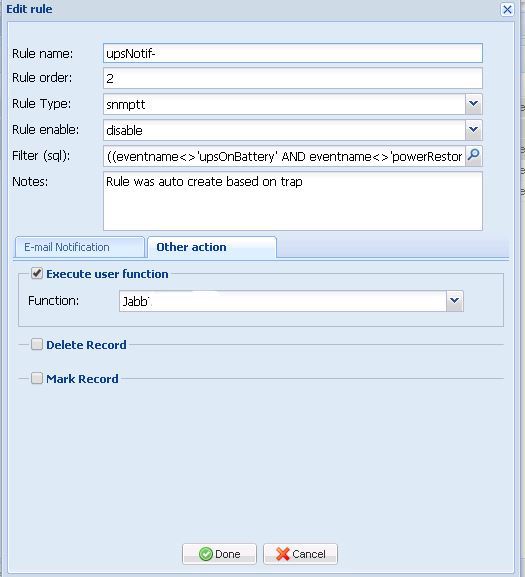 Так же весьма удобная группировка на основе MIB и БД самого кактуса.camm group
Так же весьма удобная группировка на основе MIB и БД самого кактуса.camm group
 Второй создает автономную базу данных с очень прозрачной структурой, к которой я привязал функционал, написанный самостоятельно, но об этом чуть позже.Network Maps
Weathermap — последний плагин использующийся у меня для мониторинга сетей. Он прекрасен и прост. Данные берет с RRD баз данных самого кактуса, а редактор похож на Paint.Channels
Второй создает автономную базу данных с очень прозрачной структурой, к которой я привязал функционал, написанный самостоятельно, но об этом чуть позже.Network Maps
Weathermap — последний плагин использующийся у меня для мониторинга сетей. Он прекрасен и прост. Данные берет с RRD баз данных самого кактуса, а редактор похож на Paint.Channels
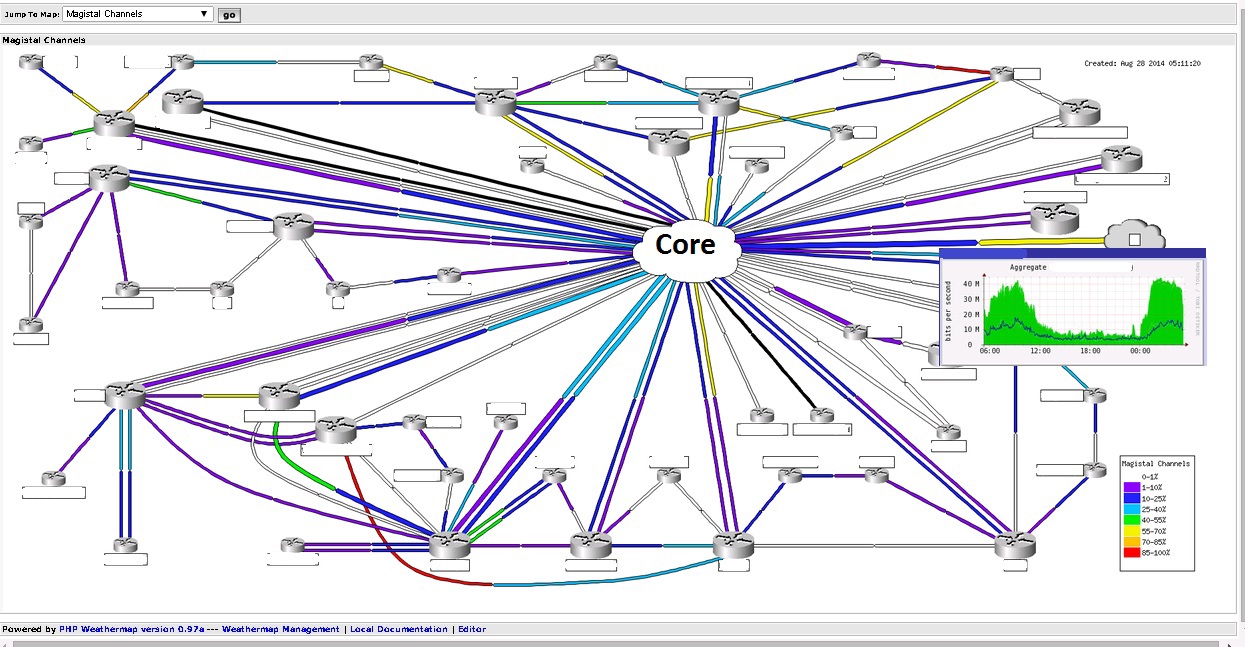 Позволяет графически отображать загруженность каналов связи. Так и возможные проблемы с каналом.Кусочек конфигурационного файла weathermap.Пример конфига weathermap
NODE C7606.1
LABEL C7606.1
LABELOFFSET N
INFOURL /cacti/graph.php? rra_id=all&local_graph_id=3691
OVERLIBGRAPH /cacti/graph_image.php? rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3691
ICON images/Router_PU2.png
POSITION 1132 180
Позволяет графически отображать загруженность каналов связи. Так и возможные проблемы с каналом.Кусочек конфигурационного файла weathermap.Пример конфига weathermap
NODE C7606.1
LABEL C7606.1
LABELOFFSET N
INFOURL /cacti/graph.php? rra_id=all&local_graph_id=3691
OVERLIBGRAPH /cacti/graph_image.php? rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3691
ICON images/Router_PU2.png
POSITION 1132 180
NODE C7609#1 LABEL C7609#1 LABELOFFSET N INFOURL /cacti/graph.php? rra_id=all&local_graph_id=3366 OVERLIBGRAPH /cacti/graph_image.php? rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300&local_graph_id=3366 ICON images/Router_PU2.png POSITION 795 180
