[Из песочницы] Расширение функциональных возможностей Splunk – это просто

Меня зовут Ткачев Константин, я работаю архитектором прикладных решений.
Хочу рассказать о том, как можно расширить имеющуюся функциональность платформы Splunk на примере библиотеки для машинного обучения scikit-learn (sklearn), реализованной в Python. В нашем примере мы будем использовать алгоритм «деревьев решений». Данный алгоритм не входит в стандартную поставку Splunk и ниже я покажу, что подключить его для реализации прикладной задачи можно, выполнив достаточно простые действия.
Итак, сначала определимся с целями работ. Цель: определить пути расширения функциональных возможностей Splunk для решения индивидуальных прикладных задач. При этом, что немаловажно, мы хотим:
- использовать Splunk в качестве источника данных;
- а также выводить результаты наших расчетов в интерфейс Splunk.
Реализацию работ будем выполнять с использованием Python. Выбор был сделан в пользу Python, т.к. он входит в стандартную поставку Splunk и является одним из самых распространенных языков программирования, используемых в области машинного обучения. Кроме того, этот язык программирования входит в подавляющее большинство дистрибутивов Linux и MacOS.
В качестве возможных прикладных задач предлагаю рассмотреть следующие варианты:
1. Классификация клиентов в зависимости от параметров:
a. Время последнего посещения клиентом торговых точек ритейлера. Назовем этот параметр — R (Recency).
b. Частота покупок клиента в торговых точках ритейлера. Назовем этот параметр — F (Frequency).
Дано:
Имеется зависимость (закон распределения) времени последнего визита R (recency) от частоты покупок F (frequency).
В соответствии с данным законом распределения, клиенты разделены на три категории: «Перспективные», «Нормальные», «Неперспективные».
Задача:
Необходимо определить категорию клиента на основании данных о времени его последнего визита R (recency) и частоты покупок F (frequency) для тех клиентов, у которых категория не задана.
2. Классификация состояния платежного шлюза в зависимости от параметров: время суток (периодичность — 1 час), количество запросов в час.
Дано:
Имеется зависимость (закон распределения) количества запросов на платежный шлюз в час от времени суток (с группировкой по часам).
В соответствии с данным законом распределения, состояние может быть: «Спокойное», «Нормальное», «Критическое».
Задача:
Необходимо определить состояние платежного шлюза на основании информации о времени суток и количестве запросов в час для тех значений, у которых состояние неизвестно.
Реализация задачи классификации, разумеется, может быть выполнена и другими методами. Наша цель — показать, как просто и быстро дополнить функциональность Splunk своими алгоритмами. В частности, используя классификацию метода «деревья решений».
Описание подхода
Напомню, что в состав Splunk«а входит интерпретатор Python, который используется для разработки собственных поисковых команд языка SPL (Splunk Processing Language), и Python SDK для взаимодействия с API Splunk.
Одна из основных идей реализации состоит в том, чтобы «отделить» выполнение Вашего собственного алгоритма от интерпретатора Python, который входит в состав Splunk«а. Для этого мы реализуем два отдельных модуля Python:
1. «Модуль-обертка», который будет использоваться Splunk«ом (точнее его Python интерпретатором). Функции данного модуля:
a. Реализация Вашей поисковой команды Splunk SPL;
b. Организация взаимодействия со Splunk и модулем, который реализует Ваш уникальный алгоритм.
2. Модуль, в котором будет реализовано выполнение Вашего уникального алгоритма. Для исполнения данного модуля будет использоваться Ваша системная инсталляция Python«а.

Достоинства и недостатки данного подхода приведены ниже.
Достоинства:
— Снижение «сильной» связанности Splunk«а и Вашего алгоритма, за счет отдельной реализации «модуля-обертки», выполняющего обработку Вашей команды SPL, и модуля, реализующего Ваш алгоритм.
