[Из песочницы] PHP парсинг от А до Я. Грабли и возможные решения

Поскольку на Хабре после лавины публикаций «N в 30 строк» в 2013-м г. почти не публикуются материалы по программированию, то скажу, что этот материал для домохозяек, желающих научиться программированию, тестировщиков и просто неравнодушных людей.
В современном мире микросервисов господствует API. Но сервисов с каждым днем все больше, а API предоставляют далеко не все. Между тем данные сервисов могут быть весьма важны для анализа, бизнеса, копирования и т.д.
Посмотрим, как можно распарсить один известный сайт объявлений о продаже/аредне недвижимости максимально эффективно (и быстро), научимся обходить качпу и парсить мобильные приложения.
Внимание. Данный материал не является призывом к действию, носит информационный характер с целью повышения квалификации и увеличения качества работы тестировщиков.
Теория
Парсинг — структурирование данных, если говорить коротко. Если рассматривать классическую схему работы любого сайта, то в любом случае у нас будет хранилище данных (база данных), которое будет иметь структурированный вид. Удобный для машин, но не удобный для человека. Но поскольку сайт должен обслуживать людей, а не машин, данные нужно перевести в удобный для человека вид, но уже не очень удобный для чтения машинами. Схематично это можно изобразить так:
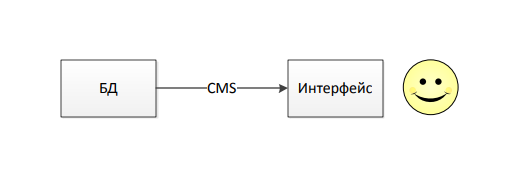
Всё это сферический конь в вакууме, и может быть не очень интересно, пока вдруг Вы не захотите прилично сэкономить, купив квартиру по методу линейной регрессии и Вам понадобятся данные не в няшном виде на сайте, а в конкретной SQL-таблице. А для этого нужно собрать данные.
Парсим на PHP
Итак, мы на коне. У нас есть: страницы сайта с HTML-версткой, в которую примешаны искомые данные. Чтобы вычленить наши данные, можно использовать разные методы, которые ограничиваются только вашей фантазией и функциями PHP для работы со строками, т.к. полученная HTML-страница — всего лишь строка (string):
Хм. Я уже умею кодить на jQuery, можно мне селектировать дивы контейнеры простыми селекторами, а не писать $document['body']['div']['div']['div']? Да, можно.
phpQuery — для тех кто хочет кодить на jQuery в PHP. И когда при помощи phpQuery вы получите одну строчку в вашей таблице, соответствующую одному объявлению, Вас закружит эйфория, Вы поставите Ваш скрипт парсить весь сайт, а тем временем пойдете в ближайшую пятёрочку покупать шампанское и будете мечтать о маленькой яхточке. Так пройдет ночь.
Суровая реальность
Наутро, придя к монитору, Вы увидите, что в таблице у Вас всего 2 тыс. строк, а скрипт отвалился с ошибкой Allowed Memory Size of… Bytes Exhausted…
Да, phpQuery, хоть и удобная штука, но память утекает. А скорость — самая низкая. Тогда Вам придется отказаться от удобной библиотеки и перейти на preg_match ради стабильности и скорости.
Ещё одни грабли — динамические селекторы. Запустив скрипт на следующий день, Вы поймете, что все классы изменились.
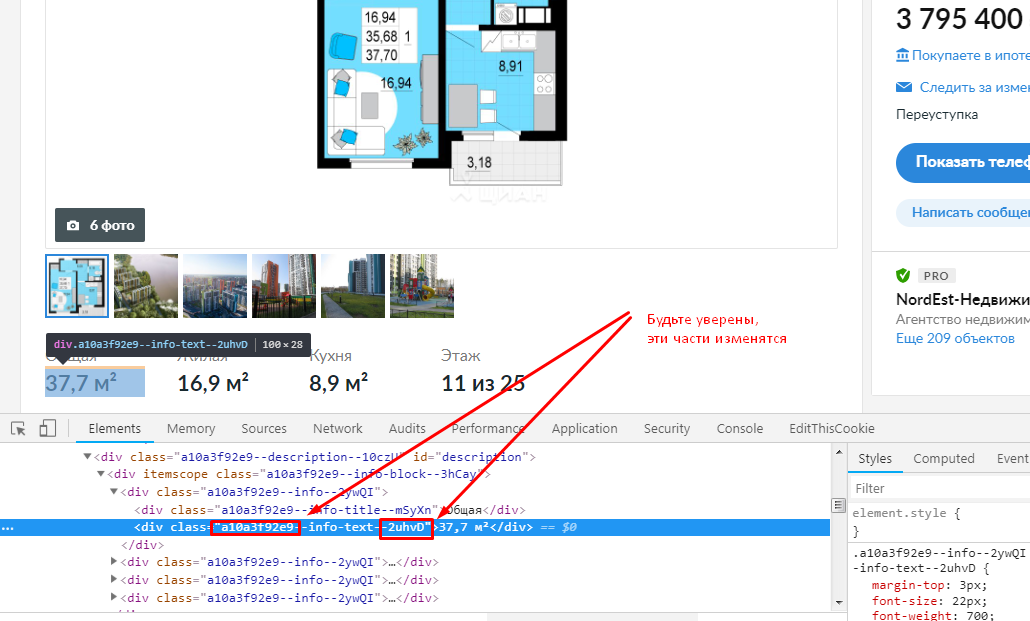
Решение: вообще не привязываться к классам. Ниже пример, как можно вычленить из циановского объявления все некоторые параметры, не привязываясь к CSS-классам.
