[Из песочницы] Перевод книги Эндрю Ына «Страсть к машинному обучению» Главы 1 — 14
Некоторое время назад в моей ленте в фейсбуке всплыла ссылка на книгу Эндрю Ына (Andrew Ng) «Machine Learning Yearning», которую можно перевести, как «Страсть к машинному обучению» или «Жажда машинного обучения».
 » alt=«image»/>» />
» alt=«image»/>» />
Людям, интересующимся машинным обучением или работающим в этой сфере представлять Эндрю не нужно. Для непосвященных достаточно сказать, что он является звездой мировой величины в области искусственного интеллекта. Ученый, инженер, предприниматель, один из основателей Coursera. Автор отличного курса по введению в машинное обучение и курсов, составляющих специализацию «Глубокое обучение» (Deep Learning).
Я с глубоким уважением отношусь к Эндрю, прошел его курсы, поэтому тут же решил прочитать выпускаемую книгу. Оказалось, что книга еще не написана и публикуется по частям, по мере ее написания автором. И вообще это даже не книга, а черновик будущей книги (будет ли она издана в бумажном виде, неизвестно). Потом пришла идея перевести выпускаемые главы. На настоящий момент перевел 14 глав (это первый выпущенный отрывок книги). Планирую продолжить данную работу и перевести всю книгу. Переводимые главы буду публиковать в своем блоге на Хабре.
На момент написания этих строк автор опубликовал 52 главы из задуманных 56 (уведомление о готовности 52 главы пришло мне на почту 4 июля). Все доступные на настоящий момент главы можно скачать здесь ну или самостоятельно найти в интернете.
Перед тем, как опубликовать свой перевод, поискал другие переводы, нашел вот этот, тоже опубликованный на Хабре. Правда переведены только первые 7 глав. Не могу судить о том, чей перевод лучше. Ни я, ни IliaSafonov (по ощущениям от прочтения) не являемся профессиональными переводчиками. Некоторые части мне больше нравятся у меня, некоторые у Ильи. В предисловии Ильи же можно прочитать интересные подробности о книге, которые я опускаю.
Свой перевод публикую без вычитки, «из печи», к некоторым местам планирую вернуться и поправить (особенно это относится к путанице с train / dev / test датасетами). Буду признателен, если в комментариях будут даны замечания как по стилистике, ошибкам и т.п., так и содержательные, касающиеся текста автора.
Все картинки оригинальные (от Эндрю Ын), без них книга была бы более скучной.
Итак, к книге:
Машинное обучение находится в основе бесчисленных важных приложений, включающих веб поиск, емейл антиспам, распознавание речи, рекомендации продуктов, и другие. Я предполагаю, что вы или ваша команда работают над приложениями с использованием машинного обучения. И что вы хотите ускорить свой прогресс в этой работе. Эта книга поможет вам сделать это.
Пример: Создание стартапа по распознаванию кошачьих картинок
Предположим, вы работаете в стартапе, который обрабатывает бесконечный поток кошачьих фотографий для любителей кошек.

Вы используете нейронную сеть для построения системы компьютерного зрения для распознавания кошек на фотографиях.
Но к несчастью, качество вашего обучающегося алгоритма еще не достаточно хорошее и на вас с колоссальной силой давит необходимость улучшить кошачий детектор.
Что делать?
У вашей команды много идей, таких как:
- Добыть больше данных: собрать больше фотографий кошек.
- Собрать более разнородный датасета. Например, фотографии, на которых кошки находятся в необычных положениях; фотографии кошек с необычной окраской; снимки с разнообразными настройками фотокамеры; …
- Дольше тренировать алгоритм, увеличив количество итераций градиентного спуска
- Попробовать увеличить нейронную сеть, с большим количеством слоев /скрытых нейронов / параметров.
- Попробовать уменьшить нейронную сеть.
- Попробовать добавить регуляризацию (такую, как L2 регуляризацию)
- Изменить архитектуру нейронной сети (функцию активации, количество скрытых нейронов, т. д.)
- …
Если вы удачно выберете между этими возможными направлениями, вы построите лидирующую платформу обработки кошачьих изображений, и приведете вашу компанию к успеху. Если ваш выбор окажется неудачным, вы можете напрасно потерять месяцы работы.
Как поступить?
Эта книга расскажет вам, как.
Большинство задач машинного обучения имеют подсказки, которые могут сообщить, что было бы полезно попробовать и что пробовать бесполезно. Если вы научитесь читать эти подсказки, то сможете сэкономить месяцы и годы разработки.
После окончания чтения этой книги, у вас будет глубокое понимание, как выбрать техническое направление работ для проекта по машинному обучению.
Но вашим товарищам по команде может быть не ясно, почему вы рекомендуете определенное направление. Возможно, вы хотите, чтобы ваша команда использовала одно параметрическую метрику при оценке качества работы алгоритма, но коллеги не уверены в том, что это хорошая идея. Как вам убедить их?
Вот почему я сделал главы короткими: Чтобы вы могли распечатать их и дать вашим коллегам одну две страницы, содержащие материал, с которым нужно ознакомить команду.
