[Из песочницы] Реверс-инжиниринг бинарного формата на примере файлов Korg .SNG

Мы живем в удивительное время. Вокруг нас изобилие техники: телефоны, компьютеры, умные часы и прочие гаджеты. Каждый день производители выпускают на рынок все новые и новые устройства. Большинству их них предначертана короткая и яркая (или не очень) жизнь: мощная маркетинговая компания в момент выпуска, 1–2 года полноценной поддержки производителем, а затем медленное забвение. Простые устройства могут годами работать и после окончания срока официальной поддержки. С «умными» девайсами все сложнее. Хорошо если гаджет хотя бы продолжит работу после отключения серверов/сервисов производителя. И повезет, если очередное обновление ОС, драйверов или другого ПО не прибьет совместимость.
К сожалению все чаще события развиваются по пессимистичному сценарию. И спустя 5–10 лет после покупки, у нас на руках оказываются технически исправные устройства, которыми тем не менее нельзя пользоваться из-за отсутствия софтовой поддержки. Конечно, неработающий гаджет — это неприятно. Но куда неприятнее, если имеются пользовательские данные в несовместимом ни с чем формате. Эти данные можно считать потерянными если устройство перестает функционировать. В моем случае самое страшное еще не случилось, но тревожные звоночки уже во всю звенят.
Итак, есть небезызвестная фирма Korg, которая выпускает весьма качественное музыкальное оборудование. В 2010 м году я купил синтезатор этой фирмы для занятия музыкой в качестве хобби. Korg microstation — модель достаточно продвинутая. Кроме всего прочего, имеет на борту секвенсер для записи своих трэков и может писать данные на карту памяти в проприетарном формате SNG. Есть возможность экспорта в распространенный формат миди, но при этом теряются почти все метаданные: информация о наложенных эффектах и фильтрах, различные настройки виртуальных инструментов и т.д. Основная же проблема лично для меня — в скорости перехода к записи музыкальных идей. Муза — создание капризное, и я чаще всего наталкиваюсь на интересную идею просто импровизируя или наигрывая что-нибудь незамысловатое. Чем быстрее я нажму кнопку записи без блуждания по меню — тем вероятнее смогу повторить и записать интересный фрагмент, который в будущем может стать частью полноценного произведения. Конечно, этот подход неидеален, но мы же говорим про хобби. Так или иначе, за почти десять лет, у меня скопилось около тысячи музыкальных эскизов и зарисовок в формате SNG.
Звоночек же прозвенел в виде череды глюков синтезатора, потребовавших перепрошивки устройства. И я задумался о переводе всех своих скопившихся данных в формат Midi, тем более что это позволит гораздо проще их хранить, систематизировать и редактировать. Поиск конвертера в гугле ничего не дал. Есть множество запросов на всевозможных форумах, история вопроса тянется уже лет 20 если не больше. Все что я нашел — чья-то древняя виндовая утилита, естественно несовместимая с моими файлами.
И тогда я решил попробовать посмотреть что же представляет из себя этот формат SNG? Может где-то внутри там спокойно лежат обычные миди данные, которые можно без особых усилий вытащить и сохранить?
Попытка решить задачу «в лоб»
Итак, из инструкции к синтезатору можно узнать, что формат SNG — это контейнер, в котором хранятся так называемые «песни». Каждая песня содержит 16 трэков секвенсера с музыкальными данными, а также настройки звуков и эффектов. При экспорте в формат Midi через меню синтезатора, каждая «песня» экспортируется в отельный файл .MID, а все настройки звуков и эффектов теряются. Т.к. свои идеи я наигрываю в самом простом виде и без эффектов, то проблемой является именно большое количество SNG файлов и неудобство процесса ручной конвертации. Посмотрим, нельзя ли этот процесс ускорить или автоматизировать.
Для начала вспомним что такое миди-данные. Упрощенно говоря, это поток музыкальных событий: нажатие и отпускание клавиши, нажатие и отпускание педали сустейна, изменение темпа, патча (виртуального инструмента) и других параметров. Каждое событие содержит временную дельту с момента предыдущего события и данные, например, интенсивность и высоту ноты. Формат midi файла очень простой: кроме заголовков и самих данных там практически ничего нет.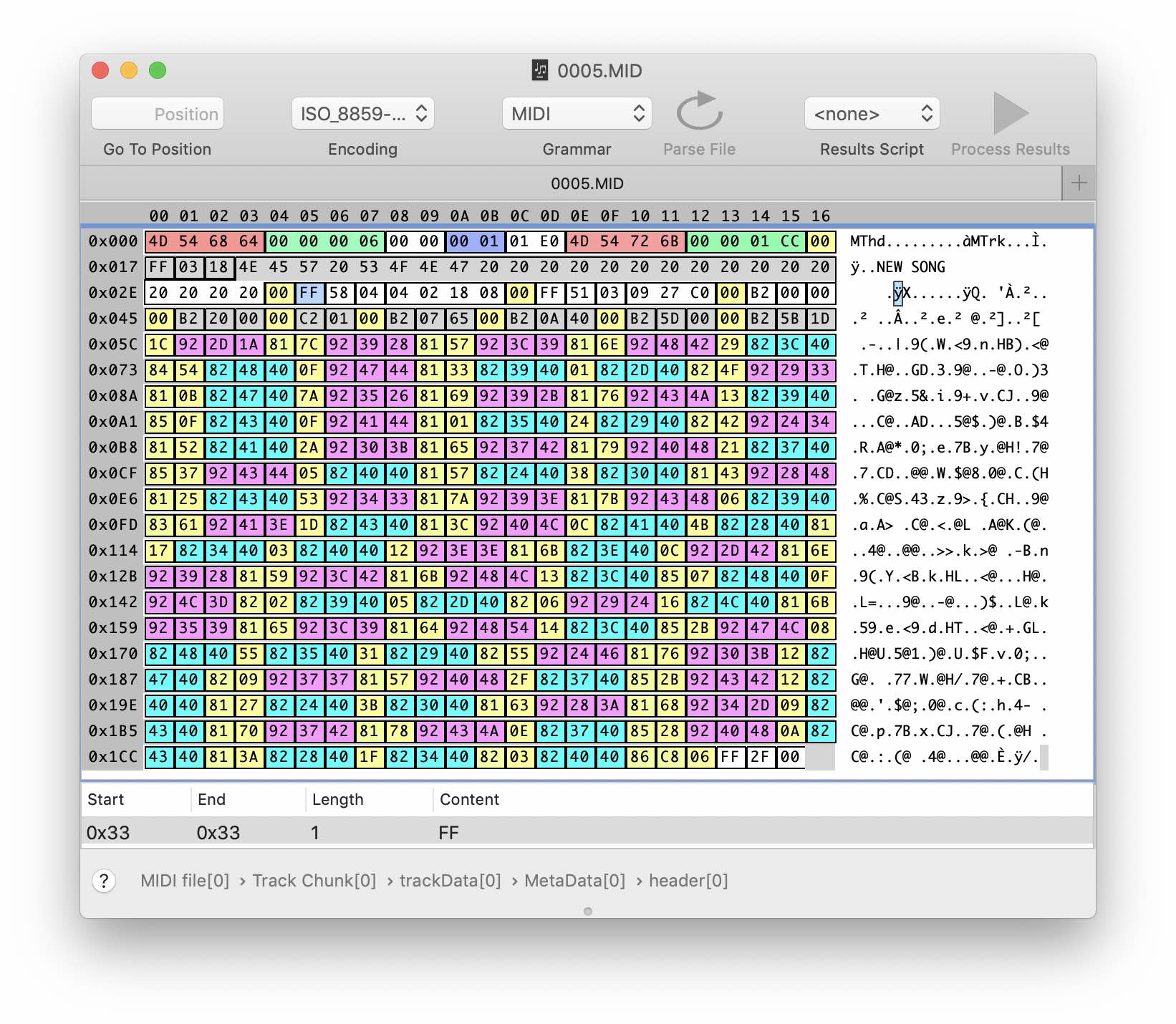
Розовый — событие Note On. Бледно-желтый — дельта времени. Голубой — событие Note Off.
