[Из песочницы] Приручение строптивого

Любите ли вы разрабатывать базы данных? Нет, не новомодные NoSQL, а старые добрые реляционные, где вы можете описывать отношения и хранимые процедуры для доступа к данным и логики. Может быть, вы разрабатываете базы данных для PostgreSQL? Если да, то отлично — этот пост определенно для вас.
Описывать преимущества PostgreSQL, пожалуй, смысла нет. Скажу лишь в двух словах, что это современная быстрая СУБД с богатыми возможностями, вполне способная конкурировать с коммерческими системами управления базами данных. То, что PostgreSQL распространяется под свободной лицензией, схожей с лицензией BSD (что позволяет использовать её без лицензионных отчислений в коммерческих проектах и открывает полный доступ к исходному коду без необходимости открывать свой в случае внесения изменений), и активно развивается в настоящее время (совсем недавно, в январе 2016 года вышла версия 9.5 с некоторыми крайне приятными улучшениями), позволяет утверждать, что PostgreSQL мог бы являться одной из лучших СУБД на сегодняшний день. Но что же мешает завоевать популярность в среде разработчиков PostgreSQL?
Одним из таких факторов является достаточно небольшое количество инструментов как для разработки баз данных, так и для дальнейшего сопровождения. Разумеется, для PostgreSQL есть JDBC драйвера, и с ним работают все те инструменты, которые используют JDBC, но эти инструменты, как правило, универсальны, и не всегда могут использовать особенности конкретной СУБД.
О каких особенностях разработки идет речь? Например, достаточно часто, когда вы модифицируете существующие объекты БД (как правило, таблицы или представления), вы можете столкнуться с ошибкой изменения объекта, поскольку это запрещено PostgreSQL, т.к. имеются зависимые объекты.
ags=# create table t1 (f1 text);
CREATE TABLE
ags=# create view v1 as select * from t1;
CREATE VIEW
ags=# alter table t1 alter column f1 type char(5);
ERROR: cannot alter type of a column used by a view or rule
ПОДРОБНОСТИ: rule _RETURN on view v1 depends on column "f1"
Подобная особенность уже надоела многим разработчикам, зафиксирована в TODO wiki.postgresql.org/wiki/Todo#Views_and_Rules и имеет некоторые возможные варианты решения (например: mwenus.blogspot.nl/2014/04/postgresql-how-to-handle-table-and-view.html).
Или вот ещё пример. Не случалось ли с вами подобного: вы создали хранимую процедуру, начали активно использовать её и через какое-то время, как это обычно бывает, захотели модифицировать. И лишь когда начнете разбираться с тем, почему логика частично работает, а частично нет, замечаете, что фактически вы создали дополнительную процедуру с новой сигнатурой (которую и использует часть кода), другая же часть кода использует случайно оставленную по недосмотру старую процедуру?
ags=# \df f1
Список функций
Схема | Имя | Тип данных результата | Типы данных аргументов | Тип
--------+-----+-----------------------+------------------------+---------
public | f1 | void | | обычная
public | f1 | void | p1 integer | обычная
(2 строки)
Столкнуться с подобной ситуацией очень просто, и этому способствует, на мой взгляд, отсутствие группирующих объектов наподобие пакетов Oracle, которые логически объединяют хранимые процедуры и накатываются на базу обычно одним пакетом, что исключает появление «забытых» объектов. Да, разумеется, если вы тестируете ваш код, то вероятность попадания подобных объектов в бой невелика, однако такое поведение увеличивает сложность сопровождения.
Что делать, если вы хотите сравнить две БД и сформировать скрипт преобразования одной в другую? Скорее всего, вы захотите воспользоваться Liquibase, однако будете неприятно огорчены, когда узнаете, что Liquibase ничего не знает про способы решения возникающих проблем с зависимостями, о которых я упомянул чуть раньше.