Маленькие изменения в приоритизации могу дать огромный эффект для продуктивности вашей команды. Помогая с этими небольшими изменениями, я, надеюсь, вы сможете стать супергероем вашей команды!

Если вы прошли курс по машинному обучению, такие как мой курс машинного обучения MOOC на Coursera, или если у вас есть опыт обучения алгоритмов с учителем, вам будет не сложно понять этот текст.
Я предполагаю, что вы знакомы с «обучением с учителем»: обучение функции, которая связывает х с y, используя размеченные тренировочные примеры (х, у). К алгоритмам обучения с учителем относятся линейная регрессия, логистическая регрессия, нейронные сети и другие. На сегодняшний день существует много форм и подходов к машинному обучению, но большая часть подходов, имеющих практическое значение получены из алгоритмов класса «обучение с учителем».
Я буду часто обращаться к нейронным сетям (к «глубокому обучению»). Вам нужно только базовые представления о том, что они из себя представляют для понимания этого текста.
Если вы не знакомы с концепциями, упоминаемыми тут, посмотрите видео первых трех недель из курса Машинного обучения на Coursera http://ml-class.org/
Многие идеи глубокого обучения (нейронных сетей) существовали десятилетия. Почему эти идеи взлетели только сегодня?
Двумя наибольшими драйверами недавнего прогресса стали:
- Доступность данных Сегодня люди проводят много времени с вычислительными приборами (ноутбуки, мобильные устройства). Их цифровая активность генерирует огромные объемы данных, которые мы можем скармливать нашим обучающимся алгоритмам.
- Вычислительные мощности Только несколько лет назад стало возможным тренировать нейронные сети достаточно больших размеров, позволяющих получать преимущества использования огромных датасетов, которые у нас появились.
Уточню, даже если вы аккумулируете много данных, обычно, кривая роста точности старых обучающихся алгоритмов, таких как логистическая регрессия «плоская». Это подразумевает, что кривая обучения «уплощается» и качество предсказания алгоритма перестает расти несмотря на то, что вы даете ему больше данных для обучения.
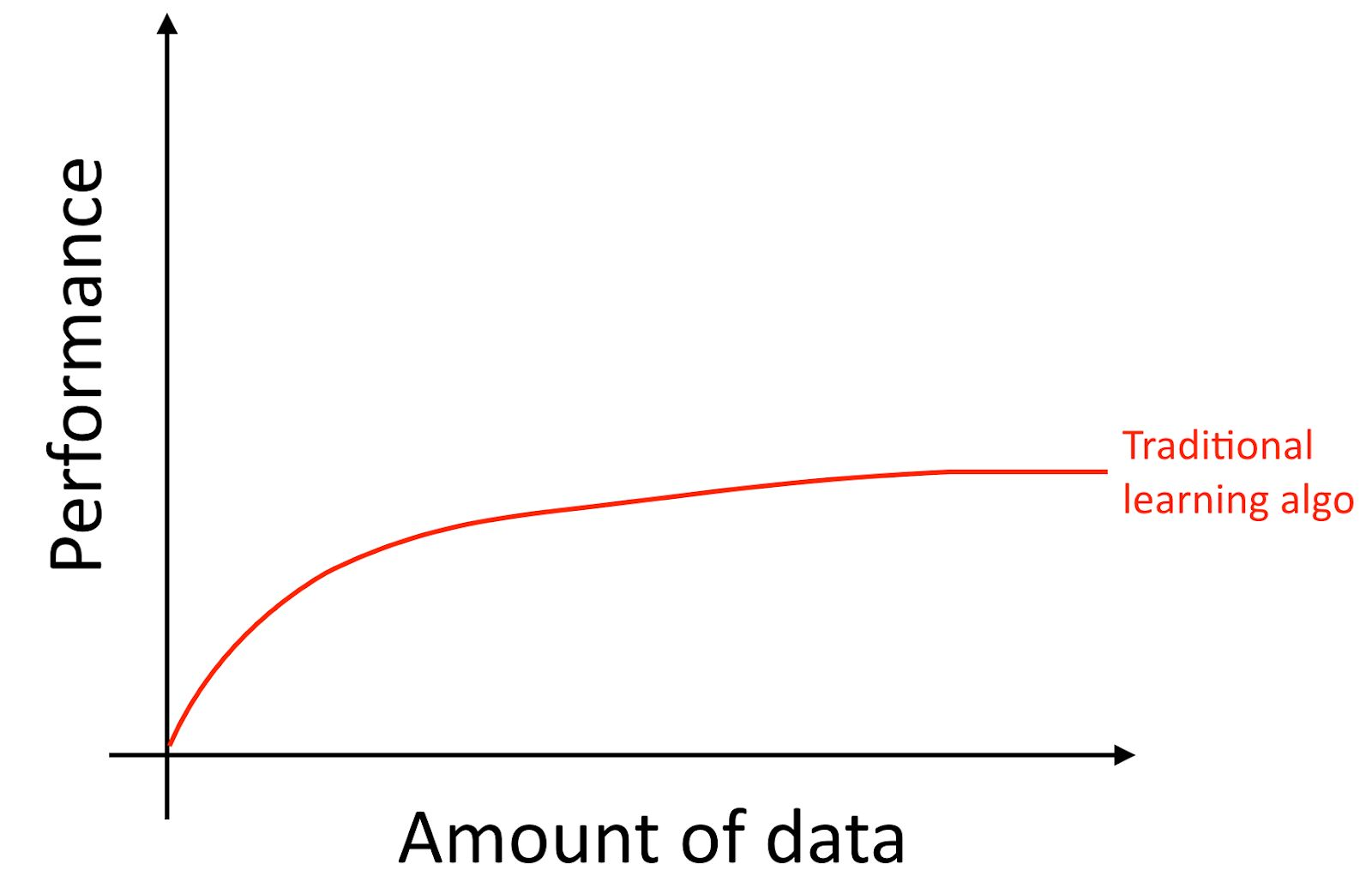
Это выглядит, как будто старые алгоритмы не знают, что делать со всеми этими данными, которые сейчас оказались в нашем распоряжении.