Попробуем поискать наши миди данные в файле SNG. Для этого запишем на синтезаторе последовательность из несколько нот и экспортируем в оба формата. Т.к. мы не знаем где конкретно в бинарных файлах находятся музыкальные данные, то попробуем повторить процесс с разными последовательностями нот.
Здесь и дальше я пользуюсь Hex-редактором Synalyze It! Его возможности в дальнейшем нам очень пригодятся. Пока же просто воспользуемся функцией сравнения двоичных файлов.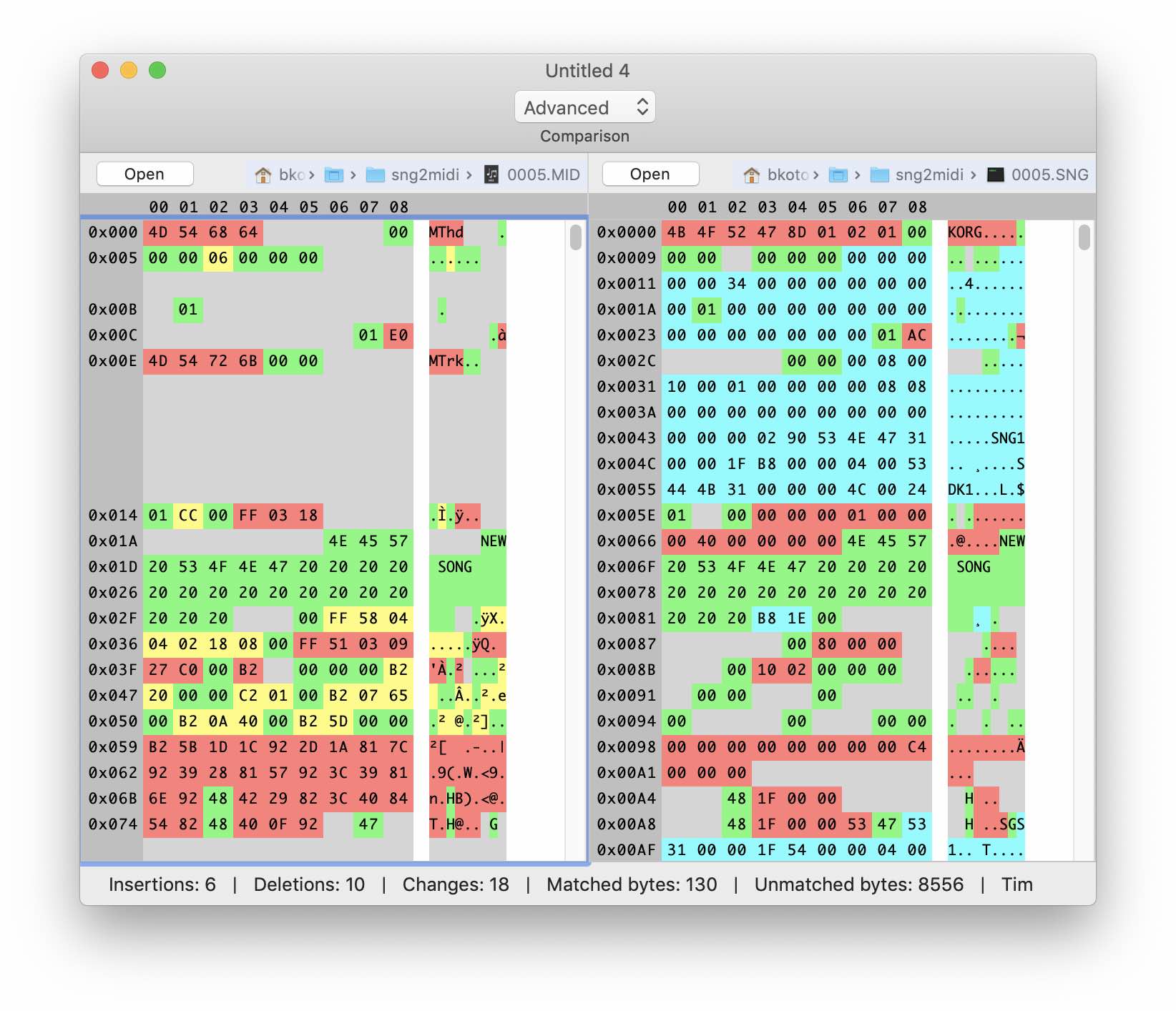
По сути, совпало только название «песни». Сравнив два SNG файла с разными последовательностями нот можно примерно предположить где именно хранятся музыкальные данные, но нам это пока ничем не поможет — формат данных отличается. Сам файл в десятки раз больше Midi файла и судя по всему содержит много дополнительной информации. Можно видеть сигнатуру KORG в первых четырех байтах и некоторые другие строки, в том числе название «песни» и имена патчей (тембров), назначенных на трэки.
Разбор структуры блоков данных
На этом можно было бы закончить, если бы, к счастью, не появились инструменты, позволяющие относительно легко проанализировать и понять структуру данных хранящихся в двоичном виде. В этом нам поможет все та же программа Synalaze It!, которая позволяет создавать и применять «грамматику» для анализа бинарных файлов.
Грамматика — это иерархическая описательная структура, позволяющая представить двоичные данные в понятном человеку виде. Программа позволяет загрузить грамматики для некоторых форматов. Например, для того же midi: 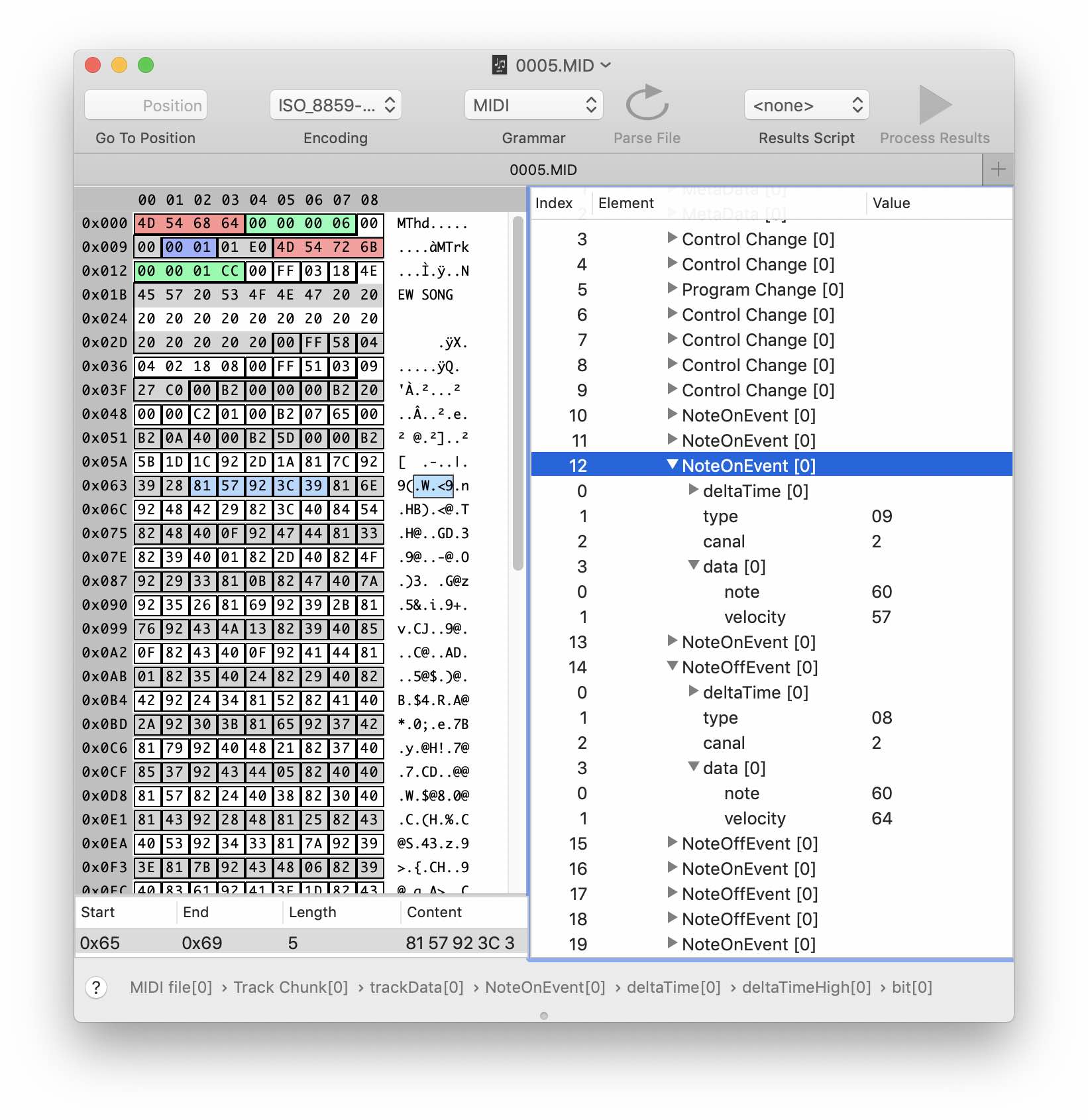
Для формата SNG готовой грамматики ожидаемо не нашлось. Что ж, посмотрим, что мы сможем извлечь из файла своими силами.