С подобными вопросами столкнулись и мы, когда примерно три года назад начали процесс миграции с MSSQL на PostgreSQL. В то время мы использовали Redgate SQL Source Control для работы с MSSQL и были ужасно раздосадованы отсутствием подобного инструмента для работы с PostgreSQL. Раздосадованы настолько, что приняли решение о создании собственного инструмента, способного отслеживать изменения в БД и создавать скрипты миграций выбранных объектов как в интерактивном, так и автоматическом режиме.
Поскольку мы программируем большей частью на Java, то решение о выборе платформы разработки пришло достаточно быстро. Приложение стало развиваться, спустя несколько итераций проб и ошибок, как набор дополнений Eclipse.
Именно так через какое-то время появился на свет наш продукт — pgCodeKeeper.
Если вкратце, то его работу можно описать следующим образом: объекты БД сохраняются на диск в виде проекта Eclipse, который в дальнейшем может (по желанию) быть помещен в систему хранения версий. Сравнив в дальнейшем БД с проектом или какой-либо из ветвей проекта, можно сформировать как скрипт миграции из БД (для переноса состояний объектов из проекта в БД), так и в обратном направлении. А в связи с тем, что для разбора объектов мы используем собственные грамматики ANTLR, это позволяет нам строить достаточно хорошо проработанные графы зависимостей объектов, что приводит к созданию корректных скриптов миграции (с учетом существующих проблем с зависимостями, которые были озвучены мной выше).
Использование pgCodeKeeper может помочь выстроить рабочий процесс [workflow] внесения изменений в БД. У себя мы успешно используем следующую схему:
- Разработчик вносит изменения в девелоперскую БД (при этом не задумываясь о создании скрипта миграции, который будет необходим при накате на боевую БД). Кстати, девелоперская БД может быть одна, разделенная между несколькими разработчиками. При применении изменений pgCodeKeeper позволяет переносить только выбранные объекты.
- Изменения (если необходимо, то изменения только части объектов), внесенные разработчиком при помощи pgCodeKeeper, переносятся в девелоперскую ветку проекта и создается запрос на объединение [merge request] с основной веткой.
- Запрос на объединение проверяется и принимается ответственным лицом.
- После принятия запроса на объединение pgCodeKeeper формирует скрипт миграции (при этом предупреждает, если в скрипте формируются инструкции, которые могут привести к потере данных) из основной ветки в боевую БД.
- Созданный скрипт накатывается на боевую БД.
Первые два пункта выполняются разработчиком, третий выполняются инспектором, четвертый и пятый может быть выполнен лицом сопровождающим БД. Четвертый и пятый пункты могут быть также выполнены в автоматическом режиме, и это может быть очень удобно для построения процессов непрерывной доставки [Continuous Delivery], но в рамках текущей статьи об этом говорить не будем.
В описанном рабочем процессе не все действия выполняется через pgCodeKeeper. Например, создание новой ветки в системе контроля версий выполняются дополнением EGit для Eclipse. В то время как проверку запроса на объединение кода [merge request code review] мы выполняем используя возможности GitLab.
Т.е. основная цель pgCodeKeeper — это сравнение предварительно созданного проекта с экземпляром базы данных, определение модифицированных объектов и применение изменений или в проект из БД (модификация файлов проекта) или в БД из проекта (через создание скрипта миграции).
Прошло время, начатый проект успешно развивался и в определенный момент не осталось сомнений, что с текущими требованиями по сопровождению наших внутренних БД продукт справляется превосходно, однако бэклог продукта [product backlog] отнюдь не пуст. А заполнен он теми фичами или ошибками, которые потенциально могут встречаться в базах данных других разработчиков. Стало понятно, что проект или останется в рамках корпоративного проекта (и, возможно, перейдет в стадию стагнации, т.к. текущие затребованные фичи выполнены практически все), или попытается выйти на публичный рынок и с помощью обратной связи получить ответы на следующие вопросы:
- Востребован ли продукт на текущий момент на рынке программного обеспечения?