Если вы тренируете маленькую нейронную сеть (NN) для той же самой задачи «обучения с учителем», вы можете получить результат немного лучший, чем у «старых алгоритмов».
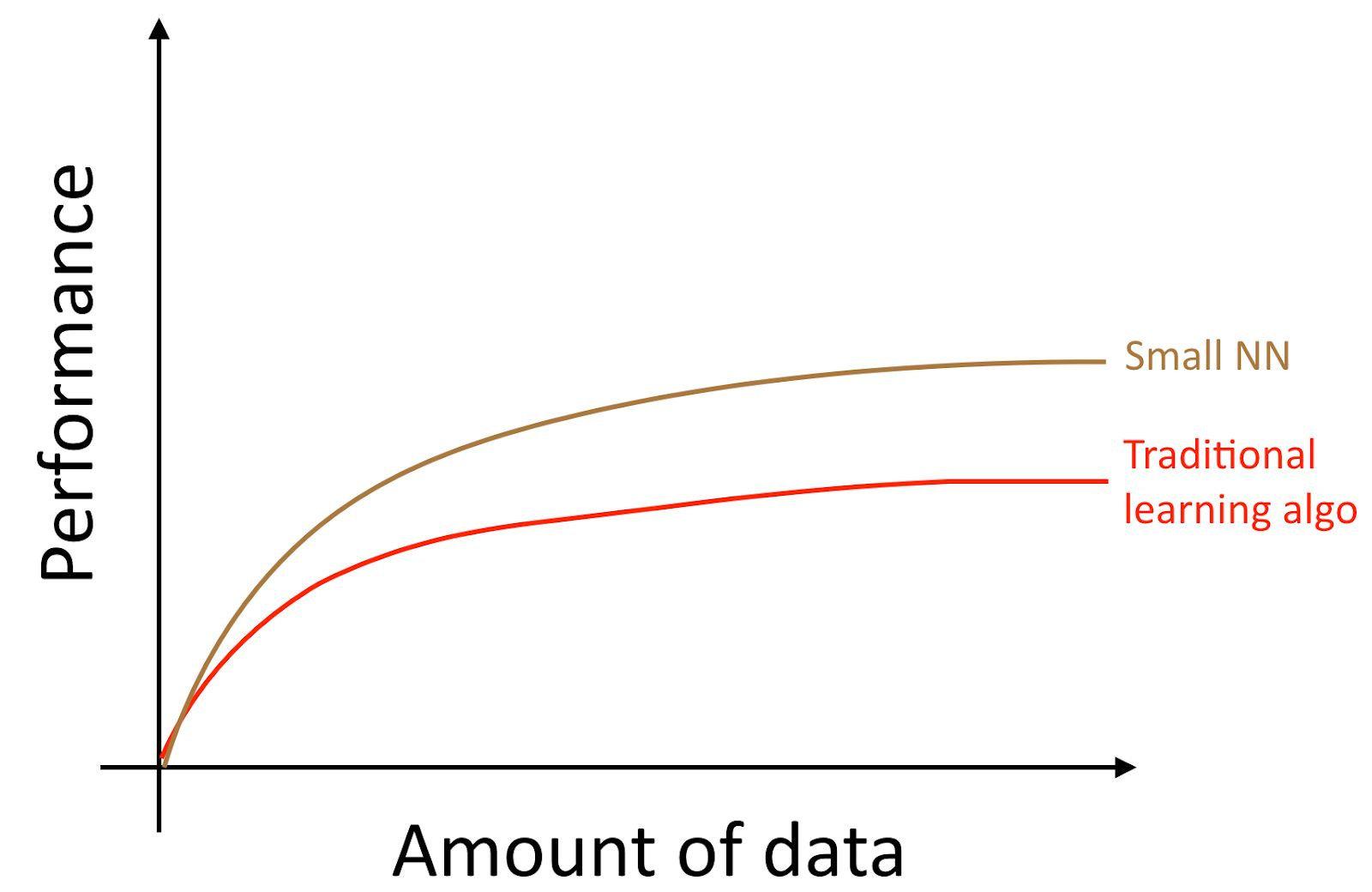
Здесь под «Малой NN» мы понимаем нейронную сеть с небольшим количеством скрытых нейронов / слоев / параметров. Наконец, если вы начинаете тренировать все большие и большие нейронные сети, вы можете получить все более высокое качество.