Начнем с заголовка. Как правило эта часть содержит сигнатуру файла, информацию о версии, размеры и смещения блоков данных. Сравнив несколько различных SNG файлов, найдем неизменные части и обратим более пристальное внимание на те что меняются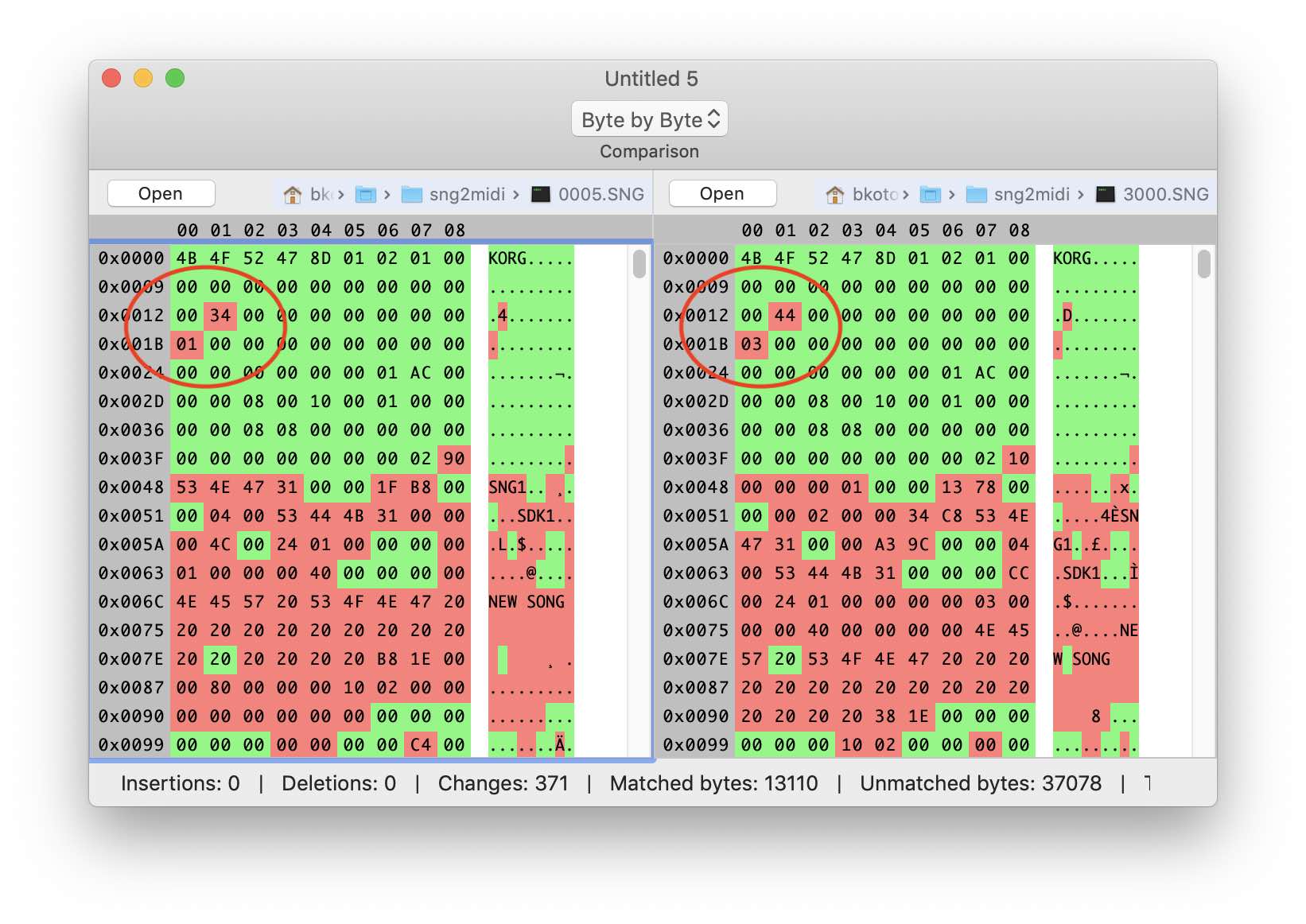
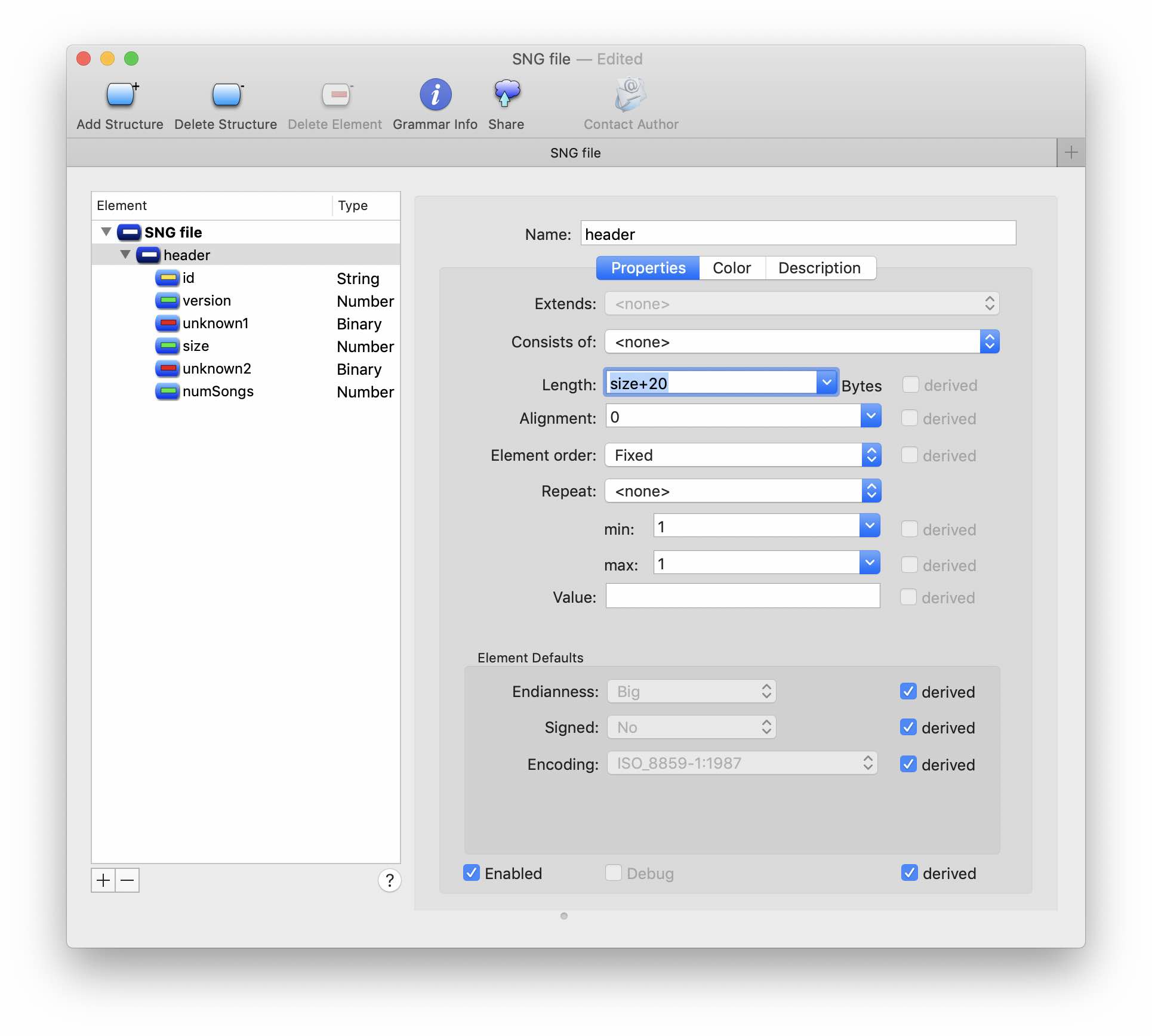
Создадим структуру заголовка в редакторе грамматики. Первые 4 байта — очевидно сигнатура файла. Предположим, что следующие 4 байта относятся к версии. Следующие несколько десятков байт не меняются и не содержат ничего интересного — создадим для них binaryData соответствующего размера. А вот дальше начинается интересное. Можно заметить некоторые закономерности в поведении байтов по смещениям 0×13 и 0×1b. Второй похоже соответсвует количеству «песен» в нашем файле. А первый тоже растет с ростом количества данных в заголовке — похоже это размер, только отсчет идет не от начала файла, а со следующего байта 0×1с. На данном этапе мы можем только догадываться о типе числовых данных. Предположим, что размер имеет тип UInt32, т.