# regular LINKs: LINK C7606.1-C7609#1 INFOURL /cacti/graph.php? rra_id=all&local_graph_id=347 OVERLIBGRAPH /cacti/graph_image.php? local_graph_id=347&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_403.rrd NODES C7606.1: N20 C7609#1: N50 BANDWIDTH 40M
LINK C7606.2-C7609#2 INFOURL /cacti/graph.php? rra_id=all&local_graph_id=340 OVERLIBGRAPH /cacti/graph_image.php? local_graph_id=340&rra_id=0&graph_nolegend=true&graph_height=100&graph_width=300 TARGET /var/www/cacti/rra/c7606_1_traffic_in_396.rrd NODES C7606.1: N10 C7609#1: N50 BANDWIDTH 40M
Настройка NetFlow В качестве нашего программного коллектора будет использоваться flow-tools. Данное ПО умеет не только захватывать трафик, но и анализировать его. Так же на основе этого пакета написано не мало GUI для отображения собранной информации в человеческом виде.Управлять компонентом flow-capture я собирался с плагина кактуса flowview, поэтому после установки flow-tools, необходимо скопировать скрипт запуска сервиса с папки плагина в наш init.d на сервере.Из-за чего вся эта возня с системой управления? Ведь проще поправить конфиг вручную и забить? Но не тут то было. Количество устройств порядка 500 штук с весьма большим объемом трафика. Если сложить все flow в одну папку, извлечение данных по одному часу трафика займет более 2-х часов, это неприемлемо.
Решено было разделить потоки от каждого устройства в отдельную папку, чтобы выборка происходила в определенной папке с нужным трафиком. Средствами flow-capture это делается путем разнесения потоков от устройств по портам. А это значит, каждое устройство нужно настроить с уникальным портом отдачи flow?
Это так же неприемлемо, поэтому на помощь в решении данной проблемы приходит простая маленькая программка samplicator. Суть работы такова: принимает входящие UDP пакеты, сортирует их по адресу источника и транслирует в выбранный порт. А это значит, что настройку оборудования мы делаем типовую на один порт, а уже на самом сервере распределяем потоки по портам.
