[Из песочницы] Простейший тренажер английских слов с использованием Питона и Балаболки
Существует большое количество различных методик изучения иностранных языков вообще и английского в частности. Но какая бы методика ни была, учить слова все равно надо.
Для этих целей есть очень много различных тренажеров с выбором слов для изучения. Тем не менее, их возможностей иногда не хватает.
На одном из таких тренажеров я уже изучила достаточное количество слов. И столкнулась с одной проблемой. Тренажер предлагает русское слово, в ответ нужно написать это слово на английском, диктор (на самом деле синтезатор речи) потом озвучивает английский вариант. Все слова я пишу отлично, однако, когда я вижу английский текст, я помню только то, что я это слово учила, но не помню, что оно означает. То есть я поняла, что мне не хватает узнаваемости слов.
Еще один недостаток выбранного тренажера заключается в том, что для ввода предлагаются пустые позиции, в которые надо вводить буквы, и у меня всегда есть подсказка сколько букв должно быть в слове, а это не спортивно.
Исходя из этих соображений, я поняла, что я хочу сделать свой тренажер для повторения изученных мною слов. Этот тренажер должен быть англо-русским по направлению перевода и с озвучкой английского текста, чтобы тренировать аудирование.
Порядок решения задачи был следующим:
- Я подготовила csv файл из двух столбцов: 'word' и 'translate', в который включила все нужные мне слова.
- Я скачала консольную версию Балаболки — известной бесплатной программы tts (text-to-speach), предназначенной для озвучки любого текста как из файла, так и из буфера обмена.
- Написала работающий код в Jupiter Notebook под операционкой Windows 10.
К использованию Балаболки я пришла не сразу. Сначала я хотела использовать библиотеку pyttsx3, но при инициализации пакета pyttsx3.init () вылетала куча ошибок, а при запуске pyttsx3.init ('dummy') не было звука. Пробиться через взаимное непонимание с этим пакетом мне не удалось, поэтому пришлось искать другие варианты, и с Балаболкой у меня получилось.
Код у меня получился такой:
import subprocess, clipboard
import pandas as pd
Стандартное начало. Если pandas знают все, то библиотеки subprocess и clipboard мне были незнакомы. Пакет subprocess обращается к консольной версии Балаболки, имитируя командную строку. Пакет clipboard позволяет скопировать текст в буфер обмена, откуда он будет прочитан синтезатором речи.
words = pd.read_csv ('C:/.../Python_Scripts/words.csv', delimiter=';')
words.head()
Читаю подготовленный csv файл со словами и переводом.
words.shape
А еще я всегда контролирую значения переменных, что в них и как записалось.
words1 = words.sample(frac=1)
words1.head()
Перемешиваю слова в файле как карточки, чтобы не запоминать последовательность слов.
words10 = words1.iloc[0:100]
Иногда не хватает времени пройтись по всему файлу слов целиком и здесь можно ограничить количество повторяемых слов.
for i in range (len (words10)):
path = r'C:\...\balcon\balcon.exe'
flag = ' -n Slt -s -3 -c'
clipboard.copy (words10['word'].iloc[i])
subprocess.Popen(path + flag, creationflags=0, close_fds = True)
print ("\033[1m {}\033[0m" .format(words10['word'].iloc[i]))
tr = input ()
print ("\033[1m {}\033[0m" .format(words10['translate'].iloc[i]))
res = words10['translate'].iloc[i] == tr
if res == True:
print("\033[1m\033[36m {}\033[0m" .format('ОК'))
else:
print("\033[1m\033[31m {}\033[0m" .format('ОШИБКА'))
i = +1
Сам текст программы.
В переменной path я вызываю консольную версию Балаболки, файл balcon.exe.
Консоль имеет свои параметры вызова, записанные в переменную flag.