- Если востребован, то какая модель распространения/лицензирования продукта может быть наиболее интересна как нам, так и рынку?
Сейчас мы готовы выпустить pgCodeKeeper в публичное бета-тестирование с единственным условием использования — предоставление фидбека. Есть ли желающие попробовать продукт в работе?
Пробуем в деле
Итак, я надеюсь, что если вы дочитали до этого момента, то уже достаточно заинтересованы, чтобы попробовать работу pgCodeKeeper в деле. Готовы? Приступаем.
Как я уже писал ранее, pgCodeKeeper в конце своего эволюционного пути стал представлять из себя набор дополнений для платформы Eclipse. А это значит, что с многоплатформенностью у него всё отлично, и работает он как под Linux, так и под Windows. Естественно, будет работать и под другими платформами, на которых может быть запущена платформа Eclispe, но мы используем только эти две.
Для корректной работы pgCodeKeeper требуется Eclipse платформа версии Juno или выше, впрочем, это замечание относится к тем, кто хочет установить в существующий экземпляр Eclipse. Для новых инсталляций Eclipse берите последнюю версию с сайта eclipse.org/downloads. Вы можете установить Eclipse IDE for Java Developers (т.к. в ней, помимо всего прочего, уже установлены дополнения для интеграции с Git и относительно небольшой размер), или же выбрать любой, который понравится вам (не забудьте: Eclipse — это Java приложение, и для его работы вы должны предварительно установить JRE/JDK).

Выбираем пункты меню Help — Install new software и вводим URL сайта обновлений: pgcodekeeper.ru/update/release
Выбираем и устанавливаем дополнение pgCodeKeeper. Перегружаем Eclispe и, если в списке визардов новых проектов видим проект pgCodeKeeper, то считаем миссию по установке завершённой.
Работа pgCodeKeeper сводится к сравнению объектов в проекте и БД, на момент создания проекта у вас уже должна быть БД, с которой вы хотите сделать начальный «слепок» проекта. Давайте создадим базу и попробуем пройтись по процессу разработки БД.
$ psql -X <
Ну что же, у нас есть база данных, пришло время поразвлечься и написать немного кода. Изменим таблицу t1:
(ags@10.84.0.6:5432) 15:12:28 [dev] =# alter table t1 alter column f1 type char(5);
ERROR: cannot alter type of a column used by a view or rule
ПОДРОБНОСТИ: rule _RETURN on view v1 depends on column "f1"
Время: 2,393 мс
Вполне ожидаемо — мы не можем выполнить запрашиваемое действие, т.к. от таблицы t1 зависит представление v1. Более того, для того чтобы удалить v1, нам придется удалить и v2 и f1.
(ags@10.84.0.6:5432) 15:16:05 [dev] * =# drop view v1;
ERROR: cannot drop view v1 because other objects depend on it
ПОДРОБНОСТИ: view v2 depends on view v1
function f1(integer) depends on type v2
ПОДСКАЗКА: Use DROP ... CASCADE to drop the dependent objects too.
Время: 1,631 мс
Да… похоже, мы в небольшой западне, теперь придется прибегать или к помощи чудо-скриптов (например, подобных тому, о котором я писал выше… правда, они работают далеко не со всеми объектами, которые могут попасть в граф зависимостей), или воспользоваться pgCodeKeeper (есть ещё вариант удалить представление и зависимые объекты каскадно и восстановить потом потерянные объекты из предварительно сохраненного дампа, но мы не будем пользоваться такой «возможностью»).
Самое время создать проект для сопровождения БД.
