[Из песочницы] Программный модуль оцифровки поврежденных документов
Оптическое распознавание символов (OCR) — это процесс получения печатных текстов в оцифрованном формате. Если вы прочитали классический роман на цифровом устройстве или попросили врача поднять старые медицинские записи через компьютерную систему больницы, вы, вероятно, воспользовались OCR.
OCR делает ранее статический контент доступным для редактирования, доступным для поиска и для обмена. Но многие документы, стремящиеся к оцифровке, содержат кофейные пятна, выцветшие солнечные пятна, страницы с загнутыми уголками и множество морщин сохраняют некоторые печатные документы в не оцифрованном виде.
Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах. Использование этих книг запрещено по причине их ветшалости и дряхлости, и поэтому оцифровка этих книг столь важна.
В работе рассматривается задача очистки текста от зашумленности, распознавание текста на изображении и конвертации его в текстовый формат.

Для обучения использовалось 144 картинки. Размер может быть разным, но желательно должен быть в пределах разумного. Картинки должны иметь формат PNG. После считывании изображения используется бинаризация — процесс преобразования цветного изображения в черно-белое, то есть каждый пиксель нормализуется в диапазон от 0 до 255, где 0 — это черный, 255 — белый.
Чтобы обучить сверточную сеть, нужно больше изображений, чем имеется. Было принято решение разделить изображения на части. Так как обучающая выборка состоит из картинок разного размера, каждое изображение было сжато до 448×448 пикселей. В результате получилось 144 изображения в разрешении 448×448 пикселей. После чего все они были нарезаны на неперекрывающиеся окна размером 112×112 пикселей.

Таким образом из 144 первоначальных изображений было получено порядка 2304 изображений в обучающей выборке. Но и этого было недостаточно. Для хорошего обучения сверточной сети необходимо больше примеров. В следствии этого, лучшем вариантом было повернуть картинки на 90 градусов, затем на 180 и 270 градусов. В результате на вход сети подается массив с размером [16,112,112,1]. Где 16 — это количество изображений, 112 — ширина и высота каждого изображения, 1 — цветовые каналы. Получилось 9216 примеров для обучения. Этого достаточно для обучения сверточной сети.
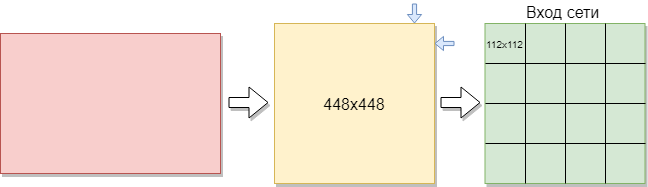
Каждое изображение имеет размер 112×112 пикселей. Если размер будет слишком велик, то вычислительная сложность повысится, соответственно ограничения на скорость ответа будут нарушены, определение размера в данной задаче решается методом подбора. Если выбрать размер слишком маленький, то сеть не сможет выявить ключевые признаки. Каждое изображение имеет черно-белый формат, поэтому разбивается на 1 канал. Цветные изображения разбиваются на 3 канала: красный, синий, зеленый. Так как у нас черно-белые изображения, то размер каждого изображения 112×122х1 пикселей.
Первым делом необходимо обучить сверточную нейронную сеть на заготовленных, обработанных изображениях. Для этой задачи была подобрана архитектура U-Net.
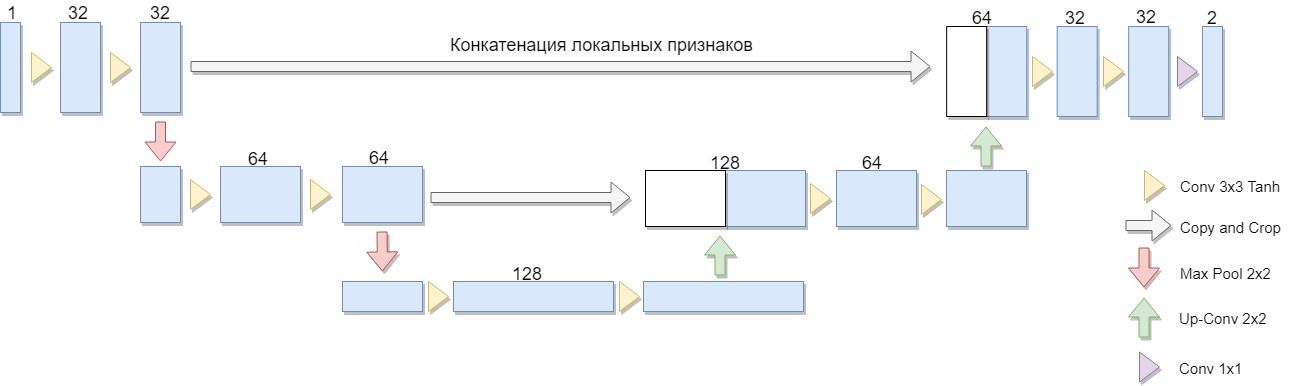
Была выбрана уменьшенная версия архитектуры, состоящая всего из двух блоков (оригинальная версия из четырёх). Важным соображением было и то, что большой класс известных алгоритмов бинаризации явно выразим в такой архитектуре или подобной архитектуре (в качестве примера можно взять модификацию алгоритма Ниблэка с заменой среднеквадратичного отклонения на средний модуль отклонения, в этом случае сеть строится особенно просто).
Преимущество такой архитектуры состоит в том, что для обучения сети можно создать достаточное количество обучающих данных из небольшого числа исходных изображений. При этом сеть имеет сравнительно малое число весов за счет своей сверточной архитектуры. Но есть и свои нюансы. В частности, используемая искусственная нейронная сеть, строго говоря, не решает задачу бинаризации: каждому пикселю исходного изображения она ставит в соответствие некоторое число от 0 до 1, которое характеризует степень принадлежности данного пикселя к одному из классов (содержательное заполнение или фон) и которое необходимо еще преобразовать в финальный бинарный ответ. [1]
U-Net состоит из сжимающего и разжимающего пути и «пробросов» между ними. Сжимающий путь, в данной архитектуре, состоит из двух блоков (в оригинальной версии из четырёх). В каждом блоке по две свертки с фильтром 3×3 (с использованием функции активации Tanh после свёртки) и пулинга с размером фильтра 2×2 с шагом 2. Количество каналов на каждом шаге вниз удваивается.
Разжимающий путь также состоит из двух блоков. Каждый из них состоит из «развёртки» с размером фильтра 2×2, сокращающий в два раза количество каналов, конкатенации с соответствующей обрезанной картой признаков со сжимающего пути («проброс») и двух свёрток с фильтром 3×3 (с использованием функции активации Tanh после свёртки). Далее, на последнем слое свёртка 1×1(с использованием функции активации Sigmoid) для получения выходного, плоского изображения. Заметим, что обрезание карты признаков при конкатенации существенно в силу потери граничных пикселей при каждой свёртке. В качестве метода стохастической оптимизации был выбран Adam.
В общем архитектура представляет собой последовательность слоев свёртка+пулинг, которые уменьшают пространственное разрешение картинки, после этого увеличивают его, заранее объединив с данными картинки и пропустив через другие слои свёртки. Таким образом, сеть выполняет роль своеобразного фильтра. [2]
Тестовая выборка состояла из аналогичных изображений, отличия были только в текстуре зашумления и в тексте. Тестирование сети происходило на этом изображении.