е. занимает 4 байта. Добавим их к нашей структуре. Теперь мы можем задать размер структуры заголовка (size + 20).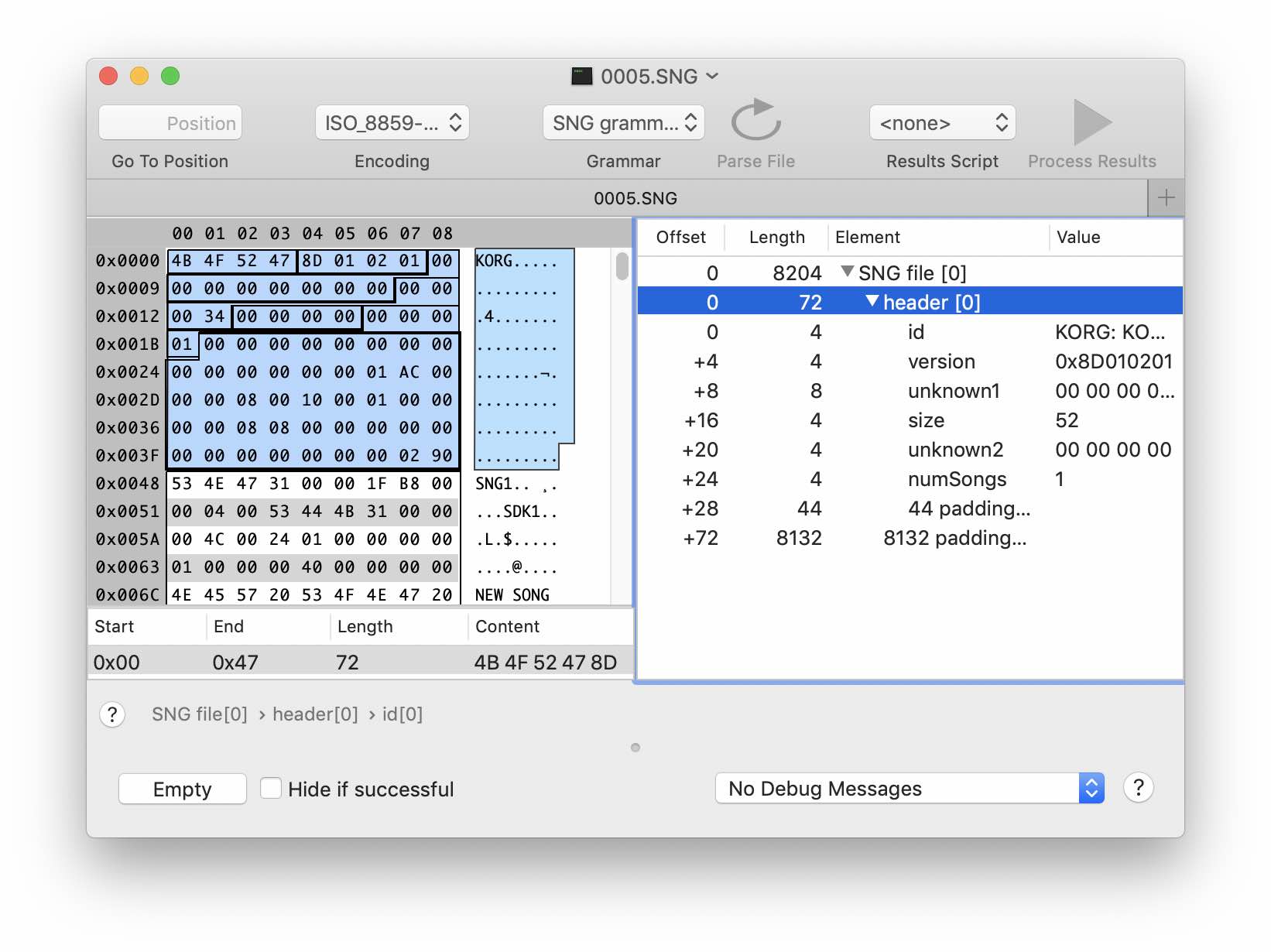
Посмотрим что же идет дальше. Если внимательно присмотреться, то можно заметить что по всему файлу разбросаны трехбуквенные аббревиатуры: SNG1, SDK1, SGS1 и так далее. Эти символы встречаются во всех SNG файлах, поэтому можно предположить, что это сигнатуры неких блоков. К тому же наш заголовок очень удачно закончился как раз перед одной из таких сигнатур. Сравним как ведут себя следующие за ней 4 байта в файлах разного размера. Видно, что значения растут с увеличением количества данных.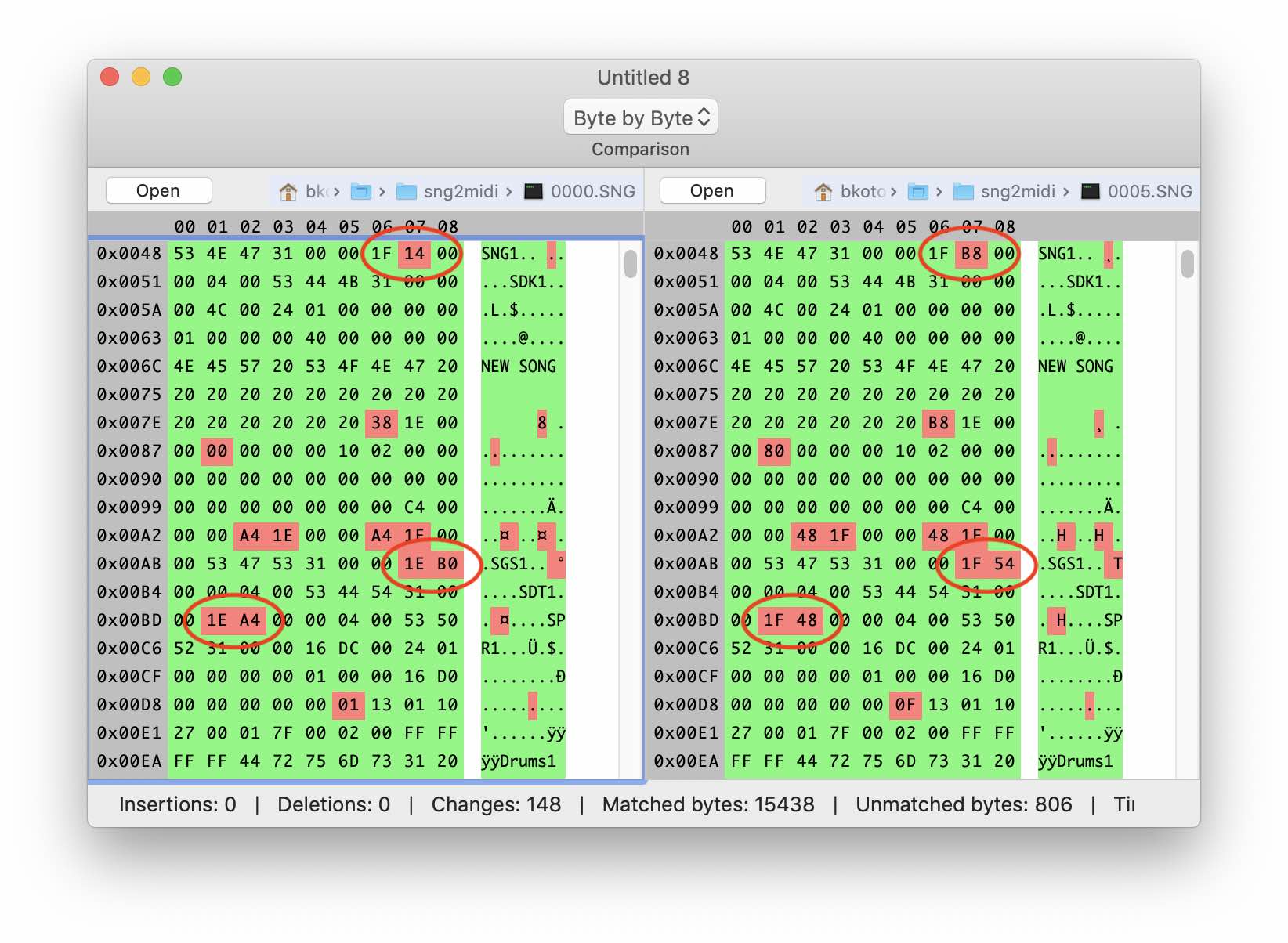
Еще немного экспериментов, анализа и расчетов и начинает вырисовываться следующая картина:
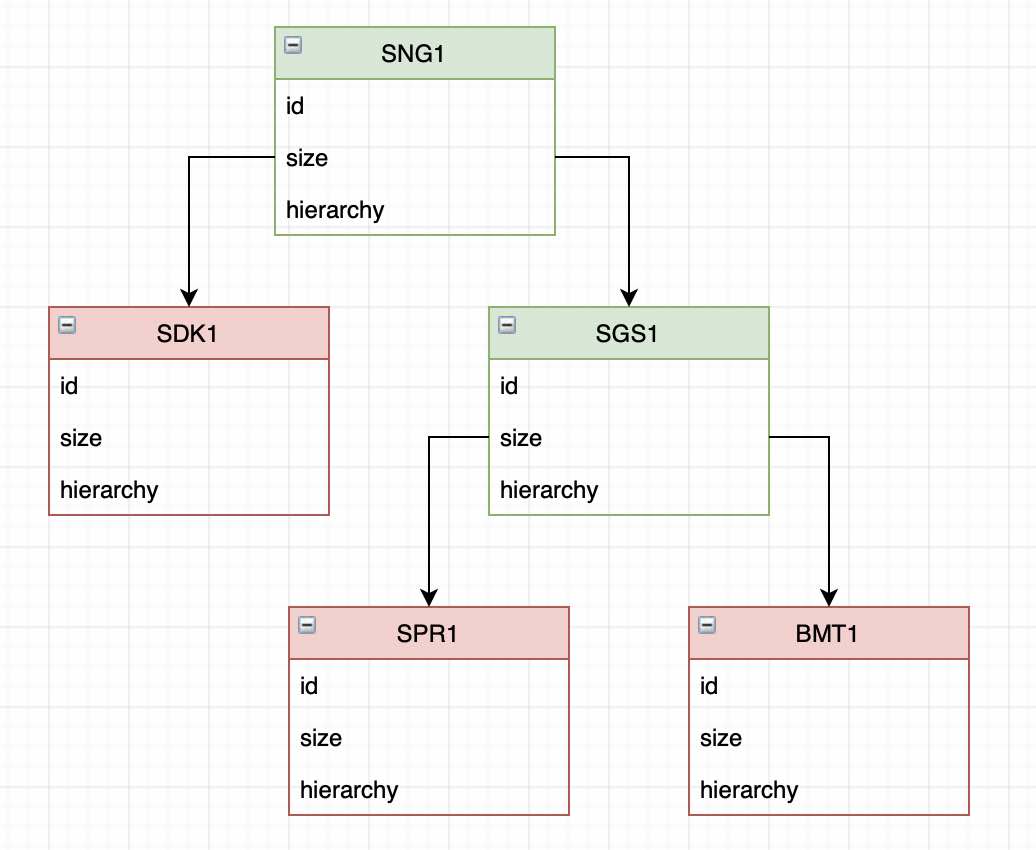

Таким образом наш файл состоит из достаточно простой иерархии блоков. Есть родительские блоки, которые могут содержать несколько дочерних блоков. Есть блоки-листья (в терминологии бинарных деревьев), которые не содержат других блоков.
Дальше начинается магия. С помощью всего нескольких структур грамматики мы можем полностью автоматически распарсить блочную структуру файла
Итак, создадим структуру-шаблон DataChunk со следующими полями (в квадратных скобочках указан размер):
id: String [4]
size: Int [4]
hierarchy: Int [4]
data: structure
Теперь создадим структуру parentChunk, которая наследует DataChunk. В свойстве hierarchy укажем Fixed Value 0×400 — это признак родительского блока. Обязательно отметить чекбокс Must match
Аналогично, создадим childChunk. Hierarchy в данном случае будет иметь два значения: 0×240100 и 0×100
Добавим ссылки на структуры parentChunk и childChunk в структуру data parentChunk — таким образом мы создаем рекурсию.
