[Из песочницы] Pandasql vs Pandas для решения задач анализа данных
В этой статье я бы хотела рассказать о применении python-библиотеки Pandasql.
Многие люди, сталкивающиеся с задачами анализа данных, уже, скорее всего, знакомы с библиотекой Pandas. Pandas позволяет быстро и удобно работать с табличными данными: фильтровать, группировать, делать join над данными; строить сводные таблицы и даже рисовать графики (для простых визуализации достаточно функции plot (), а если хочется чего-то позаковыристее, то поможет библиотека matplotlib). На Хабре не раз рассказывали о применении этой библиотеки для работы с данными: раз, два, три.
Но по моему опыту далеко не все знают о библиотеке Pandasql, которая позволяет работать с Pandas DataFrames как с таблицами и обращаться к ним, используя язык SQL. В некоторых задачах проще выразить желаемое с помощью декларативного языка SQL, поэтому я считаю, что людям, работающим с данными, полезно знать о наличии такой функциональности. Если говорить о реальных задачах, то я использовала эту библиотеку для решения задачи join’a таблиц по нечетким условиям (необходимо было объединить записи о событиях из разных систем по примерно совпадающему времени, разрыв порядка 5 секунд).
Рассмотрим использование этой библиотеки на конкретных примерах.
Для иллюстрации я взяла данные о вовлеченности студентов специализации «Data Analyst Nanodegree» на Udacity. Эти данные опубликованы в курсе Intro to Data Analysis (могу порекомендовать этот курс всем, кто хочет познакомиться с использованием библиотек Pandas и Numpy для анализа данных, хотя там совсем не рассмотрена бибилиотека Pandasql).
В примерах я буду использовать 2 таблицы (подробнее о данных можно почитать тут):
- enrollments: данные о записи на специализацию «Data Analyst Nanodegree» некоторого случайного подмножества студентов;
- account key: ID студента;
- join date: день, когда студент записался на специализацию;
- status: статус студента на момент сбора данных: «current», если студент активен, и «canceled», если он покинул курс;
- cancel date: день, когда студент покинул курс, None для активных студентов;
- is udacity: принимает значение True для тестовых аккаунтов в Udacity, для живых пользователей — False;
- daily engagements: данные об активности студентов из таблицы enrollments для каждого дня, когда они были записаны на специализацию;
- acct: ID студента;
- utc date: дата активности;
- total minutes visited: суммарное число минут, которое студент провел на курсах специализации «Data Analyst Nanodegree».
Теперь мы можем перейти к рассмотрению примеров. Мне кажется, наиболее наглядно будет показать, как решить каждую из задач с помощью стандартной функциональности Pandas и Pandasql.
Для начала нужно сделаем все необходимы импорты и загрузим данные из csv файлов в DataFrames. Полный код примеров и исходные данные можно найти в репозитории.
import pandas as pd
import pandasql as ps
from datetime import datetime
import seaborn
daily_engagements = pd.read_csv('./data/daily_engagement.csv')
enrollments = pd.read_csv('./data/enrollments.csv')
Импорт библиотеки seaborn использован только для того, чтобы сделать графики красивее, никакой специальной функциональности библиотеки использовано не будет.
Простой запрос
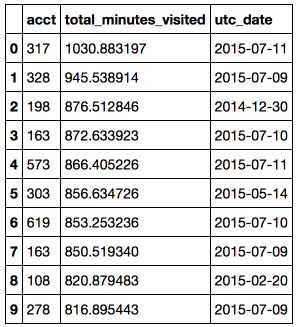
Задача: найти топ-10 максимальных активностей студента в конкретный день.
В данном примере рассмотрено, как использовать фильтрацию, сортировку и получение N первых объектов. Для выполнения SQL запроса используется функция sqldf модуля Pandasql, также в эту функцию необходимо передать словарь локальных имен locals() (подробнее про использование функций locals() и globals() в Pandasql можно почитать на Stackoverflow).
# pandas code
top10_engagements_pandas = daily_engagements[['acct', 'total_minutes_visited', 'utc_date']]
.sort('total_minutes_visited', ascending = False)[:10]
# pandasql code
simple_query = '''
SELECT
acct,
total_minutes_visited,
utc_date
FROM daily_engagements
ORDER BY total_minutes_visited desc
LIMIT 10
'''
top10_engagements_pandas = ps.sqldf(simple_query, locals())
Вывод: Самый усердный студент просидел за учебой более 17 часов в один день.
Использование агрегатных функций
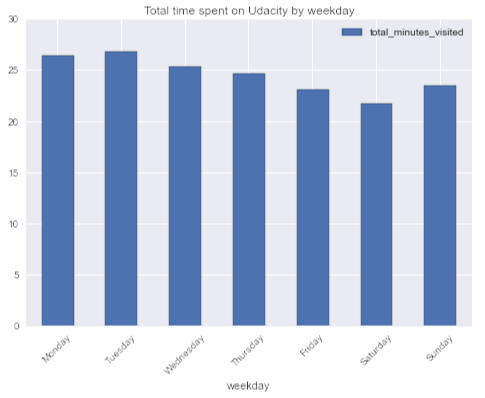
Задача: интересно, есть ли недельная сезонность в активности студентов (если судить по себе, то обычно не хватает времени на online курсы по будням, но можно уделять этому больше времени в выходные).