$paramsNames = '["Общая","Жилая","Кухня","Этаж","Год постройки","Материалы стен","Этажность","Подъездов","Квартир","Средняя цена за м2","Средний возраст домов","Средняя цена за м2","Население","Название","Налог на недвижимость"]';
if( preg_match_all( '#]*>[^<]*]*>[^<]*(' . implode( '|', $paramsNames ) . ')
Как видите, структура верстки всегда одна и та же. Поэтому нет смысла вообще привязваться к классам, зацепимся к названиям параметров. И так, Вы опять ставите скрипт на ночь.
Капча
Наутро Вы увидите, что скрипт доработал до конца, но на сайт показывает 50 тыс. объявлений, а у Вас примерно те же 2 тыс.

Так выглядит капча ЦИАН
С капчей можно было бы посоревноваться при помощи ruCaptcha. Но только не в случае с reCaptcha. Бросьте эту идею, она провальна. Весь наш метод прямых HTTP-запросов из PHP уперся в тупик.
Есть выход
Выход заключается в том, что мы не будем делать GET-запросы прямо из PHP, а запустим браузер, и через PHP заставим его открывать нужные страницы и читать их содержимое. Когда вылетит капча, мы просто её пройдем, и будем парситься дальше. Рассмотрим технологии, которые нам понадобятся.
Selenium Webdriver — позволяет запускать браузер и управлять им по API (ссылка). Это инструмент тестировщиков, но мы ведь и тестируем, не правда ли? Обычно тестировщики используют Java. Но нам зачем эти танцы, если есть
php-webdriver — инструмент от Facebook (спасибо, Цукерберг!), предоставляющий SDK на PHP для Selenium webdriver.
Вот как мы откроем главную страницу ЦИАН и нажмем на кнопку «Найти»
# используем хром как рабочую лошадку
$capabilities = DesiredCapabilities::chrome();
$capabilities->setCapability(ChromeOptions::CAPABILITY, $options);
$driver = RemoteWebDriver::create('192.168.1...:4444/wd/hub', $capabilities, 5000);
$driver->manage()->timeouts()->implicitlyWait(10);
# открываем сессию и сразу открываем страницу
$remote = $driver->get('https://cian.ru/');
# ищем по CSS-селектору. Да, это почти что jQuery
$remote->findElement(WebdriverBy::cssSelector('.c-filters-field-button___1EBB-'))->click();
В примере я просто вставил динамический CSS-селектор. Но так делать нельзя, нужно сначала узнать класс у кнопки «Найти», предварительно получив все содержимое в HTML, потом программно подставить. Получить содержимое страницы из Selenium можно так:
$content = $remote->findElement(WebdriverBy::cssSelector('body'))->getAttribute('innerHTML');
И вот, Вы один раз ввели капчу, наслаждаетесь потоком приятных строк, наполняющих Вашу таблицу, параллельно тестируя ЦИАН. Вам нравится процесс, хотя он идет и не очень быстро, но главное — идет! И Вы уходите спать.
Грабли
А наутро приходите, и обнаруживаете, что парсинг закончился, а в таблице стало чуть больше объявлений. Всего 3 тыс. Скрипт не может вызвать Selenium (не достучаться). Что происходит?!
А вот что.
Открывая страницу через $driver→get, Вы заполняете location history у браузера. Открывая следующую в текущей сессии, предыдущая из памяти не стирается. И браузер просто пухнет в оперативной памяти, пока не произойдет коллапс. Выход — прерывать сессию через $driver→close. Но тогда можно опять нарваться на капчу…
А что если…
И так до бесконечности. Скорость очень низкая, Selenium чересчур, постоянные срывы парсинга… Нужно искать что-то другое. Да, у сервиса бесплатных объявлений, который мы тестируем, есть ещё мобильное приложение. А значит, есть и публичное API. Нужно только добраться до URL-ов API, и успех у нас в кармане! Делать это будем, конечно, через Android.
Прослушивать трафик, чтобы протестировать мобильное приложение, можно, но сложно мало эффективно. Инструкция, как это сделать, уже есть. Гораздо более школьный метод просто установить SSL Capture.
