[Из песочницы] Расстояние Левенштейна и поиск контролёров
Наверное, в каждом городе Беларуси, где есть троллейбусы, существуют группы ВК или чаты в Telegram, в которых люди отслеживают местоположение контролёров. В основном это делается для того, чтобы не оплатить проезд и проехать бесплатно, хотя в описании групп почти всегда есть постскриптум «Платите за проезд».
В ВК это всё обычно выглядит вот так:
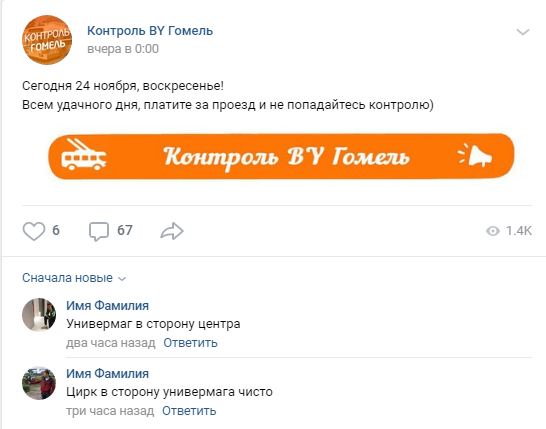
Типичный комментарий выглядит вот так:
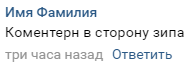
Структура предельно проста. В комментарии есть названия остановки, где в данный момент были замечены контролёры, есть и направление, на котором они стоят:
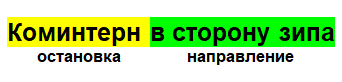
Комментарий, по итогу, — объект с остановкой, временем и датой, а так же уникальным id, по которому мы можем его идентифицировать. С помощью этого всего и можно вычислять наиболее вероятное местоположение того, где сейчас находятся контролёры.
Подготовка
Для начала нужно определить целевой паблик, из которого мы будем парсить данные. В группе должна быть достаточно большая активность в комментариях, иначе мы рискуем получить слишком мало данных
В моём случае это группа «Kонтроль Гомель».
Парсить комментарии мы будем с помощью официального API ВКонтакте для Python
Аутентифицируемся с ключом доступа пользователя, так как некоторые группы могут быть закрытыми, и доступ к их комментариям можно будет получить только если вас приняли в группу.
После этого можно приступать к добыче комментариев:
Получение комментариев
Для начала, получаем последний доступный пост в группе, чтобы вытащить оттуда комментарии через vk.wall.getComments, и инициализируем DataFrame, в который мы и будем сохранять данные.
В каждом посте с комментариями есть надпись «Всем удачного дня, платите за проезд и не попадайтесь контролю», так что, скачиваем комментарии, проверяем содержание поста и получаем массив комментариев, из которого и можно брать данные.
Я взял комментарии из постов за последние 3 месяца, учитывая, что каждый день выкладывается 1 пост (сейчас конец ноября, в сентябре начинается учебный год, и контролёры скорее всего это учитывают и меняют свои обыденные места). В принципе, можно учесть и другие признаки, такие как, например, время года.
Часть комментариев засорена сообщения типа «На Барыкина есть кто?». Если посмотреть на такие (ненужные) комментарии, то можно выделить некоторые признаки:
- В тексте встречаются слова «чисто», «уехали», «никого» и подобные
- Слова «подскажите», «кто», «что», «как»
- Cимволы, такие как, например, смайлы
После этого проходимся по массиву комментариев, и вытаскиваем из них уникальный id, текст, время, дату и день недели, которые кладём в уже созданный DataFrame.