Синтаксис конфига: Source/Mask: Destination1/Port [Destination2/Port] и пример:
samplicate.conf 10.20.0.0/255.255.0.0:0/205610.20.30.252/255.255.255.252:10.20.0.108/2057 0/205710.20.30.4/255.255.255.252:10.20.0.108/2058 0/205810.20.30.160/255.255.255.255:10.20.0.108/2059 0/2059
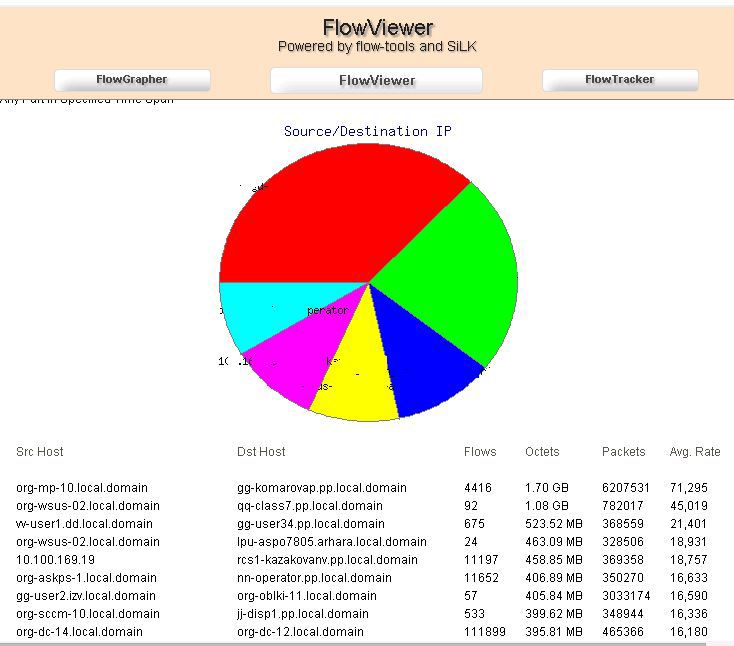
Flow собрали, с ужасом смотрим скорость заполнения наших дисков. Как теперь все это просмотреть? Есть много способов, можно генерировать отчеты вручную через тот же пакет flow-tools. Но это могут сделать не все пользователи системы, да и тому, кто может, надо попотеть, чтобы написать человеческий отчет.Я обратился к еще одному замечательному проекту FlowViewer.
Когда я его откопал и начал использовать, была версия 3.3 или что-то вроде того, 2006 года. Пока я разобрался с 3-й версии, проект неожиданно ожил и начал развиваться, 4-я версия была просто гениальна, по сравнению с 3-й. На момент написания статьи текущая версия 4.4 (у меня используется 4.1).
По своей сути, он почти полностью дублирует плагин Кактуса flowview, но сам плагин мне понравился только имеющимся расписанием, его работа по выборке нестабильна, фильтры не полные, а нужной агрегации нет. И архитектурно весь flow хранится на втором сервере, а значит FlowViever с удовольствием ставиться на второй сервер и предоставляет красивые графики и выборки с трафиком.
flowviewer
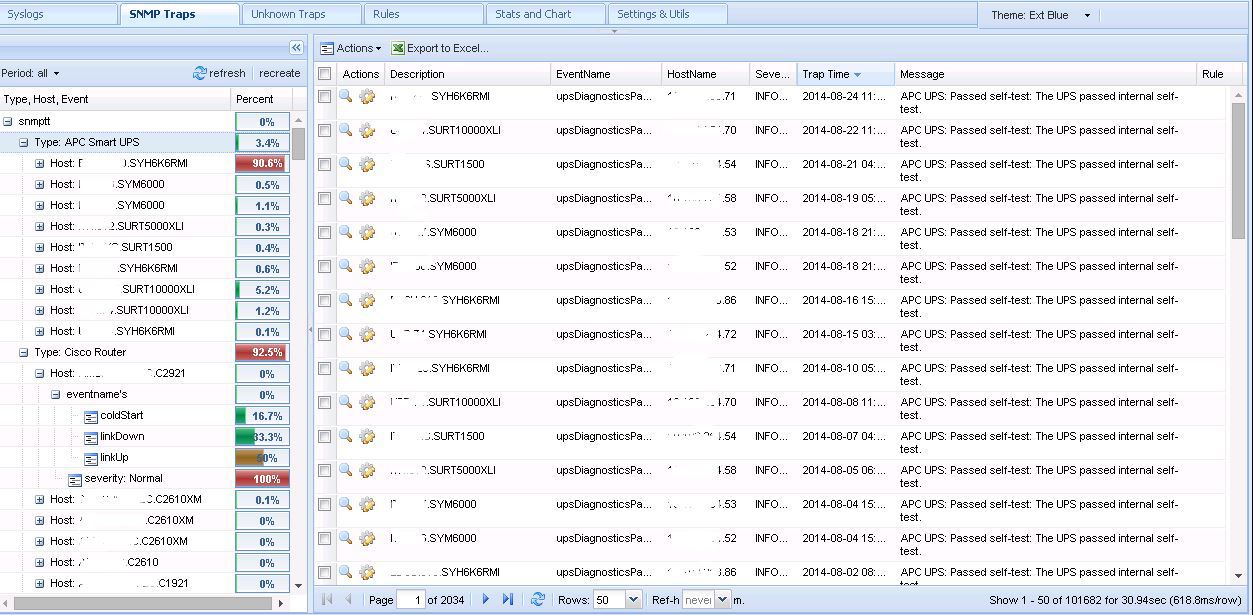
 SNMP Traps
Потоки с flow — это очень хорошо и заманчиво, но использовать их для оповещения о проблемах невозможно. Только для анализа уже после устранения проблемы.Ну и самый доступный способ оповещения — это SNMP трапы. Получать SNMP трапы от 500 устройств одним списком не очень приятное занятие, потеряешь в мусоре важную на данный момент информацию. Ясно, что надо делать какой-то фильтр. Тут готового решения, удовлетворяющего мои требования найдено не было. Но не беда, вспомнив тягу к программированию в институте решил написать анализатор трапов сам.
SNMP Traps