Наконец, добавляем ссылку на структуру parentChunk в главную ноду.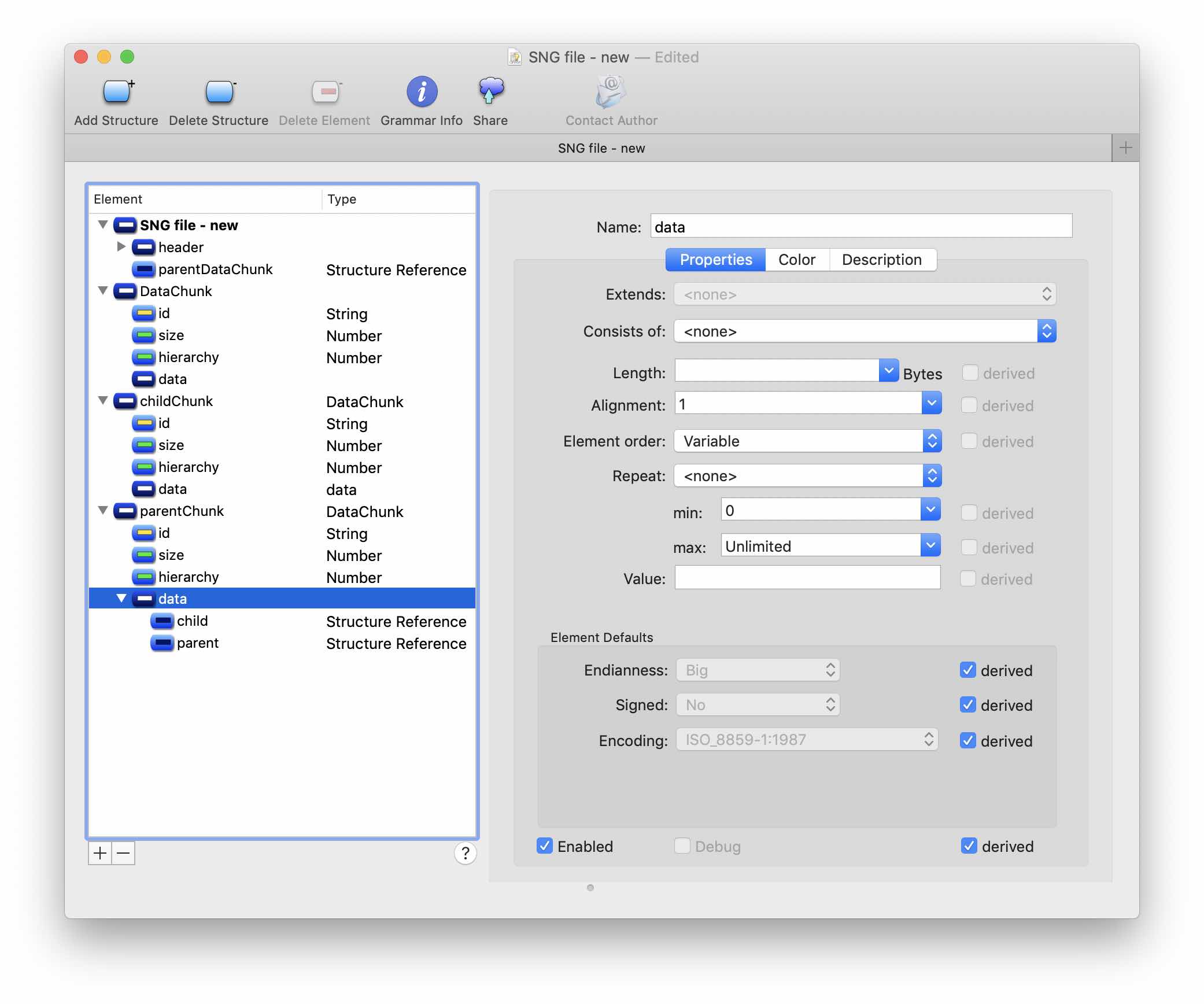
Порядок элементов в структуре data parentChunk должен быть Variable, также требуется задать минимальное и максимальное количество дочерних элементов этой структуры: 0 и Unlimited соотвественно.
Применим изменения, и вуаля — наш файл красиво распарсен на основные блоки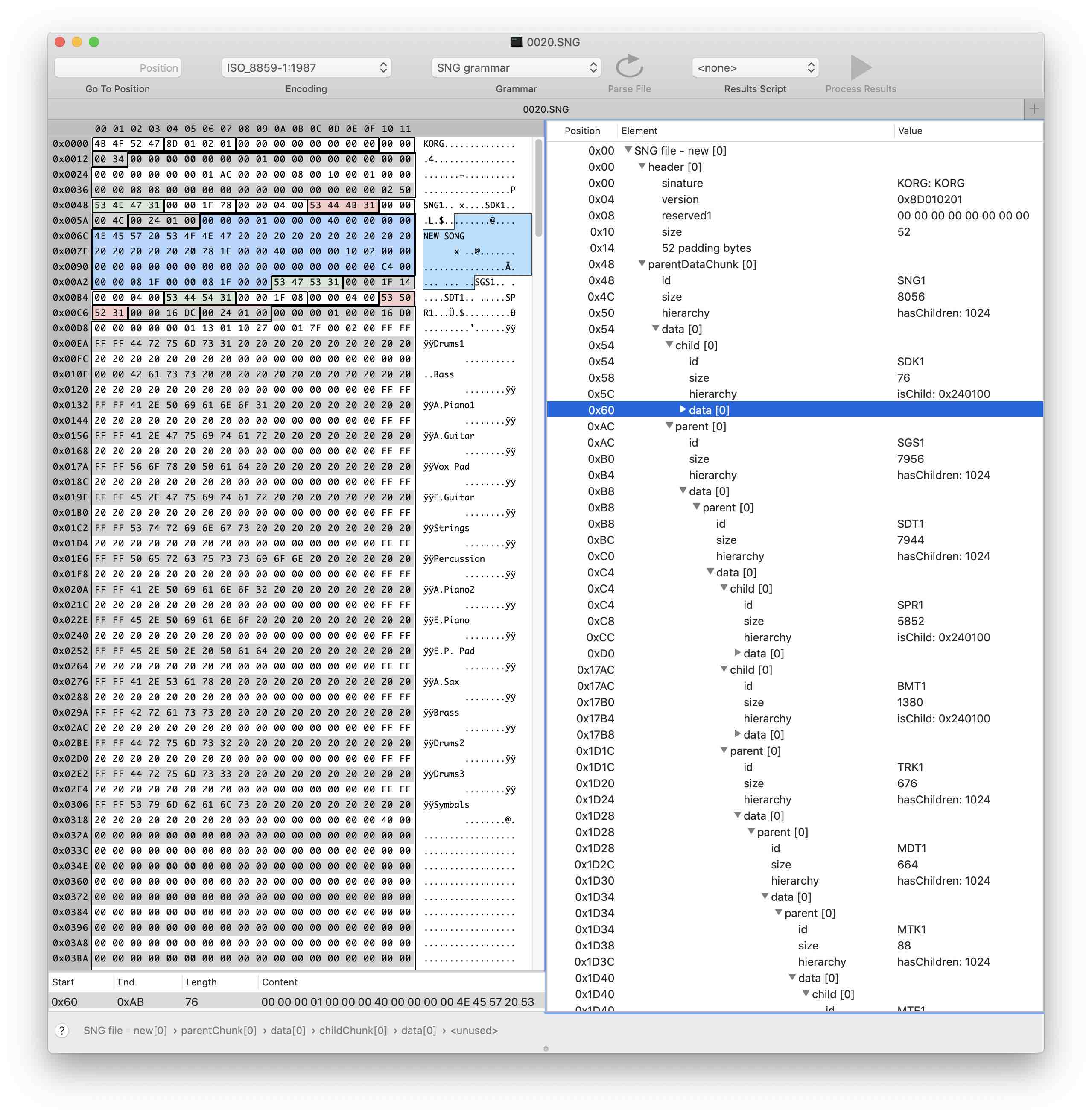
Про сами данные нам по-прежнему ничего не известно, зато теперь мы можем гораздо легче ориентироваться в файле и сосредоточиться на поиске нужной нам информации.