Примечание автора: Эта диаграмма показывает, что нейронные сети работают лучше в режиме малых датасетов. Этот эффект менее устойчивый, чем эффект нейронных сетей, хорошо работающих в режиме огромных датасетов. В режиме малых данных, в зависимости от того, как признаки были обработаны (в зависимости от качества ижниниринга признаков), традиционные алгоритмы могут работать как лучше, так и хуже, чем нейронные сети. Например, если вы имеете 20 примеров для обучения, не имеет большого значения, используете вы логистическую регрессию или нейронную сеть; подготовка признаков имеет больший эффект, чем выбор алгоритма. Однако, если вы имеете 1 миллион обучающих примеров, я бы предпочел нейронную сеть

Таким образом, вы получаете лучшее качество работы алгоритма, когда вы (i) тренируете очень большую нейронную сеть, в этом случае вы находитесь на зеленой кривой на картинке вверху; (ii) в вашем распоряжении огромное количество данных.
Многие другие детали, такие как, архитектура нейронной сети являются также важными, и в этой области создано много инновационных решений. Но наиболее надежный путь улучшить качество работы алгоритма на сегодня все еще остается (i) увеличение размера тренируемой нейронной сети (ii) получения большего количества данных для обучения.
Процесс совместного выполнения условий (i) и (ii) на практике оказывается удивительно сложным. В этой книге будут подробно обсуждены его детали. Мы начнем с общих стратегий, которые одинаково полезны как для традиционных алгоритмов, так и для нейронных сетей, и затем изучим наиболее современные стратегии, используемые при проектировании и разработке систем глубинного обучения.
Давайте вернемся к нашему примеру с кошачьими фотографиями, рассмотренному выше: Вы запустили мобильное приложение и пользователи закачивают большого количество различных фотографий в ваше приложение. Вы хотите автоматически находить фотографии кошек.
Ваша команда получает большой тренировочный набор, скачивая фотографии кошек (позитивные примеры) и фотографии, на которых кошек нет (негативные примеры) с различных веб-сайтов. Они нарезали разделили датасет на обучающий и тестовый в отношении 70% на 30%. Используя эти данные, они построили алгоритм, находящий кошек, хорошо работающий как на обучающих так и на тестовых данных.
Однако, когда вы внедрили этот классификатор в мобильное приложение, вы обнаружили, что качество его работы очень низкое!

Что случилось?
Вы вдруг выясняете, что фотографии, которые пользователи загружают в ваше мобильное приложение, имеют совершенно другой вид, чем те фотографии с веб-сайтов, из которых состоит ваш обучающий датасет: пользователи загружают фотографии, снятые камерами мобильных телефонов, которые, как правило, имеют более низкое разрешение, менее четкие и сделаны при плохом освещении. После обучения на вашей обучающей/тестовой выборках, собранных из фотографий с веб-сайтов, ваш алгоритм не смог качественно обобщить результаты на реальное распределение данных, актуальных для вашего приложения (на фотографии, сделанные камерами мобильных телефонов).
До наступления современной эры больших данных, общим правилом машинного обучения было разбиение данных на обучающие и тестовые в отношении 70% на 30%. Несмотря на то, что этот подход все еще работает, будет плохой идеей использовать его во все большем и большем количестве приложений, где распределение обучающей выборки (фотографии с веб-сайтов в примере, рассмотренном выше) отличается от распределения данных, которые будут использоваться в боевом режиме вашего приложения (фотографии с камеры мобильных телефонов).
Обычно используются следующие определения:
- Обучающая выборка (Training set) — выборка из данных, которая используется для обучения алгоритма
- Валидационная выборка (Выборка для разработки Dev (development) set) — выборка данных, которая используется для подбора параметров, выбора признаков и принятия других решений, касающихся обучения алгоритма. Ее иногда так же называют удерживаемой выборкой для кросс-валидации (hold-out cross validation set)
- Тестовая выборка — выборка, которая используется для оценки качества работы алгоритма, при этом никак не используется для обучения алгоритма или используемым при этом обучении параметрам.
Замечание переводчика: Андрю Ын использует понятие development set или dev set, в русском языке и русскоязычной терминологии машинного обучения такого термин не встречается. «Выборка для разработки» или «Разработческая выборка» (прямой перевод английских слов) звучит громоздко. Поэтому я буду в дальнейшем использовать словосочетание «валидационная выборка» в качестве синонима dev set.
Выбрать валидационную и тестовую выборки такими, чтобы они отражали данные, которые вы ожидаете получать в будущем и хотите, чтобы на них ваш алгоритм работал хорошо.
Другими словами, ваша тестовая выборка должна быть не просто 30% от доступных данных, особенно если вы ожидаете, что данные, которые будут поступать в будущем (фотографии с мобильных телефонов) будут отличаться по своей природе от вашей обучающей выборки (фотографий, полученных с веб сайтов).