Потоки с flow — это очень хорошо и заманчиво, но использовать их для оповещения о проблемах невозможно. Только для анализа уже после устранения проблемы.Ну и самый доступный способ оповещения — это SNMP трапы. Получать SNMP трапы от 500 устройств одним списком не очень приятное занятие, потеряешь в мусоре важную на данный момент информацию. Ясно, что надо делать какой-то фильтр. Тут готового решения, удовлетворяющего мои требования найдено не было. Но не беда, вспомнив тягу к программированию в институте решил написать анализатор трапов сам.
Технология получения фильтрованного списка такая: при получении трапа сервер мониторинга принимает (snmptrapd) его, анализирует (snmptt) в соответствии с загруженными MIB спецификациями и сразу кладет в базу данных.
snmptt.conf mysql_dbi_enable = 1mysql_dbi_host = localhostmysql_dbi_port = 3306mysql_dbi_database = cactimysql_dbi_table = plugin_camm_snmpttmysql_dbi_table_unknown = plugin_camm_snmptt_unkmysql_dbi_table_statistics = plugin_camm_snmptt_statmysql_dbi_username = cactimysql_dbi_password = cactimysql_ping_on_insert = 1mysql_ping_interval = 300 Перехватывать эту обработку особого смысла нет, потому что придется заводить как-то свой стек событий. Это нам ни к чему, тем более база данных в которую попадают трапы у нас заполнена информаций об устройствах (имена, порты, линки), которую Кактус собирает сам по средствам SNMP опроса.Привлекательным выглядит вариант забирать с базы события, связывать их с имеющейся базой для информативности. Вооружившись блокнотом, начал придумывать логику. С ней особых проблем не возникло, проблемы возникли при выборки данных из БД. Которая начала занимать от 30 секунд. Ни о какой оперативности тут речь не шала. Теория оптимизации баз данных, оптимизация запросов, индексы, планы, умные советы моей спутницы (специалиста по сверхбольшим БД) сделали своё дело.

Основная мысль фильтровать Up/Down трапы, в описании которых встречаются имена интерфейсов (Eth, Serial, Gi, E), по идентификаторам и источнику ищем данные в таблице с SNMP. На выходе получаем красивую строку, когда, где и куда упал линк.