Разбор блока, содержащего «оглавление» файла
Для тренировки, попробуем разобрать какой-нибудь простой блок, например, SDK1. Судя по всему, он содержит что-то вроде оглавления — список песен и, вероятно, некие смещения/размеры.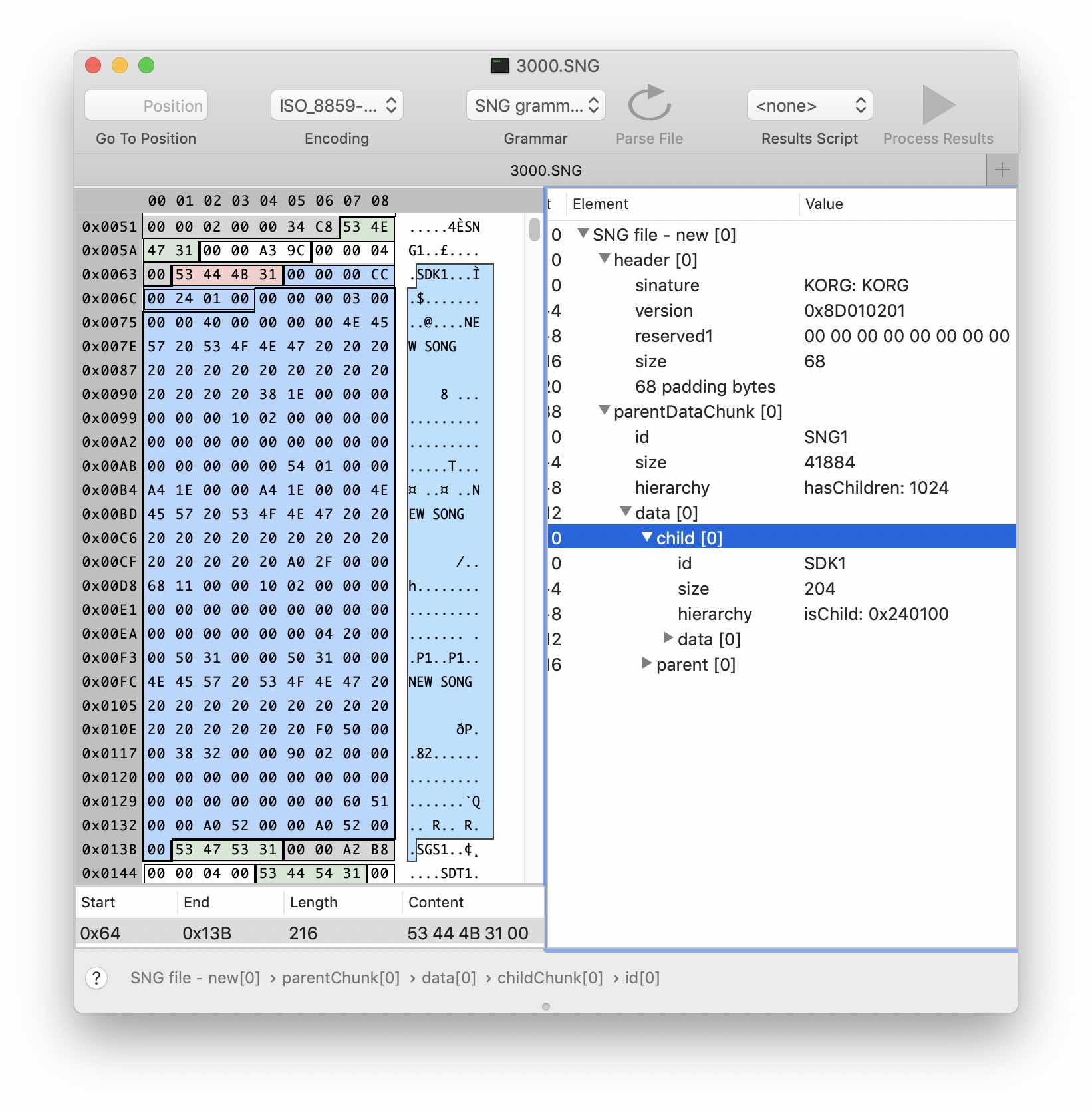
Создадим структуру sdk1Chunk, наследующую childChunk. Отредактируем поле ID, указав сигнатуру нашего блока в поле Fixed Values. Не забываем про чекбокс Must match. В данных блока можно наблюдать достаточно очевидный повторяющийся паттерн: название «песни» и пока неизвестные данные. Заметим, что размер повторяющихся фрагментов 64 байта. Также, сравнив версии файлов с разным количеством «песен», можно определить что в первых четырех байтах хранится их количество. Путем несложных расчетов и сделав несколько допущений, получим следующий вариант структуры в грамматике: 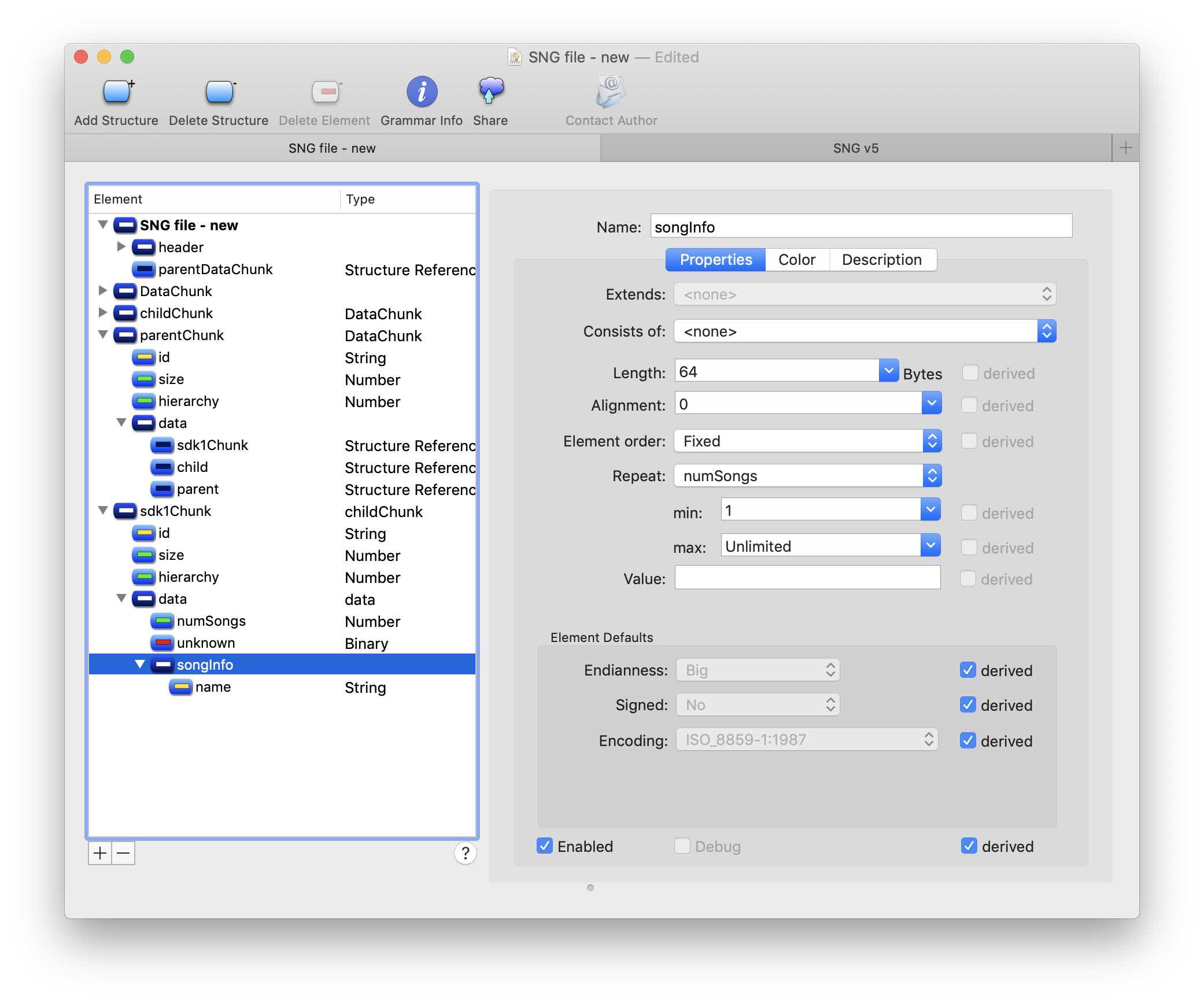
Здесь я создал дочернюю структуру songInfo размером 64 байта и указал возможность повторения numSongs раз. Вот так выглядит результат применения грамматики: 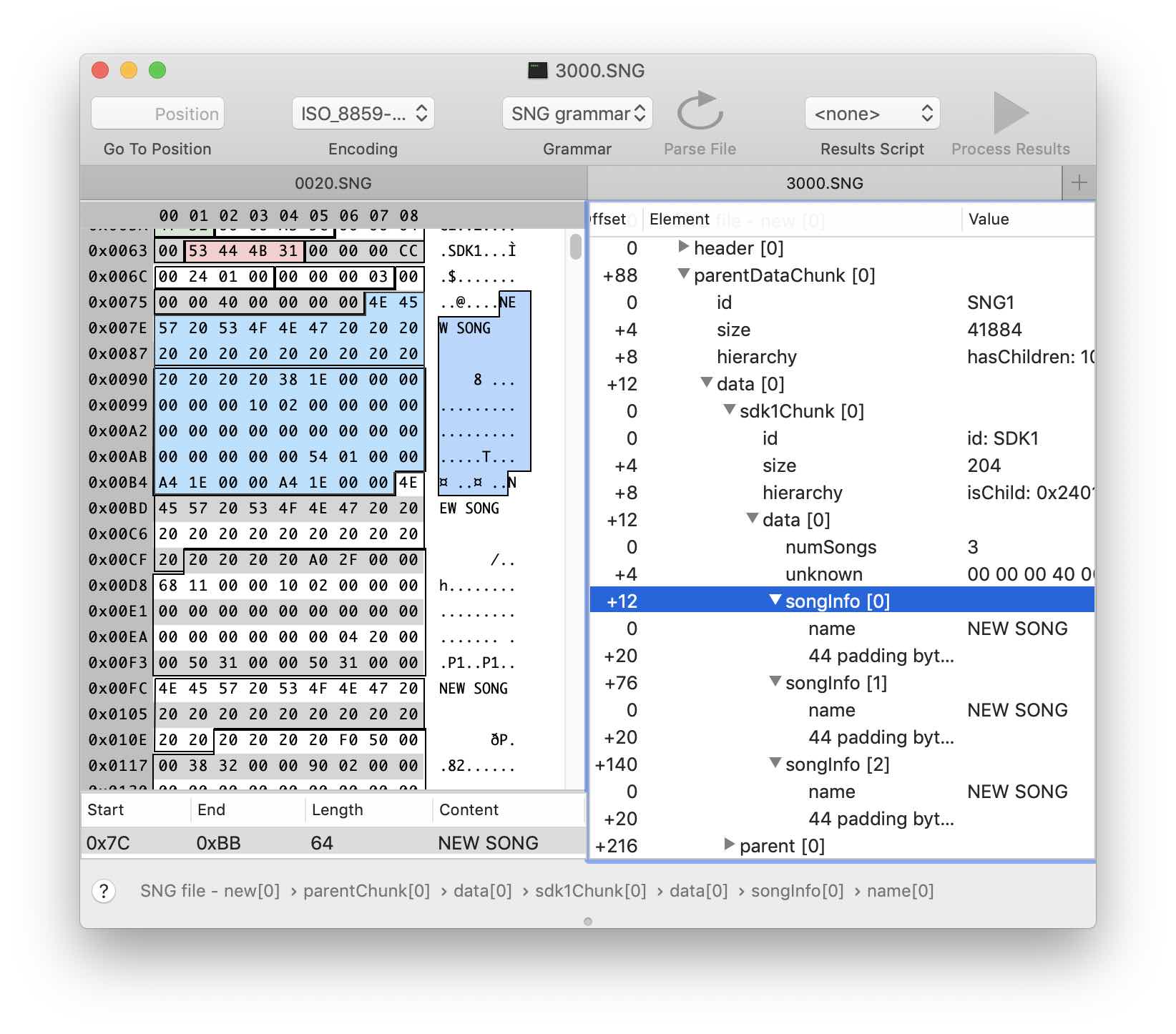
Дальнейший анализ файла остается делом техники. Я менял на синтезаторе общие настройки «песни» и параметры отдельных трэков. Сравнивая версии файлов с различными изменениями, можно совершенствовать и уточнять грамматику. После достаточно большого количества таких итераций, нераспознанных фрагментов данных в файле почти не остается. Я немного увлекся процессом и разобрал почти все секции файла, хотя для исходной задачи это не требовалось.
Детали этого процесса я упущу — в дальнейшем мы сосредоточимся на анализе непосредственно музыкальных данных.