import re
import time
import pandas as pd
import lp
import vk_api
import check_correctness
def auth():
vk_session = vk_api.VkApi(lp.login, lp.password)
vk_session.auth()
vk = vk_session.get_api()
return vk
def getDataFromComments(vk, groupID):
#получаем последний пост в группе
posts = vk.wall.get(owner_id=groupID, offset=1, count=90)
print("\n")
data = pd.DataFrame(columns=['text', 'post_id', "date", "day_in_week", "hour","minute", "day_in_month"])
for post in posts.get("items"):
#получаем id последнего поста в группе
postID = post.get("id")
if "Всем удачного дня, платите за проезд и не попадайтесь контролю" not in post.get("text"):
continue
#получаем объект commentary чтобы из него вытащить число комментариев
comments = vk.wall.getComments(owner_id=groupID, post_id=postID, count=200)
# проходимся по массиву комментариев и достаем всё что нужно в dataframe
for comment in comments.get("items"):
text = comment.get("text")
text = re.sub(r"A-Za-zА-Яа-я0123456789 ", "", str(text))
commentaryIsNice = check_correctness.detection(text)
if commentaryIsNice:
print(text)
date = comment.get("date")
time_struct = time.gmtime(date)
post_id = comment.get("post_id")
data = data.append({"text": text, "post_id" : post_id,
"date": date,"day_in_week" : time_struct.tm_wday,
"hour": (time_struct.tm_hour+3),
"minute": time_struct.tm_min,
"day_in_month": time_struct.tm_mday}, ignore_index=True)
# print(data[:10])
# print(data.info())
print("dataset is ready")
return data
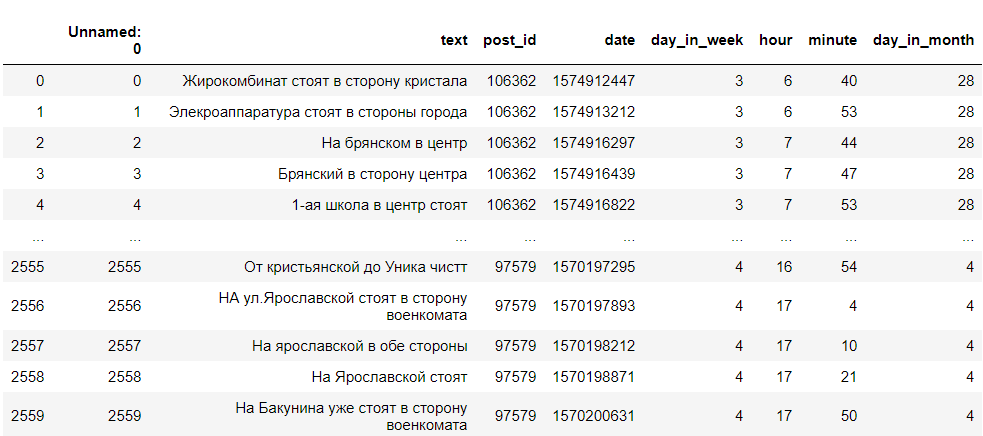
Таким образом, мы получили DataFrame с текстом комментариев, их id, днём недели, часом и минутой в которую был написан комментарий. Нам понадобится только день недели, час написания и текст. Примерно вот так это выглядит:
Очистка данных
Теперь нам нужно очистить данные. Необходимо убрать из комментария направление, чтобы при поиске расстояния Левенштейна меньше ошибаться. Находим выражения «в сторону», «ехать», «как», «возле», так как после них обычно следует название второй остановки, и удаляем их вместе с тем, что идёт после них, а так же заменить некоторые жаргонные названия остановок обычными.
from fuzzywuzzy import process
def clear_commentary(text):
"""удаляем вторую часть комментария -
направление на котором стоят контролёры"""
index = 0
splitted = text.split(" ")
for i, s in enumerate(splitted):
if len(splitted) == 1:
return np.NaN
if ((("сторон" in s) or ("ехать" in s) or (
"как" in s) or (
"возл" in s)) and s is not ""):
index = i
if index is not 0 and index < len(splitted) - 2:
for i in range(1, 4):
splitted.remove(splitted[index])
string = " ".join(splitted)
text = (string.lower())
elif index is not 0:
splitted = splitted[:index]
string = " ".join(splitted)
text = string.lower()
else:
text = " ".join(splitted).lower()
return text
def clean_data(data):
data.dropna(inplace=True)
data["text"] = data["text"].map(lambda s: clear_commentary(s))
data.dropna(inplace=True)
print("cleaned")
return dataПреобразование с помощью расстояния Левенштейна
Непосредственно переходим к расстоянию Левеншейна. Небольшая справка: расстояние Левенштейна — минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую.