MySQL Select: Channel Status
Select
MAX (sd.id),
sd.id_channel,
sd.`status`,
sd.diff,
MAX (sd.date) as 'date',
MIN (sd.date2) as 'date2',
SUM (UNIX_TIMESTAMP (sd.date)-UNIX_TIMESTAMP (sd.date2)) as 'time',
MAX (sd.id_trap) as 'id_trap',
`host`.description,
channel_list.ch_name
from (
SELECT
a.id,
a.id_channel,
a.`status`,
UNIX_TIMESTAMP (NOW ())-UNIX_TIMESTAMP (a.date) as 'diff',
a.date,
(select
CASE cs2.`status`
WHEN a.`status` THEN null
ELSE cs2.`date`
END
from custom_status AS cs2
where cs2.id_channel = a.id_channel and cs2.date =
(select MAX (cs.date) from custom_status cs
where cs.date < a.date
and cs.id_channel = a.id_channel
) LIMIT 1 ) as 'date2',
a.id_trap
FROM
custom_status AS a
JOIN (SELECT t.id_channel,
MAX(t.date) AS max_date
FROM custom_status t
GROUP BY t.id_channel) AS b ON b.id_channel= a.id_channel) sd
INNER JOIN channel_list ON channel_list.id = sd.id_channel
INNER JOIN `host` ON channel_list.hostname = `host`.hostname
where sd.`status` = 'linkUp'
AND sd.date between DATE_SUB(CURDATE(),INTERVAL MOD(DAYOFWEEK(CURDATE())-2,7)+7 DAY) AND DATE_ADD(CURDATE(), INTERVAL MOD(7 - (DAYOFWEEK(CURDATE()) - 1), 7)-6 DAY)
GROUP BY sd.id_channel,sd.`status`
ORDER BY date desc"
Все данные с базы оформляются в читабельным вид в виде html страничек.Info from Traps
 Выборки с БД получая разные условия, формируют разные таблички отчетов.
Выборки с БД получая разные условия, формируют разные таблички отчетов.
Detail info
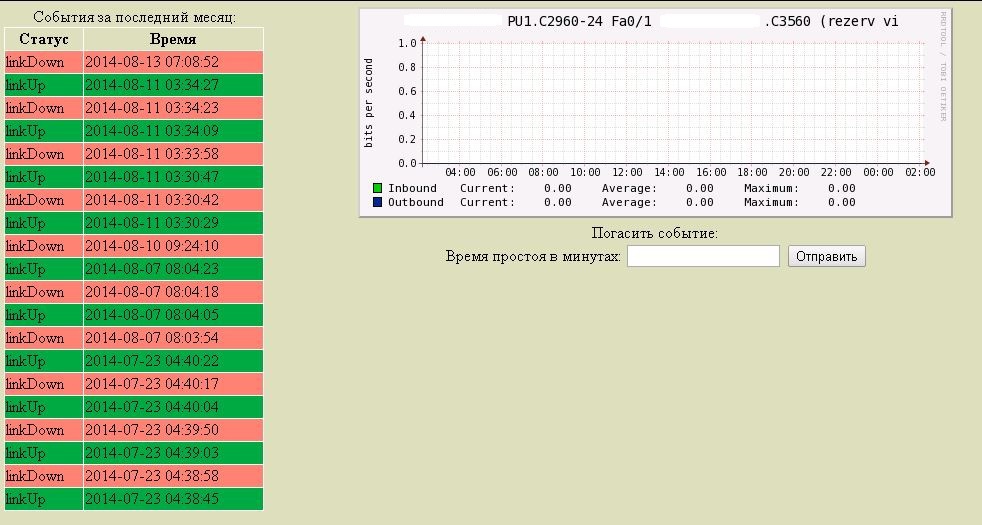 Благодарю читателя, осилившего все моё сумбурное повествование. Отчасти связанное с тем, что система уже год с лишним работает без меня. Много забылось, что-то потеряло смысл. Но работает мониторинг до сих пор, собирает данные и обеспечивает выборки уже без моей поддержки.
Благодарю читателя, осилившего все моё сумбурное повествование. Отчасти связанное с тем, что система уже год с лишним работает без меня. Много забылось, что-то потеряло смысл. Но работает мониторинг до сих пор, собирает данные и обеспечивает выборки уже без моей поддержки.
Все данные, скриншоты и конфиги деперсонализированы. Любые совпадения являются случайностью.