Если вы еще не запустили ваше мобильное приложение, у вас может не быть пользователей, и как следствие, может не быть доступных данных, отражающих боевые данные, с которым должен справляться ваш алгоритм. Но вы можете попытаться аппроксимировать их. Например, попросите ваших друзей сделать фотографии котов с помощью мобильных телефонов и прислать их вам. После запуска вашего приложения, вы сможете обновить ваши валидационную и тестовую выборки, используя актуальные пользовательские данные.
Если вы не имеете возможности получить данные, которые аппроксимируют те, которые будут загружать пользователи, наверное вы можете попробовать стартовать, используя фотографии с вебсайтов. Но вы должны осознавать, что это несет в себе риск того, что система будет плохо работать с боевыми данными (ее обобщающая способность будет недостаточной для них).
Разработка валидационной и тестовой выборок требует серьезного подхода и основательных размышлений. Не постулируйте изначально, что распределение вашей обучающей выборки должно в точности совпадать с распределением тестовой выборки. Попытайтесь выбрать тестовые примеры таким образом, чтобы они отражали то распределение данных, на которых вы хотите, чтобы ваш алгоритм хорошо работал в конечном счете, а не те данные, которые оказались в вашем распоряжении при формировании обучающей выборки.

Допустим данные вашего приложения для кошачьих фотографий сегментированы по четырем регионам, соответствующих вашим наибольшим рынкам: (i) США, (ii) Китай, (iii) Индия, (iv) Прочие.
Допустим, мы сформировали валидационную выборку из данных, полученных с американского и индийского рынка, а тестовую на основании китайских и прочих данных. Другими словами мы можем случайным образом назначить два сегмента для получения валидационной выборки и два других для получения тестовой выборки. Правильно?
После того, как вы определили валидационную и тестовую выборки, ваша команда будет сфокусирована на улучшение работы алгоритма на валидационной выборке. Таким образом, валидационная выборка должна отражать задачи, продвинуться в решении которых наиболее важно — алгоритм должен хорошо работать на всех четырех географических сегментах, а не только на двух.
Вторая проблема, вытекающая из различных распределений валидационной и тестовой выборок заключается в том, что существует вероятность, что ваша команда разработает что-то, что будет хорошо работать на валидационной выборке только для того, чтобы узнать, что оно выдает низкое качество на тестовой выборке. Я наблюдал много разочарований и впустую потраченных усилий из-за этого. Избегайте того, чтобы это случилось с вами.
Например, предположим ваша команда разработала систему, которая хорошо работает на валидационной выборке, но не работает на тестовой. Если ваши валидационная и тестовая выборки получены из одного и того же распределения вы [получаете очень ясную диагностику того] можете легко диагностировать, что пошло не так: ваш алгоритм переобучился на валидационной выборке. Очевидным лечением этой проблемы будет использование большего количества данных для валидационной выборки.
Но если валидационная и тестовая выборки получены из разных распределений данных, тогда возможные причины плохой работы алгоритма менее очевидны.
- Вы получили переобученный алгоритм на валидационной выборке
- Тестовая выборка более сложная для алгоритма, чем валидационная. Ваш алгоритм уже работает настолько хорошо, насколько это возможно и существенного улучшения качества невозможно.
- Тестовая выборка необязательно более сложная, она может быть просто другой, отличной от валидационной. И то что хорошо работает на валидационной выборке просто не дает хорошего качества на тестовой. В этом случае большое количество вашей работы по улучшению качества работы алгоритма на на валидационой выборке окажется напрасными усилиями.
Работа над приложениями с использованием машинного обучения и так довольно тяжелая. Имея не совпадающие тестовую и валидационные выборки, мы сталкиваемся с дополнительной неопределенностью — приведет ли улучшения работы алгоритма на валидационной выборке к улучшению его работы на тестовой. При несовпадении распределений тестовой и валидационной выборок трудно понять, что улучшает качество работы алгоритма и что мешает его улучшению, и как следствие, становится сложно расставить приоритеты в работе.
Если вы работаете над проблемой, поставленной перед вами внешним заказчиком, тот кто ее формулировал, мог выдать вам валидационную и тестовую выборки из разных распределений данных (вы не имеете возможности это изменить). В этом случае скорее удача, чем опыт будет иметь большее значение для качества работы вашего алгоритма, обратная ситуация наблюдается, если валидационная и тестовая выборка имеют одинаковое распределение. Это серьезная исследовательская проблема — разрабатывать обучающиеся алгоритмы, которые будут тренироваться на одном распределении данных и должны хорошо работать на другом. Но если вашей задачей является разработка определенного приложения, на основании машинного обучения, а не исследования в этой области, я рекомендую попытаться выбрать валидацинную и тестовую выборки, имеющих одинаковое распределение данных. Работа с такими выборками сделает вашу команду более эффективной.