— Можно отдельно от Splunk выполнять разработку и тестирование Ваших алгоритмов в рамках Вашего системного Python.
— Обновление Splunk«а не будет влиять на функционирование Вашего алгоритма.
— Splunk не будет «перегружен» специфическими библиотеками Python.
Недостатки:
— Небольшая избыточность кода, которая необходима для взаимодействия между модулями. Необходимость в выполнения дополнительных преобразований с данными, которые передаются между модулями в качестве параметров (аргументов).
— Возможное снижение производительности общего решения, связанное с дополнительными преобразованиями данных, используемых в качестве параметров (аргументов).
В дальнейшем, возможно, я подключу необходимые внешние библиотеки в интерпретатор Python, используемый Splunk«ом.
Шаги реализации
Условия и ограничения
1. Пример реализации приведен для ОС Ubuntu.
2. Выполнение задачи мы будем осуществлять в рамках стандартного приложения Splunk — «Search & Reporting». В моем случае необходимые для выполнения файлы будут располагаться по следующему пути — »/opt/splunk/etc/apps/search».
Настройка системного Python
В качестве «отправной точки» настроим нашу системную среду Python, в которой будет выполняться наш уникальный алгоритм. Для этого импортируем необходимые библиотеки. Напомню, что в нашем случае мы используем алгоритм «деревьев решений». В Ubuntu это можно выполнить с помощью команды apt-get. Пример, который я использовал, приведен ниже.
apt-get install python-numpy python-scipy python-pandas
В итоге я получил подготовленную среду системного Python для реализации алгоритма классификации с использованием «деревьев решений».
Настройка Splunk
Все настройки Splunk заключаются в создании/доработке конфигурационного файла commands.conf. В данном файле необходимо указать имя команды Splunk и «модуль-обертку» Python, который будет реализовывать данную команду. Конфигурационный файл необходимо расположить в папке »/opt/splunk/etc/apps/search/local».
Разработка модулей Python
Здесь я приведу краткое описание работы и требования к исходным форматам данных. Запуск модулей инициируется из Splunk, путем вызова команды »|dtree», на вход которой должна быть передана следующая структура: X, Y, Class. Где X и Y — закон распределения (см. примеры в разделе «Описание прикладной задачи»), Class –классификация. Обучение модели осуществляется на имеющихся значениях поля «Class», затем модель определяет классификацию для записей с пустыми значениями поля Class. Вызов команды »|dtree» в Splunk, запускает соответствующий «скрипт-обертку» (dtree.py), который, в свою очередь, вызывает скрипт с реализацией алгоритма классификации (dtree_lib.py).
Код «модуля-обертки» и модуля, который реализует Ваш алгоритм, приведены в «Приложение».
Необходимо отметить, что код не содержит необходимых конструкций для управления исключительными ситуациями, обработки ошибок и т.д. В примерах приведены минимально необходимые действия для демонстрации подхода.
Перезагрузка Splunk
По завершении указанных выше шагов необходимо перезагрузить Splunk. После этого мы можем перейти к использованию созданной нами команды.
Для использования созданной нами команды необходимо в поисковой строке Splunk«а набрать имя нашей команды — »|dtree», предварительно подготовив для нее данные.
В качестве исходных данных можно использовать результаты поискового запроса Splunk. В итоге на «вход» нашей команде необходимо подать формат данных, который указан в разделе «Разработка модулей Python».
Я заранее подготовил исходные данные в csv-файле. Они представлены ниже в табличном виде и в виде графика распределения.