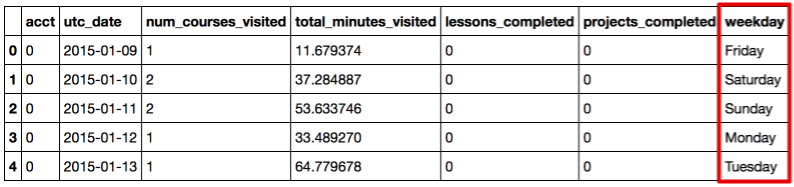
Для начала добавим в исходный DataFrame колонку «weekday», преобразовав дату ко дню недели.
daily_engagements['weekday'] = map(lambda x: datetime.strptime(x, '%Y-%m-%d').strftime('%A'),
daily_engagements.utc_date)
daily_engagements.head()
# pandas code
weekday_engagement_pandas = pd.DataFrame(daily_engagements.groupby('weekday').total_minutes_visited.mean())
# pandasql code
aggr_query = '''
SELECT
avg(total_minutes_visited) as total_minutes_visited,
weekday
FROM daily_engagements
GROUP BY weekday
'''
weekday_engagement_pandasql = ps.sqldf(aggr_query, locals()).set_index('weekday')
week_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_engagement_pandasql.loc[week_order].plot(kind = 'bar', rot = 45,
title = 'Total time spent on Udacity by weekday')
Вывод: Любопытно, но в среднем больше всего времени студенты проводят за курсами во вторник, а меньше всего в суботту. В среднем студенты больше времени тратят на MOOC в будние дни, нежели в выходные. Еще одно доказательство того, что я нерепрезентативна.
JOIN таблиц
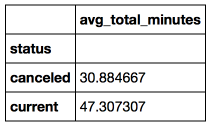
Задача: рассмотрим студентов, которые не прошли специализацию (со статусом canceled) и тех, которые успешно учатся/учились и сравним для них среднюю активность в день за первую неделю, после того как они записались на специализацию. Есть гипотеза, что те, кто остались и успешно учатся, тратили на обучение больше времени.
Для ответа на этот вопрос нам понадобятся данные из обеих таблиц enrollments и daily engagements, так что будем использовать join по ID студента.
Также в этой задаче есть несколько подводных камней, которые нужно учесть:
- не все пользователи это живые люди, есть также тестовые аккаунты Udacity, их нужно отфильтровать
is_udacity = 0; - студент может записываться на специализацию несколько раз, в том числе и с интервалом менее одной недели, так что нужно проверять что дата активности utc date находится между join date и cancel date (только для студентов со статусом canceled).
# pandas code
join_df = pd.merge(daily_engagements,
enrollments[enrollments.is_udacity == 0],
how = 'inner',
right_on ='account_key',
left_on = 'acct')
join_df = join_df[['account_key', 'status', 'total_minutes_visited', 'utc_date', 'join_date', 'cancel_date']]
join_df['days_since_joining'] = map(lambda x: x.days,
pd.to_datetime(join_df.utc_date) - pd.to_datetime(join_df.join_date))
join_df['before_cancel'] = (pd.to_datetime(join_df.utc_date) <= pd.to_datetime(join_df.cancel_date))
join_df = join_df[join_df.before_cancel | (join_df.status == 'current')]
join_df = join_df[(join_df.days_since_joining < 7) & (join_df.days_since_joining >= 0)]
avg_account_total_minutes = pd.DataFrame(join_df.groupby(['account_key', 'status'], as_index = False)
.total_minutes_visited.mean())
avg_engagement_pandas = pd.DataFrame(avg_account_total_minutes.groupby('status').total_minutes_visited.mean())
avg_engagement_pandas.columns = []
# pandasql code
join_query = '''
SELECT
avg(avg_acct_total_minutes) as avg_total_minutes,
status
FROM
(SELECT
avg(total_minutes_visited) as avg_acct_total_minutes,
status,
account_key
FROM
(SELECT
e.account_key,
e.status,
de.total_minutes_visited,
(cast(strftime('%s',de.utc_date) as interger) - cast(strftime('%s',e.join_date) as interger))/(24*60*60)
as days_since_joining,
(cast(strftime('%s',e.cancel_date) as interger) - cast(strftime('%s', de.utc_date) as interger))/(24*60*60)
as days_before_cancel
FROM enrollments as e JOIN daily_engagements as de ON (e.account_key = de.acct)
WHERE (is_udacity = 0) AND (days_since_joining < 7) AND (days_since_joining >= 0)
AND ((days_before_cancel >= 0) OR (status = 'current'))
)
GROUP BY status, account_key)
GROUP BY status
'''
avg_engagement_pandasql = ps.sqldf(join_query, locals()).set_index('status')
Стоит отметить, что в SQL запросе были использованы функции cast и strftime, чтобы привести даты из строк в timestamp (количество секунд с начала эпохи), а затем посчитать разницу между этими датами в днях.
Вывод: В среднем студенты, не забросившие специализацию, в первую неделю проводили на Udacity на 53% больше времени чем те, кто решил прекратить обучение.
В этой статье мы рассмотрели примеры применения библиотеки Pandasql для анализа данных и сравнили ее с использованием функциональности Pandas. Мы применяли фильтрацию, сортировку, агрегатные функции и join’ы для работы с DataFrames в Pandasql.
Pandas — очень удобная библиотека, позволяющая быстро и легко преобразовывать данные, но мне кажется, что в некоторых задачах проще выразить свою мысль с помощью декларативного языка и тогда Pandasql приходит на помощь. Кроме того, Pandasql может быть полезен тем, кто только начинает знакомство с Pandas, но уже имеет хорошие знания SQL.
Полный код примеров и исходные данные также приведены в репозитории на github.
Для заинтересовавшихся есть также хороший tutorial по Pandasql на The Yhat Blog.