Валидационная выборка должна быть достаточной для определения различий между алгоритмами, которые вы испытываете. Например, если классификатор А имеет точность 90.0% и классификатор В имеет точность 90.1%, в этом случае, на валидационной выборке, состоящей из 100 примеров, невозможно обнаружить эту разницу в 0.1%.
Замечание автора: В теории можно проверить имеет ли статистическую значимость изменение качества работы алгоритма при изменении размера валидационной выборки. На практике большинство команд об этом не беспокоятся об этом (если речь идет не о публиковании результатов академических исследований), и я обычно не считаю полезным использование тестов на статистическую значимость для оценки промежуточного прогресса при работе над алгоритмом.
Для зрелых и важных приложений — например, рекламных, интернет-поиска, и рекомендательных сервисов, я встречал команды, которые были высоко мотивированы биться даже за 0.01% улучшения, так как это напрямую влияет на прибыль компании. В этом случае, валидационная выборка должна быть много больше чем 10000, для того, чтобы обнаружить еще меньшие улучшения.
Что можно сказать о размере тестовой выборки? Она должна быть достаточно большой для получения высокой уверенности в качестве работы вашей системы. Одной популярной эвристикой является использование 30% доступных для обучения данных для тестовой выборки. Это хорошо работает, если в вашем распоряжении небольшое количество примеров, скажем от 100 до 10000 примеров. Но в сегодняшнюю эпоху больших данных, когда перед машинным обучением стоят задачи, иногда имеющие больше миллиарда примеров, доля данных, используемых для тестовой и валидационной выборок сокращается, даже если растет абсолютное количество примеров в этих выборках. Нет никакой необходимости использовать чрезмерно большие валидационные/тестовые выборки, свыше того, что необходимо для оценки качества работы ваших алгоритмов.
Точность классификации является примером однопараметрической метрики качества: вы запускаете свой классификатор на валидационной выборке (или на тестовой), и получаете одну цифру, говорящую о том, какое количество примеров классифицированны правильно. Согласно этой метрике, если классификатор А показывает 97% точность, а классификатор В показывает 90%, мы считаем классификатор А более предпочтительным.
Для контраста рассмотрим метрику точности (precision) и полноты (recall), которая не являются однопараметрической. Она дает две цифры для оценки вашего классификатора. Данную многопараметрическую метрику сложнее использовать для сравнения алгоритмов. Предположим ваш алгоритм показывает следующие результаты:
| Classifier | Precision | Recall |
|---|---|---|
| А | 95% | 90% |
| В | 98% | 85% |
В данном примере ни один из классификаторов с очевидностью не превосходит другой, поэтому невозможно сразу выбрать один из них.
| Classifier | Precision | Recall | F1 score |
|---|---|---|---|
| А | 95% | 90% | 92.4% |
Замечание автора: Точность (precision) кошачьего классификатора оценивает долю фотографий в валидационной (тестовой) выборке, на которых действительно изображены коты в классифицированных алгоритмом, как изображение котов. Полнота (recall) показывает процент всех картинок с кошками в валидационной (тестовой) выборке, которые корректно классифицированы, как изображение котов. Часто приходится идти на компромисс, выбирая между высокой точностью и высокой полнотой.
В процессе разработки, ваша команда будет пробовать реализовать множество идей об архитектуре алгоритмов, параметрах моделей, выбор признаков, и т. д. Использование однопараметрическую метрику качества такую, как точность (accuracy) позволяет вам оценивать модели с помощью данной метрики и быстро решать, которая является наилучшей.
Если вам действительно необходимо оценивать качество точностью и полнотой, я рекомендую использовать один из стандартных способов их комбинации, превращая их в одну цифру. Например, можно взять среднюю точности и полноты и в конечном счете работать с одним параметром. В качестве альтернативы можно рассчитывать F1 метрику, которая является более совершенным способом расчета их средневзвешенного и работает лучше, чем просто среднее.
Замечание автора: Если вы хотите узнать больше об F1 метрике, см. https://en.wikipedia.org/wiki/F1_score, Она является «гармоническим средним» между Точностью и Полнотой и рассчитывается, как 2/((1/Precision)+(1/Recall)).
| Classifier | Precision | Recall | F1 score |
|---|---|---|---|
| А | 95% | 90% | 92.4% |
| B | 98% | 85% | 91.0% |
Использование однопараметирической метрики оценки качества ускорит принятие решения, когда вы выбираете между большим количеством классификаторов. Это дает очевидные преимущества при ранжировании их всех и теоретически делает очевидным направления для дальнейшего развития проекта.
В качестве последнего примера, предположим, что вы раздельно отслеживаете точность вашего кошачьего классификатора на ваших ключевых рынках: (i) США, (ii) Китай, (iii) Индия и (iv) Прочие. Таким образом вы имеете четыре метрики. Взяв средневзвешенную этих четырех цифр, в конце концов у вас будет однопараметрическая метрика оценки качества. Использование средневзвешенного является одним из наиболее распространенных путей превращения нескольких метрик в одну.
Здесь мы рассмотрим другой подход к комбинации многопараметрических метрик качества алгоритмов.