Его мы будем находить с помощью библиотеки fuzzywuzzy. Она помогает быстро и просто высчитать расстояние Левенштейна. Для ускорения работы авторы библиотеки советуют также установить библиотеку python-Levenshtein.
Для того чтобы вытащить остановки из комментариев, нам нужен список остановок. Его мне любезно предоставил разработчик приложения GoTrans, Александр Козлов.
Список пришлось расширить, добавив туда некоторые остановки, которых там не было, и изменив часть названий, чтобы они лучше находились.
stops = ['универсам', 'луговая', 'рембыттехника', 'ленинградская', 'ярославская', 'полесская',
'ярославская', 'тимофеенко', '8 марта',
'торговый дом речицкий', 'проспект речицкий', 'цирк', 'универмаг', 'чонгарcкая',
'чонгарка', 'ггу', 'скорина', 'университет', 'прибор', '1000 мелочей', 'майская', 'вокзал',
'парк выпускников', 'торговоэкономический', 'юбилейный', 'мкр 18', 'аэропорт', 'встречная',
'гомельгеодезцентр', 'кристалл', 'озеро любенское', 'рынок давыдовский', 'давыдовка',
'река сож', 'гомельдрев',
'севруки', 'гму №1', 'тд речицкий', 'костюковка', 'инфекционную больницу', 'лагерь чайка',
'волотова', 'коралловая', ' гомельторгмаш', 'гомельпроект', 'внешгомельстрой', 'газета',
'каленикова', 'ерёмино', 'ликероводочный', 'спецпромавтоматика', '2ая школа', 'барыкина',
'станочных узлов', 'молодёжный', 'корпус литья', 'химы', 'головацкого', 'будённого',
'спту67', '35й', 'гагарина', '50 лет заводу гомсельмаш', 'горка', 'радиозавод',
'бабушкина', 'стеклозавод', 'каштановая', ' пусковых двигателей', 'космонавтов',
'рцрм начальная', 'быховская', 'институт мчс', 'дк гомсельмаш', 'магазин', ' речицкий',
'севруки', 'осовцы', 'турист', 'мясокомбинат', 'святотроицкий', 'медгородок', 'октябрь',
'нефтебаза', 'гомельоблавтотранс', 'милкавита', 'бакунина', 'зип', 'ома', 'живица',
'строймаркет кск', 'дорожник', 'полевой', 'каменецкая', 'большевик', 'якубовка',
'бородина', 'гипермаркет гиппо', 'героев подпольщиков', '9 мая', ' каштан', 'протезист',
'станция ипуть', 'коминтерн', 'музпедколледж', 'агрофирма', 'объездная дорога', 'победа',
'западный', 'жемчужная', 'владимирова', 'сухого', 'профилакторий', 'иванова',
'машиностроительный', 'берёзки', '60 лет', 'энергетик', 'центролит',
'онкологический диспансер', 'стрелковый тир', 'головинцы', 'коралл', 'южный', 'весенняя',
'ефремова', 'пограничная', 'белгут', 'гомельстрой', 'борисенко', 'дворец легкой атлетики',
'мичуринский', 'солнечная', 'гастелло', 'войсковая', 'автоцентр', 'сантехзаготовок', 'уза',
'медколледж', 'детский сад 11', 'большевик', 'ченки', 'давыдовский', 'океан', 'прогресс',
'добрушская', 'белого', 'гск', 'давыдовка', 'электроаппаратура', 'дружба',
'70 лет', 'авторемонтный', 'шведская горка', 'автодром', 'водоканал', 'станкогомель',