На выходе сверточной нейронной сети получается массив из чисел с размером [16,112,112,1]. Каждое число — это отдельный пиксель, обработанный сетью. Изображения имеют формат 112×112 пикселей, так как раньше, она была разрезана на части. Ей необходимо предать первоначальный вид. Объединяем полученные изображения в одну часть, в результате картинка имеет формат 448×448. Далее каждое число в массиве умножаем на 255, чтобы получить диапазон от 0 до 255, где 0 — это черный, 255 — белый. Возвращаем изображению первоначальный размер, так как раньше, она была сжата. В результате получается картинка ниже на рисунке.

В данном примере видно, что сверточная сеть справилась с большинством зашумлений и проявила себя работоспособно. Но хорошо заметно, что картинка стала мутнее и видны пропущенные шумы. В будущем, это может повлиять на точность распознавания текста.
Опираясь на этот факт, было принято решение использовать еще одну нейронную сеть — многослойный перцептрон. В ожидаемом результате сеть должна делать текст на изображении четче и убирать пропущенные сверточной нейронной сетью зашумления.
На вход многослойного перцептрона посылается изображение, уже обработанное сверточной сетью. В этом случае обучающая выборка для этой сети будет отличаться от выборки для сверточной сети, так как сети обрабатывают изображение по-разному. Сверточная сеть считается основной сетью и убирает большинство шумов на изображении, при этом многослойный перцептрон обрабатывает то, с чем не справилась сверточная.
Вот несколько примеров из обучающей выборки для многослойного перцептрона.

Данные изображения были получены путем обработки обучающей выборки для сверточной сети многослойным перцептроном. При этом, перцептрон был обучен на этой же выборке, но на малом количестве примеров и небольшом количестве эпох.
Для обучения перцептрона было обработано 36 изображений. Обучение сети происходит попиксельно, то есть на вход сети посылается по одному пикселю из изображения. На выходе сети получаем тоже один выходной нейрон — один пиксель, то есть ответ сети. Для увеличения точности обработки было сделано 29 входных нейронов. И на изображение, полученное после обработки сверточной сетью, наложено 28 фильтров. В результате получится 29 изображений с разными фильтрами. Посылаем на вход сети по одному пикселю из каждого 29 изображения и на выходе сети получает только один пиксель, то есть ответ сети.
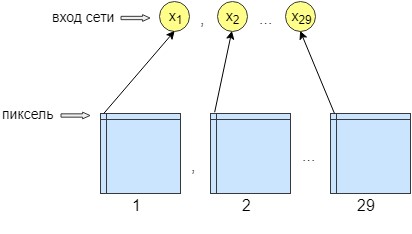
Это было сделано для лучшего обучения и работы сети. После этого сеть стала увеличивать точность и контрастность изображения. Также она очищает мелкие погрешности, которая не смогла очистить сверточная сеть.
В результате нейронная сеть имеет 29 входных нейронов, по одному пикселю из каждого изображения. После экспериментов было выяснено что необходим всего один скрытый слой, в котором 500 нейронов. Выход у сети один. Так как обучение происходило попиксельно, к сети обращались n*m раз, где n — это ширина изображения, а m — соответственно высота.