Представьте, что вам необходимо оптимизировать точность и скорость работы обучающегося алгоритма. Вам необходимо выбрать один из трех классификаторов из таблицы:
| Классификатор | Точность | Скорость |
|---|---|---|
| А | 90% | 80 мсек |
| B | 92% | 95 мсек |
| С | 95% | 1500 мсек |
Получение однопараметрической метрики, связыванием скорости и точности через формулу, такую как [Точность] — 0.5*[Скорость], выглядит не естественным.
Вот что вы можете сделать вместо этого: Во-первых, определите, какое время выполнение алгоритма является «приемлемым». Давайте предположим, что исполнение в течение 100 мили секунд является приемлемым. Затем выберем максимальную точность, соответствующую критерию скорости выполнения. Здесь скорость выполнения является ограничивающей (satisficing) метрикой — ваш классификатор должен удовлетворять ограничивающим значениям этой метрики, в том смысле, что его максимальное значение не может превышать 100 мсек. Точность при этом становится оптимизационной метрикой.
Если вы оперируете N различными критериями, такими как размер бинарного файла модели (который важен для мобильных приложений из-за того, что пользователи не хотят загружать большие приложения), время исполнения, и точность, вы можете рассматривать N-1 из этих критериев как ограничивающие метрики. Т. е. Вы просто требуете, чтобы они принимали определенное значение. Затем определите последнюю (N-ую) метрику, как оптимизационную. Например, установите приемлемое пороговое значение для размера бинарного файла и для времени выполнения алгоритма, и попытайтесь оптимизировать точность, выдерживая эти ограничения.
В качестве последнего примера, представьте что вы разрабатываете прибор, использующий микрофон для улавливания определенного «инициирующего слова», произносимого пользователем для включения системы (после произнесения которого, система просыпается). Например, Amazon Echo улавливает «Alexa»; Apple Siri улавливает «Hey Siri»; Android улавливает «Okay, Google»; приложения Baidu улавливают «Hello Baidu». Вашей заботой является оба false-positive соотношения — как частота включения системы, когда никто не произносил ключевого слова, так и false-negative — как часто система не включается при произнесении ключевого слова. Целесообразной целью при разработке такой системы является минимизация false-negative метрики (это будет оптимизационным параметром) при наличие не более чем один случай false positive каждые 24 часа работы (ограничивающая метрика).
Выбор метрик для оптимизации позволяет командам ускорить прогресс в разработке моделей.
Очень сложно наперед знать, какой подход будет работать лучше всего для новой проблемы. Даже опытные исследователи в области машинного обучения обычно пробуют много дюжин идей прежде чем находят что-то удовлетворительное. При создании системы на основании алгоритмов машинного обучения, я обычно выполняю следующие шаги:
- Начинаю с некоторой идеи, как построить эту систему
- Реализую эту идею в коде (программирую идею)
- Провожу эксперимент который показывает мне, насколько хорошо работает эта идея. (Обычно мои первые несколько идей не работают!) Отталкиваясь от приобретенных знаний, возвращаюсь к генерации новых идей и далее по кругу.
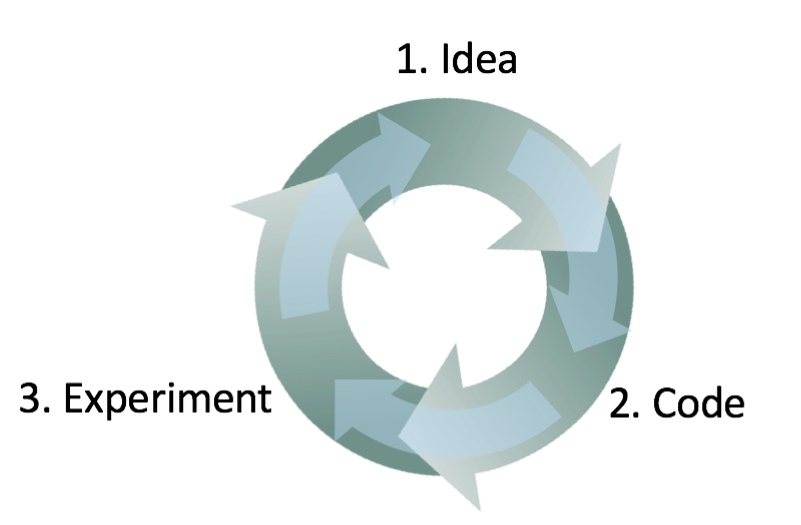
Это итерационный процесс. Чем быстрее можете пройти эту итерационную петлю, тем быстрее будет ваш прогресс в создании системы. Вот почему наличие валидационной и тестовой выборок и метрик является важным: Каждый раз вы пробуете идею, измерение качества выполнения вашей идеи на валидационной выборке позволяет вам быстро решить, в правильном ли направлении вы движетесь.