Конкретно здесь я использую:
- бесплатный голос -n Slt (он скачан у разработчика голосовых синтезаторов Ольги Яковлевой, я подбирала с английский голос нужной мне четкостью произношения и, на самом деле, голос может быть любым другим)
- скорость произношения -s -3 (этот параметр означает замедление скорости произношения -3 от стандартного)
- чтение из буфера обмена -c (Балаболка умеет читать текст как из файла, так и из буфера обмена; я выбрала буфер обмена, т.к. создавать тысячи файлов со словами ужасная затея).
Результат работы программы выглядит так:
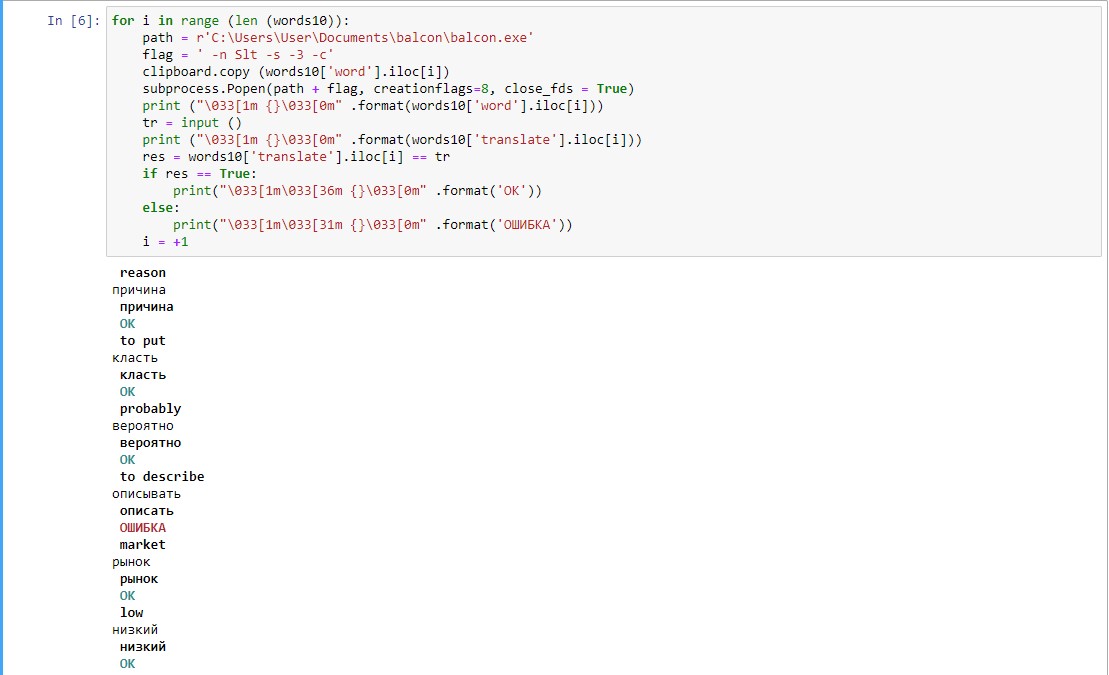
Изначально длинная «колбаса» вывода без выделения текста выглядела совершенно нечитаемо (сначала слово на английском, потом введенный мною ответ, потом вывод правильного перевода, потом результат сравнения исходного варианта и введенного, итого четыре строки на одно слово). Это сильно затрудняло анализ ошибок. Пришлось использовать ANSI коды, чтобы потом можно было быстро найти те слова, где я ошиблась.
Этот простейший тренажер не претендует на оригинальность. Создано большое количество более продвинутых программ, но для решения моей собственной локальной задачи меня этот результат устраивает. Я могу его контролировать от начала и до конца. Скрипт можно модифицировать, убрать написание английского слова, оставить только голос и тренировать аудирование. Также можно поменять направление перевода и тренировать написание английских слов, которого мне оказалось мало в исходном тренажере, и с которого и началась вся эта история.
Буду рада, если этот простой скрипт поможет людям, не владеющим сильными навыками программирования, сделать свой тренажер или реализовать на основе этого кода что-то иное.