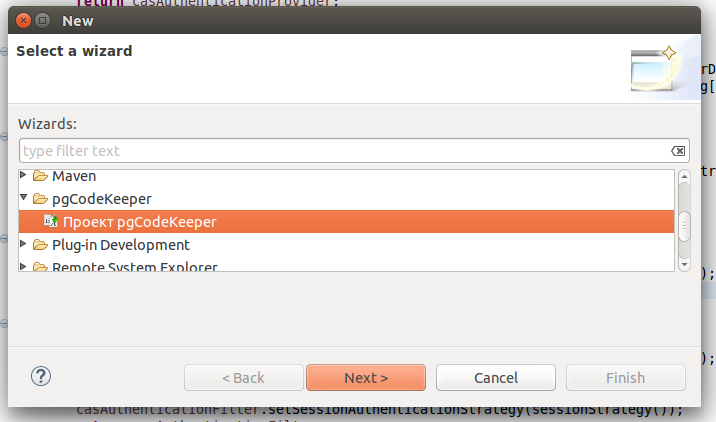
Вводим имя нового проекта:
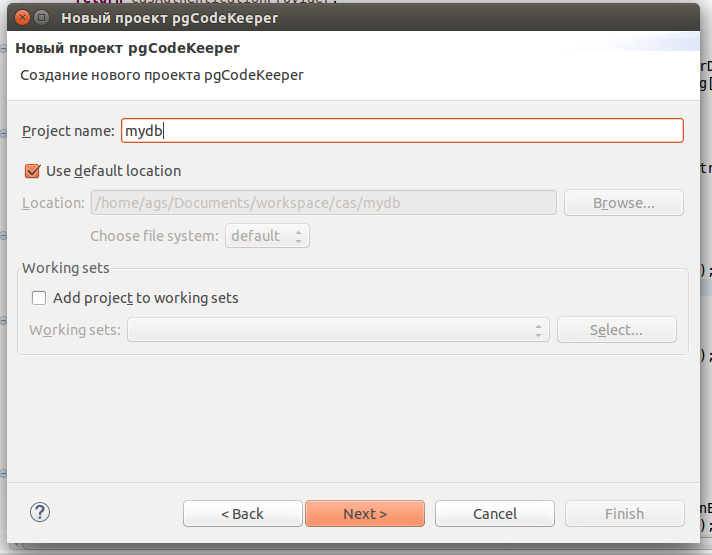
Настраиваем источник для БД (да, вы можете столкнуться с чуть неочевидным моментом добавления нового источника, но будьте терпеливы, мы обязательно это улучшим в будущем). Я лично пароли обычно храню в .pgpass и pgCodeKeeper умеет брать их из него, но если вы не пользуетесь, то заполните поле пароля в визарде.
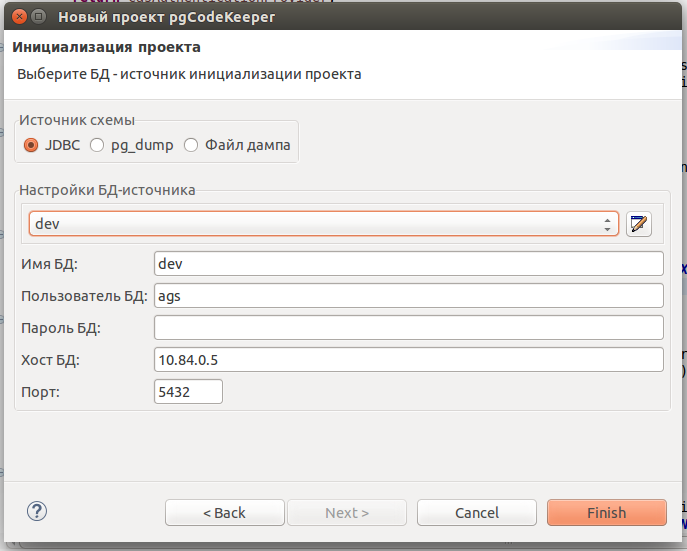
Создание проекта завершено, нажимайте кнопку «Finish». Если вы все сделали правильно, то будет инициализирован и заполнен объектами БД новый проект.