Но об этом — в следующей части. Там же мы столкнемся с интересной задачей по конвертации данных (вполне подходит для собеседований), попробуем решить ее с помощью небольшого скрипта и услышим довольно необычный результат тестовой конвертации.
Предварительные итоги
Потребность в реверс-инжиниринге двоичных файлов может возникнуть неожиданно. Например, для анализа прошивки устройств, конвертации из редких форматов данных, анализа цифровых угроз или даже банальной модификации сохранений игр. Современные инструменты позволяют решать эти задачи быстро и эффективно. Примерно 10 лет назад, я занимался исследованием прошивок ноутбуков и этот процесс мог занять несколько недель. Тогда требовалось вручную писать скрипты для анализа блоков данных и размечать структуры. С новым частично автоматизированным подходом, я создал почти полную грамматику файла всего за пару дней.
Начать анализ двоичного файла можно с поиска строк — они могут дать первые зацепки и ускорить процесс анализа. Часто двоичные файлы состоят из блоков данных, которые организованы в иерархическую или линейную структуру. Если разобраться с этой структурой, то дальнейший анализ будет проходить гораздо проще. Заголовок файла может дать подсказки по смещениями/размерам блоков данных. На первых этапах имеет смысл сосредоточиться на описании очевидных структур и блоков. Задачу анализа сильно упрощает возможность создавать новые версии файлов с разными настройками, параметрами, данными. Существует ряд сложностей связанных с неизвестными типами данных и порядком байт в их двоичном представлении (Endianness). Эти вопросы мы затронем в следующей части.
Рекомендуемая литература
Andreas Pehnack. How to Approach
Binary File Format Analysis