'волотова', 'пионер', 'рцрм', 'химторг', '2й переулок луговой', 'бочкина', 'купалы',
'онкологический диспансер', 'площадь', 'ленина', '1ая школа', 'магазин южный',
'гомельагротранс', 'мельников', 'любенский', 'военкомат', 'больница', 'уза', 'рцрм',
'лизюковых', 'магазин ипуть', 'ратон', 'азс', 'рандовское', 'хутор', 'каштан', 'роповский',
'романовичи', 'ильича', 'гребной', 'строительное предприятие', 'инфекционная',
'жирокомбинат', 'автосервис', 'агросервис', 'залипье', 'никольская',
'самоходных комбайнов', 'каменщикова', 'стройматериалы', 'рембыттехника', 'администрация',
'октября', 'лесная сказка', 'татьяна', 'бориса царикова', 'жарковского', 'зайцева',
'переезд', 'карповича', 'домостроительный комбинат', 'горэлектротранспорт', 'злин',
'стадион гомсельмаш', 'ап 6', 'гидропривод', 'локомотивное депо', 'авторынок осовцы',
'новая жизнь', 'жукова', 'военная часть', '3ая школа', 'лесная', 'красный маяк',
'областная', 'давыдовская', 'карбышева', 'спутник мира', 'молодёжная', 'стадион локомотив',
'солнечный', 'ладасервис', 'мкр 21', 'арэса', 'интернационалистам', 'косарева',
'богданова', 'гомельжелезобетон', 'мкр 20а', 'мкр речицкий', ' медтехника', 'джураева',
'колледж художественных промыслов', 'ледовый', 'дк фестивальный', 'торговый центр',
'куйбышевский', 'фестивальный', 'гараж кооп 27', 'сейсмотехника', 'мильча', 'туббольница',
'пту179', 'химизделий', 'пожарная часть', 'госпиталь', 'автобусный парк',
'газетный комплекс', 'победы', 'клёнковский', 'алмазная', 'мотороремонтный', 'мкр 19']
С помощью .map и fuzzywuzzy.process.extractOne находим в списке остановку с минимальным расстоянием Левенштейна, после чего заменяем текст комментария на название остановки, что позволяет в итоге получить датасет с названиями остановок.
Получившийся датасет выглядит примерно вот так:
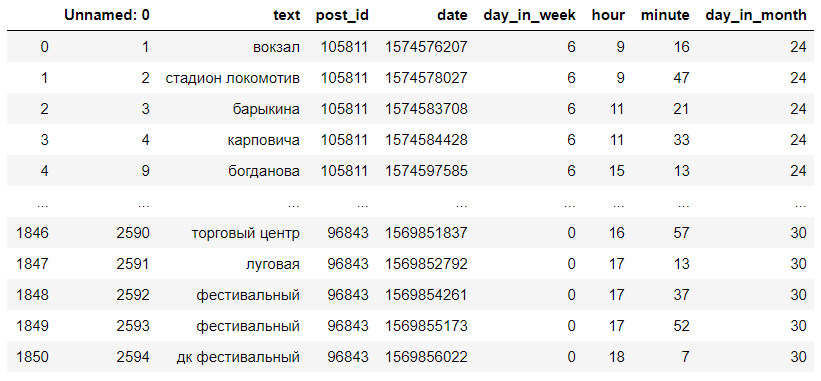
def get_category_from_comment(text):
"""ищет наилучшее расстояние Левенштейна до названия остановки из списка
и перезаписывает комментарий названием остановки """
dict = process.extractOne(text.lower(), stops)
if dict[1] > 75:
text = dict[0]
else:
text = np.nan
print("wait")
return text
def get_category_dataset(data):
"""преобразуем сообщение в каждом комментарии в остановку"""
print("remap started. wait")
data.text = data.text.map(lambda comment: get_category_from_comment(str(comment)))
print("remap ends")
data.dropna(inplace=True)
data["text"] = data.text.map(lambda s: "университет" if s=="скорина" else s)
data["text"] = data.text.map(lambda s: "университет" if s=="ггу" else s)
data["text"] = data.text.map(lambda s: "площадь ленина" if s=="площадь" else s)
data["text"] = data.text.map(lambda s: "площадь ленина" if s=="ленина" else s)
return dataВывод данных
Теперь мы можем предположить где в данный час скорее всего будут находиться контролёры.