Объект БД в проекте — это удобочитаемый файл, который в том числе можно и отредактировать.
На текущий момент pgCodeKeeper не позиционируется как полноценный редактор SQL или PL/pgSQL кода, но порой — как, например, в данном случае, — нет ничего лучше, чем отредактировать файл непосредственно в редакторе. Давайте изменим тип единственного поля с text на char (5).

Перейдём на основную панель проекта (нижний таб — «Обновить БД») и нажмём кнопку «Получить изменения». pgCodeKeeper отобразил список объектов, которые отличаются как в БД, так и в проекте. Diff панель показывает детальные изменения в объектах БД.
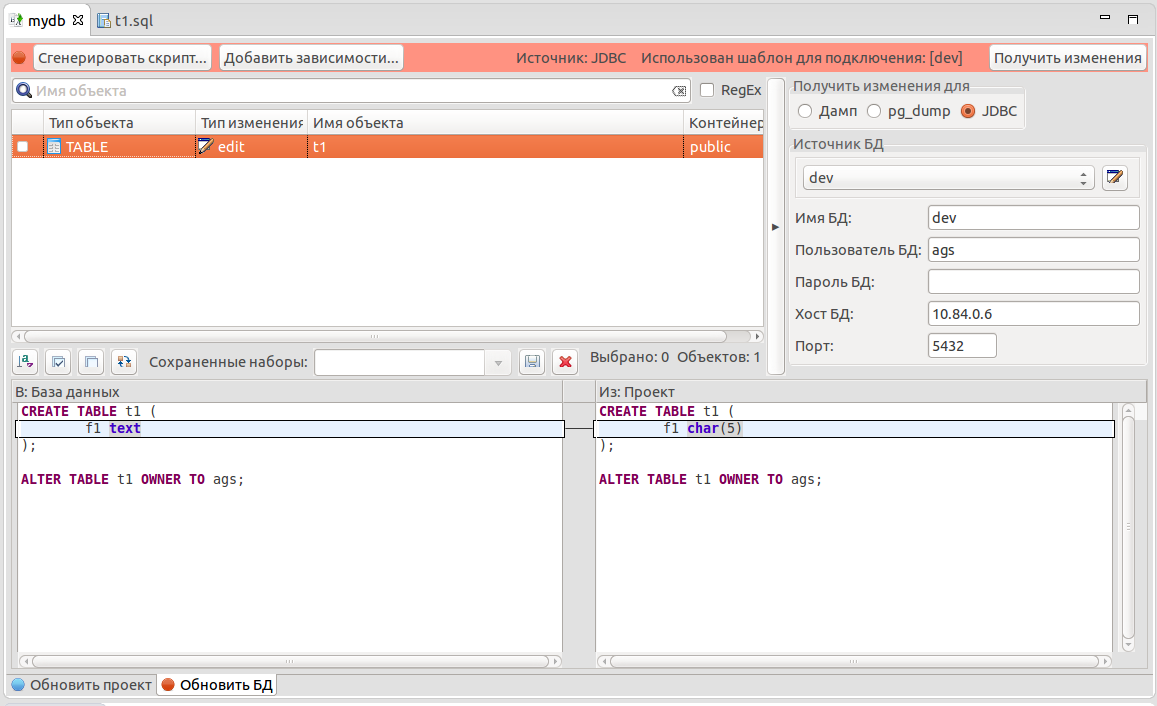
Ну, а теперь осталась самая малость, поставим галочку на объектах БД, которые мы хотим синхронизировать с объектами проекта и нажмем кнопку «Сгенерировать скрипт». pgCodeKeeper услужливо сообщит о том, что сгенерированный скрипт содержит опасные инструкции, которые могут привести к потере данных и сформирует следующий скрипт:
SET TIMEZONE TO 'UTC';
SET check_function_bodies = false;
-- DEPCY: This FUNCTION depends on the COLUMN: t1.f1
DROP FUNCTION f1(p1 integer);
-- DEPCY: This VIEW depends on the COLUMN: t1.f1
DROP VIEW v2;
-- DEPCY: This VIEW depends on the COLUMN: t1.f1
DROP VIEW v1;
ALTER TABLE t1
ALTER COLUMN f1 TYPE char(5); /* ТИП колонки изменился - Таблица: t1 оригинал: text новый: char(5) */
-- DEPCY: This VIEW is a dependency of FUNCTION: f1(integer)
CREATE VIEW v1 AS
SELECT t1.f1
FROM t1;
ALTER VIEW v1 OWNER TO ags;
-- DEPCY: This VIEW is a dependency of FUNCTION: f1(integer)
CREATE VIEW v2 AS
SELECT v1.f1
FROM v1;
ALTER VIEW v2 OWNER TO ags;
CREATE OR REPLACE FUNCTION f1(p1 integer) RETURNS v2
LANGUAGE sql
AS $$select * from v2 limit 1$$;
ALTER FUNCTION f1(p1 integer) OWNER TO ags;
Ура!!! Пара кликов мышкой (если не считать инициализации проекта) и мы можем формировать скрипты миграции! Полученный скрипт можно накатить как самостоятельно через pgAdmin/psql, так и через pgCodeKeeper. Поскольку в PostgreSQL инструкции DDL транзакционны, то я при накате подобных скриптов указываю о необходимости выполнения скрипта в одной транзакции (ключик -1 в psql), чтобы не допустить возникновения неконсистентного состояния БД, в случае, если возникнет ошибка во время выполнения скрипта.