Для контраста, представьте, что у вас нет специальной валидационной выборки и метрики. Таким образом каждый раз ваша команда разрабатывает новый кошачий классификатор, вы должны интегрировать этот классификатор в ваше приложение и играть с приложением какое-то количество часов для того, чтобы почувствовать, действительно ли новый классификатор является улучшением. Это может тянуться невероятно медленно! Кроме того, если ваша команда улучшила точность классификатора с 95.0% до 95.1%, вы можете оказаться не способными заметить эти 0.1% улучшения при манипуляциях (игре) с приложением. Но большой прогресс в вашей системе может быть достигнут постепенным накоплением дюжин таких 0.1%-ных улучшений. Наличие валидационной выборки и метрик, позволяют вам очень быстро замечать и оценивать какие идеи являются успешными, дающими вам маленькие (или большие) улучшения, и поэтому дают вам быстрое решение, какие идеи нужно совершенствовать и какие отбросить.
Когда запускается новый проект, я пытаюсь быстро выбрать валидационную и тестовую выборки, которые поставят перед командой четко определенную цель.
Я обычно прошу мои команды получить первоначальные валидационную и тестовую выборки и первоначальную метрику быстрее чем за одну неделю с момента старта проекта, редко дольше. Лучше взять что-нибудь несовершенное и быстро двинуться вперед, чем долго обдумывать лучшее решение. Однако, этот одно недельный срок не подходит для зрелых приложений. Например, антиспамовый фильтр является зрелым приложением с использованием глубокого обучения. Я наблюдал команды, работающие над уже зрелыми системами и тратящие месяцы для получения еще лучших выборок для тестирования и разработки.
Если позднее вы решите, что ваши первоначальные dev/test выборки или первоначальная метрика выбраны неудачно, киньте все силы на то, чтобы быстро их поменять. Например, если ваш выборка для разработки + метрика ранжируют классификатор A выше, чем классификатор B, при этом вы и ваша команда думаете, что классификатор В объективно лучше подходит для вашего продукта, то это может быть знаком, что вы нуждаетесь в изменении dev/test датасетов или в изменении метрики оценки качества.
Существует три основные возможные причины, из-за которых валидационная выборка или метрика оценки качества неправильно ранжируют классификатор А выше классификатора В:
1. Реальное распределение, которое нужно улучшать, отличается от dev/test выборок
Представьте, что ваши первоначальные dev/test датасеты содержат в основном картинки взрослых кошек. Вы начинаете распространять ваше кошачье приложение, и обнаруживаете, что пользователи загружают существенно больше изображений котят, чем вы ожидали. Таким образом dev/test распределение не репрезентативно, оно не отражает реального распределения объектов, качество распознавания которых вам необходимо улучшать. В этом случае обновите ваши dev/test выборки, сделав их более репрезентативными.

2. Вы переобучаетесь на валидационной выборке (dev set)
Процесс многократной эволюции идей, на валидационной выборке (dev set) заставляет ваш алгоритм постепенно переобучаться на ней. Когда вы завершили разработку, вы оцениваете качество вашей системы на тестовой выборке. Если вы обнаружите, что качество работы вашего алгоритма на валидационной выборке (dev set) много лучше, чем на тестовой (test set), то это говорит о том, что вы переобучились на валидационной выборке. В этом случае нужно получить новую валидационную выборку.
Если вам необходимо отслеживать прогресс работы вашей команды, вы так же можете регулярно оценивать качество вашей системы, скажем, еженедельно или ежемесячно, используя оценку качества работы алгоритма на тестовой выборке. Однако, не используйте тестовую выборку для принятия каких-либо решений относительно алгоритма, включая следует ли вернуться к предыдущей версии системы, которая тестировалась на прошлой неделе. Если вы начнете использовать тестовую выборку для изменения алгоритма, вы начнете переобучаться на тестовой выборке и не сможете больше рассчитывать на нее, для получения объективной оценки качества работы вашего алгоритма (в котором вы нуждаетесь, если публикуете исследовательские статьи, или, возможно, используете эти метрики для принятия важных решений в бизнесе).
3. Метрика оценивает что-то отличное от того, нужно оптимизировать для целей проекта
Предположим, что для вашего кошачьего приложения, вашей метрикой является точность классификации. Эта метрика в настоящий момент ранжирует классификатор А, как превосходящий классификатор В. Но предположим, что вы испытали оба алгоритма и обнаружили, что через классификатор А проскакивают случайные порнографические изображения. Несмотря на то, что классификатор А более точный, плохое впечатление, оставляемое случайными порнографическими изображениями, делает качество его работы неудовлетворительное. Что вы сделали не так?
В данном случае метрика, оценивающая качество алгоритмов, не может определить, что алгоритм В фактически лучше, чем алгоритм А для вашего продукта. Таким образом вы больше не можете доверять метрике для выбора лучшего алгоритма. Настало время изменить метрику оценки качества. Например, вы можете изменить метрику, введя сильное наказание алгоритма за пропуск порнографического изображения. Я настоятельно рекомендую выбрать новую метрику и использовать эту новую метрику для установления в явной форме новой цели для команды, а не продолжать слишком долго работать с метрикой, не вызывающей доверия, возвращаясь каждый раз к ручному выбору между классификаторами.
Это довольно общие подходы к изменению dev/test выборок или изменению метрики оценки качества в процессе работы над проектом. Наличие первоначальных dev/test выборок и метрики позволяют вам быстро нача