После обработки изображения последовательно двумя нейронными сетями, осталось главное — это распознать текст. Для этого было взято уже готовое решение, а именно питоновская библиотека Pytesseract. Pytesseract не обеспечивает настоящей привязки к Python. Скорее, он является простой обёрткой для двоичного файла tesseract. При этом tesseract устанавливается отдельно на компьютер. Pytesseract сохраняет изображение во временный файл на диске, а затем вызывает двоичный файл tesseract и полученный результат записывает в файл.
Данная обертка разработана Google и является бесплатной и свободной в использовании. Она может использоваться как в своих, так и в коммерческих целях. Библиотека работает без подключения к интернету, поддерживает множество языков для распознавания и впечатляет своей скоростью. Ее применение можно найти в разных популярных приложениях.
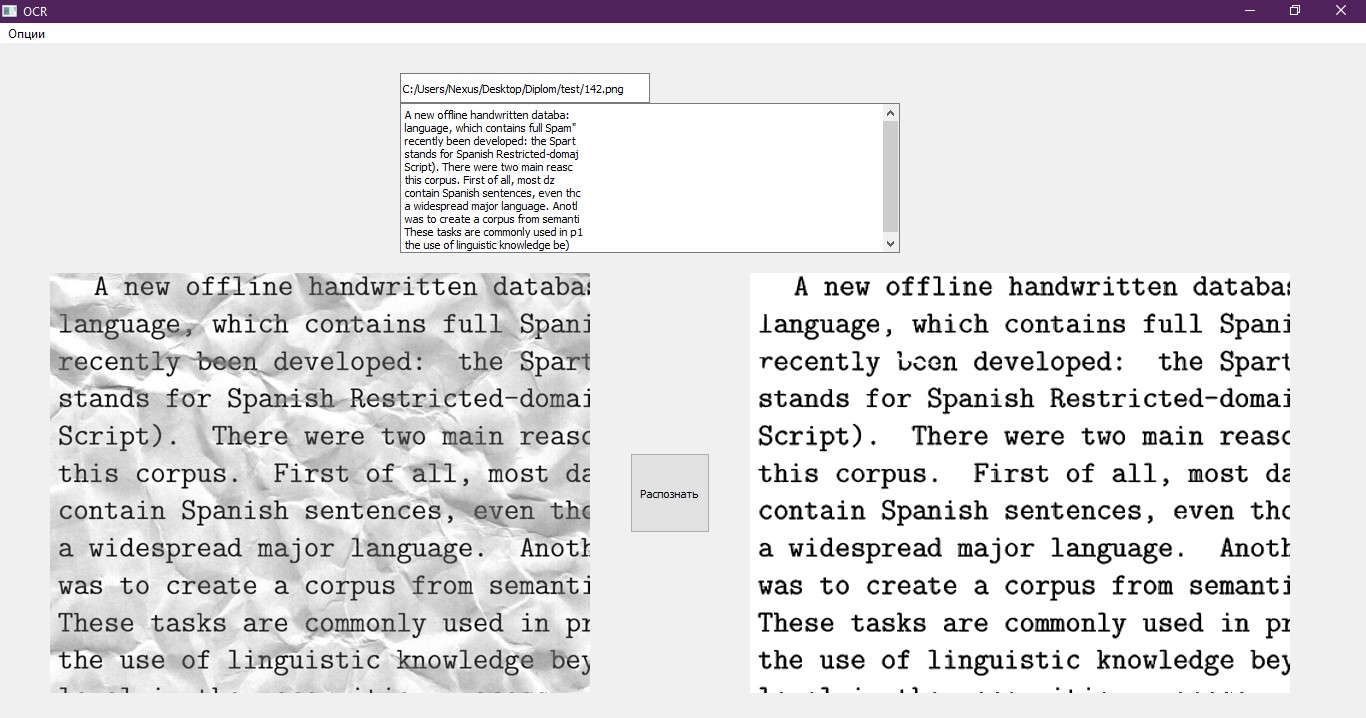
Последним пунктом осталось записать распознанный текст в файл в формате пригодном для его обработки. Используем для этого обычный блокнот, который открывается, после завершения работы программы. Также текст выводится на тестовый интерфейс. Наглядный пример интерфейса.
Список литературы:
- История победы на международном соревновании по распознаванию документов команды компании SmartEngines [Электронный ресурс]. Режим доступа: https://habr.com/company/smartengines/blog/344550/
- Сегментация изображений при помощи нейронной сети: U-Net [Электроный ресурс]. Режим доступа: http://robocraft.ru/blog/machinelearning/3671.html
> Репозиторий на github