Если сейчас повторно выполнить сравнение проекта и БД, то мы увидим, что объекты в проекте и БД… Отличаются?!
Без паники, это связано с тем, что, когда мы вносили изменения в проект руками, мы указали сокращенную форму типа character как char, в БД же он теперь отображается именно в полной форме.

Чтобы выполнить обновление проекта переключитесь на нижний таб «Обновить проект», нажмите «Получить изменения», выберите нужные объекты и нажмите на кнопку «Применить выбранные изменения». После выполнения этих действий объекты БД и проекта станут идентичными.
Известные особенности продукта
Поскольку продукт изначально разрабатывался под внутренние БД, то в первую очередь тестировались только те типы объектов, которые используем мы, некоторые пока не поддерживаются (например FOREIGN TABLE). pgCodeKeeper поддерживает работу не со всеми версиями PostgreSQL, на текущий момент гарантируется работа для версий 9.3 и выше (нужно проверить — возможно, что будет работать и с 9.1–9.2, но не более ранними).
Заключение
Сегодня вы познакомились с новым продуктом, облегчающим работу с PostgreSQL, я рассказал об основных возможностях продукта, не затронув такие темы как: ручное добавление зависимостей (если наш парсер не справился, то всегда можно подсказать ему), работа с системами контроля версий, работа pgCodeKeeper в автоматическом, неинтерактивном режиме.
В статье не обошлось без неологизмов, жаргонизмов или несколько устаревших оборотов речи, во всех случаях я указывал значение слова или выражения, при первом его употреблении, на английском языке наиболее точно определяющее его.
На текущий момент pgCodeKeeper проходит процесс регистрации в реестре отечественного ПО согласно Постановления Правительства РФ от 16 ноября 2015 г. N 1236 «Об установлении запрета на допуск программного обеспечения, происходящего из иностранных государств, для целей осуществления закупок для обеспечения государственных и муниципальных нужд» www.garant.ru/hotlaw/federal/671898 и это значит, что в ближайшем будущем pgCodeKeeper сможет участвовать в программе импортозамещения.
Использование pgCodeKeeper значительно облегчает сопровождение баз данных PostgreSQL (был даже замечен эффект привыкания).
Насколько интересным показался вам pgCodeKeeper?