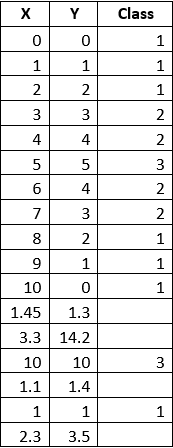
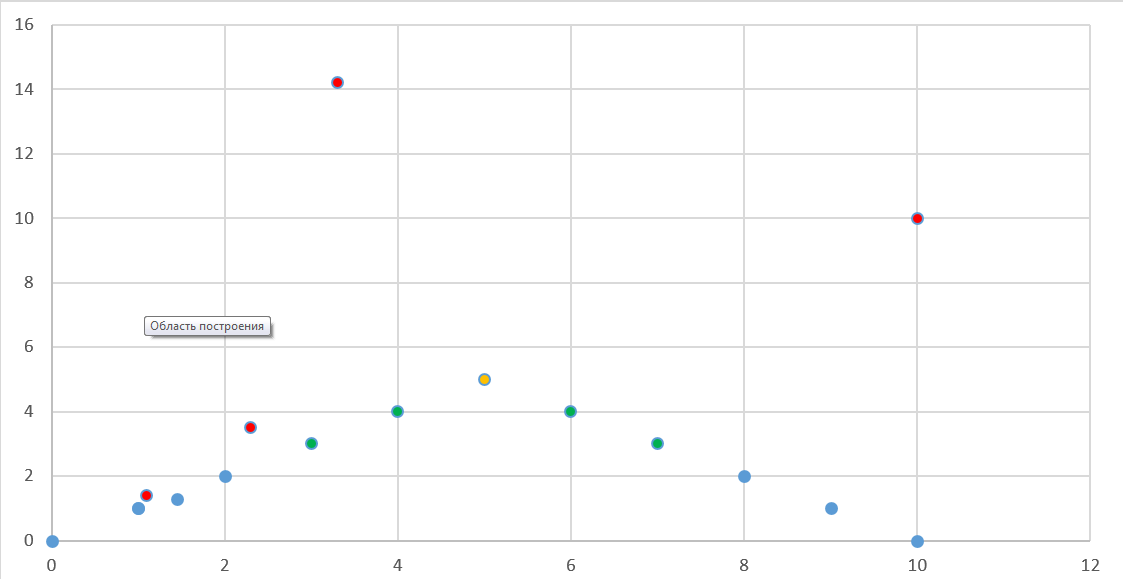
Для пустых значений поля «Class» (на графике — красные точки) мы будем определять классификацию методом «деревья решений».
Для просмотра данных в Splunk необходимо выполнить команду »|inputlookup dtree.csv». Предварительно csv-файл был помещен в папку »/opt/splunk/etc/apps/search/lookups».

График распределения, построенный Splunk«ом ниже.

Выполняем наш алгоритм запуском команды »|inputlookup dtree.csv|dtree». Результат ее работы представлен ниже. Определен класс (см. поле «Predicted») для тех X и Y, у которых поле «Class» было не заполнено.

Дополнительно хочу отметить имеющиеся возможности Splunk в области Machine Learning. Splunk содержит богатую библиотеку команд для выполнения функций прогнозной аналитики и машинного обучения:
> корреляция;
> кластеризация (k means, cluster);
> ассоциативные правила;
> классификация и прогнозирование (байесовская классификация, линейная и логистическая регрессии, SVM);
> поиск аномалий;
> метод главных компонент (PCA).
Некоторые из команд я привел в таблице ниже.