Ищем в получившихся данных записи за определенный час и день недели. Например, за вторник, 9 часов утра:
data[(data["day_in_week"] == day) & (data["hour"] == hour)]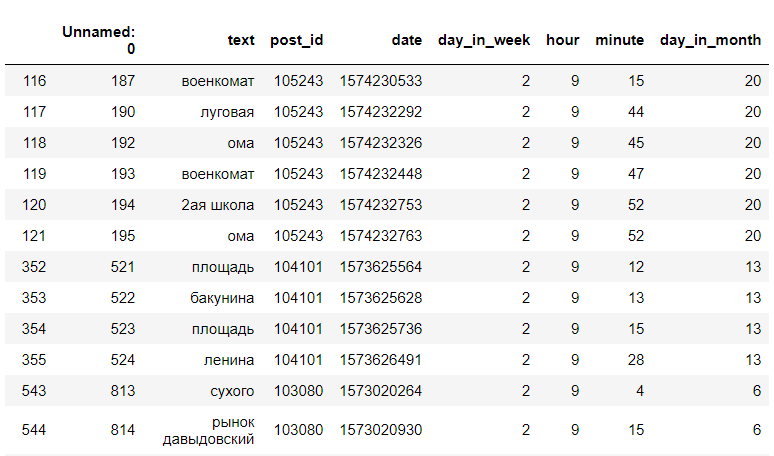
(это не все данные)
После этого находим количество уникальных остановок, и выводим только остановки, и их количество:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()
Теперь мы можем сказать, что в 9 часов утра, по вторникам, контролёры скорее всего будут замечены на остановках Мясокомбинат, ул. Луговая, БелГУТ, ТД «Ома».
Главный изъян этого метода — недостаток данных. Не для всех дней и часов есть записи в комментариях, данных в час-пик, когда люди больше пользуются общественным транспортом гораздо больше, чем данных в менее популярные часы, однако если добавить данные, например, не только из комментариев одной группы, но ещё и из альтернативных групп, или телеграм-чатов, с количеством записей всё станет проще.
Бот с VK LongPoll API
Чтобы дать возможность получать данные о местоположении контролёров, в зависимости от времени, и без привязки к компьютеру, я сделал бота для группы во ВКонтакте, который отвечает на любое сообщение, высылая количество остановок в записях, учитывая текущий час и день недели.
from random import randint
import vk_api
from requests import *
from get_stops_from_data import get_stops_by_time
def start_bot(data, token):
vk_session = vk_api.VkApi(token=token)
vk = vk_session.get_api()
print("bot started")
longPoll = vk.groups.getLongPollServer(group_id=183524419)
server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts']
while True:
# Последующие запросы: меняется только ts
longPoll = post('%s' % server, data={'act': 'a_check',
'key': key,
'ts': ts,
'wait': 25}).json()
if longPoll['updates'] and len(longPoll['updates']) != 0:
for update in longPoll['updates']:
if update['type'] == 'message_new':
# Помечаем сообщение от этого пользователя как прочитанное
vk.messages.markAsRead(peer_id=update['object']['user_id'])
user = update['object']["user_id"]
text = get_stops_by_time(data)
if text is None or text == {}:
message = "íåò çàïèñåé"
vk.messages.send(user_id=user, random_id=randint(-2147483648, 2147483647),
message=message)
print(message)
ts = longPoll['ts']
continue
message = "чем больше частота - тем больше шанс встретить контролёра\n" \
"\nостановка частота\n"
for i in text.items():
message += i[0] + " "
message += str(i[1])
message += "\n"
# Отправляем форматированое сообщение
vk.messages.send(user_id=user, random_id=randint(-2147483648, 2147483647),
message=message)
ts = longPoll['ts']Заключение
Качество подобных гипотез была проверена мною на практике не 1 раз, и всё вполне работает. Оказалось, контролёры, в основном, стоят на одних и тех же остановках, хотя абсолютно верных прогнозов давать нельзя, и вероятность успеха не 100%. У расстояния Левенштейна ещё десятки различных применений, от исправления ошибок в слове, до сравнения генов, хромосом и белков, но и в таких прикладных задачах у него вполне есть потенциал.
Удачного дня, и платите за проезд.
Весь код бота и работы с данными опубликован тут.