Так выглядит интерфейс приложения одного из бесплатных сервисов объявлений недвижимости
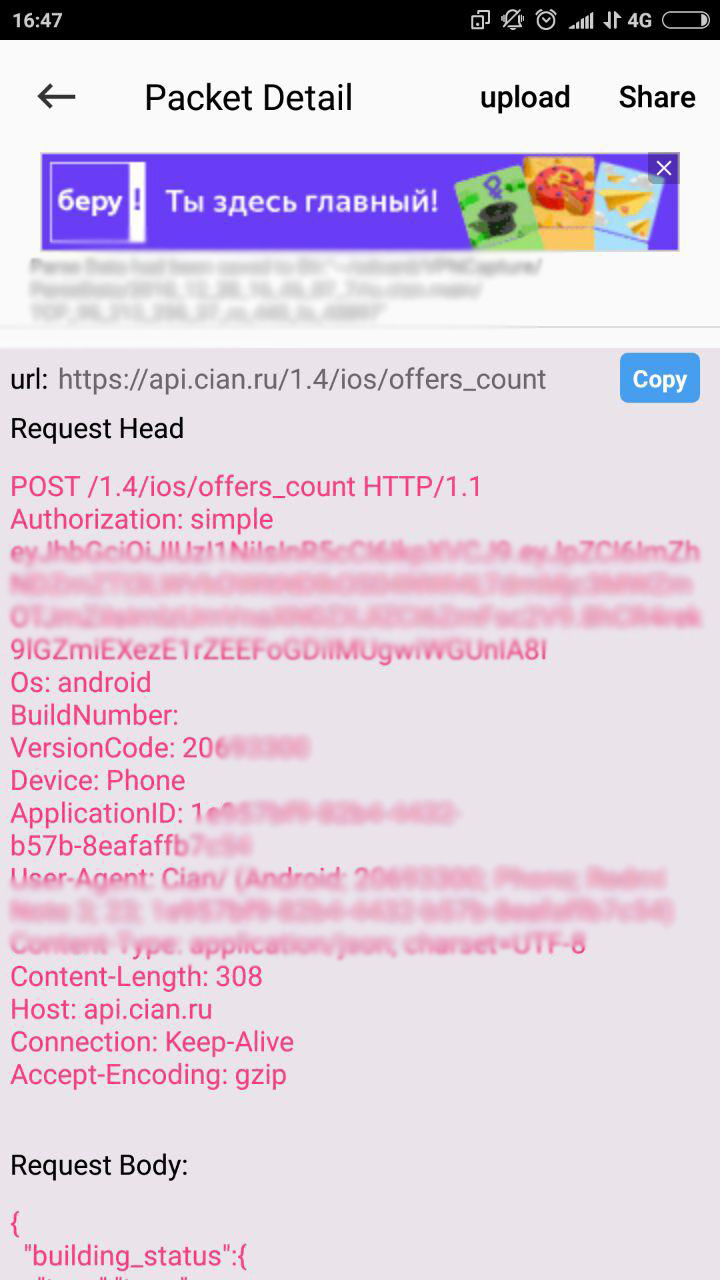
Так выглядит запрос на получение общего количества объявлений. Да-да, это на Android.
Для того, чтобы распарсить весь тестируемый сайт (сервис), нужен всего-лишь один метод API. Вот он: api.cian.ru/search-offers/v1/search-offers-for-mobile-apps
И в завершение прикреплю функцию (код), при помощи которой Вы сможете уже через час получить весь массив данных. Никаких (!!!) ограничений на запросы к мобильному API нет.
$request = [
'query' => [
'engine_version' => [
'type' => 'term',
'value' => '2'
],
'limit' => [
'type' => 'term',
'value' => 50
],
'object_type' => [
'type' => 'terms',
'value' => [0]
],
'page' => [
'type' => 'term',
'value' => $page
],
'_type' => 'flatsale'
]
];
$body = json_encode( $request );
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://api.cian.ru/search-offers/v1/search-offers-for-mobile-apps/?new_schema=1&multioffer_version=3" );
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1 );
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt($ch, CURLOPT_POST, 1 );
curl_setopt($ch, CURLOPT_HEADER, 0 );
curl_setopt($ch,CURLOPT_ENCODING , "gzip");
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Authorization: simple ....',
'Os: android',
'BuildNumber: ',
'VersionCode: 20630300',
'Device: Phone',
'ApplicationID: ....',
'User-Agent: Cian/ (Android; ....; Phone; ....)',
'Content-Type: application/json; charset=UTF-8',
'Content-Length: ' . mb_strlen($body),
// 'Host: api.cian.ru',
'Connection: Keep-Alive',
'Accept-Encoding: gzip',
]);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body );
$result=json_decode( curl_exec ($ch), true );
Вместо точек нужно подставить свои данные авторизации. После этого в $result['data']['offers'] будет абсолютно вся информация по каждому объявлению в списке.
Если у Вас есть критические замечания по данному материалу, просьба написать в ЛС. Так же я всегда открыт к предложениям.
Используемые инструменты:
phpQuery
Selenium Webdriver
php-webdriver
Oracle VirtualBox