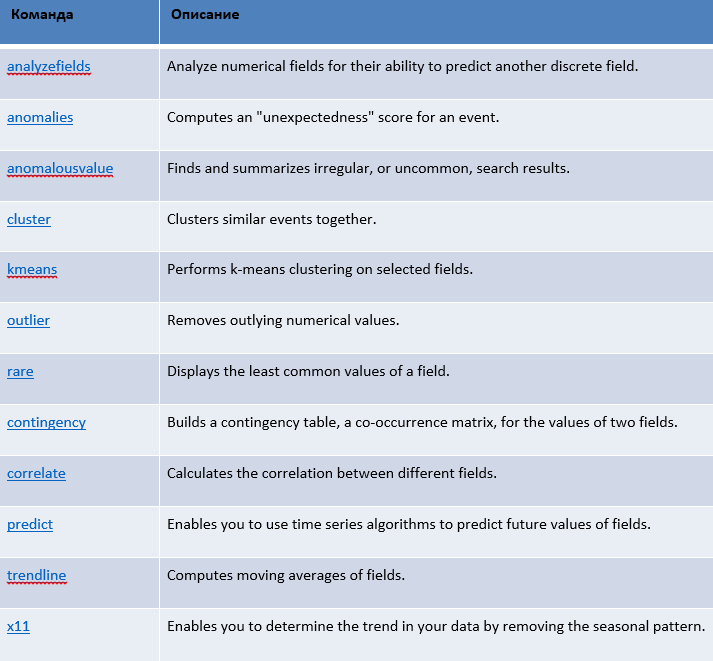
Так же доступно приложение — ML Toolkit and Showcase, которое в удобном интерфейсе предоставляет пользователям возможности выполнения функций машинного обучения, а так же содержит набор готовых примеров.

Спасибо за внимание. Надеюсь, что данная статья будет для вас полезной. Ссылка на видео по данной публикации — www.youtube.com/watch? v=uVPaLWbXW1E&feature=youtu.be.
commands.conf
Содержимое файла commands.conf приведено ниже.
[dtree]
type = python
filename = dtree.py
generating = false
streaming = false
retainsevents = false
Исходные коды
«Модуль-обертка» (dtree.py)
import os
import sys
import subprocess
import splunk.Intersplunk
#---Get data from Splunk---
results,unused1,unused2 = splunk.Intersplunk.getOrganizedResults()
#---Prepare data---
str_X=""
str_Y=""
str_Class=""
predict_X=""
predict_Y=""
cnt=0
delim=""
for result in results:
if result["Class"]=="":
predict_X=predict_X+","+result["X"]
predict_Y=predict_Y+","+result["Y"]
else:
if cnt>=1: delim=","
str_X=str_X+delim+result["X"]
str_Y=str_Y+delim+result["Y"]
str_Class=str_Class+delim+result["Class"]
result["new_X"] = str_X
result["new_Y"] = str_Y
result["new_Class"]=str_Class
cnt=cnt+1
#---Call python module with required functionality
_NEW_PYTHON_PATH = '/usr/bin/python'
os.environ['PYTHONPATH'] = '/opt/splunk/lib/python2.7'
_SPLUNK_PYTHON_PATH = os.environ['PYTHONPATH']
os.environ['PYTHONPATH'] = _NEW_PYTHON_PATH
my_process = os.path.join(os.getcwd(), '/home/konstantin/Documents/dtree_lib.py')
p = subprocess.Popen([os.environ['PYTHONPATH'], my_process, _SPLUNK_PYTHON_PATH,str_X,str_Y,str_Class,predict_X,predict_Y],
stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
output = p.communicate()[0]
#---Print results---
#splunk.Intersplunk.outputResults(results)
print output
Модуль с реализацией алгоритма «деревьев решений» (dtree_lib.py)
import sys
from sklearn import tree
#---Get data---
X=sys.argv[2]
Y=sys.argv[3]
Class=sys.argv[4]
predict_X=sys.argv[5]
predict_Y=sys.argv[6]
#---Prepare data---
X=X.split(",")
Y=Y.split(",")
Class=Class.split(",")
predict_X=predict_X.split(",")
predict_Y=predict_Y.split(",")
predict=list(zip(predict_X,predict_Y))
new_X=list(zip(X,Y))
new_Y=Class
#---Call Machine Learning function---
clf = tree.DecisionTreeClassifier()
clf = clf.fit(new_X, new_Y)
result=clf.predict(predict[1:])
#---Print results---
print '{},{},{}'.format("Predicted","X","Y")
for line,(x,y) in zip(result,predict[1:]):
print '{},{},{}'.format(line, x, y)
